













Introduction
YOLOv8, développé par Ultralytics en 2023, s’est imposé comme l’un des algorithmes de détection d’objets uniques de la série YOLO et présente des améliorations architecturales et de performances significatives par rapport à ses prédécesseurs, tels que YOLOv5. Ces améliorations comprennent un réseau CSPNet pour une meilleure extraction des caractéristiques, un cou et un cou FPN+PAN pour une meilleure détection multi-échelle des objets, et un passage à une approche sans ancrage. Ces changements améliorent significativement la précision, l’efficacité et la facilité d’utilisation du modèle pour la détection d’objets en temps réel.
Utiliser un GPU avec YOLOv8 peut considérablement améliorer les performances pour les tâches de détection d’objets, offrant une formation et une inférence plus rapides. Ce guide vous guidera dans la configuration de YOLOv8 pour une utilisation avec un GPU, y compris la configuration, le dépannage et des astuces d’optimisation.
YOLOv8
YOLOv8 s’appuie sur ses prédécesseurs avec des techniques avancées de conception et d’entraînement de réseaux neuronaux pour améliorer les performances en détection d’objets. Il unifie la localisation et la classification d’objets dans un cadre unique et efficace, équilibrant vitesse et précision. L’architecture comprend trois composants clés :
- Backbone : Un Backbone CNN hautement optimisé, potentiellement basé sur CSPDarknet, extrait des caractéristiques multi-échelles en utilisant des couches efficaces comme des convolutions séparables en profondeur, garantissant des performances élevées avec un minimum de charge computationnelle.
- Neck : Un réseau d’agrégation de chemins amélioré (PANet) affine et intègre des caractéristiques multi-échelles pour mieux détecter les objets de tailles variées. Il est optimisé pour l’efficacité et l’utilisation de la mémoire.
- Head : La tête sans ancre prédit les boîtes englobantes, les scores de confiance et les étiquettes de classe, simplifiant les prédictions et améliorant l’adaptabilité aux formes et échelles d’objets diverses.
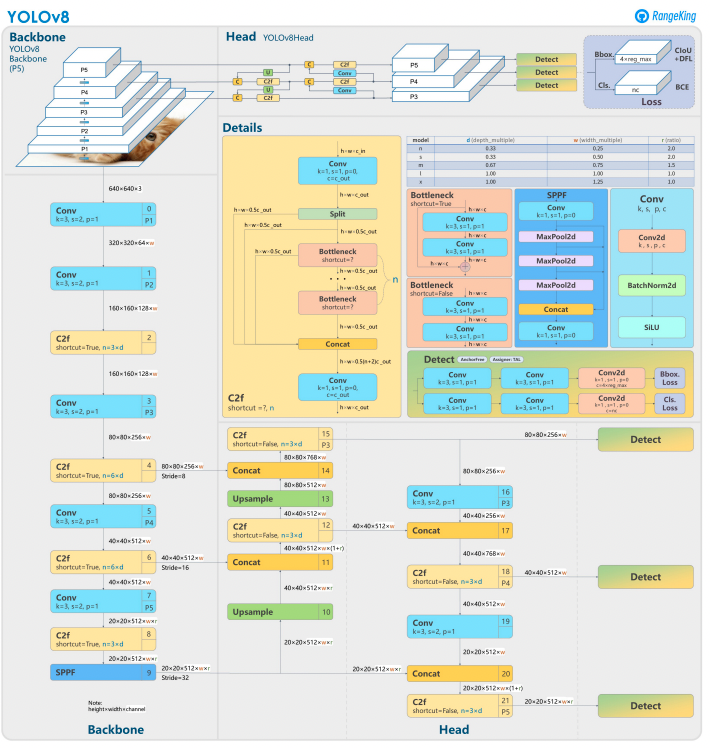
Ces innovations rendent YOLOv8 plus rapide, plus précis et plus polyvalent pour les tâches modernes de détection d’objets. De plus, YOLOv8 introduit une approche sans ancre pour la prédiction des boîtes englobantes, s’éloignant des méthodes basées sur des ancres des versions précédentes.
Pourquoi utiliser un GPU avec YOLOv8?
YOLOv8 (You Only Look Once, Version 8) est un puissant framework de détection d’objets. Bien qu’il fonctionne sur les CPU, l’utilisation d’un GPU offre quelques avantages clés, tels que :
- Vitesse : Les GPUs gèrent les calculs parallèles de manière plus efficace, réduisant les temps d’entraînement et d’inférence.
- Scalabilité : Les ensembles de données et les modèles plus grands sont gérables avec les GPUs.
- Performances améliorées : La détection d’objets en temps réel devient réalisable, permettant des applications telles que les véhicules autonomes, la surveillance et le traitement vidéo en direct.

