













אלגוריתמים לאופטימיזציה משחקים תפקיד מפתחים בלמידה עמוקה: הם מותקנים את המשקלים של המודל על מנת למזער את הפונקציות האקדמיות בזמן האימון. אחד מהאלגוריתמים האלה הוא ה אופטימיזר הAdam.
Adam הפך לפופולרי ביותר בלמידה עמוקה בגלל היכולתו לשלב את היתרונות של מומנטום ושיעורים הגיוניים. זה עשה אותו מאוד יעיל לאימון רשתות עמוקות ניורנליות. הוא גם דורש מינימום הגהה של היפרפארמטרים, כך שהוא נגיש ויעיל לרוב המשימות.
ב-2017, איליה לושצ'ילוב ופרנק חאטר הציגו גירסה מתקדמת יותר של אלגוריתמת Adam הפופולרית במאמר שלהם "Decoupled Weight Decay Regularization." הם קראו לה אדם-וי, שמייצג הפרדה של הדיברדיאל מהתהליך העדכון של הגראדיאל. הפרדה הזו היא שיפור קריטי מאדם ועוזר לנו לקבל הגיון טוב יותר למודל.
אדם-ווי (AdamW) הפך לחשוב יותר ויותר ביישומים העולמים בלמידה עמוקה, בעיקר בהדבקת מודלים בקנה מידה גדול. היכולת הטובה שלו לרגול את עדכוני המשקל התרמצתה באמצעותה וסייעה להאמצעותו במשימות שדורשות ביצועים גבוהים ויציבות.
במדריך הבית הזה, אנחנו נגע בהבדלים העיקריים בין אדם לאדם-ווי, ובין השימושים השונים, וניתן להדריך שלם להגדרת אדם-ווי בPyTorch.
אדם מול אדם-ווי
אדם ואדםW הם שני מתקדמים הדמייתיים שמשמשים רחבה בלמידת עמוקה. ההבדל הגדול בינם הוא באופן בו הם מטפלים בהגנת משקל, שהוא משפיע על יעילותם בסיטואציות שונות.
בעוד Adam משלב מומנטום וקצבים הסתגלים במטרה לספק אקופטימיזציה יעילה, הוא מעלה לתוך הערך את הגדלת המשקל ה-L2 בדרך שיכולה להתמודד עם ביצועים. AdamW מתייחסת לזה על-ידי הפרדה של הדחיסות המשקלית מערכת העדכון הלמידה, מעניקה גישה יעילה יותר עבור מודלים גדולים ושיפור ה普נטציה. הדחיסות המשקלית, סוג של הגנת המשקל L2, מעלה עליה במשקלים גדולים במודל. Adam משלב את הדחיסות המשקלית לתהליך עדכון הגראדיאודים, בעוד AdamW ייחודשה אותה באופן נפרד אחרי תהליך עדכון הגראדיאודים.
פה כמה דרכים אחרות בהן הם שונים:
ההבדלים המפתחים בין Adam ו-AdamW
למרוצים השניים נעצמם לניהול מומנטום ולהגיע לשינוי קצבי הלמידה באופן דינמי, הם שונים באופן בסיסי בטיפולם בגלל המידע העליון.
באדם, הדחיפות ניתן באופן לא ישיר כחלק מעידוד השורשים, שעלול לשינוי בלתי מכוון את הדינמיקות הלמידה ולהתערב בתהליך האופטימיזציה. אך ב-AdamW, הדחיפות מופרדת מהצעד של השורשים, ומובטחת שהרגולרציה משפיעה ישירות על הפרמטרים בלי לשנות את מנגנון הלמידה האדפטיבית.
עיצוב זה מוביל לרגולרציה יותר מדויקת, שעוזרת למודלים להגיע להתקבלה טובה יותר, בעיקר במשימות שעלולות להכיל מידע גדול ומורכב.
המשימות המועדכנות ל-Adam כוללות משימות בהן הרגולרציה פחות חשובה או בהן מקדםת יעילות המערכת מוכרחת על פני ההגיון. דוגמאות כוללות:
- רשתות עצבים קטנות. למשימות כמו סיווג תמונות בסיסי באמצעות CNNs קטנים (רשתות עצבים קונבולוציוניות) על קבוצות נתונים כמו MNIST או CIFAR-10, שבהן המודל מורכבות נמוכה, Adam יכול לבצע אופטימיזציה ביעילות בלי צורך ברגולריזציה מתוחכמת.
