













I came across one of the test cases in my previous projects where I had to click on a button to navigate to the next page. I searched for the element locator of the button on the page and ran the tests hoping it would click the button and navigate to the next page.
Mais à ma surprise, le test a échoué car il n’a pas pu localiser l’élément, et j’ai reçu une NoSuchElementException dans les journaux de la console. Je n’étais pas content de voir cette erreur car il s’agissait d’un simple bouton que j’essayais de cliquer, et il n’y avait aucune complexité.
En analysant davantage l’issue, en développant le DOM et en vérifiant les éléments racine, j’ai constaté que le localisateur du bouton était à l’intérieur du #shadow-root(open) noeud de l’arbre, ce qui m’a fait réaliser qu’il devait être traité différemment car il s’agit d’un élément Shadow DOM.
Dans ce tutoriel Selenium WebDriver, nous discuterons des éléments Shadow DOM et comment automatiser le Shadow DOM dans Selenium WebDriver. Avant de passer à l’automatisation du Shadow DOM dans Selenium, comprenons d’abord ce qu’est le Shadow DOM. Et pourquoi est-il utilisé?
Qu’est-ce que le Shadow DOM?
Le Shadow DOM est une fonctionnalité qui permet au navigateur Web de rendre des éléments DOM sans les mettre dans l’arbre DOM principal du document. Cela crée une barrière entre ce que le développeur et le navigateur peuvent atteindre; le développeur ne peut pas accéder au Shadow DOM de la même manière qu’il le ferait avec des éléments imbriqués, tandis que le navigateur peut rendre et modifier ce code de la même manière qu’il le ferait avec des éléments imbriqués.
Le Shadow DOM est un moyen d’obtenir l’encapsulation dans le document HTML. En l’implémentant, vous pouvez garder le style et le comportement d’une partie du document cachés et séparés du reste du code du même document afin qu’il n’y ait pas d’interférence.
Le Shadow DOM permet aux arbres DOM cachés d’être attachés à des éléments dans le DOM normal – l’arbre Shadow DOM commence par une racine d’ombre, en dessous de laquelle vous pouvez attacher n’importe quel élément de la même manière que le DOM normal.
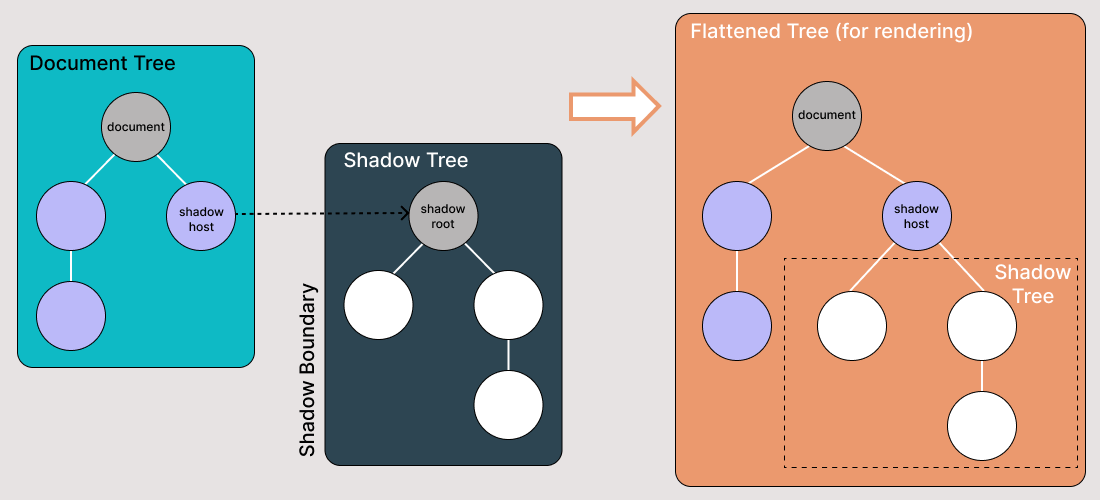
Il y a quelques termes liés au Shadow DOM à connaître:
- Hôte Shadow: Le nœud DOM régulier auquel le Shadow DOM est attaché
- Arbre Shadow: L’arbre DOM à l’intérieur du Shadow DOM
- La limite Shadow est l’endroit où le Shadow DOM se termine et où le DOM régulier commence.
- Racine Shadow: Le nœud racine de l’arbre Shadow
Quel est l’usage du Shadow DOM?
Le Shadow DOM sert à l’encapsulation. Il permet à un composant d’avoir son propre « ombre » arbre DOM qui ne peut pas être accidentellement accédé à partir du document principal, peut avoir des règles de style locales, et plus.
Voici quelques-unes des propriétés essentielles du Shadow DOM:
- Avoir leur propre espace de noms d’identifiants
- Invisible aux sélecteurs JavaScript du document principal, tels que querySelector
- Utiliser des styles uniquement de l’arbre Shadow, pas du document principal
Trouver des éléments Shadow DOM à l’aide de Selenium WebDriver
Lorsque nous essayons de trouver les éléments Shadow DOM à l’aide des localisateurs Selenium, nous obtenons NoSuchElementException car il n’est pas directement accessible au DOM.
Nous utiliserions la stratégie suivante pour accéder aux localisateurs Shadow DOM:
- En utilisant JavaScriptExecutor.
- En utilisant la méthode
getShadowDom()de Selenium WebDriver.
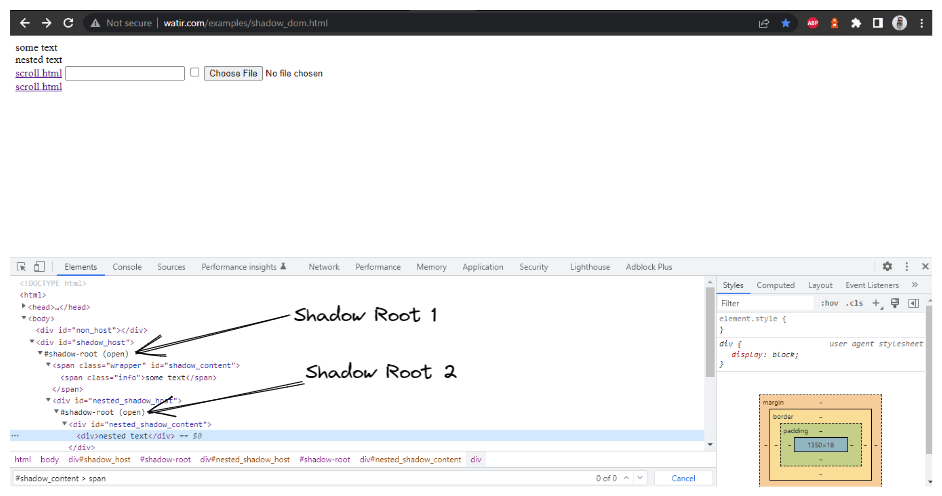
Dans cette section de blog sur l’automatisation du Shadow DOM dans Selenium, prenons l’exemple de la page d’accueil de Watir.com et essayons d’affirmer le texte du shadow dom et du shadow dom imbriqué avec Selenium WebDriver. Notez qu’il y a un élément racine shadow avant d’atteindre le texte -> some text, et il y a deux éléments racine shadow avant d’atteindre le texte -> nested text.
