













تلعب خوارزميات التحسين دور رئيسي في التعلم العميق: تنقيح وزنات النماذج لتحديد الوزن الخاطئ أقل مئة خطأ أثناء التدريب. واحد من هذه الخوارزميات هو محرك التحسين Adam.
أصبح Adam مشهورًا جدًا في التعلم العميق بسبب قدرته على تركيب مميزات المومنة ومعدلات التعلم التكافؤية. وهذا جعله فعالًا للغاية لتدريب شبكات الأعداد العميقة. ويتطلب أيضًا تنظيم قليل للمتغيرات الفرعية، مما جعله واسعًا النطاق وفعالًا للغاية في مختلف المهام.
في عام 2017، أعلنا إيليا لوشيلوف وفرانك هيتر نسخة أكثر تقدمًا لخوارزمية الأدم المشهورة في الوثيقة التي أعطوا لها ترجمة “تنظيم التناسب المفصل للتكافؤ الناجم عن التقليل الكهربائي.” أطلقوا عليها إسم AdamW، الذي يميز التنفيذ بإنفصال التقليل الكهربائي عن عملية تحديث المتوسط. هذا الفصل هو تحسين حاسم عن الأدم ويساعد على تعميم النموذج الأفضل.
أصبح أدم W أكثر أهمية في التطبيقات الحديثة للتعلم العميق بالخصوص في معالجة النماذج الكبيرة الحجم. قدرته الرائعة على تنظيم تحديث الوزنات سماه للاعتماد في المهام التي تتطلب الأداء العالي والاستقرار.
في هذا الدرس التعليمي، سنصلح على أحد الاختلافات الرئيسية بين Adam وAdamW والحالات المختلفة للاستخدام، وسنقوم بإيجاد درجة خطوات توجيهية لتنفيذ AdamW فيPyTorch.
Adam مقابل AdamW
أدم وأدمو كلاهما محاكين تكيفيون وهما يستخدمان بشكل واسع في التعلم العميق. يمكن أن يكون لهما اختلاف كبير في كيفية معالجة التنظيم الطبيعي للوزنات، وهذا يؤثر على فاعليتهم في مختلف الأحيان.
بينما يوحد أدم المومنة ومعدلات التعلم التكيفية لتوفير تنظيم فعال ، يشمل تنظيم L2 الطبيعي بطريقة قد تعقب الأداء. يتعامل أدمو بهذا بتفصيل التنزيل من الوزن الطبيعي عن تحديد المعدل التعلمي، مما يوفر طريقة أكثر فاعلية للأنماط الكبيرة وتحسين التعميم. التنزيل من نوع L2 الطبيعي يعامل عقوبة للوزنات الكبيرة في النموذج. يتضمن أدم التنزيل في عملية تحديد التنقلات، بينما يطبق أدمو ذلك بصورة منفصلة بعد تحديد التنقلات.
هنا بعض طرق اختلافاتهم الأخرى:
الاختلافات الرئيسية بين أدم وأدمو
بينما كلا المحاكاين الطريقة من التخطيط للتنمو وتكسير المعاملات الديناميكية، إلا أنهما يختلفان بشكل أساسي في معالجة التدخل الى الوزن.
في الأدم، يتم تطبيق التدخل بشكل غير مباشر كجزء من التحديث المتزايد للمتغيرات، وهو قد يغير الديناميكات التعلمية بشكل لا مقصود ويدخل في العملية التطبيقية. ومع ذلك، يقسم أدمو الى مجموعة من التدخل، مما يضمن تأثير التنظيم الى المتغيرات بشكل ديناميكي دون تغيير الآلية التكافؤية للتعلم.
هذا التصميم يوجه الى تنظيم أكثر دقة، مما يساعد النماذج على التعميم بشكل أفضل، وخاصة في المهام التي تتضمن قواعد كبيرة ومعقدة. ونتيجة لذلك، يمكن أن يكونا مع كلا المحاكاين الطريقة أساسيات مختلفة للاستخدام.
يعمل الأدم أفضل في المهام التي يتم التدخل فيها أقل أهمية أو عندما يتم توليد الكفاءة الكمputational أكثر أهمية من التعميم. مثالين على ذلك:
- الشبكات العصبية الأصغر. في مهام مثل تصنيف الصور الأساسية باستخدام شبكات CNN الصغيرة (الشبكات العصبية التلافيفية) على مجموعات بيانات مثل MNIST أو CIFAR-10، حيث تكون تعقيد النموذج منخفضًا، يمكن لآدم أن يعمل على التحسين بكفاءة دون الحاجة إلى تنظيم واسع.
