













I came across one of the test cases in my previous projects where I had to click on a button to navigate to the next page. I searched for the element locator of the button on the page and ran the tests hoping it would click the button and navigate to the next page.
Mas, para minha surpresa, o teste falhou porque não conseguiu localizar o elemento e recebi NoSuchElementException nos logs do console. Não fiquei feliz ao ver esse erro, pois era um botão simples que estava tentando clicar e não havia complexidade.
Ao analisar o problema mais a fundo, expandindo o DOM e verificando os elementos raiz, descobri que o localizador do botão estava dentro do #shadow-root(open) nó da árvore, o que me fez perceber que precisa ser tratado de forma diferente, pois é um elemento Shadow DOM.
Neste tutorial do Selenium WebDriver, discutiremos elementos Shadow DOM e como automatizar o Shadow DOM no Selenium WebDriver. Antes de passarmos para a automação do Shadow DOM no Selenium, vamos primeiro entender o que é o Shadow DOM e por que é usado.
O que é Shadow DOM?
Shadow DOM é uma funcionalidade que permite que o navegador web renderize elementos DOM sem colocá-los na árvore DOM principal do documento. Isso cria uma barreira entre o que o desenvolvedor e o navegador podem alcançar; o desenvolvedor não pode acessar o Shadow DOM da mesma maneira que acessaria elementos aninhados, enquanto o navegador pode renderizar e modificar esse código da mesma forma que faria com elementos aninhados.
O Shadow DOM é uma maneira de alcançar encapsulamento no documento HTML. Ao implementá-lo, você pode manter o estilo e o comportamento de uma parte do documento ocultos e separados do restante do código do mesmo documento, de modo que não haja interferência.
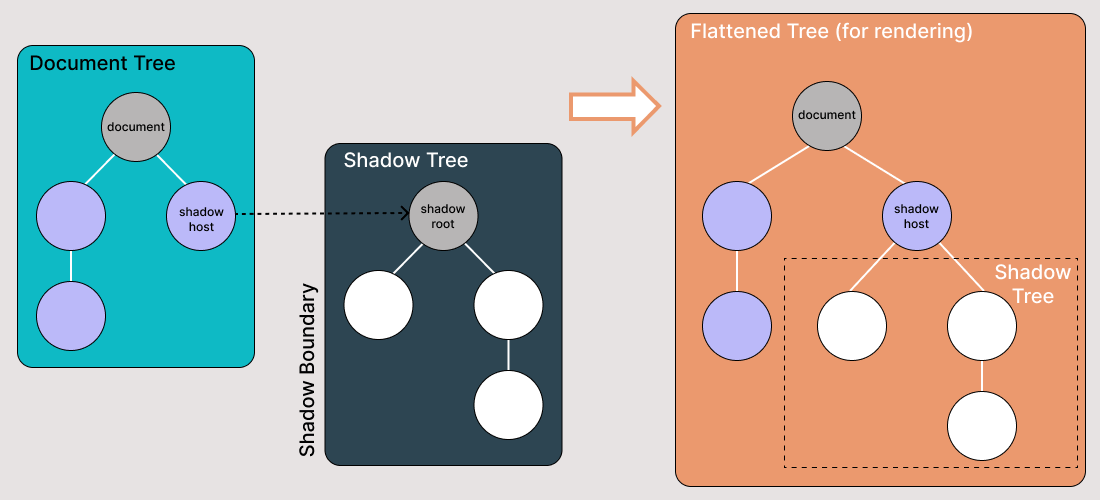
O Shadow DOM permite que árvores DOM ocultas sejam anexadas a elementos na árvore DOM regular — a árvore Shadow DOM começa com uma raiz Shadow, embaixo da qual você pode anexar quaisquer elementos da mesma maneira que o DOM normal.
Existem algumas partes da terminologia do Shadow DOM que devem ser conhecidas:
- Anfitrião Shadow: O nó DOM regular ao qual o Shadow DOM está anexado
- Árvore Shadow: A árvore DOM dentro do Shadow DOM
- A fronteira Shadow é onde o Shadow DOM termina e o DOM regular começa.
- Raiz Shadow: O nó raiz da árvore Shadow
Qual é a Utilização do Shadow DOM?
O Shadow DOM serve para encapsulamento. Permite que um componente tenha sua própria “sombra” árvore DOM que não pode ser acessada acidentalmente a partir do documento principal, pode ter regras de estilo locais e muito mais.
Aqui estão algumas das propriedades essenciais do Shadow DOM:
- Têm seu próprio espaço de ids
- Invisível para seletores JavaScript do documento principal, como querySelector
- Usam estilos apenas da árvore Shadow, não do documento principal
Encontrando Elementos do Shadow DOM Usando Selenium WebDriver
Quando tentamos encontrar os elementos do Shadow DOM usando localizadores Selenium, recebemos NoSuchElementException pois não é diretamente acessível ao DOM.
Usaríamos a seguinte estratégia para acessar os localizadores do Shadow DOM:
- Usando JavaScriptExecutor.
- Usando o método
getShadowDom()do Selenium WebDriver.
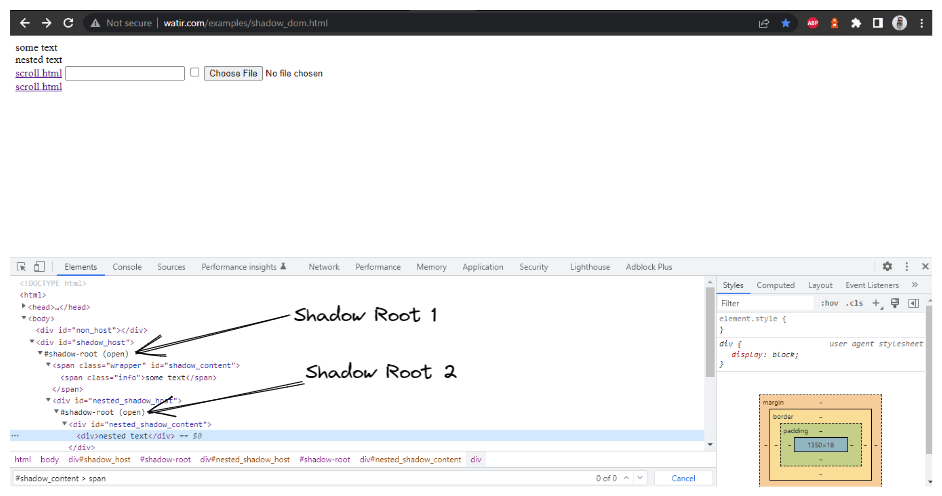
Nesta seção de blog sobre automação do Shadow DOM no Selenium, vamos usar como exemplo a Watir.com página inicial e tentar afirmar o texto do shadow dom e do shadow dom aninhado com o Selenium WebDriver. Observe que há um elemento raiz de sombra antes de chegarmos ao texto -> algum texto, e existem dois elementos raiz de sombra antes de chegarmos ao texto -> texto aninhado.
