













SQLで行を列にピボットするとはどういう意味ですか?
SQLでのピボットは、データを行ベースの形式から列ベースの形式に変換することを指します。この変換はレポート作成やデータ分析に役立ち、より構造化されたコンパクトなデータビューを可能にします。行から列にピボットすることで、ユーザーはデータを分析して要約することができ、キーポイントをより明確に強調することができます。
次の例を考えてみましょう:日次の売上取引を記録したテーブルがあり、各行には日付、製品名、売上金額が記録されています。
| Date | Product | Sales |
|---|---|---|
| 2024-01-01 | Laptop | 100 |
| 2024-01-01 | Mouse | 200 |
| 2024-01-02 | Laptop | 150 |
| 2024-01-02 | Mouse | 250 |
このテーブルをピボットすることで、各製品を列として表示し、各日付の売上データを対応する列の下に表示できます。また、集計も行われます。
| Date | Laptop | Mouse |
|---|---|---|
| 2024-01-01 | 100 | 200 |
| 2024-01-02 | 150 | 250 |
従来、ピボット操作には条件付き集計を伴う複雑なSQLクエリが必要でした。時間とともに、SQLの実装は進化し、多くの現代のデータベースには、より効率的でわかりやすい変換を可能にするPIVOTおよびUNPIVOT演算子が含まれています。
SQLピボットの行から列への理解
SQLピボット操作は、行の値を列に変換することでデータを変換します。以下は、SQLピボットの基本的な構文と構造です:
-
SELECT:
SELECTステートメントは、SQLピボットテーブルで返す列を参照します。 -
サブクエリ:サブクエリには、SQLピボットテーブルに含めるデータソースまたはテーブルが含まれています。
-
PIVOT:
PIVOT演算子には、ピボットテーブルに適用される集計およびフィルタが含まれています。
-- 静的列とピボット列を選択 SELECT <static columns>, [pivoted columns] FROM ( -- ピボットのソースデータを定義するサブクエリ <subquery that defines data> ) AS source PIVOT ( -- 値列に適用される集計関数、新しい列を作成 <aggregation function>(<value column>) FOR <column to pivot> IN ([list of pivoted columns]) ) AS pivot_table;
SQLで行から列にピボットする方法を段階的な例で示すために、以下のSalesDataテーブルを考えてみましょう。

SQL PIVOT演算子を使用して変換する表の例。著者による画像。
このデータをピボットして、各製品の日次売上を比較したいです。まず、PIVOT演算子を構造化するサブクエリを選択します。
-- ピボットのソースデータを定義するサブクエリ SELECT Date, Product, Sales FROM SalesData;
次に、PIVOT演算子を使用して、Productの値を列に変換し、SalesをSUM演算子で集計します。
-- 日付と各製品のピボットされた列を選択します SELECT Date, [Laptop], [Mouse] FROM ( -- 日付、製品、売上の列を取得するサブクエリ SELECT Date, Product, Sales FROM SalesData ) AS source PIVOT ( -- 製品別に売上を集計し、製品の値を列にピボットします SUM(Sales) FOR Product IN ([Laptop], [Mouse]) ) AS pivot_table;

SQLピボット行を列に変換する例の出力変換。著者による画像。
データのピボットはデータの要約を簡素化する一方で、潜在的な問題を抱えています。以下はSQLのピボットに関する潜在的な課題とその対処方法です。
-
動的な列名: ピボットする値(例:製品の種類)が不明な場合、列名をハードコーディングすることはできません。SQL Serverなどの一部のデータベースは、この問題を回避するためにストアドプロシージャを使用した動的なSQLをサポートしていますが、他のデータベースではアプリケーションレイヤーでの処理が必要です。
-
NULL値の処理: 特定のピボット列にデータがない場合、結果には
NULLが含まれる可能性があります。NULL値をゼロや他のプレースホルダーで置き換えるには、COALESCEを使用できます。 -
データベース間の互換性: すべてのデータベースが直接
PIVOT演算子をサポートしているわけではありません。SQLの方言によっては、CASE文と条件付き集計を使用して類似の結果を得ることができます。
SQLのピボット行を列に変換する: 例と使用例
異なる方法が使用され、SQLでデータをピボットする際には、使用するデータベースやその他の要件によって異なります。 PIVOT演算子はSQL Serverで一般的に使用されていますが、PIVOTサポートが直接的でなくても、CASEステートメントなどの他の手法を使用することで、同様のデータベース変換が可能です。SQLでデータをピボットする2つの一般的な方法と、その利点と欠点について説明します。
PIVOT演算子の使用
PIVOT演算子は、SQL Serverで利用可能であり、集計関数を指定し、ピボットする列を定義することで、行を列にピボットする簡単な方法を提供します。
次の名前がsales_dataというテーブルを考えてみましょう。