- בעיות רגרסיה פשוטות. במשימות רגרסיה ישרות עם סטי תכונות מוגבל, כמו חיזוי מחירי בתים באמצעות מודל רגרסיה ליניארי, Adam יכול להתכנס במהירות בלי צורך בטכניקות רגולריזציה מתקדמות.
- שלבי התכנות המוקדמים. בשלבי התכנות הראשוניים של פיתוח המודל, שבהם נדרשת ניסוי מהיר, Adam מאפשר תהליכי איטרציה מהירים על ארכיטקטורות פשוטות, מאפשר לחוקרים לזהות בעיות אפשריות בלי העומס של התאמת פרמטרים של רגולריזציה.
- נתונים פחות רועשים. בעבודה עם קבוצות נתונים נקיים עם רעש מינימלי, כמו נתוני טקסט מסודרים היטב לניתוח רגשות, Adam יכול ללמוד תבניות ביעילות מבלי להיסתכן בכך שיהיה צורך ברגולריזציה כבדה.
- מחזורי הדרכה הקצרים. בתרחישים עם הגבלות זמן, כמו הפצת מודלים מהירה ליישומים בזמן אמת, האופטימיזציה היעילה של Adam יכולה לעזור לספק תוצאות מספקות במהירות, גם אם הן לא מותאמות באופן מלא לכלליות.
שימושים ל-AdamW
אדם-W מביך בסיטואציות בהן מוכרחת הדאגה לעוברת יתר, והגודל של המודל הוא משמעותי. לדוגמה:
- מערכות שינוי גדולות. במשימות עיבוד שפה טבעית, כמו אתחזור של מודלים כמו GPT על מערכות טקסט רחבות, היכולת של AdamW לנהל את ההתמדדות האקספונציונלית בצורה יעילה מנעה עוברת יתר, ובדאגה להגיון טוב יותר.
- מודלים מורכבים של מבט מחשב. למשימות שמערכת מערכות קונוולציונלים עמוקים (CNNs) שמאמנים על מערכות נתונים גדולות כמו ImageNet, AdamW עוזר לשמר את היציבות והביצועים של המודל על-ידי הפרדוקס של ההתמדדות האקספונציונלית, שהוא חשוב להשיג דיוק גבוה.
- למידה מרובת משימות. בתרחישים שבהם מודל מאומן על משימות מרובות בו זמנית, AdamW מספק גמישות להתמודד עם מערכות נתונים שונות ולמנוע התאמה יתרה על כל משימה בודדת.
- מודלים גנרטיביים. לאימון רשתות גנרטיביות נגדיות (GANs), שבהן שמירה על איזון בין הגנרטור למבחן היא קריטית, רגולציה משופרת של AdamW יכולה לעזור לייצב את האימון ולשפר את איכות הפלטים המיוצרים.
- למידת חיזוק. באפליקציות של למידת חיזוק שבהן מודלים צריכים להסתגל לסביבות מורכבות וללמוד מדיניות עמידה, AdamW מסייע להקטין התאמה יתרה למצב או לפעולה ספציפיים, משפר את הביצועים הכלליים של המודל במצבים מגוונים.
יתרונות של AdamW על פני Adam
אבל למה שמישהו ירצה להשתמש ב-AdamW על פני Adam? פשוט. AdamW מציע מספר יתרונות מרכזיים שמחמיאים את הביצועים שלו, במיוחד בתרחישי ד modeling מורכבים.
הוא מתייחס לחלק מהמגבלות שנמצאות באופטימIZר אדם, ולכן הוא יותר אפקטיבי בעיצוב ומתרחב לאיכות האימון המושפעת ולעמידות המודל.
הנה כמה מהיתרונות המוצגים:
- דילוגדינג של דיכלון משקל. על-ידי הפרדה של הדיכלון משקל מערכי העדכונים הגרעיניים, אדםW מאפשר שליטה יותר מדויקת ברגולריזציה, וזה מוביל לתוך הגיון טוב יותר של המודל.
- הגיון משופע. אדםW מפחית את סיכון העבירה הרחבה, בעיקר במודלים בקנה מידה גדול, וזה מתאים למשימות שעוסקות במידע רחב ובמבנים מורכבים.
- יציבות במהלך האימון. עיצוב AdamW עוזר לשמור על יציבות במהלך תהליך האימון, שהיא חיונית עבור מודלים שדורשים תיקון קפיצי של הפרמטרים היפר.
- סקאלביליות. AdamW יעיל במיוחד לסקאלת מודלים, מאחר והוא יכול להתמודד עם הרכבה מורכבת של רשתות עמוקות מבלי לפגוע בביצועים, מאפשרת להשתמש בו עם ארכיטקטורות ברמה הגבוהה ביותר.
