













I came across one of the test cases in my previous projects where I had to click on a button to navigate to the next page. I searched for the element locator of the button on the page and ran the tests hoping it would click the button and navigate to the next page.
Но, к моему удивлению, тест провалился, так как не смог найти элемент, и в консольных логах я получил NoSuchElementException. Меня это не обрадовало, ведь я пытался кликнуть по простой кнопке, и никакой сложности не было.
После более глубокого анализа проблемы, расширения DOM и проверки корневых элементов, я обнаружил, что локатор кнопки находился внутри #shadow-root(open) узла дерева, что заставило меня понять, что его нужно обрабатывать иначе, так как это элемент Shadow DOM.
В этом руководстве по Selenium WebDriver мы обсудим элементы Shadow DOM и то, как автоматизировать Shadow DOM в Selenium WebDriver. Прежде чем перейти к автоматизации Shadow DOM в Selenium, давайте сначала разберемся, что такое Shadow DOM и зачем он используется.
Что такое Shadow DOM?
Shadow DOM — это функционал, который позволяет веб-браузеру рендерить DOM-элементы, не включая их в основную DOM-древо документа. Это создает барьер между тем, что разработчик и браузер могут достичь; разработчик не может получить доступ к Shadow DOM так же, как к вложенным элементам, в то время как браузер может рендерить и изменять этот код так же, как и вложенные элементы.
Shadow DOM — это способ достижения инкапсуляции в HTML-документе. Реализовав его, вы можете сохранить стиль и поведение одной части документа скрытыми и отдельными от остального кода того же документа, чтобы не было помех.
Shadow DOM позволяет присоединять скрытые деревья DOM к элементам в обычном дереве DOM — дерево Shadow DOM начинается с корня Shadow, под которым вы можете присоединить любой элемент так же, как и в обычном DOM.
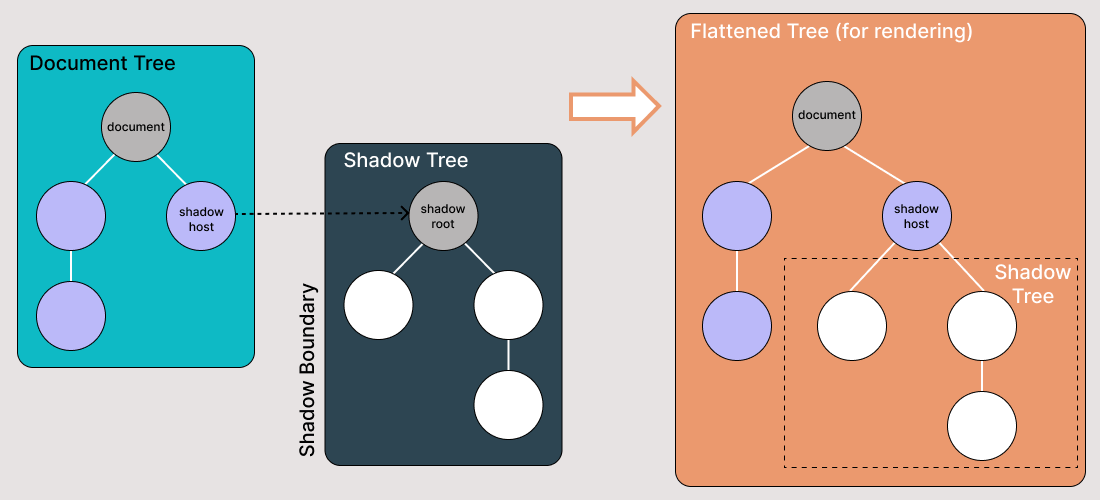
Есть некоторые термины Shadow DOM, о которых стоит знать:
- Хост Shadow DOM: Обычный узел DOM, к которому присоединен Shadow DOM
- Дерево Shadow: DOM-дерево внутри Shadow DOM
- Границей тени является место, где заканчивается Shadow DOM и начинается обычный DOM.
- Корень тени: Корень узла дерева Shadow
Каково использование Shadow DOM?
Shadow DOM служит для инкапсуляции. Он позволяет компоненту иметь свое собственное “теневoe” DOM-дерево, которое не может быть случайно доступно из основного документа, может иметь локальные правила стилей и многое другое.
Вот некоторые из основных свойств Shadow DOM:
- Имеют свой собственный пространство имен идентификаторов
- Невидимы для выборок JavaScript из основного документа, таких как querySelector
- Используют стили только из дерева тени, а не из основного документа
Поиск элементов Shadow DOM с использованием Selenium WebDriver
Когда мы пытаемся найти элементы Shadow DOM с помощью локаторов Selenium, мы получаем NoSuchElementException, поскольку он не является прямо доступным для DOM.
Мы будем использовать следующую стратегию для доступа к локаторам Shadow DOM:
- С помощью JavaScriptExecutor.
- Используя метод
getShadowDom()WebDriver Selenium.
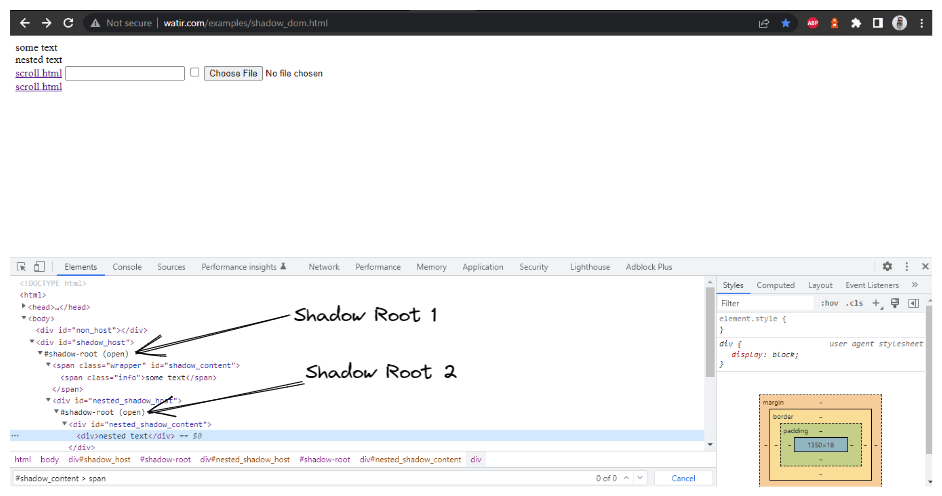
В этом блоге о автоматизации Shadow DOM в Selenium давайте рассмотрим пример главной страницы Watir.com и попробуем утверждать текст из shadow DOM и вложенного shadow DOM с помощью Selenium WebDriver. Обратите внимание, что перед доступом к тексту -> некоторый текст есть один элемент корня тени, а перед текстом -> вложенный текст есть два элемента корня тени.
