













Le organizzazioni oggi devono utilizzare lo spazio di archiviazione in modo razionale poiché grandi quantità di dati possono aumentare i costi di archiviazione e portare alla proliferazione dei dati. I supporti di archiviazione dei dati differiscono in termini di costo, velocità di scrittura/lettura, ecc., e diversi tipi di dati dovrebbero essere archiviati sui supporti più efficienti per risparmiare costi e risorse.
Ad esempio, archiviare i backup su dispositivi SSD (unità a stato solido) ad alta velocità è eccessivamente costoso poiché l’alta velocità degli SSD non è necessaria per questo tipo di dati secondari. Al contrario, archiviare le macchine virtuali di produzione (VM) su dischi rigidi (HDD) con bassa velocità di rotazione (RPM) potrebbe essere conveniente dal punto di vista del budget ma non soddisferà i requisiti di prestazione per i sistemi primari.
Per questo motivo, i tipi di archiviazione dovrebbero essere categorizzati per utilizzare ciascun tipo di archiviazione per memorizzare i dati appropriati mediante la suddivisione in livelli di archiviazione.
Cos’è la suddivisione in livelli di archiviazione?
La suddivisione in livelli di archiviazione è una strategia di gestione dell’archiviazione dati utilizzata per ottimizzare le prestazioni e l’efficienza dei costi di un sistema di archiviazione suddividendo i dati in diversi livelli in base alle loro caratteristiche e ai modelli di accesso. L’obiettivo principale della suddivisione in livelli di archiviazione è garantire che i dati più frequentemente accessibili e critici siano archiviati su supporti di archiviazione ad alte prestazioni, mentre i dati meno frequentemente accessibili o meno critici siano archiviati su supporti di archiviazione a costo inferiore.
Questo approccio consente alle organizzazioni di archiviare i propri dati su vari tipi di supporti di archiviazione, come veloci ed costosi unità a stato solido (SSD) o dischi rigidi (HDD) più lenti ma più economici, a seconda del valore dei dati e dei modelli di utilizzo.
La tierizzazione dello storage inizia con la classificazione dei dati in diverse categorie o livelli in base a criteri come la frequenza di accesso, l’importanza e i requisiti di performance. Questa classificazione può cambiare nel tempo se il processo lavorativo lo richiede. Il numero e i tipi di livelli di storage possono variare – da 3 a 7 – a seconda dell’infrastruttura di storage.
A tiered storage architecture helps organizations reduce storage costs by allocating high-cost storage resources only to the data that requires it. This ensures that expensive resources are not wasted on data that doesn’t benefit from them. By placing hot (frequently accessed) data on high-performance storage media and cold (less frequently accessed) data on lower-performance media, storage tiering optimizes overall system performance.
Classi dei Dati per lo Storage Tierizzato
Le classi dei dati in un’architettura di storage tierizzato si riferiscono alla categorizzazione o classificazione dei dati basata su attributi o caratteristiche specifiche. Queste classi creano una gerarchia dei dati e aiutano a determinare dove i dati dovrebbero essere memorizzati all’interno di un sistema di storage tierizzato. Questo approccio garantisce che i dati siano collocati nel livello di storage più appropriato per bilanciare le prestazioni, il costo e l’accessibilità. I dettagli delle classi dei dati possono variare a seconda delle esigenze dell’organizzazione e dell’infrastruttura di storage. Gli attributi comuni utilizzati per la classificazione dei dati sono:
- Frequenza di accesso. Uno dei criteri principali per la classificazione dei dati è quanto spesso viene accesso dagli utenti e dalle applicazioni. I dati che vengono utilizzati regolarmente e attivamente (dati “caldi”) dovrebbero essere memorizzati su livelli di storage ad alte prestazioni, come SSD o unità NVMe, per garantire tempi di accesso rapidi. Al contrario, i dati poco utilizzati (dati “freddi”) possono essere collocati su livelli di storage a costo inferiore come HDD o storage cloud.
- Criticità o importanza. Alcuni dati sono più critici per le operazioni di un’organizzazione o per i requisiti di conformità rispetto ad altri. I dati critici potrebbero necessitare di essere archiviati su livelli di storage più affidabili e resilienti, come il RAID (insieme ridondante di dischi indipendenti) o lo storage cloud con ridondanza, per ridurre al minimo il rischio di perdita di dati.
- Tipo di dati. Tipi diversi di dati, come file di database, contenuti multimediali, log delle applicazioni o documenti archivistici, possono avere requisiti di archiviazione variabili. Ad esempio, i file multimediali possono richiedere un alto throughput e capacità, mentre i log possono essere archiviati su storage più lenti purché siano conservati per scopi di conformità.
- Periodo di conservazione. I dati con requisiti specifici di conservazione o conformità potrebbero dover essere archiviati su livelli che possono garantire l’integrità e la disponibilità dei dati per la durata richiesta. I dati di conformità spesso richiedono una conservazione a lungo termine e quindi possono essere archiviati su livelli di storage più affidabili.
