













Introducción
YOLOv8, desarrollado por Ultralytics en 2023, ha emergido como uno de los algoritmos de detección de objetos únicos en la serie YOLO y viene con mejoras arquitectónicas y de rendimiento significativas en comparación con sus predecesores, como YOLOv5. Estas mejoras incluyen un backbone CSPNet para una mejor extracción de características, un cuello FPN+PAN para una detección de objetos multiescala mejorada y un cambio hacia un enfoque sin anclas. Estos cambios mejoran significativamente la precisión, eficiencia y usabilidad del modelo para la detección de objetos en tiempo real.
Usar una GPU con YOLOv8 puede aumentar significativamente el rendimiento para tareas de detección de objetos, proporcionando un entrenamiento y una inferencia más rápidos. Esta guía te guiará a través de la configuración de YOLOv8 para el uso de GPU, incluyendo configuración, solución de problemas y consejos de optimización.
YOLOv8
YOLOv8 se basa en sus predecesores con un diseño de red neuronal avanzado y técnicas de entrenamiento para mejorar el rendimiento en detección de objetos. Unifica la localización y clasificación de objetos en un solo marco eficiente, equilibrando velocidad y precisión. La arquitectura se compone de tres componentes clave:
- Backbone: Un backbone CNN altamente optimizado, potencialmente basado en CSPDarknet, extrae características a múltiples escalas utilizando capas eficientes como convoluciones separables por profundidad, asegurando un alto rendimiento con un mínimo coste computacional.
- Neck: Una Red de Agregación de Rutas (PANet) mejorada refina e integra características a múltiples escalas para detectar mejor objetos de diferentes tamaños. Está optimizada para la eficiencia y el uso de memoria.
- Head: La cabeza sin anclas predice cajas delimitadoras, puntajes de confianza y etiquetas de clase, simplificando las predicciones y mejorando la adaptabilidad a diversas formas y escalas de objetos.
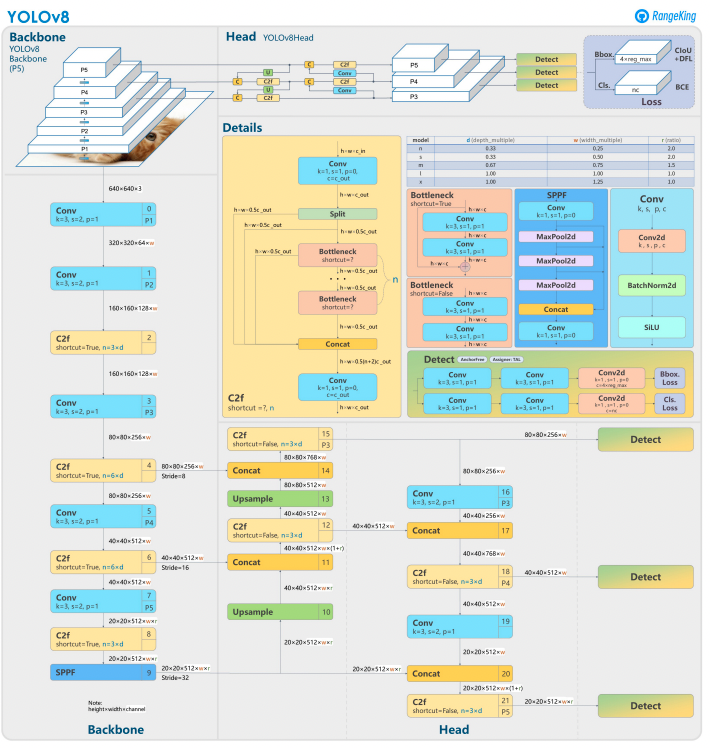
Estas innovaciones hacen que YOLOv8 sea más rápido, más preciso y versátil para tareas modernas de detección de objetos. Además, YOLOv8 introduce un enfoque sin anclas para la predicción de cajas delimitadoras, alejándose de los métodos basados en anclas de versiones anteriores.
¿Por qué usar una GPU con YOLOv8?
YOLOv8 (You Only Look Once, Versión 8) es un potente marco de detección de objetos. Aunque se ejecuta en CPUs, utilizar una GPU ofrece algunos beneficios clave, tales como:
- Velocidad: Las GPUs manejan cálculos paralelos de manera más eficiente, reduciendo los tiempos de entrenamiento e inferencia.
- Escalabilidad: Con las GPUs, se pueden gestionar conjuntos de datos y modelos más grandes.
- Rendimiento Mejorado: La detección de objetos en tiempo real se vuelve factible, habilitando aplicaciones como vehículos autónomos, vigilancia y procesamiento de video en vivo.