- مشاكل الانحدار البسيطة. في مهام الانحدار البسيطة مع مجموعات مميزات محدودة، مثل توقع أسعار المنازل باستخدام نموذج الانحدار الخطي، يمكن لآدم أن يتقارب بسرعة دون الحاجة إلى تقنيات تنظيم متقدمة.
- التصميم الأولي للمراحل المبكرة. خلال المراحل الأولى من تطوير النموذج، حيث يتطلب الأمر تجربة سريعة، يسمح آدم بالتكرار السريع على البنيات الأبسط، مما يتيح للباحثين تحديد المشاكل المحتملة دون العبء الإضافي لضبط معلمات التنظيم.
- بيانات أقل ضوضاء. عند العمل مع مجموعات بيانات نظيفة بحد أدنى من الضوضاء، مثل بيانات النصوص الجيدة التنظيم لتحليل المشاعر، يمكن لآدم أن يتعلم الأنماط بفعالية دون مخاطر الإفراط في التحسين التي قد تتطلب تنظيمًا أكبر.
- دورات تدريب قصيرة. في السيناريوهات التي تتطلب قيود زمنية، مثل نشر النموذج السريع للتطبيقات الفورية، يمكن أن يساعد تحسين آدم الفعال في تقديم نتائج مقبولة بسرعة، حتى لو لم تكن تمامًا محسنة للتعميم.
حالات الاستخدام لآدم دبليو
تميز أدم واحد في الأحيان التي يشعر بالتعبير فوق التكرار والحجم الكبير للنموذج. على سبيل المثال:
- المحركات الكبيرة النموذجية. في المهام التي تتطلب المعالجة بالكلمات الطبيعية، مثل تعديل النماذج المثل GPT على مجموعات النصوص الكبيرة، قدرة أدم واحد على إدارة التندريد بشكل فعال تمنع التعبير فوق التكرار، مما يضمن تعميم أفضل.
- النماذج المعقدة للرؤية الحاسوبية. للمهام التي تشمل أنظمة الخوارزميات العميقة التعلمية (الشبكيات العميقة) المدربة على أعدادات كبيرة مثل ImageNet، يساعد أدم واحد على حفظ مستقرة وأداء النموذج من خلال تفصيل التندريد، وهذا مهم لإحقاق دقة عالية.
- تعلم المتعدد المهام. في محاور تدريب نموذج عن متعدد المهام معاً يوفر AdamW المرونة للتعامل مع أحجام البيانات المتنوعة ومنع التعقيد في أي مهمة واحدة.
- النماذج الإنتجية. لتدريب الشبكات التعاملية التعادية (GANs)، حيث يتم إبقاء توازن معين بين المولد والمُراقب، يمكن أن تساعد AdamW التطبيق المعيد بالتنظيم التي تساعد على تحسين جودة إنتاج البيانات المنتجة.
- التعلم التعاملي. في تطبيقات التعلم التعاملي التي يتوجب على النماذج أن تتكيف مع بيئات معقدة وتتعلم سياسات قوية، يساعد AdamW على تخفيض التعقيد في الوضعيات أو الأفعال بعدة، مما يحسن أداء النموذج في أوضاع مختلفة.
المزايا AdamW مقارنة بAdam
لكن لماذا يرغب أي شخص في استخدام AdamW بدلاً من Adam؟ بسيط. AdamW يوفر عدة مزايا رئيسية تمكنه من تحسين أداءه بشكل خاص في محاور التشكيل المعقدة.
يتناول بعض القيود التي يوجد في محرك الأدم، مما يجعله أكثر فاعلية في التحسين ويساهم في تحسين تدريب النماذج والمرونة.
وهذه بعض المزايا الرئيسية الأخرى:
- التفرقة بين التنديل الوزني.من خلال فصل التنديل الوزني عن التحديثات المتقدمة، يسمح لAdamW بالسيطرة الأكثر دقة على التنظيم، مما يوفر بشكل أفضل التعميم العام للنموذج.
- التعميم المميز. يخفض AdamW خطر تعصب المزيد، وخاصة في النماذج الكبيرة الحجم، مما يجعله مناسبًا للمهام التي تتطلب بases de datos وهيكلات معقدة.
- الاستقرار أثناء التمرين. تصميم AdamW يساعد في حفظ الاستقرار طوال عملية التمرين، وهذا أساسي للنماذج التي تتطلب تنظيم حساب خياراتها الرئيسية بشكل دقيق.
- التنمية القابلة للتكبير.AdamW فعال جدا لتكبير النماذج، لأنه يمكنه التعامل مع تعقيد أكبر للشبكات العميقة دون تضييع الأداء، مما يسمح له بتطبيقه في الأنماط الحديثة.
