













介紹
YOLOv8由Ultralytics於2023年開發,成為YOLO系列中獨特的物體檢測演算法之一,相較於其前身如YOLOv5,在架構和性能上有顯著的提升。這些改進包括採用CSPNet作為主幹網路以便於更好的特徵提取,使用FPN+PAN作為頸部以改善多尺度物體檢測,以及轉向無錨點的方式。這些變化顯著提高了模型在實時物體檢測中的準確性、效率和可用性。
使用GPU搭配YOLOv8可以顯著提升物體檢測任務的性能,提供更快的訓練和推斷速度。本指南將指導您如何設置YOLOv8以便使用GPU,包括配置、故障排除和優化建議。
YOLOv8
YOLOv8 基於其前身,採用先進的神經網絡設計和訓練技術,以增強在物件檢測中的性能。它將物件定位和分類統一在一個高效的框架中,平衡速度和準確性。該架構包括三個關鍵組件:
- 主幹:高度優化的 CNN 主幹,可能基於 CSPDarknet,使用高效的層(如深度可分卷積)提取多尺度特徵,確保高性能並降低計算成本。
- 頸部:增強的 路徑聚合網絡(PANet) 用於精煉和整合多尺度特徵,以更好地檢測各種尺寸的物件。它針對效率和記憶體使用進行了優化。
- 頭部:無錨頭部預測邊界框、置信度分數和類別標籤,簡化了預測並提高了對不同物件形狀和尺度的適應性。
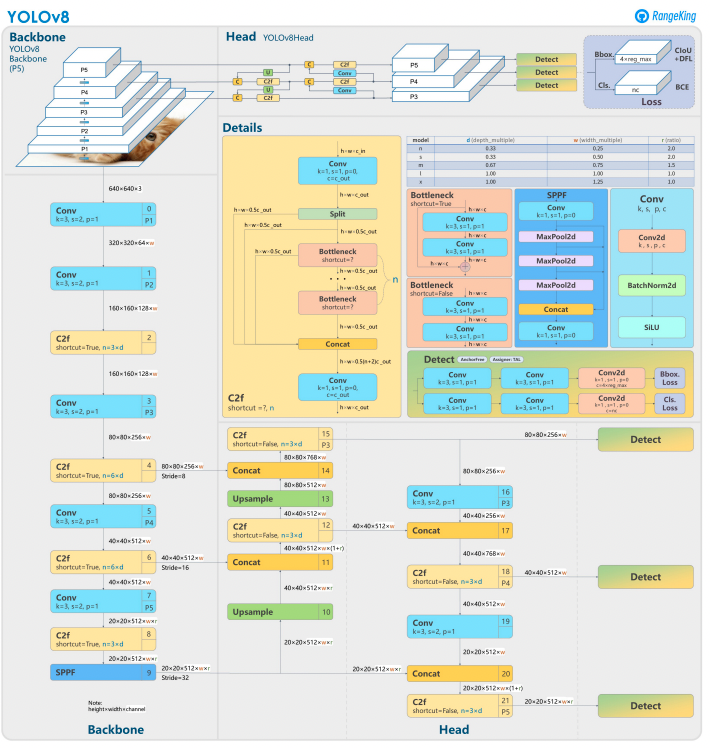
這些創新使 YOLOv8 在現代物件檢測任務中更快、更準確、更多功能。此外,YOLOv8 引入了一種基於無錨的邊界框預測方法,遠離了早期版本的基於錨點的方法。
為什麼在 YOLOv8 中使用 GPU?
