













Le calcul sans serveur a émergé en réponse aux défis posés par les architectures traditionnelles basées sur des serveurs. Avec le calcul sans serveur, les développeurs n’ont plus besoin de gérer ou de scaler les serveurs manuellement. Au lieu de cela, les fournisseurs de cloud se chargent de la gestion de l’infrastructure, ce qui permet aux équipes de se concentrer exclusivement sur l’écriture et le déploiement du code.
Les solutions sans serveur scalent automatiquement en fonction de la demande et offrent un modèle de paiement à la consommation. Cela signifie que vous ne payez que pour les ressources que votre application utilise réellement. Cette approche réduit显著ement les frais opérationnels, augmente la flexibilité et accélère les cycles de développement, ce qui en fait une option attrayante pour le développement d’applications modernes.
En abstraignant la gestion des serveurs, les plateformes sans serveur vous permettent de concentrer sur la logique métier et les fonctionnalités de l’application. Cela conduit à des déploiements plus rapides et plus d’innovation. Les architectures sans serveur sont également basées sur les événements, ce qui signifie qu’elles peuvent réagir automatiquement à des événements en temps réel et scaler pour répondre aux besoins des utilisateurs sans intervention manuelle.
Table des matières
-
Étape 3 : développer les fonctions lambda pour les opérations CRUD
.
-
Étape 5 : Tester les pipelines de développement et de production
-
Étape 6 : Tester et valider les APIs de production et de développement à l’aide de Postman
Avant de plonger dans les détails techniques, nous passerons en revue certains concepts de base importants.
Concepts importants à comprendre
Interface de programmation d’applications (API)
Une interface de programmation d’applications (API) permet à différentes applications logicielles de communiquer et d’interagir ensemble. Elle définit les méthodes et les formats de données que les applications peuvent utiliser pour demander et échanger des informations pour l’intégration et le partage de données entre des systèmes divers.
Méthodes HTTP
Les méthodes HTTP ou méthodes de requête sont un composant critique des services Web et des API. Elles indiquent l’action souhaitée à exécuter sur une ressource dans l’URL de la requête donnée.
Les méthodes les plus couramment utilisées dans les API RESTful sont :
-
GET : utilisé pour récupérer des données à partir d’un serveur
-
POST : envoie des données, inclues dans le corps de la requête, pour créer ou mettre à jour une ressource
-
PUT : met à jour ou remplace une ressource existante ou crée une nouvelle ressource si elle n’existe pas
-
DELETE : supprime les données spécifiées du serveur.
Amazon API Gateway
Amazon API Gateway est un service entièrement géré qui permet aux développeurs de créer, publier, maintenir, surveiller et sécuriser des API à une échelle large. Il agit en tant qu’entrée pour plusieurs API, gérant et contrôlant les interactions entre les clients (tels que les applications web ou mobiles) et les services backend.
Il offre également diverses fonctions, telles que le routage des demandes, la sécurité, l’authentification, le cache et la limitation de débit, qui facilitent la gestion et la déploiement des API.
Amazon DynamoDB
DynamoDB est un service de base de données NoSQL entièrement géré conçu pour une haute scalabilité, une latence basse et la réplication des données sur plusieurs régions.
DynamoDB stocke les données dans un format sans schéma, permettant un stockage et un accès rapides flexibles et rapides pour des données structurées et semi-structurées. Il est couramment utilisé pour construire des applications scalables et réactives dans un environnement basé sur les nuages.
Application CRUD serverless
Une application CRUD serverless fait référence à la capacité de Créer, Lire, Mettre à jour et Supprimer des données. Cependant, l’architecture et les composants impliqués diffèrent de ceux des applications traditionnelles basées sur un serveur.
Créer implique l’ajout de nouvelles entrées dans une table DynamoDB. L’opération Lire récupère les données depuis une table DynamoDB. Mettre à jour met à jour les données existantes dans DynamoDB. Et l’opération Supprimer supprime les données de DynamoDB.
Le Framework Serverless.
Le Framework Serverless est une herramienta open source que simplifie le déploiement et la gestion des applications serverless sur plusieurs fournisseurs de cloud, y compris AWS. Il abstrait la complexité de la provisioning et de la gestion de l’infrastructure en permettant aux développeurs de définir leur infrastructure en tant que code à l’aide d’un fichier YAML.
Le framework gère le déploiement, le scaling et la mise à jour de fonctions serverless, d’APIs et d’autres ressources.
GitHub Actions
GitHub Actions est un puissant outil d’automatisation CI/CD qui permet aux développeurs d’automatiser leurs flux de travail logiciel directement à partir de leur dépôt GitHub.
Avec GitHub Actions, vous pouvez créer des pipelines personnalisés déclenchés par des événements tels que des push de code, des demandes de pull ou des fusions de branche. Ces workflows sont définis dans des fichiers YAML au sein du dépôt et peuvent effectuer des tâches telles que le test, la construction et le déploiement d’applications dans divers environnements.
Postman
Postman est une plateforme de collaboration populaire qui simplifie le processus de conception, de test et de documentation des APIs. Elle offre une interface utilisateur友好 pour que les développeurs puissent créer et envoyer des requêtes HTTP, tester des points de terminaison API et automatiser les flux de travail de test.
Très bien, maintenant que vous êtes familiarisé avec les outils et technologies que nous utiliserons ici, fassons-y un plongeon.
Prérequis
-
Node.js et npm installés
-
AWS CLI configuré avec accès à votre compte AWS
-
Un compte Serverless Framework
-
Serverlesss Framework installé globalement dans votre interface CLI locale
Notre cas d’utilisation
Rencontrez Alyx, une entrepreneure qui a récemment commencé à apprendre sur l’architecture serverless. Elle a lu sur la manière dont c’est une méthode puissante et efficiente pour construire les backends des applications web, offrant une approche plus moderne au développement des applications web.
Elle souhaite appliquer ce qu’elle a appris jusqu’à présent sur les fondamentaux de l’informatique serverless d’AWS. Elle sait que serverless ne signifie pas qu’il n’y a pas de serveurs impliqués – plutôt, il s’agit juste de l’abstraction du management et de la provisioning des serveurs. Et maintenant, elle veut se concentrer uniquement sur l’écriture de code et l’implémentation de la logique d’affaires.
