













Что означает перестановка строк в столбцы в SQL?
Поворот в SQL относится к преобразованию данных из формата строки в формат столбца. Это преобразование полезно для отчетности и анализа данных, позволяя получить более структурированный и компактный вид данных. Поворот строк в столбцы также позволяет пользователям анализировать и суммировать данные таким образом, что ключевые идеи становятся более ясными.
Рассмотрим следующий пример: у меня есть таблица с ежедневными транзакциями по продажам, и каждая строка записывает дату, название продукта и сумму продаж.
| Date | Product | Sales |
|---|---|---|
| 2024-01-01 | Ноутбук | 100 |
| 2024-01-01 | Мышь | 200 |
| 2024-01-02 | Ноутбук | 150 |
| 2024-01-02 | Мышь | 250 |
Поворачивая эту таблицу, я могу переструктурировать её, чтобы показать каждый продукт в качестве столбца, а данные о продажах для каждой даты под соответствующим столбцом. Обратите также внимание, что происходит агрегирование.
| Date | Laptop | Mouse |
|---|---|---|
| 2024-01-01 | 100 | 200 |
| 2024-01-02 | 150 | 250 |
Традиционно операции сводки требовали сложных SQL-запросов с условной агрегацией. Со временем реализации SQL развились, и сейчас многие современные базы данных включают операторы PIVOT и UNPIVOT, позволяющие проводить более эффективные и простые преобразования.
Понимание сводных строк в столбцы SQL
Операция сводки SQL преобразует данные, превращая значения строк в столбцы. Ниже приведены основный синтаксис и структура сводки SQL с следующими частями:
-
SELECT: Оператор
SELECTссылается на столбцы, которые нужно вернуть в таблице сводки SQL. -
Подзапрос: Подзапрос содержит источник данных или таблицу, которые должны быть включены в сводную таблицу SQL.
-
ПОВОРОТ: Оператор
PIVOTсодержит агрегирования и фильтр, которые будут применены в сводной таблице.
-- Выбор статических столбцов и столбцов для сворачивания SELECT <static columns>, [pivoted columns] FROM ( -- Подзапрос, определяющий исходные данные для сворачивания <subquery that defines data> ) AS source PIVOT ( -- Применение агрегирующей функции к столбцу значений, создание новых столбцов <aggregation function>(<value column>) FOR <column to pivot> IN ([list of pivoted columns]) ) AS pivot_table;
Давайте рассмотрим следующий пошаговый пример, чтобы продемонстрировать, как свернуть строки в столбцы в SQL. Рассмотрим таблицу SalesData ниже.

Пример таблицы для преобразования с использованием оператора PIVOT SQL. Изображение автора.
Я хочу изменить формат этих данных, чтобы сравнить ежедневные продажи каждого продукта. Я начну с выбора подзапроса, который будет структурировать оператор PIVOT.
-- Подзапрос, определяющий исходные данные для оператора PIVOT SELECT Date, Product, Sales FROM SalesData;
Теперь я буду использовать оператор PIVOT, чтобы преобразовать значения Product в столбцы и агрегировать Sales с использованием оператора SUM.
-- Выбор даты и пивот-столбцов для каждого продукта SELECT Date, [Laptop], [Mouse] FROM ( -- Подзапрос для выборки столбцов Date, Product и Sales SELECT Date, Product, Sales FROM SalesData ) AS source PIVOT ( -- Агрегирование Sales по Product, с преобразованием значений продукта в столбцы SUM(Sales) FOR Product IN ([Laptop], [Mouse]) ) AS pivot_table;

Пример преобразования вывода с использованием оператора PIVOT SQL для преобразования строк в столбцы. Изображение автора.
При преобразовании данных упрощается обобщение данных, однако у этой техники есть потенциальные проблемы. Ниже перечислены потенциальные проблемы с SQL-поворотом и способы их решения.
-
Динамические имена столбцов: Когда значения для поворота (например, типы продуктов) неизвестны, жесткое закодирование имен столбцов не подходит. Некоторые базы данных, например, SQL Server, поддерживают динамический SQL с хранимыми процедурами для решения этой проблемы, в то время как другие требуют обработки этого на уровне приложения.
-
Обработка значений NULL: Когда для определенного сводного столбца нет данных, результат может содержать
NULL. Вы можете использовать функциюCOALESCEдля замены значенийNULLна ноль или другой заполнитель. -
Совместимость в разных базах данных: Не все базы данных напрямую поддерживают оператор
PIVOT. Если ваш SQL диалект его не поддерживает, вы можете достичь аналогичных результатов с помощью оператораCASEи условной агрегации.
Преобразование строк в столбцы в SQL: примеры и применение
Различные методы используются для сводки данных в SQL, в зависимости от используемой базы данных или других требований. В то время как оператор PIVOT часто используется в SQL Server, другие техники, такие как операторы CASE, позволяют выполнять аналогичные преобразования базы данных без прямой поддержки PIVOT. Я рассмотрю два общих метода сводки данных в SQL и поговорю о их достоинствах и недостатках.
Использование оператора PIVOT
Оператор PIVOT, доступный в SQL Server, предоставляет простой способ сводки строк в столбцы, указывая функцию агрегации и определяя столбцы для сводки.
Рассмотрим следующую таблицу с именем sales_data.

