













組織のインフラにおけるITモニタリングを使用することで、その信頼性を向上させ、深刻な問題、障害、およびダウンタイムを防ぐことができます。ITモニタリングを実装するためのアプローチは、専用ツールを使用するか、ネイティブ機能を利用するかのいずれかです。いずれのアプローチでも、必要に応じてモニタリングデータを表示したり、重要なイベントについて通知を受け取るための自動アラートやレポートを構成したりできます。このブログ記事では、アラームとレポートを使用してITモニタリング戦略を強化する方法について説明します。
ビジネスにおけるITモニタリングとレポーティングの重要性
ITモニタリングは、ITインフラが適切かつ信頼性を持って機能していることを保証するために、組織にとって非常に重要です。
- 稼働時間と信頼性の最大化。重要なビジネスシステムは通常、24時間365日の運用を必要とします。このようなシステムは、ダウンタイムが深刻な結果を招く可能性のあるヘルスケア、金融、その他のサービスプロバイダーなどの業界で使用されています。幸いなことに、ITモニタリングシステムを実装し、適切に構成すれば、そのような問題を防ぐことが可能です。
プロアクティブな問題検出は、管理者がサーバーの過負荷、アプリケーションエラー、ハードウェアの問題、パフォーマンスの低下などの潜在的な問題を主要な障害に至る前に発見するのに役立ちます。このプロアクティブなアプローチにより、管理者はサーバー、仮想マシン(VM)、ビジネス運営、エンドユーザーに悪影響を及ぼす前に対処し、修正アクションを実行することができます。潜在的な問題を示すレポートを受け取ることで、ITモニタリングと管理がより効率的になります。
- セキュリティの強化。IT監視は、無許可のアクセス試行、異常なネットワークトラフィック、サイバー攻撃の指標となる可能性のあるその他の疑わしい活動を検出するために使用されます。このアプローチにより、管理者はセキュリティ脅威をタイムリーに検出できます。特定の業界では、罰則を避けるためにITシステムの継続的な監視を要求する規制要件に準拠する必要があります。
- パフォーマンスと効率の向上。管理者は、IT監視とアラートを設定することで、サーバー、仮想マシン、ネットワーク機器のリソース使用を最適化できます。CPU、メモリ、および帯域幅の使用状況を追跡し、このデータをさらに分析するためにIT監視ツールを設定することで、何を改善すべきかをより良く理解できるようになります。その結果、組織はリソースを最適化し、無駄を減らしてITシステムの高効率を達成できます。これにより、管理者はボトルネックを特定し、パフォーマンスを向上させることもできます。
- ビジネス継続性と災害復旧を向上する。早期障害検知は、組織の管理者がITモニタリングシステムを通知と共に構成すべき主な理由の1つです。このアプローチにより、データの破損、アプリケーションのクラッシュ、ハードウェアの障害の兆候を早期に検出してデータ損失を防ぐことができます。データ損失を防ぐことは、ビジネス継続性を維持するために必要です。構成された通知を備えたモニタリングツールを使用することで、管理者はバックアップシステムと災害復旧計画がテストされ、正しく機能していることを確認できます。これにより、災害が発生した場合にビジネスが迅速にデータとワークロードを回復できる保証になります。
- 顧客体験を向上する。顧客はいつでもサービスが利用可能であることを期待しています。ITモニタリングシステムをサーバー、VM、ネットワーク機器、ウェブサイト運用に関連するアプリケーションを監視するように構成することで、ウェブサイトやサービスが常に顧客に利用可能であることを確認できます。リソースの可用性だけでなく、パフォーマンスも監視され、最高のサービスを提供するために役立ちます。
問題に関する情報を含むレポートを受け取ることで、迅速な解決が可能となります。レポートには、管理者が問題をできるだけ早く解決するために必要な情報が含まれています。これらの行動により、顧客への負の影響が最小限に抑えられ、結果として顧客はポジティブな体験を得ることができます。
- コスト管理。予防的な監視の設定は、ダウンタイムを防ぐことができます。計画外のダウンタイムはコストがかかる可能性があり、組織は収益を失い、データとインフラを回復するためにリソースを費やさなければなりません。アラート通知付きの監視により、管理者は問題をできるだけ早く修正し、ダウンタイムのリスクを軽減することができます。
ITモニタリングにおけるアラームの理解
ITモニタリングシステム用のアラームを設定することで、管理者が問題を認識し、迅速に修正する反応時間が向上します。グラフや統計などのリソースのみが設定されている場合、システム管理者はモニタリング情報のウェブページをチェックしたときにのみ問題に気づくことができます。管理者はさまざまなタスクを持っており、通常はITインフラの状態を継続的にモニタリングすることはできません。
アラームが設定されていると、管理者は問題、潜在的な問題、障害、その他の重要なまたは疑わしいイベントについてできるだけ早く通知メッセージを受け取ります。通常、時間間隔を設定できます。たとえば、監視システムが問題を検出した後、1分または5分後にメッセージを送信することができます。
結果として、システム管理者は問題に早く気付き、問題を修正して負の影響を回避できます。異なる通知方法が使用される可能性があり、その中には、電子メール、SMS、Skypeなどを通じた通知が含まれます。これは、ITモニタリングソフトウェアによって異なります。
アラームとは何か、そしてなぜ重要なのか?