PIVOT演算子を使用して変換する例の注文テーブル。著者による画像。
年ごとの合計sales_revenueが列に表示されるように、PIVOT演算子を使用します。
-- 年ごとに売上高を集計するためにPIVOTを使用する SELECT * FROM ( -- ソーステーブルから関連する列を選択する SELECT sale_year, sales_revenue FROM sales_data ) AS src PIVOT ( -- 各年の売上高を集計する SUM(sales_revenue) -- 各年の列を作成する FOR sale_year IN ([2020], [2021], [2022], [2023]) ) AS piv;

SQL PIVOTを使用した出力の変換例。Image by Author。
PIVOT演算子の利点および制限は次のとおりです:
-
利点: 適切にインデックスが設定されている場合、効率的な方法です。また、シンプルで読みやすい構文も持っています。
-
制限:すべてのデータベースが
PIVOT演算子をサポートしているわけではありません。列を事前に指定する必要があり、動的なピボットには追加の複雑さが必要です。
CASE文を使用した手動のピボット
また、PIVOT演算子をサポートしていないMySQLやPostgreSQLなどのデータベースでデータを手動でピボットするには、CASE文を使用することもできます。この方法では、各行を評価し、特定の条件に基づいて新しい列に値を条件付きで割り当てることにより、条件付き集計を行います。
たとえば、同じsales_dataテーブルでデータを手動でピボットすることができます。
-- CASE文を使用して年ごとに売上高を集計する SELECT -- 各年の総売上高を計算する SUM(CASE WHEN sale_year = 2020 THEN sales_revenue ELSE 0 END) AS sales_2020, SUM(CASE WHEN sale_year = 2021 THEN sales_revenue ELSE 0 END) AS sales_2021, SUM(CASE WHEN sale_year = 2022 THEN sales_revenue ELSE 0 END) AS sales_2022, SUM(CASE WHEN sale_year = 2023 THEN sales_revenue ELSE 0 END) AS sales_2023 FROM sales_data;