كيف تعمل AdamW
أقوى ما يمتلك AdamW هو مقاربته للتدخل المفروض على الوزن، وهو مجهول من خلال تحديد التدخل التفاضلي المتكامل للتحسينات التلقائية التي يمتلكها Adam. هذا التنظيم يضمن تطبيق التدخل المباشر على الوزنات النموذجية، مما يحسن التعميم بدون تأثير سلبي على توازن معدل التعلم.
يقوم المحسن بالإضافة إلى طبيعة متناغمة آدم، مما يحتفظ بمزايا المومنة وتنظيمات معدلات التعلم لكل مادة. تطبيق التنقل المستقل يواجه واحدا من الأخطاء الرئيسية لآدم: تendency إلى تأثير تحسينات المجاورة أثناء التنظيم. هذا الفصل يسمح لـ AdamW بالحفاظ على التعلم المستقر حتى في النماذج المعقدة والكبيرة الحجم، بينما يحمي من التعجيل بالفعل.
في الأقسام المقبلة، سنبحث في النظرية وراء التنقل المستقل والتنظيم والرياضيات التي تؤسس عملية تحسين AdamW.
نظرية خلفية التنقل المستقل والتنظيم L2
تنظيم L2 هو تقنية تستخدم لمنع التعجيل. يحقق هذا الهدف عن طريق إضافة عقبة جراءة إلى وظيفة الخسران، منعًا من أربع قيم كبيرة. تساعد هذه التقنية على خلق نماذج أبسط تعمل بشكل أفضل في إعادة البيانات الجديدة.
في محركات التحسين التقليدية، مثل Adam، يتم تطبيق التناقص الوزني كجزء من تحديد المسار، وهو يؤثر بشكل لا مقصدي على معدلات التعلم ويمكن أن يولد أداء تحت الأفضل.
AdamW يحسن هذا بعزل التناقص الوزني عن حساب المسار. بعبارة أخرى، بدلاً عن تطبيق التناقص الوزني خلال تحديد المسار، يتم تمريره في خطوة منفصلة، تطبيقه مباشر على الوزنات بعد التحديد المساري. هذا يمنع التناقص الوزني من التدخل في عملية التحسين، مما يؤدي إلى تدريب أكثر استقرارًا والعمل العام الأفضل.
البنية الرياضية لـ AdamW
يتم تغيير AdamW عن طريق تغيير كيفية تطبيق التناقص الوزني. يمكن تمثيل المعادلات القائمة عن AdamW بواسطة التالي:
- المومنة ومعدل التعلم التكيفي:مثلwise, AdamW يستخدم المومنة ومعدلات التعلم التكيفية لحساب تحديثات المادة بواسطة المعدلات التحركية للمسائل ومجموع المسائل التركيبية.
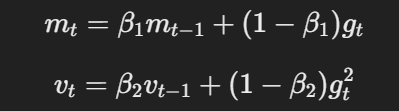
المعادلة للمومنة ومعدل التعلم التكيفي
- تقديرات مُتصحبة:تم تصحيح التقديرات الأولية والثانية المومنة من خلال استخدام التالي:
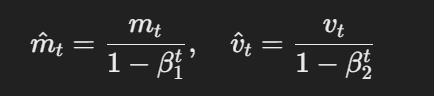
الصيغة لتقديرات مُتصحبة
- تحديث ما بعد الإزالة المنعزلة للتوزيع: في AdamW، يتم تطبيق التناسل الى المادات بعد تحديث المسار. تشمل القاعدة التحديثية:
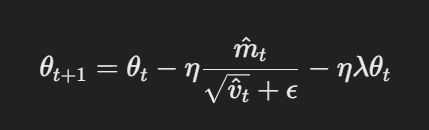
تحديث المادة مع الإزالة المنعزلة للتوزيع
هنا، يعني معدل التعلم ، و يعني معدل التناسل ، و تمثل تمثال المادات. يضمنا هذا العنصر المنعزل من التناسل للتوزيع للتنظيم الذي يتم بصفة مستقلة عن التحديث المساري ، وهذا هو الفرق الرئيسي مع Adam.
تطبيق AdamW في PyTorch
تنسيق AdamW في PyTorch هو بسيط; هذا القسم يوفر دراسة شاملة لتكوينه. اتبع هذه الخطوات لتعلم كيفية تنقيط النماذج بفعالية مع محرك التنسيق Adam.
دراسة خطوة بخطوة لـ AdamW في PyTorch
ملاحظة: يتم الاعتماد في هذا التورية على أنك قد تم تثبيت PyTorch بالفعل. انظر إلىالمساعدات لأي إشراف.
