













SQL에서 행을 열로 피벗하는 것이 의미하는 바는 무엇인가요?
SQL에서의 피벗은 데이터를 행 기반 형식에서 열 기반 형식으로 변환하는 것을 의미합니다. 이 변환은 보고 및 데이터 분석에 유용하며, 더 구조화되고 간결한 데이터 뷰를 제공합니다. 행을 열로 피벗하면 사용자가 데이터를 분석하고 요약하여 핵심 통찰을 더 명확하게 강조할 수 있습니다.
다음 예를 고려해보세요: 매일의 판매 거래를 기록한 테이블이 있고, 각 행에는 날짜, 제품 이름 및 판매 금액이 기록되어 있습니다.
| Date | Product | Sales |
|---|---|---|
| 2024-01-01 | Laptop | 100 |
| 2024-01-01 | Mouse | 200 |
| 2024-01-02 | Laptop | 150 |
| 2024-01-02 | Mouse | 250 |
이 테이블을 피벗함으로써 각 제품을 열로 나타내고, 각 날짜의 판매 데이터를 해당 열 아래에 표시할 수 있습니다. 또한 집계가 이루어집니다.
| Date | Laptop | Mouse |
|---|---|---|
| 2024-01-01 | 100 | 200 |
| 2024-01-02 | 150 | 250 |
전통적으로, 피벗 작업은 조건부 집계를 사용한 복잡한 SQL 쿼리가 필요했습니다. 시간이 지나면서 SQL 구현은 발전해, 현대의 많은 데이터베이스에는 이제 더 효율적이고 간편한 변환을 가능하게 하는 PIVOT 및 UNPIVOT 연산자가 포함되어 있습니다.
SQL Pivot 행을 열로 변환하는 방법 이해하기
SQL pivot 작업은 행 값을 열로 변환하여 데이터를 변환합니다. 다음은 SQL pivot의 기본 구문과 구조이며 다음과 같은 부분으로 구성됩니다:
-
SELECT:
SELECT문은 SQL pivot 테이블에서 반환할 열을 참조합니다. -
서브쿼리: 서브쿼리는 SQL 피벗 테이블에 포함될 데이터 원본 또는 테이블을 포함합니다.
-
PIVOT: 피벗:
PIVOT연산자는 피벗 테이블에 적용할 집계 및 필터를 포함합니다.
-- 정적 열 및 피벗된 열 선택 SELECT <static columns>, [pivoted columns] FROM ( -- 피벗용 원본 데이터를 정의하는 서브쿼리 <subquery that defines data> ) AS source PIVOT ( -- 값 열에 적용된 집계 함수, 새로운 열 생성 <aggregation function>(<value column>) FOR <column to pivot> IN ([list of pivoted columns]) ) AS pivot_table;
다음 단계별 예제를 살펴보며 SQL에서 행을 열로 피벗하는 방법을 설명해보겠습니다. 아래 SalesData 테이블을 고려해주세요.

SQL PIVOT 연산자를 사용하여 변환할 테이블 예시. 저자 제공 이미지.
이 데이터를 피벗하여 각 제품의 일일 매출을 비교하려고 합니다. 먼저 PIVOT 연산자를 구조화할 서브쿼리를 선택합니다.
-- 피벗할 소스 데이터를 정의하는 서브쿼리 SELECT Date, Product, Sales FROM SalesData;
이제 PIVOT 연산자를 사용하여 Product 값을 열로 변환하고 Sales를 SUM 연산자를 사용하여 집계합니다.
-- 날짜와 각 제품의 피벗된 열 선택 SELECT Date, [Laptop], [Mouse] FROM ( -- 날짜, 제품 및 매출 열을 가져오는 서브쿼리 SELECT Date, Product, Sales FROM SalesData ) AS source PIVOT ( -- 제품별 매출을 집계하고 제품 값을 열로 피벗 SUM(Sales) FOR Product IN ([Laptop], [Mouse]) ) AS pivot_table;

SQL 피벗 행을 열로 변환한 예시 출력 변환. 저자 제공 이미지.
데이터 피벗화는 데이터 요약을 간단하게 만들지만, 이 기술에는 잠재적인 문제가 있습니다. 다음은 SQL 피벗의 잠재적인 도전 과제 및 해결 방법입니다.