Faisons le tour de comment Alyx, propriétaire d’un prospère café, commence à exploiter l’architecture serverless pour le backend de son application web.
Alyx’s Coffee Haven, un site de vente en ligne de cafés, offre une gamme de melanges de café et de petits plats à vendre. Initialement, Alyx gérait les commandes et l’inventaire du magasin avec des services de hébergement web traditionnels et des opérations, où elle devait gérer plusieurs serveurs et ressources. Cependant, à mesure que son café gagnait en popularité, elle a commencé à faire face à un nombre croissant de commandes, en particulier pendant les heures de pointe et les promotions saisonnières.
Gérer les serveurs et s’assurer que l’application pouvait gérer la surcharge de trafic est devenu un défi pour Alyx. Elle se trouvait constamment préoccupée par la capacité des serveurs, la scalabilité et le coût du maintien de l’infrastructure.
Elle voulait également introduire de nouvelles fonctionnalités telles que des recommandations personnalisées et des programmes de fidélité, mais cette tâche est devenue redoutable compte tenu des limitations de son système traditionnel.
Alyx a ensuite découvert la notion de backend sans serveur. Elle a comparé un backend sans serveur à un barista qui automatiquement prépare un café en temps réel, sans qu’elle soit tenue de s’occuper des détails subtils du processus de fabrication du café.
Enchantée par cette idée, Alyx a décidé de migrer le backend de son café vers une plateforme sans serveur en utilisant AWS Lambda, AWS API Gateway et Amazon DynamoDB. Ce dispositif lui permettra de se concentrer davantage sur la création de parfaites recettes de café et de gâteux pour ses clients.
Avec le backend sans serveur, chaque commande client devient un événement qui déclenche une série de fonctions sans serveur. Des fonctions AWS Lambda distinctes traiteront les commandes et géreront tous les processus logiques derrière le dos. Par exemple, elles créent une commande de client et sont capables de récupérer cette commande. Elles peuvent également supprimer une commande ou mettre à jour l’état d’une commande.
Alyx n’a plus à se soucier de la gestion de serveurs, car la plateforme sans serveur se scalera automatiquement en fonction des demandes de commandes entrantes. De plus, l’efficacité des coûts du backend sans serveur est énorme pour Alyx. Avec un modèle pay-per-use, elle ne paye que pour le temps de calcul réellement consommé par ses fonctions, offrant ainsi une solution plus économique pour son entreprise en croissance.
Mais elle ne s’arrête pas là ! Elle veut également automatiser tout, de la déployment de l’infrastructure à la mise à jour de son application chaque fois qu’il y a une nouvelle modification. En utilisant l’Infrastructure comme Code (IaC) avec le Serverless Framework, elle peut définir toute son infrastructure dans le code et la gérer facilement.
En plus de cela, elle configure GitHub Actions pour la intégration continue et la distribution continue (CI/CD), de sorte que chaque modification qu’elle effectue est automatiquement déployée via un pipeline, que ce soit une nouvelle fonction en développement ou une correction urgente pour la production.
Objectifs du tutoriel
-
Configurer l’environnement du Serverless Framework
-
Définir une API dans le fichier YAML
-
Développer des fonctions AWS Lambda pour traiter les opérations CRUD
-
Configurer les déploiements multi-étapes pour Dev et Prod
-
Tester les pipelines Dev et Prod
-
Tester et valider les API Dev et Prod à l’aide de Postman
Comment démarrer : Clonez le dépôt Git.
Pour améliorer votre compréhension et pouvoir suivre ce tutoriel plus efficacement, clonez le dépôt du projet depuis mon GitHub. Vous pouvez le faire en allant ici. Au fur et à mesure, n’hésitez pas à modifier les fichiers comme il vous semble nécessaire.
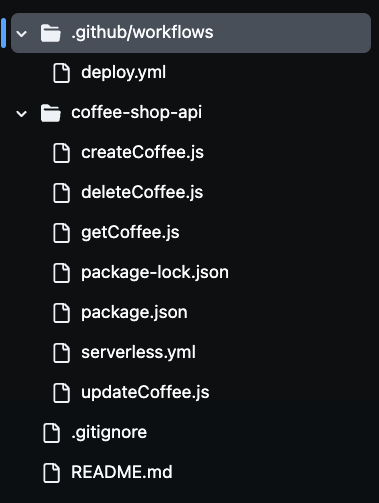
Après avoir cloné le dépôt, vous remarquerez la présence de multiples fichiers dans votre dossier, comme vous pouvez le voir sur l’image ci-dessous. Nous utiliserons tous ces fichiers pour construire notre API de café sans serveur.
Étape 1 : Configurer l’environnement du Framework Serverless
Pour configurer l’environnement du Framework Serverless pour des déploiements automatisés, vous aurez besoin d’authentifier votre compte Serverless Framework via la CLI.
Cela nécessite la création d’une clé d’accès qui permet à la chaîne CI/CD d’utiliser le Framework Serverless pour s’authentifier de manière sécurisée dans votre compte sans exposer vos informations d’identification. En vous connectant à votre compte Serverless et en générant une clé d’accès, la chaîne peut déployer automatiquement votre application sans serveur à partir du fichier de configuration de build.
Pour ce faire, rendez-vous sur votre compte Serverless et allez dans la section Clés d’accès. Cliquez sur “+ajouter”, nommez-la SERVERLESS_ACCESS_KEY, puis créez la clé.
Une fois que vous avez créé votre clé d’accès, assurez-vous de la copier et de la stocker en sécurité. Vous utiliserez cette clé en tant que variable secrète dans votre dépôt GitHub pour authentifier et autoriser votre chaîne CI/CD.
Il permettra d’accéder à votre compte Serverless Framework pendant le processus de déploiement. Vous ajouteriez cette clé à vos secrets de repository GitHub plus tard, afin que votre pipeline puisse l’utiliser de manière sécurisée pour déployer les ressources serverless sans exposer des informations sensibles dans votre codebase.
Maintenant, définissons les ressources AWS en code dans le fichier severless.yaml.
Étape 2 : Définir l’API dans le fichier Serverless YAML
Dans ce fichier, vous définirez l’infrastructure et la fonctionnalité principales de l’API du Coffee Shop en utilisant la configuration YAML du Serverless Framework.
