













導入
YOLOv8は、2023年にUltralyticsによって開発され、YOLOシリーズの中でもユニークな物体検出アルゴリズムの1つとして台頭しました。これには、YOLOv5などの前任者に比べて、重要なアーキテクチャとパフォーマンスの向上が含まれています。これらの改善点には、より良い特徴抽出のためのCSPNetバックボーン、改善されたマルチスケール物体検出のためのFPN+PANネック、およびアンカーフリーアプローチへの移行が含まれます。これらの変更により、モデルの精度、効率、およびリアルタイム物体検出の利便性が大幅に向上します。
YOLOv8を使用すると、GPUを使用して物体検出タスクのパフォーマンスを大幅に向上させることができ、より高速なトレーニングと推論を提供します。このガイドでは、GPUを使用したYOLOv8のセットアップ方法、構成、トラブルシューティング、最適化のヒントについて説明します。
YOLOv8
YOLOv8は、前のバージョンを基にした高度なニューラルネットワーク設計とトレーニング技術を活用して、物体検出の性能を向上させています。物体の位置特定と分類を1つの効率的なフレームワークに統合し、速度と精度のバランスを取っています。アーキテクチャは、以下の3つの主要コンポーネントで構成されています:
- バックボーン:高度に最適化されたCNNバックボーンで、CSPDarknetに基づいている可能性があり、効率的な層(深さ別分離畳み込みなど)を使用してマルチスケール特徴を抽出し、最小限の計算オーバーヘッドで高い性能を確保しています。
- ネック:強化されたパス集約ネットワーク(PANet)は、マルチスケール特徴を洗練させて統合し、さまざまなサイズの物体をより良く検出します。効率性とメモリ使用を最適化しています。
- ヘッド:アンカーフリーのヘッドは、バウンディングボックス、信頼度スコア、クラスラベルを予測し、予測を簡素化し、多様な物体の形状やスケールに対する適応性を向上させます。
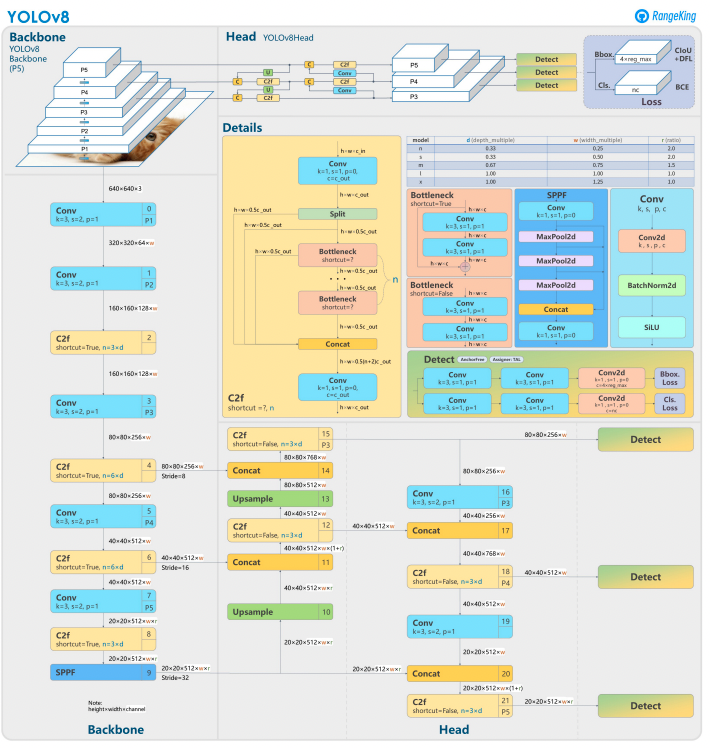
これらの革新により、YOLOv8はより速く、より正確で、現代の物体検出タスクにおいて多才です。さらに、YOLOv8は、以前のバージョンのアンカーに基づく手法から脱却し、バウンディングボックス予測にアンカーフリーアプローチを導入しています。
YOLOv8でGPUを使用する理由
YOLOv8(You Only Look Once, Version 8)は強力な物体検出フレームワークです。CPUでも動作しますが、GPUを利用することでいくつかの重要な利点があります。
- 速度: GPUは並列計算をより効率的に処理し、トレーニングと推論の時間を短縮します。
- スケーラビリティ: より大きなデータセットやモデルをGPUで管理できます。
- パフォーマンスの向上: リアルタイムの物体検出が可能になり、自律走行車、監視、ライブビデオ処理などのアプリケーションを実現します。

GPUは、YOLOv8でより速い結果を得て、より複雑なタスクを処理するための明確な選択肢です。
CPU対GPU
YOLOv8や他の物体検出モデルを使用する際に、CPUとGPUの選択は、モデルのトレーニングと推論のパフォーマンスに大きな影響を与える可能性があります。CPUは一般用途に優れており、小さなタスクを効率的に処理できますが、計算量が多くなると性能が低下します。物体検出のようなタスクには、速度と並列処理が必要であり、GPUは高性能な並列処理タスクを処理するために設計されています。したがって、YOLOのような深層学習モデルを実行するのに最適です。例えば、GPUでのトレーニングと推論は、ハードウェアとモデルのサイズに応じて、10〜50倍速くなることがあります。
| Aspect | CPU | GPU |
|---|---|---|
| 推論時間(画像あたり) | 約500 ms | 約15 ms |
| トレーニング速度(エポック/時) | 約2エポック/時 | 約30エポック/時 |
| バッチサイズの能力 | 小(2〜4画像) | 大(16〜32画像) |
| リアルタイムパフォーマンス | いいえ | はい |
| 並列処理 | 制限あり | 優れた(数千のコア) |
| エネルギー効率 | 大規模タスクでは低い | 並列ワークロードでは高い |