Les GPUs sont le choix évident pour obtenir des résultats plus rapides et gérer des tâches plus complexes avec YOLOv8.
Comparaison CPU vs GPU
En travaillant avec YOLOv8 ou tout autre modèle de détection d’objets, le choix entre CPU et GPU peut avoir un impact significatif sur les performances du modèle pour l’entraînement et l’inférence. Les processeurs, comme nous le savons, sont excellents pour les tâches générales et peuvent gérer efficacement des tâches plus petites. Cependant, les processeurs échouent lorsque la tâche devient computationnellement coûteuse. Des tâches telles que la détection d’objets nécessitent rapidité et calcul parallèle, et les GPU sont conçus pour gérer des tâches de traitement parallèle à haute performance. Par conséquent, ils sont idéaux pour exécuter des modèles d’apprentissage profond comme YOLO. Par exemple, l’entraînement et l’inférence sur un GPU peuvent être 10 à 50 fois plus rapides que sur un CPU, en fonction du matériel et de la taille du modèle.
| Aspect | CPU | GPU |
|---|---|---|
| Temps d’inférence (par image) | ~500 ms | ~15 ms |
| Vitesse d’entraînement (epochs/heure) | ~2 epochs/heure | ~30 epochs/heure |
| Capacité de taille de lot | Petite (2-4 images) | Grande (16-32 images) |
| Performances en temps réel | Non | Oui |
| Traitement parallèle | Limité | Excellent (milliers de cœurs) |
| Efficacité énergétique | Moins pour les tâches importantes | Plus élevée pour les charges de travail parallèles |
| Efficacité en termes de coûts | Adapté pour les petites tâches | Idéal pour toutes les tâches d’apprentissage profond |
La différence devient encore plus prononcée pendant l’entraînement, où les GPU raccourcissent considérablement les époques par rapport aux CPU. Cet accélération de vitesse permet aux GPU de traiter des ensembles de données plus importants et d’effectuer une détection d’objets en temps réel de manière plus efficace.
Prérequis pour utiliser YOLOv8 avec un GPU
Avant de configurer YOLOv8 pour le GPU, assurez-vous de remplir les conditions suivantes :
1. Exigences matérielles
- GPU NVIDIA: YOLOv8 dépend de CUDA pour l’accélération GPU, donc vous aurez besoin d’un GPU NVIDIA avec une Capacité de Calcul CUDA de 6.0 ou supérieure.
- Mémoire: Au moins 8 Go de mémoire GPU sont recommandés pour des ensembles de données modérés. Pour des ensembles de données plus importants, 16 Go ou plus sont préférables.
2. Exigences logicielles
- Python: Version 3.8 ou ultérieure.
- PyTorch: Installé avec le support GPU (via CUDA). De préférence, GPU NVIDIA.
- Boîte à outils CUDA et cuDNN: Assurez-vous qu’ils sont compatibles avec votre version de PyTorch.
- YOLOv8: Installable depuis le référentiel Ultralytics.
3. Exigences du pilote
- Téléchargez et installez les derniers pilotes NVIDIA depuis le site web de NVIDIA.
- Vérifiez la disponibilité de votre GPU en utilisant
nvidia-smiaprès l’installation du pilote.
Guide étape par étape pour configurer YOLOv8 pour GPU
1. Installer les pilotes NVIDIA
Pour installer les pilotes NVIDIA :
- Identifiez votre GPU en utilisant le code ci-dessous :
- Visitez la page de téléchargement des pilotes NVIDIA Drivers et téléchargez le pilote approprié.
- Suivez les instructions d’installation pour votre système d’exploitation.
- Redémarrez votre ordinateur pour appliquer les changements.
- Vérifiez l’installation en exécutant :
- Cette commande affiche les informations sur le GPU et confirme le bon fonctionnement du pilote.
2. Installer CUDA Toolkit et cuDNN
Pour utiliser YOLOv8, nous devons sélectionner la version appropriée de PyTorch, ce qui nécessite à son tour une version de CUDA.
Étapes pour installer CUDA Toolkit
- Téléchargez la version appropriée du CUDA Toolkit sur le site des développeurs NVIDIA.
- Installez CUDA Toolkit et configurez les variables d’environnement (par exemple,
PATH,LD_LIBRARY_PATH). - Vérifiez l’installation en exécutant :
Assurez-vous d’avoir la dernière version de CUDA pour permettre à PyTorch d’utiliser efficacement le GPU
Étapes pour installer cuDNN
- Téléchargez cuDNN depuis le site des développeurs de NVIDIA.
- Extrayez le contenu et copiez-le dans les répertoires CUDA correspondants (par exemple,
bin,include,lib). - Assurez-vous que la version de cuDNN correspond à votre installation CUDA.
