













Inleiding
YOLOv8, ontwikkeld door Ultralytics in 2023, is naar voren gekomen als een van de unieke objectdetectiealgoritmes in de YOLO-serie en wordt geleverd met aanzienlijke architecturale en prestatieverbeteringen ten opzichte van zijn voorgangers, zoals YOLOv5. Deze verbeteringen omvatten een CSPNet-backbone voor betere functie-extractie, een FPN+PAN-nek voor verbeterde multi-schaal objectdetectie, en een verschuiving naar een aanker-vrije aanpak. Deze veranderingen verbeteren aanzienlijk de nauwkeurigheid, efficiëntie en bruikbaarheid van het model voor real-time objectdetectie.
Door een GPU te gebruiken met YOLOv8 kan de prestatie voor objectdetectietaken aanzienlijk worden verbeterd, met snellere training en inferentie. Deze handleiding zal je begeleiden bij het instellen van YOLOv8 voor GPU-gebruik, inclusief configuratie, probleemoplossing en optimalisatietips.
YOLOv8
YOLOv8 bouwt voort op zijn voorgangers met geavanceerd ontwerp van neurale netwerken en trainings technieken om de prestaties in objectdetectie te verbeteren. Het verenigt objectlokalisatie en classificatie in een enkel, efficiënt framework, waarbij snelheid en nauwkeurigheid in balans zijn. De architectuur bestaat uit drie belangrijke componenten:
- Ruggengraat: Een zeer geoptimaliseerde CNN-ruggengraat, mogelijk gebaseerd op CSPDarknet, haalt multi-schaal eigenschappen op met behulp van efficiënte lagen zoals dieptescheidende convoluties, waardoor hoge prestaties worden gegarandeerd met minimale computationele overhead.
- Hals: Een verbeterd Path Aggregation Network (PANet) verfijnt en integreert multi-schaal eigenschappen om objecten van verschillende groottes beter te detecteren. Het is geoptimaliseerd voor efficiëntie en geheugenverbruik.
- Hoofd: Het ankerloze hoofd voorspelt begrenzingskaders, betrouwbaarheidsscores en klassenlabels, waardoor voorspellingen worden vereenvoudigd en de aanpasbaarheid aan diverse objectvormen en schalen wordt verbeterd.
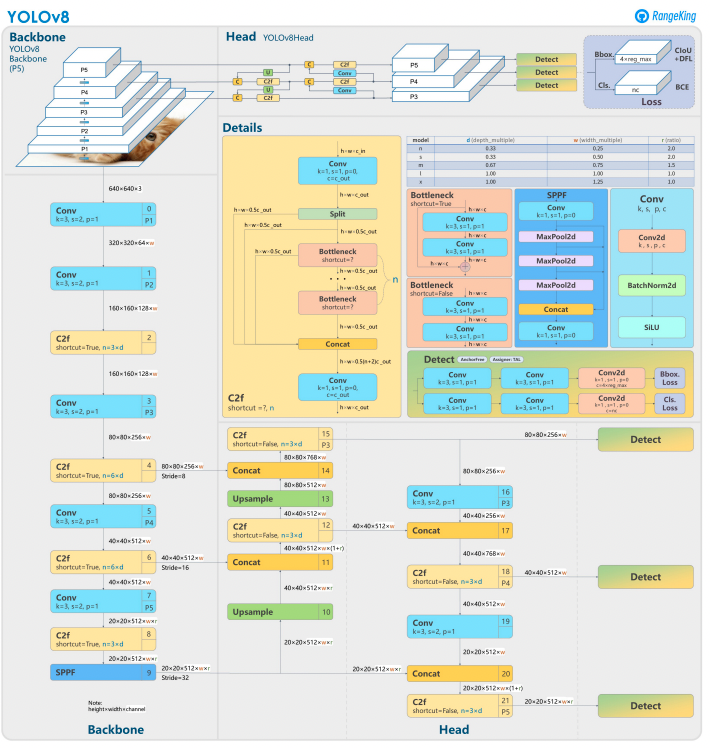
Deze innovaties maken YOLOv8 sneller, nauwkeuriger en veelzijdiger voor moderne objectdetectietaken. Bovendien introduceert YOLOv8 een ankerloze benadering voor het voorspellen van begrenzingskaders, waarbij wordt afgestapt van de ankergebaseerde methoden van eerdere versies.