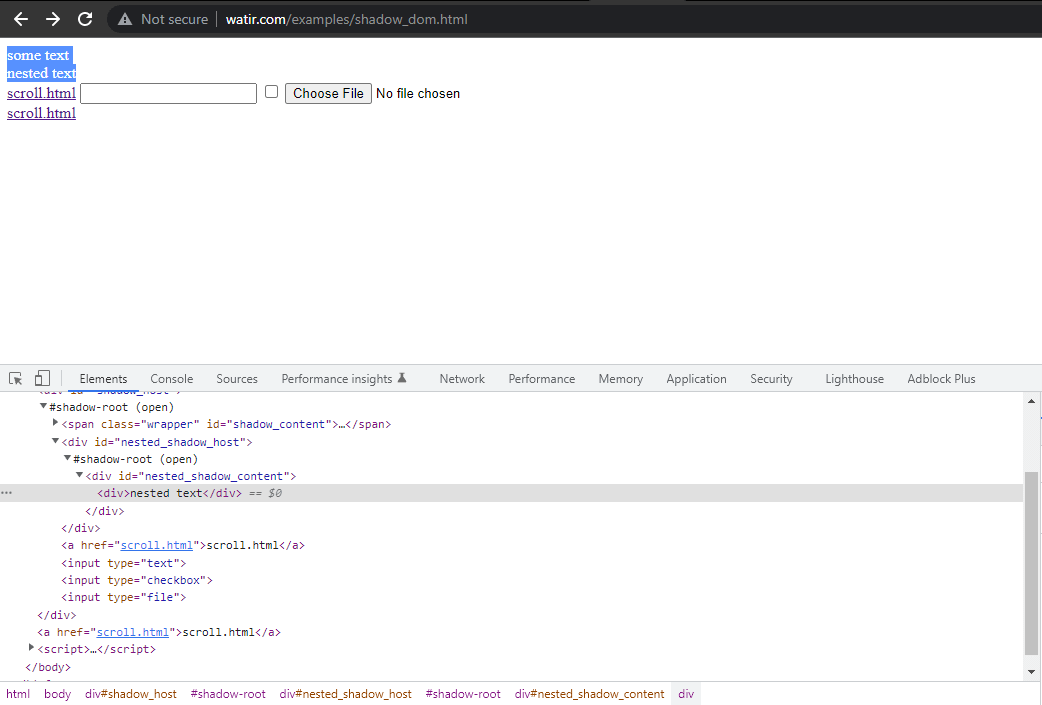
Теперь, если мы попытаемся найти элемент, используя cssSelector("#shadow_content > span"), он
не будет обнаружен, и Selenium WebDriver выбросит NoSuchElementException.
Вот скриншот класса Homepage, в котором код пытается получить текст с помощью
cssSelector(“#shadow_content > span”).

Вот скриншот тестов, в которых мы пытаемся утверждать текст(“некоторый текст”).
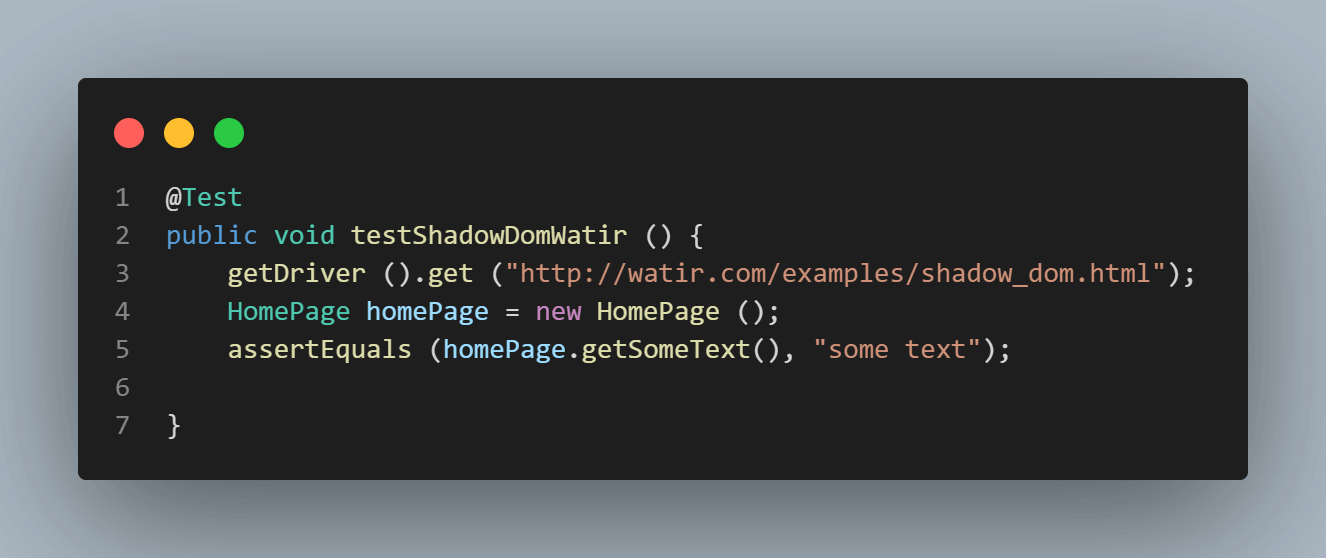
Ошибка при запуске тестов показывает NoSuchElementException
Чтобы правильно найти элемент для текста, нам нужно пройти через элементы корня тени. Только тогда мы сможем найти “некоторый текст” и “вложенный текст” на странице?
Как найти Shadow DOM в Selenium WebDriver, используя метод ‘getShadowDom’
С выходом версии Selenium WebDriver 4.0.0 и выше был введен getShadowRoot() метод, который помог найти элементы корня тени.
Вот синтаксис и детали метода getShadowRoot():
default SearchContext getShadowRoot()
Returns:
The ShadowRoot class represents the shadow root of a web component. With a shadow root, you can access the shadow DOM of a web component.
Throws:
NoSuchShadowRootException - If shadow root is not found.Согласно документации, метод getShadowRoot() возвращает представление корня тени элемента для доступа к теневому DOM веб-компонента.
В случае, если корень тени не найден, будет выброшена ошибка NoSuchShadowRootException.
Прежде чем мы начнем писать тесты и обсуждать код, позвольте рассказать о инструментах, которые мы будем использовать для написания и запуска тестов:
Вот программные языки и инструменты, использованные при написании и запуске тестов:
- Программный язык: Java 11
- Инструмент для автоматизации веб: Selenium WebDriver
- Запуск тестов: TestNG
- Инструмент для сборки: Maven
- Облачная платформа: LambdaTest
Начало работы с поиском теневого DOM в Selenium WebDriver
Как обсуждалось ранее, этот проект по теневому DOM в Selenium был создан с использованием Maven. TestNG используется в качестве запускателя тестов. Чтобы узнать больше о Maven, вы можете прочитать эту статью о начале работы с Maven для тестирования Selenium.
После создания проекта нам нужно добавить зависимость для Selenium WebDriver и TestNG в файл pom.xml.
Версии зависимостей устанавливаются в отдельном блоке свойств. Это делается для удобства обслуживания, чтобы, если нам нужно обновить версии, мы могли это сделать легко, не просматривая зависимость по всему файлу pom.xml.
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>io.github.mfaisalkhatri</groupId>
<artifactId>shadowdom-selenium</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<selenium.java.version>4.4.0</selenium.java.version>
<testng.version>7.6.1</testng.version>
<webdrivermanager.version>5.2.1</webdrivermanager.version>
<maven.compiler.version>3.10.1</maven.compiler.version>
<surefire-version>3.0.0-M7</surefire-version>
<java.release.version>11</java.release.version>
<maven.source.encoding>UTF-8</maven.source.encoding>
<suite-xml>testng.xml</suite-xml>
<argLine>-Dfile.encoding=UTF-8 -Xdebug -Xnoagent</argLine>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.seleniumhq.selenium/selenium-java -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>${selenium.java.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.testng/testng -->
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>${testng.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.github.bonigarcia</groupId>
<artifactId>webdrivermanager</artifactId>
<version>${webdrivermanager.version}</version>
<exclusions>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>${maven.compiler.version}</version>
<configuration>
<release>${java.release.version}</release>
<encoding>${maven.source.encoding}</encoding>
<forceJavacCompilerUse>true</forceJavacCompilerUse>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>${surefire-version}</version>
<executions>
<execution>
<goals>
<goal>test</goal>
</goals>
</execution>
</executions>
<configuration>
<useSystemClassLoader>false</useSystemClassLoader>
<properties>
<property>
<name>usedefaultlisteners</name>
<value>false</value>
</property>
</properties>
<suiteXmlFiles>
<suiteXmlFile>${suite-xml}</suiteXmlFile>
</suiteXmlFiles>
<argLine>${argLine}</argLine>
</configuration>
</plugin>
</plugins>
</build>
</project>Давайте перейдем к коду; в этом проекте использовался Page Object Model (POM), так как он полезен для сокращения дублирования кода и улучшения обслуживания тестовых случаев.