アラームは、特定のイベントが発生し、適切な条件やしきい値がITシステムで満たされたときにトリガーされる通知です。これらの条件は、次のようなさまざまなイベントに基づいています:
- パフォーマンスの問題:高いCPU使用率、メモリの枯渇、応答時間の遅さ
- リソースのしきい値:ディスク容量が不足している、ネットワーク帯域が飽和している
- システムの障害:サーバーのクラッシュ、アプリケーションのエラー、サービスの停止
- セキュリティインシデント:不正アクセスの試行、マルウェアの検出、異常なネットワークトラフィック
- オペレーションイベント:バックアップの失敗、サービスの再起動、構成の変更
アラームがトリガーされると、モニタリングシステムがアラートを生成し、このアラートは主にIT管理者を含む関連ユーザーに、さまざまなチャネルを通じて送信されます。これらのアラートには、問題に関する情報、深刻さ、影響を受けるシステムやコンポーネント、および推奨されるアクションが含まれています。
モニタリングすべき主要なメトリクス
CPU使用率。CPU使用状況を監視することは、サーバーやシステムの処理能力において十分なリソースが確保されていることを確認するために必要です。これは、過負荷にならずにワークロードを処理するために重要です。CPU使用率が高いことは、システムが過負荷であることを示す信号となる場合があります。低いCPU使用率は、リソースが十分にあるか、CPUリソースが過小利用されていることを示します。
