













I came across one of the test cases in my previous projects where I had to click on a button to navigate to the next page. I searched for the element locator of the button on the page and ran the tests hoping it would click the button and navigate to the next page.
Maar, tot mijn verrassing, mislukte de test omdat hij het element niet kon vinden en ik kreeg een NoSuchElementException in de console logs. Ik was niet blij om die fout te zien, want het was een simpele knop die ik probeerde aan te klikken en er was geen complexiteit.
Na verder onderzoek, het DOM uitbreiden en de hoofdelementen controleren, ontdekte ik dat de knoplocator zich binnen de #shadow-root(open) knoop bevond, wat me deed beseffen dat het anders moet worden behandeld omdat het een Shadow DOM-element is.
In deze Selenium WebDriver tutorial zullen we Shadow DOM-elementen bespreken en hoe je Shadow DOM in Selenium WebDriver kunt automatiseren. Voordat we verder gaan met het automatiseren van Shadow DOM in Selenium, laten we eerst begrijpen wat Shadow DOM is. En waarom wordt het gebruikt?
Wat Is Shadow DOM?
Shadow DOM is een functionaliteit die de webbrowser in staat stelt DOM-elementen te renderen zonder deze in de hoofddocument DOM-boom te plaatsen. Dit creëert een barrière tussen wat de ontwikkelaar en de browser kan bereiken; de ontwikkelaar kan de Shadow DOM niet op dezelfde manier benaderen als met geneste elementen, terwijl de browser die code op dezelfde manier kan renderen en wijzigen als met geneste elementen.
Shadow DOM is een manier om encapsulatie in het HTML-document te realiseren. Door het te implementeren, kun je de stijl en het gedrag van een deel van het document verborgen en gescheiden houden van de rest van de code in hetzelfde document, zodat er geen interferentie is.
Shadow DOM stelt verborgen DOM-bomen in staat om aan elementen in de reguliere DOM-boom te worden gekoppeld – de Shadow DOM-boom begint met een Shadow root, waaronder je elk element kunt koppelen zoals in de normale DOM.
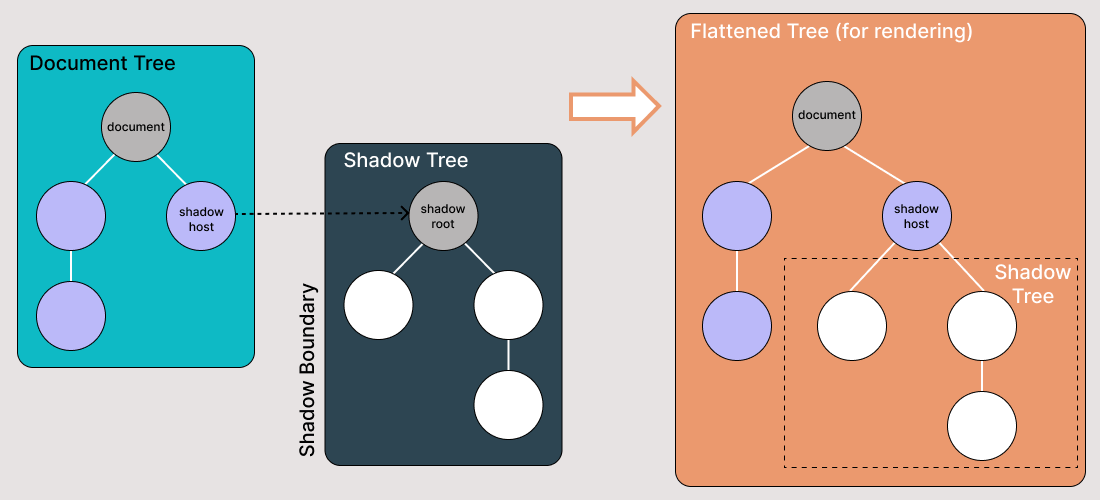
Er zijn enkele aspecten van Shadow DOM-terminologie waar je rekening mee moet houden:
- Schaduwhost: De normale DOM-node waaraan het Shadow DOM is gekoppeld
- Schaduwboom: De DOM-boom binnen het Shadow DOM
- De schaduwgrens is waar het Shadow DOM eindigt en het normale DOM begint.
- Schaduwroot: De root-node van de schaduwboom
Wat Is De Toepassing Van Shadow DOM?
Shadow DOM wordt gebruikt voor encapsulatie. Het stelt een component in staat om zijn eigen “schaduw” DOM-boom te hebben die niet per ongeluk kan worden benaderd vanuit de hoofddocument, kan plaatselijke stijlregels hebben, en meer.
Hier zijn enkele van de belangrijkste eigenschappen van Shadow DOM:
- Hebben hun eigen id-ruimte
- Onzichtbaar voor JavaScript-selectoren vanuit het hoofddocument, zoals querySelector
- Gebruik maken van stijlen alleen vanuit de schaduwboom, niet vanuit het hoofddocument
Het vinden van Shadow DOM-elementen met behulp van Selenium WebDriver
Wanneer we proberen de Shadow DOM-elementen te vinden met behulp van Selenium-locatoren, krijgen we NoSuchElementException omdat het niet direct toegankelijk is voor de DOM.
We zouden de volgende strategie gebruiken om toegang te krijgen tot de Shadow DOM-locatoren:
- Met behulp van JavaScriptExecutor.
- Met behulp van Selenium WebDriver’s
getShadowDom()methode.
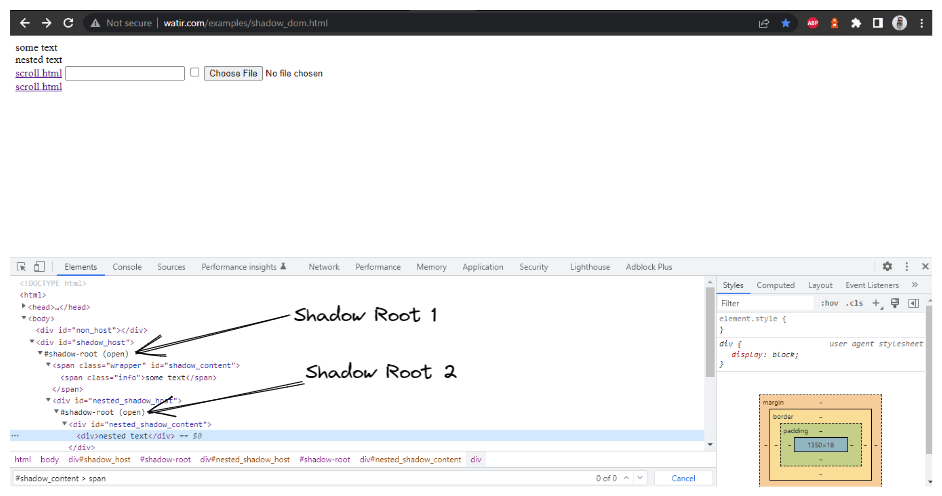
In deze blogsectie over het automatiseren van Shadow DOM in Selenium, laten we een voorbeeld nemen van Watir.com’s Homepagina en proberen te asserten op de shadow dom en de geneste shadow dom tekst met Selenium WebDriver. Merk op dat er één shadow root element is voordat we bij de tekst -> enige tekst komen, en er zijn twee shadow root elementen voordat we bij de tekst -> geneste tekst komen.