- Dimensione. Oggetti di grandi dimensioni possono beneficiare dell’essere archiviati su livelli di storage ottimizzati per la capacità, mentre i dati di piccole dimensioni e frequentemente accessibili possono richiedere uno storage con bassa latenza e elevata performance di I/O.
- Ciclo di vita dei dati. I dati passano attraverso varie fasi nel loro ciclo di vita, dalla creazione e uso attivo all’archiviazione o alla cancellazione. Le classi di dati dovrebbero tener conto di queste fasi e spostare i dati tra i livelli secondo necessità. Ad esempio, i dati appena creati possono iniziare su un livello ad alte prestazioni ma gradualmente essere spostati su livelli a costo inferiore man mano che diventano meno attivi.
- Sensibilità al costo. Le organizzazioni spesso hanno vincoli di bilancio. Le classi di dati possono aiutare ad allineare i costi di archiviazione dei dati con le considerazioni di bilancio garantendo che le risorse di archiviazione più costose siano riservate per i dati che giustificano il costo.
- Requisiti dell’utente o dell’applicazione. Utenti o applicazioni differenti possono avere esigenze di archiviazione specifiche. Le classi di dati possono tener conto di questi requisiti per garantire che ciascun gruppo riceva le prestazioni e la capacità di archiviazione necessarie.
Una volta che i dati sono classificati in queste classi, vengono utilizzate politiche e algoritmi per gestire il posizionamento e lo spostamento dei dati all’interno dell’infrastruttura di archiviazione a più livelli. Ciò garantisce che i dati siano continuamente ottimizzati per le prestazioni e l’efficienza dei costi, rispettando le esigenze organizzative e i modelli di accesso.
Classificazione con archiviazione calda, tiepida e fredda
Il tipo comune di classificazione dei dati nei sistemi di archiviazione a più livelli consiste nella classificazione dei dati come mission-critical, caldi, tiepidi e freddi. Queste classi aiutano a determinare come i dati vengono archiviati, gestiti e accessibili all’interno dell’infrastruttura di archiviazione. In questo caso, le classi di dati utilizzate nelle strategie di archiviazione a più livelli includono:
- Dati mission-critical. Questa classe di dati si riferisce ai dati che sono assolutamente essenziali per le operazioni principali di un’organizzazione. I dati mission-critical richiedono il più alto livello di prestazioni, affidabilità e disponibilità. Di solito vengono archiviati sui supporti di archiviazione più resistenti e ad alte prestazioni disponibili, come gli array SSD ridondanti o i sistemi di archiviazione a tolleranza di guasti.
- Dati caldi. I dati caldi si riferiscono ai dati che vengono accessi attivamente e frequentemente. Questi dati sono tipicamente di grande importanza per l’organizzazione e richiedono tempi di risposta rapidi e storage ad alte prestazioni. I dati caldi vengono spesso archiviati sui supporti di archiviazione di livello superiore, come i drive a stato solido (SSD) o i drive NVMe, per garantire bassa latenza e accesso rapido.
- Dati tiepidi. I dati tiepidi rappresentano dati che vengono accessi meno frequentemente rispetto ai dati caldi, ma sono comunque utilizzati attivamente. Questa classe di dati risiede tipicamente in un livello inferiore rispetto ai dati caldi in termini di prestazioni, come ad esempio i dischi rigidi ad alte prestazioni (HDD) o soluzioni di storage ibride. Anche se i dati tiepidi potrebbero non richiedere lo storage più veloce, devono comunque essere prontamente disponibili per un accesso efficiente.
- Dati freddi. I dati freddi includono dati che vengono raramente accessi, storici o archiviati. Questi dati sono spesso considerati meno critici e vengono archiviati su livelli di storage a costo inferiore, che potrebbero essere costituiti da HDD tradizionali più lenti o opzioni di archiviazione archiviate come nastro o storage freddo basato su cloud. L’accento per i dati freddi è sulla conservazione a lungo termine e sul risparmio di costi.
Il numero di classi di dati può dipendere dal numero di livelli di storage nel modello di classificazione dello storage. Le organizzazioni possono classificare i dati in modo più complesso utilizzando le seguenti classi di dati oltre alle classi spiegate in precedenza:
- Backup e recupero dati da disastro. I dati utilizzati per scopi di backup e recupero da disastro sono spesso categorizzati separatamente. Queste classi di dati si concentrano sul garantire che i dati possano essere ripristinati in modo affidabile e rapido in caso di perdita di dati o guasto del sistema. I dati di backup possono essere memorizzati su sistemi basati su disco, mentre le copie di conservazione a lungo termine potrebbero essere memorizzate su nastro o nel cloud.
- Dati di conformità. I dati che devono rispettare i requisiti normativi di conformità, come registri finanziari o dati sanitari, possono avere esigenze di archiviazione specifiche. Le classi di dati di conformità garantiscono che questi dati siano memorizzati in modo sicuro, con funzionalità come crittografia e rigorosi controlli di accesso, e conservati per la durata richiesta.
- Dati utente o dipartimentali. Alcune organizzazioni classificano i dati in base alla loro origine, come i dati generati da dipartimenti o utenti specifici. Questo approccio può aiutare a allocare risorse di archiviazione in base alle esigenze delle diverse unità organizzative.