| コスト効率 | 小さなタスクに適しています | 深層学習タスクに最適です |
トレーニング中に、GPUはCPUと比較してエポックを劇的に短縮するため、違いがさらに顕著になります。この速度向上により、GPUはより大きなデータセットを処理し、リアルタイムの物体検出をより効率的に行うことができます。
GPUでYOLOv8を使用するための前提条件
YOLOv8をGPU用に構成する前に、以下の要件を満たしていることを確認してください:
1. ハードウェア要件
- NVIDIA GPU:YOLOv8はGPU加速のためにCUDAに依存しているため、NVIDIA GPUでCUDAのコンピュート能力が6.0以上のものが必要です。
- メモリ:中程度のデータセットには少なくとも8GBのGPUメモリを推奨します。より大きなデータセットの場合は、16GB以上が望ましいです。
2. ソフトウェア要件
- Python: バージョン3.8以降。
- PyTorch: GPUサポート(CUDA経由)でインストール。できればNVIDIA GPU。
- CUDA ToolkitとcuDNN: これらがあなたのPyTorchバージョンと互換性があることを確認してください。
- YOLOv8: Ultralyticsリポジトリからインストール可能。
3. ドライバー要件
- 最新のNVIDIAドライバーをNVIDIAのウェブサイトからダウンロードしてインストールしてください。
- ドライバーインストール後に
nvidia-smiを使用してGPUの使用可能状況を確認します。
GPU用にYOLOv8を設定するためのステップバイステップガイド
1. NVIDIAドライバーのインストール
NVIDIAドライバーをインストールするには:
- 以下のコードを使用してGPUを特定します:
- NVIDIA ドライバーダウンロードページを訪れて、適切なドライバーをダウンロードしてください。
- お使いのオペレーティングシステムのインストール手順に従ってください。
- 変更を適用するためにコンピュータを再起動してください。
- 次のコマンドを実行してインストールを確認してください:
- このコマンドはGPU情報を表示し、ドライバーの機能を確認します。
2. CUDA ToolkitとcuDNNをインストール
YOLOv8を使用するためには、適切なPyTorchバージョンを選択する必要があり、それにはCUDAバージョンが必要です。
CUDA Toolkitのインストール手順
- NVIDIA Developerサイトから適切なバージョンのCUDA Toolkitをダウンロードしてください。
- CUDA Toolkitをインストールし、環境変数(例:
PATH、LD_LIBRARY_PATH)を設定してください。 - 次のコマンドを実行してインストールを確認してください:
CUDAの最新バージョンを持っていることを確認することで、PyTorchがGPUを効果的に利用できるようになります。
cuDNNのインストール手順
- NVIDIA Developer siteからcuDNNをダウンロードしてください。
- 内容を解凍し、それらを対応するCUDAディレクトリ(例:
bin、include、lib)にコピーしてください。 - cuDNNバージョンがCUDAインストールと一致していることを確認してください。
3. GPUサポート付きでPyTorchをインストールする
GPUサポート付きでPyTorchをインストールするには、PyTorchのGet Startedページを訪れ、適切なインストールコマンドを選択してください。例:
4. YOLOv8をインストールして実行する
以下の手順に従ってYOLOv8をインストールしてください:
- Ultralyticsをインストールしてyolov8と必要なライブラリをインポートしてください
- Pythonスクリプトの例:
- コマンドラインの例:
5. YOLOv8でGPU構成を確認する
次のPythonコマンドを使用して、GPUが検出され、CUDAが有効になっているか確認します:
6. GPUでトレーニングまたは推論を実行する
トレーニングまたは推論コマンドでデバイスをcudaとして指定します:
コマンドライン例
カスタムモデルを検証する
Pythonスクリプトの例
なぜDigitalOceanのGPUドロップレットなのか?
