













Gli algoritmi di ottimizzazione hanno un ruolo cruciale nel deep learning: impostano le pesi del modello per minimizzare le funzioni di perdita durante l’addestramento. Tra questi algoritmi vi è ilottimizzatore Adam.
Adam è diventato estremamente popolare nel deep learning grazie alla sua capacità di combinare le vantaggi della momento e degli impostazioni di apprendimento adattive. Questo lo ha reso altamente efficiente per l’addestramento di reti neurali profonde. Anche questo richiede un minimo di adattamento delleiperparametri, rendendolo quindi accessibile e efficiente in varie attività.
Nel 2017, Ilya Loshchilov e Frank Hutter hanno introdotto una versione più avanzata del popolare algoritmo Adam nel loro paper “Decoupled Weight Decay Regularization.” Diy6>.“. L’hanno chiamato AdamW, che si distingue per la decoupling della perdita di peso dalla procedura di aggiornamento della gradiente. Questa separazione rappresenta un miglioramento fondamentale rispetto all’Adam e aiuta a migliorare la generalizzazione del modello.
AdamW è diventato sempre più importante nelle applicazioni moderne di deep learning, soprattutto nel gestire modelli a grandi scale. La sua capacità superiore di regolare gli aggiornamenti di peso ha contribuito alla sua adozione in compiti che richiedono alta performance e stabilità.
In questo tutorial, tratteremo le principali differenze tra Adam e AdamW, e i diversi casi d’uso, e implementeremo un guide passo-passo per l’implementazione di AdamW inPyTorch.
Adam contro AdamW
Adam e AdamW sono entrambi ottimizzatori adattivi ampiamente utilizzati nel deep learning. La grande differenza tra loro è come trattano la regolarizzazione del peso, che influenza la loro efficacia in diversi scenario.
Mentre Adam combina la momento e l’apprendimento adatto per offrire un’ottimizzazione efficiente, include la regolarizzazione L2 in un modo che può ostacolare il rendimento. AdamW risolve questo problema decoupando la decadenza del peso dalla modifica dell’apprendimento, fornendo un approcio più efficace per i grandi modelli e migliorando la generalizzazione. La decadenza del peso, una forma di regolarizzazione L2, penalizza i pesi grandi nel modello. Adam include la decadenza del peso nel processo di aggiornamento della gradienza, mentre AdamW la applica separatamente dopo l’aggiornamento della gradienza.
Ecco altri modi in cui differiscono:
Differenze chiave tra Adam e AdamW
Anche se entrambi gli ottimizzatori sono progettati per gestire il momento e adattare le velocità di apprendimento in modo dinamico, differiscono fondamentalmente nel trattamento della decadenza delle pesature.
In Adam, la decadenza delle pesature viene applicata indirettamente come parte dell’aggiornamento della gradiente, il che può modificare in modo imprevisto le dinamiche di apprendimento e influenzare il processo di ottimizzazione. Ad AdamW invece, la decadenza delle pesature viene separata dalla fase di gradiente, garantendo che la regolarizzazione abbia un impatto diretto sui parametri senza alterare il meccanismo di apprendimento adattivo.
Questo design porta a una regolarizzazione più precisa, aiutando i modelli a generalizzare meglio, specialmente in task che coinvolgono grandi e complessi dataset. Come risultato, gli ottimizzatori di solito hanno casi d’uso molto diversi.
Casi d’uso per Adam
Adam funziona meglio in task nei quali la regolarizzazione è meno critica o quando è prioritaria l’efficienza computazionale rispetto alla generalizzazione. Esempi includono:
- Reti neurali più piccole. Per compiti come la classificazione di base di immagini utilizzando piccole CNN (Convolutional Neural Networks) su dataset come MNIST o CIFAR-10, dove la complessità del modello è bassa, Adam può ottimizzare efficientemente senza richiedere una regolarizzazione estensiva.
- Problemi di regressione semplici. In compiti di regressione semplice con insiemi di feature limitati, come la predizione del prezzo delle case utilizzando un modello di regressione lineare, Adam può convergere rapidamente senza la necessità di tecniche avanzate di regolarizzazione.