- Dati temporanei o di cache. Le classi di dati per dati temporanei o di cache possono includere dati che hanno una durata breve e possono essere memorizzati su livelli di archiviazione ad alta velocità per un accesso rapido, con la comprensione che possono essere eliminati o sostituiti quando non sono più necessari.
Dati di migrazione di livello . In alcuni casi, le classi di dati vengono utilizzate per identificare dati che si stanno spostando attivamente tra livelli di archiviazione in base a modelli di accesso. Ad esempio, i dati che iniziano come caldi ma diventano meno frequentemente accessibili nel tempo possono migrare verso livelli di archiviazione più caldi o più freddi. - Dati di migrazione delle gerarchie. In alcuni casi, le classi di dati vengono utilizzate per identificare i dati che si spostano attivamente tra le gerarchie di archiviazione in base ai modelli di accesso. Ad esempio, i dati che iniziano come caldi ma che vengono meno acceduti frequentemente nel tempo potrebbero migrare verso archiviazione più tiepida o fredda.
Queste classi di dati possono servire da linee guida per gli amministratori di archiviazione e sistemi di gestione automatizzata dell’archiviazione per prendere decisioni informate su dove posizionare i dati all’interno di un’infrastruttura di archiviazione gerarchica.
Tipi di Archiviazione Multigerarchia
L’archiviazione multigerarchia si riferisce ad un’architettura di archiviazione in cui i dati sono classificati in diverse gerarchie in base ai loro requisiti di prestazioni e accessibilità. Ogni gerarchia rappresenta un livello specifico di prestazioni di archiviazione e costo. L’obiettivo è garantire che i dati siano memorizzati nella gerarchia più appropriata per ottimizzare sia le prestazioni che l’efficienza dei costi. Di seguito, puoi vedere le gerarchie di archiviazione comuni, a partire da Tier 0:
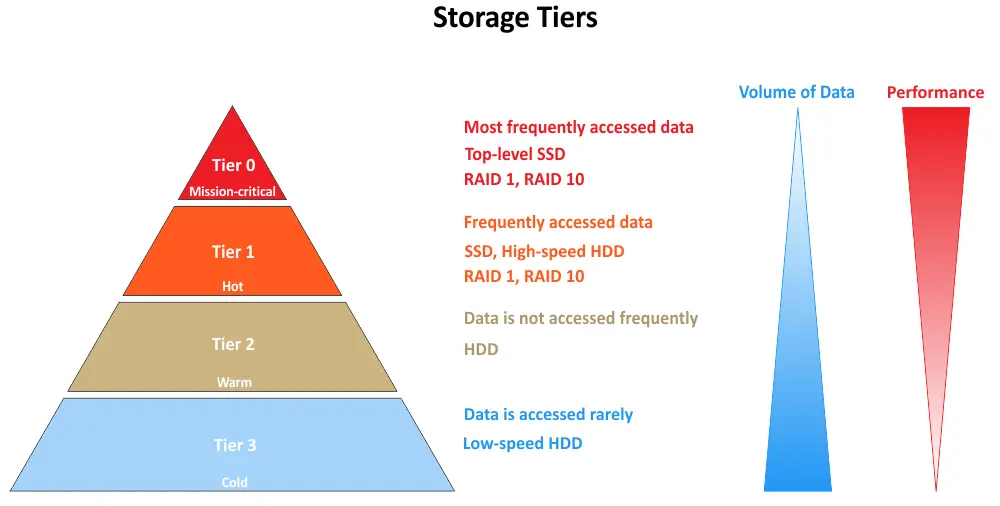
- Tier 0 rappresenta la gerarchia di archiviazione con le migliori prestazioni in un sistema di archiviazione multigerarchia. È spesso composto dai supporti di archiviazione più veloci ed esigenti disponibili, come dischi a stato solido (SSDs) di fascia enterprise o NVMe (Non-Volatile Memory Express) SSDs. I dati memorizzati in Tier 0 sono di solito fondamentali e richiedono bassissime latenze, elevate prestazioni I/O e accesso rapido ai dati. Viene utilizzato per applicazioni e dati che richiedono i livelli più alti di prestazioni.
- Primo livello è il livello successivo in termini di prestazioni e costo. Di solito è costituito da dischi rigidi (HDD) ad alte prestazioni, array di archiviazione ibrida (che combinano SSD e HDD) o SSD più veloci, che non sono così costosi come quelli nel livello 0. I dati nel livello 1 sono importanti ma potrebbero non richiedere l’archiviazione più veloce disponibile. Questo livello è adatto per applicazioni e dati che necessitano di buone prestazioni ma possono tollerare un po’ più di latenza rispetto ai dati del livello 0.
- Livello 2 rappresenta un livello di archiviazione a costo inferiore con prestazioni leggermente più lente rispetto al livello 1. Spesso include HDD tradizionali o soluzioni di archiviazione basate sul cloud. I dati nel livello 2 sono tipicamente meno accessibili o meno critici per le operazioni in tempo reale. Questo livello è adatto per dati archiviati, backup e dati che possono tollerare tempi di accesso più lunghi.