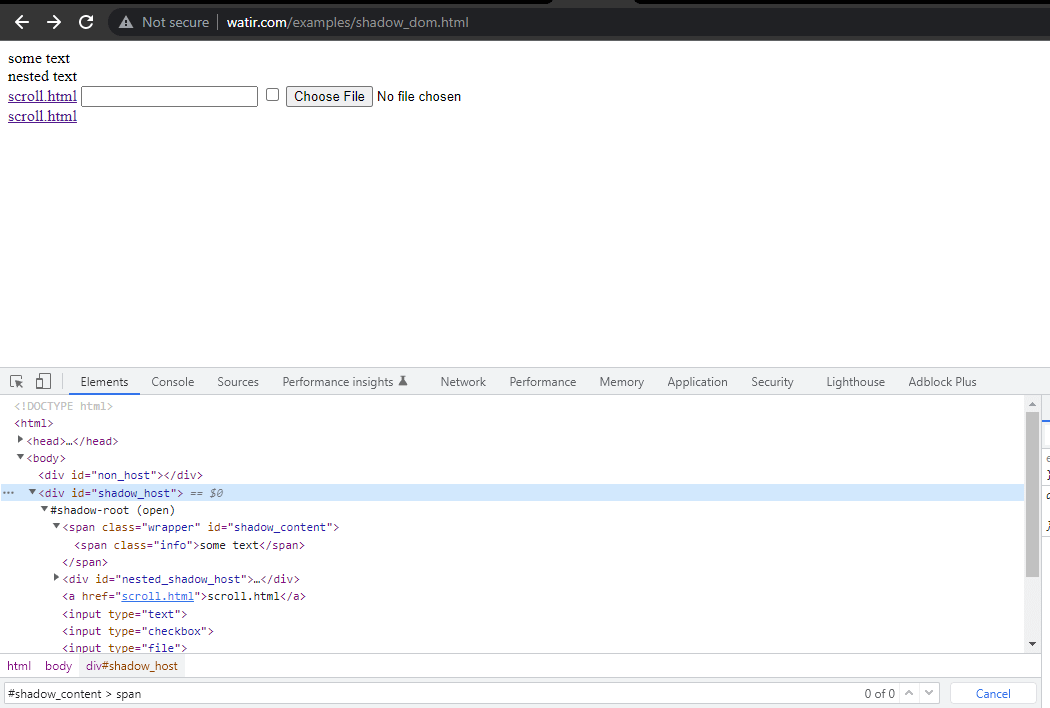
Сначала мы найдем локатор для “some text” и “nested text” на главной странице.
public class HomePage {
public SearchContext expandRootElement (WebElement element) {
SearchContext shadowRoot = (SearchContext) ((JavascriptExecutor) getDriver ()).executeScript (
"return arguments[0].shadowRoot", element);
return shadowRoot;
}
public String getSomeText () {
return getDriver ().findElement (By.cssSelector ("#shadow_content > span"))
.getText ();
}
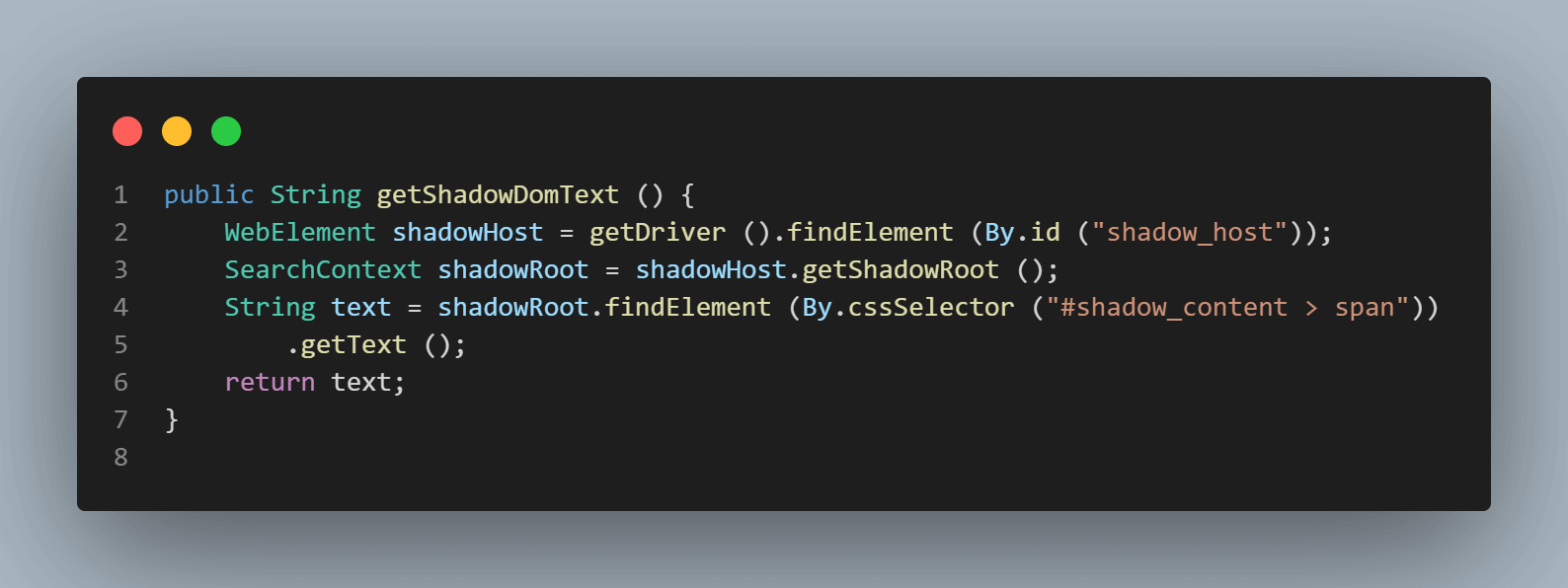
public String getShadowDomText () {
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRoot = shadowHost.getShadowRoot ();
String text = shadowRoot.findElement (By.cssSelector ("#shadow_content > span"))
.getText ();
return text;
}
public String getNestedShadowText () {
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRoot = shadowHost.getShadowRoot ();
WebElement shadowContent = shadowRoot.findElement (By.cssSelector ("#nested_shadow_host"));
SearchContext shadowRootTwo = shadowContent.getShadowRoot ();
String nestedText = shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div")).getText ();
return nestedText;
}
public String getNestedText() {
WebElement nestedText = getDriver ().findElement (By.id ("shadow_host")).getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_host")).getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_content > div"));
return nestedText.getText ();
}
public String getNestedTextUsingJSExecutor () {
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRootOne = expandRootElement (shadowHost);
WebElement nestedShadowHost = shadowRootOne.findElement (By.cssSelector ("#nested_shadow_host"));
SearchContext shadowRootTwo = expandRootElement (nestedShadowHost);
return shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div"))
.getText ();
}
}Обзор кода
Первым элементом, который мы будем находить в < div id = "shadow_host" > с использованием стратегии локатора – id.