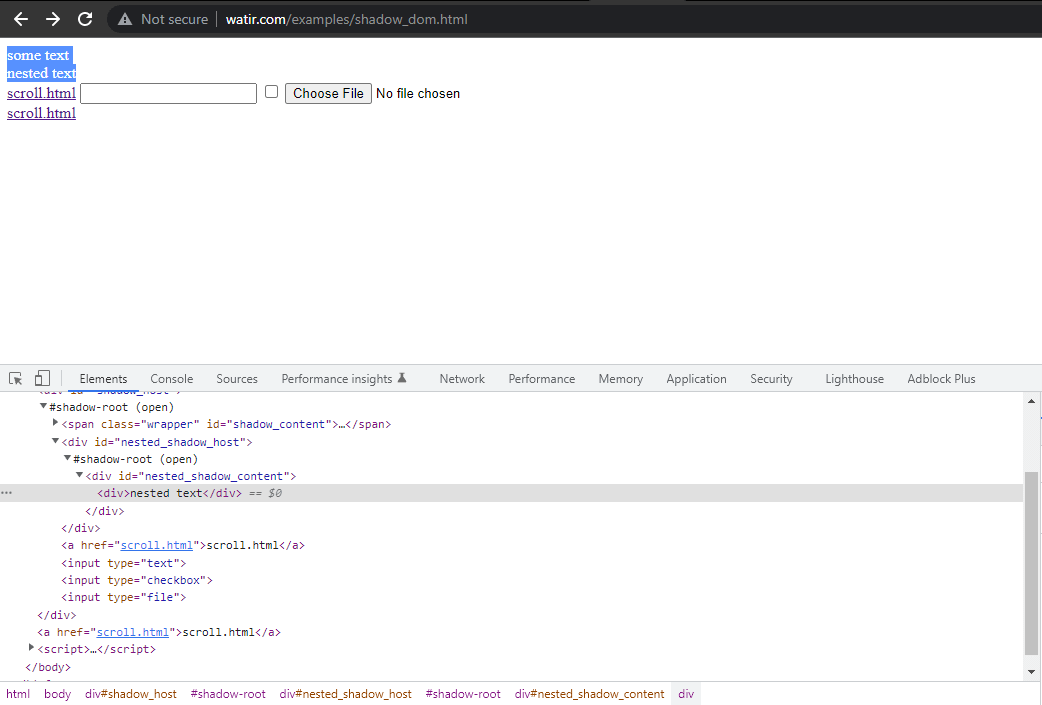
Als we nu proberen het element te lokaliseren met behulp van de cssSelector("#shadow_content > span"), wordt het
niet gevonden, en zal Selenium WebDriver een NoSuchElementException geven.
Hier is een screenshot van de Homepage-klasse, die probeert tekst te verkrijgen met behulp van
cssSelector(“#shadow_content > span”).

Hier is een screenshot van de tests waar we proberen de tekst(“enige tekst”) te asserten.
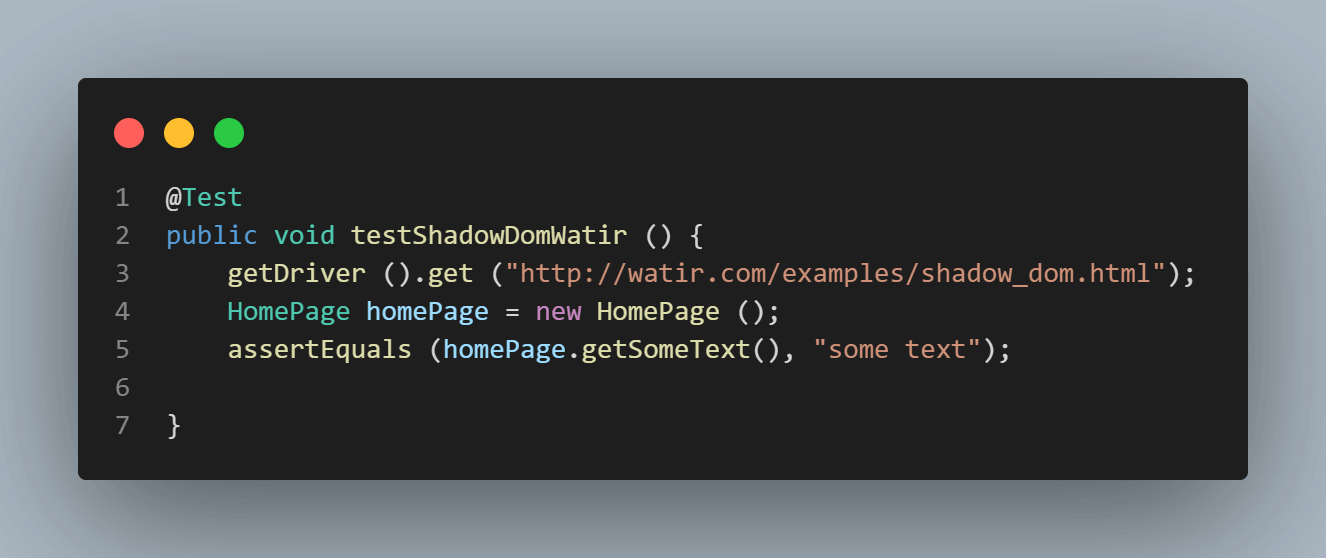
Fout bij uitvoeren van de tests toont NoSuchElementException
Om het element correct te lokaliseren voor de tekst, moeten we door de Shadow root elementen heen gaan. Alleen dan zullen we in staat zijn om “enige tekst” en “geneste tekst” op de pagina te vinden?
Hoe Shadow DOM in Selenium WebDriver te vinden met behulp van de ‘getShadowDom’ methode
Met de release van Selenium WebDriver’s versie 4.0.0 en hoger, werd de getShadowRoot() methode geïntroduceerd en hielp bij het lokaliseren van Shadow root elementen.
Hier zijn de syntaxis en details van de getShadowRoot() methode:
default SearchContext getShadowRoot()
Returns:
The ShadowRoot class represents the shadow root of a web component. With a shadow root, you can access the shadow DOM of a web component.
Throws:
NoSuchShadowRootException - If shadow root is not found.Volgens de documentatie retourneert de getShadowRoot() methode een representatie van de Shadow root van een element voor toegang tot de Shadow DOM van een webcomponent.