כיצד עובד AdamW
הכוח המרכזי של AdamW נמצא בגישתו לקריסת משקל, שמופרדת מעדכוני הגרדיאנט המותאמים שטמון בפנים של Adam. התאמה זו מבטיחה שהרגולריזציה מתייחסת ישירות למשקלים של המודל, משפרת את הכלליות בלי לפגוע בדינמיקת הקצב למידה.
האופטימיzer בונה על האדם הגיוני המתאים, שמשמרת על היתרונות של הרגל וההגדרות הלמודיות הפרמטריות. יישום הדחיפה העצמאית מתייחסת לאחד מהחסרונות המפתחים של האדם: הנטיה שלו להשפיע על העדרגודים בזמן הרגולרציה. ההפרדה זו מאפשרת ל-AdamW לשמור על למידה יציבה, אפילו במודלים מורכבים ובקנה מידה גדול, בעוד שהיא משמרת על ההתגבשות.
בחלקים הבאים, אנחנו נבדוק את התיאוריה מאחורי הדחיפה והרגולרציה והמתמטיקה שמבססת את תהליך האופטימציה של AdamW.
תיאוריית הדחיפה והרגולרציה L2
רגולרציית L2 היא טכניקה שמשתמשת כדי למנוע התגבשות. היא משגיחה על המטרה הזו על ידי הוספת משמעות פנלית לפונקציית האבדן, שמדחידה על ערכים משקל גדולים. הטכניקה זו עוזרת ליצור מודלים פשוטים יותר שמתקבלים טוב יותר על נתונים חדשים.
במערכות האופטימיזצרים המסורתיות, כמו אדם, קידוד משקל ניתן בתור חלק מערכת העדכון המשקלי, שזה באופן בלתי מוכר ישפע את שיעורי הלמידה ויכול להוביל לביצועים לא מושלמים.
AdamW משפר את זה על ידי הפרדות את קידוד משקל מתהליך חישוב העדכון המשקלי. במילים אחרות, במקום ליישם קידוד משקל בזמן עדכון המשקלי, AdamW מטיל עליו מבט חדש, יישמו אותו ישר אחרי העדכון המשקלי. זה מנע מקידוד משקל מלהתערבב בתהליך האופטימיזציה, מגביר את האיומים על האימונים ומספק את הכיוונים הטובים יותר.
יסודות מתמטיים של AdamW
AdamW משנה את מערכת האופטימיזצר Adam המסורתית על-ידי שינוי איך קידוד משקל ניתן. המשוואות היסודיות לAdamW יכולות להיות מיוצגות באופן הבא:
- מוניטין וקצב לימוד הגיוני:ממש כמו Adam, AdamW משתמש במוניטין וקצבי לימוד הגיוניים כדי לחשב את העדכונים הגלומיים של הגראדים והגראדים המסוגלים בהתבסס על הממוצעים המתנועים שלהם.
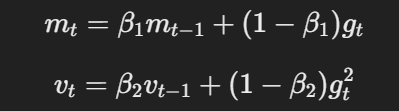
המשוואה למוניטין וקצב הלימוד ההגיוני
- הערכים מתוקנים במוניטין:הערכים הראשון והשני של המוניטין מתוקנים במוניטין באמצעות הבאה:
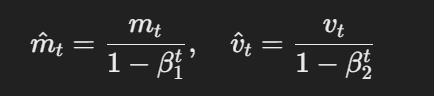
המשוואה לערכים מתוקנים במוניטין
- עדכון משתנה עם התדירות נפרדת: ב AdamW, התדירות ניתנת ישירות למשתנים אחרי עדכון הגראדיאלד. החוק העדכוני הוא:
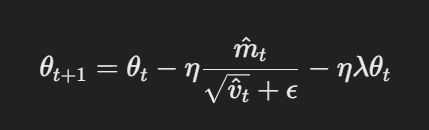
עדכון משתנה עם התדירות נפרדת
כאן, η הוא קצב הלמידה, λ הוא מפתח ההתדירות, ו θt מייצג את המשתנים. המשתנה הנפרדת הזו של λθt ודאי שישומעת ברגילוג המיוחדת בניגוד ל Adam.
ביצוע של AdamW ב PyTorch
אמצעיית העדכון האקספוננציאלי של אדם-וייס בפייטורץ 'היא פשוטה; החלק הזה מספק מדריך מוחשי של הגדרה שלו. עבדו את השלבים הבאים כדי ללמוד איך למתקנים מודלים באופן יעיל בעזרת מתקן האדם.
מדריך צעד אחר צעד לאמצעיית אדם-וייס בפייטורץ '.