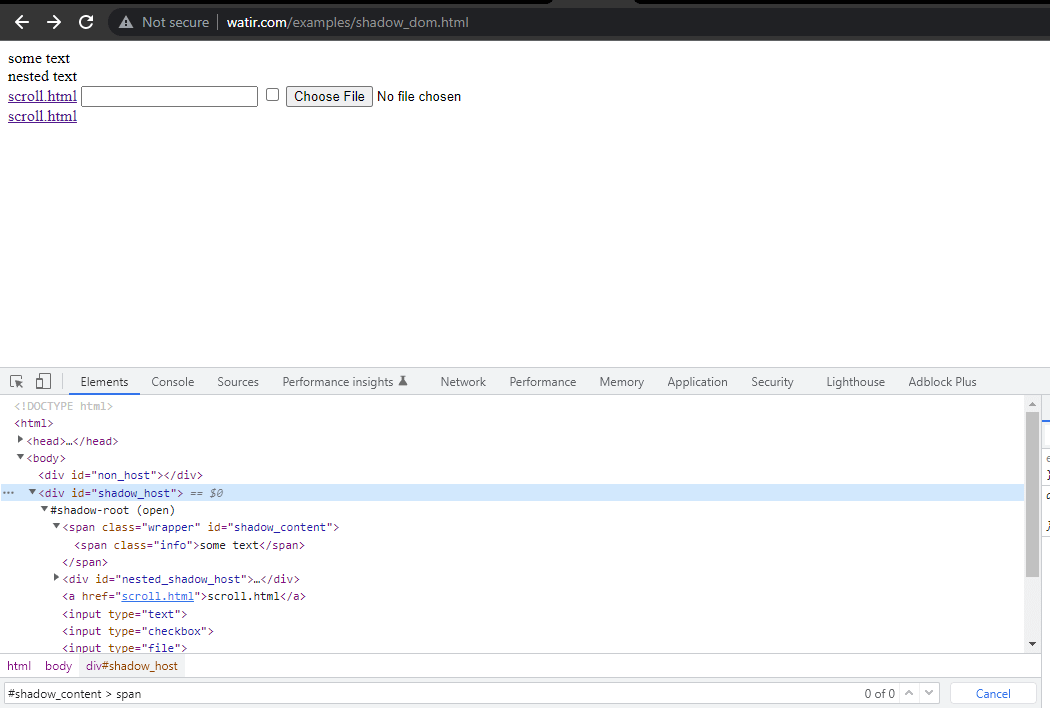
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));Далее, мы ищем первый Shadow Root в DOM рядом с ним. Для этого мы использовали интерфейс SearchContext. Shadow Root возвращается с помощью метода getShadowRoot(). Если вы проверите скриншот выше, #shadow-root (open) он находится рядом с < div id = "shadow_host" >.
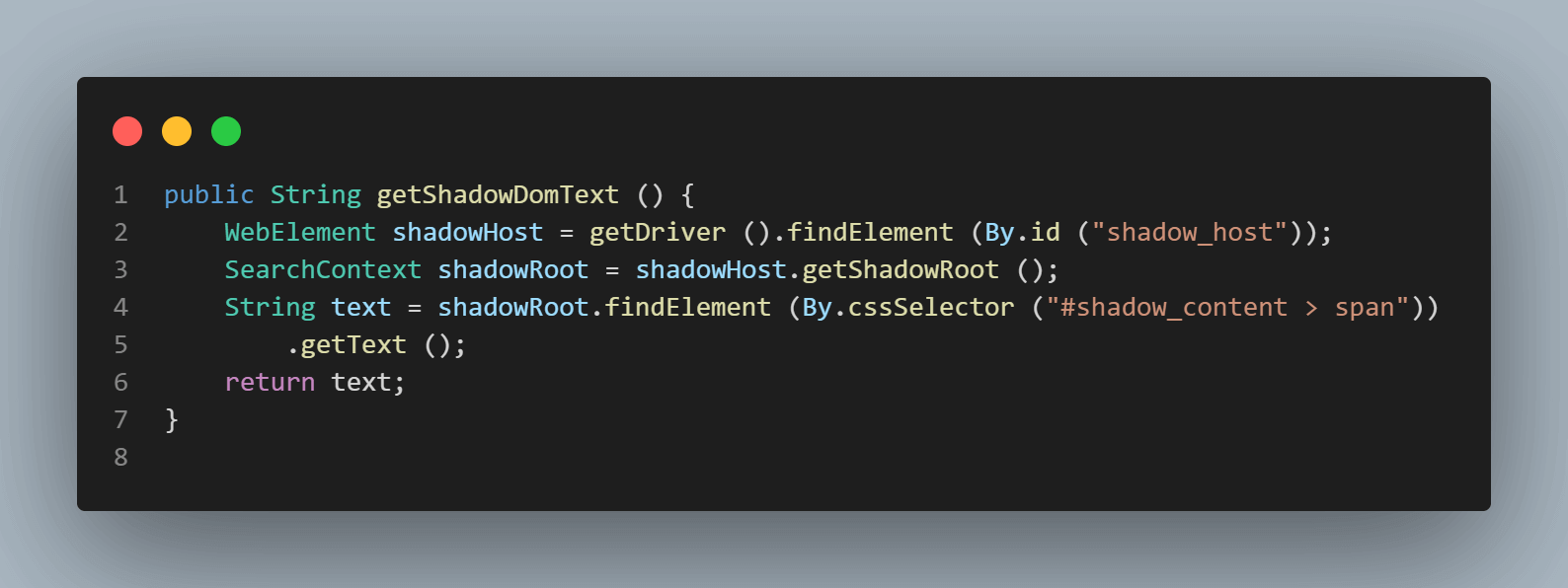
Для нахождения текста – “some text,” нам нужно пройти только через один элемент Shadow DOM.
Следующая строка кода помогает нам получить элемент корня Shadow.
SearchContext shadowRoot = downloadsManager.getShadowRoot();Как только Shadow Root найден, мы можем искать элемент для нахождения текста – “some text.” Следующая строка кода помогает нам получить текст:
String text = shadowRoot.findElement (By.cssSelector ("#shadow_content > span"))
.getText ();Далее, давайте найдем локатор для “вложенного текста,“, который имеет вложенный элемент Shadow root, и выясним, как его найти.
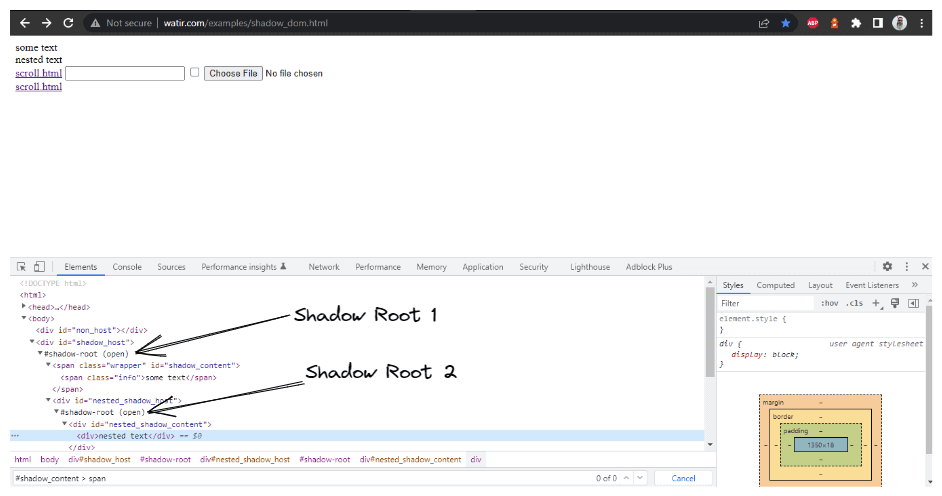
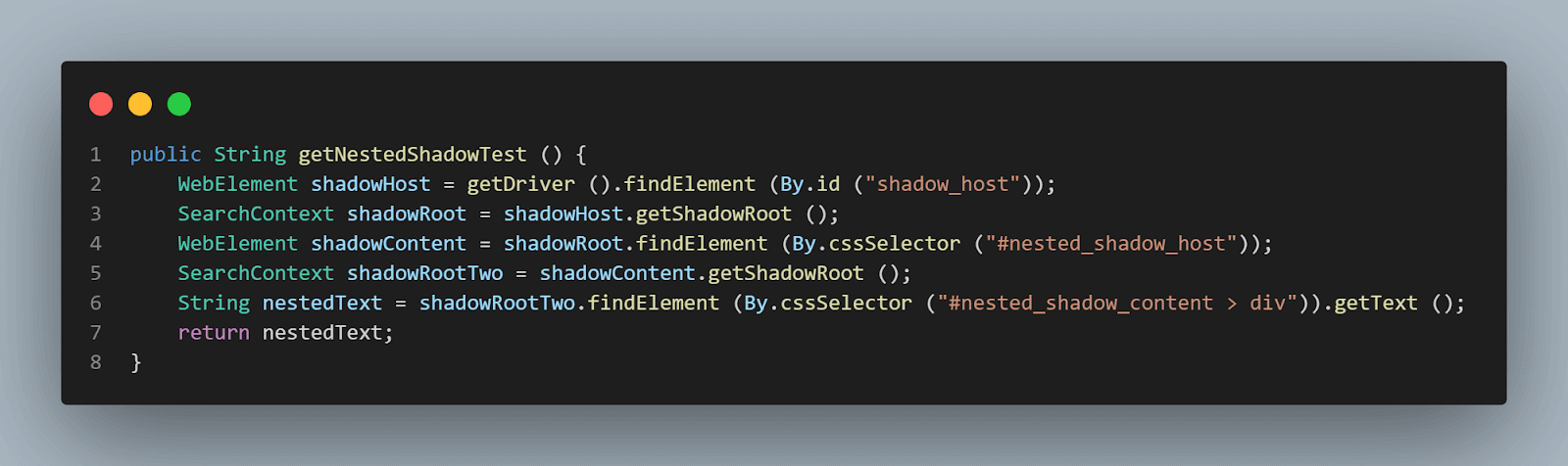
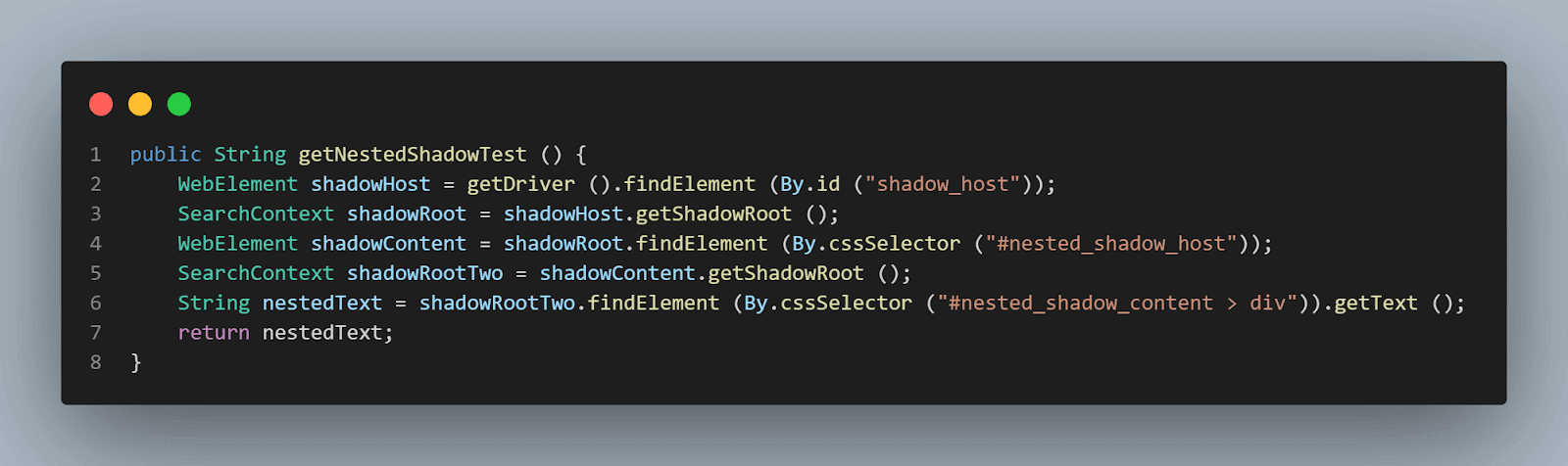
метод getNestedShadowText():
Начиная сверху, как обсуждалось в предыдущем разделе, нам нужно найти< div id = "shadow_host" > с использованием стратегии локатора – id.
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));После этого, нам нужно найти элемент Shadow Root, используя метод getShadowRoot(); как только мы получим элемент Shadow root, нам нужно будет перейти к поиску второго Shadow root, используя cssSelector для нахождения:
<div id ="nested_shadow_host">