Als de Shadow root niet wordt gevonden, zal het NoSuchShadowRootException gooien.
Voordat we beginnen met het schrijven van de tests en het bespreken van de code, laat me je vertellen over de tools die we zullen gebruiken om de tests te schrijven en uit te voeren:
De volgende programmeertaal en tools zijn gebruikt bij het schrijven en uitvoeren van de tests:
- Programmeertaal: Java 11
- Web Automation Tool: Selenium WebDriver
- Test Runner: TestNG
- Build Tool: Maven
- Cloud Platform: LambdaTest
Aan de slag met het vinden van Shadow DOM in Selenium WebDriver
Zoals eerder besproken, is dit project over Shadow DOM in Selenium gemaakt met behulp van Maven. TestNG wordt gebruikt als test runner. Om meer te weten te komen over Maven, kunt u dit blog lezen over aan de slag met Maven voor Selenium testen.
Zodra het project is gemaakt, moeten we de afhankelijkheid voor Selenium WebDriver en TestNG toevoegen in het pom.xml bestand.
Versies van de afhankelijkheden worden ingesteld in een aparte eigenschappenblok. Dit wordt gedaan voor onderhoudbaarheid, zodat we de versies gemakkelijk kunnen bijwerken zonder de afhankelijkheid door het pom.xml bestand te zoeken.
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>io.github.mfaisalkhatri</groupId>
<artifactId>shadowdom-selenium</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<selenium.java.version>4.4.0</selenium.java.version>
<testng.version>7.6.1</testng.version>
<webdrivermanager.version>5.2.1</webdrivermanager.version>
<maven.compiler.version>3.10.1</maven.compiler.version>
<surefire-version>3.0.0-M7</surefire-version>
<java.release.version>11</java.release.version>
<maven.source.encoding>UTF-8</maven.source.encoding>
<suite-xml>testng.xml</suite-xml>
<argLine>-Dfile.encoding=UTF-8 -Xdebug -Xnoagent</argLine>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.seleniumhq.selenium/selenium-java -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>${selenium.java.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.testng/testng -->
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>${testng.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.github.bonigarcia</groupId>
<artifactId>webdrivermanager</artifactId>
<version>${webdrivermanager.version}</version>
<exclusions>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>${maven.compiler.version}</version>
<configuration>
<release>${java.release.version}</release>
<encoding>${maven.source.encoding}</encoding>
<forceJavacCompilerUse>true</forceJavacCompilerUse>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>${surefire-version}</version>
<executions>
<execution>
<goals>
<goal>test</goal>
</goals>
</execution>
</executions>
<configuration>
<useSystemClassLoader>false</useSystemClassLoader>
<properties>
<property>
<name>usedefaultlisteners</name>
<value>false</value>
</property>
</properties>
<suiteXmlFiles>
<suiteXmlFile>${suite-xml}</suiteXmlFile>
</suiteXmlFiles>
<argLine>${argLine}</argLine>
</configuration>
</plugin>
</plugins>
</build>
</project>Laten we nu naar de code gaan; het Page Object Model (POM) is gebruikt in dit project omdat het handig is bij het verminderen van code duplicatie en verbeteren van testcase onderhoud.
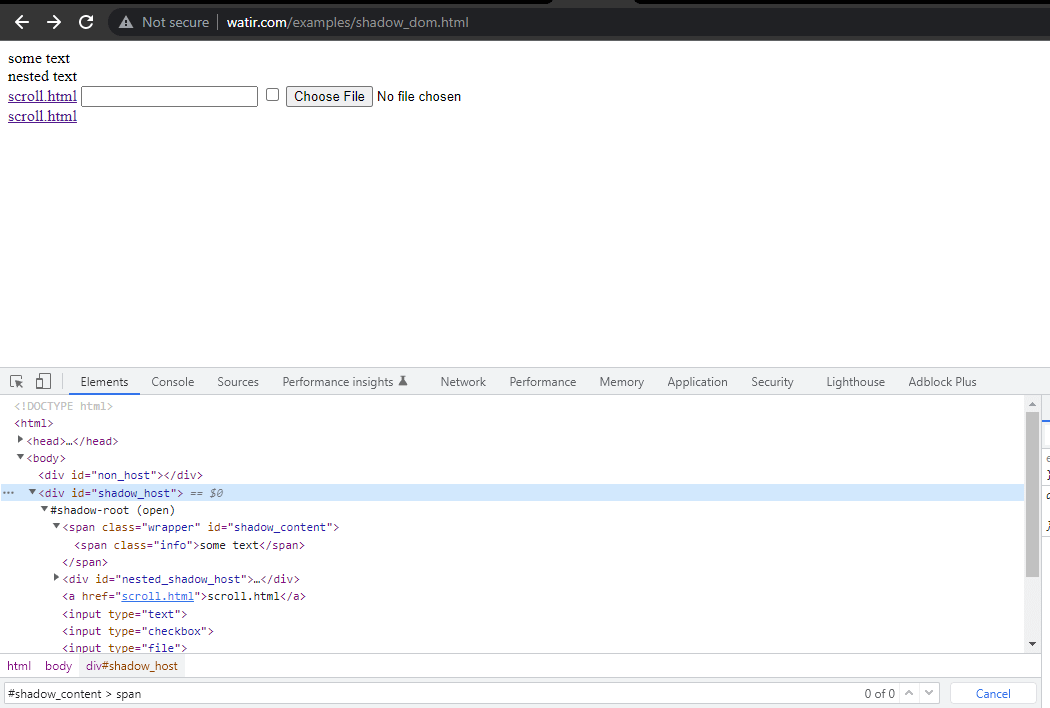
Eerst zouden we de locator voor ” some text ” en ” nested text ” op HomePage vinden.
