













What Does it Mean to Pivot Rows to Columns in SQL?
Pivoting in SQL refers to transforming data from a row-based format to a column-based format. This transformation is useful for reporting and data analysis, allowing for a more structured and compact data view. Pivoting rows to columns also allows users to analyze and summarize data in a way that highlights key insights more clearly.
Consider the following example: I have a table with daily sales transactions, and each row records the date, product name, and sales amount.
| Date | Product | Sales |
|---|---|---|
| 2024-01-01 | Laptop | 100 |
| 2024-01-01 | Mouse | 200 |
| 2024-01-02 | Laptop | 150 |
| 2024-01-02 | Mouse | 250 |
By pivoting this table, I can restructure it to show each product as a column, with sales data for each date under its corresponding column. Notice also that an aggregation takes place.
| Date | Laptop | Mouse |
|---|---|---|
| 2024-01-01 | 100 | 200 |
| 2024-01-02 | 150 | 250 |
Traditionally, pivot operations required complex SQL queries with conditional aggregation. Over time, SQL implementations have evolved, with many modern databases now including PIVOT and UNPIVOT operators to allow for more efficient and straightforward transformations.
Understanding SQL Pivot Rows to Columns
The SQL pivot operation transforms data by turning row values into columns. The following is the basic syntax and structure of SQL pivot with the following parts:
-
SELECT: The
SELECTstatement references the columns to return in the SQL pivot table. -
Subquery: The subquery contains the data source or table to be included in the SQL pivot table.
-
PIVOT: The
PIVOToperator contains the aggregations and filter to be applied in the pivot table.
-- Select static columns and pivoted columns SELECT <static columns>, [pivoted columns] FROM ( -- Subquery defining source data for pivot <subquery that defines data> ) AS source PIVOT ( -- Aggregate function applied to value column, creating new columns <aggregation function>(<value column>) FOR <column to pivot> IN ([list of pivoted columns]) ) AS pivot_table;
Let us look at the following step-by-step example to demonstrate how to pivot rows to columns in SQL. Consider the SalesData table below.

Example of table to transform using SQL PIVOT operator. Image by Author.
I want to pivot this data to compare each product’s daily sales. I will begin by selecting the subquery that will structure the PIVOT operator.
-- Subquery defining source data for pivot SELECT Date, Product, Sales FROM SalesData;
Now, I will use the PIVOT operator to convert Product values into columns and aggregate Sales using the SUM operator.
-- Select Date and pivoted columns for each product SELECT Date, [Laptop], [Mouse] FROM ( -- Subquery to fetch Date, Product, and Sales columns SELECT Date, Product, Sales FROM SalesData ) AS source PIVOT ( -- Aggregate Sales by Product, pivoting product values to columns SUM(Sales) FOR Product IN ([Laptop], [Mouse]) ) AS pivot_table;

Example output transformation using SQL pivot rows to columns. Image by Author.
While pivoting data simplifies data summary, this technique has potential issues. The following are the potential challenges with SQL pivot and how to address them.
-
Dynamic Column Names: When the values to pivot (e.g., Product types) are unknown, hardcoding column names won’t work. Some databases, like SQL Server, support dynamic SQL with stored procedures to avoid this issue, while others require handling this at the application layer.
-
Dealing with NULL Values: When there’s no data for a specific pivoted column, the result may include
NULL. You can useCOALESCEto replaceNULLvalues with zero or another placeholder. -
Compatibility Across Databases: Not all databases directly support the
PIVOToperator. You can achieve similar results withCASEstatements and conditional aggregation if your SQL dialect doesn’t.
SQL Pivot Rows to Columns: Examples and Use Cases
Different methods are used to pivot data in SQL, depending on the database used or other requirements. While the PIVOT operator is commonly used in SQL Server, other techniques, such as the CASE statements, allow for similar database transformations without direct PIVOT support. I will cover the two common methods of pivoting data in SQL, and talk about the pros and cons.
Using the PIVOT operator
The PIVOT operator, available in SQL Server, provides a straightforward way to pivot rows to columns by specifying an aggregation function and defining the columns to pivot.
Consider the following table named sales_data.

Example Orders table to transform using PIVOT operator. Image by Author.
I will use the PIVOT operator to aggregate the data so that each year’s total sales_revenue is shown in columns.
-- Use PIVOT to aggregate sales revenue by year SELECT * FROM ( -- Select the relevant columns from the source table SELECT sale_year, sales_revenue FROM sales_data ) AS src PIVOT ( -- Aggregate sales revenue for each year SUM(sales_revenue) -- Create columns for each year FOR sale_year IN ([2020], [2021], [2022], [2023]) ) AS piv;