-
동적 열 이름: 피벗할 값(예: 제품 유형)이 알려지지 않은 경우, 열 이름을 하드코딩하는 것은 작동하지 않습니다. SQL Server와 같은 일부 데이터베이스는 이 문제를 피하기 위해 저장 프로시저로 동적 SQL을 지원하며, 다른 데이터베이스는 응용 프로그램 레이어에서 이를 처리해야 합니다.
-
NULL 값 다루기: 특정한 피벗된 열에 대한 데이터가 없는 경우 결과에는
NULL이 포함될 수 있습니다.COALESCE를 사용하여NULL값을 0이나 다른 값으로 대체할 수 있습니다. -
데이터베이스 간 호환성: 모든 데이터베이스가
PIVOT연산자를 직접 지원하지는 않습니다. SQL 방언에서 지원하지 않는 경우CASE문과 조건부 집계를 사용하여 유사한 결과를 얻을 수 있습니다.
SQL Pivot 행을 열로 변환: 예제 및 사용 사례
SQL에서 데이터를 Pivot하는 데 사용되는 방법은 사용되는 데이터베이스나 다른 요구 사항에 따라 다릅니다. SQL Server에서는 PIVOT 연산자가 일반적으로 사용되지만 CASE 문과 같은 다른 기술을 사용하면 PIVOT 지원 없이도 유사한 데이터베이스 변환을 수행할 수 있습니다. SQL에서 데이터를 Pivot하는 두 가지 일반적인 방법과 그 장단점에 대해 다룰 것입니다.
PIVOT 연산자 사용하기
PIVOT 연산자는 SQL Server에서 제공되며 집계 함수를 지정하고 Pivot할 열을 정의하여 행을 열로 Pivot하는 간단한 방법을 제공합니다.
다음과 같이 sales_data라는 테이블을 고려해보십시오.

PIVOT 연산자를 사용하여 변환할 예제 주문 테이블. 저자 제공 이미지.
나는 데이터를 집계하기 위해 PIVOT 연산자를 사용하여 각 연도의 총 sales_revenue이 열에 표시되도록 할 것이다.
-- 연도별로 매출액을 집계하기 위해 PIVOT 사용 SELECT * FROM ( -- 원본 테이블에서 관련 열을 선택 SELECT sale_year, sales_revenue FROM sales_data ) AS src PIVOT ( -- 각 연도별 매출액 집계 SUM(sales_revenue) -- 각 연도를 위한 열 생성 FOR sale_year IN ([2020], [2021], [2022], [2023]) ) AS piv;

SQL PIVOT를 사용한 예시 출력 변환. 저자 이미지.
PIVOT 연산자를 사용하는 것에는 다음과 같은 장단점이 있다:
-
장점: 열이 적절하게 색인화된 경우 효율적인 방법입니다. 또한 간단하고 가독성이 높은 구문을 갖추고 있습니다.
-
제한 사항: 모든 데이터베이스가
PIVOT연산자를 지원하지는 않습니다. 열을 미리 지정해야 하며, 동적 피벗팅은 추가 복잡성을 요구합니다.
CASE 문으로 수동 피봇
PIVOT 연산자를 지원하지 않는 MySQL 및 PostgreSQL과 같은 데이터베이스에서 데이터를 수동으로 피벗하는 데 CASE 문을 사용할 수도 있습니다. 이 접근 방식은 각 행을 평가하고 특정 기준에 따라 새 열에 값을 조건부로 할당함으로써 조건부 집계를 사용합니다.
예를 들어, 우리는 동일한 sales_data 테이블에서 CASE 문을 사용하여 데이터를 수동으로 피벗할 수 있습니다.
-- CASE 문을 사용하여 연도별 매출 수익 집계 SELECT -- 각 연도별 총 매출 수익 계산 SUM(CASE WHEN sale_year = 2020 THEN sales_revenue ELSE 0 END) AS sales_2020, SUM(CASE WHEN sale_year = 2021 THEN sales_revenue ELSE 0 END) AS sales_2021, SUM(CASE WHEN sale_year = 2022 THEN sales_revenue ELSE 0 END) AS sales_2022, SUM(CASE WHEN sale_year = 2023 THEN sales_revenue ELSE 0 END) AS sales_2023 FROM sales_data;

SQL CASE 문을 사용한 예제 출력 변환입니다. 작성자에 의한 이미지입니다.