הערה: הדרכה הזו מנבאת שיש לך 已经安装了 PyTorch. הגיש ל 文档 עבור כל אודות הוראות.
שלב 1: ייבא את הספריות הנחוצות
import torch import torch.nn as nn import torch.optim as optim Import torch.nn.functional as F
שלב 2:הגדרת המודל
class SimpleCNN(nn.Module): def __init__(self): super(SimpleCNN, self).__init__() self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1) self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0) self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1) self.fc1 = nn.Linear(64 * 8 * 8, 128) self.fc2 = nn.Linear(128, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 64 * 8 * 8) x = F.relu(self.fc1(x)) x = self.fc2(x)
שלב 3:הגדרת ההיפרפארמטרים
learning_rate = 1e-4 weight_decay = 1e-2 num_epochs = 10 # מספר המחזורים
שלב 4:התחלת אופטימיzer AdamW והגדרת הפונקציה האובדנית
optimizer = optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=weight_decay) criterion = nn.CrossEntropyLoss()
ווילה!
עכשיו, אתה מוכן להתחיל באימון המודל שלך של CNN, וזה מה שאנחנו נעשה בחלק הבא.
דוגמה מעשית: מעדכן מודל בעזרת AdamW
למעלה, הגדרנו את המודל, הגדרנו את ההיפרפרמטרים, הואילצטרמנו את האופטימיzer (AdamW), והגדרנו את הפונקציית הפסד.
כדי לאמן את המודל, אנחנו נזדקק להיותר מודלים;
from torch.utils.data import DataLoader # מספק איטרבל של המידע המקורי import torchvision import torchvision.transforms as transforms
בהמשך, הגדרו את המידע והמעבדים המידעיים. עבור הדוגמה הזו, אנחנו נהשתמש במידע ה CIFAR-10:
# הגדרות לשינויים עבור אובייקטים האימון transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), ]) # טעינת מערכת CIFAR-10 train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) val_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform) # יצירת משאבי טעינה train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)
מפני שכבר הגדרנו את המודל שלנו, השלב הבא הוא ליישם מעגל האימון כדי לאופטימיze את המודל בעזרת AdamW.
כך הוא נראה:
for epoch in range(num_epochs): model.train() # הגדרת מצב המודל למודל האימון running_loss = 0.0 for inputs, labels in train_loader: optimizer.zero_grad() # ניקוף הגדלים outputs = model(inputs) # עבר הדרך קדמי loss = criterion(outputs, labels) # חישוב הפסד loss.backward() # עבר הדרך אחורני optimizer.step() # עדכון המשקלים running_loss += loss.item() print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader):.4f}')
השלב האחרון הוא לבחינת ביצועי המודל על המערכת הבדיקה שיצרנו קודם.
כאן יש הקוד:
model.eval() # מצב המודל למצב בדיקה correct = 0 total = 0 with torch.no_grad(): for inputs, labels in val_loader: outputs = model(inputs) # עברת הגלאי _, predicted = torch.max(outputs.data, 1) # קבלת המחלה הצפויה total += labels.size(0) # עדכון הדגימות הכלליות correct += (predicted == labels).sum().item() # עדכון ההצלאות הנכונות accuracy = 100 * correct / total print(f'Validation Accuracy: {accuracy:.2f}%')
והנה זה.
עכשיו אתה יודע איך ליישם AdamW ב PyTorch.
השימושים הנפוצים ל AdamW
אוקיי, אז אנחנו מוכרחים ש AdamW הרגיש פופולרי בשל הניהול היעיל יותר של הדחיפה מאשר הקודמת שלו, Adam.
אבל מהן כמה מהשימושים הנפוצים לאופטימיzer הזה?
אנחנו נעבור לזה בחלק זה…
מודלים מוניטיניים בלמידה עמוקה
AdamW מועיל במיוחד באימון של מודלים גדולים כמו BERT, GPT וארכיטקטורות אחרות של מעבדים. הם בדרך כלל מקבלים מיליונים או אפילו מיליארדים של פרמטרים, מה שלעולם אומר שהם דורשים אלגוריתמים יעילים שמסייעים בעיקרון עידכנים מורכבים ובאתגרים הגלומליים האלה.
משימות מבט מחשבי ומשימות תמידה טקסטיות
AdamW הפך למערכת האופטימיזציה המועדפת עליה במשימות מבט מחשבי שמערכת עליה CNNs ובמשימות תמידה טקסטיות שעליה על מעבדים. היכולת שלו למנוע עיוות מעין הופך אותו לאישי למשימות שעליה על מאגרי נתונים גדולים וארכיטקטורות מורכבות. ההפרדות של הדחק משמע שAdamW ממנע את הבעיות שקיימות בעזרת Adam לעיוות מדי את המודלים.