public class HomePage {
public SearchContext expandRootElement (WebElement element) {
SearchContext shadowRoot = (SearchContext) ((JavascriptExecutor) getDriver ()).executeScript (
"return arguments[0].shadowRoot", element);
return shadowRoot;
}
public String getSomeText () {
return getDriver ().findElement (By.cssSelector ("#shadow_content > span"))
.getText ();
}
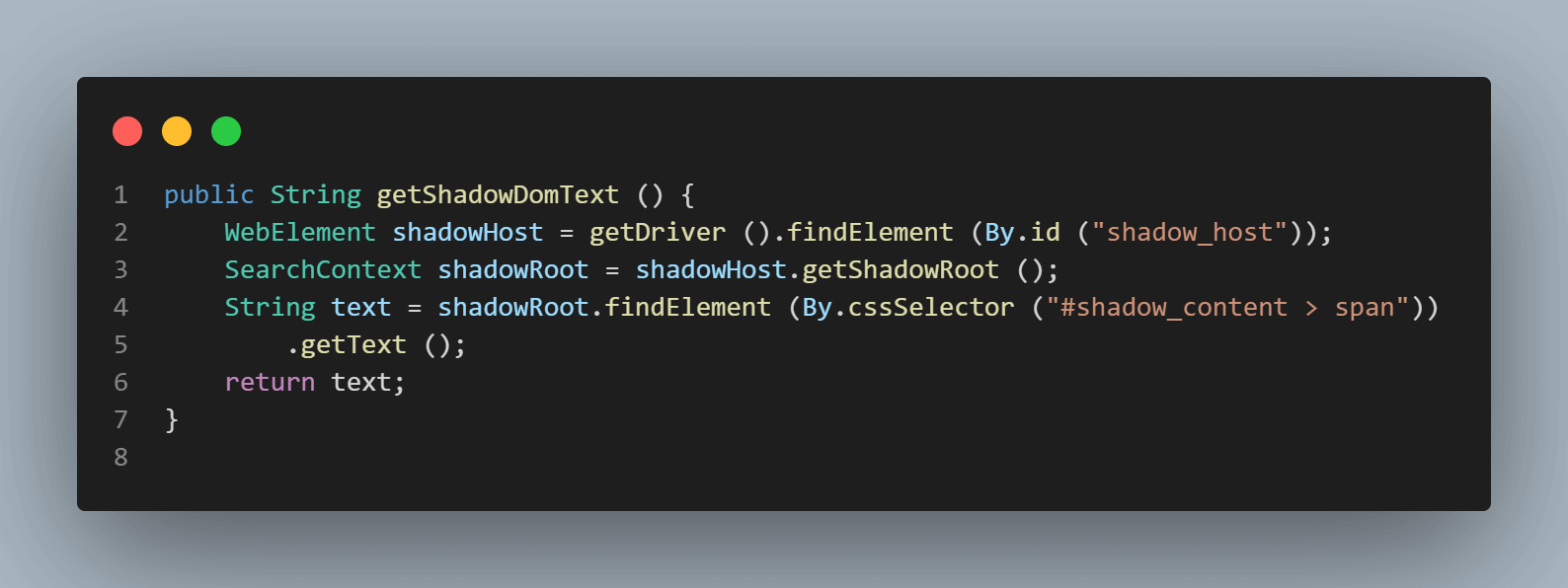
public String getShadowDomText () {
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRoot = shadowHost.getShadowRoot ();
String text = shadowRoot.findElement (By.cssSelector ("#shadow_content > span"))
.getText ();
return text;
}
public String getNestedShadowText () {
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRoot = shadowHost.getShadowRoot ();
WebElement shadowContent = shadowRoot.findElement (By.cssSelector ("#nested_shadow_host"));
SearchContext shadowRootTwo = shadowContent.getShadowRoot ();
String nestedText = shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div")).getText ();
return nestedText;
}
public String getNestedText() {
WebElement nestedText = getDriver ().findElement (By.id ("shadow_host")).getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_host")).getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_content > div"));
return nestedText.getText ();
}
public String getNestedTextUsingJSExecutor () {
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRootOne = expandRootElement (shadowHost);
WebElement nestedShadowHost = shadowRootOne.findElement (By.cssSelector ("#nested_shadow_host"));
SearchContext shadowRootTwo = expandRootElement (nestedShadowHost);
return shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div"))
.getText ();
}
}Code Walkthrough
Het eerste element dat we zouden lokaliseren in de < div id = "shadow_host" > door gebruik te maken van locatiestrategie – id.
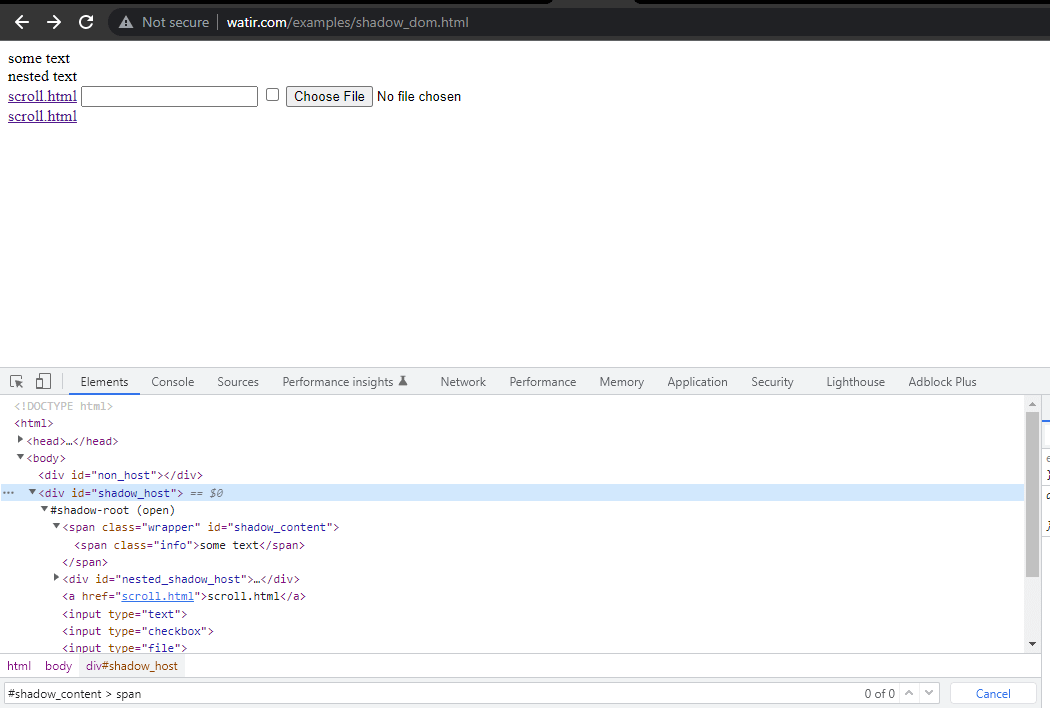
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));Vervolgens zoeken we naar de eerste Shadow Root in de DOM ernaast. Hiervoor hebben we de SearchContext-interface gebruikt. De Shadow Root wordt geretourneerd met behulp van de getShadowRoot() methode. Als je het screenshot hierboven bekijkt, #shadow-root (open) het is naast de < div id = "shadow_host" >.
Voor het lokaliseren van de tekst – ” some text, “, is er slechts één Shadow DOM-element dat we door moeten krijgen.
De volgende coderegel helpt ons het Shadow root-element te krijgen.