Ce fichier définit les services AWS utilisés, y compris API Gateway, des fonctions Lambda pour les opérations CRUD et DynamoDB pour le stockage de données.
Vous configurerez également un rôle IAM afin que les fonctions Lambda aient les permissions nécessaires pour interagir avec le service DynamoDB.
L’API Gateway est configuré avec les méthodes HTTP appropriées (POST, GET, PUT et DELETE) pour gérer les demandes entrantes et déclencher les fonctions Lambda correspondantes.
Allons-y voir dans le code :
service: coffee-shop-api
frameworkVersion: '4'
provider:
name: aws
runtime: nodejs20.x
region: us-east-1
stage: ${opt:stage}
iam:
role:
statements:
- Effect: Allow
Action:
- dynamodb:PutItem
- dynamodb:GetItem
- dynamodb:Scan
- dynamodb:UpdateItem
- dynamodb:DeleteItem
Resource: arn:aws:dynamodb:${self:provider.region}:*:table/CoffeeOrders-${self:provider.stage}
functions:
createCoffee:
handler: createCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: post
getCoffee:
handler: getCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: get
updateCoffee:
handler: updateCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: put
deleteCoffee:
handler: deleteCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: delete
resources:
Resources:
CoffeeTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: CoffeeOrders-${self:provider.stage}
AttributeDefinitions:
- AttributeName: OrderId
AttributeType: S
- AttributeName: CustomerName
AttributeType: S
KeySchema:
- AttributeName: OrderId
KeyType: HASH
- AttributeName: CustomerName
KeyType: RANGE
BillingMode: PAY_PER_REQUEST
La configuration serverless.yml définit comment l’API du Coffee Shop d’Alyx sera exécutée dans un environnement serverless sur AWS. La section provider spécifie que l’application utilisera AWS comme fournisseur de cloud, avec Node.js comme environnement de runtime.
La région est définie sur us-east-1 et la variable stage permet le déploiement dynamique dans différents environnements, tels que dev et prod. Cela signifie que le même code peut être déployé dans différents environnements, avec les ressources nommées correspondantes pour éviter les conflits.
Dans la section iam, des permissions sont octroyées aux fonctions Lambda pour interagir avec la table DynamoDB. La syntaxe ${self:provider.stage} donne dynamiquement le nom de la table DynamoDB, de sorte que chaque environnement a ses propres ressources distinctes, telles que CoffeeOrders-dev pour l’environnement de développement et CoffeeOrders-prod pour la production. Cet attribution dynamique d’ nom helpe à gérer plusieurs environnements sans configurer manuellement des tables distinctes pour chacun d’eux.
La section functions définit les quatre fonctions Lambda centrales, createCoffee, getCoffee, updateCoffee et deleteCoffee. Celles-ci gèrent les opérations CRUD pour l’API du Coffee Shop.
Chaque fonction est connectée à un méthode HTTP spécifique de l’API Gateway, tels que POST, GET, PUT et DELETE.ces fonctions interagissent avec la table DynamoDB nommée dynamiquement en fonction de l’étape actuelle.
La dernière section resources définit elle-même la table DynamoDB. Elle configure la table avec les attributs OrderId et CustomerName, utilisés comme clé primaire. La table est configurée pour utiliser un mode de facturation pay-per-request, ce qui en fait une solution économique pour le business en croissance d’Alyx.
By automating the deployment of these resources using the Serverless Framework, Alyx peut facilement gérer son infrastructure, libérant ainsi de la charge de provisioning et de mise à l’échelle manuelle des ressources.
Étape 3 : Développer les fonctions Lambda pour les opérations CRUD
À cette étape, nous implémentons la logique de base de l’API du Café d’Alyx en créant des fonctions Lambda avec JavaScript qui effectuent les opérations CRUD essentielles createCoffee, getCoffee, updateCoffee et deleteCoffee.
Ces fonctions utilisent le SDK AWS pour interagir avec les services AWS, en particulier DynamoDB. Chaque fonction sera responsable de la gestion des demandes d’API spécifiques telles que la création d’une commande, la récupération des commandes, la mise à jour des statuts de commande et la suppression des commandes.
Fonction Lambda Create Coffee
Cette fonction crée une commande :
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
const { v4: uuidv4 } = require('uuid');
module.exports.handler = async (event) => {
const requestBody = JSON.parse(event.body);
const customerName = requestBody.customer_name;
const coffeeBlend = requestBody.coffee_blend;
const orderId = uuidv4();
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE,
Item: {
OrderId: orderId,
CustomerName: customerName,
CoffeeBlend: coffeeBlend,
OrderStatus: 'Pending'
}
};
try {
await dynamoDb.put(params).promise();
return {
statusCode: 200,
body: JSON.stringify({ message: 'Order created successfully!', OrderId: orderId })
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Could not create order: ${error.message}` })
};
}
};
Cette fonction Lambda gère la création d’une nouvelle commande de café dans la table DynamoDB. Nous importons d’abord le SDK AWS et initialisons un DynamoDB.DocumentClient pour interagir avec DynamoDB. La bibliothèque uuid est également importée pour générer des IDs de commande uniques.
A l’intérieur de la fonction handler, nous parseons le corps de la requête entrante pour extraire les informations client, telles que le nom du client et le mélange de café préféré. Un orderId unique est généré à l’aide de uuidv4() et ces données sont préparées pour insertion dans DynamoDB.
L’objet params définit la table où les données seront stockées, avec TableName définie dynamiquement à la valeur de la variable d’environnement COFFEE_ORDERS_TABLE. Le nouvel ordre inclut des champs tels que OrderId, CustomerName, CoffeeBlend, et un statut initial de Pending.
Dans le bloc try, le code essaye d’ajouter l’ordre à la table DynamoDB en utilisant la méthode put(). Si la tentative est réussie, la fonction retourne un code de statut de 200 avec un message de succès et l’OrderId. Si une erreur survient, le code la capture et retourne un code de statut de 500 accompagné d’un message d’erreur.