Пример таблицы заказов для преобразования с использованием оператора PIVOT. Изображение автора.
Я буду использовать оператор PIVOT для агрегации данных таким образом, чтобы общая sales_revenue для каждого года отображалась в столбцах.
-- Используйте PIVOT для агрегации выручки от продаж по годам SELECT * FROM ( -- Выберите соответствующие столбцы из таблицы-источника SELECT sale_year, sales_revenue FROM sales_data ) AS src PIVOT ( -- Агрегируйте выручку от продаж для каждого года SUM(sales_revenue) -- Создайте столбцы для каждого года FOR sale_year IN ([2020], [2021], [2022], [2023]) ) AS piv;

Пример выходного преобразования с использованием SQL PIVOT. Изображение от автора.
Использование оператора PIVOT имеет следующие преимущества и ограничения:
-
Преимущества: Метод эффективен при правильном индексировании столбцов. Он также имеет простой и более читаемый синтаксис.
-
Ограничения: Не все базы данных поддерживают оператор
PIVOT. Для его использования необходимо заранее указать столбцы, а динамическое пивотирование требует дополнительной сложности.
Ручное пивотирование с помощью операторов CASE
Вы также можете использовать операторы CASE для ручного пивотирования данных в базах данных, которые не поддерживают операторы PIVOT, таких как MySQL и PostgreSQL. Этот подход использует условную агрегацию, оценивая каждую строку и условно присваивая значения новым столбцам на основе определенных критериев.
Например, мы можем ручным образом пивотировать данные в той же таблице sales_data с помощью операторов CASE.
-- Агрегировать выручку от продаж по годам с помощью операторов CASE SELECT -- Рассчитать общую выручку от продаж для каждого года SUM(CASE WHEN sale_year = 2020 THEN sales_revenue ELSE 0 END) AS sales_2020, SUM(CASE WHEN sale_year = 2021 THEN sales_revenue ELSE 0 END) AS sales_2021, SUM(CASE WHEN sale_year = 2022 THEN sales_revenue ELSE 0 END) AS sales_2022, SUM(CASE WHEN sale_year = 2023 THEN sales_revenue ELSE 0 END) AS sales_2023 FROM sales_data;

