













Introducción
Los métodos de interpretabilidad de modelos han adquirido un creciente significado en los últimos años como consecuencia directa del aumento de la complejidad de los modelos y la falta de transparencia asociada. La comprensión del modelo es un tema de estudio caliente y un área focal para las aplicaciones prácticas que emplean machine learning en varios sectores.
Captum proporciona a académicos y desarrolladores técnicas punta de lanza, como los Gradientes Integrados, que simplifican la identificación de los elementos que contribuyen a la salida del modelo. Captum hace más fácil para los investigadores de ML utilizar modelos de PyTorch para construir métodos de interpretabilidad.
Al facilitar la identificación de muchos elementos que contribuyen a la salida del modelo, Captum puede ayudar a los desarrolladores de modelos a crear mejores modelos y corregir modelos que dan resultados inesperados.
Descripciones de Algoritmos
Captum es una biblioteca que permite la implementación de diversas aproximaciones a la interpretabilidad. Es posible clasificar los algoritmos de atribución de Captum en tres categorías amplias:
- atribución primaria: Determina la contribución de cada característica de entrada a la salida del modelo.
- Atribución de Capas: Cada neurona en una capa particular es evaluada por su contribución al salida del modelo.
- Atribución de Neuronas: La activación de una neurona oculta se determina evaluando la contribución de cada característica de entrada.
A continuación, se ofrece una breve visión general de los diversos métodos que actualmente están implementados en Captum para la atribución primaria, de capa y de neurona. También se incluye una descripción del túnel de ruido, que se puede utilizar para suavizar los resultados de cualquier método de atribución.
Captum proporciona métricas para estimar la confiabilidad de las explicaciones del modelo, además de sus algoritmos de atribución. En este momento, proporcionan métricas de infidelidad y sensibilidad que ayudan a evaluar la precisión de las explicaciones.
Técnicas de Atribución Primaria
Gradientes Integrados
Supongamos que tenemos una representación formal de una red neuronal profunda, F: Rn → [0, 1].
Sea x ∈ Rn el input actual y x′ ∈ Rn el input de referencia.
La línea de base en redes de imágenes podría ser la imagen negra, mientras que en modelos de texto podría ser el vector de embedding cero.
Desde la línea de base x′ hasta el input x, calculamos gradientes en todos los puntos a lo largo de la trayectoria recta (en Rn). Al acumular estos gradientes, se pueden generar gradientes integrados. Los gradientes integrados se definen como el integral de los gradientes a lo largo de una trayectoria directa desde la línea de base x′ hasta el input x.
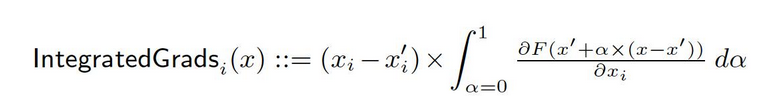
Las dos hipótesis básicas, sensibilidad y invariancia de implementación, forman la base de este método. Consulte el documento original para aprender más sobre estos axiomas.
Gradiente SHAP
Los valores de Shapley en teoría de juegos cooperativos se utilizan para calcular los valores de SHAP gradientes, que se calculan utilizando una abstracción de gradientes. SHAP gradientes agrega ruido gaussiano a cada muestra de entrada varias veces, luego se elige un punto aleatorio en la trayectoria entre el punto de referencia y la entrada para determinar el gradiente de las salidas. Como resultado, los valores de SHAP finales representan la esperanza de los gradientes. * (entradas – referencias). Los valores de SHAP se aproximan bajo el supuesto de que las características de entrada son independientes y que el modelo explicativo es lineal entre las entradas y las referencias proporcionadas.
