













在今日數據為導向的世界中,企業必須 adaptation to the rapid changes in how data is managed, analyzed, and utilized. 傳統的集中系統和單體結構,雖然在過去足夠,但已經不再足以前腳 meet the growing demands of organizations that need faster, real-time access to data insights. 在這個領域中,一個革新的框架是事件驱动的數據网格結構,當與AWS服務結合時,它成為了一個強大的解決方案,用於解決複雜的數據管理挑戰。
數據困境
許多組織在依賴過時的數據結構時面臨著 significant challenges. 這些挑戰包括:
集中的、單體的、領域agnostic的數據湖
一個集中的數據湖是所有數據的單一存儲位置,使其容易管理 和存取,但如果沒有適當的擴展,可能會導致性能問題。一個單體數據湖將所有數據處理過程結合 入一個 integrated system,這简化了设置,但可能难以擴展和維護。一個領域agnostic數據湖設計用來存儲任何行業或源头的數據, 提供靈活性和廣泛的适用性,但可能難以管理,且對於特定用途 optimize less.
傳統結構失敗的压力點
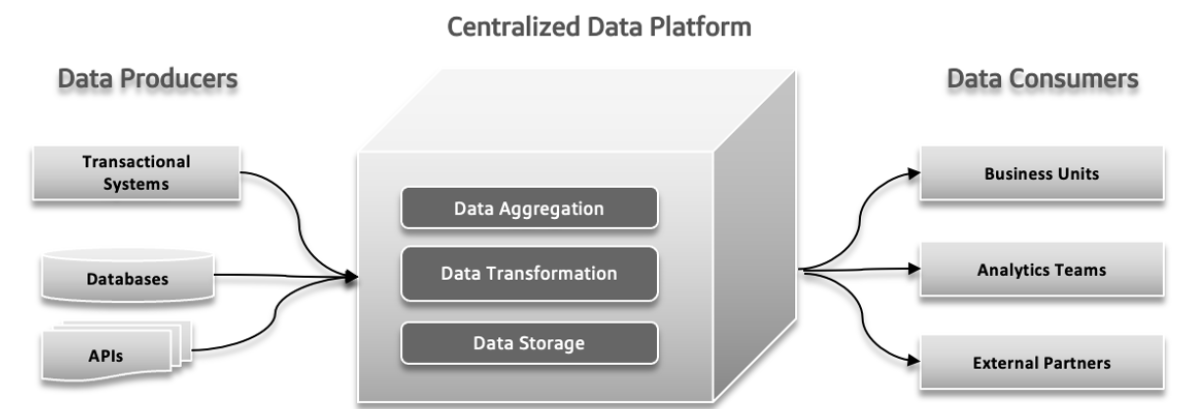
在傳統數據系統中,可能會發生幾種問題。數據生產者可能會傳送大量數據或帶有錯誤的數據,從而導致下游問題。隨著數據複雜性增加且更多不同來源的數據參與系統,集中的數據平台可能很難應對不斷增加的負載,導致系統當機和性能變慢。對快速實驗的 demands 可能會使系統無法應對,難以快速適應和測試新想法。數據響應時間可能會成為一種挑戰,導致無法及時獲得和使用數據,從而影響決策和整體效率。
操作和分析數據環境的分歧
在軟件架構中,像孤立擁有、不清確的数据使用、過於依賴數據管線和 inherent 限制等問題可能會導致顯著問題。孤立擁有發生在不同的團隊獨立工作時,導致協調問題和效率低下。缺乏對數據應該如何使用或分享的精確理解,可能會導致重複努力和不一致的結果。依賴過度的數據管線,其中部件彼此之間过于依賴,使得系統適應或擴展困難,導致延誤。最後,系統中的 inherent 限制可能會延缓新功能和更新的交付,阻碍整體進程。解決這些壓力點對更有效率和反應快速的開發過程至關重要。
大数据挑戰
在線分析處理(OLAP)系統將數據組織成一種方式,使其 easier for analysts to explore different aspects of the data. To answer queries, these systems must transform operational data into a format suitable for analysis and handling large volumes of data. Traditional 數據庫 use ETL (Extract, Transform, Load) processes to manage this. Big data technologies, like Apache Hadoop, improved data warehouses by addressing scaling issues and being open source, which allowed any company to use it as long as they could manage the infrastructure. Hadoop introduced a new approach by allowing unstructured or semi-structured data, rather than enforcing a strict schema upfront. This flexibility, where data could be written without a predefined schema and structured later during querying, made it easier for data engineers to handle and integrate data. Adopting Hadoop often meant forming a separate data team: data engineers handled data extraction, data scientists managed cleaning and restructuring, and data analysts performed analytics. This setup sometimes led to problems due to limited communication between the data team and application developers, often to prevent impacting production systems.