3. Installer PyTorch avec le support GPU
Pour installer PyTorch avec le support GPU, visitez la page de démarrage de PyTorch et sélectionnez la commande d’installation appropriée. Par exemple:
4. Installer et exécuter YOLOv8
Installez YOLOv8 en suivant ces étapes:
- Installez Ultralytics pour travailler avec yolov8 et importez les bibliothèques nécessaires
- Exemple de script Python:
- Exemple pour la ligne de commande :
5. Vérifier la configuration du GPU dans YOLOv8
Utilisez la commande Python suivante pour vérifier si votre GPU est détecté et si CUDA est activé :
6. Entraîner ou effectuer une inférence avec le GPU
Spécifiez le périphérique comme cuda dans vos commandes d’entraînement ou d’inférence :
Exemple de ligne de commande
Valider le modèle personnalisé
Exemple de script Python
Pourquoi choisir les Droplets GPU DigitalOcean ?
Les droplets GPU DigitalOcean sont conçus pour gérer des tâches d’IA et de machine learning haute performance. Les GPU H100 alimentent ces Droplets GPU pour offrir une vitesse exceptionnelle et des capacités de traitement parallèle, les rendant idéaux pour l’entraînement et l’exécution efficace des modèles YOLOv8. De plus, ces droplets sont préinstallés avec la dernière version de CUDA, garantissant que vous pouvez commencer à tirer parti de l’accélération GPU sans passer de temps sur des configurations manuelles. Cet environnement rationalisé vous permet de vous concentrer entièrement sur l’optimisation de vos modèles YOLOv8 et de faire évoluer vos projets sans effort.
Résolution des problèmes courants
1. YOLOv8 n’utilise pas le GPU
- Vérifiez la disponibilité du GPU en utilisant
- Vérifiez la compatibilité de CUDA et PyTorch.
- Assurez-vous de spécifier
device=0oudevice='cuda'dans les commandes ou scripts. - Mettez à jour les pilotes NVIDIA et réinstallez le kit d’outils CUDA si nécessaire.
2. Erreurs CUDA
- Assurez-vous que la version du kit d’outils CUDA correspond aux exigences de PyTorch.
- Vérifiez l’installation de cuDNN en exécutant des scripts de diagnostic.
- Vérifiez les variables d’environnement pour CUDA (
PATHetLD_LIBRARY_PATH).
3. Performances lentes
- Activez l’entraînement en précision mixte pour optimiser l’utilisation de la mémoire et la vitesse:
- Réduisez la taille du lot si l’utilisation de la mémoire est trop élevée.
- Assurez-vous d’avoir un système optimisé pour exécuter le traitement parallèle, et envisagez d’utiliser le traitement par lot dans votre script de détection pour améliorer les performances.
Questions fréquemment posées
Comment activer le GPU pour YOLOv8 ?
Spécifiez device='cuda' ou device=0 (si vous utilisez le premier GPU) dans vos commandes ou scripts lors du chargement du modèle. Cela permettra à YOLOv8 d’utiliser le GPU pour une computation plus rapide lors de l’inférence et de l’entraînement. Assurez-vous que votre GPU est correctement configuré et détecté.
Pourquoi YOLOv8 n’utilise-t-il pas mon GPU ?
YOLOv8 pourrait ne pas utiliser le GPU s’il y a des problèmes avec le matériel, les pilotes ou la configuration.
Pour commencer, vérifiez l’installation de CUDA et sa compatibilité avec PyTorch. Mettez à jour les pilotes si nécessaire. Assurez-vous que votre CUDA et CuDNN sont compatibles avec votre installation de PyTorch.
Installez torchvision et vérifiez la configuration qui est installée et utilisée.
De plus, si PyTorch n’est pas installé avec le support du GPU (par exemple, une version uniquement pour CPU), ou si le paramètre device dans vos commandes YOLOv8 n’est pas explicitement défini sur cuda, cela peut également provoquer le passage en mode CPU. L’exécution de YOLOv8 sur un système sans GPU compatible CUDA ou avec une VRAM insuffisante peut également le faire passer en mode CPU.
Pour résoudre ce problème, assurez-vous que votre GPU est compatible avec CUDA, vérifiez l’installation de toutes les dépendances requises, vérifiez que torch.cuda.is_available() renvoie True, et spécifiez explicitement le paramètre device='cuda' dans vos scripts ou commandes YOLOv8.
Quels sont les exigences matérielles pour YOLOv8 sur GPU ?
Pour installer et exécuter efficacement YOLOv8 sur un GPU, Python 3.7 ou une version ultérieure est recommandé, et un GPU compatible avec CUDA est requis pour utiliser l’accélération GPU.
