













Optimierungsalgorithmen spielen eine entscheidende Rolle in der Deep Learning: Sie passen die Gewichte des Modells an, um Verlustfunktionen während der Trainingszeit zu minimieren. Ein solcher Algorithmus ist derAdam-Optimizer.
Adam wurde aufgrund seiner Fähigkeit, die Vorteile von Momentum und adaptiven Lernraten zu kombinieren, in der Deep Learning sehr beliebt. Dies machte ihn für die Ausbildung von tiefen neuronalen Netzen sehr effizient. Außerdem erfordert er eine minimalistische Justierung von Hyperparametern, was ihn breit zugänglich und effektiv für verschiedene Aufgaben macht.
Im Jahr 2017 präsentierten Ilya Loshchilov und Frank Hutter in ihrer Arbeit „Decoupled Weight Decay Regularization.“ eine fortschrittlichere Version des populären Adam-Algorithmus. Sie nannten diesen Algorithmus AdamW, der sich durch die Trennung des Weight Decay von der Gradienten-Update-Prozess auszeichnet. Diese Trennung ist eine entscheidende Verbesserung gegenüber dem Adam-Algorithmus und trägt zum besseren Allgemeinvermögen der Modelle bei.
AdamW hat in modernen Deep Learning-Anwendungen zunehmend an Bedeutung gewonnen, insbesondere bei der Behandlung von großskaligen Modellen. Seine überlegene Fähigkeit, Gewichtsaktualisierungen zu regulieren, hat zu seiner Verwendung in Aufgaben beigetragen, die hohe Leistung und Stabilität verlangen.
In diesem Tutorial werden wir die wichtigen Unterschiede zwischen Adam und AdamW und die verschiedenen Anwendungsfälle anschneiden und ein Schritt-für-Schritt-Leitfaden für die Implementierung von AdamW inPyTorch erarbeiten.
Adam vs AdamW
Adam und AdamW sind beide adaptive Optimizer, die in der tiefen Lernumgebung breit verwendet werden. Der größte Unterschied zwischen ihnen besteht darin, wie sie Gewichtsregularisierung behandeln, was ihre Effektivität in verschiedenen Situationen beeinflusst.
Während Adam Momentum und adaptives Lernrate kombiniert, um effiziente Optimierung anzubieten, integriert er die L2-Regularisierung auf eine Weise, die das Performance behindern kann. AdamW behandelt dies, indem er das Gewichtszersetzung von der Lernrate-Aktualisierung trennt, was eine effektivere Methode für große Modelle und eine Verbesserung der Allgemeinheit darstellt. Gewichtszersetzung, eine Form der L2-Regularisierung, bestraft große Gewichte im Modell. Adam integriert Gewichtszersetzung in den Gradienten-Aktualisierungsprozess ein, während AdamW sie separat nach der Gradienten-Aktualisierung anwendet
Hier sind einige andere Unterschiede:
Wesentliche Unterschiede zwischen Adam und AdamW
Obwohl beide Optimizer dafür konzipiert sind, Momentum zu verwalten und Lernraten dynamisch anzupassen, unterscheiden sie sich grundsätzlich in ihrer Behandlung von Gewichtskraftverlust (Weight Decay).
Bei Adam wird der Gewichtskraftverlust indirekt als Teil der Gradientenaktualisierung angewendet, was unabsichtlich die Lerndynamik verändern und das Optimierungsverfahren stören kann. AdamW jedoch trennt den Gewichtskraftverlust von der Gradientenbewegung, sodass die Regularisierung direkt die Parameter beeinflussen kann, ohne das adaptive Lernverfahren zu ändern.
Dieser Entwurf führt zu genauerer Regularisierung, wasModelle besserer Allgemeinheit besser helfen, insbesondere bei Aufgaben mit großen und komplexen Datensätzen. Daher haben diese beiden Optimizer oft sehr unterschiedliche Anwendungsfälle.