問題 1:數據模型邊界問題
分析所使用的資料與其原始結構密切相關,對於複雜且經常更新的模型可能會帶來問題。資料模型的變更會影響所有使用者,使他們容易受到這些變更的影響,特別是當模型涉及多個表格時。
問題2:資料不良,忽視問題的代價
不良資料通常不會引起注意,直到它在模式中引起問題,例如資料類型不正確等問題。由於驗證通常被延遲到流程的最後,不良資料可能會在流程中傳播,導致昂貴的修復和不一致的解決方案。不良資料可能導致重大的商業損失,例如造成數百萬的帳單錯誤。研究表明,不良資料每年給企業造成數萬億的損失,浪費知識工作者和數據科學家大量的時間。
問題3:缺乏單一擁有權
應用程式開發人員對於源資料模型通常不會將這些資訊與其他團隊進行溝通。他們的責任通常僅限於應用程式和資料庫的範圍。資料工程師負責管理資料的提取和移動,通常是反應性的工作,對於資料來源的控制有限。與開發人員相距甚遠的資料分析師在接收到的資料上面臨著挑戰,導致協調問題和需要獨立解決方案的需求。
問題4:自定義資料連接
大型的組織內,多個團隊可能使用同一份數據,但卻建立自己的數據管理流程。這導致數據存在多份,每份都被獨立管理,造成一團糟的狀況。這使得追蹤ETL作業變得困難,也無法確保數據質量,導致因同步問題和較不安全的數據來源等因素而出現不準確的情況。這種分散的方法浪費了時間、金錢和機會。
數據网格(Data mesh)通過將數據當作具有清晰結構、文件化和標準化訪問的產品來解決這些問題,減少劣質數據風險,並提升數據準確性和效率。
數據网格:一種現代化的方法
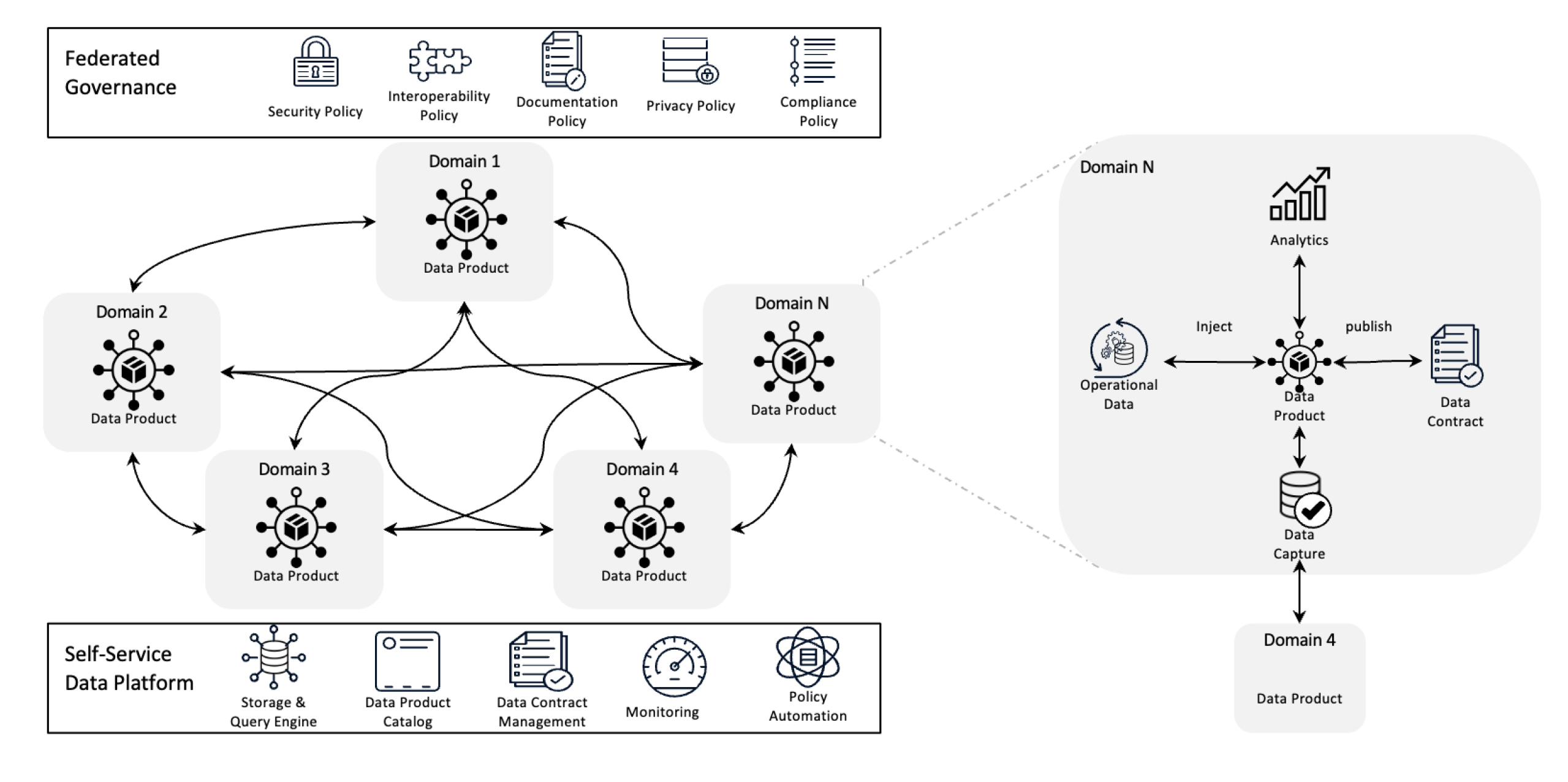
數據网格架構