CASE 문을 사용한 변환은 다음과 같은 장점과 제한 사항이 있습니다:
-
장점: 이 방법은 모든 SQL 데이터베이스에서 작동하며, 제품 이름이 알려지지 않거나 자주 변경되는 경우에도 동적으로 새로운 열을 생성하는 데 유연합니다.
-
제한 사항: 많은 열을 피벗해야 하는 경우 쿼리가 복잡하고 길어질 수 있습니다. 여러 조건 확인으로 인해 이 방법은
PIVOT연산자보다 약간 느리게 실행됩니다.
행을 열로 피벗할 때의 성능 고려 사항
SQL에서 행을 열로 피벗하는 것은 대규모 데이터셋과 작업할 때 성능에 영향을 줄 수 있습니다. 효율적인 피벗 쿼리를 작성하고 성능을 최적화하며 일반적인 함정을 피하기 위한 몇 가지 팁과 모범 사례가 있습니다.
모범 사례
다음은 쿼리를 최적화하고 성능을 향상시키는 데 도움이 되는 최상의 방법론입니다.
-
인덱싱 전략: 피벗 쿼리를 최적화하기 위해 적절한 인덱싱이 중요합니다. SQL이 데이터를 더 빨리 검색하고 처리할 수 있게 합니다. 항상
WHERE절에서 자주 사용되는 열이나 그룹화하는 열에 인덱스를 생성하여 스캔 시간을 줄입니다. -
중첩된 피벗을 피하십시오: 하나의 쿼리에 여러 피벗 작업을 쌓으면 읽기 어렵고 실행 속도가 느릴 수 있습니다. 쿼리를 여러 부분으로 나누거나 임시 테이블을 사용하여 단순화하세요.
-
피벗에서 열과 행 제한: 분석에는 피벗 열만 필요하며, 많은 열을 피벗하면 리소스를 많이 사용하고 큰 테이블을 만들 수 있습니다.
흔한 함정 피하기
다음은 피벗 쿼리에서 마주치는 흔한 실수들과 그 피하는 방법입니다.
-
불필요한 전체 테이블 스캔: 특히 관련 인덱스가 없는 경우, 피벗 쿼리는 전체 테이블 스캔을 유발할 수 있습니다. 핵심 열에 인덱스를 걸고 피벗을 적용하기 전에 데이터를 필터링하여 전체 테이블 스캔을 피하세요.
-
빈번한 피벗 작업에 동적 SQL 사용: 동적 SQL을 사용하면 쿼리 재컴파일로 인해 성능이 저하될 수 있습니다. 이 문제를 피하기 위해 동적 피벗을 캐시하거나 제한하여 특정 시나리오에 적용하고 가능한 경우 동적 열을 응용프로그램 계층에서 처리하는 것을 고려하십시오.
-
사전 필터링 없이 대규모 데이터 집계: 대규모 데이터셋에서
SUM또는COUNT와 같은 집계 함수를 사용하면 데이터베이스 성능이 떨어질 수 있습니다. 전체 데이터셋을 피벗하는 대신WHERE절을 사용하여 데이터를 먼저 필터링하십시오. -
피벗된 열의 NULL 값: 피벗 작업은 특정 열에 데이터가 없을 때
NULL값을 생성하는 경우가 많습니다. 이는 쿼리 성능을 떨어뜨리고 결과 해석을 어렵게 만들 수 있습니다. 이 문제를 피하기 위해COALESCE와 같은 함수를 사용하여NULL값을 기본값으로 대체하세요. -
샘플 데이터로만 테스트하기: 피벗 쿼리는 대용량 데이터셋에서는 메모리와 처리 요구사항이 증가하여 다르게 작동할 수 있습니다. 성능 영향을 정확히 평가하기 위해 항상 실제 또는 대표적인 데이터 샘플에서 피벗 쿼리를 테스트하세요.
SQL Server Developer 커리어 트랙을 시도해보세요. 이 트랙은 트랜잭션 및 오류 처리부터 쿼리 성능 향상까지 모두 다룹니다.
