













介绍
YOLOv8于2023年由Ultralytics开发,已成为YOLO系列中独特的目标检测算法之一,并在架构和性能上与其前身(如YOLOv5)相比有了显著的提升。这些改进包括了更好的特征提取的CSPNet骨干、改进的多尺度目标检测的FPN+PAN颈部以及转向无锚点方法。这些变化显著提高了模型的准确性、效率和实时目标检测的可用性。
使用GPU配合YOLOv8可以显著提升目标检测任务的性能,提供更快的训练和推理速度。本指南将指导您如何为GPU使用设置YOLOv8,包括配置、故障排除和优化技巧。
YOLOv8
YOLOv8基于其前身,采用先进的神经网络设计和训练技术来增强目标检测性能。它将目标定位和分类统一到一个高效的框架中,平衡了速度和准确性。该架构包括三个关键组件:
- Backbone:一个经过高度优化的CNN骨干网络,可能基于CSPDarknet,利用高效的层(如深度可分离卷积)提取多尺度特征,确保高性能且计算开销最小。
- Neck:增强的Path Aggregation Network (PANet)调整和整合多尺度特征,以更好地检测各种大小的目标。它针对效率和内存使用进行了优化。
- Head:无锚点的头部预测边界框、置信度分数和类别标签,简化了预测并提高了适应各种目标形状和尺度的能力。
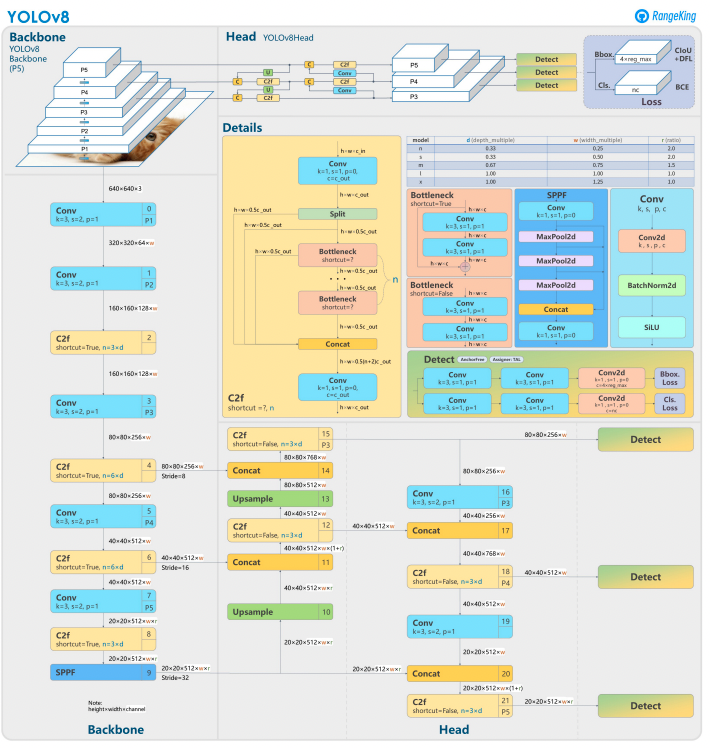
这些创新使YOLOv8在现代目标检测任务中更快、更准确、更多样化。此外,YOLOv8引入了一种无锚点的边界框预测方法,摆脱了早期版本的基于锚点的方法。
为什么要在YOLOv8中使用GPU?