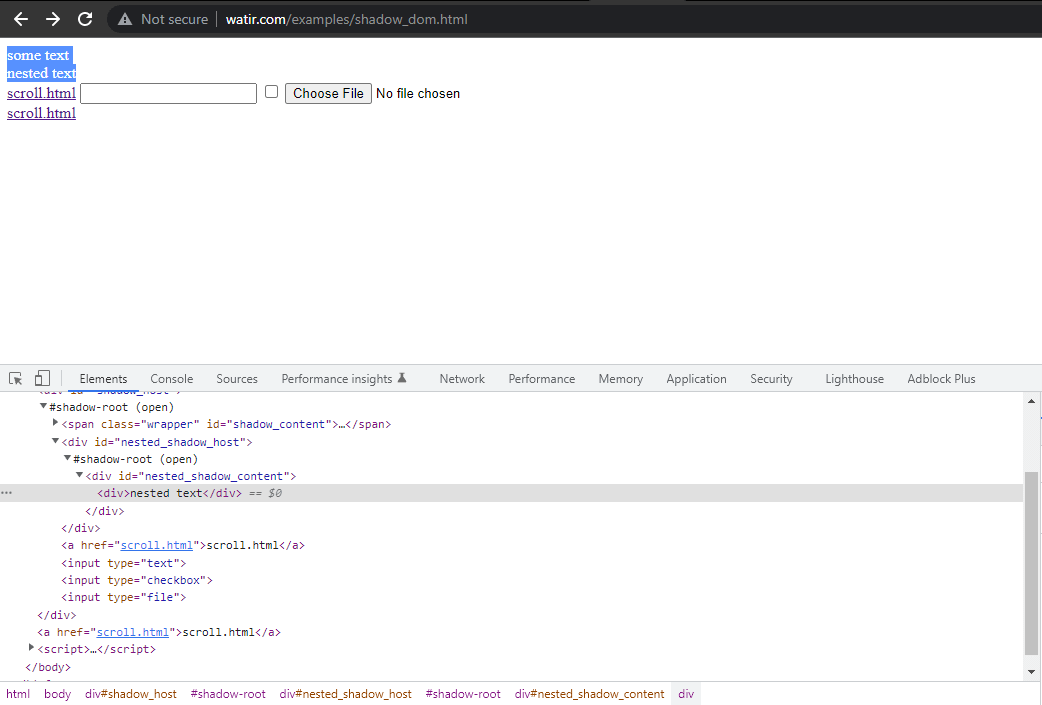
Maintenant, si nous essayons de localiser l’élément en utilisant le cssSelector("#shadow_content > span"), il
n’est pas localisé, et Selenium WebDriver lancera NoSuchElementException.
Voici l’image de la classe Homepage, qui contient le code qui essaie d’obtenir le texte en utilisant
cssSelector(« #shadow_content > span »).

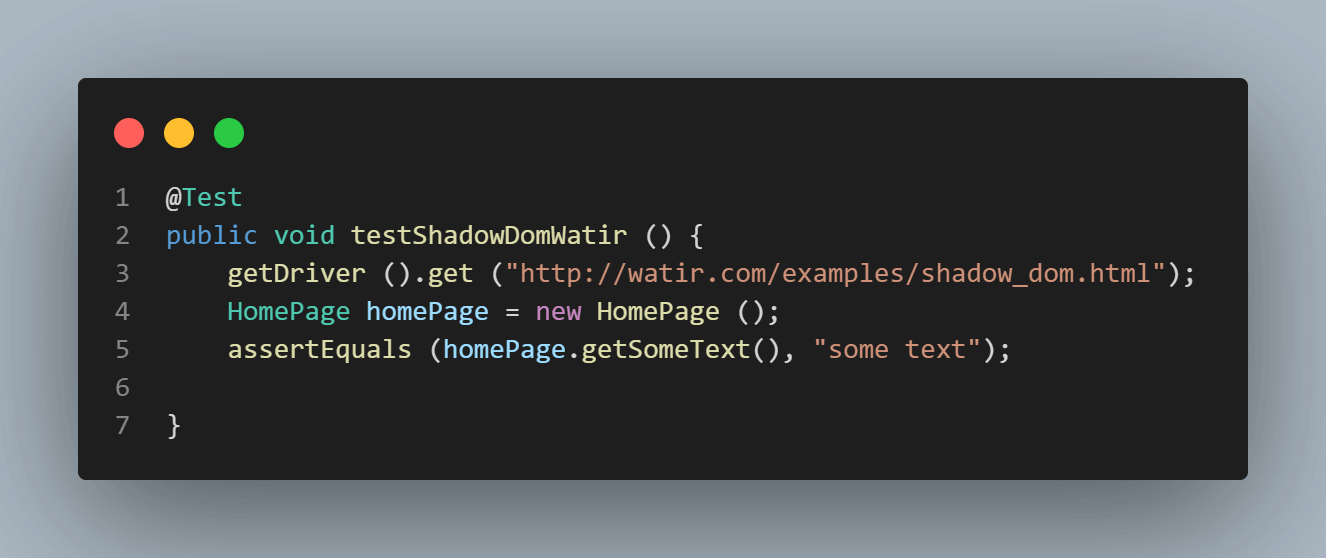
Voici l’image des tests où nous essayons d’affirmer le texte(« some text »).
Erreur lors de l’exécution des tests indiquant NoSuchElementException
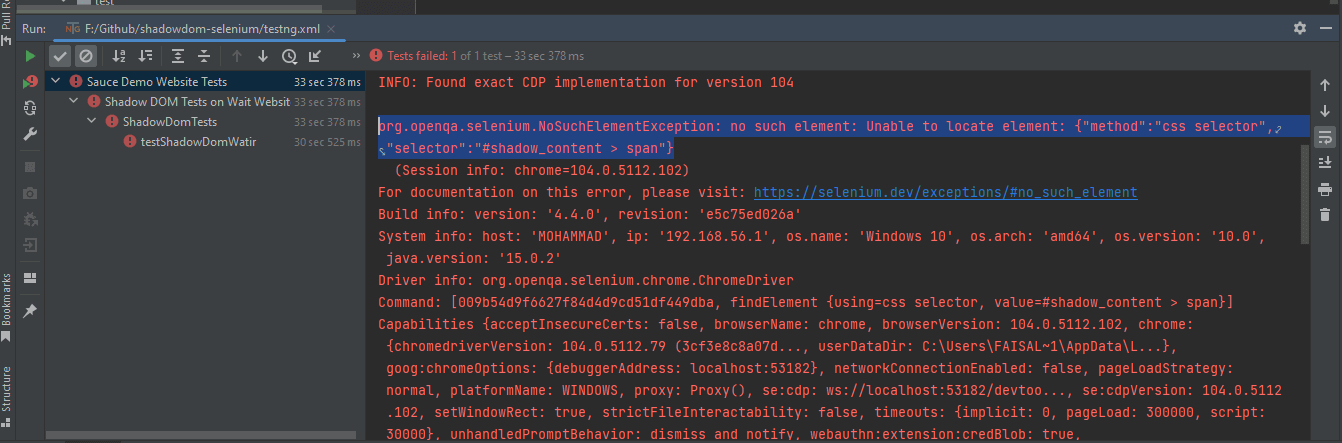
Pour localiser correctement l’élément pour le texte, nous devons passer par les éléments racine shadow. Seulement ainsi pourrions-nous localiser « some text » et « nested text » sur la page?
Comment trouver le Shadow DOM dans Selenium WebDriver en utilisant la méthode ‘getShadowDom’
Avec la sortie de la version 4.0.0 et supérieure de Selenium WebDriver, la getShadowRoot() méthode a été introduite et a aidé à localiser les éléments racine shadow.
Voici la syntaxe et les détails de la méthode getShadowRoot():
default SearchContext getShadowRoot()
Returns:
The ShadowRoot class represents the shadow root of a web component. With a shadow root, you can access the shadow DOM of a web component.
Throws:
NoSuchShadowRootException - If shadow root is not found.Selon la documentation, la méthode getShadowRoot() renvoie une représentation de la racine d’ombre d’un élément pour accéder au DOM d’ombre d’un composant web.
En cas d’absence de racine d’ombre, elle lancera NoSuchShadowRootException.
Avant de commencer à écrire les tests et de discuter du code, laissez-moi vous parler des outils que nous utiliserons pour écrire et exécuter les tests:
Les langages de programmation et outils suivants ont été utilisés pour écrire et exécuter les tests:
- Langage de Programmation: Java 11
- Outil d’Automatisation Web: Selenium WebDriver
- Exécuteur de Tests: TestNG
- Outil de Gestion de Build: Maven
- Plateforme Cloud: LambdaTest
Démarrage avec la recherche du DOM d’ombre dans Selenium WebDriver
Comme mentionné précédemment, ce projet sur le DOM d’ombre dans Selenium a été créé à l’aide de Maven. TestNG est utilisé comme exécuteur de tests. Pour en savoir plus sur Maven, vous pouvez consulter ce blog sur comment démarrer avec Maven pour les tests Selenium.
Une fois le projet créé, nous devons ajouter la dépendance pour Selenium WebDriver, et TestNG dans le fichier pom.xml.
Les versions des dépendances sont définies dans un bloc de propriétés séparé. Ceci est fait pour faciliter la maintenance, afin que si nous devons mettre à jour les versions, nous puissions le faire facilement sans chercher la dépendance partout dans le fichier pom.xml.