Las GPUs son la elección clara para lograr resultados más rápidos y manejar tareas más complejas con YOLOv8.
CPU vs. GPU
Mientras trabajas con YOLOv8 o cualquier modelo de detección de objetos, la elección entre CPU y GPU puede impactar significativamente el rendimiento del modelo tanto en entrenamiento como en inferencia. Las CPU, como sabemos, son excelentes para propósitos generales y pueden manejar tareas más pequeñas de manera eficiente. Sin embargo, las CPU fallan cuando la tarea se vuelve computacionalmente cara. Tareas como la detección de objetos requieren velocidad y computación paralela, y las GPU están diseñadas para manejar tareas de procesamiento paralelo de alto rendimiento. Por lo tanto, son ideales para ejecutar modelos de aprendizaje profundo como YOLO. Por ejemplo, el entrenamiento y la inferencia en una GPU pueden ser 10–50 veces más rápidos que en una CPU, dependiendo del hardware y el tamaño del modelo.
| Aspect | CPU | GPU |
|---|---|---|
| Tiempo de Inferencia (por imagen) | ~500 ms | ~15 ms |
| Velocidad de Entrenamiento (épocas/hora) | ~2 épocas/hora | ~30 épocas/hora |
| Tamaño de Lote Capacidad | Pequeño (2-4 imágenes) | Grande (16-32 imágenes) |
| Rendimiento en Tiempo Real | No | Sí |
| Procesamiento Paralelo | Limitado | Excelente (miles de núcleos) |
| Eficiencia Energética | Menor para tareas grandes | Mayor para cargas de trabajo paralelas |
| Eficiencia de Costos | Adecuado para tareas pequeñas | Ideal para cualquier tarea de aprendizaje profundo |
La diferencia se vuelve aún más pronunciada durante el entrenamiento, donde las GPU acortan drásticamente las épocas en comparación con las CPU. Este aumento de velocidad permite que las GPU procesen conjuntos de datos más grandes y realicen detección de objetos en tiempo real de manera más eficiente.
Requisitos para usar YOLOv8 con GPU
Antes de configurar YOLOv8 para GPU, asegúrate de cumplir con los siguientes requisitos:
1. Requisitos de hardware
- GPU NVIDIA: YOLOv8 depende de CUDA para la aceleración de GPU, por lo que necesitarás una GPU NVIDIA con una Capacidad de Cómputo CUDA de 6.0 o superior.
- Memoria: Se recomienda al menos 8GB de memoria de GPU para conjuntos de datos moderados. Para conjuntos de datos más grandes, se prefieren 16GB o más.
2. Requisitos de software
- Python: Versión 3.8 o posterior.
- PyTorch: Instalado con soporte para GPU (a través de CUDA). Preferiblemente GPU NVIDIA.
- CUDA Toolkit y cuDNN: Asegúrate de que sean compatibles con tu versión de PyTorch.
- YOLOv8: Instalado desde el repositorio de Ultralytics.
3. Requisitos de Controlador
- Descarga e instala los últimos controladores de NVIDIA desde el sitio web de NVIDIA.
- Verifica la disponibilidad de tu GPU usando
nvidia-smidespués de la instalación del controlador.
Guía Paso a Paso para Configurar YOLOv8 para GPU
1. Instalar Controladores de NVIDIA
Para instalar los controladores de NVIDIA:
- Identifica tu GPU usando el siguiente código:
- Visita la página de descarga de controladores de NVIDIA y descarga el controlador correspondiente.
- Sigue las instrucciones de instalación para tu sistema operativo.
- Reinicia tu computadora para aplicar los cambios.
- Verifica la instalación ejecutando:
- Este comando muestra información de la GPU y confirma la funcionalidad del controlador.
2. Instalar CUDA Toolkit y cuDNN
Para usar YOLOv8, necesitamos seleccionar la versión adecuada de PyTorch, que a su vez requiere la versión de CUDA.
Pasos para instalar CUDA Toolkit
- Descarga la versión adecuada del CUDA Toolkit desde el sitio de desarrolladores de NVIDIA.
- Instala el CUDA Toolkit y configura las variables de entorno (por ejemplo,
PATH,LD_LIBRARY_PATH). - Verifica la instalación ejecutando:
Asegurarte de tener la última versión de CUDA permitirá que PyTorch utilice la GPU de manera efectiva
Pasos para instalar cuDNN
- Descarga cuDNN desde el sitio de desarrolladores de NVIDIA.