メモリ(RAM)使用量。アプリケーションやサービスはスムーズな動作のために十分なメモリを必要とし、このコンテキストではメモリパラメータが重要です。管理者はメモリボトルネックを防ぐためにRAM使用量を監視する必要があります。メモリボトルネックは、パフォーマンスの低下やシステムのクラッシュを引き起こす可能性があります。過剰なメモリ使用、十分でないメモリアロケーション、およびメモリリークに注意を払ってください。
ディスク使用量とI/Oパフォーマンス。ディスクスペースと入出力(I/O)パフォーマンスは、データストレージにおいて重要な指標です。これらのパラメータを監視して、パフォーマンスの問題を含むストレージ関連の問題を防ぐことをお勧めします。高いディスク使用量、使用中のディスクスペースの急速な増加、データの読み書き時の高い待機時間、頻繁なI/O待機時間に注意してください。これらのパラメータに関する異常な動作は、潜在的なストレージ問題を示す可能性があります。
ネットワーク帯域幅と遅延。ネットワークのパフォーマンスは、オフィスやデータセンター内のすべての操作に影響を与えます。なぜなら、コンピュータ、サーバ、および仮想マシンはネットワークを介して互いに接続されています。ネットワークのパフォーマンスは、顧客に提供されるサービスにとって重要です。ネットワーク帯域幅と遅延を監視することで、ボトルネックやその他の問題を検出し、ネットワークリソースを効率的に利用するために修正することができます。ネットワーク利用率の高さ、パケットロス、遅延の高さに注意してください。これらの指標は、遅いパフォーマンスやネットワークに関する問題の兆候です。
