













Que Signifie Transformer des Lignes en Colonnes en SQL?
Le pivot en SQL fait référence à la transformation des données d’un format basé sur les lignes à un format basé sur les colonnes. Cette transformation est utile pour les rapports et l’analyse de données, permettant une vue de données plus structurée et compacte. Le pivot des lignes aux colonnes permet également aux utilisateurs d’analyser et de résumer les données de manière à mettre en évidence plus clairement les informations clés.
Considérez l’exemple suivant : j’ai une table avec des transactions de ventes quotidiennes, et chaque ligne enregistre la date, le nom du produit et le montant des ventes.
| Date | Product | Sales |
|---|---|---|
| 2024-01-01 | Laptop | 100 |
| 2024-01-01 | Mouse | 200 |
| 2024-01-02 | Laptop | 150 |
| 2024-01-02 | Mouse | 250 |
En pivotant cette table, je peux la restructurer pour afficher chaque produit comme une colonne, avec les données de ventes pour chaque date sous sa colonne correspondante. Remarquez également qu’une agrégation a lieu.
| Date | Laptop | Mouse |
|---|---|---|
| 2024-01-01 | 100 | 200 |
| 2024-01-02 | 150 | 250 |
Traditionnellement, les opérations de pivot nécessitaient des requêtes SQL complexes avec agrégation conditionnelle. Avec le temps, les implémentations SQL ont évolué, de nombreux bases de données modernes incluent désormais les opérateurs PIVOT et UNPIVOT pour permettre des transformations plus efficaces et directes.
Comprendre les lignes de pivot SQL en colonnes
L’opération de pivot SQL transforme les données en transformant les valeurs de lignes en colonnes. Voici la syntaxe de base et la structure du pivot SQL avec les parties suivantes:
-
SELECT: La déclaration
SELECTfait référence aux colonnes à retourner dans la table de pivot SQL. -
Sous-requête: La sous-requête contient la source de données ou la table à inclure dans la table pivot SQL.
-
PIVOT: L’opérateur
PIVOTcontient les agrégations et les filtres à appliquer dans le tableau croisé dynamique.
-- Sélectionnez les colonnes statiques et les colonnes pivotées SELECT <static columns>, [pivoted columns] FROM ( -- Sous-requête définissant les données source pour le pivot <subquery that defines data> ) AS source PIVOT ( -- Fonction d'agrégation appliquée à la colonne de valeur, créant de nouvelles colonnes <aggregation function>(<value column>) FOR <column to pivot> IN ([list of pivoted columns]) ) AS pivot_table;
Prenons l’exemple suivant étape par étape pour démontrer comment pivoter les lignes en colonnes dans SQL. Considérez la table SalesData ci-dessous.

Exemple de tableau à transformer en utilisant l’opérateur SQL PIVOT. Image par l’auteur.
Je veux pivoter ces données pour comparer les ventes quotidiennes de chaque produit. Je commencerai par sélectionner la sous-requête qui va structurer l’opérateur PIVOT.
-- Sous-requête définissant les données source pour le pivot SELECT Date, Product, Sales FROM SalesData;
Maintenant, j’utiliserai l’opérateur PIVOT pour convertir les valeurs de Produit en colonnes et agréger les Ventes en utilisant l’opérateur SUM.
-- Sélectionner la Date et les colonnes pivotées pour chaque produit SELECT Date, [Laptop], [Mouse] FROM ( -- Sous-requête pour récupérer les colonnes Date, Produit et Ventes SELECT Date, Product, Sales FROM SalesData ) AS source PIVOT ( -- Agréger les Ventes par Produit, en pivotant les valeurs des produits en colonnes SUM(Sales) FOR Product IN ([Laptop], [Mouse]) ) AS pivot_table;

Exemple de transformation de sortie en utilisant des lignes pivot SQL en colonnes. Image par l’auteur.
Alors que la pivotisation des données simplifie le résumé des données, cette technique comporte des problèmes potentiels. Voici les défis potentiels avec la pivotisation SQL et comment les résoudre.