DigitalOceanのGPUドロップレットは、高性能のAIおよび機械学習タスクを処理するために設計されています。H100sはこれらのGPUドロップレットに電力を供給し、卓越した速度と並列処理能力を提供します。これにより、YOLOv8モデルを効率的にトレーニングおよび実行するのに最適です。さらに、これらのドロップレットには最新のCUDAバージョンがプリインストールされており、手動設定に時間をかけることなくGPUアクセラレーションを活用できることを保証します。この合理化された環境により、YOLOv8モデルの最適化やプロジェクトのスケーリングに完全に集中することができます。
一般的な問題のトラブルシューティング
1. YOLOv8がGPUを使用していない
- GPUの可用性を確認するには
- CUDAとPyTorchの互換性をチェックします。
- コマンドやスクリプトでは、
device=0またはdevice='cuda'を指定してください。 - NVIDIAドライバーを更新し、必要に応じてCUDA Toolkitを再インストールします。
2. CUDAエラー
- CUDA ToolkitのバージョンがPyTorchの要件と一致していることを確認してください。
- 診断スクリプトを実行してcuDNNのインストールを確認します。
- CUDAの環境変数(
PATHおよびLD_LIBRARY_PATH)をチェックします。
3. パフォーマンスの低下
- メモリ使用量と速度を最適化するために混合精度トレーニングを有効にします:
- メモリ使用量が高すぎる場合はバッチサイズを減らしてください。
- 並列処理を実行するために最適化されたシステムを持っていることを確認し、パフォーマンスを向上させるために検出スクリプトでバッチ処理を使用することを検討してください。
よくある質問
YOLOv8のGPUを有効にするにはどうすればよいですか?
モデルを読み込む際に、コマンドやスクリプトで device='cuda' または device=0(最初のGPUを使用する場合)を指定してください。これにより、YOLOv8は推論およびトレーニング中にGPUを利用して計算を高速化します。GPUが正しく設定され、検出されていることを確認してください。
YOLOv8が私のGPUを使用していないのはなぜですか?
ハードウェア、ドライバー、または設定に問題がある場合、YOLOv8はGPUを使用していない可能性があります。まず、CUDAのインストールとPyTorchとの互換性を確認してください。必要に応じてドライバーを更新してください。CUDAとCuDNNがPyTorchのインストールと互換性があることを確認してください。torchvisionをインストールし、インストールおよび使用されている設定を確認してください。
さらに、PyTorchがGPUサポートなしでインストールされている場合(例:CPU専用バージョン)、またはYOLOv8コマンドの device パラメータが明示的に cuda に設定されていない可能性があります。CUDA互換のGPUがないシステムやVRAMが不十分なシステムでYOLOv8を実行すると、CPUがデフォルトで使用されることがあります。
これを解決するには、GPUがCUDA互換であることを確認し、すべての必要な依存関係のインストールを確認し、torch.cuda.is_available()がTrueを返すことを確認し、YOLOv8スクリプトやコマンドでdevice='cuda'パラメータを明示的に指定してください。
GPUでのYOLOv8のハードウェア要件は何ですか?