Example output transformation using SQL PIVOT. Image by Author.
Using the PIVOT operator has the following advantages and limitations:
-
Advantages: The method is efficient when columns are properly indexed. It also has a simple, more readable syntax.
-
Limitations: Not all databases support the
PIVOToperator. It requires specifying the columns in advance, and dynamic pivoting requires additional complexity.
Manual pivoting with CASE statements
You can also use the CASE statements to manually pivot data in databases that do not support PIVOT operators, such as MySQL and PostgreSQL. This approach uses conditional aggregation by evaluating each row and conditionally assigning values to new columns based on specific criteria.
For example, we can manually pivot data in the same sales_data table with CASE statements.
-- Aggregate sales revenue by year using CASE statements SELECT -- Calculate total sales revenue for each year SUM(CASE WHEN sale_year = 2020 THEN sales_revenue ELSE 0 END) AS sales_2020, SUM(CASE WHEN sale_year = 2021 THEN sales_revenue ELSE 0 END) AS sales_2021, SUM(CASE WHEN sale_year = 2022 THEN sales_revenue ELSE 0 END) AS sales_2022, SUM(CASE WHEN sale_year = 2023 THEN sales_revenue ELSE 0 END) AS sales_2023 FROM sales_data;

Example output transformation using SQL CASE statement. Image by Author.
Using the CASE statement for transformation has the following advantages and limitations:
-
Advantages: The method works across all SQL databases and is flexible for dynamically generating new columns, even when product names are unknown or change frequently.
-
Limitations: Queries can become complex and lengthy if there are many columns to pivot. Due to the multiple conditional checks, the method performs slightly slower than the
PIVOToperator.
Performance Considerations When Pivoting Rows to Columns
Pivoting rows to columns in SQL can have performance implications, especially when working with large datasets. Here are some tips and best practices to help you write efficient pivot queries, optimize their performance, and avoid common pitfalls.
Best practices
The following are the best practices to optimize your queries and improve performance.
-
Indexing Strategies: Proper indexing is crucial for optimizing pivot queries, allowing SQL to retrieve and process data faster. Always index the columns frequently used in the
WHEREclause or the columns you’re grouping to reduce the scan times. -
Avoid Nested Pivots: Stacking multiple pivot operations in one query can be hard to read and slower to execute. Simplify by breaking the query into parts or using a temporary table.
-
Limit Columns and Rows in Pivot: Only pivot columns are necessary for the analysis since pivoting many columns can be resource-intensive and create large tables.
Avoiding common pitfalls
The following are the common mistakes you may encounter in pivot queries and how to avoid them.
-
Unnecessary Full Table Scans: Pivot queries can trigger full table scans, especially if no relevant indexes are available. Avoid full table scans by indexing key columns and filtering data before applying the pivot.
-
Using Dynamic SQL for Frequent Pivoting: Using dynamic SQL can slow down performance due to query recompilation. To avoid this problem, cache or limit dynamic pivots to specific scenarios and consider handling dynamic columns in the application layer when possible.
-
Aggregating on Large Datasets Without Pre-filtering: Aggregation functions like
SUMorCOUNTon large datasets can slow database performance. Instead of pivoting the entire dataset, filter the data first using aWHEREclause. -
NULL Values in Pivoted Columns: Pivot operations often produce
NULLvalues when there’s no data for a specific column. These can slow down queries and make results harder to interpret. To avoid this problem, use functions likeCOALESCEto replaceNULLvalues with a default. -
Testing with Sample Data Only: Pivot queries can behave differently with large datasets due to increased memory and processing demands. Always test pivot queries on real or representative data samples to assess performance impacts accurately.
Try our SQL Server Developer career track, which covers everything from transactions and error handling to improving query performance.
Database-Specific Implementations
Pivot operations significantly differ across databases such as SQL Server, MySQL, and Oracle. Each of these databases has specific syntax and limitations. I will cover examples of pivoting data in the different databases and their key features.
SQL Server
SQL Server provides a built-in PIVOT operator, which is straightforward when pivoting rows to columns. The PIVOT operator is easy to use and integrates with SQL Server’s powerful aggregation functions. The key features of pivoting in SQL include the following:
-
Direct Support for PIVOT and UNPIVOT: SQL Server’s
PIVOToperator allows quick row-to-column transformation. TheUNPIVOToperator can also reverse this process. -
Aggregation Options: The
PIVOToperator allows various aggregation functions, such asSUM,COUNT, andAVG.
The limitation of the PIVOT operator in SQL Server is that it requires that column values to be pivoted are known in advance, making it less flexible for dynamically changing data.
In the example below, the PIVOT operator converts Product values into columns and aggregates Sales using the SUM operator.
-- Select Date and pivoted columns for each product SELECT Date, [Laptop], [Mouse] FROM ( -- Subquery to fetch Date, Product, and Sales columns SELECT Date, Product, Sales FROM SalesData ) AS source PIVOT ( -- Aggregate Sales by Product, pivoting product values to columns SUM(Sales) FOR Product IN ([Laptop], [Mouse]) ) AS pivot_table;
I recommend taking DataCamp’s Introduction to SQL Server course to master the basics of SQL Server for data analysis.
MySQL
MySQL lacks native support for the PIVOT operator. However, you can use the CASE statement to manually pivot rows to columns and combine other aggregate functions like SUM, AVG, and COUNT. Although this method is flexible, it can become complex if you have many columns to pivot.
The query below achieves the same output as the SQL Server PIVOT example by conditionally aggregating sales for each product using the CASE statement.
-- Select Date and pivoted columns for each product SELECT Date, -- Use CASE to create a column for Laptop and Mouse sales SUM(CASE WHEN Product = 'Laptop' THEN Sales ELSE 0 END) AS Laptop, SUM(CASE WHEN Product = 'Mouse' THEN Sales ELSE 0 END) AS Mouse FROM SalesData GROUP BY Date;
Oracle
Oracle supports the PIVOT operator, which allows for the straightforward transformation of rows into columns. Just like SQL Server, you will need to explicitly specify the columns for transformation.
In the query below, the PIVOT operator converts ProductName values into columns and aggregates SalesAmount using the SUM operator.
SELECT * FROM ( -- Source data selection SELECT SaleDate, ProductName, SaleAmount FROM SalesData ) PIVOT ( -- Aggregate Sales by Product, creating pivoted columns SUM(SaleAmount) FOR ProductName IN ('Laptop' AS Laptop, 'Mouse' AS Mouse) );