-
Noms de colonnes dynamiques: Lorsque les valeurs à pivoter (par exemple, les types de produits) sont inconnues, le codage en dur des noms de colonnes ne fonctionnera pas. Certains bases de données, comme SQL Server, prennent en charge le SQL dynamique avec des procédures stockées pour éviter ce problème, tandis que d’autres nécessitent de gérer cela au niveau de l’application.
-
Gestion des valeurs NULL : Lorsqu’il n’y a pas de données pour une colonne pivotée spécifique, le résultat peut inclure
NULL. Vous pouvez utiliserCOALESCEpour remplacer les valeursNULLpar zéro ou un autre espace réservé. -
Compatibilité entre les bases de données: Toutes les bases de données ne prennent pas en charge directement l’opérateur
PIVOT. Vous pouvez obtenir des résultats similaires avec des déclarationsCASEet une agrégation conditionnelle si votre dialecte SQL ne le permet pas.
Transformation des lignes en colonnes avec SQL Pivot : exemples et cas d’utilisation
Différentes méthodes sont utilisées pour pivoter des données en SQL, en fonction de la base de données utilisée ou d’autres exigences. Alors que l’opérateur PIVOT est couramment utilisé dans SQL Server, d’autres techniques, telles que les déclarations CASE, permettent des transformations de base de données similaires sans prise en charge directe de PIVOT. Je vais couvrir les deux méthodes communes de pivotement des données en SQL, et parler des avantages et des inconvénients.
Utilisation de l’opérateur PIVOT
L’opérateur PIVOT, disponible dans SQL Server, fournit un moyen simple de pivoter des lignes en colonnes en spécifiant une fonction d’agrégation et en définissant les colonnes à pivoter.
Considérez la table suivante nommée sales_data.

Exemple de table des commandes à transformer à l’aide de l’opérateur PIVOT. Image par l’auteur.
Je vais utiliser l’opérateur PIVOT pour agréger les données afin que le total des sales_revenue de chaque année soit affiché dans des colonnes.
-- Utiliser PIVOT pour agréger les revenus des ventes par année SELECT * FROM ( -- Sélectionner les colonnes pertinentes de la table source SELECT sale_year, sales_revenue FROM sales_data ) AS src PIVOT ( -- Agréger les revenus des ventes pour chaque année SUM(sales_revenue) -- Créer des colonnes pour chaque année FOR sale_year IN ([2020], [2021], [2022], [2023]) ) AS piv;

Exemple de transformation de sortie utilisant SQL PIVOT. Image par l’auteur.
L’utilisation de l’opérateur PIVOT présente les avantages et les limitations suivants :
-
Avantages: La méthode est efficace lorsque les colonnes sont correctement indexées. Elle a également une syntaxe simple et plus lisible.
-
Limitations: Toutes les bases de données ne prennent pas en charge l’opérateur
PIVOT. Il est nécessaire de spécifier les colonnes à l’avance, et le pivotement dynamique nécessite une complexité supplémentaire.
Pivotement manuel avec des instructions CASE
Vous pouvez également utiliser les instructions CASE pour pivoter manuellement les données dans des bases de données qui ne prennent pas en charge les opérateurs PIVOT, comme MySQL et PostgreSQL. Cette approche utilise l’agrégation conditionnelle en évaluant chaque ligne et en attribuant conditionnellement des valeurs à de nouvelles colonnes en fonction de critères spécifiques.
Par exemple, nous pouvons pivoter manuellement les données dans la même table sales_data avec des instructions CASE.
-- Agréger les revenus des ventes par an en utilisant des instructions CASE SELECT -- Calculer le chiffre d'affaires total pour chaque année SUM(CASE WHEN sale_year = 2020 THEN sales_revenue ELSE 0 END) AS sales_2020, SUM(CASE WHEN sale_year = 2021 THEN sales_revenue ELSE 0 END) AS sales_2021, SUM(CASE WHEN sale_year = 2022 THEN sales_revenue ELSE 0 END) AS sales_2022, SUM(CASE WHEN sale_year = 2023 THEN sales_revenue ELSE 0 END) AS sales_2023 FROM sales_data;

Exemple de transformation de sortie en utilisant l’instruction SQL CASE. Image par l’auteur.