SQL CASEステートメントを使用した出力変換の例。著者による画像。
CASEステートメントを使用した変換の利点と制限事項:
-
利点: この方法はすべてのSQLデータベースで動作し、製品名が不明または頻繁に変更されても新しい列を動的に生成するのに柔軟です。
-
制約事項:列のピボットが多い場合、クエリは複雑で長くなる可能性があります。複数の条件チェックがあるため、この方法は
PIVOT演算子よりもわずかに遅くなります。
行を列にピボットするとパフォーマンスに影響が出る場合があります
特に大きなデータセットで作業する場合、SQLで行を列にピボットすることはパフォーマンスに影響を与える可能性があります。効率的なピボットクエリを作成し、パフォーマンスを最適化し、一般的な落とし穴を避けるためのヒントとベストプラクティスを以下に示します。
ベストプラクティス
次に、クエリの最適化とパフォーマンスの向上を図るためのベストプラクティスを紹介します。
-
インデックス戦略: 適切なインデックス設定は、ピボットクエリの最適化に不可欠であり、SQLがデータをより速く取得および処理できるようにします。常に、
WHERE句で頻繁に使用される列やグループ化される列にインデックスを付けることで、スキャン回数を削減できます。 -
ネストされたピボットを回避する: 1つのクエリで複数のピボット操作を重ねると読みづらく、実行が遅くなることがあります。クエリを複数の部分に分割するか、一時テーブルを使用することでシンプルにできます。
-
ピボットで列と行を制限する: 分析にはピボット列のみが必要です。多くの列をピボットするとリソースを消費し、大きなテーブルを作成する可能性があるためです。
一般的な失敗を避ける
ピボットクエリで遭遇する可能性のある一般的な間違いとその回避方法は以下の通りです。
-
不要なフルテーブルスキャン:ピボットクエリは、関連するインデックスがない場合にフルテーブルスキャンを引き起こす可能性があります。キーカラムにインデックスを付け、ピボットを適用する前にデータをフィルタリングすることでフルテーブルスキャンを回避します。
-
頻繁なピボット処理に動的SQLを使用: 動的SQLを使用すると、クエリの再コンパイルによりパフォーマンスが低下する可能性があります。 この問題を回避するために、動的なピボットをキャッシュしたり制限したりして特定のシナリオに制限し、可能な限りアプリケーションレイヤーで動的な列を処理することを検討してください。
-
事前フィルタリングなしで大規模データセットで集計する:大規模データセットでの
SUMやCOUNTなどの集計関数はデータベースのパフォーマンスを低下させる可能性があります。データセット全体をピボットさせる代わりに、WHERE句を使用してデータを事前にフィルタリングしてください。 -
ピボットされた列のNULL値: ピボット操作は、特定の列にデータがない場合に
NULL値を生成することがよくあります。これはクエリの遅延を引き起こし、結果を解釈しにくくします。この問題を回避するために、COALESCEなどの関数を使用してNULL値をデフォルト値で置き換えてください。 -
サンプルデータのみでのテスト:大規模なデータセットではメモリおよび処理の要求が増加するため、ピボットクエリの動作が異なる場合があります。パフォーマンスへの影響を正確に評価するためには、常に実際のデータサンプルまたは代表データでピボットクエリをテストしてください。
SQL Server Developerキャリアトラックを試してみてください。このトラックでは、トランザクションやエラーハンドリングからクエリパフォーマンスの向上まで幅広くカバーしています。
データベース固有の実装
SQL Server、MySQL、Oracleなどのデータベース間で、ピボット操作は大きく異なります。これらのデータベースごとに固有の構文と制限事項があります。異なるデータベースでのデータのピボット化の例と主な機能について説明します。
SQL Server
SQL Serverは、行を列にピボットする際に直感的なPIVOT演算子を提供しています。PIVOT演算子は使いやすく、SQL Serverの強力な集計機能と統合されています。SQLでのピボットの主な特徴は以下の通りです。
-
PIVOTおよびUNPIVOTの直接サポート: SQL ServerのPIVOT演算子は、簡単な行から列への変換を可能にします。また、UNPIVOT演算子はこのプロセスを逆にすることもできます。
-
集計オプション:
PIVOT演算子は、SUM、COUNT、AVGなどのさまざまな集計関数を許容します。
SQL ServerにおけるPIVOT演算子の制限は、ピボットされる列の値が事前にわかっている必要があるため、データが動的に変更される場合には柔軟性に欠けるという点です。
以下の例では、PIVOT オペレーターを使用して Product の値を列に変換し、Sales を SUM オペレーターで集計します。
-- 各製品ごとの日付とピボットされた列を選択する SELECT Date, [Laptop], [Mouse] FROM ( -- 日付、製品、および売上の列を取得するためのサブクエリ SELECT Date, Product, Sales FROM SalesData ) AS source PIVOT ( -- 製品ごとに売上を集計し、製品の値を列にピボットする SUM(Sales) FOR Product IN ([Laptop], [Mouse]) ) AS pivot_table;
データ分析のための SQL Server の基礎をマスターするには、DataCamp の Introduction to SQL Server コースをおすすめします。
MySQL
MySQL には PIVOT オペレーターへのネイティブサポートはありません。ただし、CASE 文を使用して行を手動で列にピボットし、SUM、AVG、および COUNT のような他の集計関数を組み合わせることができます。この方法は柔軟ですが、多くの列をピボットする場合は複雑になる可能性があります。
以下のクエリは、SQL ServerのPIVOTの例と同じ出力を得るために、CASE文を使用して各製品の売上を条件付きで集計します。
-- 日付と各製品のピボットされた列を選択 SELECT Date, -- ラップトップとマウスの売上のための列を作成するためにCASEを使用 SUM(CASE WHEN Product = 'Laptop' THEN Sales ELSE 0 END) AS Laptop, SUM(CASE WHEN Product = 'Mouse' THEN Sales ELSE 0 END) AS Mouse FROM SalesData GROUP BY Date;
Oracle
OracleはPIVOT演算子をサポートしており、行を列に変換するための簡単な変換が可能です。SQL Serverと同様に、変換する列を明示的に指定する必要があります。
以下のクエリでは、PIVOT演算子がProductNameの値を列に変換し、SalesAmountをSUM演算子で集計します。
SELECT * FROM ( -- ソースデータの選択 SELECT SaleDate, ProductName, SaleAmount FROM SalesData ) PIVOT ( -- 製品ごとに売上を集計し、ピボットされた列を作成 SUM(SaleAmount) FOR ProductName IN ('Laptop' AS Laptop, 'Mouse' AS Mouse) );