Пример преобразования вывода с использованием оператора CASE SQL. Изображение от автора.
Использование оператора CASE для преобразования имеет следующие преимущества и ограничения:
-
Преимущества: Этот метод работает во всех базах данных SQL и гибок для динамического создания новых столбцов, даже когда имена продуктов неизвестны или часто меняются.
-
Ограничения: Запросы могут стать сложными и длинными, если нужно сворачивать много столбцов. Из-за множественных условных проверок метод работает немного медленнее, чем оператор
PIVOT.
Рассмотрение производительности при сворачивании строк в столбцы
Преобразование строк в столбцы в SQL может иметь последствия для производительности, особенно при работе с большими наборами данных. Вот несколько советов и bew practices, которые помогут вам написать эффективные запросы на сворачивание, оптимизировать их производительность и избежать распространенных проблем.
Best practices
Ниже приведены лучшие практики для оптимизации ваших запросов и улучшения производительности.
-
Стратегии индексирования: Правильное индексирование является ключевым для оптимизации сводных запросов, позволяя SQL быстрее извлекать и обрабатывать данные. Всегда индексируйте столбцы, часто используемые в
WHEREили столбцы, по которым происходит группировка, чтобы снизить время сканирования. -
Избегайте вложенных поворотов: Стекирование нескольких операций поворота в одном запросе может быть сложным для чтения и медленным в выполнении. Упростите, разбив запрос на части или используя временную таблицу.
-
Ограничьте столбцы и строки в повороте: Для анализа необходимы только столбцы поворота, поскольку поворачивание многих столбцов может быть ресурсоемким и создавать большие таблицы.
Избегание распространенных ошибок
Ниже перечислены распространенные ошибки, с которыми вы можете столкнуться при использовании запросов на сводные таблицы, и способы их избежать.
-
Ненужные полные сканирования таблицы: Запросы на сводные таблицы могут вызывать полные сканирования таблицы, особенно если соответствующих индексов нет. Избегайте полных сканирований таблицы, создавая индексы на ключевые столбцы и фильтруя данные перед применением сводной таблицы.
-
Использование динамического SQL для частого выполнения операции Pivot: Использование динамического SQL может замедлить производительность из-за повторной компиляции запроса. Чтобы избежать этой проблемы, кэшируйте или ограничивайте динамические операции Pivot для конкретных сценариев и рассмотрите возможность обработки динамических столбцов на уровне приложения, если это возможно.
-
Агрегирование на больших наборах данных без предварительной фильтрации: Агрегирующие функции, такие как
SUMилиCOUNTна больших наборах данных, могут замедлить производительность базы данных. Вместо того чтобы делать поворот всего набора данных, сначала отфильтруйте данные с помощью оператораWHERE. -
NULL-значения в пивотируемых столбцах: Операции пивотирования часто приводят к появлению значений
NULL, когда нет данных для определенного столбца. Это может замедлить запросы и усложнить интерпретацию результатов. Чтобы избежать этой проблемы, используйте функции, такие какCOALESCE, для замены значенийNULLна значение по умолчанию. -
Тестирование только с Образцовыми Данными: Запросы на поворот могут вести себя по-разному с большими наборами данных из-за увеличенного объема памяти и требований к обработке. Всегда тестируйте запросы на поворот на реальных или представительных образцах данных, чтобы точно оценить влияние на производительность.
Попробуйте нашу карьеру SQL Server Developer, которая охватывает всё, начиная от транзакций и обработки ошибок до улучшения производительности запросов.
Реализации, Специфичные для Базы Данных
Операции Pivot значительно различаются в различных базах данных, таких как SQL Server, MySQL и Oracle. У каждой из этих баз данных есть свой синтаксис и ограничения. Я расскажу о примерах пивотирования данных в различных базах данных и их ключевых особенностях.
SQL Server
SQL Server предоставляет встроенный оператор PIVOT, который является простым в использовании при преобразовании строк в столбцы. Оператор PIVOT легко использовать и интегрируется с мощными функциями агрегации SQL Server. Основные особенности поворота в SQL включают в себя следующее:
-
Прямая поддержка PIVOT и UNPIVOT: Оператор
PIVOTSQL Server позволяет быстрое преобразование строк в столбцы. ОператорUNPIVOTтакже может инвертировать этот процесс. -
Варианты агрегирования: Оператор
PIVOTпозволяет использовать различные функции агрегирования, такие какSUM,COUNTиAVG.
Ограничение оператора PIVOT в SQL Server заключается в том, что требуется знать заранее значения столбцов, которые будут повернуты, что делает его менее гибким для динамически изменяющихся данных.
В приведенном ниже примере оператор PIVOT преобразует значения Product в столбцы и агрегирует Sales, используя оператор SUM.
-- Выбор даты и столбцов, связанных с каждым продуктом SELECT Date, [Laptop], [Mouse] FROM ( -- Подзапрос для выбора даты, продукта и столбцов Sales SELECT Date, Product, Sales FROM SalesData ) AS source PIVOT ( -- Агрегирование продаж по продукту, преобразование значений продукта в столбцы SUM(Sales) FOR Product IN ([Laptop], [Mouse]) ) AS pivot_table;
Я рекомендую пройти курс Introduction to SQL Server на DataCamp, чтобы овладеть основами SQL Server для анализа данных.
MySQL
MySQL не имеет встроенной поддержки оператора PIVOT. Однако вы можете использовать оператор CASE для ручного преобразования строк в столбцы и комбинировать другие агрегатные функции, такие как SUM, AVG и COUNT. Хотя этот метод гибок, он может стать сложным, если нужно преобразовать много столбцов.
Запрос ниже достигает того же результата, что и пример SQL Server PIVOT, условно агрегируя продажи для каждого продукта с использованием оператора CASE.
-- Выбор даты и пивот-столбцов для каждого продукта SELECT Date, -- Использование оператора CASE для создания столбца продаж ноутбуков и мышей SUM(CASE WHEN Product = 'Laptop' THEN Sales ELSE 0 END) AS Laptop, SUM(CASE WHEN Product = 'Mouse' THEN Sales ELSE 0 END) AS Mouse FROM SalesData GROUP BY Date;
Oracle
Oracle поддерживает оператор PIVOT, который позволяет просто преобразить строки в столбцы. Как и в SQL Server, вам нужно явно указать столбцы для преобразования.
В запросе ниже оператор PIVOT преобразует значения ProductName в столбцы и агрегирует SalesAmount с использованием оператора SUM.
SELECT * FROM ( -- Выбор исходных данных SELECT SaleDate, ProductName, SaleAmount FROM SalesData ) PIVOT ( -- Агрегирование продаж по продукту, создание пивот-столбцов SUM(SaleAmount) FOR ProductName IN ('Laptop' AS Laptop, 'Mouse' AS Mouse) );