SearchContext shadowRoot = shadowHost.getShadowRoot ();
WebElement shadowContent = shadowRoot.findElement (By.cssSelector ("#nested_shadow_host"));Затем нам нужно найти второй элемент Shadow Root с помощью метода getShadowRoot(). Наконец, пришло время найти фактический элемент для получения текста – “вложенный текст.”
Следующая строка кода поможет нам в нахождении текста:
SearchContext shadowRootTwo = shadowContent.getShadowRoot ();
String nestedText = shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div"Написание кода в лаконичном стиле
В предыдущем разделе этого блога о Shadow DOM в Selenium, мы видели длинный путь, где нам нужно найти фактический элемент, с которым мы хотим работать, и нам нужно выполнить несколько инициализаций интерфейсов WebElement и SearchContext и написать несколько строк кода для нахождения одного элемента для работы.
У нас также есть лаконичный способ написания всего этого кода, вот как вы можете это сделать:
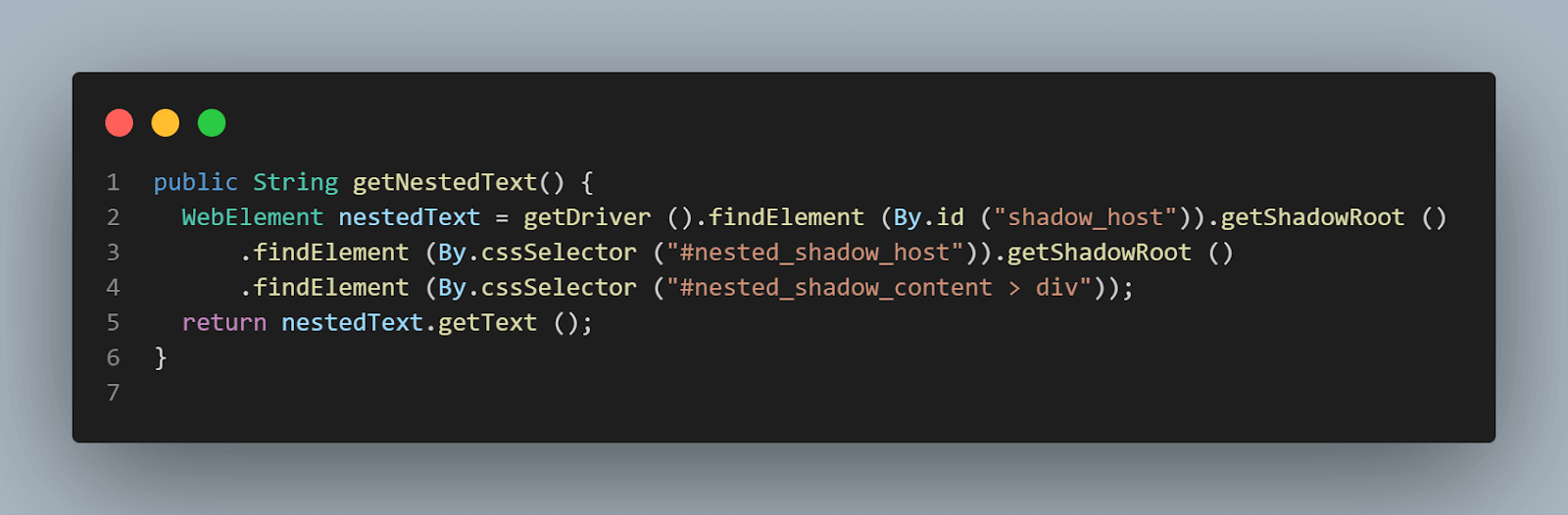
public String getNestedText() {
WebElement nestedText = getDriver ().findElement (By.id ("shadow_host"))
.getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_host"))
.getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_content > div"));
return nestedText.getText ();
}Дизайн Fluent Interface широко опирается на цепочку методов. Шаблон Fluent Interface помогает нам писать легкочитаемый код, который можно понять без необходимости глубокого технического понимания кода. Этот термин был впервые предложен в 2005 году Эриком Эвансом и Мартином Фаулером.