خطوة 1: استير أساسيات المكتبة المطلوبة
import torch import torch.nn as nn import torch.optim as optim Import torch.nn.functional as F
خطوة 2:تعريف النموذج
class SimpleCNN(nn.Module): def __init__(self): super(SimpleCNN, self).__init__() self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1) self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0) self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1) self.fc1 = nn.Linear(64 * 8 * 8, 128) self.fc2 = nn.Linear(128, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 64 * 8 * 8) x = F.relu(self.fc1(x)) x = self.fc2(x)
خطوة 3:ضبط المتغيرات العالية
learning_rate = 1e-4 weight_decay = 1e-2 num_epochs = 10 # عدد المرات التعميمية
خطوة 4:تكوين المحاكد الأدم وتأسيس المعامل الخاطئ
optimizer = optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=weight_decay) criterion = nn.CrossEntropyLoss()
ها هو!
الآن، أنت جاهز لبدء تدريب نموذجك التعلم التصادفي، وهذا ما سنفعله في القسم القادم.
مثال عملي: تنقيط نموذج باستخدام AdamW
في الأعلى، حددنا النموذج، وضعنا الخيارات الجيدة، أوليميزر (AdamW)، وConfigured the loss function.
لتدريب النموذج، سيتوجب علينا تحميل بعض المواد الأخرى؛
from torch.utils.data import DataLoader # يوفر متفاعلًا عن المجموعة البيانات. import torchvision import torchvision.transforms as transforms
ثم، قم بتعريف المجموعة ومعالجو البيانات. لهذا المثال، سنستخدم مجموعة CIFAR-10:
# تعريف التحويلات للمجموعة التدريبية transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), ]) # تحميل قاعدة البيانات CIFAR-10 train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) val_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform) # إنشاء محملين البيانات train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)
ولأننا قمنا بتعريف ما بالفعل لزيادة النموذج، الخطوة القادمة هي تنفيذ دور التدريب لتحسين النموذج باستخدام AdamW.
هذا ما يبدو عليه:
for epoch in range(num_epochs): model.train() # تعيين النموذج للوضع التدريبي running_loss = 0.0 for inputs, labels in train_loader: optimizer.zero_grad() # تمرير التدريبيات outputs = model(inputs) # المرور الأول loss = criterion(outputs, labels) # حساب الخسارة loss.backward() # المرور الخلفي optimizer.step() # تحديث الوزنات running_loss += loss.item() print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader):.4f}')
والخطوة الأخيرة هي تحقق أداء النموذج في قاعدة التحقق التي أنشأناها من قبل.
هذا هو الشيئ:
model.eval() # تعيين النموذج إلى وضعية التقييم correct = 0 total = 0 with torch.no_grad(): for inputs, labels in val_loader: outputs = model(inputs) # تلقي المرور الأول _, predicted = torch.max(outputs.data, 1) # حصد الفئة المتوقعة total += labels.size(0) # تحديث العينات الكلية correct += (predicted == labels).sum().item() # تحديث التخمينات الصحيحة accuracy = 100 * correct / total print(f'Validation Accuracy: {accuracy:.2f}%')
وها هو لديك بالفعل.
يمكنك أن تعرف الآن كيفية تطبيق AdamW في PyTorch.
الحالات الشائعة للموكد AdamW
حسنًا، لقد أبرزنا أن AdamW أخذ بعيدًا عن الوصول بسبب تحديده أكثر فاعلية لإدارة التخفيف من أساسها من موكد Adam.
ولكن ما هي بعض حالات الاستخدام الشائعة لهذا الموكد الموكد؟
سنناقش هذا الموضوع في هذا القسم…
نماذج التعلم العميق على نطاق كبير
AdamW مفيد بشكل خاص في تدريب النماذج الكبيرة مثل BERT و GPT والهياكل الأخرى للتحويلات. 이러한 النماذج عادة ما تحتوي على ملايين أو حتى مليارات من المعلمات، مما يعني أنها تتطلب خوارزميات تحسين كفية لتัดการ بالتحديثات المركبة للمعلمات والتحديات العامة.
مهام الرؤية الحاسوبية و NLP
أصبح AdamW الخيار المفضّل في مهام الرؤية الحاسوبية التي تتضمن الشبكات العصبية التلافيفية (CNNs) و مهام NLP التي تتضمن التحويلات. قدرته على منع التحسين الزائد يجعلها مثالية للمهام التي تتضمن مجموعات بيانات كبيرة وهياكل معقدة. الفصل بين انحدار الأوزان يعني أن AdamW يتجنب المشكلات التي يتعرض لها Adam في تنظيم النماذج بشكل مفرط.