Anwendungsfälle für Adam
Adam zeigt bessere Leistung in Aufgaben, in denen Regularisierung weniger wichtig ist oder bei denen die Computations effizienz über Allgemeinheit priorisiert wird. Beispiele dafür sind:
- Kleinere neuronale Netze. Für Aufgaben wie grundlegende Bildklassifizierung mit kleinen CNNs (konvolutionale Neuronennetze) auf Datensets wie MNIST oder CIFAR-10, bei denen die Komplexität des Modells niedrig ist, kann Adam effizient optimiert werden, ohne umfassende Regularisierung zu benötigen.
- Einfache lineare Regressionsprobleme. In einfahrenden linearen Regressionsaufgaben mit begrenzten Merkmals集, wie z.B. dem Preis von Häusern zu prognostizieren, kann Adam schnell konvergieren, ohne fortschrittliche Regularisierungstechniken zu benötigen.
- Frühe Prototypenentwicklung. Während der frühen Stadien der Modellentwicklung, wo rasche Experimentierung erforderlich ist, ermöglicht Adam schnelle Iterationen an einfacheren Architekturen, was Forschern hilft, mögliche Probleme zu erkennen, ohne die Overhead von Regularisierungsparametertuning zu haben.
- Weniger ruckelnde Daten. Bei der Arbeit mit sauberen Datensätzen mit minimalem Rauschen, wie z.B. gut zusammengestellter Textdaten für die Sentimentanalyse, kann Adam effektiv Muster erkennen, ohne das Risiko eines Overfittings, das eine strengere Regularisierung erfordern könnte.
- Kurze Trainingsschleifen. In Szenarien mit zeitlichen Begrenzungen, wie z.B. der schnellen Modelldeployment für Echtzeitanwendungen, hilft Adams effiziente Optimierung, zufriedenstellende Ergebnisse schnell zu liefern, auch wenn sie nicht für die Allgemeingültigkeit optimiert sein mögen.
Anwendungsfälle für AdamW
AdamW ist in Szenarien hervorragend, in denen es um das Überfitten geht und die Modelgröße substanziell ist. Zum Beispiel:
- großskalige Transformer. In Aufgaben der natürlichen Sprachverarbeitung, wie der Feinabstimmung von Modellen wie GPT auf umfangreichen Textkorpora, besitzt AdamW die Fähigkeit, den Gewichtskontraktionsfaktor effizient zu verwalten, was die Überfittingvermeidung gewährleistet und bessere Generalisierung ermöglicht.
- komplexe Bildverarbeitungsmodelle. Für Aufgaben mit tiefen Konvolutionsneuronennetzen (CNNs), die auf großen Datensets wie ImageNet trainiert werden, hilft AdamW dem Modell Stabilität und Leistung zu erhalten, indem er den Gewichtskontraktionsfaktor entkoppelt, was für die Erreichung hoher Genauigkeit entscheidend ist.
- Multitask-Lernen. Im Fall, dass ein Modell gleichzeitig auf mehreren Aufgaben trainiert wird, bietet AdamW Flexibilität, um verschiedene Datensets zu behandeln und die Overfitting-Vermeidung auf einer einzigen Aufgabe zu verhindern.
- Generative Modelle. Bei der Ausbildung von generativen Adversarialen Netzen (GANs) ist es wichtig, dass der Generator und der Diskriminator ein Gleichgewicht halten. Die verbesserte Regularisierung von AdamW kann dabei helfen, den Trainingsprozess zu stabilisieren und die Qualität der generierten Ausgaben zu verbessern.
- Reinforcement Learning. In Anwendungen des reinforcement learning, wo Modelle komplexe Umgebungen anpassen und robuster Strategien lernen müssen, kann AdamW das Overfitting auf bestimmte Zustände oder Aktionen verringern, verbessernd somit die allgemeine Leistung des Modells in verschiedenen Situationen.