Fonction Get Coffee Lambda
Cette fonction récupère tous les articles de café :
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
module.exports.handler = async () => {
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE
};
try {
const result = await dynamoDb.scan(params).promise();
return {
statusCode: 200,
body: JSON.stringify(result.Items)
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Could not retrieve orders: ${error.message}` })
};
}
};
Cette fonction Lambda est chargée de récupérer tous les ordres de café depuis une table DynamoDB et illustre une approche serverless pour récupérer des données de DynamoDB de manière scalable.
Nous utilisons à nouveau l’SDK AWS pour initialiser une instance de DynamoDB.DocumentClient pour interagir avec DynamoDB. La fonction handler construit l’objet params, spécifiant le TableName, qui est défini dynamiquement en utilisant la variable d’environnement COFFEE_ORDERS_TABLE.
La méthode scan() récupère tous les éléments de la table. En cas de succès de l’opération, la fonction retourne un code de statut de 200 accompagné des éléments récupérés au format JSON. En cas d’erreur, un code de statut de 500 et un message d’erreur sont retournés.
Mise à jour de la fonction Coffee Lambda
Cette fonction met à jour un élément de café par son ID :
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
module.exports.handler = async (event) => {
const requestBody = JSON.parse(event.body);
const { order_id, new_status, customer_name } = requestBody;
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE,
Key: {
OrderId: order_id,
CustomerName: customer_name
},
UpdateExpression: 'SET OrderStatus = :status',
ExpressionAttributeValues: {
':status': new_status
}
};
try {
await dynamoDb.update(params).promise();
return {
statusCode: 200,
body: JSON.stringify({ message: 'Order status updated successfully!', OrderId: order_id })
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Could not update order: ${error.message}` })
};
}
};
Cette fonction Lambda gère la mise à jour du statut d’un ordre de café spécifique dans la table DynamoDB.
La fonction handler extrait order_id, new_status et customer_name du corps de la requête. Elle construit ensuite l’objet params pour spécifier le nom de la table et la clé primaire de l’ordre (en utilisant OrderId et CustomerName). L’UpdateExpression définit le nouveau statut de l’ordre.
Dans le bloc try, le code essaye de mettre à jour l’ordre dans DynamoDB en utilisant la méthode update(). Encore une fois, si cela réussi, la fonction retourne un code de statut de 200 avec un message de succès. Si une erreur survient, elle capture l’erreur et retourne un code de statut de 500 accompagné d’un message d’erreur.
Fonction Supprimer Café Lambda
Cette fonction supprime un élément de café par son ID :
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
module.exports.handler = async (event) => {
const requestBody = JSON.parse(event.body);
const { order_id, customer_name } = requestBody;
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE,
Key: {
OrderId: order_id,
CustomerName: customer_name
}
};
try {
await dynamoDb.delete(params).promise();
return {
statusCode: 200,
body: JSON.stringify({ message: 'Order deleted successfully!', OrderId: order_id })
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Could not delete order: ${error.message}` })
};
}
};
La fonction Lambda supprime une commande de café spécifique de la table DynamoDB. Dans la fonction handler, le code analyse le corps de la requête pour extraire les valeurs order_id et customer_name. Ces valeurs sont utilisées comme clé primaire pour identifier l’élément à supprimer de la table. L’objet params spécifie le nom de la table et la clé de l’élément à supprimer.
Dans le bloc try, le code essaye de supprimer la commande de DynamoDB en utilisant la méthode delete(). Si l’opération est réussie, il retourne à nouveau un code d’état 200 avec un message de succès, indiquant que la commande a été supprimée. Si une erreur se produit, le code la capture et retourne un code d’état 500 accompagné d’un message d’erreur.
Maintenant que nous avons expliqué chaque fonction Lambda, venez nous configurer une chaîne de CI/CD à plusieurs étapes.
Étape 4 : Configurer les déploiements de pipeline CI/CD multi-étapes pour les environnements Dev et Prod
Pour configurer les secrets AWS dans votre dépôt GitHub, naviguez d’abord vers les paramètres du dépôt. Sélectionnez Settings en haut à droite, puis allez en bas à gauche et sélectionnez Secrets and variables.

Ensuite, cliquez sur Actions comme visible sur l’image ci-dessous:
Depuis là, sélectionnez New repository secret pour créer les secrets.
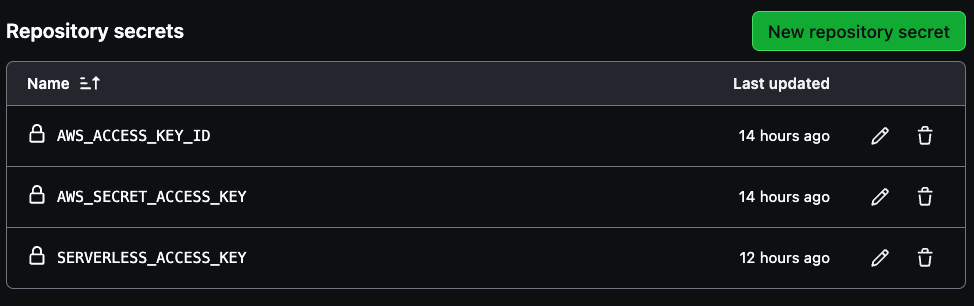
Deux secrets sont nécessaires pour créer votre pipeline, AWS_ACCESS_KEY_ID et AWS_SECRET_ACCESS_KEY.
Utilisez les crédits de clé d’accès à votre compte AWS pour les deux premières variables, puis la clé d’accès sans serveur précédemment enregistrée pour créer la SERVERLESS_ACCESS_KEY. Ces secrets authentifieront de manière sécurisée votre pipeline CI/CD comme illustré dans l’image ci-dessous.
Assurez-vous que votre branche principale s’appelle « main, » car elle servira de branche de production. Ensuite, créez une nouvelle branche appelée « dev » pour le travail de développement.
Vous pouvez également créer des branches spécifiques aux fonctionnalités, telles que « dev/feature, » pour un développement plus granulaire. GitHub Actions utilisera ces branches pour déployer automatiquement les modifications, avec dev représentant l’environnement de développement et main représentant la production.
Cette stratégie de branching vous permet de gérer le pipeline CI/CD efficacement, en déployant de nouveaux changements de code à chaque fusion dans l’environnement dev ou prod.
Comment utiliser GitHub Actions pour déployer le fichier YAML
Pour automatiser le processus de déploiement de l’API Coffee Shop, vous utiliserez GitHub Actions, qui s’intègre à votre dépôt GitHub.