Это метод цепочки, который мы будем использовать для поиска элемента.
Этот код делает то же самое, что и шаги выше.
- Сначала мы будем находить элемент shadow_host по его id, затем получим элемент Shadow Root с помощью метода
getShadowRoot(). - Далее, мы будем искать элемент nested_shadow_host с помощью CSS-селектора и получим элемент Shadow Root с помощью метода
getShadowRoot(). - Наконец, мы получим текст “вложенный текст” с помощью cssSelector – nested_shadow_content > div.
Как найти Shadow DOM в Selenium с использованием JavaScriptExecutor
В приведенных выше примерах кода мы находили элементы с помощью метода getShadowRoot(). Теперь давайте посмотрим, как можно найти элементы Shadow root с помощью JavaScriptExecutor в Selenium WebDriver.
getNestedTextUsingJSExecutor() метод был создан внутри класса HomePage,
где мы будем расширять элемент Shadow Root на основе WebElement, который мы передаем в качестве параметра. В DOM (как показано на скриншоте выше), мы увидели, что есть два элемента Shadow Root, которые нужно расширить, прежде чем мы доберемся до фактического локатора для получения текста – вложенный текст. Поэтому создан метод expandRootElement() вместо копирования и вставки одного и того же кода JavaScript executor каждый раз.
Мы будем реализовывать интерфейс SearchContext, который поможет нам с JavaScriptExecutor и вернет элемент Shadow root на основе WebElement, который мы передаем в качестве параметра.
public SearchContext expandRootElement (WebElement element) {
SearchContext shadowRoot = (SearchContext) ((JavascriptExecutor) getDriver ()).executeScript (
"return arguments[0].shadowRoot", element);
return shadowRoot;
}
getNestedTextUsingJSExecutor() метод
Первым элементом, который мы будем находить, является < div id = "shadow_host" > с использованием стратегии локатора – id.
Далее, мы будем расширять Root Element на основе WebElement shadow_host, который мы искали.
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRootOne = expandRootElement (shadowHost);После расширения первого Shadow Root, мы можем искать другой WebElement с использованием cssSelector для нахождения:
<div id ="nested_shadow_host">
WebElement nestedShadowHost = shadowRootOne.findElement (By.cssSelector ("#nested_shadow_host"));
SearchContext shadowRootTwo = expandRootElement (nestedShadowHost);Наконец, пришло время найти фактический элемент для получения текста – “вложенный текст.”
Следующая строка кода поможет нам в нахождении текста:
shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div"))
.getText ();Демонстрация
В этом разделе статьи о Shadow DOM в Selenium давайте быстро напишем тест и проверим, что локаторы, которые мы нашли на предыдущих этапах, предоставляют нам требуемый текст. Мы можем запускать проверки на написанном коде, чтобы убедиться, что то, что мы ожидаем от кода, работает.
@Test
public void testShadowDomWatir () {
getDriver ().get ("http://watir.com/examples/shadow_dom.html");
HomePage homePage = new HomePage ();
// assertEquals (homePage.getSomeText(), "some text");
assertEquals (homePage.getShadowDomText (), "some text");
assertEquals (homePage.getNestedShadowText (),"nested text");
assertEquals (homePage.getNestedText (), "nested text");
assertEquals (homePage.getNestedTextUsingJSExecutor (), "nested text");
}Это всего лишь простой тест для проверки того, что тексты отображаются корректно, как и ожидалось. Мы будем проверять это с помощью утверждения assertEquals() в TestNG.
В фактическом значении мы предоставим метод, который мы только что написали, для получения текста с страницы, а в ожидаемом значении мы передадим текст “some text” или “nested text,” в зависимости от проводимых проверок.
В тесте предоставлено четыре утверждения assertEquals.
- Проверка элемента Shadow DOM с использованием метода
getShadowRoot():
- Проверка вложенного элемента Shadow DOM с использованием метода
getShadowRoot():
- Проверка вложенного элемента Shadow DOM с использованием метода
getShadowRoot()и написанием в потоковом режиме:
Выполнение
Существует два способа запуска тестов для автоматизации Shadow DOM в Selenium:
- Из IDE с использованием TestNG
- Из CLI с использованием Maven
Автоматизация Shadow DOM в Selenium WebDriver с использованием TestNG
TestNG используется в качестве исполнителя тестов. Поэтому был создан файл testng.xml, с помощью которого мы будем запускать тесты, щелкнув правой кнопкой мыши по файлу и выбрав опцию Run ‘…\testng.xml’. Но перед запуском тестов нам нужно добавить имя пользователя и ключ доступа LambdaTest в Run Configurations, так как мы читаем имя пользователя и ключ доступа из системного свойства.
LambdaTest предлагает тестирование на различных браузерах в онлайн-ферме браузеров, насчитывающей более 3000 реальных браузеров и операционных систем, чтобы помочь вам запускать тесты Java как локально, так и/или в облаке. Вы можете ускорить тестирование Selenium с Java и уменьшить время выполнения тестов в несколько раз, запустив параллельные тесты на различных браузерах и конфигурациях ОС.
- Добавьте значения в Run Configuration, как указано ниже:
- Dusername =
< LambdaTest username > - DaccessKey =
< LambdaTest access key >
- Dusername =
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd">
<suite name="Sauce Demo Website Tests">
<test name="Shadow DOM Tests on Watir Website">
<parameter name="browser" value="remote-chrome"/>
<classes>
<class name="ShadowDomTests">
<methods>
<include name="testShadowDomWatir"/>
</methods>
</class>
</classes>
</test> <!-- Test -->
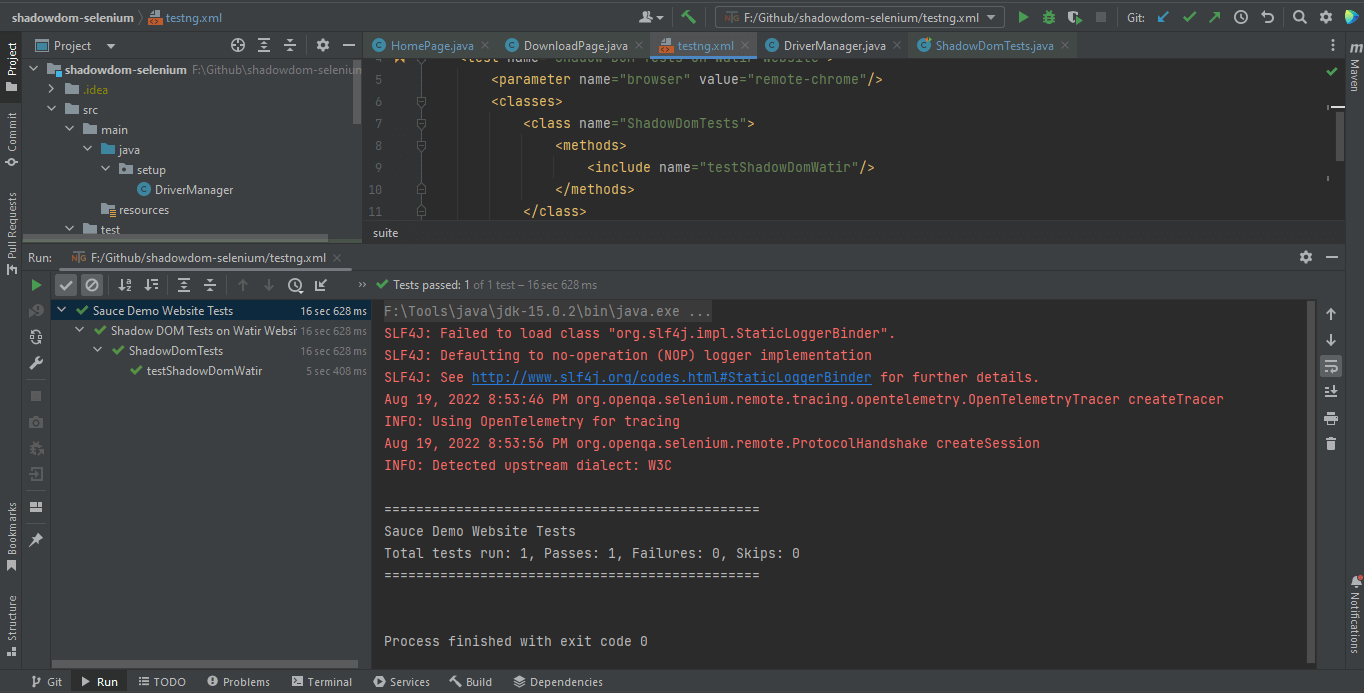
</suite>Вот снимок экрана теста, запущенного локально для Shadow DOM в Selenium с использованием Intellij IDE.