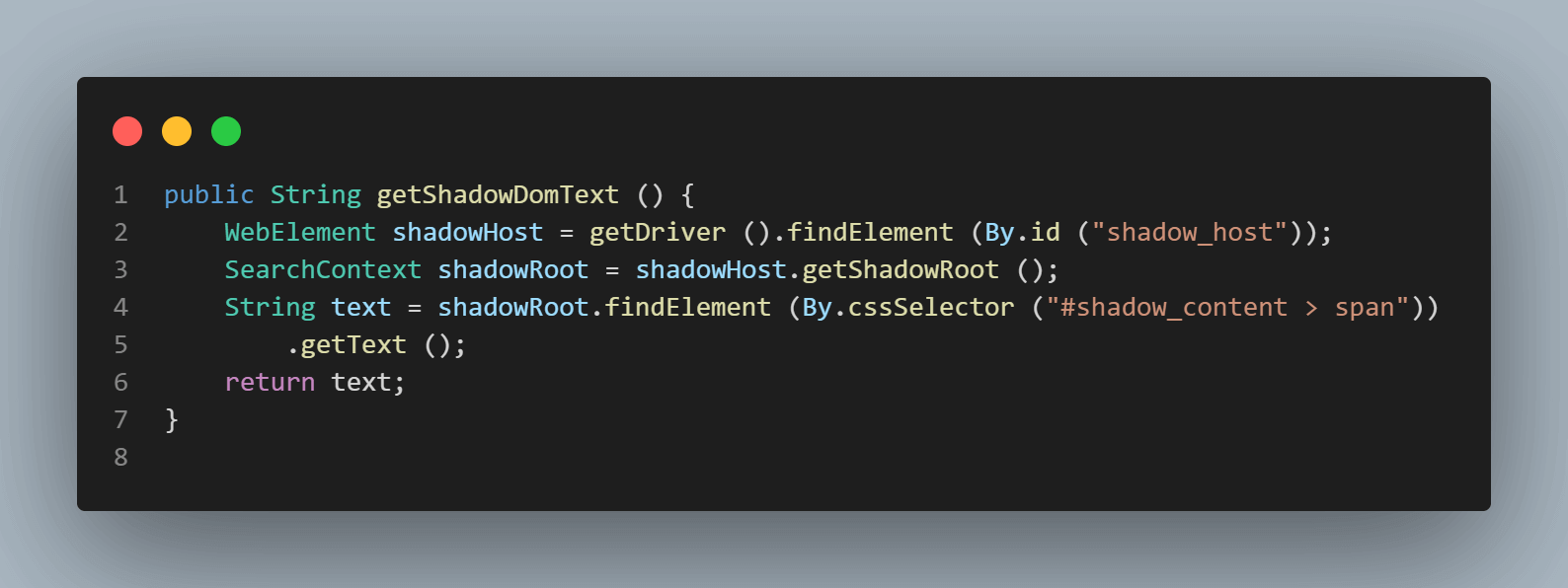
SearchContext shadowRoot = downloadsManager.getShadowRoot();Zodra de Shadow Root is gevonden, kunnen we zoeken naar het element om de tekst – ” some text. ” te lokaliseren. De volgende coderegel helpt ons de tekst te krijgen:
String text = shadowRoot.findElement (By.cssSelector ("#shadow_content > span"))
.getText ();Volgende, laten we de locator van “geneste tekst,” vinden, die een geneste Shadow root-element heeft, en laten we onderzoeken hoe we het element kunnen lokaliseren.
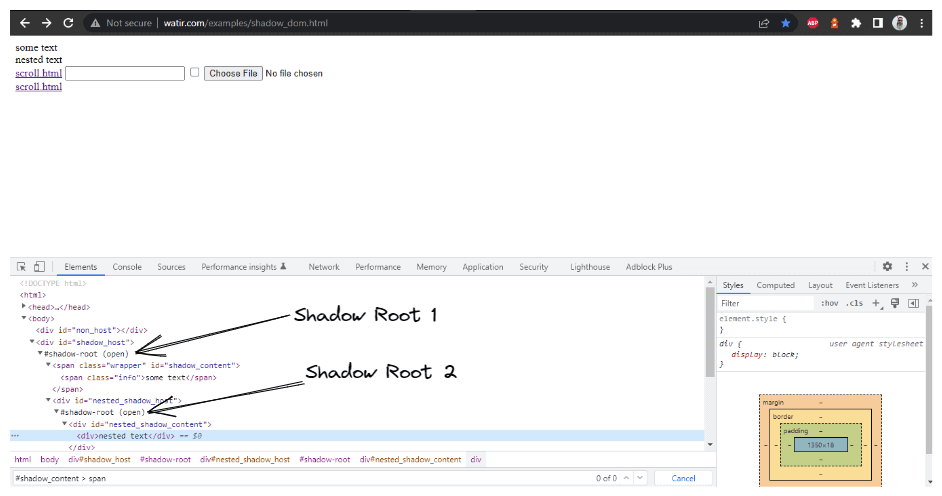
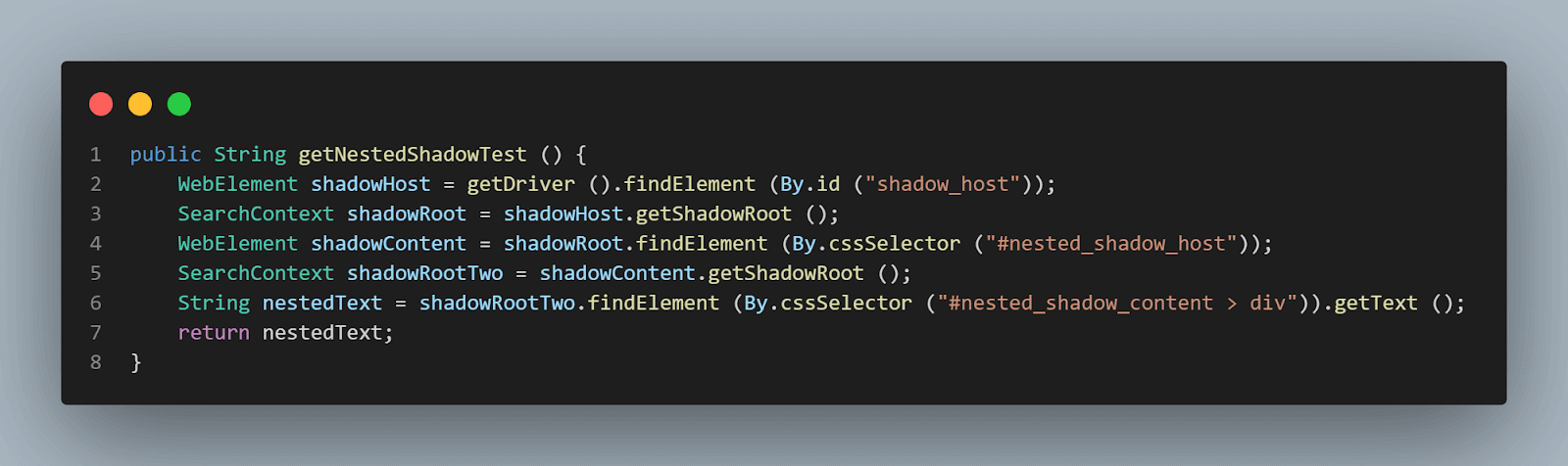
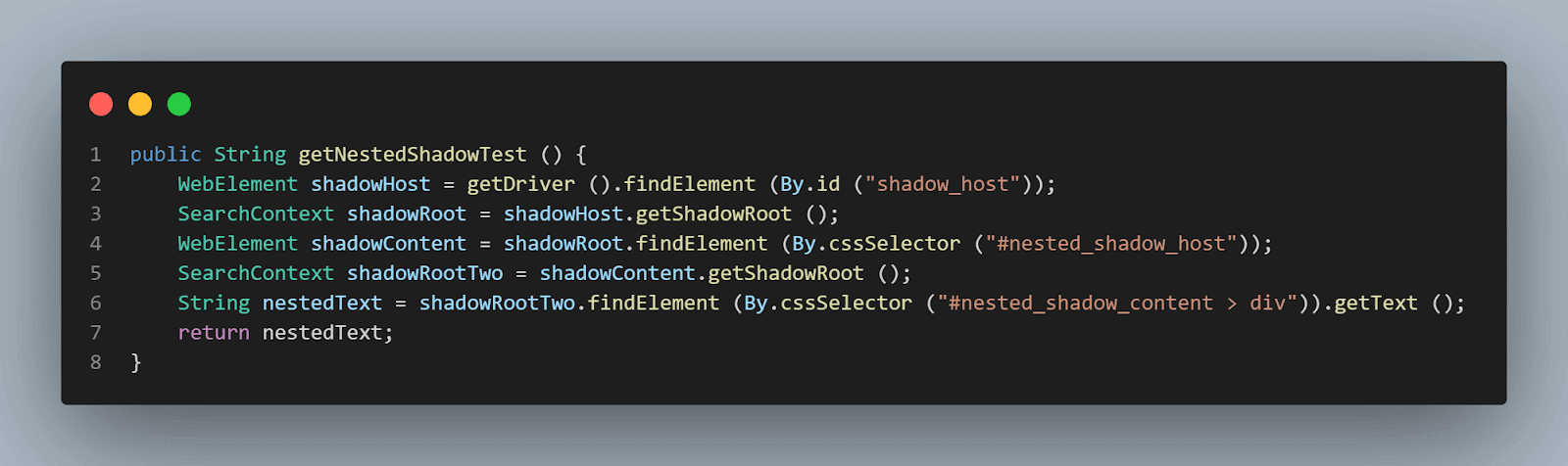
getNestedShadowText() methode:
Als we beginnen van bovenaf, zoals besproken in de bovenstaande sectie, moeten we < div id = "shadow_host" > lokaliseren met behulp van de locator strategie – id.
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));Daarna moeten we het Shadow Root-element vinden door de getShadowRoot() methode te gebruiken; zodra we het Shadow root-element hebben, zullen we moeten gaan zoeken naar de tweede Shadow root door cssSelector te gebruiken voor lokalisering:
<div id ="nested_shadow_host">
SearchContext shadowRoot = shadowHost.getShadowRoot ();
WebElement shadowContent = shadowRoot.findElement (By.cssSelector ("#nested_shadow_host"));Vervolgens moeten we het tweede Shadow Root-element vinden door de getShadowRoot() methode te gebruiken. Tenslotte is het tijd om het eigenlijke element te lokaliseren voor het verkrijgen van de tekst – “geneste tekst.”