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>io.github.mfaisalkhatri</groupId>
<artifactId>shadowdom-selenium</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<selenium.java.version>4.4.0</selenium.java.version>
<testng.version>7.6.1</testng.version>
<webdrivermanager.version>5.2.1</webdrivermanager.version>
<maven.compiler.version>3.10.1</maven.compiler.version>
<surefire-version>3.0.0-M7</surefire-version>
<java.release.version>11</java.release.version>
<maven.source.encoding>UTF-8</maven.source.encoding>
<suite-xml>testng.xml</suite-xml>
<argLine>-Dfile.encoding=UTF-8 -Xdebug -Xnoagent</argLine>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.seleniumhq.selenium/selenium-java -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>${selenium.java.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.testng/testng -->
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>${testng.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.github.bonigarcia</groupId>
<artifactId>webdrivermanager</artifactId>
<version>${webdrivermanager.version}</version>
<exclusions>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>${maven.compiler.version}</version>
<configuration>
<release>${java.release.version}</release>
<encoding>${maven.source.encoding}</encoding>
<forceJavacCompilerUse>true</forceJavacCompilerUse>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>${surefire-version}</version>
<executions>
<execution>
<goals>
<goal>test</goal>
</goals>
</execution>
</executions>
<configuration>
<useSystemClassLoader>false</useSystemClassLoader>
<properties>
<property>
<name>usedefaultlisteners</name>
<value>false</value>
</property>
</properties>
<suiteXmlFiles>
<suiteXmlFile>${suite-xml}</suiteXmlFile>
</suiteXmlFiles>
<argLine>${argLine}</argLine>
</configuration>
</plugin>
</plugins>
</build>
</project>Passons maintenant au code ; le Modèle de Page Objet (POM) a été utilisé dans ce projet car il est utile pour réduire la duplication de code et améliorer la maintenance des cas de test.
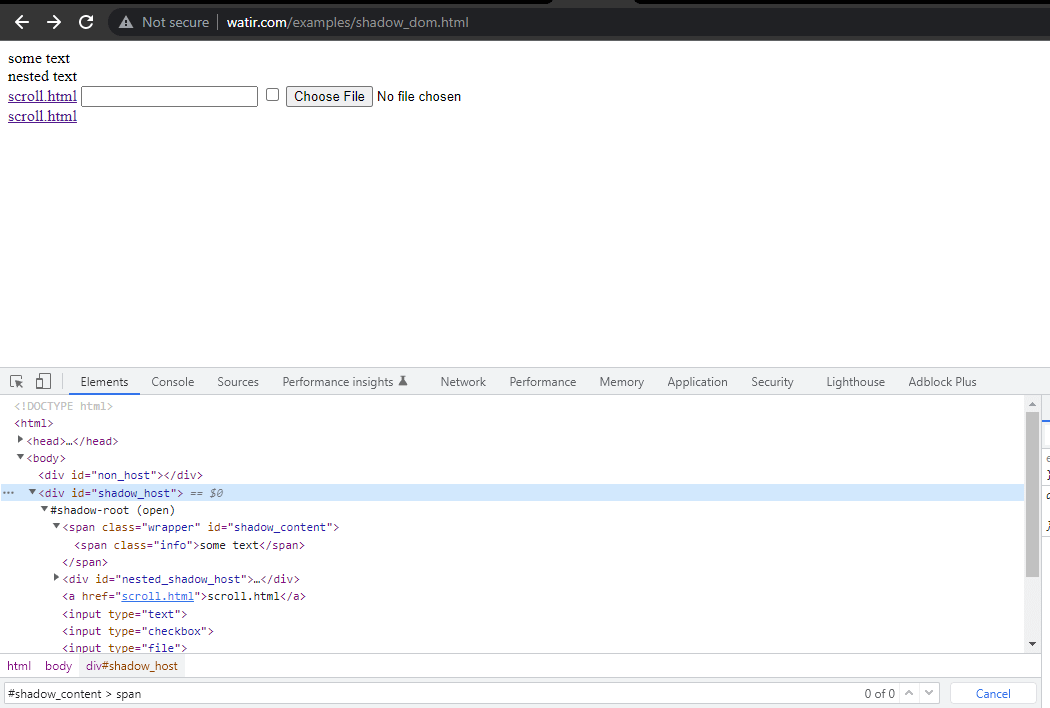