サービスとプロセスの可用性。重要なプロセスは、サーバや仮想マシン上のオペレーティングシステムで実行され、ビジネスのニーズを満たすために利用可能でなければなりません。サービスとその可用性を監視することで、クリティカルなサービスが稼働していることを確認できます。サービスの可用性を確保するために、管理者は稼働時間、サービス再起動頻度、およびプロセスの障害を監視する必要があります。
データベースのパフォーマンス。データベースは、ウェブアプリケーションを含むより複雑なソリューションの一部としてよく使用されます。さらに、組織内での利用にはデータベースが必要なソフトウェアソリューションがほとんどです。これらの理由から、データベースのパフォーマンスと可用性を監視することが重要です。データベースを監視することで、データがアクセス可能で関連する操作がスムーズに実行されることが保証されます。データベースの監視時には、クエリ応答時間、実行時間が遅いクエリ、データベースロック、および接続プールの使用状況に焦点を当てることが重要です。これらのメトリクスは、データベースの健全性にとって重要です。
ITモニタリングのためのレポーティング
レポートは、監視ツールによって収集された膨大なデータから、構造化された、実行可能なインサイトを提供するために使用されます。レポートは生データを情報に変換し、組織で働く人々や主にIT管理者にとって読みやすく理解しやすいものにします。レポートをチェックした後、管理者や経営陣は情報に基づいた意思決定を行うことができます。これにより、ITチームはパフォーマンスを最適化し、問題を予防し、ビジネス継続性を向上させることができます。
レポートには、警報を調査する際に気付かない異常を強調することができます。レポート内のデータは、手動で主要なメトリクスを検索したり収集されたデータを整理する必要がないように、より便利に集約されています。その結果、管理者は全体のインフラストラクチャや最も重要なコンポーネントの高レベルな概要を把握することができます。インシデントに至る状況について通知されることは、管理者が迅速なインシデント対応や予防措置を講じるために活用できます。
NAKIVO Backup & Replicationでの監視
NAKIVO Backup & Replicationを使用して、ITインフラストラクチャの要素を監視することができます。Webインターフェースの監視セクションに移動し、監視されるアイテムを追加し、VMware vSphereインフラストラクチャのサポートされているメトリクスを表示するグラフを確認してください。
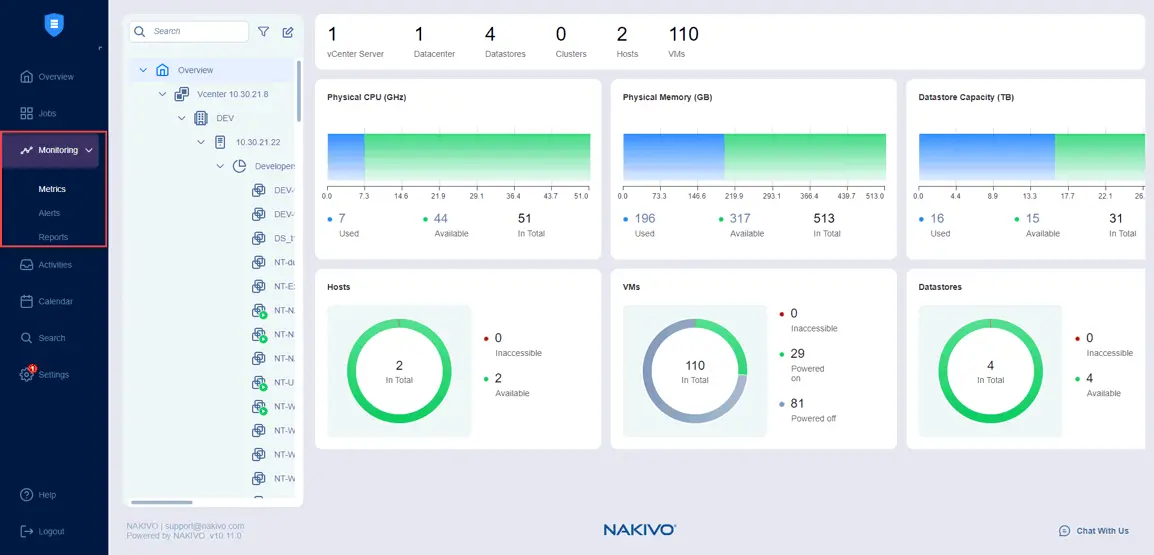
監視したいアイテムを選択することができ、監視>メトリクス内のESXiホストやクラスタ、VMware VM、データストアなどを監視できます。