- Livello 3 è il livello di archiviazione a costo più basso in un sistema di archiviazione multi-livello. Di solito include soluzioni di archiviazione di livello archivio, come biblioteche a nastro e archiviazione fredda basata sul cloud. I dati nel livello 3 sono raramente accessibili e sono principalmente conservati per motivi di conformità, normativi o per scopi di archiviazione a lungo termine. Offre le prestazioni più basse ma l’archiviazione più economica.
Alcune organizzazioni che utilizzano principalmente archiviazione on-premises dedicano livelli speciali aggiuntivi per l’archiviazione nel cloud pubblico e l’archiviazione di backup:
- Cloud Tier. In alcune architetture di archiviazione a più livelli, un Cloud Tier separato viene utilizzato per memorizzare i dati in un servizio di archiviazione cloud come Amazon S3 o Azure Blob Storage. Ciò consente alle organizzazioni di trarre vantaggio dall’archiviazione cloud scalabile e conveniente per i dati che potrebbero non adattarsi perfettamente ai livelli on-premises. I dati nel cloud tier possono essere acceduti via internet quando necessario.
- Backup Tier. Sebbene non sempre considerato un livello di archiviazione primario, l’archiviazione di backup è una parte fondamentale della gerarchia di archiviazione. I dati di backup vengono memorizzati su sistemi basati su disco o biblioteche di nastri, a seconda della strategia di backup dell’organizzazione. L’obiettivo è la protezione dei dati e il recupero rapido in caso di perdita di dati o disastri.
Quanti livelli vengono generalmente utilizzati dalle organizzazioni?
Il numero di livelli utilizzati dalle organizzazioni nelle loro architetture di archiviazione può variare ampiamente a seconda delle loro esigenze specifiche, vincoli di budget e complessità dei requisiti di gestione dei dati. Tuttavia, in pratica, molte organizzazioni implementano comunemente una gerarchia di archiviazione a tre livelli come punto di partenza (Tier 0, Tier 1, Tier 2).
Molte organizzazioni iniziano con questi tre livelli come base e poi personalizzano la loro infrastruttura di archiviazione per soddisfare le loro esigenze specifiche. Possono aggiungere ulteriori livelli o adottare classi di archiviazione specializzate man mano che i loro requisiti di dati si evolvono. Ad esempio:
- Alcune organizzazioni potrebbero aggiungere un livello 4 o livello 5 per il lungo periodo, archiviazione profonda, che potrebbe coinvolgere tecnologie come biblioteche di nastri o cloud storage a basso costo.
- Altri potrebbero implementare un livello cloud per backup remoti e scopi di disaster recovery, utilizzando servizi di cloud storage come Amazon S3 o Azure Blob Storage.
- Le strategie ibride cloud possono introdurre anche più livelli, compresi livelli basati sul cloud per i dati che devono essere spostati in modo integrale tra storage locale e cloud.
La chiave è progettare un’architettura di storage che si allinea con i modelli di accesso ai dati dell’organizzazione, i requisiti di prestazioni e le considerazioni di budget. È anche importante implementare politiche efficaci di gestione dei dati e tiering per garantire che i dati siano memorizzati sul livello appropriato in base alle esigenze in continua evoluzione di questi dati nel tempo. Con l’evoluzione continua delle tecnologie di storage dei dati, le organizzazioni potrebbero adattare le loro strategie di storage a più livelli per sfruttare le nuove innovazioni e soluzioni a costo efficiente.
Questi livelli di storage comuni possono essere riassunti in una tabella con spiegazioni brevi e casi d’uso tipici:
| Numero di Livello | Nome del Livello | Spiegazione | Casi d’uso Tipici |
| Livello 0 | SSD Ultraveloci | Massima prestazione di archiviazione, bassa latenza | Database critici, applicazioni in tempo reale |
| Livello 1 | SSD ad Alte Prestazioni | Buon equilibrio tra velocità e costo | Dati delle applicazioni generali, macchine virtuali |
| Livello 2 | Archiviazione ibrida | Mix di SSD e HDD, costo-efficace | Archiviazione di backup, dati secondari, condivisioni file |
| Livello 3 | HDD Nearline | Archiviazione di backup, dati secondari, condivisioni file | Dati archiviati, archiviazione a lungo termine |
| Livello 4 | Archiviazione fredda | Basso costo, capacità molto elevata, accesso lento | Dati archiviati accessibili raramente |
| Livello Cloud | Archiviazione cloud | Archiviazione basata sul cloud scalabile | Backup offsite, disaster recovery, condivisione dati |
Si tenga presente che i nomi e le caratteristiche dei livelli di archiviazione possono variare tra le organizzazioni e i fornitori di archiviazione. La tabella sopra fornisce una panoramica generale dei comuni livelli di archiviazione e dei loro casi d’uso tipici, ma le implementazioni specifiche possono differire in base alle esigenze dell’organizzazione e alle tecnologie disponibili.