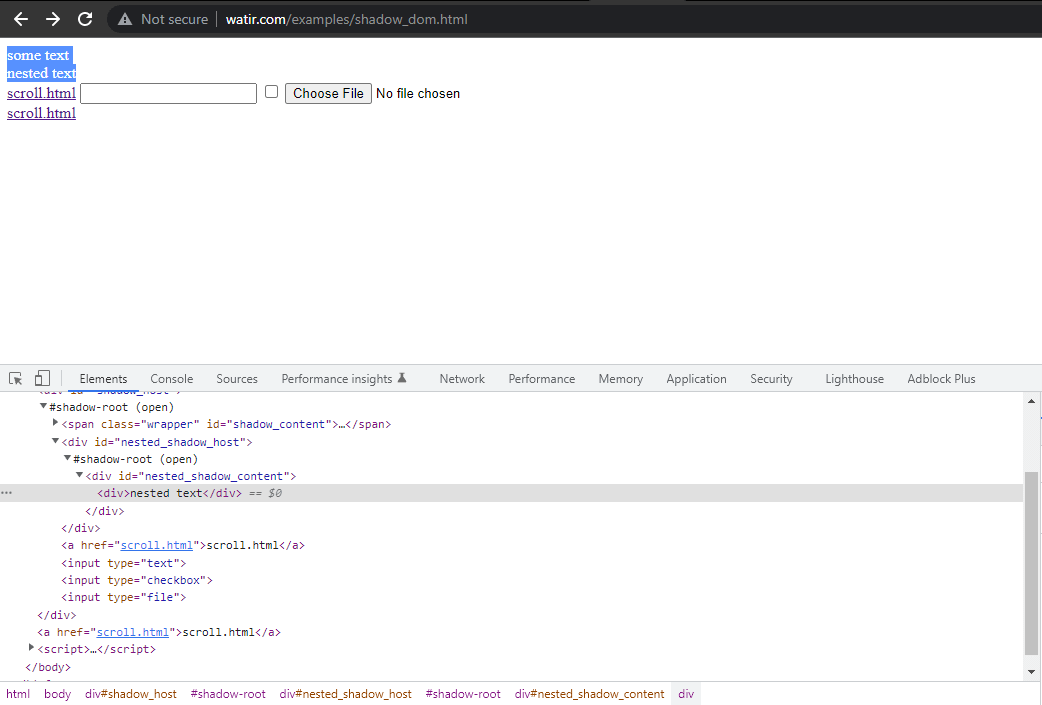
Agora, se tentarmos localizar o elemento usando o cssSelector("#shadow_content > span"), ele
não é localizado e o Selenium WebDriver lançará o NoSuchElementException.
Aqui está a captura de tela da classe Homepage, que tem o código que tenta obter o texto usando
cssSelector(“#shadow_content > span”).

Aqui está a captura de tela dos testes onde tentamos afirmar o texto(“algum texto”).
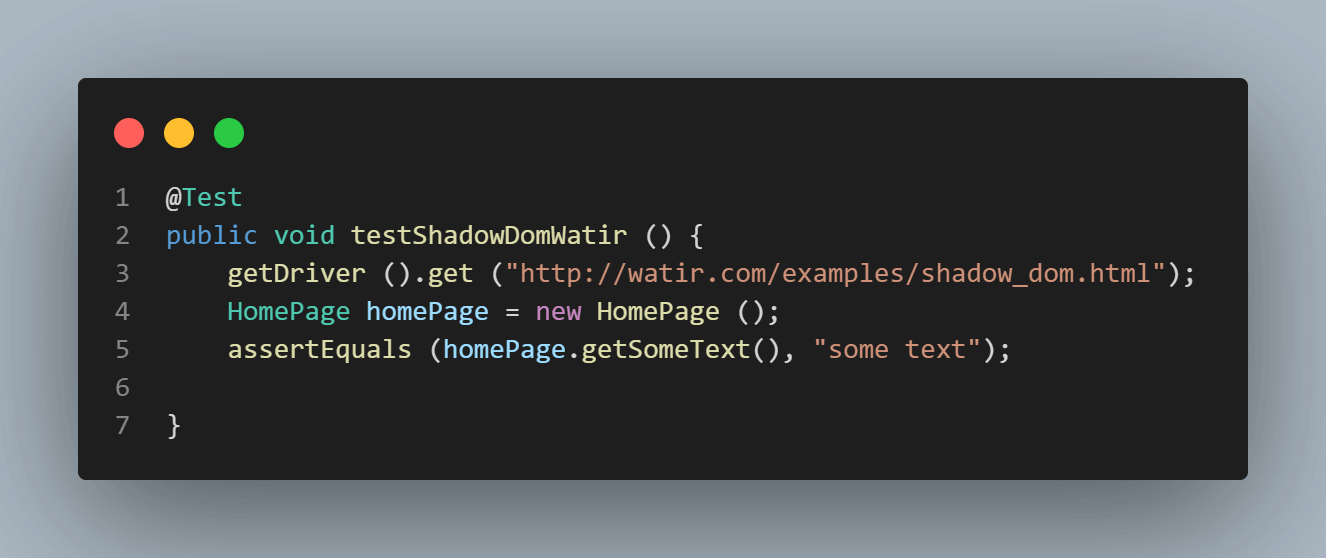
Erro ao executar os testes mostra NoSuchElementException
Para localizar o elemento corretamente para o texto, precisamos passar pelos elementos raiz de sombra. Somente assim poderemos localizar “algum texto” e “texto aninhado” na página?
Como Encontrar o Shadow DOM no Selenium WebDriver Usando o Método ‘getShadowDom’
Com o lançamento da versão 4.0.0 e acima do Selenium WebDriver, o getShadowRoot() foi introduzido e ajudou a localizar elementos raiz de sombra.
Aqui estão a sintaxe e os detalhes do método getShadowRoot():
default SearchContext getShadowRoot()
Returns:
The ShadowRoot class represents the shadow root of a web component. With a shadow root, you can access the shadow DOM of a web component.
Throws:
NoSuchShadowRootException - If shadow root is not found.De acordo com a documentação, o método getShadowRoot() retorna uma representação da raiz de sombra de um elemento para acessar o DOM de sombra de um componente web.
Caso a raiz de sombra não seja encontrada, ele lançará NoSuchShadowRootException.
Antes de começarmos a escrever os testes e discutir o código, deixe-me contar-lhe sobre as ferramentas que usaremos para escrever e executar os testes:
As seguintes linguagens de programação e ferramentas foram utilizadas na escrita e execução dos testes:
- Linguagem de Programação: Java 11
- Ferramenta de Automação Web: Selenium WebDriver
- Executador de Testes: TestNG
- Ferramenta de Construção: Maven
- Plataforma em Nuvem: LambdaTest
Começando com a Busca do DOM de Sombra no Selenium WebDriver
Como discutido anteriormente, este projeto sobre o DOM de sombra no Selenium foi criado usando Maven. TestNG é usado como executador de testes. Para saber mais sobre Maven, você pode ler este blog sobre começando com Maven para testes com Selenium.
Uma vez criado o projeto, precisamos adicionar a dependência para Selenium WebDriver, e TestNG no arquivo pom.xml.
Versões das dependências são definidas em um bloco de propriedades separado. Isso é feito para facilitar a manutenção, de modo que, se precisarmos atualizar as versões, podemos fazê-lo facilmente sem precisar procurar a dependência por todo o arquivo pom.xml.
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>io.github.mfaisalkhatri</groupId>
<artifactId>shadowdom-selenium</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<selenium.java.version>4.4.0</selenium.java.version>
<testng.version>7.6.1</testng.version>
<webdrivermanager.version>5.2.1</webdrivermanager.version>
<maven.compiler.version>3.10.1</maven.compiler.version>
<surefire-version>3.0.0-M7</surefire-version>
<java.release.version>11</java.release.version>
<maven.source.encoding>UTF-8</maven.source.encoding>
<suite-xml>testng.xml</suite-xml>
<argLine>-Dfile.encoding=UTF-8 -Xdebug -Xnoagent</argLine>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.seleniumhq.selenium/selenium-java -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>${selenium.java.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.testng/testng -->
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>${testng.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.github.bonigarcia</groupId>
<artifactId>webdrivermanager</artifactId>
<version>${webdrivermanager.version}</version>
<exclusions>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>${maven.compiler.version}</version>
<configuration>
<release>${java.release.version}</release>
<encoding>${maven.source.encoding}</encoding>
<forceJavacCompilerUse>true</forceJavacCompilerUse>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>${surefire-version}</version>
<executions>
<execution>
<goals>
<goal>test</goal>
</goals>
</execution>
</executions>
<configuration>
<useSystemClassLoader>false</useSystemClassLoader>
<properties>
<property>
<name>usedefaultlisteners</name>
<value>false</value>
</property>
</properties>
<suiteXmlFiles>
<suiteXmlFile>${suite-xml}</suiteXmlFile>
</suiteXmlFiles>
<argLine>${argLine}</argLine>
</configuration>
</plugin>
</plugins>
</build>
</project>Vamos agora para o código; o Modelo de Objeto de Página (POM) foi utilizado neste projeto, pois é útil para reduzir a duplicação de código e melhorar a manutenção dos casos de teste.