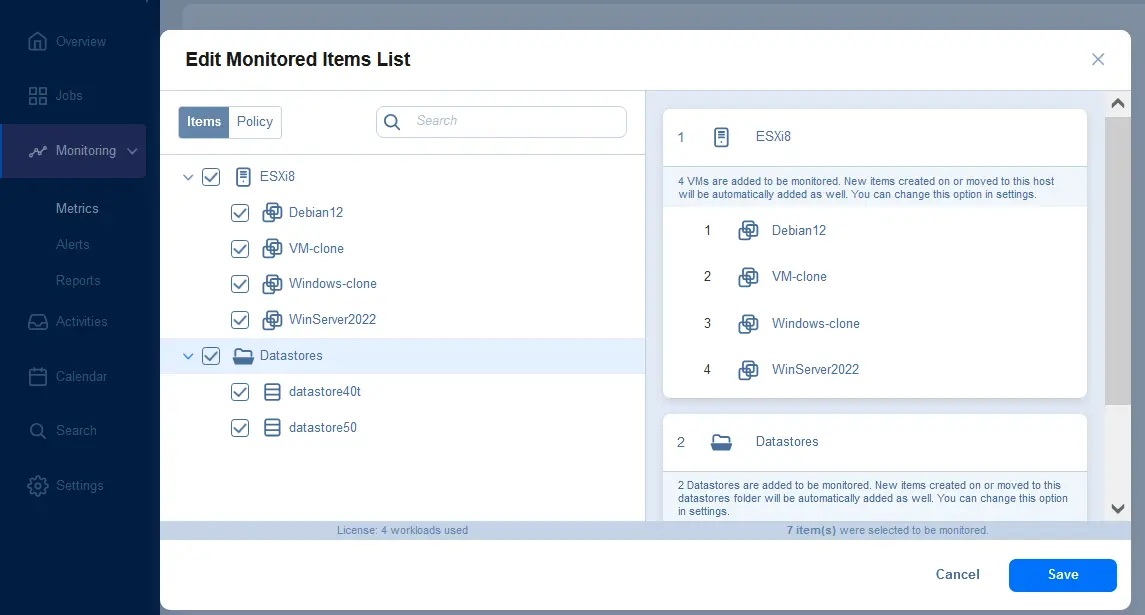
NAKIVOソリューションでのアラームの設定
NAKIVOソリューションでアラートを設定することで、潜在的な問題についてできるだけ早く通知を受け取り、深刻な結果を招く前に迅速に対処することができます。
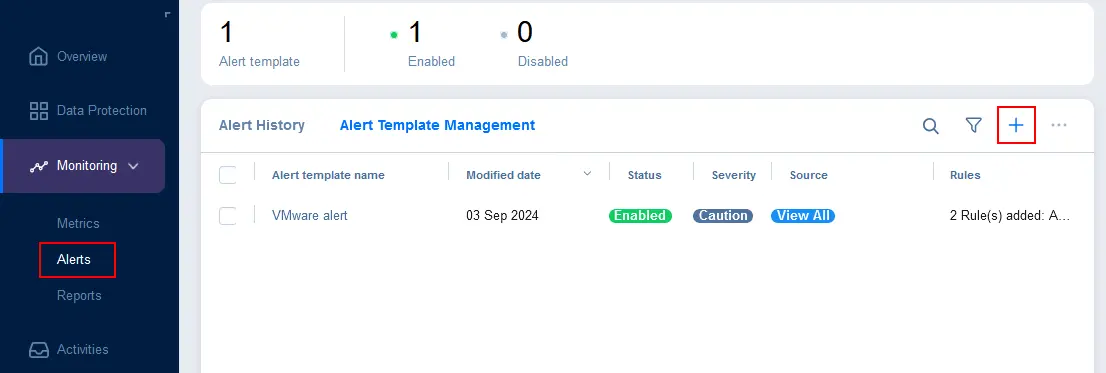
- 監視>アラートに移動し、アラートテンプレート管理タブを選択し、特定の項目のアラートを追加するために+をクリックします。
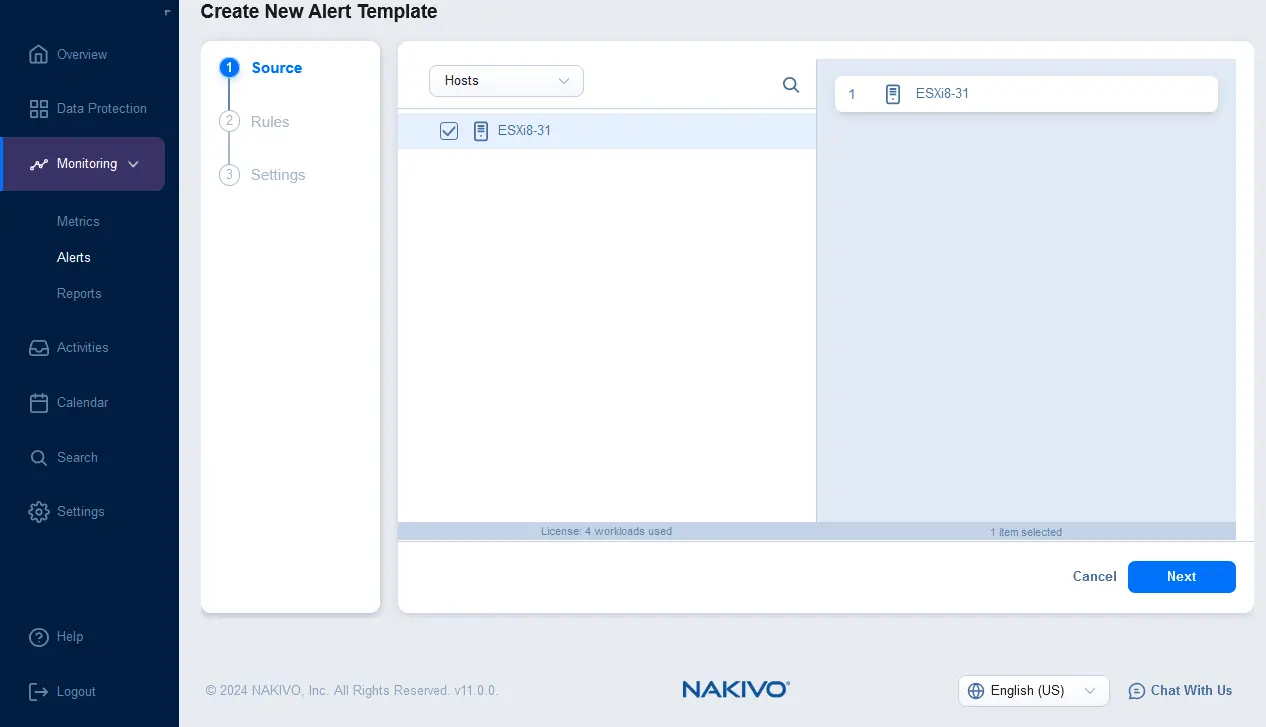
- アラートをトリガーする監視対象項目を選択します。ESXiホスト、仮想マシン(VM)、またはデータストアを選択できます。次へをクリックして続行します。
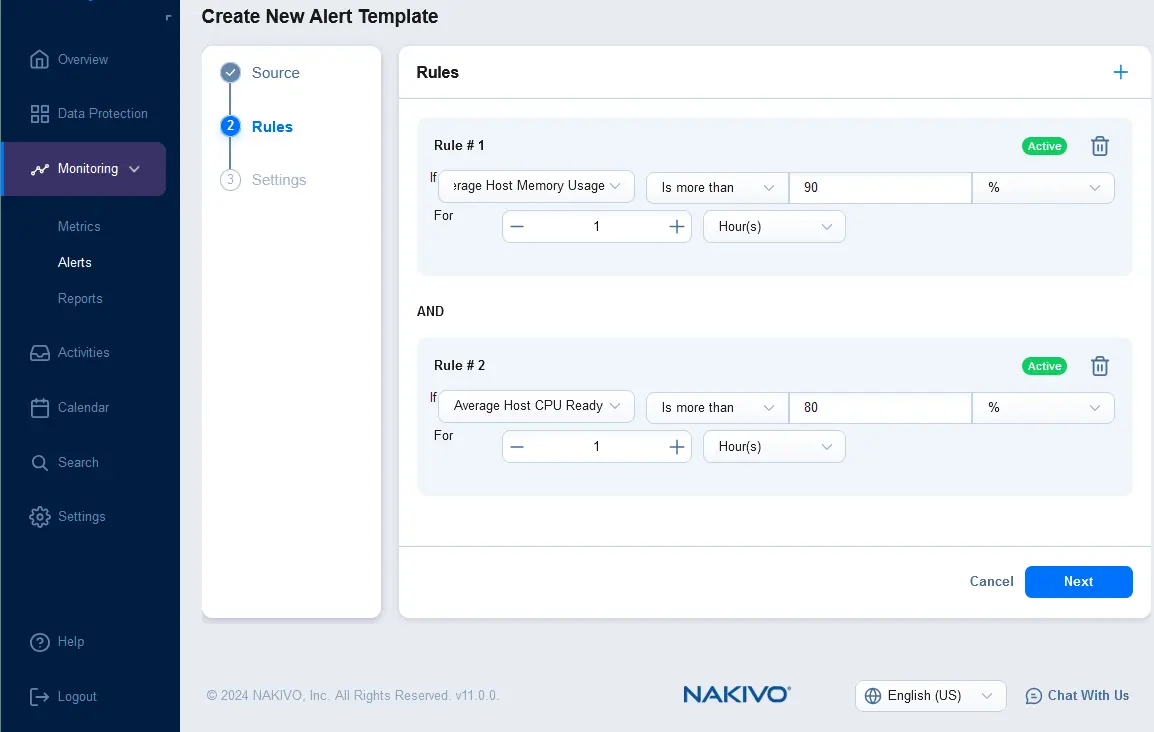
- 新しいアラートテンプレートのルールを設定します。+をクリックし、ルール条件を選択します。たとえば、ホストの平均メモリ使用率が1時間に90%を超える場合にトリガーされるアラートルールテンプレートを設定できます。1つのアラートテンプレートに複数のルールを追加することができます。
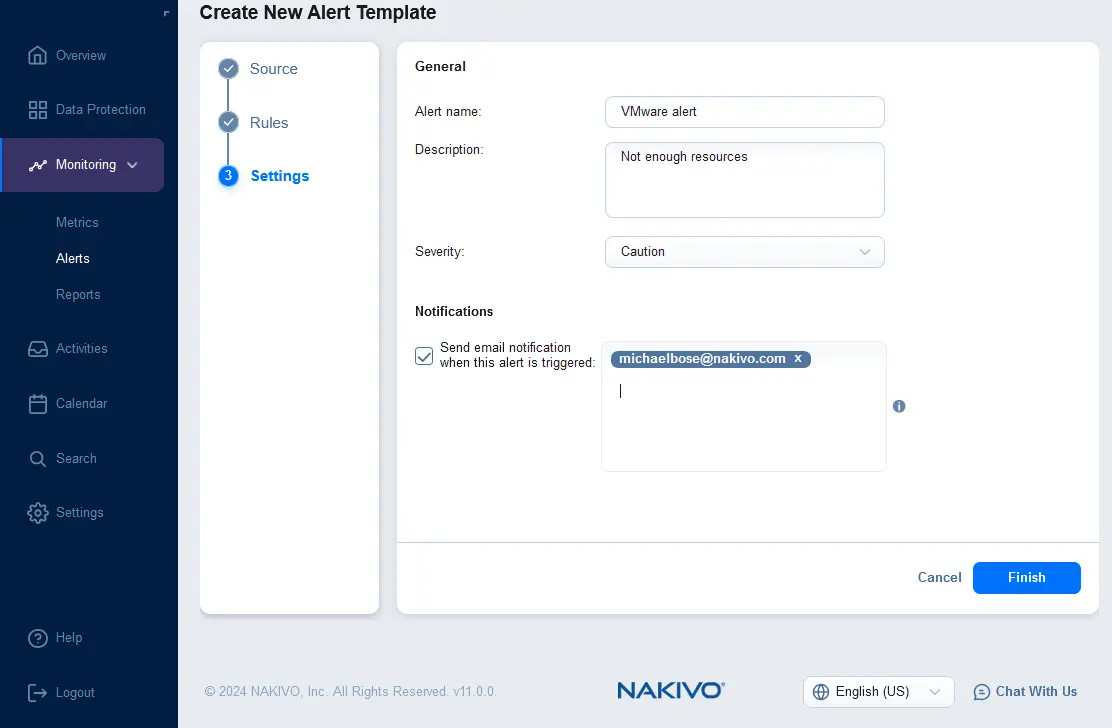