데이터베이스별 구현
SQL Server, MySQL, Oracle 등과 같은 데이터베이스 간에 피벗 작업은 매우 다릅니다. 각 데이터베이스마다 특정 구문과 제한 사항이 있습니다. 다양한 데이터베이스에서 데이터를 피벗하는 예제와 주요 기능을 다룰 것입니다.
SQL Server
SQL Server은 내장 PIVOT 연산자를 제공하며, 행을 열로 피벗하는 경우 간단합니다. PIVOT 연산자는 사용하기 쉽고 SQL Server의 강력한 집계 함수와 통합됩니다. SQL에서의 피벗의 주요 기능은 다음과 같습니다:
-
PIVOT 및 UNPIVOT에 대한 직접 지원: SQL Server의
PIVOT연산자는 빠른 행-열 변환을 가능하게 합니다.UNPIVOT연산자는 이 과정을 반대로 수행할 수도 있습니다. -
집계 옵션:
PIVOT연산자는SUM,COUNT,AVG와 같은 다양한 집계 함수를 사용할 수 있습니다.
SQL Server의 PIVOT 연산자의 한계는 피벗될 열 값이 미리 알려져 있어 동적으로 변하는 데이터에 대해 유연성이 떨어진다는 점입니다.
아래 예시에서 PIVOT 연산자는 Product 값을 열로 변환하고 SUM 연산자를 사용하여 Sales를 집계합니다.
-- 각 제품에 대한 날짜 및 피벗된 열 선택 SELECT Date, [Laptop], [Mouse] FROM ( -- 날짜, 제품 및 판매 열을 가져오기 위한 서브쿼리 SELECT Date, Product, Sales FROM SalesData ) AS source PIVOT ( -- 제품별로 판매 집계, 제품 값을 열로 피벗 SUM(Sales) FOR Product IN ([Laptop], [Mouse]) ) AS pivot_table;
DataCamp의 SQL Server 소개 코스를 추천하여 데이터 분석을 위한 SQL Server의 기본을 습득하세요.
MySQL
MySQL은 PIVOT 연산자를 네이티브로 지원하지 않습니다. 그러나 CASE 문을 사용하여 수동으로 행을 열로 피벗하고 SUM, AVG, COUNT와 같은 다른 집계 함수를 결합할 수 있습니다. 이 방법은 유연하긴 하지만 많은 열을 피벗해야 한다면 복잡해질 수 있습니다.
아래 쿼리는 각 제품의 판매를 조건부 집계하여 CASE 문을 사용하여 SQL Server의 PIVOT 예제와 동일한 결과를 얻습니다.
-- 각 제품에 대한 날짜 및 피벗된 열 선택 SELECT Date, -- 노트북 및 마우스 판매를 위한 열 생성에 CASE 사용 SUM(CASE WHEN Product = 'Laptop' THEN Sales ELSE 0 END) AS Laptop, SUM(CASE WHEN Product = 'Mouse' THEN Sales ELSE 0 END) AS Mouse FROM SalesData GROUP BY Date;
Oracle
Oracle은 행을 열로 직접 변환하는 PIVOT 연산자를 지원합니다. SQL Server와 마찬가지로 변환할 열을 명시적으로 지정해야 합니다.
아래 쿼리에서 PIVOT 연산자는 ProductName 값을 열로 변환하고 SalesAmount를 SUM 연산자를 사용하여 집계합니다.
SELECT * FROM ( -- 소스 데이터 선택 SELECT SaleDate, ProductName, SaleAmount FROM SalesData ) PIVOT ( -- 제품별 판매 집계, 피벗된 열 생성 SUM(SaleAmount) FOR ProductName IN ('Laptop' AS Laptop, 'Mouse' AS Mouse) );

오라클에서 SQL PIVOT 연산자를 사용한 예제 출력 변환. 저자에 의한 이미지.
SQL에서 행을 열로 변환하는 고급 기술
행을 열로 변환하는 고급 기술은 복잡한 데이터를 처리할 때 유연성이 필요한 경우 유용합니다. 동적 기술과 여러 열을 동시에 처리하는 것은 정적 피벗팅이 제한적인 시나리오에서 데이터를 변환할 수 있도록 합니다. 이 두 가지 방법을 자세히 살펴보겠습니다.