効果的にYOLOVv8をGPUでインストールおよび実行するには、Python 3.7以上が推奨され、CUDA互換のGPUが必要です。
少なくとも8GBのメモリを搭載した最新のNVIDIA GPUが推奨されます。大規模なデータセットの場合、より多くのメモリが有益です。最適なパフォーマンスを得るためには、Python 3.8以上、PyTorch 1.10以上、およびCUDA 11.2+に対応したNVIDIA GPUを使用することが推奨されます。GPUは適切に中規模のデータセットを効率的に処理するために、少なくとも8GBのVRAMを搭載していると良いですが、より大規模なデータセットや複雑なモデルの場合は、より多くのVRAMが有益です。さらに、システムには少なくとも8GBのRAMと50GBの空きディスク容量が必要です。これらのハードウェアおよびソフトウェア構成を確保することで、より高速なトレーニングと推論をYOLOv8で達成できます。特に計算集約的なタスクに対して有効です。
ご注意:AMD GPUはCUDAをサポートしていない場合があるため、YOLOv8の互換性を確保するにはNVIDIA GPUの選択が必要です。
YOLOv8は複数のGPUで動作しますか?
YOLOv8を複数のGPUでトレーニングするには、PyTorchのDataParallelを使用するか、複数のデバイスを直接指定します(例:cuda:0,1)。分散トレーニングの場合、YOLOv8はデフォルトでPyTorchのMulti-GPU DistributedDataParallel(DDP)を使用します。システムに複数のGPUが利用可能であることを確認し、トレーニングスクリプトまたはコマンドラインで使用したいGPUを指定してください。例えば、CLIで--device 0,1,2,3を設定するか、Pythonでdevice=[0,1,2,3]とすることで、GPU 0、1、2、3を利用できます。YOLOv8は、明示的なdata_parallel引数を必要とせず、指定されたGPU間で自動的に並列トレーニングを処理します。すべてのGPUがトレーニング中に利用されますが、検証フェーズは通常、トレーニングよりもリソースを消費しないため、デフォルトで単一のGPUで実行されます。
YOLOv8をGPUでの推論のために最適化するにはどうすればよいですか?
混合精度を有効にし、メモリと速度のバランスを取るためにバッチサイズを調整します。データセットによっては、YOLOv8を効率的に実行するにはかなりの計算能力が必要です。メモリ使用量と推論時間を削減するために、より小さいモデルバリアント(例:YOLOv8nやINT8量子化バージョン)を使用してください。推論スクリプトでは、deviceパラメータをcudaに明示的に設定してGPUで実行します。バッチ推論のような技術を使用して、複数の画像を同時に処理し、GPUの利用率を最大化します。該当する場合は、TensorRTを活用してモデルをさらに最適化し、より高速なGPU推論を実現します。効率的なリソース使用を確保するために、定期的にGPUメモリとパフォーマンスを監視します。
以下のコードスニペットを使用すると、定義されたバッチサイズ内で画像を並行して処理できます。
CLIを使用する場合は、-bまたは–batch-sizeでバッチサイズを指定します。Pythonでは、モデルを初期化する際や予測メソッドを呼び出すときに、バッチ引数が正しく設定されていることを確認してください。
CUDAのメモリ不足の問題を解決するにはどうすればよいですか?
CUDAのメモリエラーを解決するために、YOLOv8の設定ファイルで検証バッチサイズを小さくしてください。小さいバッチはGPUメモリを少なく必要とします。また、複数のGPUにアクセスできる場合は、PyTorchのDistributedDataParallelなどの機能を使用して検証の負荷を分散させることを検討してください。ただし、これはPyTorchの高度な知識が必要です。スクリプト内でtorch.cuda.empty_cache()を使用してキャッシュメモリをクリアし、GPU上で不要なプロセスが実行されていないことを確認することも試みてください。より多くのVRAMを持つGPUにアップグレードするか、メモリ効率のためにモデルとデータセットを最適化することも、こうした問題を軽減するためのさらなるステップです。
結論
YOLOv8をGPUで利用するための設定は非常に簡単で、パフォーマンスを大幅に向上させることができます。この詳細なガイドに従うことで、オブジェクト検出タスクのトレーニングと推論を加速させることができます。セットアップを最適化し、一般的な問題をトラブルシューティングし、GPUアクセラレーションを活用してYOLOv8の可能性を最大限に引き出しましょう。
参考文献
Source:
https://www.digitalocean.com/community/tutorials/yolov8-for-gpu-accelerate-object-detection