Waarom een GPU gebruiken met YOLOv8?
YOLOv8 (You Only Look Once, Versie 8) is een krachtig raamwerk voor objectdetectie. Hoewel het op CPU’s draait, biedt het gebruik van een GPU enkele belangrijke voordelen, zoals:
- Snelheid: GPU’s verwerken parallelle berekeningen efficiënter, waardoor training- en inferentietijden worden verkort.
- Schaalbaarheid: Grotere datasets en modellen zijn beheersbaar met GPU’s.
- Verbeterde Prestaties: Real-time objectdetectie wordt haalbaar, waardoor toepassingen zoals autonome voertuigen, bewaking en live videobewerking mogelijk zijn.

GPU’s zijn de duidelijke keuze voor het behalen van snellere resultaten en het verwerken van complexere taken met YOLOv8.
CPU vs. GPU
Bij het werken met YOLOv8 of elk ander objectdetectiemodel kan de keuze tussen CPU en GPU aanzienlijke invloed hebben op de prestaties van het model voor zowel training als inferentie. CPU’s zijn geweldig voor algemene doeleinden en kunnen efficiënt omgaan met kleinere taken. CPU’s schieten echter tekort wanneer de taak rekenintensief wordt. Taken zoals objectdetectie vereisen snelheid en parallelle berekening, en GPU’s zijn ontworpen om taken met hoge prestaties en parallelle verwerking aan te kunnen. Daarom zijn ze ideaal voor het draaien van diepe leermmodellen zoals YOLO. Bijvoorbeeld, training en inferentie op een GPU kunnen 10-50 keer sneller zijn dan op een CPU, afhankelijk van de hardware en de modelgrootte.
| Aspect | CPU | GPU |
|---|---|---|
| Inferentietijd (per afbeelding) | ~500 ms | ~15 ms |
| Trainingsnelheid (epochs/uur) | ~2 epochs/uur | ~30 epochs/uur |
| Batchgroottecapaciteit | Klein (2-4 afbeeldingen) | Groot (16-32 afbeeldingen) |
| Real-time prestaties | Nee | Ja |
| Parallelle verwerking | Beperkt | Uitstekend (duizenden cores) |
| Energie-efficiëntie | Lager voor grote taken | Hoger voor parallelle workloads |
| Kostenefficiëntie | Geschikt voor kleine taken | Ideaal voor elke deep learning-taak |
Het verschil wordt nog duidelijker tijdens de training, waar GPU’s de epochs dramatisch verkorten in vergelijking met CPU’s. Deze snelheidstoename stelt GPU’s in staat om grotere datasets te verwerken en real-time objectdetectie efficiënter uit te voeren.
Vereisten voor het gebruik van YOLOv8 met GPU
Voordat je YOLOv8 voor GPU configureert, zorg ervoor dat je aan de volgende vereisten voldoet:
1. Hardwarevereisten
- NVIDIA GPU: YOLOv8 is afhankelijk van CUDA voor GPU-versnelling, dus je hebt een NVIDIA GPU met een CUDA Compute Capability van 6.0 of hoger nodig.
- Geheugen: Minimaal 8GB GPU-geheugen wordt aanbevolen voor gematigde datasets. Voor grotere datasets is 16GB of meer gewenst.
2. Softwarevereisten
- Python: Versie 3.8 of later.
- PyTorch: Geïnstalleerd met GPU-ondersteuning (via CUDA). Bij voorkeur NVIDIA GPU.