Het volgende regel code zal ons helpen bij het lokaliseren van tekst:
SearchContext shadowRootTwo = shadowContent.getShadowRoot ();
String nestedText = shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div"Code schrijven op een vloeiende manier
In de bovenstaande sectie van dit blog over Shadow DOM in Selenium, zagen we een lange weg waar we het eigenlijke element moeten lokaliseren waarmee we willen werken, en we moeten meerdere initialisaties van WebElement en SearchContext interfaces doen en meerdere regels code schrijven om een enkel element te lokaliseren om mee te werken.
We hebben ook een vloeiende manier om deze hele code te schrijven, en hier is hoe je dat kunt doen:
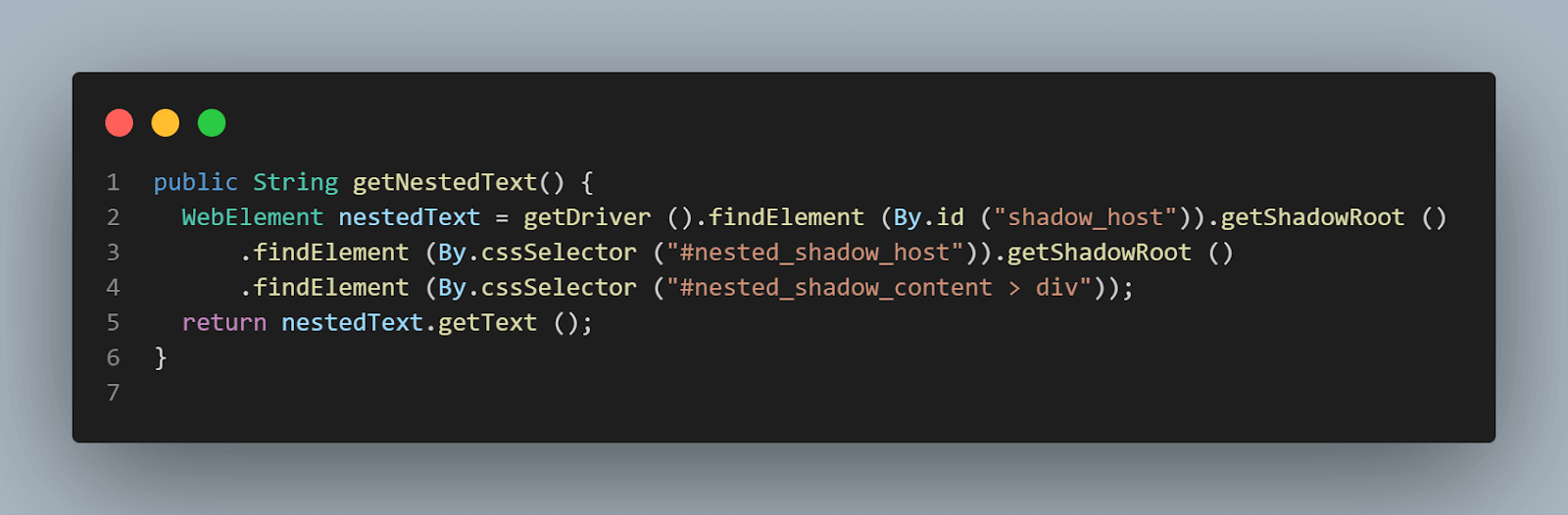
public String getNestedText() {
WebElement nestedText = getDriver ().findElement (By.id ("shadow_host"))
.getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_host"))
.getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_content > div"));
return nestedText.getText ();
}De ontwerp van een Fluent Interface berust uitgebreid op methodeketting. Het Fluent Interface-patroon helpt ons code te schrijven die gemakkelijk leesbaar is en die begrepen kan worden zonder technisch inzicht in de code te vereisen. Deze term werd voor het eerst in 2005 bedacht door Eric Evans en Martin Fowler.