התאמת היפרפרמטרים בAdamW
התסמינים העליונים הם תהליך בו מוצעים את הערכים הטובים ביותר עבור הפרמטרים האלה ששולטים בהתאמה של מודל ל leaning אבל אינם למדודים מהנתונים עצמם. הפרמטרים האלה משפיעים ישירות על איך המודל מעודד ומתרחב.
ההתסמין הנכון של אחד מהפרמטרים האלה בAdamW הוא חיוני עבור הוספת האינטגרציה היעילה, הדמיית העודף והוספת הביטחון שהמודל יתקבל על ידי הגיון טוטלי על נתונים שלא נתקלו בהם.
בחלק זה, נבדוק איך להתאים בצורה מיטבית את הפרמטרים העליונים המפתחים של AdamW.
מידע טוב לבחירת שיעורי למידה והתדרדרות משקל
שיעורי למידה הם הפרמטר העליון השולט על כמה להגדיל את המשקלים המודליים בהתבסס על השוק הדלתאטי בכל שלב האימון. שיעור למידה גבוה יעיל את האימון אך עשוי לגרום למודל לעבור את המשקלים המושלמים בצורה יתר, בעוד ששיעור נמוך מאפשר ערכים אינטימיים יותר אך יכול להאט את האימון או לגרום להיות נעול במינומים מקומיים.
דחיפה משקל, מצד שני, היא טכניקה לרגולציה שמשתמשת כדי למנוע התגבשות יתר על ידי דוחסון על משקלים גדולים במודל. במילים אחרות, דחיפה משקל מוסיפה את הפנליזה הקטנה הזו של המשקלים של המודל בזמן ההאימון, וזה עוזר לצמצם את המורכבות של המודל ולשפר את ההגיוניות הכללית לנתונים חדשים.
על מנת לבחור קצבי למידה וערכי דחיפה משקל אופטימליים עבור AdamW:
- התחל עם קצב למידה מדורש – עבור AdamW, קצב למידה בערך 1e-3 הוא לעיתים מקום מדורש טוב להתחלה. אתה יכול להגיע אליו על פי איך המודל מתקדם, לרדת אותו אם המודל נאבק להתקדם או להגביר אותו אם האימון הוא יותר מהדחיפה.
- ניסוי עם התדרדרות משקל. התחל עם ערך בערך 1e-2 עד 1e-4, בהתאם לגודל המודל ולמידע. התדרדרות משקל קצת גבוהה יכולה לסייע למניעת התגבשות עבור מודלים גדולים ומורכבים, בעוד מודלים קטנים יכולים להיות צריכים פחות רגולציה.
- השתמש בלוקחי שעות ללמוד. מימש לוקחי שעות ללמוד (כמו התדרדרות צעדים או שינוי קוסיני) כדי להפחית באופן דינמי את שיעור הלמידה במהלך ההתעמלות, ולסייע למודל להתארגן את הפרמטרים שלו בדרך להתקרבות להתאחדות.
- נטרו את הביצועים. נטרה בהמשך את ביצועי המודל על הקבוצת ההולמת. אם מוצגת התגבשות, קחי בחשבון להגבש יותר את המשקל החסר, או אם האבדן האימוני מתקבלת, פחות את שיעור הלמידה עבור התאומלות טובה יותר.
מחשבות סיום
אדם-W התפרסם כאחד מאופטימיזציות הכי יעילות בלמידה עמוקה, בעיקר עבור מודלים בקנה מידה גדול. זה בגלל היכולתו להפריד את ההתדרדרות מהעדכונים הגרעיניים. במילים אחרות, העיצוב של AdamW משפר את הרגולרציה ועוזר למודלים להפוך טוב יותר, בעיקר כשמתמודדים עם מבנים מורכבים ומידע נרחב.
כפי שהוכיח במדריך זה, היא קל ליישם AdamW ב PyTorch — זה דורש רק כמה התאמות מאדם. אף על פי כן, הגדלת הפרמטרים נשארת צעד חשוב להגברת היעילות של AdamW. למציאת המשוואה הנכונה בין קצב הלמידה וההתדרדרות היא חיונית עבור הוגברת היעילות של האופטימיזטר בלי להתרחק או להתפרץ מהמודל.
עכשיו אתה יודע מספיק כדי ליישם AdamW במודלים שלך. כדי להמשיך בלמידה שלך, בדוגמה למשאלות האלה:
Source:
https://www.datacamp.com/tutorial/adamw-optimizer-in-pytorch