數據网格通過分层所有權和將數據當作產品來重新定義數據管理,並由自助基礎設施支撐。這種轉變讓團隊能夠完全控制自己的數據,而分层化管理则確保了質量、遵從性和組織內的可擴展性。
簡單來說,它是一種設計用來解決複雜數據挑戰的架構框架,透過分层所有權和分布式方法來使用。它用於整合來自不同商業領域的數據,以進行全面的數據分析。它也是建立於強烈的數據分享和治理政策之上。
數據网格的目標
數據网格(Data mesh)幫助各種組織在 Scale 上獲得珍貴的數據洞見;簡單來說,处理不斷變化的數據環境、不斷增加的數據源和用戶、所需的數據变换種類、以及快速適應變化的需求。
數據网格通過去中心化控制來解決上述問題,因此團隊可以管理等自己的數據,而不會被隔離在不同的部門中。這種方法通過分佈式數據處理和存儲來提高可伸縮性,有助於避免單個中央系統的延缓。它通過允許團隊直接與自己的數據工作进行,減少等待中央團隊造成的延誤,從而加快洞見。每個團隊都負責自己的數據,從而提高質量和一致性。通過使用容易理解的數據產品和自助工具,數據网格確保所有團隊都能快速訪問和管理自己的數據,從而加快、提高效率並更好地符合業務需求。
數據网格的關鍵原則
- 去中心化的數據擁有權:團隊擁有和管理自己的數據產品,使他們負責其質量和可用性。
- 數據作為產品:數據被視為具有標準化訪問、版本控制和模式定義的產品,確保各部门之间的一致性和易用性。
- 联合治理:建立政策以維護數據完整性、安全性與符合规定,同時仍允許去中心化擁有權。
- 自服务能力基礎設施: 團隊可以存取可擴展的基礎設施,該基礎設施支持數據的吸入、處理和查詢,而無瓶頸或倚賴於集中的數據團隊。
事件如何幫助數據网格?