Dove vengono Utilizzati i Livelli di Archiviazione
La suddivisione in livelli di archiviazione è una strategia di gestione dell’archiviazione che può essere utilizzata sia on-premises (all’interno dei data center dell’organizzazione o ambienti cloud privati) sia nel cloud pubblico. Si tratta di un approccio flessibile che può essere applicato a varie architetture di archiviazione per ottimizzare il posizionamento dei dati e i modelli di accesso.
Architettura di storage a livelli on-premises
L’architettura di storage a livelli viene utilizzata negli ambienti seguenti focalizzati sull’infrastruttura on-premises (locale):
- Data center tradizionali. Nei data center on-premises tradizionali, l’architettura di storage a livelli viene comunemente utilizzata per gestire i dati memorizzati su diversi tipi di supporti di archiviazione, come SSD, HDD e biblioteche di nastri. Le organizzazioni implementano l’architettura di storage a livelli per ottimizzare prestazioni, costi e disponibilità dei dati all’interno della propria infrastruttura.
- Cloud privati. Molti ambienti di cloud privati incorporano l’architettura di storage a livelli per gestire in modo efficiente i dati attraverso diversi tipi di risorse di archiviazione. Questo è particolarmente importante nelle configurazioni di cloud privato dove le risorse devono essere allocate dinamicamente per supportare vari carichi di lavoro.
- Cloud ibridi. In un ambiente cloud ibrido, che combina infrastruttura on-premises con risorse di cloud pubblico, l’architettura di storage a livelli può essere utilizzata per ottimizzare il posizionamento dei dati attraverso entrambi gli ambienti. Le organizzazioni possono utilizzare politiche di livellamento per determinare quali dati dovrebbero risiedere on-premises e quali dovrebbero essere spostati nel cloud pubblico per efficienza dei costi o scalabilità.
Architettura di storage a livelli nel cloud pubblico
Per quanto riguarda il cloud pubblico, l’architettura di storage a livelli viene utilizzata negli ambienti seguenti:
- Servizi di storage cloud pubblico. I provider di cloud pubblico come Amazon Web Services (AWS), Microsoft Azure e Google Cloud Platform (GCP) offrono le proprie opzioni di stratificazione del storage cloud come parte dei loro servizi di storage cloud. Ad esempio, AWS offre classi di storage S3 (Standard, Intelligent-Tiering, Glacier, ecc.), ciascuna adattata per diversi requisiti di prestazioni e costi.
- Storage di oggetti. I servizi di storage di oggetti nel cloud pubblico spesso supportano la stratificazione del storage per consentire ai clienti di scegliere la classe di storage più appropriata per i loro dati. Questo è vantaggioso per ottimizzare i costi e i tempi di accesso.
Stratificazione del Storage Automatizzata
La stratificazione automatizzata del storage e l’ottimizzazione della stratificazione del storage sono tecniche utilizzate nella moderna gestione dei dati di archiviazione per garantire che i dati vengano posizionati nella stratificazione di archiviazione più adatta in modo efficace e al momento giusto.
Automatizzatastratificazione del storage è una tecnica di gestione dei dati che implica lo spostamento automatico e dinamico dei dati tra diverse stratificazioni di archiviazione in base a specifiche politiche e criteri. Queste politiche sono generalmente definite dagli amministratori di storage o impostate da software intelligente di gestione del storage. L’obiettivo primario della stratificazione automatizzata del storage è ottimizzare l’uso delle risorse di archiviazione garantendo che i dati siano memorizzati nella stratificazione più appropriata in qualsiasi momento.
Il livellamento automatico dell’archiviazione ti consente di ottimizzare dinamicamente il livellamento dell’archiviazione, monitorando continuamente l’uso dei dati e l’accesso per determinare le priorità dei dati e i livelli di livellamento richiesti. Quando utilizzi l’archiviazione automatizzata, imposti i tuoi limiti preferiti e l’automazione si prende cura del resto.
Man mano che l’uso dei dati raggiunge i limiti predefiniti, viene spostato di conseguenza. Se la frequenza di accesso ai dati aumenta, si sposta su un livello a latenza inferiore. Quando i dati non vengono utilizzati, vengono spostati su un livello a costo inferiore e latenza superiore. Questo approccio ottimizza sia i tuoi costi che le prestazioni con uno sforzo minimo e nessun bisogno di manutenzione continua.