DeepLIFT
Puede utilizarse DeepLIFT (una técnica de propagación hacia atrás) para atribuir cambios en la entrada en base a las diferencias entre las entradas y sus referencias correspondientes (o referencia de base). DeepLIFT intenta explicar la disparidad entre la salida de referencia utilizando la disparidad entre las entradas de referencia. DeepLIFT emplea la idea de multiplicadores para “culpar” a individuos neuronas por la diferencia en las salidas. Para una neurona de entrada x con diferencia-desde-referencia ∆x, y una neurona objetivo t con diferencia-desde-referencia ∆t que queremos calcular la contribución a, definimos el multiplicador m∆x∆t como:
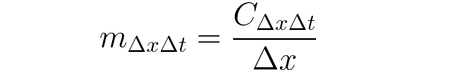
DeepLIFT SHAP
DeepLIFT SHAP es una extensión de DeepLIFT basada en los valores de Shapley establecidos en la teoría de juegos cooperativos. DeepLIFT SHAP calcula la atribución de DeepLIFT para cada par entrada-referencia y promedia las atribuciones resultantes por ejemplo de entrada utilizando una distribución de referencias. Las reglas no lineales de DeepLIFT ayudan a linealizar las funciones no lineales de la red, y la aproximación de los valores de SHAP de este método también se aplica a la red linealizada. En este método, se presume que las características de entrada son independientes.
Saliencia
El cálculo de la atribución de entrada a través de saliencia es un proceso directo que produce la gradiente de la salida con respecto a la entrada. Se utiliza una expansión de primera orden de red Taylor en la entrada, y las gradientes son los coeficientes de cada característica en la representación lineal del modelo. El valor absoluto de estos coeficientes puede utilizarse para indicar la relevancia de una característica. Puede encontrar información adicional sobre el enfoque de saliencia en el documento original.
Entrada X Gradiente
Gradiente de Entrada X es una extensión del enfoque de saliencia, que toma los gradientes de la salida con respecto a la entrada y los multiplica por los valores de las características de entrada. Una intuición para este enfoque considera un modelo lineal; los gradientes simplemente son los coeficientes de cada entrada, y el producto de la entrada con un coeficiente corresponde a la contribución total de la característica al resultado del modelo lineal.
Backpropagación Guiada y Desconvolución
La computación de gradientes se realiza a través de backpropagación guiada y desconvolución, aunque la propagación hacia atrás de funciones ReLU se sobreescribe de manera que solo se propagan gradientes no negativos. Mientras que la función ReLU se aplica a los gradientes de entrada en la backpropagación guiada, se aplica directamente a los gradientes de salida en la desconvolución. Es una práctica común emplear estos métodos en conjunción con redes convolucionales, pero también pueden utilizarse en otras arquitecturas de red neuronal.
Guided GradCAM
La computación de atribuciones de retropropagación guiada calcula la multiplicación elemento a elemento de las atribuciones guiadas de GradCAM (Guided GradCAM) con las atribuciones (capa) GradCAM ampliadas. La computación de atribuciones se realiza para una capa dada y luego se amplía para ajustar al tamaño de entrada. Las redes neuronales convolucionales son el foco de esta técnica. Sin embargo, cualquier capa que pueda alinearse espacialmente con la entrada puede proporcionarse. Normalmente, se proporciona la última capa convolucional.
Ablación de Características
Para calcular atribuciones, se utiliza una técnica conocida como “ablación de características” que emplea un método basado en la perturbación que sustituye un “valor base” o “referencia” conocido (como 0) por cada característica de entrada antes de calcular la diferencia en la salida. Agrupar y ablatizar características de entrada es una alternativa mejor que hacerlo individualmente, y muchas aplicaciones diferentes pueden beneficiarse de esto. Al agrupar y ablatizar segmentos de una imagen, podemos determinar la importancia relativa del segmento.
Permutación de características
Permutación de características es un método basado en perturbación en el cual cada característica se permuta aleatoriamente dentro de un lote, y la variación en la salida (o pérdida) se calcula como resultado de esta modificación. Las características también pueden agruparse juntas en lugar de individualmente, de la misma manera que la ablación de características. Tenga en cuenta que en contraste con los otros algoritmos disponibles en Captum, este algoritmo es el único que puede proporcionar atribuciones apropiadas cuando se le proporciona un lote de múltiples ejemplos de entrada. Otros algoritmos solo necesitan un solo ejemplo como entrada.