事件通過讓系統的不同部分實時分享和更新數據來幫助數據网格。當某個區域發生變動時,事件會通知其他區域,讓每個人都能即時更新的數據而無需直接的連接。這使系統更加靈活且可擴展,因為它能夠處理大量的數據並輕鬆地適應變化。事件還讓追踪數據的使用和管理變得更容易,並讓每個團隊能夠處理自己的數據而無需倚賴他人。
最後,讓我們來看一下以事件為基礎的數據网格架構。
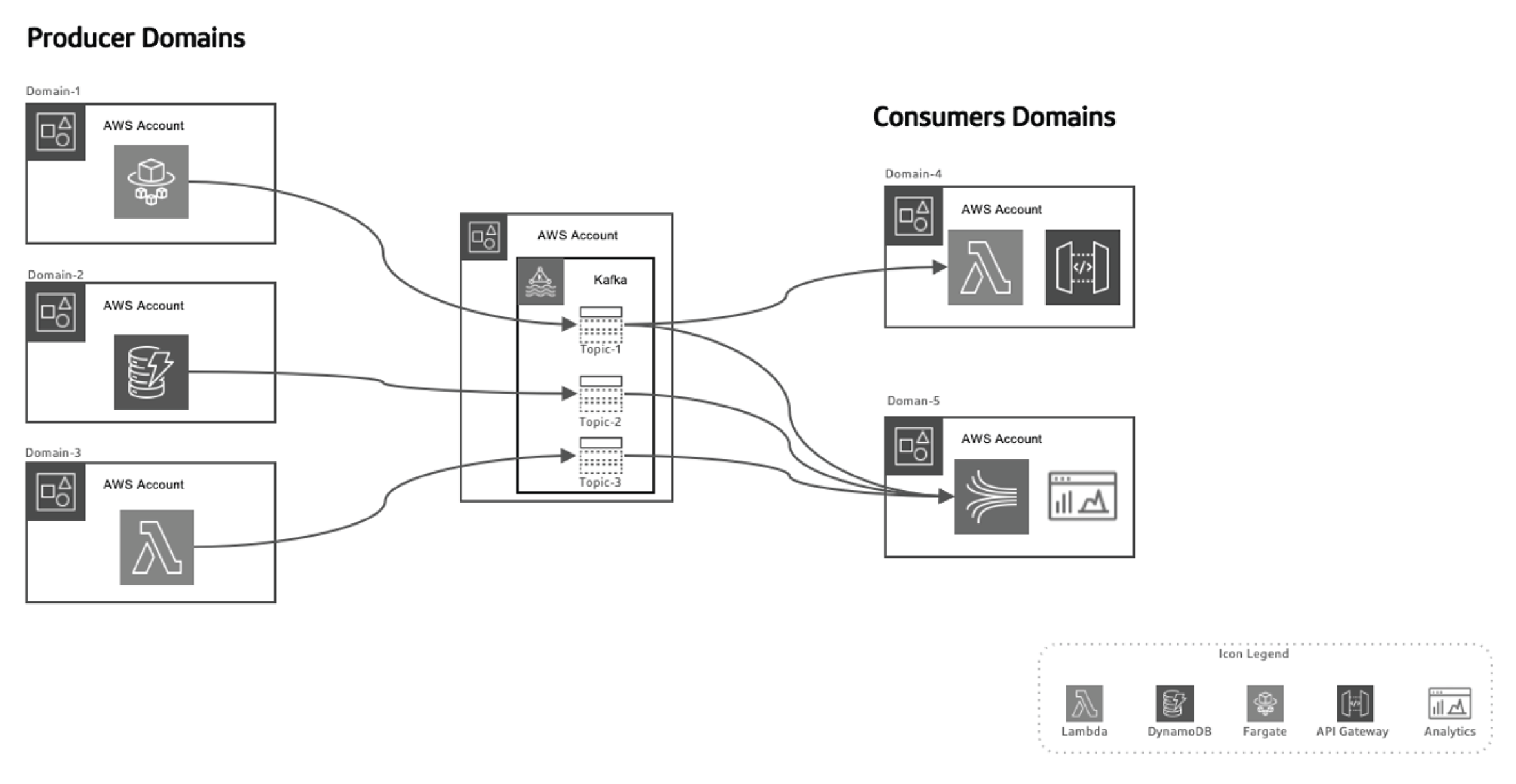
這種以事件為基礎的方法讓我們將數據的生產者和消費者分開,隨著時間的推移,domains的演變不需要對架構進行重大更改,使系統更加可擴展。生產者負責生成事件,這些事件然後傳送至數據在途中系統。串流平台確保這些事件可靠地傳送。當生產者微型服務或數據存儲發布新事件時,它會被存儲在特定的主題中。這會觸發消費端 Listener,如 Lambda 函數或 Kinesis,來處理事件並依需求使用。
利用 AWS 進行以事件為基礎的數據网格架構
AWS 提供一套服務,完美補充事件驅動數據網格(data mesh)模型,讓組織能夠擴展其數據基礎設施、確保實時數據傳遞,並维持高水平的治理和安全性。
以下是AWS服務如何融入此架構:
AWS Kinesis 用於實時事件串流
在事件驅動的數據網格中,實時串流是一個關鍵元素。AWS Kinesis 提供收集、處理和分析大规模實時串流數據的能力。
Kinesis 提供了幾個元件:
- Kinesis 數據串流:同時與多個消費者共同處理實時事件。
- Kinesis 數據Firehose:將事件串流直接傳送到S3、Redshift或Elasticsearch以進行進一步的處理和分析。
- Kinesis 數據分析:實時處理數據以獲得即時的洞察,允許在數據處理管線中立即回饋。
AWS Lambda 用於事件處理
在數據網格架構中,AWS Lambda 是無伺服器事件處理的脊梁。它能夠無伺服器管理地自動擴展並處理進來的數據串流,
Lambda 是以下用途的理想選擇:
- 實時處理 Kinesis 串流
- 在特定事件發生時呼叫 API 網關請求
- 與 DynamoDB、S3 或其他 AWS 服務互動以存儲、處理或分析數據
AWS SNS 和 SQS 用於事件 分發
AWS 簡單通知服務 (SNS) 作為主要的事件廣播系統,能夠在分散式系統中發送即時通知。AWS 簡單隊列服務 (SQS) 確保解耦服務之間的消息可靠傳遞,即使在部分系統故障的情況下也能保證可靠性。這些服務使得解耦的微服務能夠互相交互而無需直接依賴,確保系統具有可擴展性和容錯能力。
AWS DynamoDB 用於實時數據管理
在分散式架構中,DynamoDB 提供了一個可擴展的低延遲 NoSQL 數據庫,能夠實時存儲事件數據,非常適合存儲數據處理流水線的結果。它支持 Outbox 模式,即應用生成的事件存儲在 DynamoDB 中,然後由流式處理服務(例如 Kinesis 或 Kafka)消費。
AWS Glue 用於聯邦數據目錄和 ETL
AWS Glue 提供全面管理的數據目錄和 ETL 服務,對於數據網格中的聯邦數據治理至關重要。Glue 幫助在分佈式域中進行數據目錄、準備和轉換,確保組織內的可發現性、治理和集成。
AWS Lake Formation 和 S3 用於數據湖