- CUDA Toolkit en cuDNN: Zorg ervoor dat deze compatibel zijn met jouw PyTorch-versie.
- YOLOv8: Installeerbaar vanuit het Ultralytics repository.
3. Driver Vereisten
- Download en installeer de laatste NVIDIA drivers van de NVIDIA website.
- Controleer de beschikbaarheid van je GPU met
nvidia-smina de installatie van de driver.
Stapsgewijze Handleiding voor het Configureren van YOLOv8 voor GPU
1. Installeer NVIDIA Drivers
Om NVIDIA drivers te installeren:
- Identificeer jouw GPU met de onderstaande code:
- Bezoek de NVIDIA Drivers Download pagina en download de juiste driver.
- Volg de installatie-instructies voor jouw besturingssysteem.
- Herstart je computer om de wijzigingen toe te passen.
- Verifieer de installatie door uit te voeren:
- Dit commando toont GPU-informatie en bevestigt de functionaliteit van de driver.
2. Installeer CUDA Toolkit en cuDNN
Om YOLOv8 te gebruiken, moeten we de juiste versie van PyTorch selecteren, wat op zijn beurt een CUDA-versie vereist.
Stappen om CUDA Toolkit te installeren
- Download de juiste versie van de CUDA Toolkit van de NVIDIA Developer site.
- Installeer de CUDA Toolkit en stel omgevingsvariabelen in (bijv.
PATH,LD_LIBRARY_PATH). - Verifieer de installatie door uit te voeren:
Zorg ervoor dat je de nieuwste versie van CUDA hebt, zodat PyTorch de GPU effectief kan gebruiken
Stappen om cuDNN te installeren
- Download cuDNN van de NVIDIA Developer site.
- Pak de inhoud uit en kopieer deze naar de bijbehorende CUDA-directories (bijv.
bin,include,lib). - Zorg ervoor dat de cuDNN-versie overeenkomt met uw CUDA-installatie.
3. Installeer PyTorch met GPU-ondersteuning
Om PyTorch met GPU-ondersteuning te installeren, bezoek de PyTorch Startpagina en selecteer de juiste installatieopdracht. Bijvoorbeeld:
4. Installeer en voer YOLOv8 uit
Installeer YOLOv8 door deze stappen te volgen:
- Installeer Ultralytics om met yolov8 te werken en importeer de noodzakelijke bibliotheken
- Voorbeeld voor Python-script:
- Voorbeeld voor Command Line:
5. Verifieer GPU-configuratie in YOLOv8
Gebruik de volgende Python-opdracht om te controleren of uw GPU wordt gedetecteerd en CUDA is ingeschakeld:
6. Trainen of Infereren met GPU
Specificeer het apparaat als cuda in uw trainings- of inferentieopdrachten:
Command-Line Voorbeeld
Valideer het aangepaste model
Python Script Voorbeeld
Waarom DigitalOcean GPU-droplets?
DigitalOcean GPU-droplets zijn ontworpen om high-performance AI- en machine learning-taken aan te kunnen. H100s voorzien deze GPU-droplets van uitzonderlijke snelheid en parallelle verwerkingsmogelijkheden, waardoor ze ideaal zijn voor efficiënte training en uitvoering van YOLOv8-modellen. Bovendien zijn deze droplets vooraf geïnstalleerd met de nieuwste versie van CUDA, zodat je meteen gebruik kunt maken van GPU-versnelling zonder tijd te verspillen aan handmatige configuraties. Deze gestroomlijnde omgeving stelt je in staat om je volledig te richten op het optimaliseren van je YOLOv8-modellen en het moeiteloos schalen van je projecten.
Veelvoorkomende problemen oplossen
1. YOLOv8 Gebruikt Geen GPU
- Controleer de beschikbaarheid van de GPU met
- Controleer CUDA- en PyTorch-compatibiliteit.