Ocultación
Ocultación es un enfoque basado en perturbación para calcular atribuciones, reemplazando cada región rectangular contigua con un valor de referencia/base y calculando la diferencia en la salida. Para las características ubicadas en varias áreas (hiperectángulos), las diferencias de salida correspondientes se promedian para calcular la atribución para esa característica. La ocultación es más útil en casos como imágenes, donde los píxeles en una región rectangular contigua son probablemente altamente correlacionados.
Valor de Shapley de muestreo
La técnica de atribución Valor de Shapley se basa en la teoría de juegos cooperativos. Esta técnica toma cada permutación de las características de entrada y las agrega una por una a una línea de base especificada. La diferencia en la salida después de agregar cada característica corresponde a su contribución, y estas diferencias se suman entre todas las permutaciones para determinar la atribución.
Lime
Una de las metodologías de interpretabilidad más ampliamente utilizadas es Lime, que entrena un modelo sustituto interpretable mediante el muestreo de puntos alrededor de un ejemplo de entrada y el uso de evaluaciones del modelo en estos puntos para entrenar un modelo más simple y interpretable, como un modelo lineal.
KernelSHAP
Kernel SHAP es una técnica para calcular los Valores de Shapley que utiliza el marco LIME. Los Valores de Shapley se pueden obtener de manera más eficiente en el marco LIME mediante la configuración de la función de pérdida, el pesaje del kernel y la regularización adecuada de términos.
Técnicas de Atribución de Capas
Conductancia de Capa
La Conductancia de Capa es un método que crea un panorama más completo de la importancia de una neurona combinando la activación de la neurona con las derivadas parciales tanto de la neurona respecto de la entrada como de la salida respecto de la neurona. A través de la neurona oculta, la conductancia amplía la fluencia de atribución de Integrated Gradients (IG). La conductancia total de una neurona oculta y se define como sigue en el documento original:
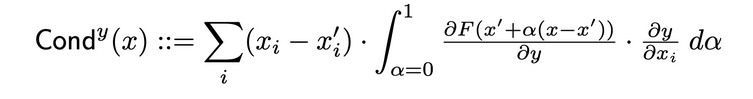
Influencia Interna
Usando Influencia Interna, se puede estimar la integral de los gradientes a lo largo del camino desde una entrada de base hasta la entrada proporcionada. Esta técnica es similar a aplicar gradientes integrados, que implica integrar el gradiente con respecto a la capa (en lugar de la entrada).
Gradiente de Capa X Activación
Gradiente de Capa X Activación es la versión de la red del technique Input X Gradiente para las capas ocultas en una red…
Se multiplica la activación de cada elemento de la capa por el gradiente de la salida objetivo con respecto a la capa especificada.
GradCAM
GradCAM es una técnica de atribución de capas de red neuronal convolucional generalmente aplicada a la última capa convolucional. GradCAM calcula los gradientes del objetivo de salida con respecto a la capa especificada, promedia cada canal de salida (dimensión de salida 2) y multiplica el gradiente promedio de cada canal por las activaciones de la capa. Se aplica una función ReLU al resultado para asegurar que solo se devuelvan atribuciones no negativas desde la suma de los resultados en todos los canales.
Técnicas de Atribución de Neuronas
Conductancia de Neurona
Conductancia combina la activación de la neurona con las derivadas parciales tanto de la neurona con respecto a la entrada como de la salida con respecto a la neurona, para proporcionar una imagen más completa de la relevancia de la neurona. Para determinar la conductancia de una neurona específica, se examina la fluencia de la atribución de IG que proviene de cada entrada que pasa a través de esa neurona. A continuación figura la definición formal de conductancia de la neurona y dada la atribución de entrada i del documento original:
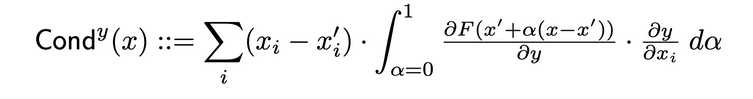
Según esta definición, cabe notar que la suma de la conductancia de una neurona (en todas las características de entrada) siempre es igual a la conductancia de la capa en la que se encuentra esa neurona específica.