- アラートテンプレートの設定を構成します。アラート名と説明を入力し、重要度を選択します。このアラートがトリガーされたときに電子メール通知を送信するチェックボックスを選択し、アラート通知を受け取るべき受信者の複数の電子メールアドレスを入力します。 完了をクリックします。
NAKIVOソリューションでのレポートの設定
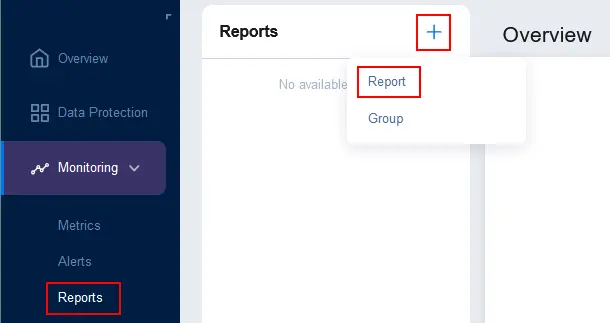
- レポートを構成するには、監視>レポートに移動し、+をクリックしてレポートを選択します。
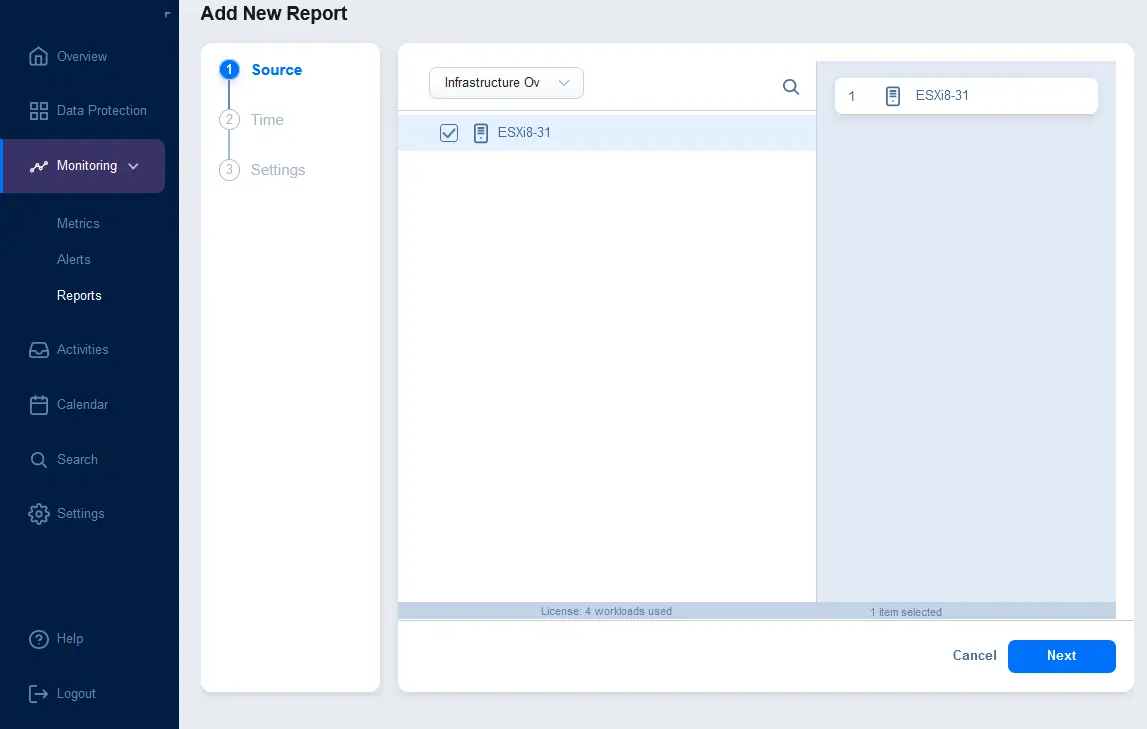
- サポートされているソースタイプの1つを選択できます:
- インフラストラクチャ概要 – vCenterサーバー、vCenterで管理されているESXiホスト、単独のESXiホストに関する情報
- VMのパフォーマンス
- データストア容量
- ホストのパフォーマンス
- 保護レポート
ソースタイプを選択したら、レポートに含めるアイテムを選択してください。以下のスクリーンショットでは、ドロップダウンリストでインフラストラクチャ概要が選択され、ESXiホストがレポートに含まれるように選択されています。続行するには次へをクリックしてください。
- レポートの時間と日付の範囲を構成してください。たとえば、過去30日間のレポートを作成できます。
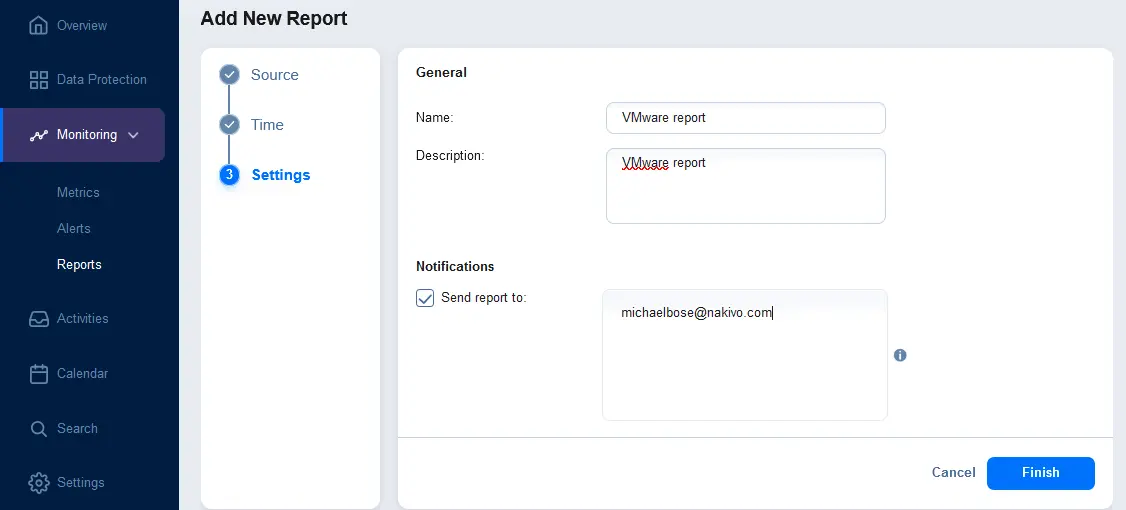