ضبط المعلمات في AdamW
تنظيم المتغيرات الرئيسية هو عملية تحديد القيم الأفضل للمتغيرات التي تحكم تدريب نموذج ال leaning لكنها لا تتعلم من البيانات بحد ذاتها. تؤثر تلك المتغيرات مباشرة على كيفية تحسين والانتقال للنموذج.
تنظيم مناسب هذه المتغيرات الرئيسية في AdamW مهم للحصول على التدريب الكفيف، وتجنب التعقيد وضمان أن النموذج يعمل جيدًا على البيانات الغير مرادفة.
في هذا المجال سنستكشف كيفية تنظيم مناسب معيارات AdamW الرئيسية للأداء الأفضل.
أفضل الممارسات لتحديد المعدلات التعلمية والتنديد بالوزن
المعدل التعلمي هو متغير رئيسي ي控制在كل خطوة تدريبية كيف يتم تنظيم الوزنات المتعلقة بالخسائر والمساواة بينها. يجعل المعدل الكبير أسرع التدريب ولكن قد يسبب تعقيد النموذج أو يتجاوز الوزنات الأفضل المطلوبة، بينما يسمح معدل أقل بالتنظيم الدقيق أكثر ولكن قد يبطء التدريب أو يتثقف في أدنى محلي قليل.
والتدهور الوزني ، من جهة أخرى ، هو تقنية للتنظيم تستخدم لمنع التعقيد الزائد بتعقيد الوزنات الكبيرة في النموذج. بالمناسبة ، يضيف التدهور الوزني عقوبة صغيرة تتناسب مع حجم وزنات النموذج أثناء التدريب ، مساعدة على خفض تعقيد النموذج وتحسين التعميم على البيانات الجديدة.
لختار معدلات التعلم وقيم التدهور الأفضل لـ AdamW:
- بدء بمعدل تعلم معتدل – بالنسبة لـ AdamW ، قد يكون معدل تعلم حوالي 1e-3 منبعة جيدة للبدء. يمكنك تأسيسه بسبب كيفية تجميع النموذج ، تخفيضه إذا كان النموذج يحاول تجميع البيانات بصعوبة أو زيادته إذا كان التدريب بطء جداً.
- تجربة بتنديد الوزن. بدء بقيمة تقريبًا بين 1e-2 إلى 1e-4، وهي تdepend على حجم النموذج ومجموعة البيانات. قيمة التنديد الأعلى قليلًا قد تساعد في منع التقليد للنماذج الكبيرة والمعقدة، بينما قد تحتاج النماذج الصغيرة إلى تنديد أقل.
- استخدم برنامج تنظيم المعدل التعلمي. قم بتنفيذ برامج تنظيم المعدل (مثل التنديد الخط المنحنى أو التخفيف المتناول) لخفض المعدل التعلمي تلقائيًا وفقًا لما يتم التدريب والتحكم فيه حسنًا، مما يساعد النموذج على تنظيم ما يتمتع به من ما يزال قريبًا من التوافر.
- الرصد بشأن الأداء. تتبع دورة النموذج في المجموعة المعروفة بالتجريد دون توقف. إذا لاحظت عندما يكون هناك تقليد، تفكر في زيادة تنديد الوزن، أو إذا كان خسائر التدريب قد توقفت، قم بخفض معدل التعلم للحصول على تنظيم أفضل.
تفكير النهاية
أدمو5 أظهر كأحد أكثر المحاكين فعالية في التعلم العميق، خاصة للmodel الكبير للحجم. وهذا بسبب قدرته على تفريغ تلف وزن العمود عن التحديث المنحني. حسنًا، تصميم AdamW يحسن التنظيم ويساعد الmodel في التعميم بشكل أفضل، خاصة عندما يتعامل مع تنظيمات معقدة ومجموعات بيانات واسعة.
وكما أظهر في هذا التورية، تنسيق AdamW في PyTorch سهل — يتطلب فقط بعض التنقيحات القليلة من Adam. ومع ذلك، تنظيم المادات الفوقية ما يزال خطوة رئيسية لتحقيق أقصى فعالية لـ AdamW. وجديدًا ، إيجاد التوازن الصحيح بين معدل التعلم وتلف وزن العمود يتمنى لضمان أن يعمل المحاكين بفعالية جيدة بدون التعبير أو التحيز بالmodel.
والآن تعرف بما يكفي لتنفيذ AdamW في modelك. للمتابعة في تعلمك، أنظر إلى بعض هذه المصادر:
Source:
https://www.datacamp.com/tutorial/adamw-optimizer-in-pytorch