Gradiente de Neurona
El enfoque de gradiente de neurona es la equivalencia de la metodología de saliencia para una sola neurona en la red. Simplemente calcula la gradiente de la salida de la neurona con relación a la entrada del modelo. Este método, como Saliency, puede considerarse como haciendo una expansión de Taylor de primera orden de la salida de la neurona en la entrada dada, con las gradientes correspondiendo a los coeficientes de cada característica en la representación lineal del modelo.
Gradientes Integrados de Neurona
Es posible estimar la integral de los gradientes de entrada con respecto a una neurona particular a lo largo de todo el camino desde una entrada de referencia hasta la entrada de interés utilizando una técnica llamada “Gradientes Integrados de Neurona.” Los gradientes integrados son equivalentes a este método, asumiendo que la salida es solo la de la neurona identificada. Puede encontrar información adicional sobre el enfoque de gradiente integrado en el artículo original aquí.
Gradientes SHAP de Neurona
Neuron GradientSHAP es el equivalente de GradientSHAP para una neurona específica. Neuron GradientSHAP agrega ruido Gaussiano a cada muestra de entrada varias veces, elige un punto aleatorio a lo largo de la trayectoria entre el punto de referencia y la entrada, y calcula la gradiente de la neurona objetivo con respecto a cada punto elegido al azar.
Los valores SHAP resultantes son similares a los valores de gradiente predichos *. (entradas – referencias).
Neuron DeepLIFT SHAP
Neuron DeepLIFT SHAP es el equivalente de DeepLIFT para una neurona específica. Usando la distribución de referencias básicas, el algoritmo DeepLIFT SHAP calcula la atribución de Neuron DeepLIFT para cada par de entrada-referencia y promedia las atribuciones resultantes por ejemplo de entrada.
Túnel de Ruido
Túnel de Ruido es una técnica de atribución que se puede usar en conjunto con otras metodologías. El túnel de ruido calcula la atribución varias veces, agregando ruido Gaussiano a la entrada cada vez, y luego combina las atribuciones resultantes dependiendo del tipo elegido. Los siguientes tipos de túnel de ruido están soportados:
- Smoothgrad: Se devuelve la media de las atribuciones muestreadas. La suavización de la técnica de atribución especificada utilizando un kernel gaussiano es una aproximación de este proceso.
- Smoothgrad Cuadrado: Se devuelve la media de las atribuciones muestreadas elevadas al cuadrado.
- Vargrad: Se devuelve la varianza de las atribuciones de muestra.
Metricas
Infidelidad
Infidelidad mide la media cuadrada del error entre las explicaciones del modelo en las magnitudes de las perturbaciones de entrada y los cambios en la función predictora de esas perturbaciones de entrada. La infidelidad se define como sigue:
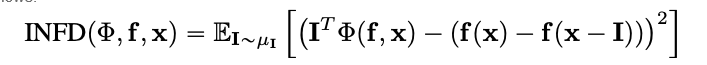
Apartir de técnicas de atribución bien conocidas como el gradiente integrado, esto es una versión computacionalmente más eficiente y extendida de Sensitivy-n. Éste analiza las correlaciones entre la suma de las atribuciones y las diferencias de la función predictora en su entrada y una línea de base predefinida.
Sensibilidad
Sensibilidad, que se define como el grado de cambio en la explicación debido a pequeñas perturbaciones en la entrada utilizando una aproximación basada en muestreo de Monte Carlo, se mide de la siguiente manera:

Por defecto, creamos muestras de un subespacio de una esfera de L-Infinity con un radio predeterminado para aproximar la sensibilidad. Los usuarios pueden cambiar el radio de la esfera y la función de muestreo.
Interpretación del Modelo para el Modelo ResNet Preentrenado
Este tutorial muestra cómo utilizar métodos de interpretabilidad de modelos en un modelo ResNet preentrenado con una imagen elegida y visualiza las atribuciones para cada pixel superponiéndolas sobre la imagen. En este tutorial, utilizaremos los algoritmos de interpretación GradCAM, GradientShape, Attribution with Layer GradCAM y Occlusion.