Автоматизация Shadow DOM в Selenium WebDriver с использованием Maven
Для запуска тестов с помощью Maven необходимо выполнить следующие шаги для автоматизации Shadow DOM в Selenium:
- Откройте командную строку/терминал.
- Перейдите в корневую папку проекта.
- Введите команду:
mvn clean install -Dusername=< LambdaTest username > -DaccessKey=< LambdaTest accessKey >.
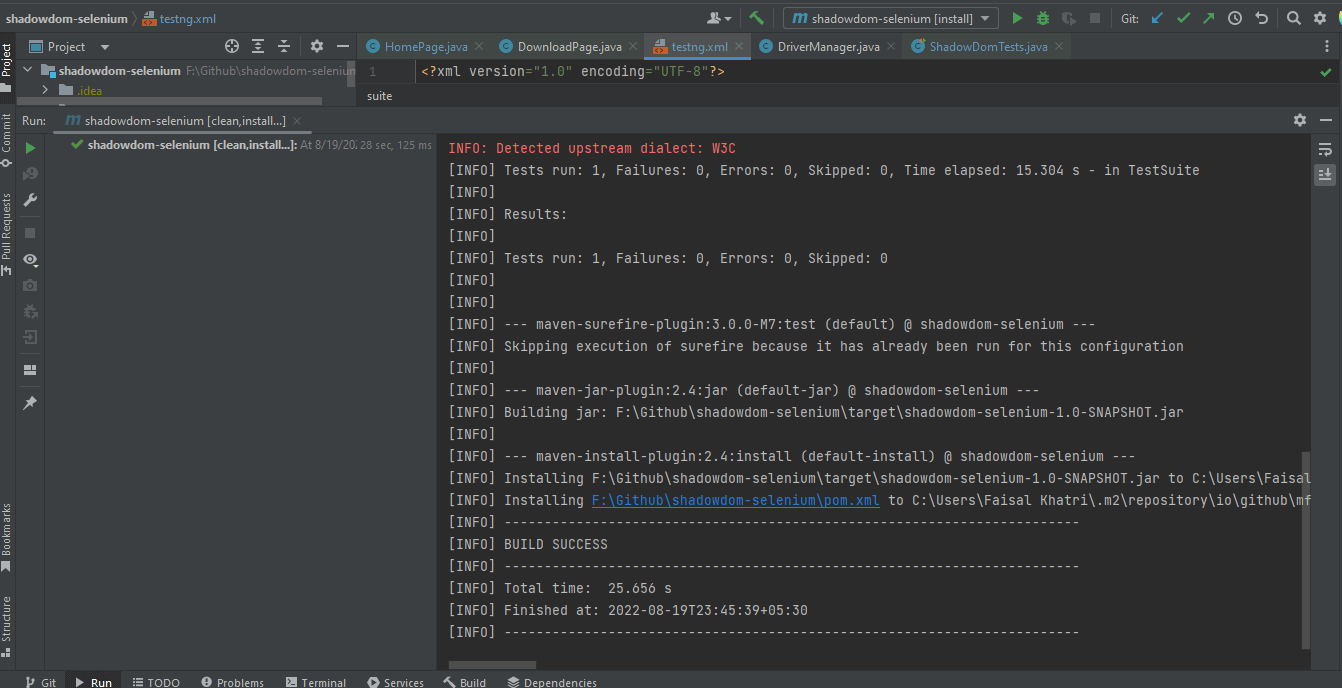
Вот скриншот из IntelliJ, на котором показано состояние выполнения тестов с использованием Maven:
После успешной прогонки тестов, мы можем перейти в панель управления LambdaTest и просмотреть все видеозаписи, скриншоты, журналы устройств и пошаговые подробности тестового запуска. Просмотрите скриншоты ниже, которые дадут вам довольно хорошее представление о панели управления для автоматизированных тестов приложений.
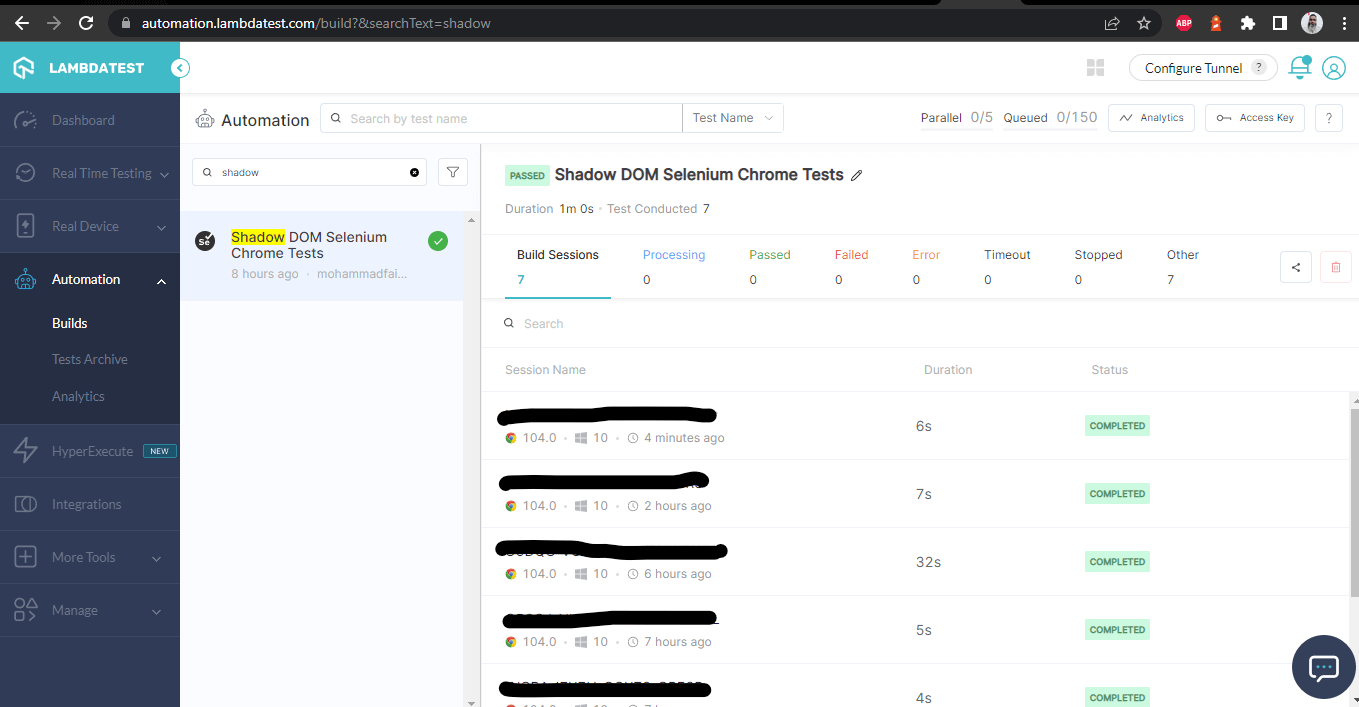 Панель управления LambdaTest
Панель управления LambdaTest
Следующие скриншоты показывают детали сборки и тестов, которые были запущены для автоматизации Shadow DOM в Selenium. Опять же, имя теста, название браузера, версия браузера, название операционной системы, соответствующая версия ОС и разрешение экрана видны для каждого теста.