Пример преобразования вывода с использованием оператора PIVOT в SQL в Oracle. Изображение от автора.
Продвинутые техники преобразования строк в столбцы в SQL
Продвинутые техники преобразования строк в столбцы полезны, когда вам нужна гибкость при работе с сложными данными. Динамические методы и обработка нескольких столбцов одновременно позволяют вам преобразовывать данные в сценариях, где статическое поворотное действие ограничено. Давайте подробнее рассмотрим эти два метода.
Динамические повороты
Динамические повороты позволяют создавать запросы на поворот, которые автоматически адаптируются к изменениям в данных. Эта техника особенно полезна, когда у вас часто меняются столбцы, такие как названия продуктов или категории, и вы хотите, чтобы ваш запрос автоматически включал новые записи без ручного обновления.
Предположим, у нас есть таблица SalesData, и мы можем создать динамическую сводную таблицу, которая будет корректироваться при добавлении новых продуктов. В запросе ниже @columns динамически создает список сводных столбцов, а sp_executesql выполняет сгенерированный SQL.
DECLARE @columns NVARCHAR(MAX), @sql NVARCHAR(MAX); -- Шаг 1: Создание списка уникальных продуктов для сводной таблицы SELECT @columns = STRING_AGG(QUOTENAME(Product), ', ') FROM (SELECT DISTINCT Product FROM SalesData) AS products; -- Шаг 2: Построение динамического SQL-запроса SET @sql = N' SELECT Date, ' + @columns + ' FROM (SELECT Date, Product, Sales FROM SalesData) AS source PIVOT ( SUM(Sales) FOR Product IN (' + @columns + ') ) AS pivot_table;'; -- Шаг 3: Выполнение динамического SQL EXEC sp_executesql @sql;
Обработка нескольких столбцов
В ситуациях, когда необходимо одновременно сводить несколько столбцов, вы будете использовать оператор PIVOT и дополнительные методы агрегации для создания нескольких столбцов в одном запросе.
В приведенном ниже примере я свел столбцы Sales и Quantity по Product.
-- Продажи и количество для ноутбуков и мышей по дате SELECT p1.Date, p1.[Laptop] AS Laptop_Sales, p2.[Laptop] AS Laptop_Quantity, p1.[Mouse] AS Mouse_Sales, p2.[Mouse] AS Mouse_Quantity FROM ( -- Сводная таблица для продаж SELECT Date, [Laptop], [Mouse] FROM (SELECT Date, Product, Sales FROM SalesData) AS source PIVOT (SUM(Sales) FOR Product IN ([Laptop], [Mouse])) AS pivot_sales ) p1 JOIN ( -- Сводная таблица для количества SELECT Date, [Laptop], [Mouse] FROM (SELECT Date, Product, Quantity FROM SalesData) AS source PIVOT (SUM(Quantity) FOR Product IN ([Laptop], [Mouse])) AS pivot_quantity ) p2 ON p1.Date = p2.Date;
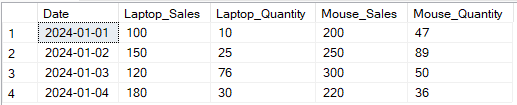
Пример преобразования вывода нескольких столбцов с использованием оператора PIVOT в SQL. Изображение от автора.
Поворот нескольких столбцов позволяет создавать более детальные отчеты, поворачивая несколько атрибутов на один элемент, обеспечивая более глубокие исследования. Однако синтаксис может быть сложным, особенно если существует много столбцов. Может потребоваться жесткое закодирование, если не используются динамические методики поворота, что усложняет процесс.
Заключение
Поворот строк в столбцы – это техника SQL, которую стоит изучить. Я видел использование техник поворота SQL для создания таблицы удержания когорт, где можно отслеживать удержание пользователей со временем. Я также видел использование техник поворота SQL при анализе данных опросов, где каждая строка представляет собой респондента, и каждый вопрос может быть повернут в свой столбец.
Наш курс Отчетность в SQL – отличный выбор, если вы хотите узнать больше о суммировании и подготовке данных для презентации и/или создания панелей управления. Наши карьерные треки Ассоциированный аналитик данных в SQL и Ассоциированный инженер данных в SQL также являются отличной идеей и добавят многое к любому резюме, поэтому записывайтесь сегодня.
Source:
https://www.datacamp.com/tutorial/sql-pivot-rows-to-columns