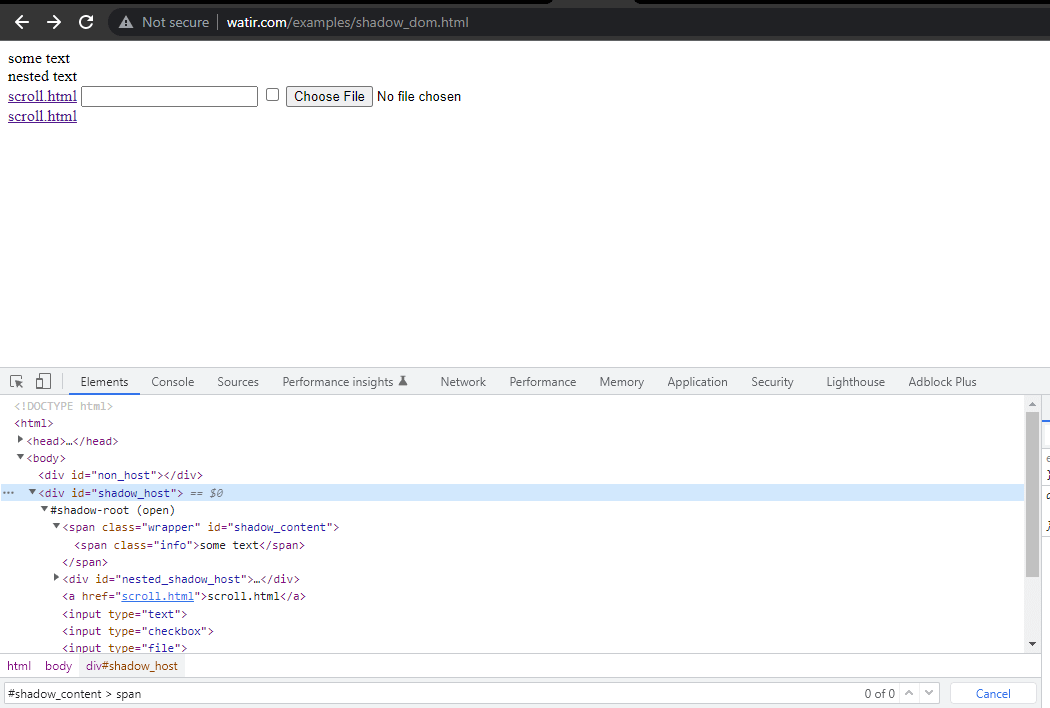
Primeiro, encontraríamos o localizador para “algum texto” e “texto aninhado” na HomePage.
public class HomePage {
public SearchContext expandRootElement (WebElement element) {
SearchContext shadowRoot = (SearchContext) ((JavascriptExecutor) getDriver ()).executeScript (
"return arguments[0].shadowRoot", element);
return shadowRoot;
}
public String getSomeText () {
return getDriver ().findElement (By.cssSelector ("#shadow_content > span"))
.getText ();
}
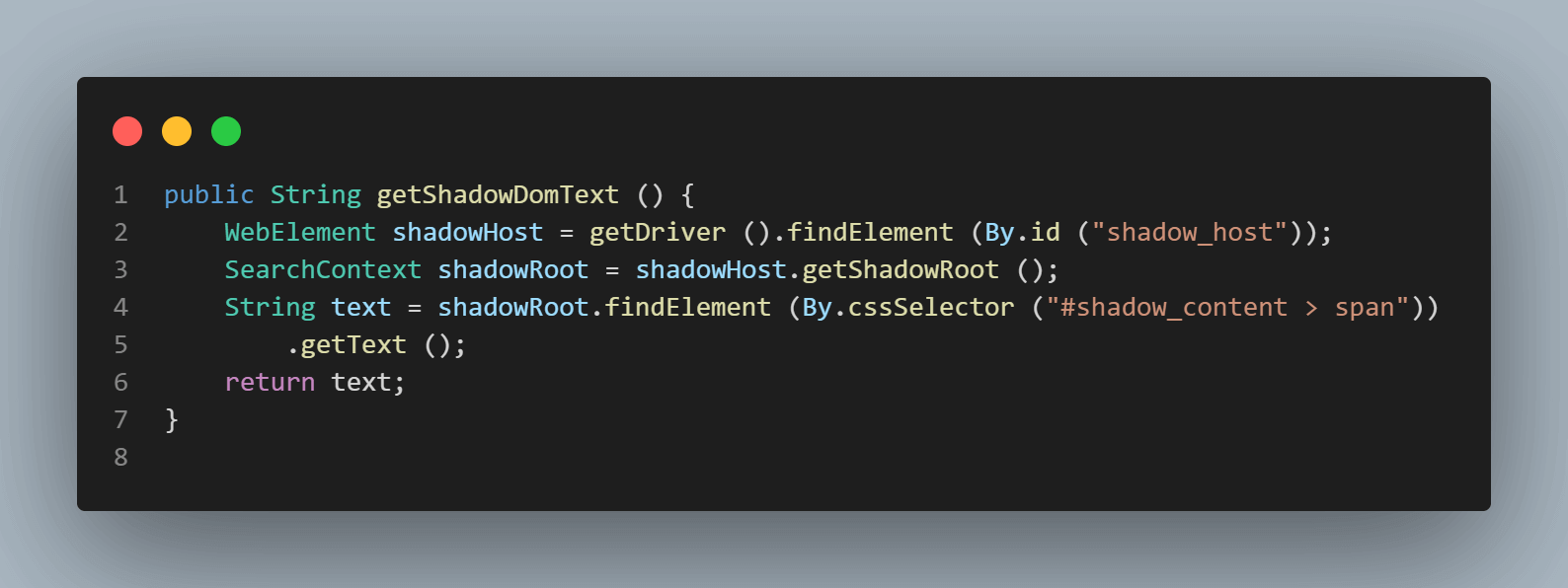
public String getShadowDomText () {
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRoot = shadowHost.getShadowRoot ();
String text = shadowRoot.findElement (By.cssSelector ("#shadow_content > span"))
.getText ();
return text;
}
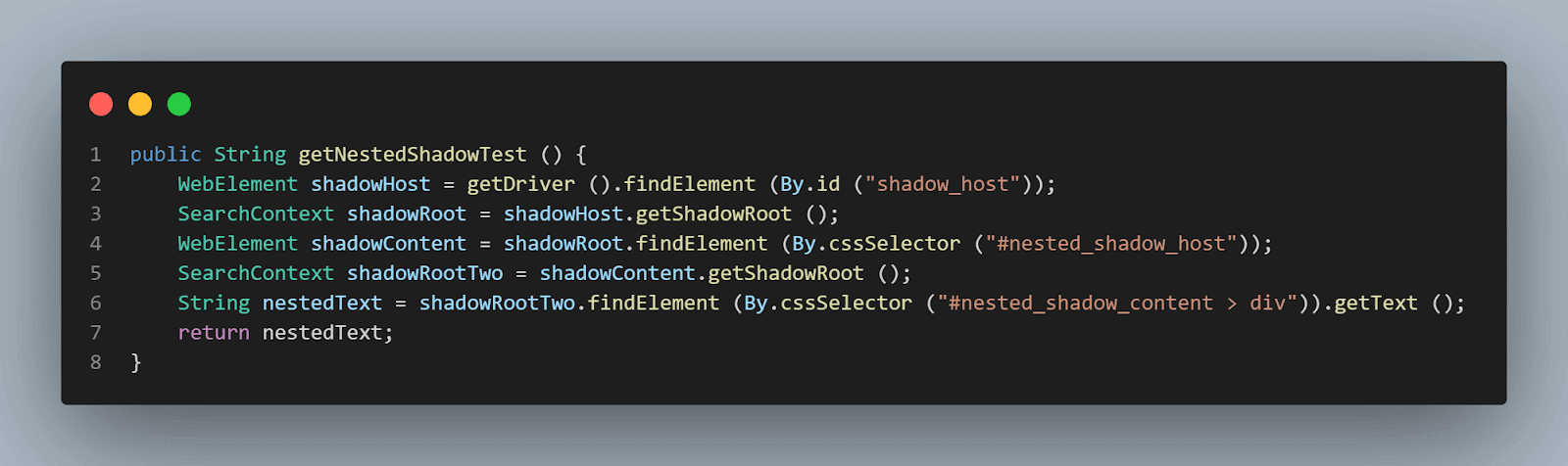
public String getNestedShadowText () {
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRoot = shadowHost.getShadowRoot ();
WebElement shadowContent = shadowRoot.findElement (By.cssSelector ("#nested_shadow_host"));
SearchContext shadowRootTwo = shadowContent.getShadowRoot ();
String nestedText = shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div")).getText ();
return nestedText;
}
public String getNestedText() {
WebElement nestedText = getDriver ().findElement (By.id ("shadow_host")).getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_host")).getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_content > div"));
return nestedText.getText ();
}
public String getNestedTextUsingJSExecutor () {
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRootOne = expandRootElement (shadowHost);