Cette pipeline de déploiement est déclenchée chaque fois que du code est poussé vers les branches main ou dev. En configurant des déploiements spécifiques à l’environnement, vous serez sûr que les mises à jour de la branche dev sont déployées dans l’environnement de développement, tandis que les modifications de la branche main déclenchent les déploiements de production.
Maintenant, examinons le code :
name: deploy-coffee-shop-api
on:
push:
branches:
- main
- dev
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v3
- name: Setup Node.js
uses: actions/setup-node@v3
with:
node-version: '20.x'
- name: Install dependencies
run: |
cd coffee-shop-api
npm install
- name: Install Serverless Framework
run: npm install -g serverless
- name: Deploy to AWS (Dev)
if: github.ref == 'refs/heads/dev'
run: |
cd coffee-shop-api
npx serverless deploy --stage dev
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
SERVERLESS_ACCESS_KEY: ${{secrets.SERVERLESS_ACCESS_KEY}}
- name: Deploy to AWS (Prod)
if: github.ref == 'refs/heads/main'
run: |
cd coffee-shop-api
npx serverless deploy --stage prod
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
SERVERLESS_ACCESS_KEY: ${{secrets.SERVERLESS_ACCESS_KEY}}
La configuration YAML de GitHub Actions est ce qui automate le processus de déploiement de l’API Coffee Shop sur AWS en utilisant le Framework Serverless. Le workflow est déclenché chaque fois que des modifications sont pushées vers les branches principale ou dev.
Il commence par checker out le code du dépôt, puis configure Node.js avec la version 20.x pour correspondre au runtime utilisé par les fonctions Lambda. Après cela, il installe les dépendances du projet en naviguant vers le répertoire coffee-shop-api et en exécutant npm install.
Le workflow installe également le Framework Serverless globalement, permettant à l’interface en ligne de commande serverless d’être utilisée pour les déploiements. En fonction de la branche mise à jour, le workflow déploye conditionnellement vers l’environnement approprié.
Si les modifications sont pushées vers la branche dev, il déploye à l’étape dev. Si elles sont pushées vers la branche principale, il déploye à l’étape prod. Les commandes de déploiement, npx serverless deploy --stage dev ou npx serverless deploy --stage prod sont exécutées dans le répertoire coffee-shop-api.
Pour un déploiement sécurisé, le workflow accède aux crédits AWS et à la clé d’accès Serverless via des variables d’environnement stockées dans les Secrets GitHub. Cela permet à la pipeline CI/CD de s’authentifier avec AWS et le Framework Serverless sans exposer d’informations sensibles dans le dépôt.
Maintenant, nous pouvons procéder à tester la pipeline.
Étape 5 : Tester les pipelines Dev et Prod.
Tout d’abord, vous devez vérifier que la branche principale (prod) est nommée « main ». Ensuite, créez une branche de développement nommée « dev ». Une fois que vous avez apporté des modifications valables à la branche de développement, committez-les pour déclencher le pipeline GitHub Actions. Cela déploiera automatiquement les ressources mises à jour dans l’environnement de développement. Après avoir vérifié tout dans le développement, vous pouvez alors fusionner la branche de développement dans la branche principale.
La fusion des modifications dans la branche principale déclenche également automatiquement le pipeline de déploiement pour l’environnement de production. De cette manière, toutes les mises à jour nécessaires sont appliquées et les ressources de production sont déployées de manière continue.
Vous pouvez surveiller le processus de déploiement et consulter des journaux détaillés de chaque exécution de GitHub Actions en naviguant vers l’onglet Actions dans votre référentiel GitHub.
Les journaux fournissent une visibilité sur chaque étape du pipeline, vous aidant à vérifier que tout fonctionne comme prévu.
Vous pouvez sélectionner n’importe quelle exécution de construction pour consulter des journaux détaillés pour les déploiements des environnements de développement et de production afin de suivre le progrès et s’assurer que tout se déroule sans problème.
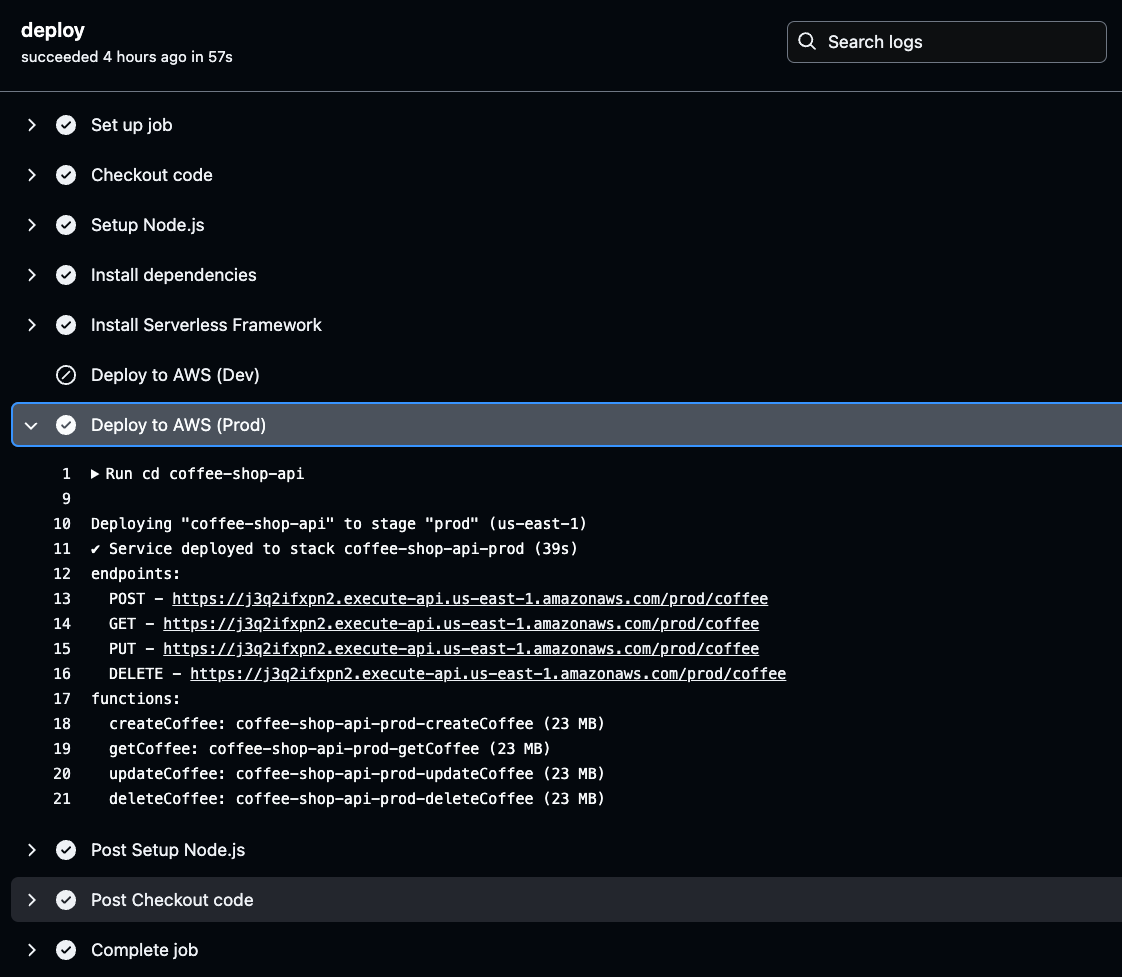
Naviguez vers l’exécution de construction spécifique dans GitHub Actions, comme illustré dans l’image ci-dessous. Là, vous pouvez afficher les détails d’exécution et les résultats pour les pipelines de développement ou de production.