Tout d’abord, nous allons trouver le localisateur pour » some text » et » nested text » sur la page d’accueil.
public class HomePage {
public SearchContext expandRootElement (WebElement element) {
SearchContext shadowRoot = (SearchContext) ((JavascriptExecutor) getDriver ()).executeScript (
"return arguments[0].shadowRoot", element);
return shadowRoot;
}
public String getSomeText () {
return getDriver ().findElement (By.cssSelector ("#shadow_content > span"))
.getText ();
}
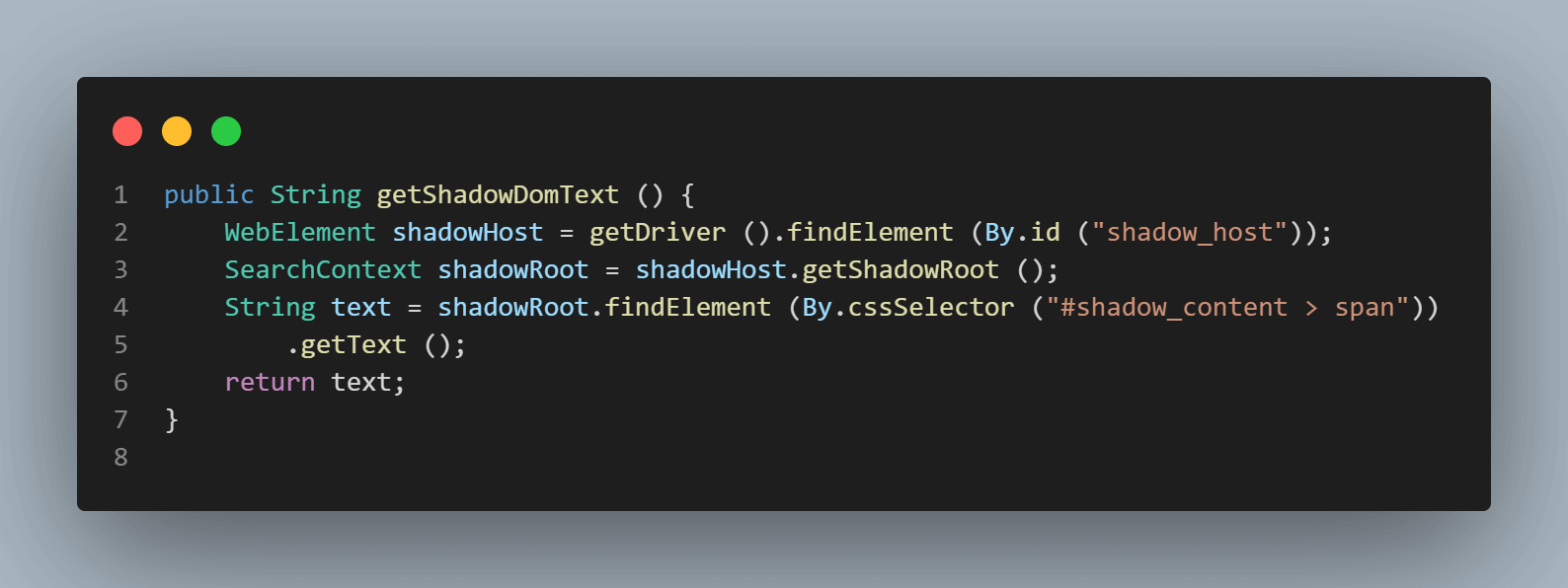
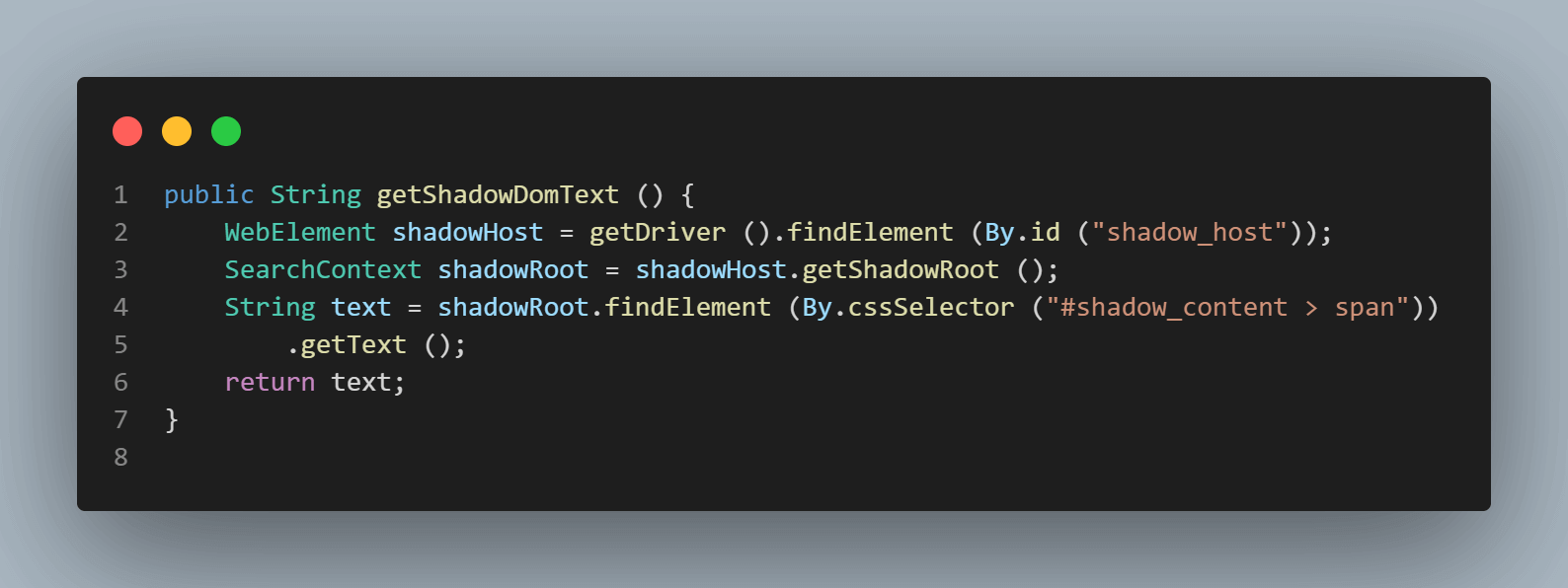
public String getShadowDomText () {
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRoot = shadowHost.getShadowRoot ();
String text = shadowRoot.findElement (By.cssSelector ("#shadow_content > span"))
.getText ();
return text;
}
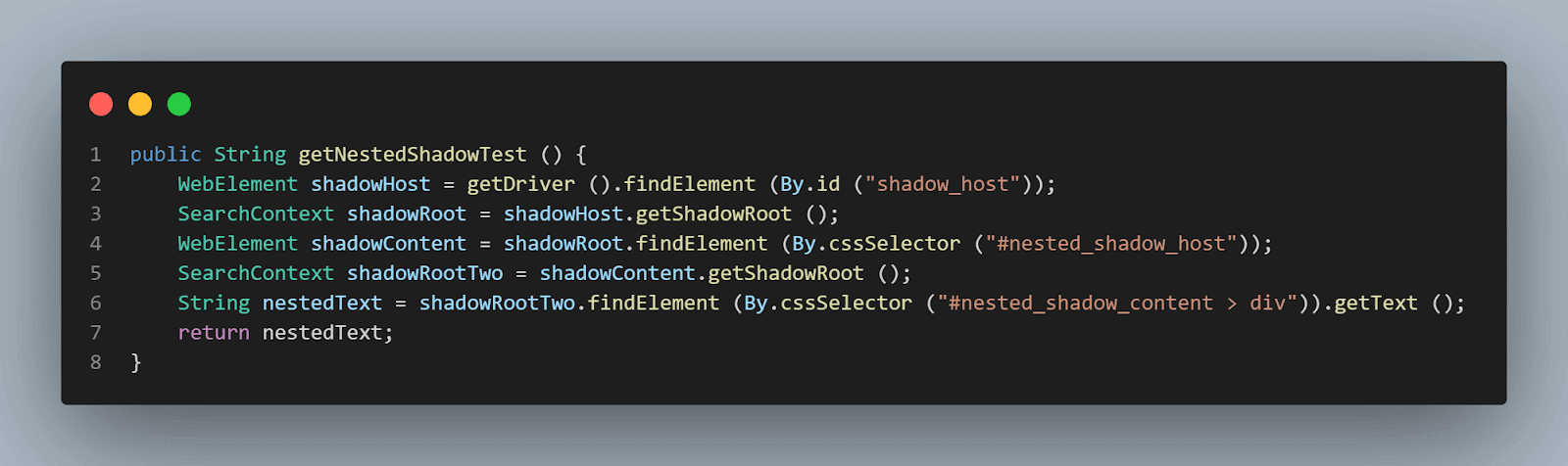
public String getNestedShadowText () {
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRoot = shadowHost.getShadowRoot ();
WebElement shadowContent = shadowRoot.findElement (By.cssSelector ("#nested_shadow_host"));
SearchContext shadowRootTwo = shadowContent.getShadowRoot ();
String nestedText = shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div")).getText ();
return nestedText;
}
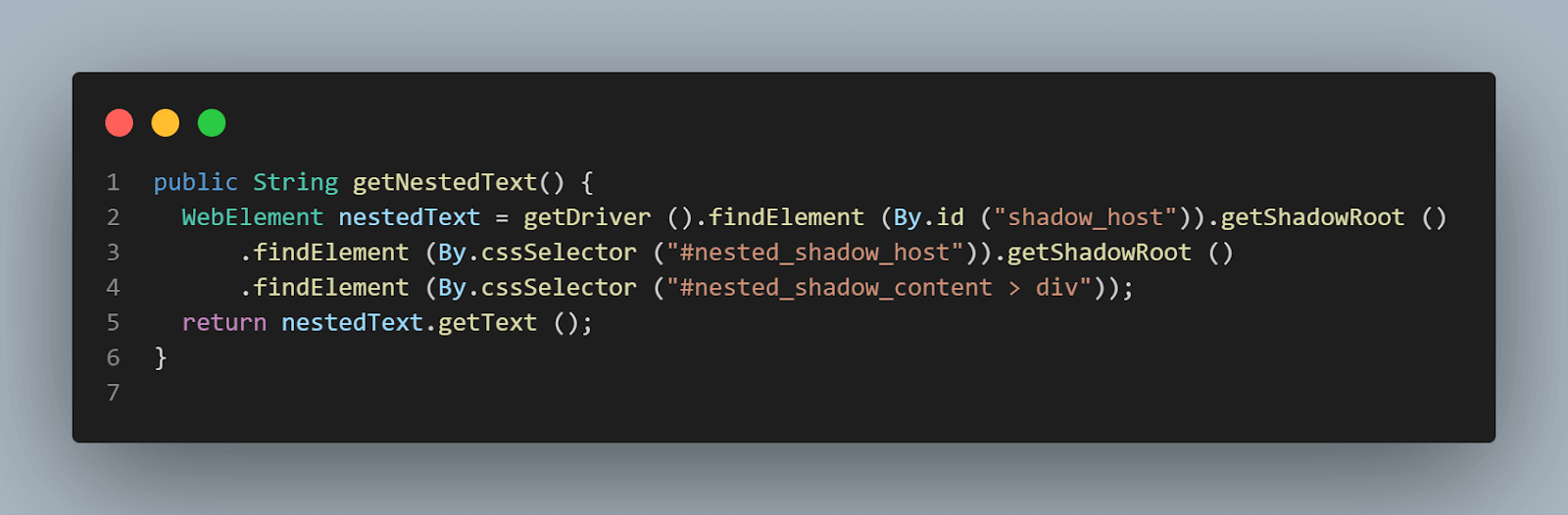
public String getNestedText() {
WebElement nestedText = getDriver ().findElement (By.id ("shadow_host")).getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_host")).getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_content > div"));
return nestedText.getText ();
}
public String getNestedTextUsingJSExecutor () {
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRootOne = expandRootElement (shadowHost);
WebElement nestedShadowHost = shadowRootOne.findElement (By.cssSelector ("#nested_shadow_host"));
SearchContext shadowRootTwo = expandRootElement (nestedShadowHost);
return shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div"))
.getText ();
}
}Explication du Code
Le premier élément que nous allons localiser dans le < div id = "shadow_host" > en utilisant la stratégie de localisateur – id.