YOLOv8(You Only Look Once,版本8)是一个强大的目标检测框架。虽然它可以在CPU上运行,但使用GPU提供了一些关键优势,例如:
- 速度:GPU更有效地处理并行计算,从而减少训练和推理时间。
- 可扩展性:使用GPU可以管理更大的数据集和模型。
- 增强性能:实时目标检测变得可行,使得自动驾驶车辆、监控和实时视频处理等应用成为可能。

GPU无疑是实现更快结果和处理更复杂任务的最佳选择,特别是在使用YOLOv8时。
CPU与GPU
在使用YOLOv8或任何目标检测模型时,选择CPU和GPU对模型的性能进行训练和推理都会产生显著影响。众所周知,CPU非常适合一般用途,可以高效处理较小的任务。然而,当任务变得计算密集时,CPU就会失败。像目标检测这样的任务需要速度和并行计算,而GPU则专为处理高性能的并行处理任务而设计。因此,它们非常适合运行像YOLO这样的深度学习模型。例如,使用GPU进行训练和推理可以比使用CPU快10-50倍,具体取决于硬件和模型大小。
| Aspect | CPU | GPU |
|---|---|---|
| 推理时间(每张图片) | ~500毫秒 | ~15毫秒 |
| 训练速度(每小时的epochs数) | ~2个epochs/小时 | ~30个epochs/小时 |
| 批处理大小能力 | 小型(2-4张图片) | 大型(16-32张图片) |
| 实时性能 | 否 | 是 |
| 并行处理 | 有限 | 优秀(数千个核心) |
| 能效 | 大型任务的能效较低 | 并行工作负载的能效较高 |
| 成本效益 | 适合小任务 | 非常适合任何深度学习任务 |
在训练过程中,差异变得更加明显,GPU相比于CPU显著缩短了训练周期。这一速度提升使得GPU能够更有效地处理更大的数据集并执行实时目标检测。
使用YOLOv8和GPU的前提条件
在配置YOLOv8以使用GPU之前,请确保满足以下要求:
1. 硬件要求
- NVIDIA GPU:YOLOv8依赖CUDA进行GPU加速,因此您需要一款计算能力为6.0或更高的NVIDIA GPU。
- 内存:建议用于中等数据集的GPU内存至少为8GB。对于更大的数据集,建议使用16GB或更多的内存。
2. 软件要求
- Python:版本3.8或更新。
- PyTorch:已安装GPU支持(通过CUDA)。最好使用NVIDIA GPU。
- CUDA Toolkit和cuDNN:确保与您的PyTorch版本兼容。
- YOLOv8:可从Ultralytics存储库安装。
3. 驱动程序要求
- 从NVIDIA网站下载并安装最新的NVIDIA驱动程序。
- 驱动程序安装后,使用
nvidia-smi检查GPU的可用性。
配置YOLOv8以供GPU使用的逐步指南
1. 安装NVIDIA驱动程序
要安装NVIDIA驱动程序:
- 使用以下代码识别您的GPU:
- 访问NVIDIA驱动程序下载页面,并下载适当的驱动程序。
- 按照您的操作系统的安装说明进行安装。
- 重新启动计算机以应用更改。
- 通过运行以下命令验证安装:
- 此命令会显示GPU信息并确认驱动程序功能。
2. 安装CUDA Toolkit和cuDNN
为了使用YOLOv8,我们需要选择适当的PyTorch版本,这又需要CUDA版本。
安装CUDA Toolkit的步骤
- 从NVIDIA开发者网站下载适当版本的CUDA Toolkit。
- 安装CUDA Toolkit并设置环境变量(例如
PATH,LD_LIBRARY_PATH)。 - 通过运行以下命令验证安装:
确保您拥有最新版本的CUDA,可以让PyTorch有效地利用GPU
安装cuDNN的步骤
- 从NVIDIA开发者网站下载cuDNN。
- 解压缩内容并将其复制到相应的CUDA目录(例如,
bin,include,lib)。 - 确保cuDNN版本与您的CUDA安装相匹配。
3. 安装支持GPU的PyTorch
要安装支持GPU的PyTorch,请访问PyTorch的入门页面并选择适当的安装命令。例如:
4. 安装并运行YOLOv8
按照以下步骤安装YOLOv8:
- 安装Ultralytics以便使用yolov8并导入必要的库
- Python脚本示例:
- 示例命令行:
5. 验证YOLOv8中的GPU配置
使用以下Python命令检查GPU是否被检测到并且CUDA已启用:
6. 使用GPU进行训练或推断
在训练或推断命令中指定设备为cuda:
命令行示例
验证自定义模型
Python脚本示例
为什么选择DigitalOcean GPU Droplets?
DigitalOcean的GPU droplets旨在处理高性能人工智能和机器学习任务。H100s为这些GPU Droplets提供动力,以提供卓越的速度和并行处理能力,使其非常适合高效训练和运行YOLOv8模型。此外,这些Droplets预装了最新版本的CUDA,确保您可以立即开始利用GPU加速,而无需花费时间进行手动配置。这种简化的环境使您完全可以专注于优化YOLOv8模型并轻松扩展您的项目。
故障排除常见问题
1. YOLOv8未使用GPU
- 验证 GPU 可用性使用
- 检查 CUDA 和 PyTorch 兼容性。
- 确保在命令或脚本中指定
device=0或device='cuda'。 - 更新 NVIDIA 驱动程序并在必要时重新安装 CUDA Toolkit。
2. CUDA 错误
- 确保 CUDA Toolkit 版本与 PyTorch 要求相匹配。
- 通过运行诊断脚本验证 cuDNN 安装。
- 检查 CUDA 的环境变量(
PATH和LD_LIBRARY_PATH)。
3. 性能缓慢
- 启用混合精度训练以优化内存使用和速度:
- 如果内存使用过高,请减小批处理大小。
- 确保您拥有一个用于运行并行处理的优化系统,并考虑在检测脚本中使用批处理以提高性能。
常见问题
如何为YOLOv8启用GPU?