數據网格結構雖然逐漸移離集中的數據湖,但S3和AWS湖形成(AWS Lake Formation)在存儲、保護和目錄化管理在不同領域間流动的數據方面扮演著至關重要的角色,確保了長期的存儲、治理和符合規範。
AWS與Python實現的事件驱动數據网格
事件生產者:AWS Kinesis + Python
在這個例子中,我們使用AWS Kinesis串流當新客戶被創建時的事件:
import boto3
import json
kinesis = boto3.client('kinesis')
def send_event(event):
kinesis.put_record(
StreamName="CustomerStream",
Data=json.dumps(event),
PartitionKey=event['customer_id']
)
def create_customer_event(customer_id, name):
event = {
'event_type': 'CustomerCreated',
'customer_id': customer_id,
'name': name
}
send_event(event)
# Simulate a new customer creation
create_customer_event('123', 'ABC XYZ')
事件處理:AWS Lambda + Python
這個Lambda函數消耗Kinesis事件並實時處理它們。
import json
import boto3
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('CustomerData')
def lambda_handler(event, context):
for record in event['Records']:
payload = json.loads(record['kinesis']['data'])
if payload['event_type'] == 'CustomerCreated':
process_customer_created(payload)
def process_customer_created(event):
table.put_item(
Item={
'customer_id': event['customer_id'],
'name': event['name']
}
)
print(f"Stored customer data: {event['customer_id']} - {event['name']}")
結論
透過運用如Kinesis、Lambda、DynamoDB和Glue等AWS服務,組織能夠充分利用事件驱动數據网格結構的潛力。這種結構提供了靈活性、可擴展性和實時見解,確保組織在今日迅速變化的數據環境中保持競爭力。採取事件驱动的數據网格結構不僅是技術提升,對於希望在大数据和分佈式系統時代中蓬勃發展的企业來說,更是一項策略必要條件。
Source:
https://dzone.com/articles/event-driven-data-mesh-architecture-with-aws