- Extrae el contenido y cópialo en los directorios correspondientes de CUDA (por ejemplo,
bin,include,lib). - Asegúrate de que la versión de cuDNN coincida con tu instalación de CUDA.
3. Instala PyTorch con soporte para GPU
Para instalar PyTorch con soporte para GPU, visita la página de inicio de PyTorch y selecciona el comando de instalación apropiado. Por ejemplo:
4. Instala y ejecuta YOLOv8
Instala YOLOv8 siguiendo estos pasos:
- Instala Ultralytics para trabajar con yolov8 e importa las bibliotecas necesarias
- Ejemplo para Script de Python:
- Ejemplo para la línea de comandos:
5. Verifica la configuración de GPU en YOLOv8
Utiliza el siguiente comando de Python para verificar si tu GPU es detectada y si CUDA está habilitado:
6. Entrena o realiza inferencia con GPU
Especifica el dispositivo como cuda en tus comandos de entrenamiento o inferencia:
Ejemplo de línea de comandos
Valida el modelo personalizado
Ejemplo de script de Python
¿Por qué los Droplets GPU de DigitalOcean?
Los droplets GPU de DigitalOcean están diseñados para manejar tareas de IA y aprendizaje automático de alto rendimiento. Los H100 alimentan estos Droplets GPU para ofrecer una velocidad excepcional y capacidades de procesamiento paralelo, lo que los hace ideales para entrenar y ejecutar modelos YOLOv8 de manera eficiente. Además, estos droplets vienen preinstalados con la última versión de CUDA, asegurando que puedas comenzar a aprovechar la aceleración GPU sin perder tiempo en configuraciones manuales. Este entorno optimizado te permite centrarte por completo en la optimización de tus modelos YOLOv8 y escalar tus proyectos sin esfuerzo.
Resolución de Problemas Comunes
1. YOLOv8 no utiliza GPU
- Verifica la disponibilidad de GPU usando
- Verifica la compatibilidad de CUDA y PyTorch.
- Asegúrate de especificar
device=0odevice='cuda'en comandos o scripts. - Actualiza los controladores de NVIDIA y reinstala el CUDA Toolkit si es necesario.
2. Errores de CUDA
- Asegúrate de que la versión del CUDA Toolkit coincida con los requisitos de PyTorch.
- Verifica la instalación de cuDNN ejecutando scripts de diagnóstico.
- Revisa las variables de entorno para CUDA (
PATHyLD_LIBRARY_PATH).
3. Rendimiento Lento
- Habilita el entrenamiento de precisión mixta para optimizar el uso de memoria y velocidad:
- Reduce el tamaño del lote si el uso de memoria es demasiado alto.
- Asegúrate de tener un sistema optimizado para ejecutar procesamiento paralelo, y considera usar procesamiento por lotes en tu script de detección para mejorar el rendimiento.
Preguntas Frecuentes
¿Cómo habilito la GPU para YOLOv8?
Especifica device='cuda' o device=0 (si usas la primera GPU) en tus comandos o scripts al cargar el modelo. Esto habilitará a YOLOv8 a utilizar la GPU para un cálculo más rápido durante la inferencia y el entrenamiento. Asegúrate de que tu GPU esté correctamente configurada y detectada.
¿Por qué YOLOv8 no está utilizando mi GPU?
YOLOv8 podría no estar usando la GPU si hay problemas con el hardware, los controladores o la configuración. Para empezar, verifica la instalación de CUDA y la compatibilidad con PyTorch. Actualiza los controladores si es necesario. Asegúrate de que tu CUDA y CuDNN sean compatibles con tu instalación de PyTorch. Instala torchvision y verifica la configuración que se está instalando y utilizando.
Adicionalmente, si PyTorch no está instalado con soporte para GPU (por ejemplo, una versión solo para CPU), o el parámetro device en tus comandos de YOLOv8 puede que no esté explícitamente configurado como cuda. Ejecutar YOLOv8 en un sistema sin una GPU compatible con CUDA o con VRAM insuficiente también puede hacer que se utilice por defecto la CPU.
Para resolver esto, asegúrate de que tu GPU sea compatible con CUDA, verifica la instalación de todas las dependencias requeridas, comprueba que torch.cuda.is_available() devuelva True, y especifica explícitamente el parámetro device='cuda' en tus scripts o comandos de YOLOv8.
¿Cuáles son los requisitos de hardware para YOLOv8 en GPU?
Para instalar y ejecutar efectivamente YOLOv8 en una GPU, se recomienda Python 3.7 o superior, y se requiere una GPU compatible con CUDA para utilizar la aceleración por GPU.