Antes de comenzar, debe tener un entorno de Python que incluya:
- Versión de Python 3.6 o superior
- Versión de PyTorch 1.2 o superior (se recomienda la versión más reciente)
- Versión de TorchVision 0
- .6 o superior (se recomienda la versión más reciente)
- Captum (se recomienda la versión más reciente)
Dependiendo de si estás utilizando un entorno virtual de Anaconda o pip, las siguientes instrucciones le ayudarán a configurar Captum:
Con conda:
conda install pytorch torchvision captum -c pytorch
Con pip:
pip install torch torchvision captum
Vamos a importar bibliotecas.
import torch
import torch.nn.functional as F
from PIL import Image
import os
import json
import numpy as np
from matplotlib.colors import LinearSegmentedColormap
import os, sys
import json
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
from matplotlib.colors import LinearSegmentedColormap
import torchvision
from torchvision import models
from torchvision import transforms
from captum.attr import IntegratedGradients
from captum.attr import GradientShap
from captum.attr import Occlusion
from captum.attr import LayerGradCam
from captum.attr import NoiseTunnel
from captum.attr import visualization as viz
from captum.attr import LayerAttribution
Carga el modelo preentrenado de ResNet y lo establece en modo de evaluación
model = models.resnet18(pretrained=True)
model = model.eval()
El ResNet está entrenado sobre el conjunto de datos ImageNet. Descarga y lee en memoria la lista de clases/etiquetas del conjunto de datos ImageNet.
wget -P $HOME/.torch/models https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json
labels_path = os.getenv("HOME") + '/.torch/models/imagenet_class_index.json'
with open(labels_path) as json_data:
idx_to_labels = json.load(json_data)
Ahora que hemos completado el modelo, podemos descargar la imagen para su análisis.
En mi caso, elegí una imagen de gato.

Tu carpeta de imágenes debe contener el archivo cat.jpg. Como pueden ver abajo, Image.open() abre e identifica el archivo de imagen proporcionado y np.asarray() lo convierte en un arreglo.
test_img = Image.open('path/cat.jpg')
test_img_data = np.asarray(test_img)
plt.imshow(test_img_data)
plt.show()
En el código de abajo, definiremos transformadores y funciones de normalización para la imagen. Para entrenar nuestro modelo de ResNet, usamos el conjunto de datos ImageNet, que requiere que las imágenes sean de un tamaño particular, con los datos de canal normalizados a un rango de valores especifico. transforms.Compose() compone varios transformadores juntos y transforms.Normalize() normaliza una imagen de tensor con media y desviación estándar.
La expectativa de modelo es una imagen de 224x224 colores三
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224), #crop the given tensor image at the center
transforms.ToTensor()
])
# Normalización de ImageNet
transform_normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
img = Image.open('path/cat.jpg')
transformed_img = transform(img)
input = transform_normalize(transformed_img)
#unsqueeze devuelve un nuevo tensor con una dimensión de tamaño uno insertada en la posición especificada.
input = input.unsqueeze(0)
Ahora, predeciremos la clase de la imagen de entrada. La pregunta que se puede hacer es, “¿Qué piensa nuestro modelo que representa esta imagen?”
# Llamar a nuestro modelo
output = model(input)
## Aplicar la función softmax()
output = F.softmax(output, dim=1)
# torch.topk devuelve los k elementos más grandes del tensor de entrada dado along a la dimensión especificada. K aquí es 1
prediction_score, pred_label_idx = torch.topk(output, 1)
pred_label_idx.squeeze_()
# Convertir en un diccionario de pares clave-valor el label predicho, convertirlo en una cadena para obtener el label predicho
predicted_label = idx_to_labels[str(pred_label_idx.item())][1]
print('Predicted:', predicted_label, '(', prediction_score.squeeze().item(), ')')
Salida:
Predicted: tabby ( 0.5530276298522949 )
El hecho de que ResNet cree que nuestra imagen de un gato representa un gato real está confirmado. Pero ¿qué le da al modelo la impresión de que esta es una imagen de un gato? Para obtener la respuesta a esa pregunta, consultaremos a Captum.