Example output transformation using SQL PIVOT operator in Oracle. Image by Author.
Advanced Techniques for Pivoting Rows to Columns in SQL
Advanced techniques for pivoting rows into columns are useful when you need flexibility in handling complex data. Dynamic techniques and handling multiple columns simultaneously allow you to transform data in scenarios where static pivoting is limited. Let us explore these two methods in detail.
Dynamic pivots
Dynamic pivots allow you to create pivot queries that automatically adapt to changes in the data. This technique is particularly useful when you have columns that change frequently, such as product names or categories, and you want your query to automatically include new entries without updating it manually.
Suppose we have a SalesData table and can create a dynamic pivot that adjusts if new products are added. In the query below, @columns dynamically builds the list of pivoted columns, and sp_executesql runs the generated SQL.
DECLARE @columns NVARCHAR(MAX), @sql NVARCHAR(MAX); -- Step 1: Generate a list of distinct products to pivot SELECT @columns = STRING_AGG(QUOTENAME(Product), ', ') FROM (SELECT DISTINCT Product FROM SalesData) AS products; -- Step 2: Build the dynamic SQL query SET @sql = N' SELECT Date, ' + @columns + ' FROM (SELECT Date, Product, Sales FROM SalesData) AS source PIVOT ( SUM(Sales) FOR Product IN (' + @columns + ') ) AS pivot_table;'; -- Step 3: Execute the dynamic SQL EXEC sp_executesql @sql;
Handling multiple columns
In scenarios where you need to pivot multiple columns simultaneously, you will use the PIVOT operator and additional aggregation techniques to create multiple columns in the same query.
In the example below, I have pivoted Sales and Quantity columns by Product.
-- Pivot Sales and Quantity for Laptop and Mouse by Date SELECT p1.Date, p1.[Laptop] AS Laptop_Sales, p2.[Laptop] AS Laptop_Quantity, p1.[Mouse] AS Mouse_Sales, p2.[Mouse] AS Mouse_Quantity FROM ( -- Pivot for Sales SELECT Date, [Laptop], [Mouse] FROM (SELECT Date, Product, Sales FROM SalesData) AS source PIVOT (SUM(Sales) FOR Product IN ([Laptop], [Mouse])) AS pivot_sales ) p1 JOIN ( -- Pivot for Quantity SELECT Date, [Laptop], [Mouse] FROM (SELECT Date, Product, Quantity FROM SalesData) AS source PIVOT (SUM(Quantity) FOR Product IN ([Laptop], [Mouse])) AS pivot_quantity ) p2 ON p1.Date = p2.Date;
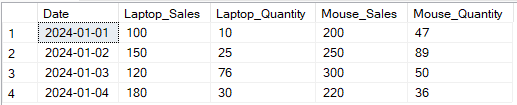
Example output transformation of multiple columns using SQL PIVOT operator. Image by Author.
Pivoting multiple columns allows for more detailed reports by pivoting multiple attributes per item, enabling richer insights. However, the syntax can be complex, especially if many columns exist. Hardcoding may be required unless combined with dynamic pivot techniques, adding further complexity.
Conclusion
Pivoting rows to columns is a SQL technique worth learning. I have seen SQL pivot techniques used to create a cohort retention table, where you might track user retention over time. I have also seen SQL pivot techniques used when analyzing survey data, where each row represents a respondent, and each question can be pivoted into its column.
Our Reporting in SQL course is a great option if you want to learn more about summarizing and preparing data for presentation and/or dashboard building. Our Associate Data Analyst in SQL and Associate Data Engineer in SQL career tracks are another great idea, and they add a lot to any resume, so enroll today.
Source:
https://www.datacamp.com/tutorial/sql-pivot-rows-to-columns