- Prototipazione iniziale. Durante gli stadi iniziali del sviluppo del modello, dove è necessaria una rapida sperimentazione, Adam consente iterazioni veloci su architetture semplici, permettendo ai ricercatori di identificare eventuali problemi senza il overhead dell’impostazione dei parametri di regolarizzazione.
- Dati meno rumorosi. Quando si lavora con dataset puliti con un minimo di rumore, come i dati di testo ben curati per l’analisi delle emozioni, Adam può imparare pattern efficientemente senza il rischio di overfitting che potrebbe richiedere una maggiore regolarizzazione.
- Cicli di addestramento brevi. In scenari con limiti di tempo, come il rapido deployment del modello per applicazioni real-time, l’ottimizzazione efficiente di Adam può portare a risultati soddisfacenti in breve tempo, anche se potrebbero non essere completamente ottimizzati per la generalizzazione.
Casi d’uso per AdamW
AdamW eccelle in scenario dove il sovraimpiego è un problema e la dimensione del modello è significativa. Per esempio:
- Transformers a grande scala. Nelle attività di processamento del linguaggio naturale, come la raffinatura dei modelli come GPT su ampi corpus di testo, la capacità di AdamW di gestire la decadenza delle pesi in modo efficace impedisce il sovraimpiego, garantendo una migliore generalizzazione.
- Modelli complessi di computer visione. Per compiti che coinvolgono reti neurali convoluzionali (CNN) profonde addestrate su grandi set di dati come ImageNet, AdamW aiuta a mantenere la stabilità e la performance del modello decouplendo la decadenza delle pesi, che è cruciale per raggiungere una alta accuratezza.
- Apprendimento multitask. Nei scenari in cui un modello è addestrato contemporaneamente su più compiti, AdamW offre la flessibilità necessaria per gestire diversi dataset e per prevenire l’overfitting in qualsiasi singolo compito.
- Modelli generativi. Per l’addestramento di reti ad antagonismo generativo (GANs), nel quale mantenere un equilibrio tra il generatore e il discriminatore è critico, l’ottimizzazione regolare migliorata di AdamW può aiutare a stabilizzare l’addestramento e a migliorare la qualità delle uscite generate.
- Apprendimento per rinforzo. Nelle applicazioni di apprendimento per rinforzo in cui i modelli devono adattarsi a ambienti complessi e imparare politiche robuste, AdamW aiuta a mitigare l’overfitting the stati o azioni specifici, migliorando il rendimento generale del modello in situazioni varie.
Vantaggi di AdamW su Adam
Ma perché qualcuno potrebbe preferire AdamW a Adam? E’ semplice. AdamW offre numerosi benefici chiave che migliorano il suo comportamento, specialmente in scenari di modellazione complessi.
Si rivolge a alcune limitazioni riscontrate nell’ottimizzatore Adam, rendendolo quindi più efficace nell’ottimizzazione e contribuendo all’improved training model e alla robustezza.
Ecco altri degli svantaggi più importanti:
- Decoupled weight decay.Separando la decadenza del peso dagli aggiornamenti della gradiente, AdamW consente un controllo più preciso sulla regolarizzazione, portando a una migliore generalizzazione del modello.
- Migliorata generalizzazione. AdamW riduce il rischio di overfitting, specialmente in modelli a grandi scale, rendendolo adatto per compiti che coinvolgono dataset ampi e architetture complesse.
- Stabilità durante l’addestramento. Il design di AdamW aiuta a mantenere la stabilità lungo tutto il processo di addestramento, essenziale per modelli che richiedono un attento aggiustamento dei loro hyperparameters.
- Scalabilità.AdamW è particolarmente efficace per scalare i modelli, in quanto può gestire l’aumentata complessità delle reti profonde senza sacrificare le prestazioni, permettendogli di essere applicato in architetture all’avanguardia.
Come funziona AdamW
La forza principale di AdamW è nell’approcio alla decadenza delle pesate, che è scollegata dagli aggiornamenti graduati adattivi tipici di Adam. Questo adattamento garantisce che la regolarizzazione sia applicata direttamente ai pesi del modello, migliorando la generalizzazione senza influenzare negativamente le dinamiche della velocità di apprendimento.