Vorteile von AdamW gegenüber Adam
Aber warum würde jemand AdamW statt Adam verwenden? Es ist einfach. AdamW bietet mehrere Schlüsselvorteile, die seine Leistung verbessern, insbesondere in komplexen Modellierungsfallen.
Es befasst sich mit einigen der Einschränkungen, die im Adam-Optimizer gefunden wurden, was ihn effektiver bei der Optimierung macht und zu verbesserten Modelltrainings und Robustheit beiträgt.
Hier sind einige hervorstechende Vorteile:
- Getrennte Gewichtskraft.Durch die Trennung der Gewichtskraft von Gradientenupdates ermöglicht AdamW eine präzisere Kontrolle über die Regularisierung, was zu besserer Modellallgemeinheit führt.
- Verbesserte Allgemeinheit. AdamW reduziert das Risiko von Überfitting, insbesondere in großskaligen Modellen, was es für Aufgaben mit umfangreichen Datenmengen und komplizierten Architekturen geeignet macht.
- Stabilität während der Trainingszeit. Die Design von AdamW hilft dabei, die Stabilität während des gesamten Trainingsprozesses zu erhalten, was für Modelle von größter Bedeutung ist, die eine sorgfältige Justierung ihrer Hyperparameter erfordern.
- Skalierbarkeit.AdamW ist besonders effektiv für die Skalierung von Modellen, da es die erhöhte Komplexität von tiefen Netzwerken ohne Leistungsverlust bewältigen kann und somit in modernen Architekturen angewendet werden kann.
Wie AdamW funktioniert
Der größte Vorteil von AdamW besteht in seinem Ansatz bezüglich des Gewichtskraftverlusts, der von den typisch adaptiven Gradienten-Updates von Adam getrennt ist. Diese Anpassung stellt sicher, dass die Regularisierung direkt auf die Gewichte des Modells angewendet wird, was die Generalisierung verbessert, ohne negative Auswirkungen auf die Dynamik der Lernrate zu haben.
Der Optimierer baut auf Adams anpassende Natur auf und hält die Vorteile von Momentum und per-Parameter-Lernrateanpassungen. Die unabhängige Anwendung von Gewichtskürzung beugt einem der Hauptmängel von Adam vor: seine Neigung, Gradientenupdates während der Regularisierung zu beeinflussen. Diese Trennung ermöglicht es AdamW, eine stabile Lernung zu unterhalten, selbst in komplexen und großskaligen Modellen, während das Überfitten in den Griff geholt wird.
In den folgenden Abschnitten werden wir die Theorie hinter Gewichtskürzung und Regularisierung sowie die Mathematik untersuchen, die die Optimierungsprozess von AdamW unterstützt.
Theorie hinter Gewichtskürzung und L2-Regularisierung
L2-Regularisierung ist eine Technik, die zur Verhinderung von Überfitting verwendet wird. Dies erreicht sie, indem sie eine Strafklausel zur Verlustfunktion hinzufügt und größere Gewichtswerte untersagt. Diese Technik hilft dabei, einfachere Modelle zu schaffen, die besser auf neue Daten generalisieren.
In traditionellen Optimierern wie z.B. Adam wird die Gewichtskontraktion als Teil des Gradientenupdates angewendet, was versehentlich die Lernraten beeinflussen kann und zu einer suboptimalen Leistung führen kann.
AdamW verbessert dies, indem die Gewichtskontraktion vom Gradientencomputationsprozess getrennt wird. Mit anderen Worten, anstatt die Gewichtskontraktion während des Gradientenupdates anzuwenden, behandelt AdamW dies als separate Schritte, indem es sie direkt auf die Gewichte angewendet wird, nach dem Gradientenupdate. Dies hält die Gewichtskontraktion davon ab, sich mit dem Optimierungsprozess zu beeinflussen, was zu einer stabileren Trainingszeit und besserer Generalisierung führt.