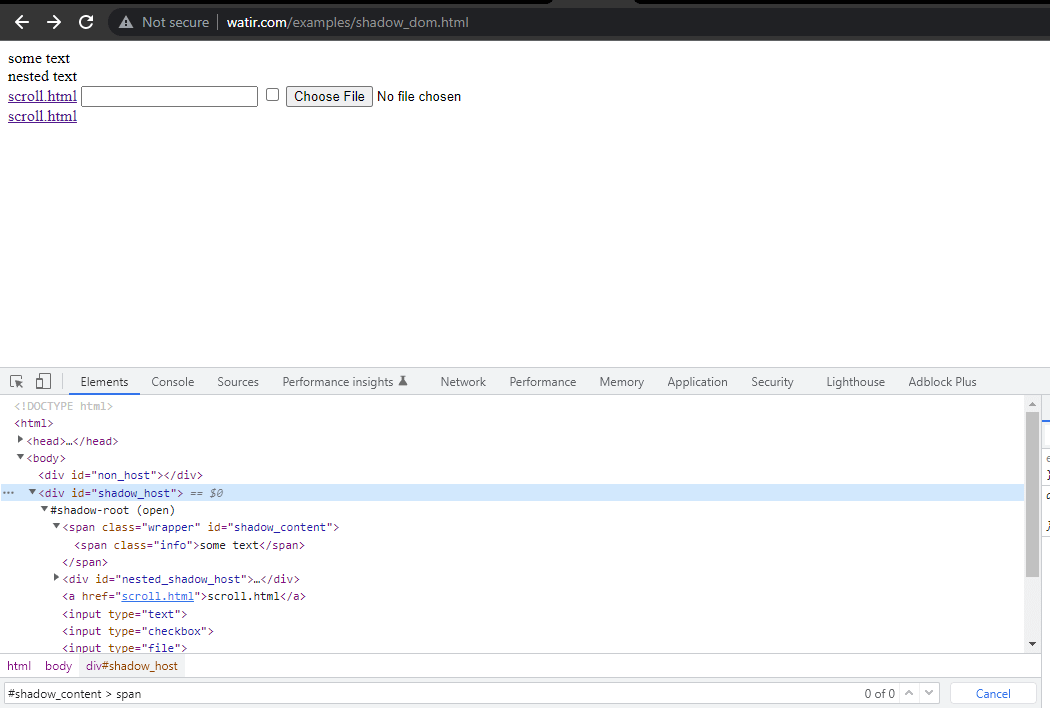
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));Ensuite, nous cherchons le premier Shadow Root dans le DOM à côté de celui-ci. Pour cela, nous avons utilisé l’interface SearchContext. Le Shadow Root est renvoyé en utilisant la méthode getShadowRoot(). Si vous regardez l’image ci-dessus, #shadow-root (open) il est à côté du < div id = "shadow_host" >.
Pour localiser le texte – “some text,”, il n’y a qu’un seul élément Shadow DOM à traverser.
La ligne de code suivante nous aide à obtenir l’élément racine Shadow.
SearchContext shadowRoot = downloadsManager.getShadowRoot();Une fois que le Shadow Root est trouvé, nous pouvons chercher l’élément pour localiser le texte – “some text.” La ligne de code suivante nous aide à obtenir le texte :
String text = shadowRoot.findElement (By.cssSelector ("#shadow_content > span"))
.getText ();Ensuite, trouvons le localisateur de « texte imbriqué, » qui possède un élément racine Shadow imbriqué, et découvrons comment localiser son élément.
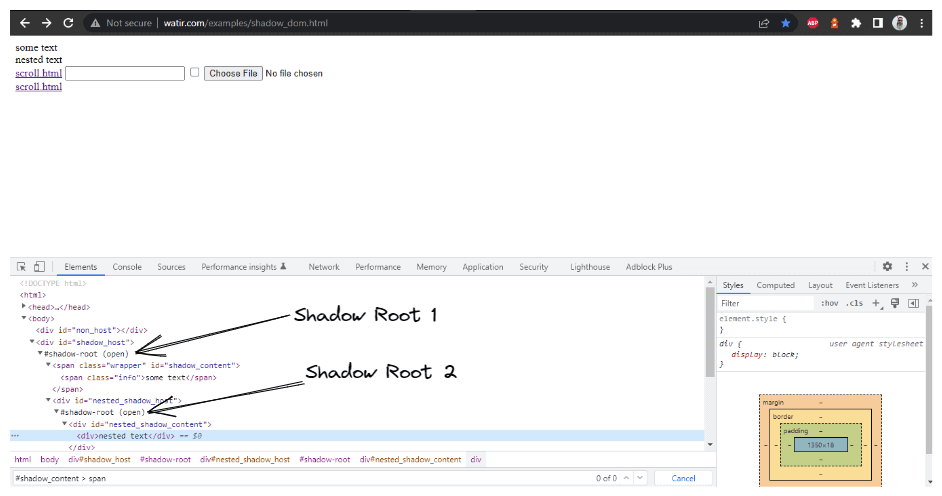
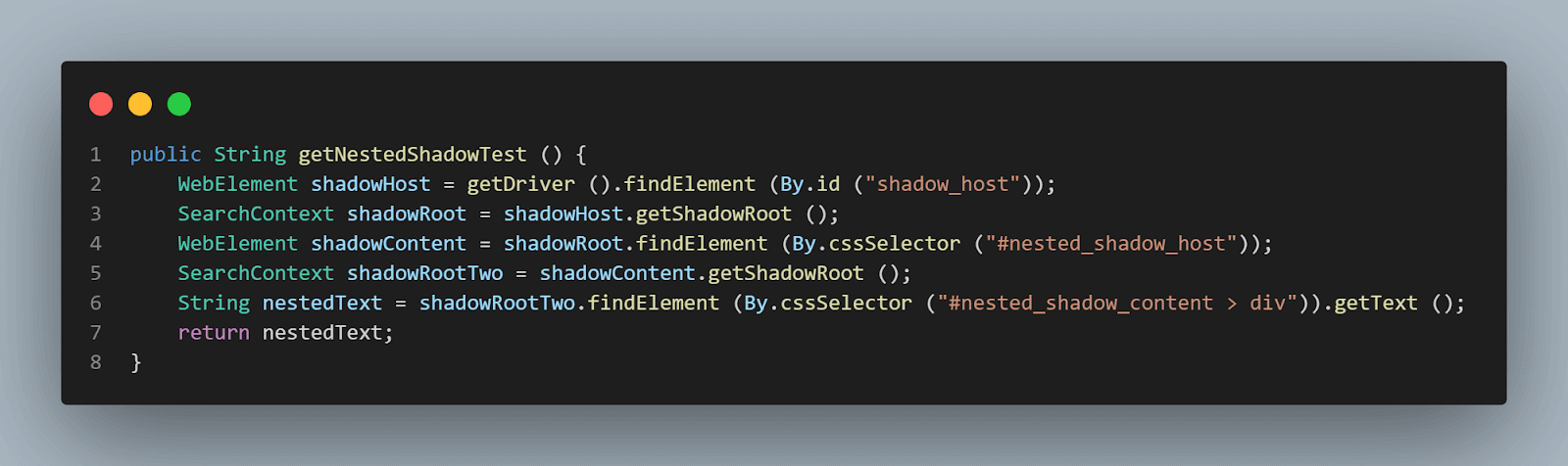
méthode getNestedShadowText() :
En partant du haut, comme discuté dans la section précédente, nous devons localiser < div id = "shadow_host" > en utilisant la stratégie de localisation – id.
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));Après cela, nous devons trouver l’élément racine Shadow en utilisant la méthode getShadowRoot(); une fois que nous obtenons l’élément racine Shadow, nous devons entrer dans la recherche de la deuxième racine Shadow en utilisant cssSelector pour localiser :
<div id ="nested_shadow_host">
SearchContext shadowRoot = shadowHost.getShadowRoot ();
WebElement shadowContent = shadowRoot.findElement (By.cssSelector ("#nested_shadow_host"));Ensuite, nous devons trouver le deuxième élément racine Shadow en utilisant la méthode getShadowRoot(). Enfin, il est temps de localiser l’élément réel pour obtenir le texte – « texte imbriqué. »
La ligne de code suivante nous aidera à localiser le texte :
SearchContext shadowRootTwo = shadowContent.getShadowRoot ();
String nestedText = shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div"Écriture du code de manière fluide
Dans la section précédente de ce blog sur le Shadow DOM dans Selenium, nous avons vu un long chemin à parcourir pour localiser l’élément réel avec lequel nous voulons travailler, et nous devons effectuer plusieurs initialisations des interfaces WebElement et SearchContext et écrire plusieurs lignes de code pour localiser un seul élément avec lequel travailler.