Un GPU NVIDIA moderne avec au moins 8 Go de mémoire est recommandé. Pour de grands ensembles de données, plus de mémoire est bénéfique. Pour des performances optimales, il est recommandé d’utiliser Python 3.8 ou une version plus récente, PyTorch 1.10 ou une version supérieure, et un GPU NVIDIA compatible avec CUDA 11.2+. Le GPU devrait idéalement avoir au moins 8 Go de VRAM pour gérer efficacement des ensembles de données modérés, bien que plus de VRAM soit bénéfique pour des ensembles de données plus importants et des modèles complexes. De plus, votre système devrait avoir au moins 8 Go de RAM et 50 Go d’espace disque libre pour stocker des ensembles de données et faciliter l’entraînement des modèles. En garantissant ces configurations matérielles et logicielles, vous pourrez obtenir une formation et une inférence plus rapides avec YOLOv8, notamment pour les tâches intensives en calcul.
Veuillez noter : les GPU AMD peuvent ne pas prendre en charge CUDA, il est donc essentiel de choisir un GPU NVIDIA pour la compatibilité avec YOLOv8.
Est-ce que YOLOv8 peut fonctionner sur plusieurs GPU ?
Pour entraîner YOLOv8 en utilisant plusieurs GPU, vous pouvez utiliser DataParallel de PyTorch ou spécifier directement plusieurs appareils (par exemple, cuda:0,1). Pour l’entraînement distribué, YOLOv8 utilise par défaut le DistributedDataParallel (DDP) de PyTorch. Assurez-vous que votre système dispose de plusieurs GPU disponibles et spécifiez les GPU que vous souhaitez utiliser dans le script d’entraînement ou en ligne de commande. Par exemple, définissez --device 0,1,2,3 dans l’interface en ligne de commande ou device=[0,1,2,3] en Python pour utiliser les GPU 0, 1, 2 et 3. YOLOv8 gère automatiquement l’entraînement parallèle sur les GPU spécifiés sans nécessiter un argument data_parallel explicite. Bien que tous les GPU soient utilisés pendant l’entraînement, la phase de validation s’exécute généralement sur un seul GPU par défaut, car elle est moins intensive en ressources que l’entraînement.
Comment puis-je optimiser YOLOv8 pour l’inférence sur GPU ?
Activer la précision mixte et ajuster les tailles de lots pour équilibrer la mémoire et la vitesse. Selon votre jeu de données, l’entraînement de YOLOv8 nécessite une quantité importante de puissance de calcul pour s’exécuter efficacement. Utilisez une variante de modèle plus petite ou quantifiée (par exemple YOLOv8n ou des versions quantifiées INT8) pour réduire l’utilisation de mémoire et le temps d’inférence. Dans votre script d’inférence, définissez explicitement le paramètre device sur cuda pour l’exécution GPU. Utilisez des techniques telles que l’inférence par lots pour traiter plusieurs images simultanément et maximiser l’utilisation du GPU. Si applicable, utilisez TensorRT pour optimiser davantage le modèle afin d’accélérer l’inférence GPU. Surveillez régulièrement la mémoire GPU et les performances pour garantir une utilisation efficace des ressources.
Le fragment de code ci-dessous vous permettra de traiter les images en parallèle dans la taille de lot définie.
Si vous utilisez l’interface en ligne de commande, spécifiez la taille du lot avec -b ou –batch-size. En Python, assurez-vous que l’argument de lot est correctement défini lors de l’initialisation de votre modèle ou lors de l’appel de la méthode de prédiction.
Comment résoudre les problèmes de mémoire épuisée CUDA ?
Pour résoudre les erreurs de mémoire épuisée de CUDA, réduisez la taille du lot de validation dans votre fichier de configuration YOLOv8, car des lots plus petits nécessitent moins de mémoire GPU. De plus, si vous avez accès à plusieurs GPU, envisagez de répartir la charge de travail de validation entre eux en utilisant DistributedDataParallel de PyTorch ou une fonctionnalité similaire, bien que cela nécessite une connaissance avancée de PyTorch. Vous pouvez également essayer de vider la mémoire mise en cache en utilisant torch.cuda.empty_cache() dans votre script et vous assurer qu’aucun processus inutile ne s’exécute sur votre GPU. La mise à niveau vers un GPU avec plus de VRAM ou l’optimisation de votre modèle et de votre jeu de données pour une efficacité mémoire sont d’autres étapes pour atténuer de tels problèmes.
Conclusion
Configurer YOLOv8 pour utiliser un GPU est un processus simple qui peut considérablement améliorer les performances. En suivant ce guide détaillé, vous pouvez accélérer l’entraînement et l’inférence pour vos tâches de détection d’objets. Optimisez votre configuration, résolvez les problèmes courants et libérez tout le potentiel de YOLOv8 avec l’accélération GPU.
Références
Source:
https://www.digitalocean.com/community/tutorials/yolov8-for-gpu-accelerate-object-detection