WebElement nestedShadowHost = shadowRootOne.findElement (By.cssSelector ("#nested_shadow_host"));
SearchContext shadowRootTwo = expandRootElement (nestedShadowHost);
return shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div"))
.getText ();
}
}Roteiro do Código
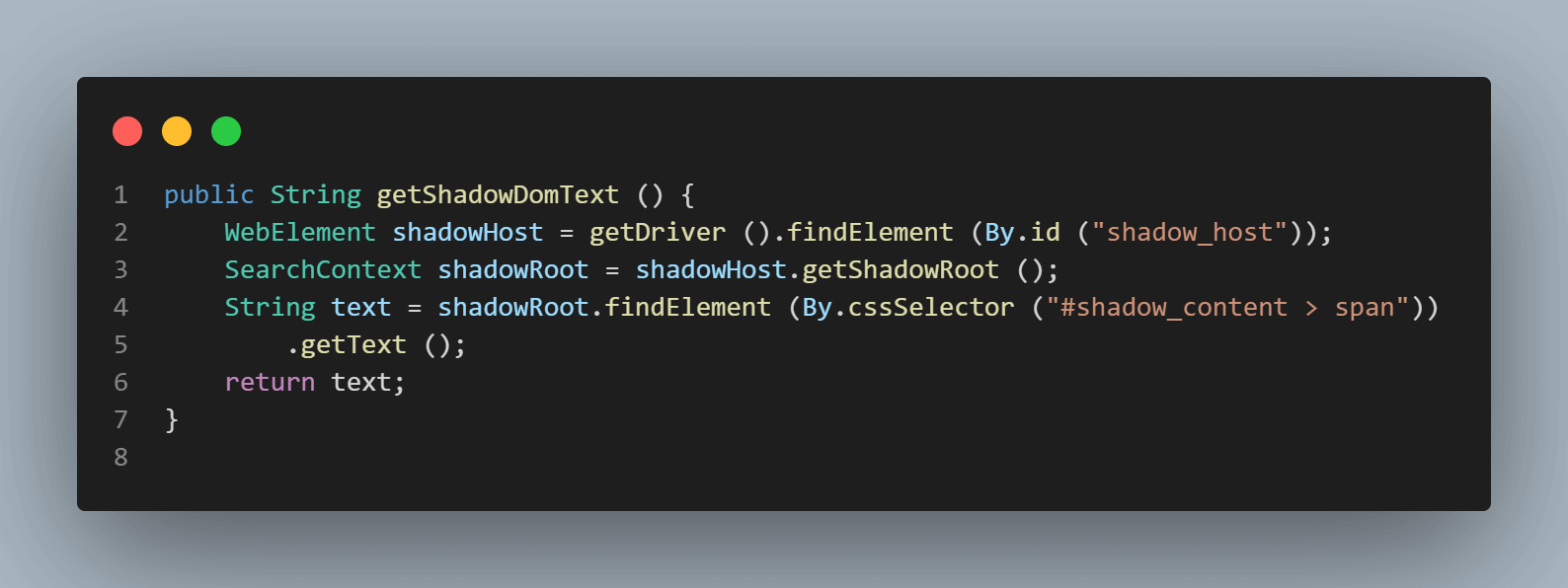
O primeiro elemento que localizaremos no < div id = "shadow_host" > usando a estratégia de localizador – id.
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));Em seguida, pesquisamos pela primeira Shadow Root no DOM ao lado disso. Para isso, utilizamos a interface SearchContext. A Shadow Root é retornada usando o método getShadowRoot(). Se você verificar a captura de tela acima, #shadow-root (open) está ao lado do < div id = "shadow_host" >.
Para localizar o texto – “algum texto,”, há apenas um elemento Shadow DOM pelo qual precisamos passar.
A seguinte linha de código nos ajuda a obter o elemento raiz Shadow.
SearchContext shadowRoot = downloadsManager.getShadowRoot();Uma vez encontrada a Shadow Root, podemos pesquisar pelo elemento para localizar o texto – “algum texto.” A seguinte linha de código nos ajuda a obter o texto:
String text = shadowRoot.findElement (By.cssSelector ("#shadow_content > span"))
.getText ();Em seguida, vamos encontrar o localizador de “texto aninhado,” que possui um elemento Shadow root aninhado, e vamos descobrir como localizar seu elemento.
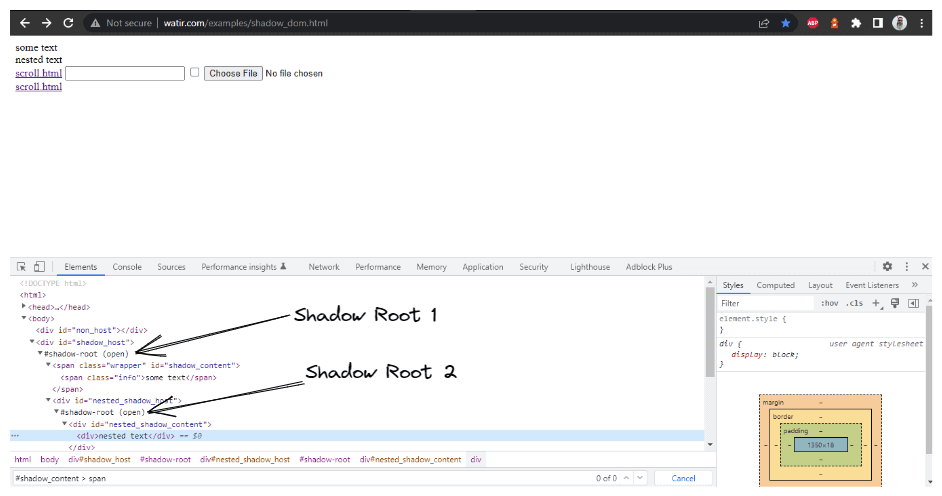
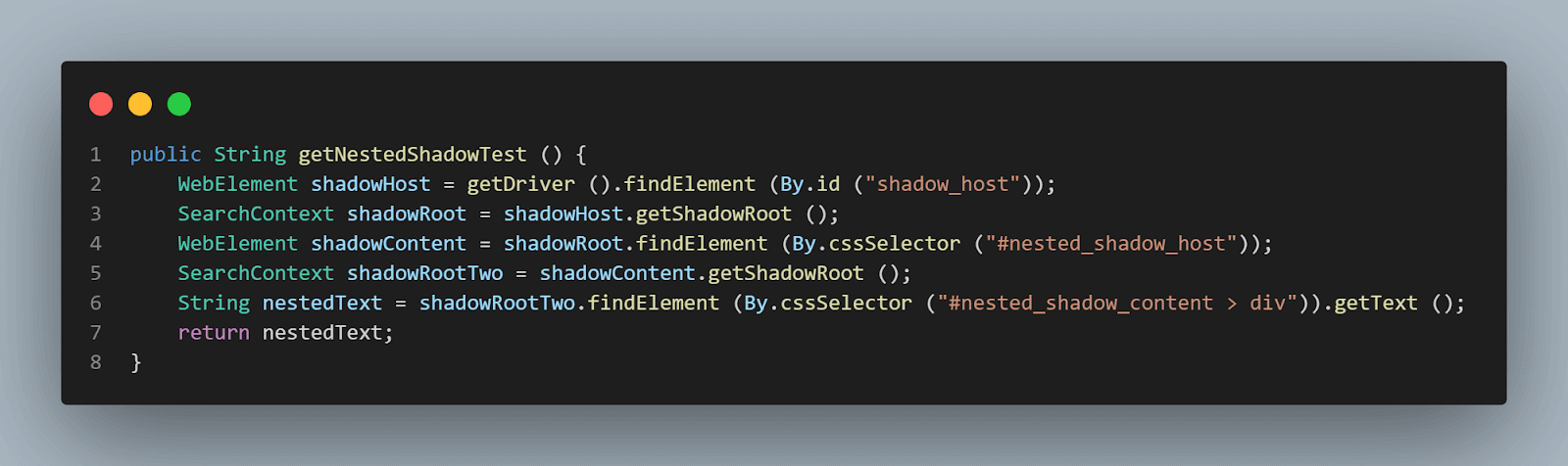
método getNestedShadowText():
A partir do topo, como discutido na seção acima, precisamos localizar< div id = "shadow_host" > usando a estratégia de localizador – id.