Atribución de Características con Gradientes Integrados
Una de las varias técnicas de atribución de características en Captum es Gradientes Integrados. Gradientes Integrados le asigna a cada característica de entrada una puntuación de relevancia calculando la integral de los gradientes de la salida del modelo con respecto a las entradas.
Para nuestro caso, seleccionaremos un componente particular del vector de salida – el que indica la confianza del modelo en su categoría seleccionada – y utilizaremos gradientes integrados para averiguar qué aspectos de la imagen de entrada contribuyen a este resultado. Permitirá determinar cuáles partes de la imagen fueron más importantes en la producción de este resultado.
Después de obtener el mapa de importancia de los Gradientes Integrados, utilizaremos las herramientas de visualización capturadas por Captum para proporcionar una representación clara y comprensible del mapa de importancia.
Los Gradientes Integrados determinarán la integral de los gradientes de la salida del modelo para la clase predicha pred_label_idx con respecto a los píxeles de la imagen de entrada a lo largo del camino desde la imagen negra hasta nuestra imagen de entrada.
print('Predicted:', predicted_label, '(', prediction_score.squeeze().item(), ')')
# Crear objeto IntegratedGradients y obtener atributos
integrated_gradients = IntegratedGradients(model)
# Solicitar que el algoritmo asigne nuestro objetivo de salida
attributions_ig = integrated_gradients.attribute(input, target=pred_label_idx, n_steps=200)
Salida:
Predicted: tabby ( 0.5530276298522949 )
Veamos la imagen y las atribuciones que van con ella superponiendo estas últimas sobre la imagen. El método visualize_image_attr() que ofrece Captum proporciona una serie de posibilidades para personalizar la presentación de los datos de atribución a nuestros gustos. Aquí, pasamos una tabla de colores personalizada de Matplotlib (ver LinearSegmentedColormap()).
Visualización de #resultados con mapa de colores personalizado
default_cmap = LinearSegmentedColormap.from_list('custom blue',
[(0, '#ffffff'),
(0.25, '#000000'),
(1, '#000000')], N=256)
# utilizar el método auxiliar visualize_image_attr para la visualización para mostrar la #imagen original para comparación
_ = viz.visualize_image_attr(np.transpose(attributions_ig.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
method='heat_map',
cmap=default_cmap,
show_colorbar=True,
sign='positive',
outlier_perc=1)
Salida:
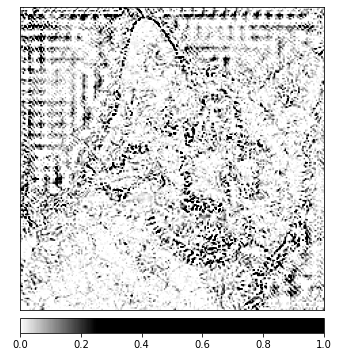
Debería poder notar en la imagen que mostramos arriba que la zona que rodea a la gata en la imagen es donde el algoritmo de Integrated Gradients nos da la señal más fuerte.
Vamos a calcular atribuciones usando Integrated Gradients y luego aplastarlas sobre varias imágenes que han sido producidas por un túnel de ruido.
El último modifica la entrada agregando ruido gaussiano con una desviación estándar de uno, 10 veces (nt_samples=10). El enfoque smoothgrad_sq es utilizado por el túnel de ruido para hacer que las atribuciones sean consistentes a través de todos los smoothgrad_sq valores de nt_samples muestras ruido. El valor de visualize_image_attr_multiple() visualiza las atribuciones para una imagen dada normalizando los valores de atribución de la señal especificada (positivo, negativo, valor absoluto o todos) y luego mostrandolos en una figura de matplotlib usando el modo seleccionado.
noise_tunnel = NoiseTunnel(integrated_gradients)
attributions_ig_nt = noise_tunnel.attribute(input, nt_samples=10, nt_type='smoothgrad_sq', target=pred_label_idx)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_ig_nt.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "positive"],
cmap=default_cmap,
show_colorbar=True)
Salida:

Puedo ver en las imágenes de arriba que el modelo se concentra en la cabeza de la gata.