Utiliser l’instruction CASE pour la transformation présente les avantages et limites suivants :
-
Avantages : La méthode fonctionne sur toutes les bases de données SQL et est flexible pour générer dynamiquement de nouvelles colonnes, même lorsque les noms de produits sont inconnus ou changent fréquemment.
-
Limitations: Les requêtes peuvent devenir complexes et longues s’il y a de nombreuses colonnes à pivoter. En raison des multiples vérifications conditionnelles, cette méthode s’exécute légèrement plus lentement que l’opérateur
PIVOT.
Considérations de performance lors du pivotement des lignes en colonnes
Le pivotement des lignes en colonnes en SQL peut avoir des implications sur les performances, en particulier lors de la manipulation de grands ensembles de données. Voici quelques conseils et bonnes pratiques pour vous aider à rédiger des requêtes pivot efficaces, optimiser leurs performances et éviter les pièges courants.
Meilleures pratiques
Voici les meilleures pratiques pour optimiser vos requêtes et améliorer les performances.
-
Stratégies d’indexation : L’indexation appropriée est cruciale pour optimiser les requêtes pivot, permettant à SQL de récupérer et traiter les données plus rapidement. Indexez toujours les colonnes fréquemment utilisées dans la clause
WHEREou les colonnes que vous regroupez pour réduire les temps de balayage. -
Évitez les pivots imbriqués: Empiler plusieurs opérations de pivot dans une seule requête peut être difficile à lire et plus lent à exécuter. Simplifiez en divisant la requête en parties ou en utilisant une table temporaire.
-
Limitez les colonnes et les lignes dans un pivot: Seules les colonnes pivot sont nécessaires pour l’analyse, car pivoter de nombreuses colonnes peut être gourmand en ressources et créer de grandes tables.
Éviter les pièges courants
Voici les erreurs courantes que vous pouvez rencontrer dans les requêtes pivot et comment les éviter.
-
Scans complets de table inutiles : Les requêtes pivot peuvent déclencher des scans complets de table, en particulier si aucun index pertinent n’est disponible. Évitez les scans complets de table en indexant les colonnes clés et en filtrant les données avant d’appliquer le pivot.
-
Utilisation de SQL Dynamique pour les Pivots Fréquents: L’utilisation de SQL dynamique peut ralentir les performances en raison de la recompilation de la requête. Pour éviter ce problème, mettez en cache ou limitez les pivots dynamiques à des scénarios spécifiques et envisagez de gérer les colonnes dynamiques au niveau de l’application lorsque cela est possible.
-
Regroupement sur de grands ensembles de données sans préfiltrage: Les fonctions d’agrégation telles que
SUMouCOUNTsur de grands ensembles de données peuvent ralentir les performances de la base de données. Au lieu de faire pivoter l’ensemble de données entier, filtrez d’abord les données en utilisant une clauseWHERE. -
Valeurs NULL dans les colonnes basculées : Les opérations de pivot produisent souvent des valeurs
NULLlorsqu’il n’y a pas de données pour une colonne spécifique. Cela peut ralentir les requêtes et rendre les résultats plus difficiles à interpréter. Pour éviter ce problème, utilisez des fonctions commeCOALESCEpour remplacer les valeursNULLpar une valeur par défaut. -
Tests avec des données d’exemple uniquement: Les requêtes pivot peuvent se comporter différemment avec de grands ensembles de données en raison de la demande accrue en mémoire et en traitement. Testez toujours les requêtes pivot sur des données réelles ou représentatives pour évaluer correctement les impacts sur les performances.
Essayez notre parcours professionnel SQL Server Developer, qui couvre tout, des transactions et de la gestion des erreurs à l’amélioration des performances des requêtes.
Implémentations spécifiques à la base de données
Les opérations de pivot diffèrent considérablement d’une base de données à l’autre, telle que SQL Server, MySQL et Oracle. Chacune de ces bases de données dispose d’une syntaxe et de limitations spécifiques. Je présenterai des exemples de pivotement de données dans les différentes bases de données et leurs principales fonctionnalités.