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));Depois disso, precisamos encontrar o elemento Shadow Root usando o getShadowRoot() método; uma vez que obtemos o elemento raiz Shadow, precisaremos entrar na busca pelo segundo Shadow root usando cssSelector para localizar:
<div id ="nested_shadow_host">
SearchContext shadowRoot = shadowHost.getShadowRoot ();
WebElement shadowContent = shadowRoot.findElement (By.cssSelector ("#nested_shadow_host"));Em seguida, precisamos encontrar o segundo elemento Shadow Root usando o getShadowRoot() método. Finalmente, é hora de localizar o elemento real para obter o texto – “texto aninhado.”
A seguinte linha de código nos ajudará a localizar o texto:
SearchContext shadowRootTwo = shadowContent.getShadowRoot ();
String nestedText = shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div"Escrevendo o Código de Forma Fluente
Na seção acima deste blog sobre o Shadow DOM no Selenium, vimos um caminho longo de onde temos que localizar o elemento real com o qual queremos trabalhar, e temos que fazer múltiplas inicializações dos WebElement e SearchContext interfaces e escrever múltiplas linhas de código para localizar um único elemento para trabalhar.
Temos uma maneira fluente de escrever todo esse código também, e aqui está como você pode fazer isso:
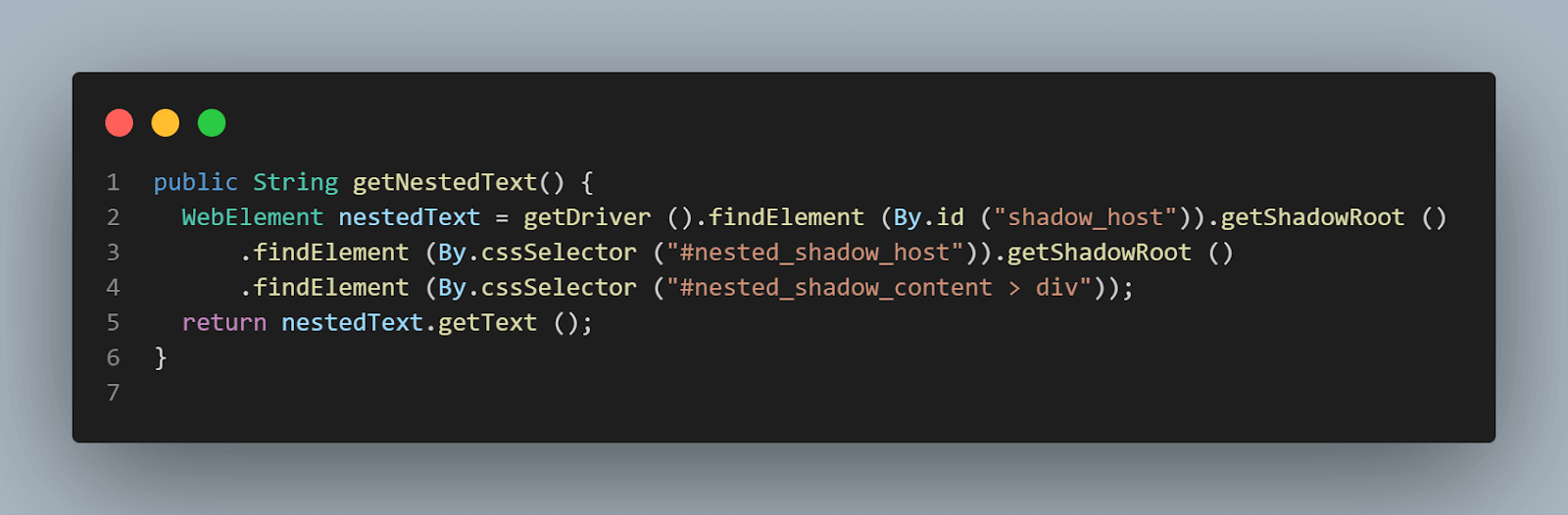
public String getNestedText() {
WebElement nestedText = getDriver ().findElement (By.id ("shadow_host"))
.getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_host"))
.getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_content > div"));
return nestedText.getText ();
}A interface fluente baseia-se amplamente na cadeia de métodos. O padrão de interface fluente ajuda a escrever código fácil de ler que pode ser entendido sem precisar se esforçar para entender tecnicamente o código. Este termo foi cunhado pela primeira vez em 2005 por Eric Evans e Martin Fowler.
Este é o método de encadeamento que executaríamos para localizar o elemento.
Este código faz a mesma coisa que fizemos nos passos acima.
- Primeiro, localizaremos o elemento shadow_host usando seu id, após o que obteremos o elemento Shadow Root usando o método
getShadowRoot(). - Em seguida, pesquisaremos o elemento nested_shadow_host usando o seletor CSS e obteremos o elemento Shadow Root usando o método
getShadowRoot(). - Finalmente, obteremos o texto “nested text” usando o seletor CSS – nested_shadow_content > div.
Como Encontrar o Shadow DOM no Selenium Usando JavaScriptExecutor
Nos exemplos de código acima, localizamos elementos usando o método getShadowRoot(). Vamos agora ver como podemos localizar elementos de raiz de sombra usando JavaScriptExecutor no Selenium WebDriver.
getNestedTextUsingJSExecutor() método foi criado dentro da classe HomePage,
onde expandiremos o elemento Shadow Root com base no WebElement que passamos no parâmetro. No DOM (conforme mostrado na captura de tela acima), vimos que existem dois elementos Shadow Root que precisamos expandir antes de chegar ao localizador real para obter o texto – texto aninhado. Portanto, foi criado o método expandRootElement() em vez de copiar e colar o mesmo código executor JavaScript sempre.
Implementaremos a interface SearchContext, que nos ajudará com o JavaScriptExecutor e retornará o elemento raiz Shadow com base no WebElement que passamos no parâmetro.
public SearchContext expandRootElement (WebElement element) {
SearchContext shadowRoot = (SearchContext) ((JavascriptExecutor) getDriver ()).executeScript (
"return arguments[0].shadowRoot", element);
return shadowRoot;
}
método getNestedTextUsingJSExecutor()
O primeiro elemento que localizaremos é o < div id = "shadow_host" > usando a estratégia de localizador – id.
Em seguida, expandiremos o Elemento Raiz com base no WebElement shadow_host que pesquisamos.