Dit is de methodeketting die we zouden uitvoeren om het element te vinden.
Deze code doet hetzelfde als wat we in de bovenstaande stappen deden.
- Eerst zouden we het shadow_host-element vinden door gebruik te maken van zijn id, daarna zouden we het Shadow Root-element krijgen met behulp van de
getShadowRoot()-methode. - Vervolgens zouden we naar het nested_shadow_host-element zoeken met behulp van de CSS-selector en het Shadow Root-element krijgen met de
getShadowRoot()-methode. - Tot slot zouden we de tekst “nested text” krijgen door gebruik te maken van de cssSelector – nested_shadow_content > div.
Hoe Shadow DOM te vinden in Selenium met behulp van JavaScriptExecutor
In de bovenstaande codevoorbeelden hebben we elementen gevonden met behulp van de getShadowRoot()-methode. Laten we nu eens kijken hoe we Shadow root-elementen kunnen vinden met JavaScriptExecutor in Selenium WebDriver.
getNestedTextUsingJSExecutor() methode is gemaakt binnen de HomePage Class,
waar we de Shadow Root-elementen zullen uitbreiden op basis van het WebElement dat we als parameter doorgeven. In de DOM (zoals weergegeven in de screenshot hierboven) zagen we dat we twee Shadow Root-elementen moeten uitbreiden voordat we bij de eigenlijke locator komen voor het verkrijgen van het tekst – nested text. Daarom is de expandRootElement() methode gemaakt in plaats van dezelfde javascript executor code elke keer te kopiëren.
We zullen de SearchContext-interface implementeren, die ons zal helpen met de JavaScriptExecutor en het Shadow root-element zal teruggeven op basis van het WebElement dat we als parameter doorgeven.
public SearchContext expandRootElement (WebElement element) {
SearchContext shadowRoot = (SearchContext) ((JavascriptExecutor) getDriver ()).executeScript (
"return arguments[0].shadowRoot", element);
return shadowRoot;
}
getNestedTextUsingJSExecutor() methode
Het eerste element dat we zullen vinden is de < div id = "shadow_host" > door gebruik te maken van de locator strategie – id.
Vervolgens zullen we de Root Element uitbreiden op basis van het shadow_host WebElement dat we hebben gezocht.
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRootOne = expandRootElement (shadowHost);Nadat de eerste Shadow Root is uitgebreid, kunnen we naar een ander WebElement zoeken met cssSelector voor het lokaliseren:
<div id ="nested_shadow_host">
WebElement nestedShadowHost = shadowRootOne.findElement (By.cssSelector ("#nested_shadow_host"));
SearchContext shadowRootTwo = expandRootElement (nestedShadowHost);Tot slot is het nu tijd om het eigenlijke element te lokaliseren voor het verkrijgen van de tekst – “nested text.”
De volgende coderegel zal ons helpen bij het lokaliseren van de tekst:
shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div"))
.getText ();Demonstratie
In deze sectie van dit artikel over Shadow DOM in Selenium, laten we snel een test schrijven en controleren of de locators die we in de vorige stappen hebben gevonden, ons de vereiste tekst geven. We kunnen assertions uitvoeren op de code die we hebben geschreven om te verifiëren of wat we verwachten van de code werkt.
@Test
public void testShadowDomWatir () {
getDriver ().get ("http://watir.com/examples/shadow_dom.html");
HomePage homePage = new HomePage ();
// assertEquals (homePage.getSomeText(), "some text");
assertEquals (homePage.getShadowDomText (), "some text");
assertEquals (homePage.getNestedShadowText (),"nested text");
assertEquals (homePage.getNestedText (), "nested text");
assertEquals (homePage.getNestedTextUsingJSExecutor (), "nested text");
}Dit is slechts een eenvoudige test om te bevestigen dat de teksten correct worden weergegeven zoals verwacht. We zouden controleren dat met behulp van de assertEquals() assertion in TestNG.
In de werkelijke waarde zouden we de zojuist geschreven methode geven om de tekst van de pagina te halen, en in de verwachte waarde zouden we de tekst “some text” of “nested text,” aanpassen aan de assertions die we zouden doen.
Er zijn vier assertEquals-statements gegeven in de test.
- Controleren van het Shadow DOM-element met behulp van de
getShadowRoot()methode:
- Controleren van het geneste Shadow DOM-element met behulp van de
getShadowRoot()methode:
- Controleren van het geneste Shadow DOM-element met behulp van de
getShadowRoot()methode en vloeiend schrijven:
Uitvoering
Er zijn twee manieren om de tests uit te voeren voor het automatiseren van Shadow DOM in Selenium:
- Vanuit de IDE met behulp van TestNG
- Vanuit de CLI met behulp van Maven
Automatiseren van Shadow DOM in Selenium WebDriver met behulp van TestNG
TestNG wordt gebruikt als testrunner. Daarom is er een testng.xml aangemaakt, waarmee we de tests zullen uitvoeren door met de rechtermuisknop op het bestand te klikken en de optie Run ‘…\testng.xml’ te selecteren. Maar voordat we de tests uitvoeren, moeten we de LambdaTest gebruikersnaam en toegangssleutel toevoegen in de Run Configuraties omdat we de gebruikersnaam en toegangssleutel uit de systeem eigenschap lezen.
LambdaTest biedt kruisbrowser testing op een online browserboerderij van meer dan 3000 echte browsers en besturingssystemen om u te helpen Java-tests lokaal en/of in de cloud uit te voeren. U kunt uw Selenium-testen met Java versnellen en de testuitvoeringstijd met meerdere factoren verminderen door parallelle tests op verschillende browsers en OS-configuraties uit te voeren.