Assurez-vous de tester suffisamment les environnements de développement et de production pour confirmer l’exécution réussie du pipeline.
Étape 6 : Tester et valider les API Prod et Dev à l’aide de Postman.
Une fois que les API et les ressources sont déployées et configurées, nous devons localiser les points de terminaison API uniques (URLs) générés par AWS pour commencer à faire des requêtes et tester la fonctionnalité.
Ces URLs peuvent tester la fonctionnalité de l’API en les collant simplement dans un navigateur web. Les URLs des API se trouvent dans les résultats de sortie de votre build CI/CD.
Pour les récupérer, accédez aux journaux d’actions GitHub, sélectionnez le build réussi le plus récent de l’environnement, et cliquez sur déployer pour vérifier les détails du déploiement des endpoints API générés.
Cliquez sur l’étape Déployer sur AWS pour l’environnement sélectionné (Prod ou Dev) dans vos journaux d’actions GitHub. Une fois là, vous trouverez l’URL API générée.
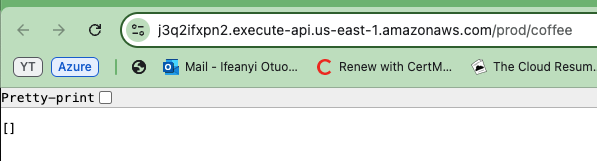
Copiez et sauvegardez cette URL, car elle sera nécessaire lors du test de la fonctionnalité de votre API. Cette URL est votre passerelle pour vérifier que l’API déployée fonctionne comme prévu.
Maintenant, copiez l’une des URLs API générées et collez-la dans votre navigateur. Vous verrez un tableau ou une liste vide affichée dans la réponse. Cela confirme en fait que l’API fonctionne correctement et que vous récupérez avec succès des données de la table DynamoDB.
Même si la liste est vide, cela indique que l’API peut se connecter à la base de données et retourner des informations.
Pour vérifier que votre API fonctionne dans les deux environnements, répétez les étapes pour l’autre environnement API (Prod et Dev).
Nous utiliserons Postman pour tester toutes les méthodes API, Create, Read, Update et Delete, et effectuerons ces tests tanto pour l’environnement de développement que pour l’environnement de production.
Pour tester la méthode GET, utilisez Postman pour envoyer une requête GET à l’endpoint de l’API via l’URL. Vous recevrez la même réponse, une liste vide de commandes de café comme montrée dans le bas de l’image ci-dessous. Cela confirme la capacité de l’API à récupérer les données avec succès, comme illustré dans l’image ci-dessous.

Pour créer réellement une commande, testons la méthode POST. Utilisez à nouveau Postman pour faire une requête POST à l’endpoint de l’API, en fournissant le nom du client et le mélange de café dans le corps de la requête, comme indiqué ci-dessous :
{
"customer_name": "REXTECH",
"coffee_blend": "Black"
}
La réponse sera un message de succès avec un OrderId unique de la commande passée.