Vamos a terminar utilizando GradientShap. GradientShap es un enfoque por gradientes que se puede utilizar para calcular valores SHAP, y también es una herramienta fantástica para adquirir insights en el comportamiento global. Es un modelo de explicación lineal que explica las predicciones del modelo utilizando una distribución de referencias de muestras. Determina las gradientes esperadas para una entrada seleccionada aleatoriamente entre la entrada y un punto de referencia básico.
El punto de referencia básico se selecciona aleatoriamente de la distribución de puntos de referencia proporcionada.
torch.manual_seed(0)
np.random.seed(0)
gradient_shap = GradientShap(model)
# Definición de la distribución de referencia de imágenes
rand_img_dist = torch.cat([input * 0, input * 1])
attributions_gs = gradient_shap.attribute(input,
n_samples=50,
stdevs=0.0001,
baselines=rand_img_dist,
target=pred_label_idx)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_gs.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "absolute_value"],
cmap=default_cmap,
show_colorbar=True)
Salida:

Atribución de Capa con GradCAM de Capa
Puedes relacionar la actividad de las capas ocultas dentro de tu modelo con las características de tu entrada mediante la Atribución de Capas.
Aplicaremos un algoritmo de atribución de capas para investigar la actividad de una de las capas convolucionales incluidas en nuestro modelo.
GradCAM es responsable de calcular las gradientes de la salida objetivo con respecto a la capa especificada. Estos gradientes luego se van a promediar por cada canal de salida (dimensión 2 de salida), y las activaciones de la capa se multiplican por el gradiente promedio para cada canal.
Los resultados se suman a través de todos los canales. Dado que la actividad de las capas convolucionales a menudo se mapea espacialmente a la entrada, las atribuciones de GradCAM se suelen upsample y se utilizan para mascarar la entrada. Es digno de notar que GradCAM está específicamente desarrollado para redes neuronales convolucionales (convnets). La atribución de capas se establece de la misma manera que la atribución de entrada, con la excepción de que, además del modelo, debes proporcionar una capa oculta dentro del modelo que quieres analizar. Similar a lo que se discutió anteriormente, cuando llamamos a attribute(), indicamos la clase objetivo de interés.
layer_gradcam = LayerGradCam(model, model.layer3[1].conv2)
attributions_lgc = layer_gradcam.attribute(input, target=pred_label_idx)
_ = viz.visualize_image_attr(attributions_lgc[0].cpu().permute(1,2,0).detach().numpy(),
sign="all",
title="Layer 3 Block 1 Conv 2")
Para hacer una comparación más precisa entre la imagen de entrada y este dato de atribución, upsampleremos este último con la ayuda de la función interpolate(), situada en la clase base LayerAttribution.
upsamp_attr_lgc = LayerAttribution.interpolate(attributions_lgc, input.shape[2:])
print(attributions_lgc.shape)
print(upsamp_attr_lgc.shape)
print(input.shape)
_ = viz.visualize_image_attr_multiple(upsamp_attr_lgc[0].cpu().permute(1,2,0).detach().numpy(),
transformed_img.permute(1,2,0).numpy(),
["original_image","blended_heat_map","masked_image"],
["all","positive","positive"],
show_colorbar=True,
titles=["Original", "Positive Attribution", "Masked"],
fig_size=(18, 6))
Salida:
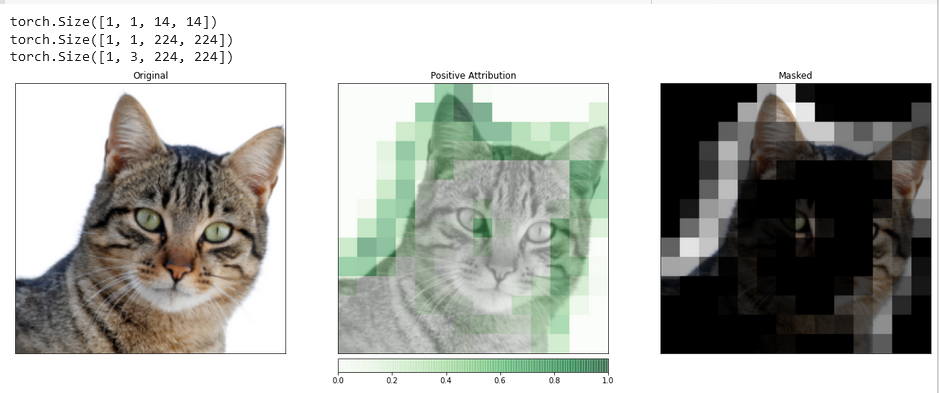
Visualizaciones como esta tienen el potencial de proporcionarte insights únicos en cómo responden tus capas ocultas a la entrada que proporciones.