- Zorg ervoor dat je
device=0ofdevice='cuda'specificeert in commando’s of scripts. - Update NVIDIA-stuurprogramma’s en installeer indien nodig de CUDA Toolkit opnieuw.
2. CUDA-fouten
- Zorg ervoor dat de versie van de CUDA Toolkit overeenkomt met de vereisten van PyTorch.
- Controleer de installatie van cuDNN door diagnostische scripts uit te voeren.
- Controleer de omgevingsvariabelen voor CUDA (
PATHenLD_LIBRARY_PATH).
3. Trage prestaties
- Activeer training in gemengde precisie om geheugengebruik en snelheid te optimaliseren:
- Verlaag de batchgrootte als het geheugengebruik te hoog is.
- Zorg ervoor dat je een geoptimaliseerd systeem hebt voor het uitvoeren van parallelle verwerking, en overweeg batchverwerking te gebruiken in je detectiescript om de prestaties te verbeteren.
Veelgestelde vragen
Hoe activeer ik de GPU voor YOLOv8?
Specificeer device='cuda' of device=0 (indien de eerste GPU wordt gebruikt) in uw commando’s of scripts bij het laden van het model. Hiermee wordt YOLOv8 in staat gesteld om de GPU te gebruiken voor snellere berekeningen tijdens inferentie en training. Zorg ervoor dat uw GPU correct is ingesteld en gedetecteerd.
Waarom gebruikt YOLOv8 mijn GPU niet?
YOLOv8 gebruikt mogelijk de GPU niet als er problemen zijn met de hardware, drivers of de configuratie.
Controleer eerst de installatie van CUDA en de compatibiliteit met PyTorch. Werk de drivers indien nodig bij. Zorg ervoor dat uw CUDA en CuDNN compatibel zijn met uw PyTorch-installatie.
Installeer torchvision en controleer de configuratie die wordt geïnstalleerd en gebruikt.
Bovendien kan YOLOv8 de GPU niet gebruiken als PyTorch niet is geïnstalleerd met GPU-ondersteuning (bijv. een versie alleen voor CPU), of als de device-parameter in uw YOLOv8-commando’s mogelijk niet expliciet is ingesteld op cuda. Het uitvoeren van YOLOv8 op een systeem zonder een CUDA-compatibele GPU of met onvoldoende VRAM kan er ook toe leiden dat het standaard naar de CPU wordt omgeleid.
Om dit op te lossen, zorg ervoor dat uw GPU CUDA-compatibel is, controleer de installatie van alle vereiste afhankelijkheden, controleer of torch.cuda.is_available() True retourneert, en specificeer expliciet de parameter device='cuda' in uw YOLOv8-scripts of commando’s.
Wat zijn de hardwarevereisten voor YOLOv8 op GPU?
Om YOLOVv8 effectief te installeren en uit te voeren op een GPU, wordt Python 3.7 of hoger aanbevolen en is een CUDA-compatibele GPU vereist voor GPU-versnelling.
Er wordt een moderne NVIDIA GPU met minimaal 8GB geheugen aanbevolen. Voor grote datasets is meer geheugen gunstig. Voor optimale prestaties wordt aanbevolen om Python 3.8 of nieuwer, PyTorch 1.10 of hoger, en een NVIDIA GPU compatibel met CUDA 11.2+ te gebruiken. De GPU moet idealiter minimaal 8GB VRAM hebben om efficiënt met gemiddelde datasets om te kunnen gaan, hoewel meer VRAM gunstig is voor grotere datasets en complexe modellen. Bovendien moet uw systeem minimaal 8GB RAM en 50GB vrije schijfruimte hebben om datasets op te slaan en modeltraining te vergemakkelijken. Door deze hardware- en softwareconfiguraties te verzekeren, kunt u snellere training en inferentie met YOLOv8 bereiken, vooral voor rekenintensieve taken.