Nous avons également une manière fluide d’écrire tout ce code, et voici comment vous pouvez le faire :
public String getNestedText() {
WebElement nestedText = getDriver ().findElement (By.id ("shadow_host"))
.getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_host"))
.getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_content > div"));
return nestedText.getText ();
}Le design d’une interface fluide repose largement sur la chaînage de méthodes. Le modèle d’interface fluide nous aide à écrire un code facilement lisible qui peut être compris sans avoir besoin d’une compréhension technique du code. Ce terme a été inventé pour la première fois en 2005 par Eric Evans et Martin Fowler.
Ceci est une méthode de chaînage que nous effectuerions pour localiser l’élément.
Ce code fait la même chose que ce que nous avons fait dans les étapes ci-dessus.
- Premièrement, nous localiserions l’élément shadow_host en utilisant son identifiant, puis nous obtiendrions l’élément Shadow Root en utilisant la méthode
getShadowRoot(). - Ensuite, nous chercherions l’élément nested_shadow_host en utilisant le sélecteur CSS et obtiendrions l’élément Shadow Root en utilisant la méthode
getShadowRoot(). - Enfin, nous obtiendrions le texte “texte imbriqué” en utilisant le sélecteur CSS – nested_shadow_content > div.
Comment trouver le Shadow DOM dans Selenium en utilisant JavaScriptExecutor
Dans les exemples de code ci-dessus, nous avons localisé des éléments en utilisant la méthode getShadowRoot(). Voyons maintenant comment nous pouvons localiser les éléments racine Shadow en utilisant JavaScriptExecutor dans Selenium WebDriver.
getNestedTextUsingJSExecutor() méthode a été créée à l’intérieur de la classe HomePage,
où nous étendrons l’élément Shadow Root basé sur le WebElement que nous passons en paramètre. Dans le DOM (comme indiqué dans la capture d’écran ci-dessus), nous avons vu qu’il y a deux éléments Shadow Root que nous devons étendre avant d’accéder au véritable localisateur pour obtenir le texte – texte imbriqué. Par conséquent, la méthode expandRootElement() est créée au lieu de coller à plusieurs reprises le même code exécutable JavaScript.
Nous mettrons en œuvre l’interface SearchContext, qui nous aidera avec le JavaScriptExecutor et retournera l’élément racine Shadow en fonction du WebElement que nous passons en paramètre.
public SearchContext expandRootElement (WebElement element) {
SearchContext shadowRoot = (SearchContext) ((JavascriptExecutor) getDriver ()).executeScript (
"return arguments[0].shadowRoot", element);
return shadowRoot;
}
méthode getNestedTextUsingJSExecutor()
Le premier élément que nous allons localiser est le < div id = "shadow_host" > en utilisant la stratégie de localisation – id.
Ensuite, nous allons étendre l’élément racine basé sur le WebElement shadow_host que nous avons recherché.
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRootOne = expandRootElement (shadowHost);Après avoir étendu le Shadow Root une fois, nous pouvons rechercher un autre WebElement en utilisant cssSelector pour localiser:
<div id ="nested_shadow_host">
WebElement nestedShadowHost = shadowRootOne.findElement (By.cssSelector ("#nested_shadow_host"));
SearchContext shadowRootTwo = expandRootElement (nestedShadowHost);Enfin, il est maintenant temps de localiser l’élément réel pour obtenir le texte – “texte imbriqué.”
La ligne de code suivante nous aidera à localiser le texte:
shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div"))
.getText ();Démonstration
Dans cette section de l’article sur le Shadow DOM dans Selenium, écrivons rapidement un test et vérifions que les localisateurs que nous avons trouvés lors des étapes précédentes nous fournissent le texte requis. Nous pouvons exécuter des assertions sur le code que nous avons écrit pour vérifier que ce que nous attendons du code fonctionne.
@Test
public void testShadowDomWatir () {
getDriver ().get ("http://watir.com/examples/shadow_dom.html");
HomePage homePage = new HomePage ();
// assertEquals (homePage.getSomeText(), "some text");
assertEquals (homePage.getShadowDomText (), "some text");
assertEquals (homePage.getNestedShadowText (),"nested text");
assertEquals (homePage.getNestedText (), "nested text");
assertEquals (homePage.getNestedTextUsingJSExecutor (), "nested text");
}Ceci est juste un test simple pour vérifier que les textes sont affichés correctement comme prévu. Nous vérifierions cela en utilisant l’assertion assertEquals() dans TestNG.
En valeur réelle, nous fournirions la méthode que nous venons d’écrire pour obtenir le texte de la page, et en valeur attendue, nous introduirions le texte “some text” ou “nested text,” en fonction des assertions que nous ferions.
Quatre déclarations assertEquals sont fournies dans le test.
- Vérification de l’élément Shadow DOM à l’aide de la méthode
getShadowRoot():
- Vérification de l’élément Shadow DOM imbriqué à l’aide de la méthode
getShadowRoot():
- Vérification de l’élément Shadow DOM imbriqué à l’aide de la méthode
getShadowRoot()et écriture fluide:
Exécution
Il existe deux façons d’exécuter les tests pour automatiser le Shadow DOM dans Selenium:
- À partir de l’IDE en utilisant TestNG
- À partir de la CLI en utilisant Maven
Automatisation du Shadow DOM dans Selenium WebDriver en utilisant TestNG
TestNG est utilisé comme exécuteur de tests. Par conséquent, un fichier testng.xml a été créé, à l’aide duquel nous allons exécuter les tests en faisant un clic droit sur le fichier et en sélectionnant l’option Run ‘…\testng.xml’. Mais avant d’exécuter les tests, nous devons ajouter le nom d’utilisateur et la clé d’accès LambdaTest dans les Configurations de lancement puisque nous lisons le nom d’utilisateur et la clé d’accès à partir d’une propriété système.
LambdaTest propose des tests multi-navigateurs sur une ferme de navigateurs en ligne comptant plus de 3000 navigateurs réels et systèmes d’exploitation pour vous aider à exécuter des tests Java à la fois localement et/ou dans le cloud. Vous pouvez accélérer vos tests Selenium avec Java et réduire le temps d’exécution des tests de plusieurs fois en exécutant des tests parallèles sur divers navigateurs et configurations OS.
- Ajoutez les valeurs dans les Configurations de lancement comme mentionné ci-dessous :
- Dusername =
< Nom d'utilisateur LambdaTest > - DaccessKey =
< Clé d'accès LambdaTest >
- Dusername =
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd">
<suite name="Sauce Demo Website Tests">
<test name="Shadow DOM Tests on Watir Website">
<parameter name="browser" value="remote-chrome"/>
<classes>
<class name="ShadowDomTests">
<methods>
<include name="testShadowDomWatir"/>
</methods>
</class>
</classes>
</test> <!-- Test -->
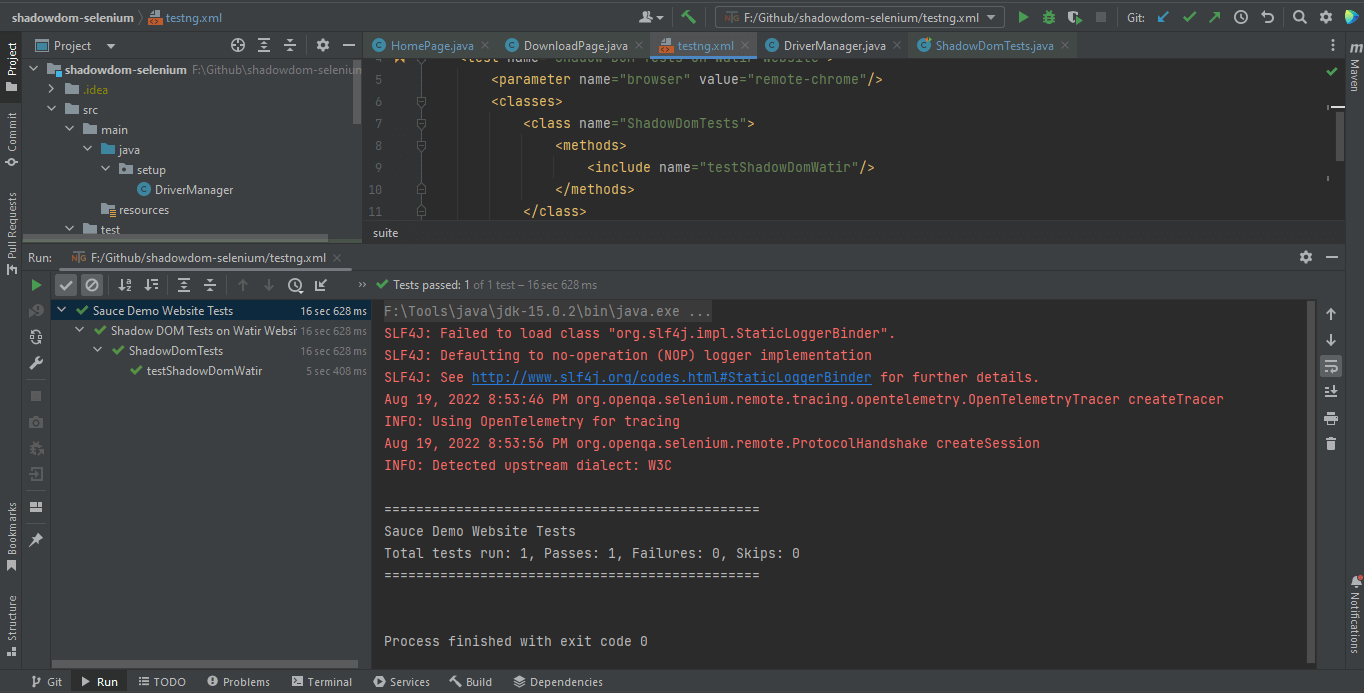
</suite>Voici la capture d’écran de l’exécution des tests localement pour Shadow DOM dans Selenium à l’aide d’Intellij IDE.