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRootOne = expandRootElement (shadowHost);Depois de expandir o Shadow Root, podemos pesquisar outro WebElement usando cssSelector para localizar:
<div id ="nested_shadow_host">
WebElement nestedShadowHost = shadowRootOne.findElement (By.cssSelector ("#nested_shadow_host"));
SearchContext shadowRootTwo = expandRootElement (nestedShadowHost);Finalmente, agora é hora de localizar o elemento real para obter o texto – “texto aninhado.”
A seguinte linha de código nos ajudará a localizar o texto:
shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div"))
.getText ();Demonstração
Nesta seção do artigo sobre Shadow DOM no Selenium, vamos rapidamente escrever um teste e verificar se os localizadores encontrados nas etapas anteriores estão nos fornecendo o texto necessário. Podemos executar asserções no código que escrevemos para verificar se o que esperamos do código está funcionando.
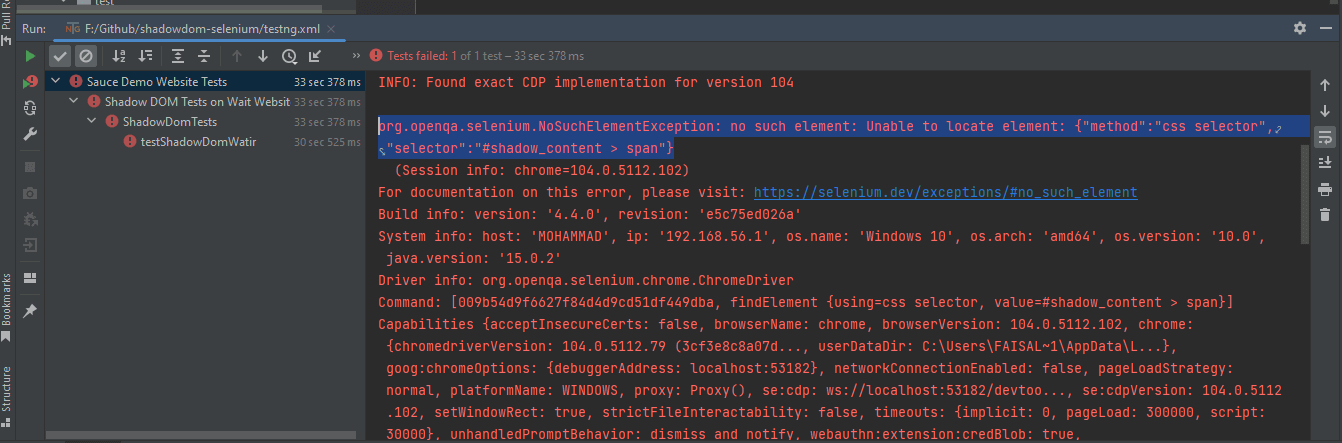
@Test
public void testShadowDomWatir () {
getDriver ().get ("http://watir.com/examples/shadow_dom.html");
HomePage homePage = new HomePage ();
// assertEquals (homePage.getSomeText(), "some text");
assertEquals (homePage.getShadowDomText (), "some text");
assertEquals (homePage.getNestedShadowText (),"nested text");
assertEquals (homePage.getNestedText (), "nested text");
assertEquals (homePage.getNestedTextUsingJSExecutor (), "nested text");
}Este é apenas um teste simples para afirmar que os textos são exibidos corretamente como esperado. Verificaremos isso usando a asserção assertEquals() no TestNG.
Na verdadeira avaliação, forneceríamos o método que acabamos de escrever para obter o texto da página, e no valor esperado, passaríamos o texto “some text” ou “nested text,” dependendo das asserções que estaremos realizando.
São fornecidas quatro declarações assertEquals no teste.
- Verificando o elemento Shadow DOM usando o método
getShadowRoot():
- Verificando o elemento Shadow DOM aninhado usando o método
getShadowRoot():
- Verificando o elemento Shadow DOM aninhado usando o método
getShadowRoot()e escrevendo fluentemente:
Execução
Existem duas maneiras de executar os testes para automatizar o Shadow DOM no Selenium:
- A partir do IDE usando TestNG
- A partir da CLI usando Maven
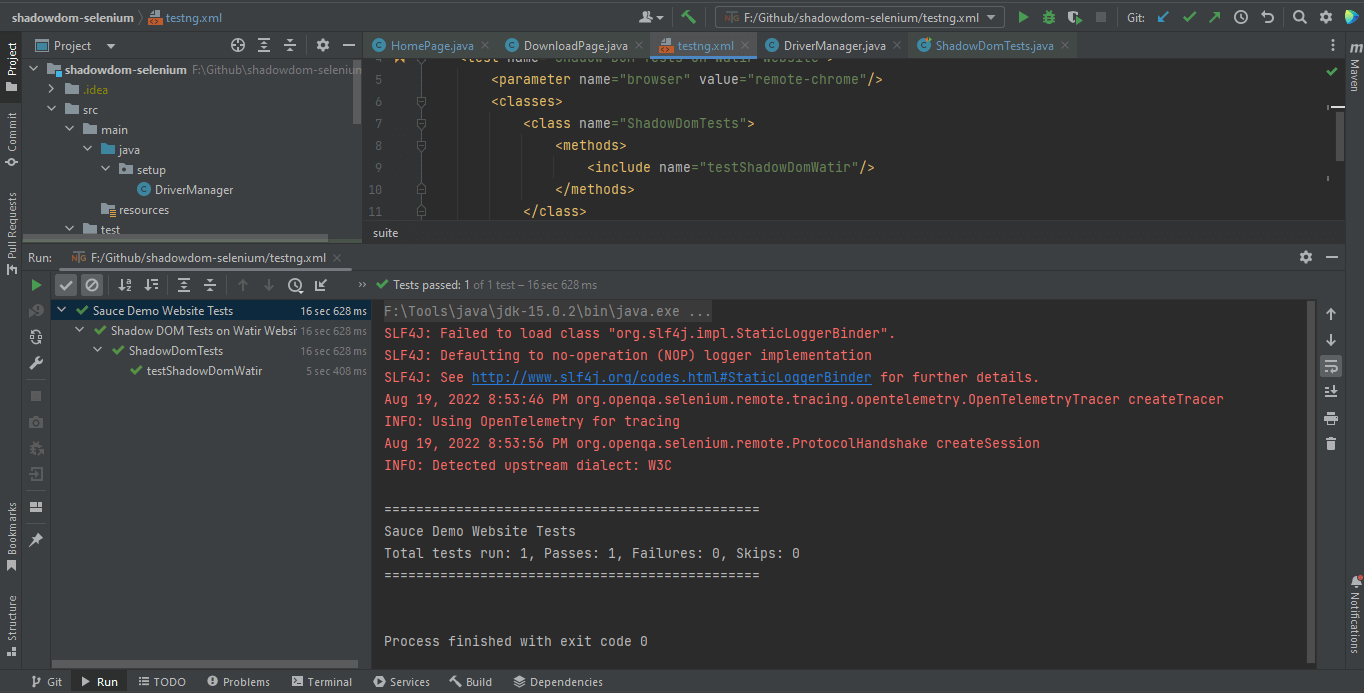
Automatizando o Shadow DOM no Selenium WebDriver Usando TestNG
TestNG é usado como um executor de testes. Portanto, foi criado o arquivo testng.xml, através do qual executaremos os testes clicando com o botão direito no arquivo e selecionando a opção Executar ‘…\testng.xml’. Mas antes de executar os testes, precisamos adicionar o nome de usuário e a chave de acesso da LambdaTest nas Configurações de Execução já que estamos lendo o nome de usuário e a chave de acesso a partir de Propriedade do Sistema.
LambdaTest oferece testes em navegadores cruzados em uma fazenda online de mais de 3000 navegadores reais e sistemas operacionais para ajudar você a executar testes Java localmente e/ou na nuvem. Você pode acelerar seus testes Selenium com Java e reduzir o tempo de execução dos testes por várias vezes executando testes em paralelo em várias configurações de navegadores e sistemas operacionais.