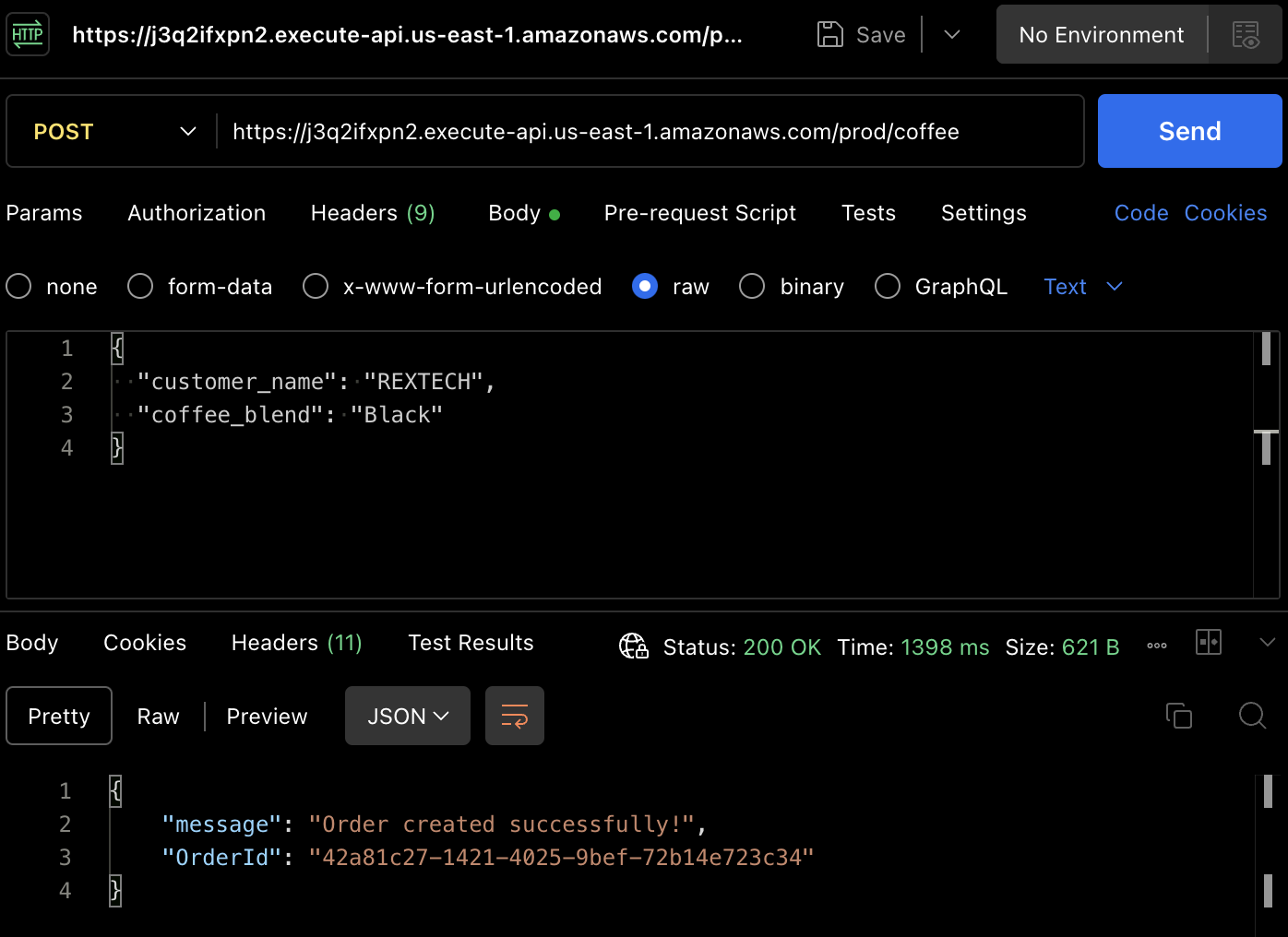
Vérifiez que la nouvelle commande a été enregistrée dans la table DynamoDB en examinant les articles de la table spécifique à l’environnement :

Pour tester la méthode PUT, faites une requête PUT à l’endpoint de l’API en fournissant l’ID de commande précédent et un nouvel état de commande dans le corps de la requête, comme montré ci-dessous :
{
"order_id": "42a81c27-1421-4025-9bef-72b14e723c34",
"new_status": "Ready",
"customer_name": "REXTECH"
}
La réponse sera un message de mise à jour de commande réussie avec l’OrderId de la commande passée.
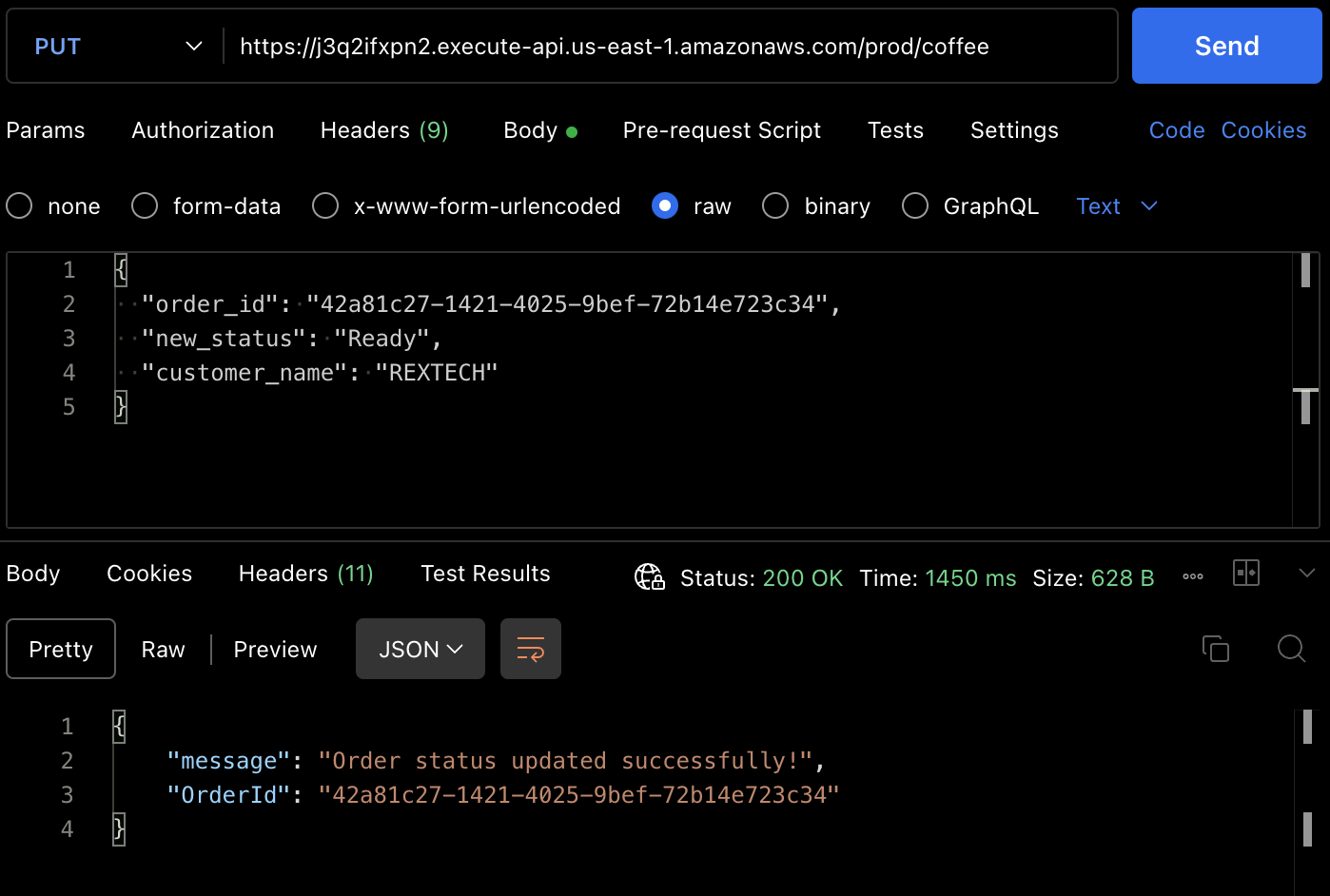
Vous pouvez également vérifier que l’état de la commande a été mis à jour à partir de l’item de la table DynamoDB.