Se recomienda una GPU NVIDIA moderna con al menos 8GB de memoria. Para conjuntos de datos grandes, más memoria es beneficiosa. Para un rendimiento óptimo, se recomienda usar Python 3.8 o más reciente, PyTorch 1.10 o superior, y una GPU NVIDIA compatible con CUDA 11.2+. La GPU debe tener idealmente al menos 8GB de VRAM para manejar conjuntos de datos moderados de manera eficiente, aunque más VRAM es beneficiosa para conjuntos de datos más grandes y modelos complejos. Además, tu sistema debe tener al menos 8GB de RAM y 50GB de espacio libre en disco para almacenar conjuntos de datos y facilitar el entrenamiento del modelo. Asegurar estas configuraciones de hardware y software te ayudará a lograr un entrenamiento e inferencia más rápidos con YOLOv8, especialmente para tareas computacionalmente intensivas.
Nota: Las GPU AMD pueden no ser compatibles con CUDA, por lo que elegir una GPU NVIDIA para la compatibilidad con YOLOv8 es esencial.
¿Puede YOLOv8 ejecutarse en múltiples GPU?
Para entrenar YOLOv8 utilizando múltiples GPU, puedes usar DataParallel de PyTorch o especificar dispositivos múltiples directamente (por ejemplo, cuda:0,1). Para el entrenamiento distribuido, YOLOv8 emplea por defecto DistributedDataParallel (DDP) de PyTorch. Asegúrate de que tu sistema tenga múltiples GPU disponibles y especifica las GPU que deseas utilizar en el script de entrenamiento o en la línea de comandos. Por ejemplo, establece --device 0,1,2,3 en la CLI o device=[0,1,2,3] en Python para utilizar las GPU 0, 1, 2 y 3. YOLOv8 maneja automáticamente el entrenamiento en paralelo a través de las GPU especificadas sin requerir un argumento explícito data_parallel. Aunque todas las GPU se utilizan durante el entrenamiento, la fase de validación generalmente se ejecuta en una sola GPU por defecto, ya que es menos intensiva en recursos que el entrenamiento.
¿Cómo optimizo YOLOv8 para inferencia en GPU?
Habilita la precisión mixta y ajusta los tamaños de lote para equilibrar la memoria y la velocidad. Dependiendo de tu conjunto de datos, entrenar YOLOv8 requiere bastante potencia de cálculo para funcionar de manera eficiente. Utiliza una variante de modelo más pequeña o cuantizada (por ejemplo, YOLOv8n o versiones cuantizadas INT8) para reducir el uso de memoria y el tiempo de inferencia. En tu script de inferencia, establece explícitamente el parámetro device en cuda para la ejecución en GPU. Utiliza técnicas como la inferencia por lotes para procesar múltiples imágenes simultáneamente y maximizar la utilización de la GPU. Si es aplicable, utiliza TensorRT para optimizar aún más el modelo para una inferencia más rápida en la GPU. Monitorea regularmente la memoria y el rendimiento de la GPU para asegurar un uso eficiente de los recursos.
El siguiente fragmento de código te permitirá procesar imágenes en paralelo dentro del tamaño de lote definido.
Si utilizas la CLI, especifica el tamaño del lote con -b o –batch-size. Con Python, asegúrate de que el argumento del lote esté configurado correctamente al inicializar tu modelo o al llamar al método de predicción.
¿Cómo resuelvo los problemas de falta de memoria de CUDA?
Para resolver errores de falta de memoria en CUDA, reduce el tamaño del lote de validación en tu archivo de configuración de YOLOv8, ya que lotes más pequeños requieren menos memoria de GPU. Además, si tienes acceso a múltiples GPUs, considera distribuir la carga de trabajo de validación entre ellas utilizando DistributedDataParallel de PyTorch o una funcionalidad similar, aunque esto requiere conocimientos avanzados de PyTorch. También puedes intentar liberar memoria caché usando torch.cuda.empty_cache() en tu script y asegurarte de que no se ejecuten procesos innecesarios en tu GPU. Actualizar a una GPU con más VRAM o optimizar tu modelo y conjunto de datos para la eficiencia de memoria son pasos adicionales para mitigar tales problemas.
Conclusión
Configurar YOLOv8 para utilizar una GPU es un proceso sencillo que puede mejorar significativamente el rendimiento. Siguiendo esta guía detallada, puedes acelerar el entrenamiento y la inferencia para tus tareas de detección de objetos. Optimiza tu configuración, soluciona problemas comunes y desbloquea todo el potencial de YOLOv8 con aceleración por GPU.
Referencias
Source:
https://www.digitalocean.com/community/tutorials/yolov8-for-gpu-accelerate-object-detection