Automatisation du Shadow DOM dans Selenium WebDriver à l’aide de Maven
Pour exécuter les tests à l’aide de Maven, les étapes suivantes doivent être effectuées pour automatiser le Shadow DOM dans Selenium :
- Ouvrez la Commande Prompt/Terminal.
- Accédez au dossier racine du projet.
- Tapez la commande :
mvn clean install -Dusername=< Nom d'utilisateur LambdaTest > -DaccessKey=< Clé d'accès LambdaTest >.
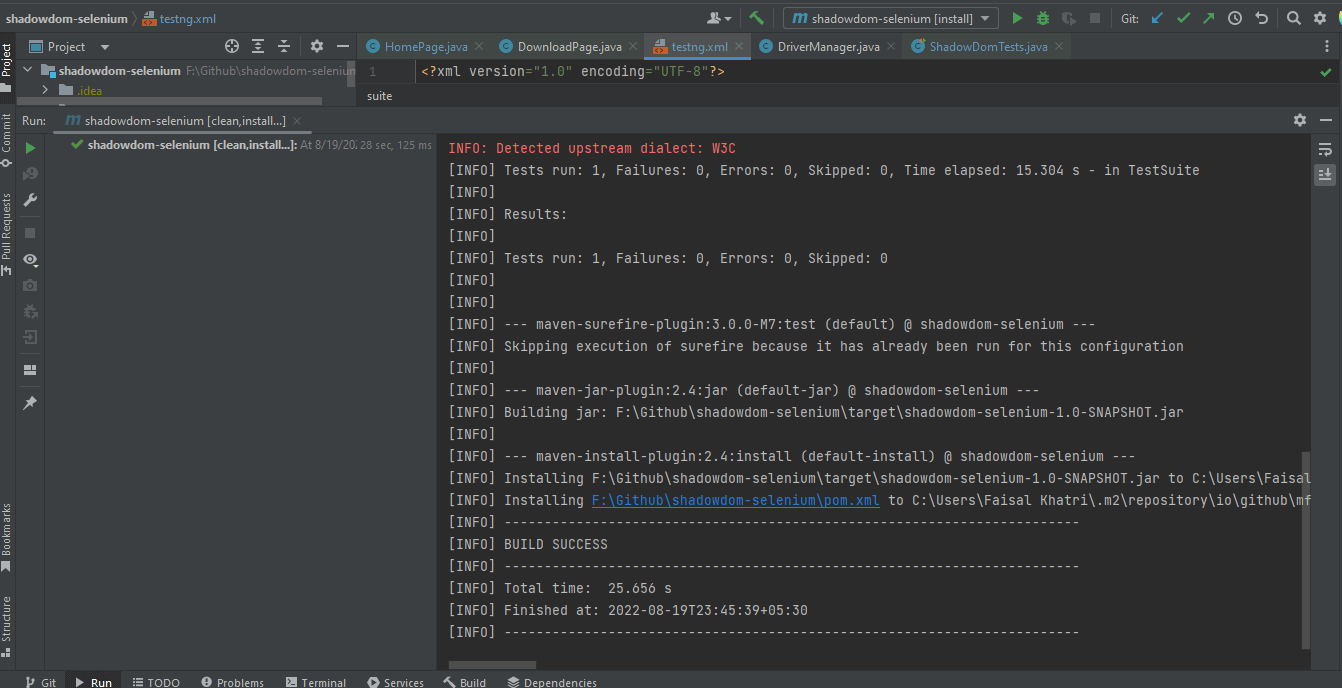
Voici une capture d’écran d’IntelliJ, qui montre l’état d’exécution des tests utilisant Maven:
Une fois les tests réussis, nous pouvons consulter le tableau de bord LambdaTest et visualiser toutes les vidéos enregistrées, les captures d’écran, les journaux d’appareils et les détails granulaires étape par étape de l’exécution des tests. Consultez les captures d’écran ci-dessous, qui vous donneront une idée juste du tableau de bord pour les tests automatisés d’applications.
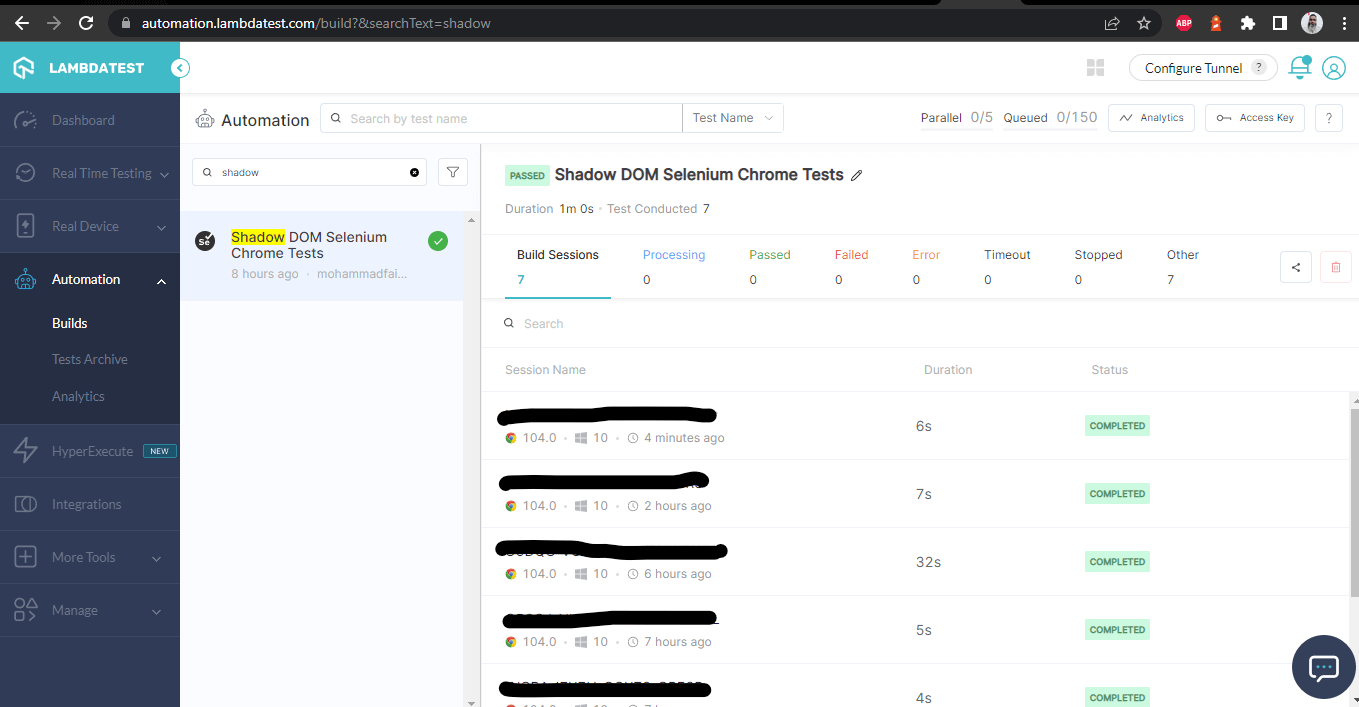 Tableau de bord LambdaTest
Tableau de bord LambdaTest
Les captures d’écran suivantes montrent les détails de la build et des tests exécutés pour l’automatisation du Shadow DOM dans Selenium. Encore une fois, le nom du test, le nom du navigateur, la version du navigateur, le nom du système d’exploitation, la version correspondante du système d’exploitation et la résolution d’écran sont tous correctement visibles pour chaque test.