L’ottimizzatore si basa sulla natura adattativa di Adam, mantenendo i benefici della momento e dell’adattamento del tasso di apprendimento per ogni parametro. L’applicazione indipendente della decadenza del peso risolve uno dei principali limiti di Adam: la sua tendenza a influenzare le aggiornamenti di gradiente durante la regolarizzazione. Questa separazione consente a AdamW di mantenere un apprendimento stabile, anche in modelli complessi e a grande scala, tenendo sotto controllo l’overfitting.
Nelle sezioni seguenti, esploriamo la teoria dietro la decadenza del peso e la regolarizzazione e la matematica che sostiene il processo di ottimizzazione di AdamW.
Teoria dietro la decadenza del peso e la regolarizzazione L2
La regolarizzazione L2 è una tecnica usata per prevenire l’overfitting. raggiunge questo obiettivo aggiungendo una penalità al termine di perdita, scoraggiando valori di peso troppo grandi. Questa tecnica aiuta a creare modelli più semplici che generalizzano meglio ai nuovi dati.
Nell’ottimizzazione tradizionale, come ad esempio in Adam, la decadenza del peso viene applicata come parte dell’aggiornamento delle gradienti, il che inavvertitamente influisce sulle learning rate e può condurre a prestazioni non ottimali.
AdamW migliora questo approcio decouplando la decadenza del peso dalla computazione delle gradienti. In altre parole, invece di applicare la decadenza del peso durante l’aggiornamento delle gradienti, AdamW la tratta come un passaggio separato, applicandola direttamente ai pesi dopo l’aggiornamento delle gradienti. Questo impedisce alla decadenza del peso di interferire con il processo di ottimizzazione, portando a un training più stabile e migliore generalizzazione.
Fondamenti matematici di AdamW
AdamW modifica l’ottimizzatore Adam tradizionale cambiando il modo in cui viene applicata la decadenza del peso. Le equazioni fondamentali per AdamW possono essere rappresentate come segue:
- Momentum e tasso di apprendimento adattivo:Come Adam, AdamW utilizza momentum e tassi di apprendimento adattivi per calcolare gli aggiornamenti dei parametri in base alle medie mobile delle gradienti e dei gradienti quadrati.
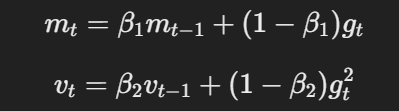
L’equazione per momentum e tasso di apprendimento adattivo
- Stime correttive dello schema:Le stime del primo e secondo momento sono correttamente elaborate per bias utilizzando i seguenti:
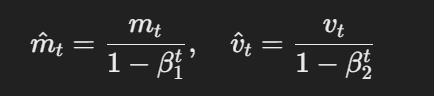
La formula per le stime correttive dello schema
- Aggiornamento del parametro con la decostruttura del decadimento della massa: In AdamW, il decadimento della massa è applicato direttamente ai parametri dopo l’aggiornamento della gradiente. La regola di aggiornamento è:
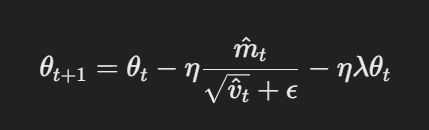
Aggiornamento del parametro con il decadimento della massa decostrutturato
Qui, η è la velocità di apprendimento, λ è il fattore di decadimento della massa, e θt rappresenta i parametri. Questo termine di decadimento della massa decostrutturato λθt assicura che la regolarizzazione sia applicata indipendentemente dalla gradienza update, che è la differenza chiave rispetto a Adam.
Implementazione di AdamW in PyTorch
L’implementazione di AdamW in PyTorch è semplice; questa sezione fornisce una guida completa per impostarlo. Seguire questi passaggi per imparare come efficacemente aggiustare i modelli con l’ottimizzatore Adam.
Un guide passo passo ad AdamW in PyTorch
Nota: questo tutorial presuppone che PyTorch sia già installato. Consultare la Documentazione per qualsiasi necessità di orientamento.