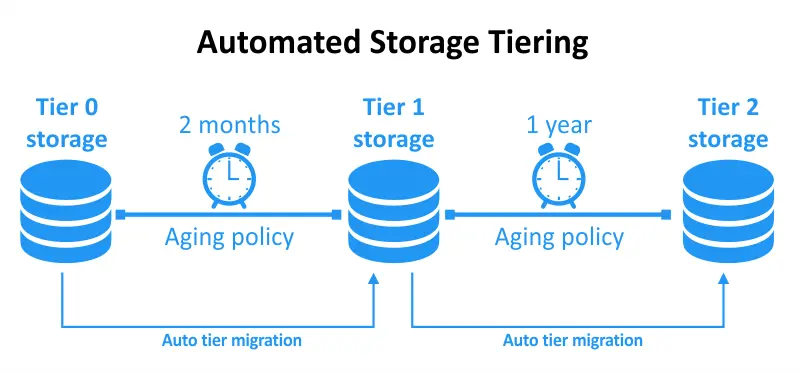
Il livellamento automatico dell’archiviazione facilita il trasferimento di dati guidato da politiche tra i livelli di archiviazione, allineandosi così con le esigenze di capacità e prestazioni dell’utente. Questa funzionalità funziona in modo efficiente con la tua architettura di archiviazione gerarchizzata esistente e semplifica la gestione dei dati attraverso l’automazione. Il livellamento automatico dell’archiviazione migliora l’ottimizzazione delle prestazioni e l’efficienza dei costi a causa dell’adattamento in tempo reale e il rapido movimento dei dati.
Livello di archiviazione ottimizzazione è un concetto più ampio che comprende varie strategie, tra cui automatizzato livellamento dell’archiviazione, per garantire che l’infrastruttura di archiviazione di un’organizzazione sia gestita e utilizzata in modo efficiente. Mentre il livellamento automatico dell’archiviazione è un componente chiave dell’ottimizzazione del livello di archiviazione, possono anche essere coinvolti altri tecniche e best practice.
Livellamento vs memorizzazione nella cache
La stratificazione e il caching sono due tecniche distinte utilizzate nel data storage e nella gestione dei dati – servono a scopi diversi. I termini stratificazione e caching vengono spesso confusi e usati in modo intercambiabile, ma si riferiscono a due diverse tecniche di accelerazione della memorizzazione. Entrambe coinvolgono la collocazione dei dati accessibili frequentemente o caldi su supporti ad alta velocità come il flash. Tuttavia, le somiglianze finiscono principalmente qui.
Caching memorizza temporaneamente i dati su un supporto ad alte prestazioni come la DRAM o la memoria a stato solido per migliorare le prestazioni. Il cache si trova tra l’applicazione e il back-end storage. Lo stesso dato risiede anche su un livello di archiviazione inferiore, di solito un HDD. I dati vengono copiati nel cache, ma i dati originali rimangono nella loro posizione iniziale. Il caching è essenzialmente una transazione unidirezionale e il cache annulla i dati dopo l’uso.
Stratificazione della memorizzazione, al contrario, sposta fisicamente i dati tra dispositivi di memorizzazione. Quando i dati vengono identificati come caldi, questi dati vengono spostati in un livello ad alta velocità, rendendo il livello standard privo di una copia. Quando i dati si raffreddano, vengono spostati di nuovo al livello standard. La stratificazione della memorizzazione comporta lo spostamento dei dati invece di semplicemente copiarli, sia da memorizzazioni più lente a memorizzazioni più veloci e viceversa.
Sia la stratificazione della memorizzazione che il caching migliorano l’accessibilità dei dati, ma differiscono nel modo in cui utilizzano l’archiviazione per i dati accessibili frequentemente. Il caching crea copie, mentre la stratificazione della memorizzazione identifica i dati e li sposta senza creare copie aggiuntive.
Pertanto, il livellamento si concentra sull’ottimizzazione della collocazione dei dati a lungo termine attraverso diversi livelli di archiviazione per raggiungere un equilibrio tra prestazioni e costi, mentre il caching mira ad accelerare l’accesso ai dati memorizzando temporaneamente i dati accessi frequentemente in un buffer ad alta velocità. La scelta tra livellamento e caching dipende dai requisiti specifici dell’applicazione o del sistema di archiviazione e dalla natura dei modelli di accesso ai dati. In alcuni casi, le organizzazioni possono utilizzare entrambe le tecniche in combinazione per ottenere le migliori prestazioni complessive ed efficienza dei costi.
Archiviazione a più livelli e Gestione dell’archiviazione gerarchica
L’archiviazione a più livelli e la gestione dell’archiviazione gerarchica sono entrambe strategie utilizzate nella gestione dell’archiviazione dei dati, ma differiscono nella loro granularità, meccanismi di movimento dei dati e obiettivi principali. L’archiviazione a più livelli si concentra sulla categorizzazione dei dati in livelli discreti di supporti di archiviazione in base alle caratteristiche, mentre la gestione dell’archiviazione gerarchica si concentra sulla migrazione trasparente di file o oggetti individuali tra archiviazione primaria e secondaria per migliorare l’efficienza dell’archiviazione primaria e risparmiare costi.
Vantaggi dell’archiviazione a più livelli
L’archiviazione a più livelli offre diversi vantaggi significativi per le organizzazioni che cercano di ottimizzare la loro infrastruttura di archiviazione dei dati. I principali vantaggi dell’implementazione dell’archiviazione a più livelli sono:
- Miglioramento delle prestazioni. Collocando i dati accessi frequentemente o critici su livelli di archiviazione ad alte prestazioni, come dischi a stato solido o archiviazione NVMe, l’archiviazione a più livelli può migliorare in modo significativo le prestazioni del sistema. Ciò si traduce in una riduzione della latenza e tempi di accesso ai dati più rapidi per le applicazioni e gli utenti, portando a una maggiore produttività e soddisfazione degli utenti.