YOLOv8(You Only Look Once,版本 8)是一個強大的物件檢測框架。雖然它可以在 CPU 上運行,但使用 GPU 會提供幾個主要優勢,例如:
- 速度:GPU 更有效地處理並行計算,從而減少訓練和推理時間。
- 可擴展性:GPU 可以管理更大的數據集和模型。
- 增強性能:實時物件檢測變得可行,實現自動駕駛車輛、監控和即時視頻處理等應用。

GPU 是實現更快結果和處理更複雜任務的明顯選擇,與 YOLOv8 一起使用。
CPU 與 GPU
在使用 YOLOv8 或任何物體檢測模型時,選擇 CPU 還是 GPU 會對模型的訓練和推理性能產生顯著影響。眾所周知,CPU 適合一般用途,能有效處理較小的任務。然而,當任務變得計算密集時,CPU 就無法應對。物體檢測等任務需要速度和並行計算,而 GPU 設計用於處理高性能的並行處理任務。因此,GPU 是運行像 YOLO 這樣的深度學習模型的理想選擇。例如,在 GPU 上的訓練和推理速度可以比在 CPU 上快 10–50 倍,具體取決於硬體和模型大小。
| Aspect | CPU | GPU |
|---|---|---|
| 推理時間(每張圖片) | 約 500 毫秒 | 約 15 毫秒 |
| 訓練速度(每小時的時期) | 約 2 個時期/小時 | 約 30 個時期/小時 |
| 批次大小能力 | 小(2-4 張圖片) | 大(16-32 張圖片) |
| 實時性能 | 否 | 是 |
| 並行處理 | 有限 | 優秀(數千個核心) |
| 能效 | 大型任務較低 | 並行工作負載較高 |
| 成本效益 | 適合小型任務 | 理想用於任何深度學習任務 |
在訓練過程中,差異變得更加明顯,GPU相比於CPU顯著縮短了訓練周期。這種速度提升使得GPU能夠更有效地處理更大的數據集並進行實時物體檢測。
使用GPU運行YOLOv8的前置條件
在配置YOLOv8以使用GPU之前,請確保滿足以下要求:
1. 硬體要求
- NVIDIA GPU:YOLOv8依賴CUDA進行GPU加速,因此您需要一個NVIDIA GPU,具備CUDA計算能力6.0或更高。
- 記憶體:對於中等大小的數據集,建議至少有8GB的GPU記憶體。對於更大的數據集,建議使用16GB或更多。
2. 軟體要求
- Python: 版本需為 3.8 或更新。
- PyTorch: 安裝時需支援 GPU(透過 CUDA)。最好使用 NVIDIA GPU。
- CUDA Toolkit 和 cuDNN: 確保與您的 PyTorch 版本相容。
- YOLOv8: 可從 Ultralytics 存儲庫安裝。
3. 驅動程式要求
- 從 NVIDIA 網站 下載並安裝最新的 NVIDIA 驅動程式。
- 安裝驅動程式後,使用
nvidia-smi檢查 GPU 的可用性。
配置 YOLOv8 以使用 GPU 的逐步指南
1. 安裝 NVIDIA 驅動程式
安裝 NVIDIA 驅動程式:
- 使用下面的程式碼識別您的 GPU:
- 訪問 NVIDIA 驅動程式下載頁面 並下載適當的驅動程式。
- 按照您操作系統的安裝說明進行安裝。
- 重新啟動您的電腦以應用更改。
- 通過運行以下命令來驗證安裝:
- 此命令顯示 GPU 資訊並確認驅動程式功能。
2. 安裝 CUDA 工具包和 cuDNN
要使用 YOLOv8,我們需要選擇適當的 PyTorch 版本,這又需要 CUDA 版本。
安裝 CUDA 工具包的步驟
- 從 NVIDIA 開發者網站 下載適當版本的 CUDA 工具包。
- 安裝 CUDA 工具包並設置環境變量(例如,
PATH、LD_LIBRARY_PATH)。 - 通過運行以下命令來驗證安裝:
確保您擁有最新版本的 CUDA 將使 PyTorch 能夠有效利用 GPU
安裝 cuDNN 的步驟
- 從NVIDIA開發人員網站下載cuDNN。
- 解壓縮內容並將其複製到相應的CUDA目錄(例如
bin、include、lib)。 - 確保cuDNN版本與您的CUDA安裝相符。
3. 安裝支援GPU的PyTorch
要安裝支援GPU的PyTorch,請訪問PyTorch入門頁面並選擇適當的安裝命令。例如:
4. 安裝並運行YOLOv8
按照以下步驟安裝YOLOv8:
- 安裝Ultralytics以使用yolov8並導入必要的庫
- Python腳本示例:
- 命令行範例:
5. 驗證YOLOv8中的GPU配置
使用以下Python命令檢查您的GPU是否被檢測到,並且CUDA是否已啟用:
6. 使用GPU進行訓練或推論
在您的訓練或推論命令中指定設備為cuda:
命令行範例
驗證自定義模型
Python腳本範例
為何選擇 DigitalOcean GPU Droplets?
DigitalOcean GPU droplets 被設計用來處理高性能的 AI 和機器學習任務。這些 GPU Droplets 由 H100 提供動力,能夠提供卓越的速度和並行處理能力,使其非常適合高效地訓練和運行 YOLOv8 模型。此外,這些 droplets 預先安裝有最新版本的 CUDA,確保您可以立即利用 GPU 加速,而無需花時間進行手動配置。這種精簡的環境使您可以完全專注於優化您的 YOLOv8 模型並輕鬆擴展您的項目。
常見問題的故障排除
1. YOLOv8 未使用 GPU
- 驗證 GPU 可用性使用
- 檢查 CUDA 和 PyTorch 的相容性。
- 確保在命令或腳本中指定
device=0或device='cuda'。 - 如有必要,更新 NVIDIA 驅動程式並重新安裝 CUDA 工具包。
2. CUDA 錯誤
- 確保 CUDA 工具包版本符合 PyTorch 的要求。
- 執行診斷腳本來驗證 cuDNN 安裝。
- 檢查 CUDA 的環境變數(
PATH和LD_LIBRARY_PATH)。
3. 性能緩慢
- 啟用混和精度訓練以優化內存使用和速度:
- 如果內存使用過高,請降低批次大小。
- 確保您有一個為運行並行處理優化的系統,並考慮在檢測腳本中使用批次處理以增強性能。
常見問題
如何為 YOLOv8 啟用 GPU?