Il inclut également la vidéo du test exécuté, donnant une meilleure idée de la façon dont les tests ont été exécutés sur l’appareil.
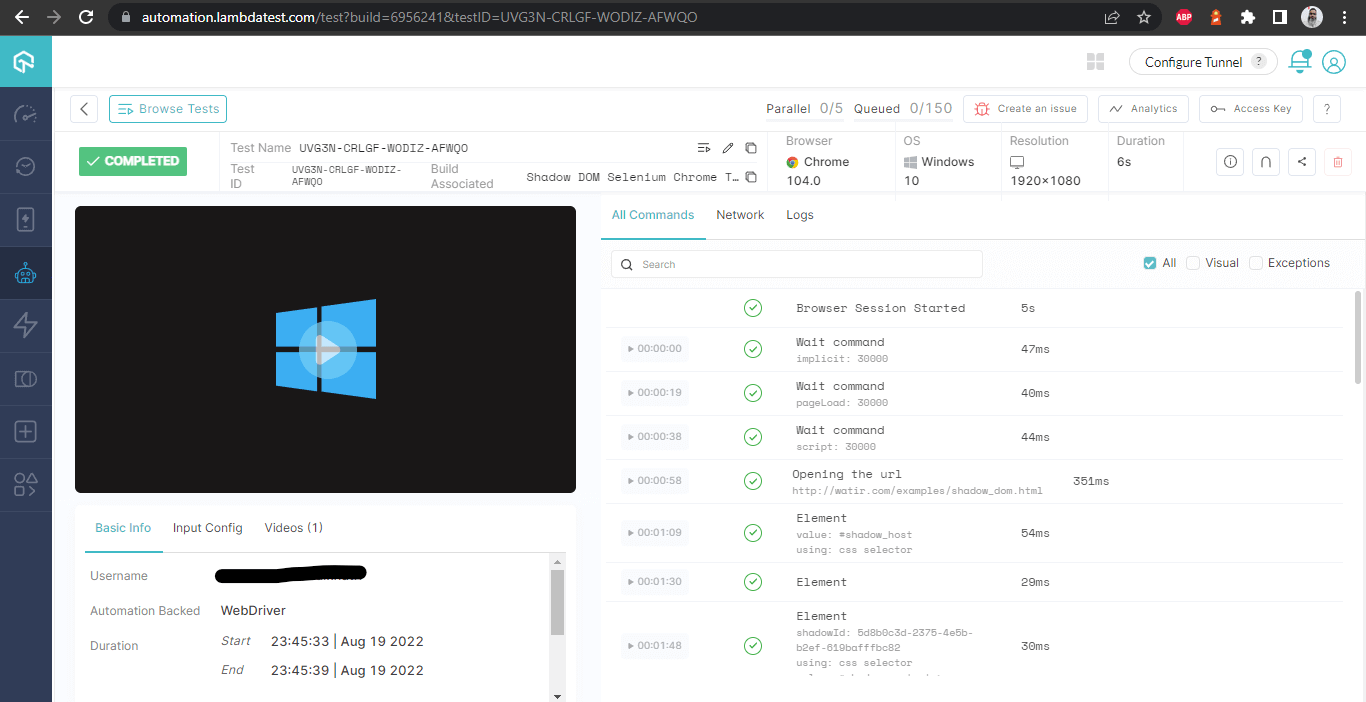 Détails de la build
Détails de la build
Cette écran affiche tous les métriques en détail, qui sont très utiles du point de vue du testeur pour vérifier quel test a été exécuté sur quel navigateur et voir en conséquence les journaux pour l’automatisation du Shadow DOM dans Selenium.
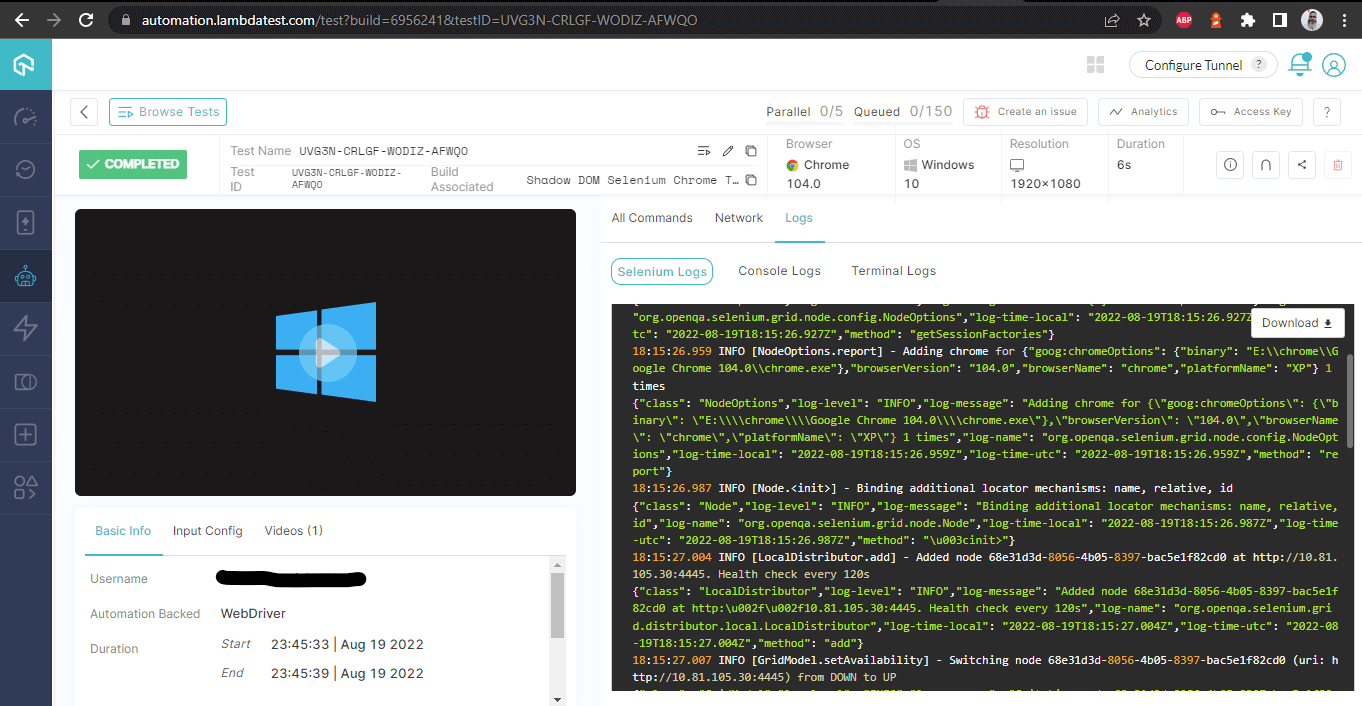 Détails de construction – avec journaux
Détails de construction – avec journaux
Vous pouvez accéder aux derniers résultats des tests, à leur statut et au nombre total de tests réussis ou échoués dans le tableau de bord d’analyse de LambdaTest. De plus, vous pouvez voir des captures d’écran des derniers exécutions de tests dans la section Vue d’ensemble des tests.
Conclusion
Dans ce blog sur l’automatisation du Shadow DOM dans Selenium, nous avons discuté de la manière de trouver les éléments du Shadow DOM et de les automatiser en utilisant la méthode getShadowRoot() introduite dans la version 4.0.0 et ultérieure de Selenium WebDriver.
Nous avons également discuté de la localisation et de l’automatisation des éléments Shadow DOM à l’aide de JavaScriptExecutor dans Selenium WebDriver et de l’exécution des tests sur la plateforme de LambdaTest, qui montre des détails granulaires des tests qui ont été exécutés avec les journaux de Selenium WebDriver.
I hope this blog on Shadow DOM in Selenium gives you a fair idea about automating Shadow DOM elements using Selenium WebDriver.
Bonne chance avec vos tests !
Source:
https://dzone.com/articles/how-to-automate-shadow-dom-in-selenium-webdriver