- レポート設定を構成します。表示するレポート名と説明を入力してください。オプションで、通知セクションで、指定したメールアドレスにレポートを送信するためのチェックボックスを選択します。メールアドレスを入力し、Enterを押してこのメールアドレスを適用します。複数のメールアドレスを入力できます。完了を押して、レポート作成の設定を保存します。
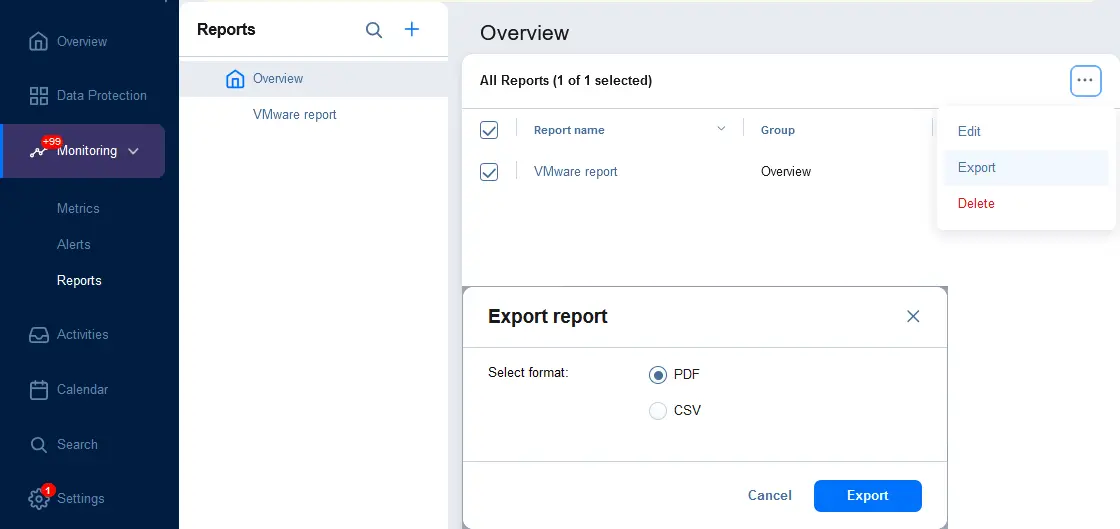
- レポートをファイルにエクスポートできます。監視 >レポートに移動し、エクスポートしたいレポートを選択します(チェックボックスを選択)。…(その他のオプション)ボタンをクリックし、エクスポートをクリックし、ダイアログボックスでファイル形式(PDFまたはCSV)を選択します。エクスポートを押します。
結論
ITインフラを監視することで、管理の効率が向上し、ビジネスの継続性が確保され、コストが節約される可能性があります。IT監視ツールを構成して、早期のインシデント対応のためにアラートやレポートを送信し、潜在的な問題を防ぎ、既存の問題をできるだけ早く修正することをお勧めします。NAKIVO Backup & Replicationを使用して、VMware仮想マシンを含むデータを保護し、vSphereインフラやデータ保護ジョブを監視してください。
Source:
https://www.nakivo.com/blog/how-to-use-alarms-and-reporting-for-it-monitoring/