- Efficiente utilizzo delle risorse. Il livellamento dei livelli di archiviazione garantisce che ogni livello di archiviazione sia utilizzato in modo efficiente, evitando la sovrastima dei supporti di archiviazione ad alte prestazioni e l’utilizzo insufficiente di archiviazione a costo inferiore. Massimizza il ritorno sull’investimento (ROI) per l’infrastruttura di archiviazione.
- Ottimizzazione dei costi. Il livellamento dei livelli di archiviazione aiuta le organizzazioni a allocare risorse di archiviazione costose solo a dati che richiedono elevate prestazioni, mentre dati meno critici o acceduti raramente possono essere archiviati su livelli a costo inferiore, come dischi rigidi o archiviazione cloud. Questa ottimizzazione dei costi porta a potenziali risparmi sui costi hardware e operativi.
- Carichi di lavoro bilanciati. Il livellamento dei livelli di archiviazione può aiutare a distribuire i dati e i carichi di lavoro tra diversi livelli, riducendo la concorrenza per le risorse. Questo è particolarmente prezioso in ambienti con carichi di lavoro misti, dove alcune applicazioni richiedono elevate prestazioni mentre altre hanno requisiti di archiviazione meno impegnativi.
- Gestione dei dati adattiva. I modelli di accesso ai dati possono cambiare nel tempo. Le soluzioni di livellamento dei livelli di archiviazione analizzano continuamente questi modelli e spostano automaticamente i dati tra i livelli secondo necessità. Questa flessibilità garantisce che i dati rimangano sul livello di archiviazione più adatto, anche mentre i requisiti di accesso si evolvono.
- Scalabilità. Man mano che le esigenze di archiviazione dei dati aumentano, il livellamento dei livelli di archiviazione consente alle organizzazioni di scalare in modo efficiente la loro infrastruttura di archiviazione. Nuovi livelli di archiviazione possono essere aggiunti o i livelli esistenti espansi secondo necessità per soddisfare volumi di dati crescenti e richieste di prestazioni.
- Gestione dati semplificata. Le soluzioni di archiviazione gerarchica spesso includono politiche automatizzate e strumenti di gestione che semplificano le attività di gestione dei dati. Ciò riduce l’onere amministrativo associato alla collocazione e alla migrazione dei dati manuali.
- Conformità e conservazione. Le organizzazioni con requisiti normativi o di conformità traggono vantaggi dall’archiviazione gerarchica garantendo che i dati siano memorizzati e conservati in conformità con le direttive legali. I dati di conformità possono essere gestiti su livelli di archiviazione specifici con le necessarie politiche di sicurezza e conservazione.
- Protezione dei dati e disaster recovery. Classificando i dati in base alla loro importanza, l’archiviazione gerarchica aiuta le organizzazioni a dare la priorità agli sforzi di protezione dei dati. I dati critici possono essere memorizzati su livelli resilienti e ridondanti, garantendo la disponibilità e la recuperabilità dei dati in caso di guasti o disastri.
- Backup e ripristino ottimizzati. Segregando i dati in base alla loro importanza e ai modelli di accesso, l’archiviazione gerarchica può aiutare a dare la priorità ai dati per le operazioni di backup e ripristino. I dati critici possono essere sottoposti a backup con maggiore frequenza, mentre i dati meno critici possono essere sottoposti a intervalli di backup più lunghi.
Mentre lo scopo primario delle gerarchie di archiviazione è ottimizzare il posizionamento dei dati e i costi di archiviazione, i vantaggi che offrono possono anche migliorare la capacità dell’organizzazione di riprendersi da disastri. La ridondanza e la conservazione dei dati a costo contenuto aumentano le probabilità di recupero dei dati. Aiuta le organizzazioni a mantenere la continuità aziendale e a riprendersi da disastri con una perdita minima di dati e tempi di inattività, migliorando alla fine la loro prontezza generale al recupero da disastri.
Best Practices per la Gerarchia di Archiviazione
La gerarchia di archiviazione è una tecnica preziosa per ottimizzare l’archiviazione dei dati, ma è importante seguire le best practices per garantirne l’efficacia ed efficienza. Le best practices per la gerarchia di archiviazione sono le seguenti:
- Conoscere i propri dati. Effettuare un’analisi approfondita dei propri dati per comprendere le loro caratteristiche, i modelli di accesso e l’importanza. Non tutti i dati hanno bisogno di essere gerarchizzati, motivo per cui è necessario identificare quali insiemi di dati trarrebbero maggiore beneficio dall’archiviazione gerarchizzata.
- Selezionare il supporto di archiviazione giusto. Scegliere i supporti di archiviazione per ogni livello in base alle esigenze di prestazioni e al budget dell’organizzazione. Drive a stato solido, dischi rigidi, archiviazione cloud e biblioteche a nastro sono opzioni comuni.