Pour tester la méthode DELETE, en utilisant Postman, faites une requête DELETE en fournissant l’ID de commande précédent et le nom du client dans le corps de la requête, comme indiqué ci-dessous :
{
"order_id": "42a81c27-1421-4025-9bef-72b14e723c34",
"customer_name": "REXTECH"
}
Le message de réponse sera une confirmation de suppression de commande avec l’ID de commande de la commande passée.
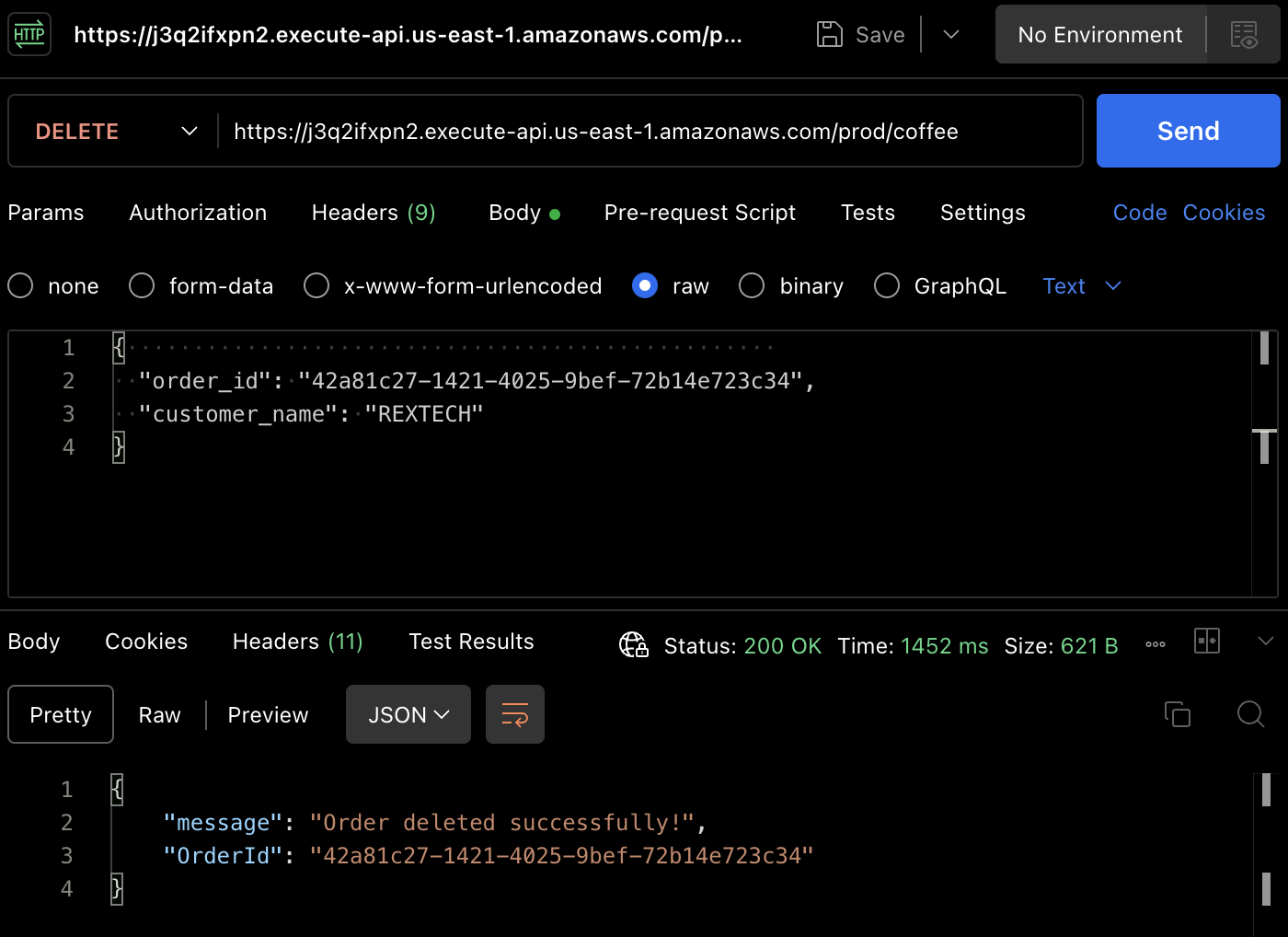
À nouveau, vous pouvez vérifier que la commande a été supprimée dans la table DynamoDB.

Conclusion
C’est tout – félicitations ! Vous avez réussi à terminer toutes les étapes. Nous avons construit une API REST sans serveur qui supporte les fonctionnalités CRUD (Créer, Lire, Mettre à jour, Supprimer) avec API Gateway, Lambda, DynamoDB, Serverless Framework et Node.js, automatisant le déploiement des modifications de code approuvées avec Github Actions.
Si vous êtes arrivé jusqu’ici, merci pour votre lecture ! J’espère que cela vous a été utile.
Ifeanyi Otuonye est un ingénieur cloud certifié AWS 6 fois, expert en DevOps, en écriture technique et en compétences pédagogiques en tant qu’instructeur technique. Il est motivé par sa soif d’apprendre et de se développer et prospère dans des environnements collaboratifs. Avant de passer au Cloud, il a passé six ans en tant qu’athlète professionnel de l’athlétisme de piste et de terrain.
À l’été 2022, il a entrepris stratégiquement une mission pour devenir un ingénieur Cloud/DevOps par l’étude autonome et en participant à un programme accéléré de Cloud de 6 mois.
En mai 2023, il a atteint son objectif en obtenant son premier poste d’ingénieur cloud et a maintenant fixé une nouvelle mission personnelle pour accompagner d’autres personnes dans leur chemin vers le Cloud.
Source:
https://www.freecodecamp.org/news/how-to-build-a-serverless-crud-rest-api/