- Adicione os valores nas Configurações de Execução conforme mencionado abaixo:
- Dusername =
< Nome de Usuário da LambdaTest > - DaccessKey =
< Chave de Acesso da LambdaTest >
- Dusername =
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd">
<suite name="Sauce Demo Website Tests">
<test name="Shadow DOM Tests on Watir Website">
<parameter name="browser" value="remote-chrome"/>
<classes>
<class name="ShadowDomTests">
<methods>
<include name="testShadowDomWatir"/>
</methods>
</class>
</classes>
</test> <!-- Test -->
</suite>Aqui está a captura de tela da execução do teste localmente para Shadow DOM no Selenium usando o Intellij IDE.
Automatizando Shadow DOM no Selenium WebDriver Usando Maven
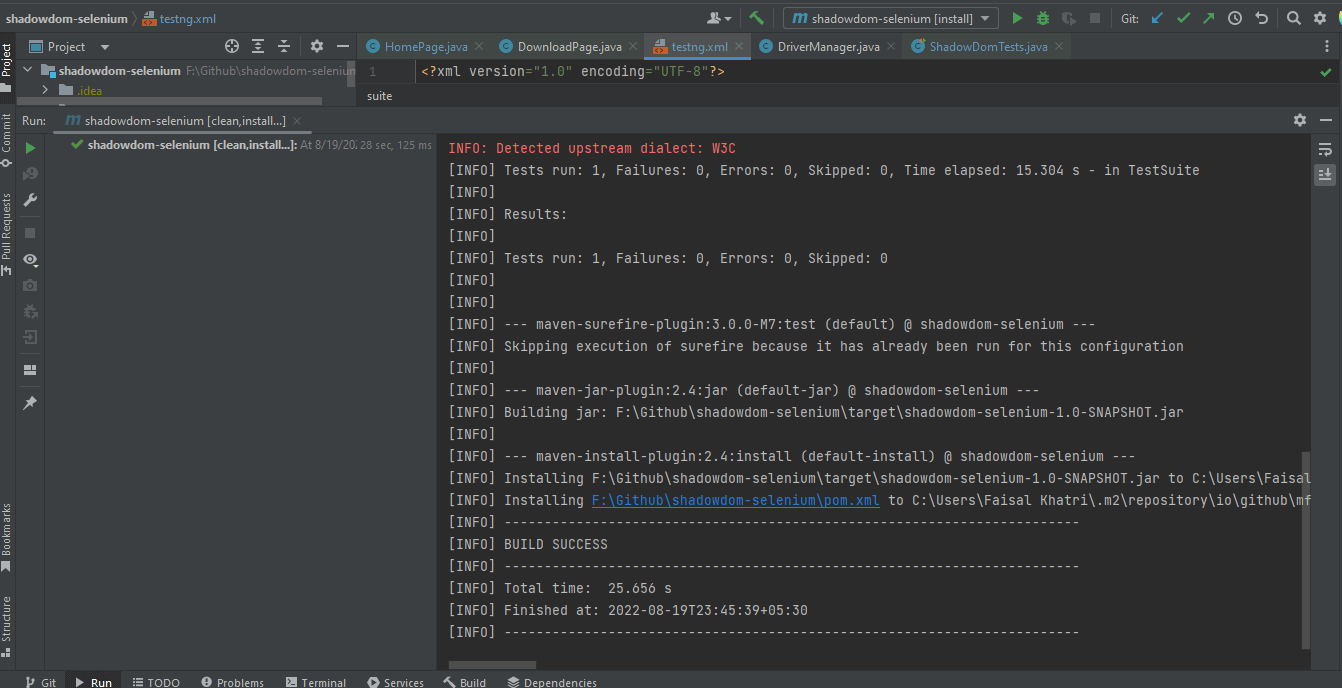
Para executar os testes usando Maven, são necessários os seguintes passos para automatizar Shadow DOM no Selenium:
- Abra o Prompt de Comando/Terminal.
- Navegue até a pasta raiz do projeto.
- Digite o comando:
mvn clean install -Dusername=< Nome de Usuário da LambdaTest > -DaccessKey=< Chave de Acesso da LambdaTest >.
Segue abaixo a captura de tela do IntelliJ, que mostra o status da execução dos testes usando Maven:
Após a execução bem-sucedida dos testes, podemos verificar o Painel do LambdaTest e visualizar todos os registros em vídeo, capturas de tela, logs de dispositivos e detalhes granulares passo a passo da execução dos testes. Confira as capturas de tela abaixo, que lhe darão uma boa ideia do painel para testes automatizados de aplicativos.
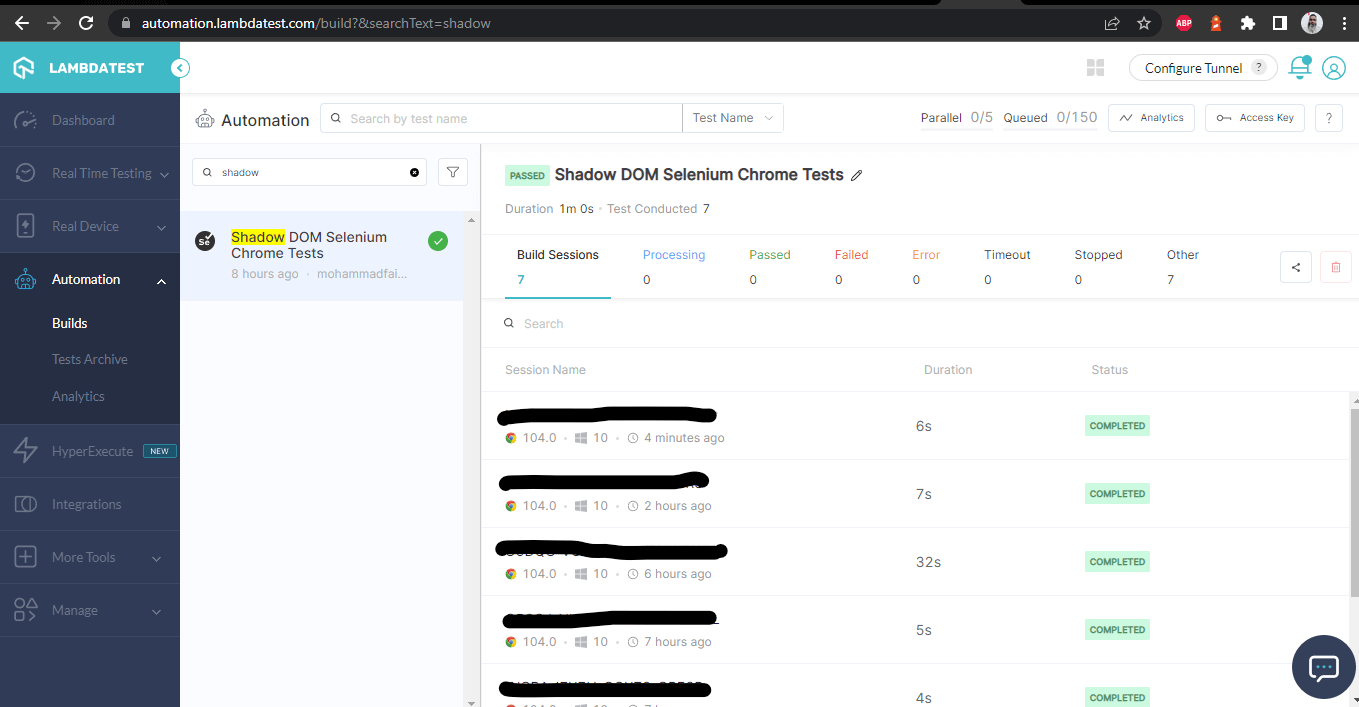 Painel do LambdaTest
Painel do LambdaTest
As seguintes capturas de tela mostram os detalhes da build e dos testes que foram executados para automatizar o Shadow DOM no Selenium. Mais uma vez, o nome do teste, nome do navegador, versão do navegador, nome do sistema operacional, respectiva versão do sistema operacional e resolução da tela são todos visíveis corretamente para cada teste.