- Monitorare e regolare regolarmente. Monitorare costantemente il proprio ambiente di archiviazione per tenere traccia dei modelli di accesso ai dati e dell’utilizzo dei livelli. Regolare le politiche di gerarchia secondo necessità per riflettere requisiti in evoluzione. La revisione e il raffinamento regolari delle proprie politiche sono essenziali per un’ottimale prestazione.
- Utilizzare la classificazione e l’etichettatura dei dati. Utilizzare metadati e etichettatura dei dati per classificare i dati. Questi metadati possono essere utilizzati dal tuo sistema di gerarchizzazione per prendere decisioni più informate sulla collocazione dei dati.
- Dare la priorità ai dati critici. Assicurarsi che i dati di missione e quelli accessibili frequentemente siano posizionati su livelli ad alte prestazioni. Ciò potrebbe richiedere politiche o livelli di priorità diversi per diversi tipi di dati.
- Includere ridondanza nei livelli critici. Se si memorizzano dati di missione su livelli ad alte prestazioni, considerare meccanismi di ridondanza come RAID (Redundant Array of Independent Disks) per proteggersi dalla perdita di dati a causa di guasti hardware.
- Implementare politiche di gerarchizzazione automatizzate. Definire chiare politiche automatizzate per spostare i dati tra i livelli. Queste politiche dovrebbero considerare fattori come frequenza di accesso, età dei dati e requisiti di prestazioni. L’automatizzazione della collocazione e del trasferimento dei dati aiuta a garantire che i dati siano sempre sul livello giusto.
- Fornire controlli di sicurezza e di accesso. Implementare le misure di sicurezza e i controlli di accesso appropriati per i dati su tutti i livelli. Assicurarsi che i dati sensibili siano protetti e accessibili solo agli utenti autorizzati.
- Backup e disaster recovery. Pianificare la protezione dei dati e il disaster recovery. Assicurarsi che le strategie di backup e recupero siano allineate con il tuo approccio di gerarchizzazione dei dati. I dati critici dovrebbero essere copiati con maggiore frequenza e conservati in modo sicuro.
- Scalabilità. Progettare la tua strategia di gerarchizzazione dei dati per essere scalabile. Man mano che le tue esigenze di archiviazione dei dati aumentano, essere pronti ad aggiungere più livelli o espandere quelli esistenti.
- Considera soluzioni ibride cloud. A seconda delle esigenze della tua organizzazione, considera l’integrazione di spazio di archiviazione cloud come uno dei tuoi livelli di archiviazione. Le soluzioni ibride cloud possono offrire scalabilità e flessibilità.
- Valuta regolarmente la tecnologia. Resta aggiornato sulle evoluzioni della tecnologia di archiviazione. Man mano che la tecnologia si evolve, nuovi supporti e soluzioni di archiviazione potrebbero diventare più convenienti e adatti ai tuoi livelli di archiviazione.
NAKIVO Backup & Replication e Backup Storage Tiering
NAKIVO Backup & Replication è una soluzione moderna di protezione dei dati e ripristino di emergenza che può funzionare con diversi livelli di archiviazione, consentendoti di ottimizzare le tue strategie di backup e ripristino in base alle loro esigenze specifiche e all’infrastruttura di archiviazione disponibile. La soluzione NAKIVO supporta vari tipi di archiviazione, tra cui archiviazione on-premise, archiviazione cloud e dispositivi di deduplicazione.
Puoi configurare NAKIVO Backup & Replication per utilizzare diversilivelli di archiviazione per i backup. Ad esempio, i backup critici possono essere memorizzati su archiviazione ad alto rendimento (Tier 1) per un recupero rapido, mentre i backup meno critici possono essere spostati su archiviazione a costo inferiore (Tier 2 o cloud) per la conservazione a lungo termine.
Il prodotto offre funzionalità come copia di backup e replica, che consentono la creazione di copie aggiuntive di backup su diversi livelli di archiviazione. Questo migliora la ridondanza dei dati e la preparazione al ripristino di emergenza posizionando i backup in più luoghi o livelli di archiviazione.
È possibile definire politiche di mantenimento all’interno di NAKIVO Backup & Replication per gestire automaticamente i dati di backup in base alla strategia di tiering. Ad esempio, i backup possono essere conservati su Tier 1 per un periodo più breve e poi trasferiti su Tier 2 per una conservazione a lungo termine.
La soluzione NAKIVO supporta provider di archiviazione cloud popolari. Ciò significa che è possibile integrare facilmente l’archiviazione cloud come livello di archiviazione per i backup offsite, riducendo la necessità di infrastrutture on-premises aggiuntive.
Conclusione
Le architetture di archiviazione a più livelli consentono alle organizzazioni di allocare risorse di archiviazione in base alle esigenze specifiche dei loro dati. Posizionando i dati sul livello più appropriato, le organizzazioni possono ottimizzare sia le prestazioni che il costo, garantendo che i dati critici ricevano le prestazioni necessarie mentre i dati meno critici o raramente accessibili vengono archiviati in modo conveniente. Le politiche di tiering dei dati automatizzate e gli strumenti di gestione aiutano a garantire che i dati vengano spostati tra i livelli man mano che i modelli di accesso e i requisiti cambiano nel tempo.