Oracle で SQL PIVOT 演算子を使用した出力変換の例。著者による画像。
SQL で行を列にピボットするための高度なテクニック
行を列にピボットするための高度なテクニックは、複雑なデータを扱う際に柔軟性が必要な場合に役立ちます。動的なテクニックや複数の列を同時に処理することで、固定的なピボットが限られているシナリオでデータを変換できます。これらの2つの方法を詳しく見てみましょう。
動的なピボット
動的なピボットを使用すると、データの変更に自動的に適応するピボットクエリを作成できます。このテクニックは、製品名やカテゴリなどの頻繁に変更される列がある場合に特に便利であり、手動で更新せずに新しいエントリをクエリに自動的に含めたい場合に役立ちます。
前提として、SalesDataテーブルがあり、新しい商品が追加された場合に自動的に調整される動的なピボットを作成できるとします。以下のクエリでは、@columnsがピボット化された列のリストを動的に構築し、sp_executesqlが生成されたSQLを実行します。
DECLARE @columns NVARCHAR(MAX), @sql NVARCHAR(MAX); -- ステップ1:ピボットするためのユニークな商品のリストを生成する SELECT @columns = STRING_AGG(QUOTENAME(Product), ', ') FROM (SELECT DISTINCT Product FROM SalesData) AS products; -- ステップ2:動的なSQLクエリを構築する SET @sql = N' SELECT Date, ' + @columns + ' FROM (SELECT Date, Product, Sales FROM SalesData) AS source PIVOT ( SUM(Sales) FOR Product IN (' + @columns + ') ) AS pivot_table;'; -- ステップ3:動的なSQLを実行する EXEC sp_executesql @sql;
複数の列の処理
複数の列を同時にピボットする場合、PIVOT演算子と追加の集計技術を使用して同じクエリ内で複数の列を作成します。
以下の例では、SalesとQuantityの列をProductでピボットしています。
- 日付ごとのラップトップとマウスの販売と数量のピボット SELECT p1.Date, p1.[Laptop] AS Laptop_Sales, p2.[Laptop] AS Laptop_Quantity, p1.[Mouse] AS Mouse_Sales, p2.[Mouse] AS Mouse_Quantity FROM ( - 販売のためのピボット SELECT Date, [Laptop], [Mouse] FROM (SELECT Date, Product, Sales FROM SalesData) AS source PIVOT (SUM(Sales) FOR Product IN ([Laptop], [Mouse])) AS pivot_sales ) p1 JOIN ( - 数量のためのピボット SELECT Date, [Laptop], [Mouse] FROM (SELECT Date, Product, Quantity FROM SalesData) AS source PIVOT (SUM(Quantity) FOR Product IN ([Laptop], [Mouse])) AS pivot_quantity ) p2 ON p1.Date = p2.Date;
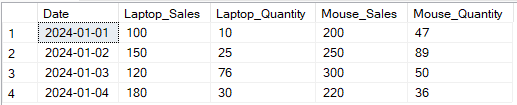
SQLのPIVOT演算子を使用した複数の列の出力変換の例。著者によるイメージ。
複数の列をピボットすることで、アイテムごとに複数の属性をピボットできるため、より詳細なレポートが作成できます。ただし、多くの列が存在する場合は、構文が複雑になることがあります。動的なピボットテクニックと組み合わせなければならず、さらなる複雑さが加わる場合もあります。
結論
行を列にピボットすることは、学ぶ価値のあるSQLの技術です。私は、SQLのピボットテクニックが、ユーザーの継続率を追跡するコホートのリテンションテーブルを作成するために使用されるのを見てきました。また、調査データを分析する際にも、各行が回答者を表し、各質問を列にピボットできるようになるSQLのピボットテクニックが使用されることもあります。
当社のSQLレポート作成コースは、データの要約やプレゼンテーションおよび/またはダッシュボード構築の準備について学びたい場合の素晴らしい選択肢です。当社のSQLデータアナリストアシスタントおよびSQLデータエンジニアアシスタントのキャリアトラックも素晴らしいアイデアであり、履歴書に多くの価値を加えるので、今すぐ登録してください。
Source:
https://www.datacamp.com/tutorial/sql-pivot-rows-to-columns