Também inclui o vídeo do teste que foi executado, o que dá uma ideia melhor de como os testes foram realizados no dispositivo.
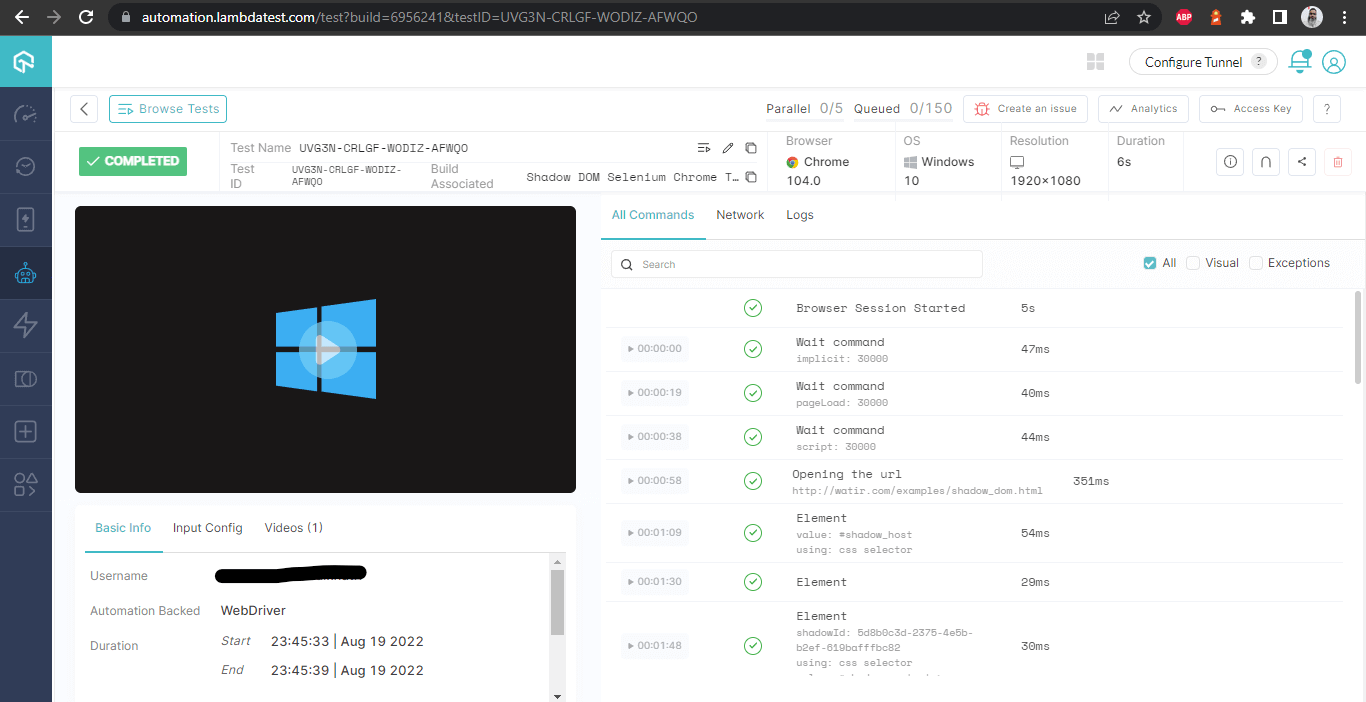 Detalhes da Build
Detalhes da Build
Esta tela mostra todos os metrólogos em detalhes, que são muito úteis do ponto de vista do testador para verificar que teste foi executado em que navegador e, assim, visualizar os logs para automatizar o Shadow DOM no Selenium.
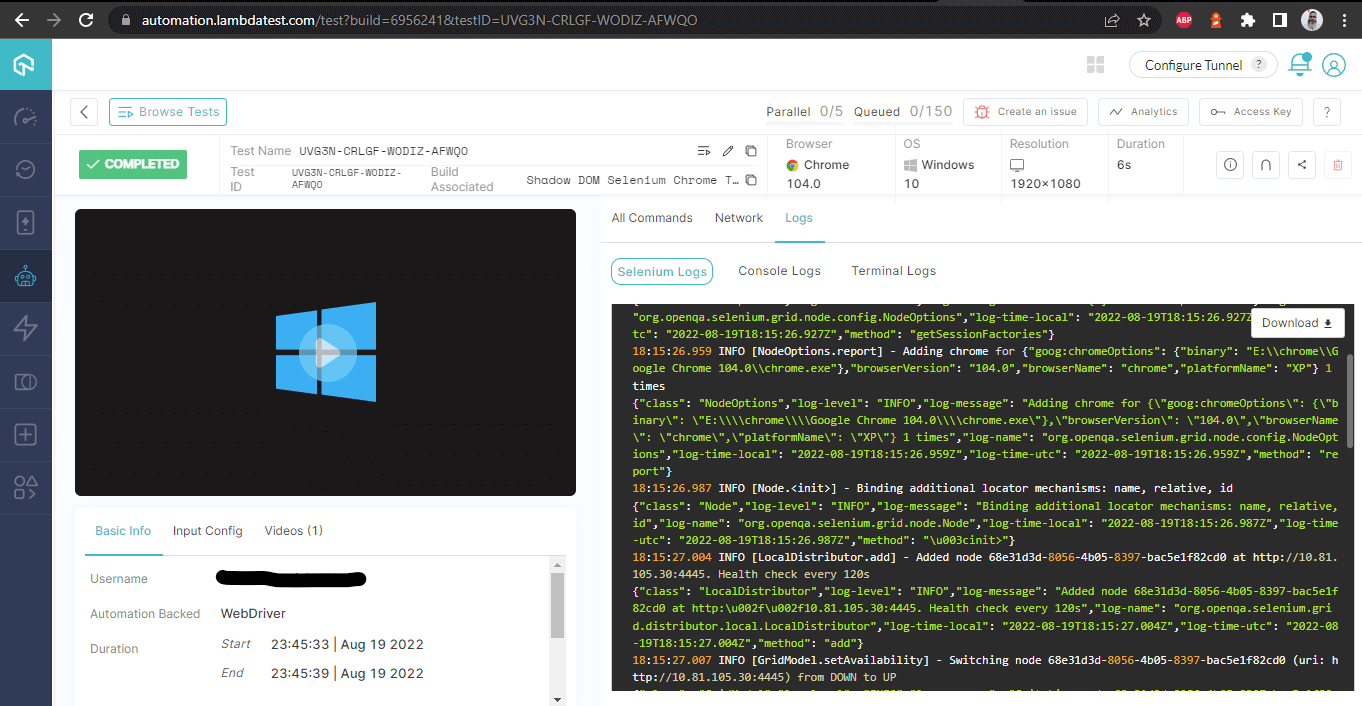 Detalhes da Construção – com logs
Detalhes da Construção – com logs
Você pode acessar os resultados de testes mais recentes, seu status e o número total de testes aprovados ou reprovados no Painel de Análise da LambdaTest. Além disso, você pode ver capturas de tela das execuções de testes recentemente executadas na seção Visão Geral de Testes.
Conclusão
Neste blog sobre automação do Shadow DOM no Selenium, discutimos como encontrar elementos do Shadow DOM e automatizá-los usando o método getShadowRoot() introduzido na versão 4.0.0 e superior do Selenium WebDriver.
Também discutimos a localização e a automação dos elementos do Shadow DOM usando JavaScriptExecutor no Selenium WebDriver e executando os testes na Plataforma LambdaTest, que mostra detalhes granulares dos testes que foram executados com logs do Selenium WebDriver.
I hope this blog on Shadow DOM in Selenium gives you a fair idea about automating Shadow DOM elements using Selenium WebDriver.
Boa testagem!
Source:
https://dzone.com/articles/how-to-automate-shadow-dom-in-selenium-webdriver