在加载模型时,在您的命令或脚本中指定 device='cuda' 或 device=0(如果使用第一块GPU)。这将使YOLOv8利用GPU进行更快的推理和训练计算。确保您的GPU已正确设置并被检测到。
为什么YOLOv8不使用我的GPU?
如果硬件、驱动程序或设置存在问题,YOLOv8可能不会使用GPU。首先,检查CUDA的安装和与PyTorch的兼容性。如有必要,更新驱动程序。确保您的CUDA和CuDNN与您的PyTorch安装兼容。安装torchvision并检查正在安装和使用的配置。
此外,如果PyTorch没有安装GPU支持(例如,仅CPU版本),或者在您的YOLOv8命令中未明确将 device 参数设置为 cuda,也可能导致这一问题。在没有CUDA兼容GPU或显存不足的系统上运行YOLOv8也可能导致其默认为CPU。
要解决此问题,请确保您的GPU兼容CUDA,验证所有必需依赖项的安装情况,检查torch.cuda.is_available()是否返回True,并在您的YOLOv8脚本或命令中明确指定device='cuda'参数。
YOLOv8在GPU上的硬件要求是什么?
为了有效地在GPU上安装和运行YOLOv8,建议使用Python 3.7或更高版本,并且需要CUDA兼容的GPU来使用GPU加速。
推荐使用至少8GB内存的现代NVIDIA GPU。对于大型数据集,更多内存是有益的。为了获得最佳性能,建议使用Python 3.8或更新版本、PyTorch 1.10或更高版本以及与CUDA 11.2+兼容的NVIDIA GPU。GPU理想情况下应至少具有8GB的VRAM,以有效处理中等数据集,尽管对于更大的数据集和复杂模型来说,更多的VRAM是有益的。此外,您的系统应至少具有8GB的RAM和50GB的可用磁盘空间,以存储数据集并促进模型训练。确保这些硬件和软件配置将有助于您在YOLOv8上实现更快的训练和推理,特别是对于计算密集型任务。
请注意:AMD GPU可能不支持CUDA,因此选择NVIDIA GPU以确保与YOLOv8的兼容性是必要的。
YOLOv8能在多个GPU上运行吗?
要使用多个GPU训练YOLOv8,可以使用PyTorch的DataParallel或直接指定多个设备(例如,cuda:0,1)。对于分布式训练,YOLOv8默认使用PyTorch的Multi-GPU DistributedDataParallel(DDP)。确保您的系统有多个可用的GPU,并在训练脚本或命令行中指定要使用的GPU。例如,在CLI中设置--device 0,1,2,3,或者在Python中设置device=[0,1,2,3]来利用GPU 0、1、2和3。YOLOv8会自动跨指定的GPU处理并行训练,而无需显式指定data_parallel参数。在训练期间会利用所有GPU,而验证阶段通常默认在单个GPU上运行,因为相对于训练而言,验证阶段的资源消耗较少。
如何优化YOLOv8以在GPU上进行推断?
启用混合精度并调整批量大小,以平衡内存和速度。根据数据集的不同,训练YOLOv8需要相当大的计算能力才能高效运行。使用较小或量化的模型变体(例如,YOLOv8n或INT8量化版本)来减少内存使用和推理时间。在推理脚本中,明确将device参数设置为cuda以进行GPU执行。使用批量推理等技术,能够同时处理多张图像,最大化GPU利用率。如适用,利用TensorRT进一步优化模型,以实现更快的GPU推理。定期监控GPU内存和性能,以确保资源使用高效。
以下代码片段将允许您在定义的批量大小内并行处理图像。
如果使用CLI,请使用-b或–batch-size指定批量大小。使用Python时,请确保在初始化模型或调用预测方法时正确设置批量参数。
我该如何解决CUDA内存不足的问题?
为了解决CUDA内存不足的错误,请在YOLOv8配置文件中减少验证批次大小,因为较小的批次需要更少的GPU内存。此外,如果您有多个GPU可用,请考虑使用PyTorch的DistributedDataParallel或类似功能将验证工作负载分配到这些GPU上,尽管这需要对PyTorch有较深入的了解。您还可以尝试在脚本中使用torch.cuda.empty_cache()清除缓存内存,并确保没有不必要的进程在您的GPU上运行。升级到具有更大显存的GPU或优化您的模型和数据集以提高内存效率也是缓解此类问题的进一步步骤。
结论
配置YOLOv8以使用GPU是一个简单的过程,可以显著提升性能。通过遵循本详细指南,您可以加速物体检测任务的训练和推理。优化您的设置,排除常见问题,并充分发挥YOLOv8在GPU加速下的潜力。
参考文献
Source:
https://www.digitalocean.com/community/tutorials/yolov8-for-gpu-accelerate-object-detection