Mathematische Grundlage von AdamW
AdamW ändert die traditionellen Adam-Optimierer, indem er die Art und Weise ändert, wie die Gewichtskontraktion angewendet wird. Die grundlegenden Gleichungen für AdamW können wie folgt dargestellt werden:
- Momentum und adaptives Lernrate:Ähnlich wie bei Adam nutzt AdamW das Momentum und adaptive Lernraten, um Parameteraktualisierungen basierend auf den bewegten Durchschnitten von Gradienten und quadrierten Gradienten zu berechnen.
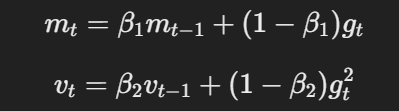
Gleichung für Momentum und adaptives Lernrate
- Korrigierte Schätzungen der Voreinstellungen:Der erste und zweite MomentSchätzungen werden mithilfe der folgenden Korrektur für Voreinstellungen korrigiert:
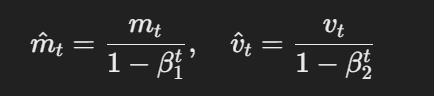
Formel für korrigierte Schätzungen der Voreinstellungen
- Parameterupdate mit abgekoppelter Gewichtskonstante:In AdamW wird die Gewichtskonstante direkt auf die Parameter angewendet, nachdem die Gradienten aktualisiert wurden. Der Update-Ausschlag lautet:
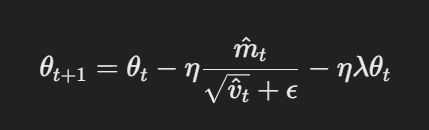
Parameterupdate mit abgekoppelter Gewichtskonstante
Hierbei ist η der Lernrate, λ die Gewichtskonstante und θt die Parameter. Dieser abgekoppelte Gewichtskonstante-Term λθt sichert eine Regularisierung, die unabhängig von der Gradienten-Aktualisierung angewendet wird, was die wichtigste Unterscheidung zu Adam darstellt.
Implementierung von AdamW in PyTorch
AdamW in PyTorch einzubinden ist einfach; dieser Abschnitt bietet einen umfassenden Leitfaden für die Einrichtung an. Folgen Sie diesen Schritten, um effizient mit dem Adam Optimizer Modelle zu finetunning.
Ein Schritt-für-Schritt-Leitfaden zu AdamW in PyTorch
Hinweis:Dieser Leitfaden geht davon aus, dass Sie bereits PyTorch installiert haben. Befolgen Sie die Dokumentation für weitere Hilfe.
Schritt 1:Importieren Sie die notwendigen Bibliotheken
import torch import torch.nn as nn import torch.optim as optim Import torch.nn.functional as F
Schritt 2: Definieren Sie das Modell
class SimpleCNN(nn.Module): def __init__(self): super(SimpleCNN, self).__init__() self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1) self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0) self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1) self.fc1 = nn.Linear(64 * 8 * 8, 128) self.fc2 = nn.Linear(128, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 64 * 8 * 8) x = F.relu(self.fc1(x)) x = self.fc2(x)
Schritt 3: Setzen Sie die Hyperparameter
learning_rate = 1e-4 weight_decay = 1e-2 num_epochs = 10 # Anzahl der Epochen
Schritt 4:Initialisieren Sie den AdamW Optimizer und richten Sie die Verlustfunktion ein
optimizer = optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=weight_decay) criterion = nn.CrossEntropyLoss()
Voila!
Nun sind Sie bereit, Ihren CNN-Modell zu starten, was wir im nächsten Abschnitt tun werden.
Praktisches Beispiel: Verfeinerung eines Modells mit AdamW
Oben haben wir das Modell definiert, die Hyperparameter eingestellt, den Optimizer (AdamW) initialisiert und die Verlustfunktion eingerichtet.