Step 1: Importare le librerie necessarie
import torch import torch.nn as nn import torch.optim as optim Import torch.nn.functional as F
Passo 2:Definire il modello
class SimpleCNN(nn.Module): def __init__(self): super(SimpleCNN, self).__init__() self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1) self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0) self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1) self.fc1 = nn.Linear(64 * 8 * 8, 128) self.fc2 = nn.Linear(128, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 64 * 8 * 8) x = F.relu(self.fc1(x)) x = self.fc2(x)
Passo 3:Impostare i hyperparameters
learning_rate = 1e-4 weight_decay = 1e-2 num_epochs = 10 # numero di epoch
Passo 4:Inizializzare l’ottimizzatore AdamW e impostare la funzione di perdita
optimizer = optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=weight_decay) criterion = nn.CrossEntropyLoss()
Ecco qui!
Ora sei pronto a iniziare l’addestramento del tuo modello CNN, e questo è ciò che faremo nella prossima sezione.
Esempio pratico: Raffinamento di un modello utilizzando AdamW
Sopra, abbiamo definito il modello, impostato gli hyperparametri, inizializzato l’ottimizzatore (AdamW), e configurato la funzione di perdita.
Per addestrare il modello, dovremo importare altri moduli;
from torch.utils.data import DataLoader # fornisce un iterabile del dataset import torchvision import torchvision.transforms as transforms
Successivamente, definiamo il dataset e i dataloader. Per questo esempio, userai il dataset CIFAR-10:
# Definisci trasformazioni per il set di addestramento transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), ]) # Carica il dataset CIFAR-10 train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) val_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform) # Crea loader dati train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)
Dato che abbiamo già definito il nostro modello, il prossimo passo è implementare il ciclo di addestramento per ottimizzare il modello usando AdamW.
Ecco come si presenta:
for epoch in range(num_epochs): model.train() # impostare il modello in modalità addestramento running_loss = 0.0 for inputs, labels in train_loader: optimizer.zero_grad() #svuotare i gradienti outputs = model(inputs) # passo in avanti loss = criterion(outputs, labels) # calcolare la perdita loss.backward() # passo indietro optimizer.step() # aggiornare i pesi running_loss += loss.item() print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader):.4f}')
L’ultimo passo è validare le prestazioni del modello sul dataset di validazione creato in precedenza.
Ecco il codice:
model.eval() # Imposta il modello in modalità di valutazione correct = 0 total = 0 with torch.no_grad(): for inputs, labels in val_loader: outputs = model(inputs) # Passo in avanti _, predicted = torch.max(outputs.data, 1) # Ottieni la classe predetta total += labels.size(0) # Aggiorna i campioni totali correct += (predicted == labels).sum().item() # Aggiorna le corrette predizioni accuracy = 100 * correct / total print(f'Validation Accuracy: {accuracy:.2f}%')
Ed ecco qui il risultato.
Ora sai come implementare AdamW in PyTorch.
Casi d’uso comuni per AdamW
Ok, così abbiamo stabilito che AdamW è diventato popolare grazie alla sua gestione più efficiente del decadimento del peso rispetto all’predecessore, Adam.
Ma quali sono alcuni casi d’uso comuni per questo ottimizzatore?
Trattiamo questo argomento nella sezione successiva…
Modelli di apprendimento profondo a scala ridotta
AdamW è particolarmente benefico nella formazione di modelli grandi come BERT, GPT e altre architetture di trasformazione. Questi modelli hanno di solito milioni o persino miliardi di parametri, il che spesso significa che richiedono algoritmi di ottimizzazione efficienti in grado di gestire aggiornamenti complessi dei pesi e sfide generalizzative.
Compiti di computer vision e NLP
AdamW è diventato l’ottimizzatore di scelta nei compiti di computer vision che coinvolgono CNN e nei compiti di NLP che coinvolgono trasformazioni. La sua capacità di prevenire l’overfitting lo rende ideale per compiti che coinvolgono grandi dataset e architetture complesse. La scelta indipendente del decadimento del peso significa che AdamW evita i problemi riscontrati da Adam nella sovra-regolazione dei modelli.