SQL Server
SQL Server offre un opérateur PIVOT intégré, qui est simple lors de la transformation des lignes en colonnes. L’opérateur PIVOT est facile à utiliser et s’intègre aux puissantes fonctions d’agrégation de SQL Server. Les principales caractéristiques du pivotement en SQL incluent les éléments suivants :
-
Support direct pour PIVOT et UNPIVOT : L’opérateur
PIVOTde SQL Server permet une transformation rapide des lignes en colonnes. L’opérateurUNPIVOTpeut également inverser ce processus. -
Options d’agrégation: L’opérateur
PIVOTpermet différentes fonctions d’agrégation, telles queSUM,COUNTetAVG.
La limitation de l’opérateur PIVOT dans SQL Server est que les valeurs de colonne à pivoter doivent être connues à l’avance, le rendant moins flexible pour les données changeantes dynamiquement.
Dans l’exemple ci-dessous, l’opérateur PIVOT convertit les valeurs de Product en colonnes et agrège les Sales en utilisant l’opérateur SUM.
-- Sélectionner la date et les colonnes pivotées pour chaque produit SELECT Date, [Laptop], [Mouse] FROM ( -- Sous-requête pour récupérer les colonnes Date, Produit et Ventes SELECT Date, Product, Sales FROM SalesData ) AS source PIVOT ( -- Agréger les Ventes par Produit, en pivotant les valeurs des produits en colonnes SUM(Sales) FOR Product IN ([Laptop], [Mouse]) ) AS pivot_table;
Je recommande de suivre le cours Introduction à SQL Server de DataCamp pour maîtriser les bases de SQL Server pour l’analyse de données.
MySQL
MySQL ne prend pas en charge nativement l’opérateur PIVOT. Cependant, vous pouvez utiliser l’instruction CASE pour pivoter manuellement les lignes en colonnes et combiner d’autres fonctions d’agrégation comme SUM, AVG et COUNT. Bien que cette méthode soit flexible, elle peut devenir complexe si vous avez de nombreuses colonnes à pivoter.
La requête ci-dessous permet d’obtenir le même résultat que l’exemple de la fonction PIVOT de SQL Server en regroupant conditionnellement les ventes pour chaque produit à l’aide de l’instruction CASE.
-- Sélectionner la date et les colonnes pivotées pour chaque produit SELECT Date, -- Utiliser CASE pour créer une colonne pour les ventes d'ordinateurs portables et de souris SUM(CASE WHEN Product = 'Laptop' THEN Sales ELSE 0 END) AS Laptop, SUM(CASE WHEN Product = 'Mouse' THEN Sales ELSE 0 END) AS Mouse FROM SalesData GROUP BY Date;
Oracle
Oracle prend en charge l’opérateur PIVOT, qui permet de transformer facilement les lignes en colonnes. Tout comme SQL Server, vous devrez spécifier explicitement les colonnes à transformer.
Dans la requête ci-dessous, l’opérateur PIVOT convertit les valeurs de ProductName en colonnes et agrège SalesAmount à l’aide de l’opérateur SUM.
SELECT * FROM ( -- Sélection des données source SELECT SaleDate, ProductName, SaleAmount FROM SalesData ) PIVOT ( -- Agréger les ventes par produit, en créant des colonnes pivotées SUM(SaleAmount) FOR ProductName IN ('Laptop' AS Laptop, 'Mouse' AS Mouse) );

Exemple de transformation de sortie en utilisant l’opérateur PIVOT en SQL dans Oracle. Image par l’auteur.
Techniques Avancées pour Pivoter des Lignes en Colonnes en SQL
Les techniques avancées pour pivoter des lignes en colonnes sont utiles lorsque vous avez besoin de flexibilité dans le traitement de données complexes. Les techniques dynamiques et la manipulation de plusieurs colonnes simultanément vous permettent de transformer des données dans des scénarios où le pivot statique est limité. Explorons ces deux méthodes en détail.