Также есть видео теста, который был запущен, что дает лучшее представление о том, как тесты выполнялись на устройстве.
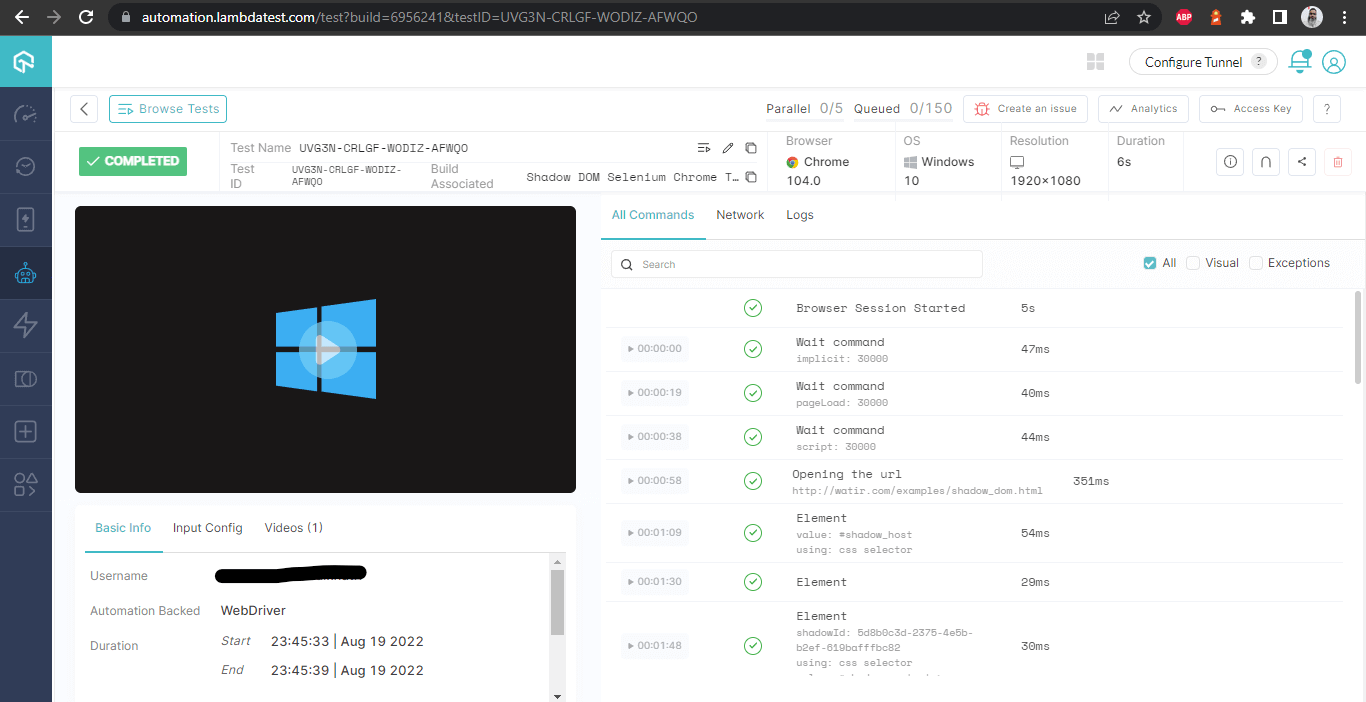 Детали сборки
Детали сборки
На этом экране показаны все метрики в деталях, которые очень полезны с точки зрения тестировщика для проверки того, какой тест был запущен на каком браузере, и соответственно просмотра логов для автоматизации Shadow DOM в Selenium.
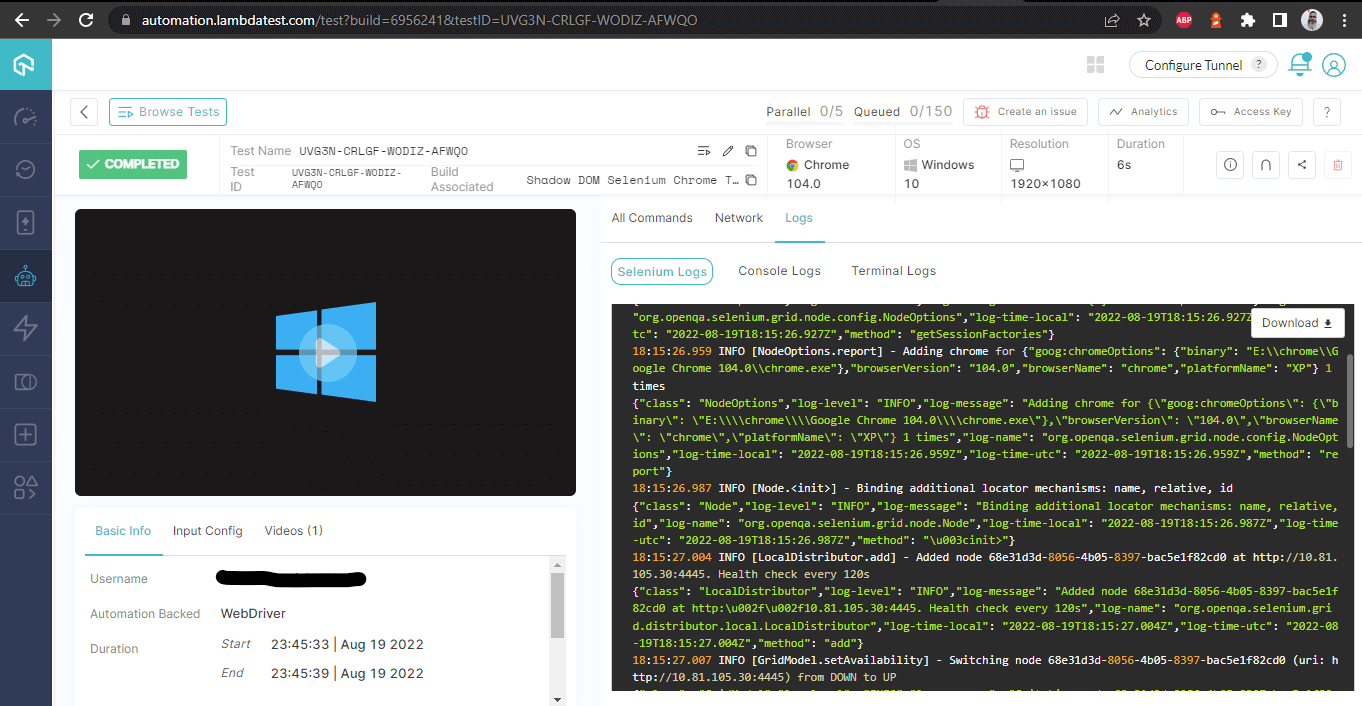 Построение деталей – с логами
Построение деталей – с логами
Вы можете получить доступ к последним тестовым результатам, их статусу и общему количеству пройденных или не пройденных тестов в панели аналитики LambdaTest. Кроме того, вы можете увидеть снимки экрана недавно выполненных тестовых запусков в разделе Обзор тестов.
Заключение
В этом блоге об автоматизации Shadow DOM в Selenium мы обсудили, как найти элементы Shadow DOM и автоматизировать их с помощью метода getShadowRoot(), введенного в версии Selenium WebDriver 4.0.0 и выше.
Мы также обсудили определение и автоматизацию элементов Shadow DOM с помощью JavaScriptExecutor в Selenium WebDriver и запуск тестов на платформе LambdaTest, которая показывает тонкие детали тестов, выполненных с логами Selenium WebDriver.
I hope this blog on Shadow DOM in Selenium gives you a fair idea about automating Shadow DOM elements using Selenium WebDriver.
Счастливого тестирования!
Source:
https://dzone.com/articles/how-to-automate-shadow-dom-in-selenium-webdriver