Ripulimento degli hyperparameter in AdamW
Il tuning degli hyperparametri è il processo di selezione delle migliori valori per i parametri che governano l’addestramento di un modello di apprendimento automatico ma non vengono imparati direttamente dai dati stessi. questi parametri influiscono direttamente sulla modalità con cui il modello ottimizza e converge.
Il corretto tuning di questi hyperparametri in AdamW è essenziale per ottenere un addestramento efficiente, evitare l’overfitting e garantire che il modello generalizzi bene su dati non visti.
In questa sezione, esploriamo come fine-tunere gli hyperparametri chiave di AdamW per ottenere un ottimo rendimento.
Pratiche migliori per la scelta delle velocità di apprendimento e della decadenza delle pesature
La velocità di apprendimento è un hyperparametro che controlla quanto aggiustare i pesi del modello rispetto alla gradiente di perdita durante ogni passo di addestramento. Una velocità di apprendimento elevata accelera l’addestramento ma può farti superare i pesi ottimali, mentre una bassa consente aggiustamenti più sottili ma può rallentare l’addestramento o bloccarsi in minimi locali.
Al contrario, la decadenza della massa è una tecnica di regularizzazione usata per prevenire l’overfitting penalizzando i pesi grandi del modello. Cioè, la decadenza della massa aggiunge una piccola penalità proporzionale alle dimensioni dei pesi del modello durante l’addestramento, aiutando a ridurre la complessità del modello e migliorare la generalizzazione su nuovi dati.
Per scegliere le quote d’apprendimento ottimali e i valori di decadenza della massa per AdamW:
- Inizia con una velocità d’apprendimento moderata – Per AdamW, una velocità d’apprendimento di circa 1e-3 spesso costituisce un buon punto di partenza. Puoi regolarla in base a come il modello converga, abbassandola se il modello ha problemi a convergere o aumentandola se l’addestramento è troppo lento.
- Esperimenta con la decadenza del peso. Inizia con un valore intorno a 1e-2 fino a 1e-4, a seconda della dimensione del modello e del dataset. Una decadenza del peso leggermente più alta può aiutare a prevenire l’overfitting per modelli più grandi e complessi, mentre i modelli più piccoli potrebbero richiedere meno regolarizzazione.
- Usa la pianificazione dell’impostazione dell’apprendimento.Implementa pianificazioni dell’impostazione dell’apprendimento (come decadenza per passo o annullamento coseno) per ridurre dinamicamente l’impostazione dell’apprendimento mentre l’addestramento prosegue, aiutando il modello a finire le sue prestazioni parametri mentre si avvicina alla convergenza.
- Monitora le prestazioni. Traccia continuamente le prestazioni del modello sul set di validazione. Se osservi overfitting, considera l’aumento della decadenza del peso, o se la perdita di training si stabilizza, abbassa l’impostazione dell’apprendimento per una migliore ottimizzazione.
Pensieri finali
AdamW è diventato uno degli ottimizzatori più efficaci in apprendimento profondo, soprattutto per modelli a grandi scale. Questo è dovuto alla sua capacità di scollegare la decadenza delle pesature dallaaggiornamento delle gradienti. In parole povere, il design di AdamW migliora la regolarizzazione e aiuta i modelli a generalizzare meglio, soprattutto quando si trattano di architetture complesse e di dataset estesi.
Come dimostrato in questo tutorial, l’implementazione di AdamW in PyTorch è semplice – richiede solo alcune correzioni da Adam. tuttavia, la sintonizzazione dei parametri hyperparameter rimane un passo fondamentale per massimizzare l’efficacia di AdamW. Trovare il giusto equilibrio tra la velocità di apprendimento e la decadenza delle pesature è essenziale per assicurare che l’ottimizzatore funzioni efficientemente senza overfitting o underfitting del modello.
Ora sai abbastanza per implementare AdamW nei tuoi stessi modelli. Per continuare l’apprendimento, controlla alcune di queste risorse:
Source:
https://www.datacamp.com/tutorial/adamw-optimizer-in-pytorch