Let op: AMD GPU’s ondersteunen mogelijk geen CUDA, dus het kiezen van een NVIDIA GPU voor YOLOv8-compatibiliteit is essentieel.
Kan YOLOv8 op meerdere GPU’s draaien?
Om YOLOv8 te trainen met meerdere GPU’s, kun je PyTorch’s DataParallel gebruiken of meerdere apparaten direct specificeren (bijv. cuda:0,1). Voor gedistribueerde training gebruikt YOLOv8 standaard PyTorch’s Multi-GPU DistributedDataParallel (DDP). Zorg ervoor dat je systeem over meerdere GPU’s beschikt en geef de GPU’s op die je wilt gebruiken in het trainingsscript of de opdrachtregel. Stel bijvoorbeeld --device 0,1,2,3 in de CLI of device=[0,1,2,3] in Python in om GPU’s 0, 1, 2 en 3 te gebruiken. YOLOv8 beheert automatisch de parallelle training over de opgegeven GPU’s zonder dat een expliciete data_parallel parameter nodig is. Terwijl alle GPU’s tijdens de training worden gebruikt, draait de validatiefase doorgaans standaard op een enkele GPU, omdat deze minder middelen vereist dan training.
Hoe optimaliseer ik YOLOv8 voor inferentie op GPU?
Schakel gemengde precisie in en pas batchgroottes aan om geheugen en snelheid in balans te brengen. Afhankelijk van uw dataset vereist het trainen van YOLOv8 nogal wat rekenkracht om efficiënt te kunnen draaien. Gebruik een kleiner of gekwantiseerd modelvariant (bijv. YOLOv8n of gekwantiseerde versies met INT8) om geheugengebruik en inferentietijd te verminderen. Stel in uw inferentiescript expliciet de parameter device in op cuda voor GPU-uitvoering. Gebruik technieken zoals batchinferentie om meerdere afbeeldingen tegelijk te verwerken en GPU-gebruik te maximaliseren. Indien van toepassing, maak gebruik van TensorRT om het model verder te optimaliseren voor snellere GPU-inferentie. Controleer regelmatig de GPU-geheugen en prestaties om efficiënt gebruik van resources te waarborgen.
De onderstaande codefragment zal u in staat stellen om afbeeldingen parallel te verwerken binnen de gedefinieerde batchgrootte.
Indien u de CLI gebruikt, geef de batchgrootte op met -b of –batch-grootte. Met Python, zorg ervoor dat het batchargument correct is ingesteld bij het initialiseren van uw model of bij het oproepen van de voorspellingsmethode.
Hoe los ik CUDA Out-of-memory problemen op?
Om CUDA out-of-memory fouten op te lossen, verlaag de validatie batchgrootte in je YOLOv8 configuratiebestand, aangezien kleinere batches minder GPU-geheugen vereisen. Daarnaast, als je toegang hebt tot meerdere GPU’s, overweeg dan om de validatiewerklast over hen te verdelen met behulp van PyTorch’s DistributedDataParallel of een vergelijkbare functionaliteit, hoewel dit geavanceerde kennis van PyTorch vereist. Je kunt ook proberen om gecachte geheugen te wissen met torch.cuda.empty_cache() in je script en ervoor zorgen dat er geen onnodige processen op je GPU draaien. Het upgraden naar een GPU met meer VRAM of het optimaliseren van je model en dataset voor geheugenefficiëntie zijn verdere stappen om dergelijke problemen te verminderen.
Conclusie
Het configureren van YOLOv8 om een GPU te gebruiken is een eenvoudig proces dat de prestaties aanzienlijk kan verbeteren. Door deze gedetailleerde handleiding te volgen, kun je training en inferentie versnellen voor je objectherkenningstaken. Optimaliseer je setup, los veelvoorkomende problemen op en ontgrendel het volledige potentieel van YOLOv8 met GPU-versnelling.
Referenties
Source:
https://www.digitalocean.com/community/tutorials/yolov8-for-gpu-accelerate-object-detection