Um das Modell zu trainieren, müssen wir einige weitere Module importieren;
from torch.utils.data import DataLoader # stellt ein iterables der Datenbank dar import torchvision import torchvision.transforms as transforms
Danach definieren wir die Datenbank und die Datenloader. Für dieses Beispiel werden wir die CIFAR-10 Datenbank verwenden:
# Definition von Transformationen für das Trainingsset transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), ]) # Laden Sie das CIFAR-10-Datensatz train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) val_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform) # Erstellen Sie Daten-Loader train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)
Da wir unser Modell bereits definiert haben, ist der nächste Schritt die Implementierung des Trainingszyklus, um das Modell mit AdamW zu optimieren.
Hier ist wie es aussieht:
for epoch in range(num_epochs): model.train() # Setzen Sie das Modell auf Trainingsmodus running_loss = 0.0 for inputs, labels in train_loader: optimizer.zero_grad() # Löschen Sie die Gradienten outputs = model(inputs) # Forward-Durchlauf loss = criterion(outputs, labels) # Berechnen der Verlustfunktion loss.backward() # Rückwärtsdurchlauf optimizer.step() # Aktualisieren der Gewichte running_loss += loss.item() print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader):.4f}')
Der letzte Schritt besteht darin, die Leistung des Modells auf dem zuvor erstellten Validierungsdatensatz zu validieren.
Hier ist der Code:
model.eval() # Setze das Modell auf Evaluierungsmodus correct = 0 total = 0 with torch.no_grad(): for inputs, labels in val_loader: outputs = model(inputs) # Durchlaufen _, predicted = torch.max(outputs.data, 1) # Erhalte vorhergesagte Klasse total += labels.size(0) # Aktualisiere Gesamtsamples correct += (predicted == labels).sum().item() # Aktualisiere korrekte Voraussagen accuracy = 100 * correct / total print(f'Validation Accuracy: {accuracy:.2f}%')
Und so ist das.
Du kannst nun verstehen, wie AdamW in PyTorch implementiert wird.
Allgemeine Anwendungsfälle für AdamW
Na ja, wir haben festgestellt, dass AdamW Popularität erlangt hat, weil es einfacher eine effektivere Management von Gewichtskraft als seine Vorgänger, Adam, erledigt.
Aber welche Anwendungsfälle gibt es für diesen Optimierer?
Wir werden das in diesem Abschnitt erörtern…
Großskalige Deep Learning Modelle
AdamW ist besonders nützlich beim Training von Großmodellen wie BERT, GPT und anderen Transformer-Architekturen. solche Modelle haben typischerweise Millionen oder selbst Milliarden von Parametern, was oft dazu führt, dass effiziente Optimierungsmethoden benötigt werden, die komplexe Gewichtsaktualisierungen und allgemeine Herausforderungen der generalisierten Lernprozesse verarbeiten können.
Computer Visio und NLP-Aufgaben
AdamW hat sich zu dem bevorzugten Optimierer in Computer Visio-Aufgaben mit CNNs und NLP-Aufgaben mit Transformern entwickelt. Seine Fähigkeit, Overfitting zu vermeiden, macht ihn ideal für Aufgaben mit großen Datensets und komplexen Architekturen. Die Trennung von Gewichtskürzung bedeutet, dass AdamW die Probleme vermeidet, die Adam bei der Über-Regularisierung von Modellen erlebt hat.
Hyperparameter-Tuning in AdamW
Hyperparameter-Tuning ist der Prozess, den besten Werten für Parameter zu suchen, die das Training eines maschinellen Lernmodells steuern, aber nicht direkt aus den Daten selbst gelernt werden. Diese Parameter beeinflussen direkt, wie das Modell optimiert und angenommen wird.
Einrichtung dieser Hyperparameter in AdamW ist wichtig, um effizientes Training zu erreichen, Überfitting zu vermeiden und sicherzustellen, dass das Modell gut auf unbekannte Daten generalisiert.