Pivots dynamiques
Les pivots dynamiques vous permettent de créer des requêtes de pivot qui s’adaptent automatiquement aux changements dans les données. Cette technique est particulièrement utile lorsque vous avez des colonnes qui changent fréquemment, telles que les noms de produits ou les catégories, et que vous voulez que votre requête inclue automatiquement les nouvelles entrées sans avoir à la mettre à jour manuellement.
Supposons que nous ayons une table SalesData et puissions créer un pivot dynamique qui s’ajuste si de nouveaux produits sont ajoutés. Dans la requête ci-dessous, @columns construit dynamiquement la liste des colonnes pivotées, et sp_executesql exécute le SQL généré.
DECLARE @columns NVARCHAR(MAX), @sql NVARCHAR(MAX); -- Étape 1 : Générer une liste de produits distincts à pivoter SELECT @columns = STRING_AGG(QUOTENAME(Product), ', ') FROM (SELECT DISTINCT Product FROM SalesData) AS products; -- Étape 2 : Construire la requête SQL dynamique SET @sql = N' SELECT Date, ' + @columns + ' FROM (SELECT Date, Product, Sales FROM SalesData) AS source PIVOT ( SUM(Sales) FOR Product IN (' + @columns + ') ) AS pivot_table;'; -- Étape 3 : Exécuter le SQL dynamique EXEC sp_executesql @sql;
Gestion de plusieurs colonnes
Dans les scénarios où vous devez pivoter plusieurs colonnes simultanément, vous utiliserez l’opérateur PIVOT et des techniques d’agrégation supplémentaires pour créer plusieurs colonnes dans la même requête.
Dans l’exemple ci-dessous, j’ai pivoté les colonnes Sales et Quantity par Product.
-- Ventes et quantité pivot pour ordinateur portable et souris par date SELECT p1.Date, p1.[Laptop] AS Laptop_Sales, p2.[Laptop] AS Laptop_Quantity, p1.[Mouse] AS Mouse_Sales, p2.[Mouse] AS Mouse_Quantity FROM ( -- Pivot pour les ventes SELECT Date, [Laptop], [Mouse] FROM (SELECT Date, Product, Sales FROM SalesData) AS source PIVOT (SUM(Sales) FOR Product IN ([Laptop], [Mouse])) AS pivot_sales ) p1 JOIN ( -- Pivot pour la quantité SELECT Date, [Laptop], [Mouse] FROM (SELECT Date, Product, Quantity FROM SalesData) AS source PIVOT (SUM(Quantity) FOR Product IN ([Laptop], [Mouse])) AS pivot_quantity ) p2 ON p1.Date = p2.Date;
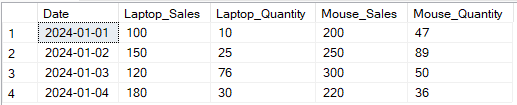
Exemple de transformation de sortie de plusieurs colonnes en utilisant l’opérateur PIVOT SQL. Image par l’auteur.
Le pivotement de plusieurs colonnes permet des rapports plus détaillés en pivotant plusieurs attributs par article, permettant des insights plus riches. Cependant, la syntaxe peut être complexe, surtout s’il existe de nombreuses colonnes. Le codage en dur peut être nécessaire sauf s’il est combiné avec des techniques de pivotement dynamique, ajoutant une complexité supplémentaire.
Conclusion
Le pivotement des lignes en colonnes est une technique SQL qui vaut la peine d’être apprise. J’ai vu des techniques de pivot SQL utilisées pour créer un tableau de rétention de cohorte, où vous pourriez suivre la rétention des utilisateurs au fil du temps. J’ai également vu des techniques de pivot SQL utilisées lors de l’analyse de données d’enquête, où chaque ligne représente un répondant, et chaque question peut être pivotée dans sa propre colonne.
Notre cours Reporting en SQL est une excellente option si vous souhaitez en apprendre davantage sur la synthèse et la préparation des données pour la présentation et/ou la construction de tableaux de bord. Nos parcours professionnels Analyste de données associé en SQL et Ingénieur de données associé en SQL sont également une excellente idée, et ils ajoutent beaucoup à tout CV, alors inscrivez-vous dès aujourd’hui.
Source:
https://www.datacamp.com/tutorial/sql-pivot-rows-to-columns