在加載模型時,指定device='cuda'或device=0(如果使用第一個 GPU)在您的命令或腳本中。這將使 YOLOv8 能夠利用 GPU 進行推理和訓練期間更快的計算。請確保您的 GPU 已正確設置和檢測。
為什麼 YOLOv8 不使用我的 GPU?
如果硬件、驅動程序或設置存在問題,YOLOv8 可能不會使用 GPU。
首先,驗證 CUDA 安裝並與 PyTorch 兼容性。如有必要,請更新驅動程序。確保您的 CUDA 和 CuDNN 與您的 PyTorch 安裝兼容。
安裝 torchvision 並檢查正在安裝和使用的配置。
此外,如果 PyTorch 沒有安裝 GPU 支持(例如僅 CPU 版本),或者您的 YOLOv8 命令中的device參數可能沒有明確設置為cuda。在沒有 CUDA 兼容 GPU 或 VRAM 不足的系統上運行 YOLOv8 也會導致其默認使用 CPU。
為了解決這個問題,請確保您的GPU支援CUDA,驗證所有所需依賴項已安裝,檢查torch.cuda.is_available()是否返回True,並在您的YOLOv8腳本或命令中明確指定device='cuda'參數。
YOLOv8在GPU上的硬體需求是什麼?
為了有效地在GPU上安裝和運行YOLOVv8,建議使用Python 3.7或更高版本,並且需要一個支援CUDA的GPU來使用GPU加速。
建議使用具有至少8GB內存的現代NVIDIA GPU。對於大型數據集,更多內存是有益的。為了獲得最佳性能,建議使用Python 3.8或更新版本,PyTorch 1.10或更高版本,以及與CUDA 11.2+兼容的NVIDIA GPU。GPU應理想地至少具有8GB的VRAM,以有效處理中等數據集,儘管對於更大的數據集和複雜模型,更多的VRAM是有益的。此外,您的系統應至少具有8GB的RAM和50GB的可用磁盤空間來存儲數據集並促進模型訓練。確保這些硬體和軟體配置將幫助您實現更快的YOLOv8訓練和推斷,特別是對於計算密集型任務。
請注意:AMD GPU可能不支援CUDA,因此選擇一個與YOLOv8兼容的NVIDIA GPU是必要的。
YOLOv8能在多個GPU上運行嗎?
要使用多個GPU訓練YOLOv8,您可以使用PyTorch的DataParallel或直接指定多個設備(例如cuda:0,1)。對於分佈式訓練,YOLOv8默認使用PyTorch的Multi-GPU DistributedDataParallel(DDP)。確保您的系統有多個GPU可用,並在訓練腳本或命令行中指定要使用的GPU。例如,在CLI中設置--device 0,1,2,3或在Python中設置device=[0,1,2,3]以利用GPU 0、1、2和3。YOLOv8會自動跨指定的GPU進行並行訓練,無需額外的data_parallel參數。在訓練過程中會利用所有GPU,而驗證階段通常默認在單個GPU上運行,因為相對於訓練來說,它的資源消耗較少。
如何優化YOLOv8以在GPU上進行推論?
啟用混和精度並調整批量大小以平衡內存和速度。根據您的數據集,訓練YOLOv8需要相當多的計算能力才能有效運行。使用較小或量化的模型變體(例如YOLOv8n或INT8量化版本)來減少內存使用量和推斷時間。在推斷腳本中,將device參數明確設置為cuda以進行GPU執行。使用批處理等技術同時處理多張圖像並最大化GPU利用率。如適用,利用TensorRT進一步優化模型以實現更快的GPU推斷。定期監控GPU內存和性能,以確保有效使用資源。
以下代碼片段將允許您在定義的批量大小內並行處理圖像。
如果使用CLI,請使用-b或–batch-size來指定批量大小。使用Python時,在初始化模型或調用預測方法時,確保正確設置批量參數。
如何解決CUDA內存不足問題?
為了解決CUDA內存不足的錯誤,您可以在YOLOv8配置文件中減少驗證批次大小,因為較小的批次需要較少的GPU內存。此外,如果您可以訪問多個GPU,考慮使用PyTorch的DistributedDataParallel或類似功能將驗證工作負載分佈在它們之間,但這需要對PyTorch有進階了解。您也可以在腳本中使用torch.cuda.empty_cache()清除緩存內存,並確保GPU上沒有運行不必要的進程。升級到具有更多VRAM的GPU或優化模型和數據集以提高內存效率是緩解此類問題的進一步步驟。
結論
配置YOLOv8以利用GPU是一個簡單的過程,可以顯著提高性能。通過遵循本詳細指南,您可以加快對象檢測任務的訓練和推斷速度。優化您的設置,解決常見問題,並利用GPU加速發揮YOLOv8的全部潛力。
參考資料
Source:
https://www.digitalocean.com/community/tutorials/yolov8-for-gpu-accelerate-object-detection