In diesem Abschnitt werden wir erkunden, wie man die wichtigsten Hyperparameter von AdamW für optimale Leistung fein abstimmt.
Beste Praktiken für die Wahl der Lernraten und der Gewichtskürzung
Die Lernrate ist ein Hyperparameter, der bestimmt, wie stark die Modelleigenschaften bezüglich der Verlustkennung in jedem Trainingsschritt angepasst werden. Eine höhere Lernrate beschleunigt das Training, kann aber dazu führen, dass das Modell optimale Gewichte übersteigt, während eine niedrigere Rate zu präziseren Anpassungen zulässt, allerdings Training langsamer machen oder in lokale Minima hängen lassen kann.
Der Gewichtsabfall ist eine Regularisierungstechnik, die zur Verhinderung von Überfitting verwendet wird, indem große Gewichte im Modell bestraft wird. Insbesondere fügt der Gewichtsabfall während der Trainingsphase einen kleinen Strafbetrag hinzu, der proportional zur Größe der Gewichte des Modells ist, was dazu beiträgt, die Komplexität des Modells zu reduzieren und die Generalisierung auf neue Daten zu verbessern.
Um optimale Lernraten und Gewichtsabfall-Werte für AdamW zu wählen:
- Starten Sie mit einer mittleren Lernrate – Für AdamW ist eine Lernrate um 1e-3 oft ein gutes Startpunkt. Sie können sie ändern, basierend darauf, wie gut das Modell konvergiert, niedriger setzen, wenn das Modell zu nicht konvergieren scheint, oder höher setzen, wenn die Trainingseinheit zu langsam ist.
- Experimentiert mit Gewichtskürzung. Beginne mit einem Wert um 1e-2 bis 1e-4, je nach der Größe des Modells und dem Datensatz. Eine etwas höhere Gewichtskürzung kann bei größeren, komplexeren Modellen helfen, Overfitting zu vermeiden, während kleinere Modelle möglicherweise weniger Regularisierung brauchen.
- Verwende Lernrate-Scheduling.Implementiere Lernratescheduktionen (wie Schrittabbau oder cosinussches Annehlen), um die Lernrate während der Trainingseinheit dynamisch zu verringern, was dem Modell hilft, seine Parameter beim Annäherung an die Konvergenz besser zu justieren.
- Leistung Überwachen. Bitte beobachte die Leistung des Modells auf dem Validierungsdatensatz ununterbrochen. Wenn Overfitting beobachtet wird, erwäge eine Erhöhung der Gewichtskürzung, oder wenn die Trainingsverlustplatteierung auftritt, senke die Lernrate für eine bessere Optimierung.
Endliche Gedanken
AdamW hat sich als einer der effektivsten Optimizer in der Tiefeinheit herausgestellt, insbesondere für großskalige Modelle. Dies ist auf seine Fähigkeit zur Trennung von Gewichtskontraktion von Gradientenaktualisierungen zurückzuführen. Konkret verbessert die Design von AdamW die Regularisierung und hilft den Modellen bessere Generalisierung zu erreichen, insbesondere beim Umgang mit komplizierten Architekturen und umfangreichen Datensätzen.
Wie in diesem Lehrgang gezeigt, ist die Implementierung von AdamW in PyTorch einfach – es erfordert nur einige Anpassungen von Adam. Allerdings bleibt die Parametertuning ein entscheidender Schritt zur Maximierung der Effektivität von AdamW. Der richtige Gleichgewicht zwischen Lernrate und Gewichtskontraktion ist wichtig, um sicherzustellen, dass der Optimizer effizient arbeitet, ohne Overfitting oder Underfitting des Modells zu verursachen.
Nun kennen Sie genug, um AdamW in Ihren eigenen Modellen zu implementieren. Um Ihre Lernung fortzusetzen, schauen Sie sich einige dieser Ressourcen an:
Source:
https://www.datacamp.com/tutorial/adamw-optimizer-in-pytorch