동적 피벗
동적 피벗은 데이터의 변경에 자동으로 적응하는 피벗 쿼리를 생성할 수 있습니다. 이 기술은 제품 이름이나 카테고리와 같이 자주 변경되는 열이 있는 경우 특히 유용하며, 수동으로 업데이트하지 않고도 새 항목을 쿼리에 자동으로 포함시키고 싶을 때 유용합니다.
우리가 SalesData 테이블을 가지고 있고, 새로운 제품이 추가되면 동적 피벗을 생성할 수 있습니다. 아래 쿼리에서 @columns은 동적으로 피벗된 열의 목록을 작성하고, sp_executesql은 생성된 SQL을 실행합니다.
DECLARE @columns NVARCHAR(MAX), @sql NVARCHAR(MAX); -- 단계 1: 피벗할 고유 제품 목록 생성 SELECT @columns = STRING_AGG(QUOTENAME(Product), ', ') FROM (SELECT DISTINCT Product FROM SalesData) AS products; -- 단계 2: 동적 SQL 쿼리 작성 SET @sql = N' SELECT Date, ' + @columns + ' FROM (SELECT Date, Product, Sales FROM SalesData) AS source PIVOT ( SUM(Sales) FOR Product IN (' + @columns + ') ) AS pivot_table;'; -- 단계 3: 동적 SQL 실행 EXEC sp_executesql @sql;
여러 열 다루기
여러 열을 동시에 피벗해야 하는 시나리오에서는 PIVOT 연산자를 사용하고 추가 집계 기술을 사용하여 동일한 쿼리에서 여러 열을 생성합니다.
아래 예시에서 Product로 Sales와 Quantity 열을 피벗했습니다.
-- 날짜별 노트북 및 마우스의 매출 및 수량에 대한 Pivot SELECT p1.Date, p1.[Laptop] AS Laptop_Sales, p2.[Laptop] AS Laptop_Quantity, p1.[Mouse] AS Mouse_Sales, p2.[Mouse] AS Mouse_Quantity FROM ( -- 매출을 위한 Pivot SELECT Date, [Laptop], [Mouse] FROM (SELECT Date, Product, Sales FROM SalesData) AS source PIVOT (SUM(Sales) FOR Product IN ([Laptop], [Mouse])) AS pivot_sales ) p1 JOIN ( -- 수량을 위한 Pivot SELECT Date, [Laptop], [Mouse] FROM (SELECT Date, Product, Quantity FROM SalesData) AS source PIVOT (SUM(Quantity) FOR Product IN ([Laptop], [Mouse])) AS pivot_quantity ) p2 ON p1.Date = p2.Date;
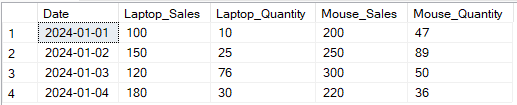
SQL PIVOT 연산자를 사용하여 여러 열의 예제 출력 변환. 저자에 의한 이미지.
여러 열을 Pivot하면 항목당 여러 속성을 Pivot하여 더 세부적인 보고서를 작성할 수 있으며, 더 풍부한 통찰력을 제공합니다. 그러나 많은 열이 존재하는 경우 구문이 복잡할 수 있습니다. 동적 Pivot 기술과 결합하지 않으면 하드코딩이 필요할 수 있으며, 이는 더 많은 복잡성을 추가합니다.
결론
행을 열로 Pivot하는 것은 배울 가치가 있는 SQL 기술입니다. SQL Pivot 기술이 사용된 코호트 유지 테이블을 생성하거나 사용자 유지율을 추적할 수 있는 경우, 또한 설문 데이터를 분석할 때 각 행이 응답자를 나타내고 각 질문이 열로 Pivot되는 경우를 본 적이 있습니다.
우리의 SQL 보고서 작성 과정은 데이터 요약 및 프레젠테이션 및/또는 대시보드 작성을 배우고 싶다면 좋은 선택입니다. 우리의 SQL 데이터 분석가 어소시에이트 와 SQL 데이터 엔지니어 어소시에이트 커리어 트랙은 또 다른 훌륭한 아이디어이며 이는 이력서에 많은 가치를 더해줍니다. 그러니 오늘 등록하세요.
Source:
https://www.datacamp.com/tutorial/sql-pivot-rows-to-columns