Atribución de características con oclusiones
Los métodos basados en gradientes ayudan a entender el modelo en términos de calcular directamente los cambios en la salida con respecto a la entrada.
La técnica conocida como atribución basada en perturbaciones toma una aproximación más directa a este problema al hacer modificaciones a la entrada para cuantificar el impacto que tales cambios tienen en la salida. Una de estas estrategias se denomina occlusion.
Esto implica intercambiar partes de la imagen de entrada y analizar cómo este cambio afecta la señal producida en la salida.
A continuación, configuraremos la atribución de oclusiones. Al igual que la configuración de una red neuronal convolucional, puede elegir el tamaño de la región de destino y una separación (stride), que determine el espaciado de las mediciones individuales.
Usaremos la función visualize_image_attr_multiple() para ver los resultados de nuestra atribución de oclusiones. Esta función mostrará mapas de calor tanto de atribuciones positivas como negativas por región y cubrirá la imagen original con las regiones de atribución positiva.
La cubierta proporciona una visión muy iluminada de las regiones de nuestra foto de gato que el modelo identificó como más “gatuna”.
occlusion = Occlusion(model)
attributions_occ = occlusion.attribute(input,
target=pred_label_idx,
strides=(3, 8, 8),
sliding_window_shapes=(3,15, 15),
baselines=0)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_occ.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map", "heat_map", "masked_image"],
["all", "positive", "negative", "positive"],
show_colorbar=True,
titles=["Original", "Positive Attribution", "Negative Attribution", "Masked"],
fig_size=(18, 6)
)
Salida:
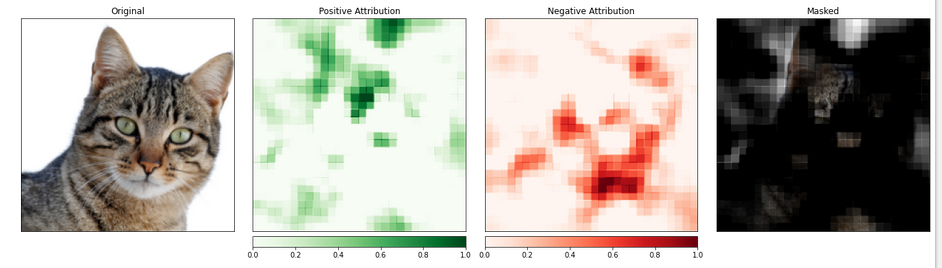
La porción de la imagen que contiene a la gata parece ser asignada un nivel de importancia superior.
Conclusión
Captum es una biblioteca de interpretabilidad de modelos para PyTorch que es versátil y simple. Ofrece técnicas de punta del arte para comprender cómo las neuronas y las capas específicas influyen en las predicciones.
Tiene tres tipos de técnicas de atribución principales: Técnicas de Atribución Primaria, Técnicas de Atribución de Capa y Técnicas de Atribución de Neurona.
Referencias
https://pytorch.org/tutorials/beginner/introyt/captumyt.html
https://gilberttanner.com/blog/interpreting-pytorch-models-with-captum/
https://arxiv.org/pdf/1805.12233.pdf
https://arxiv.org/pdf/1704.02685.pdf