- Voeg waarden toe in de Run Configuratie zoals hieronder vermeld:
- Dusername =
< LambdaTest gebruikersnaam > - DaccessKey =
< LambdaTest toegangssleutel >
- Dusername =
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd">
<suite name="Sauce Demo Website Tests">
<test name="Shadow DOM Tests on Watir Website">
<parameter name="browser" value="remote-chrome"/>
<classes>
<class name="ShadowDomTests">
<methods>
<include name="testShadowDomWatir"/>
</methods>
</class>
</classes>
</test> <!-- Test -->
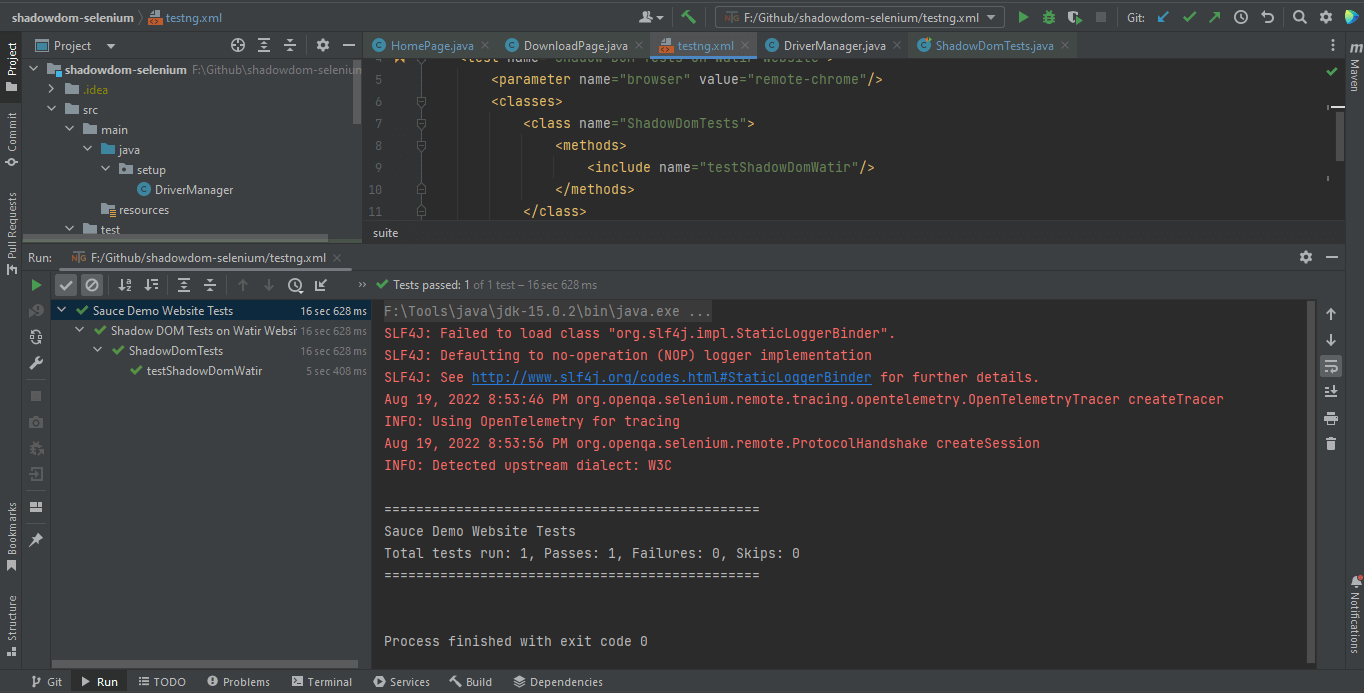
</suite>Hier is de schermafbeelding van de test uitgevoerd lokaal voor Shadow DOM in Selenium met behulp van Intellij IDE.
Automatiseren van Shadow DOM in Selenium WebDriver met behulp van Maven
Om de tests met Maven uit te voeren, moeten de volgende stappen worden uitgevoerd om Shadow DOM in Selenium te automatiseren:
- Open het commando Prompt/Terminal.
- Navigeer naar de hoofdmap van het project.
- Voer het commando in:
mvn clean install -Dusername=< LambdaTest gebruikersnaam > -DaccessKey=< LambdaTest toegangssleutel >.
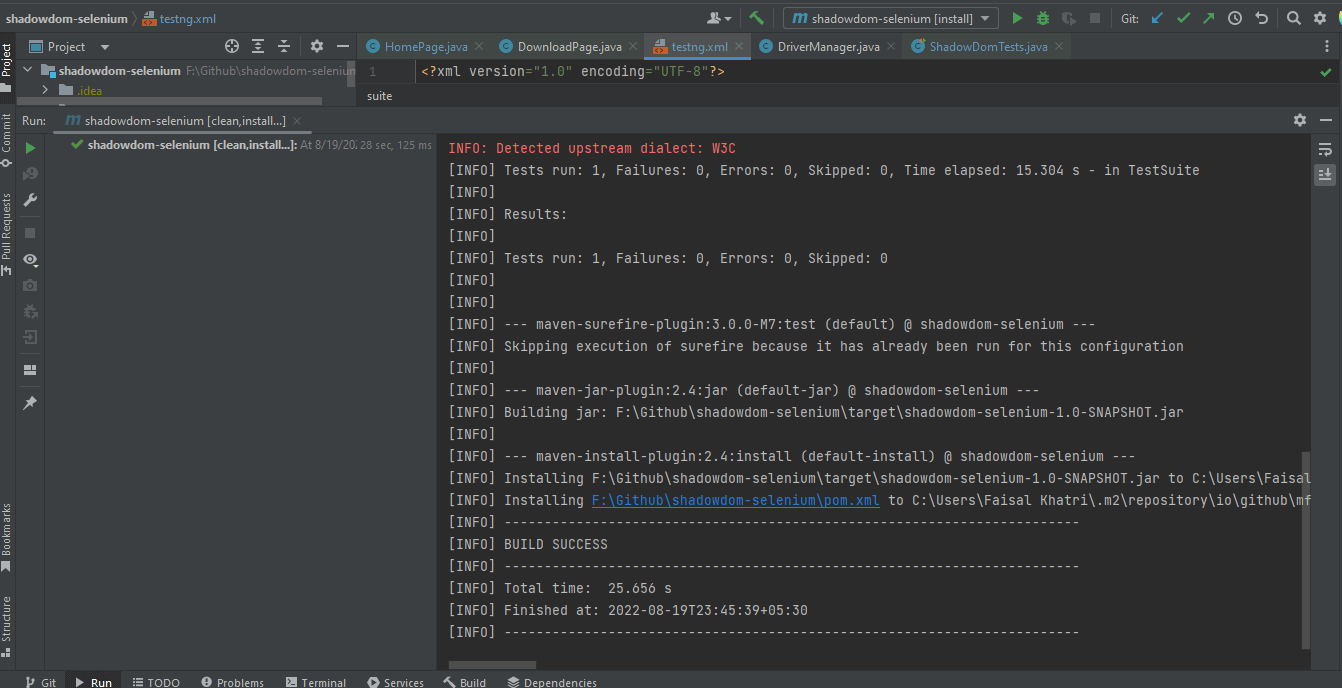
Hieronder is een screenshot van IntelliJ, die de uitvoerstatus van de tests weergeeft die worden uitgevoerd met Maven:
Zodra de tests succesvol zijn uitgevoerd, kunnen we naar het LambdaTest Dashboard gaan en alle videobandopnamen, screenshots, apparaatlogboeken en gedetailleerde stapsgewijze informatie over de testrun bekijken. Bekijk de onderstaande screenshots, die je een goed idee geven van het dashboard voor geautomatiseerde app-tests.
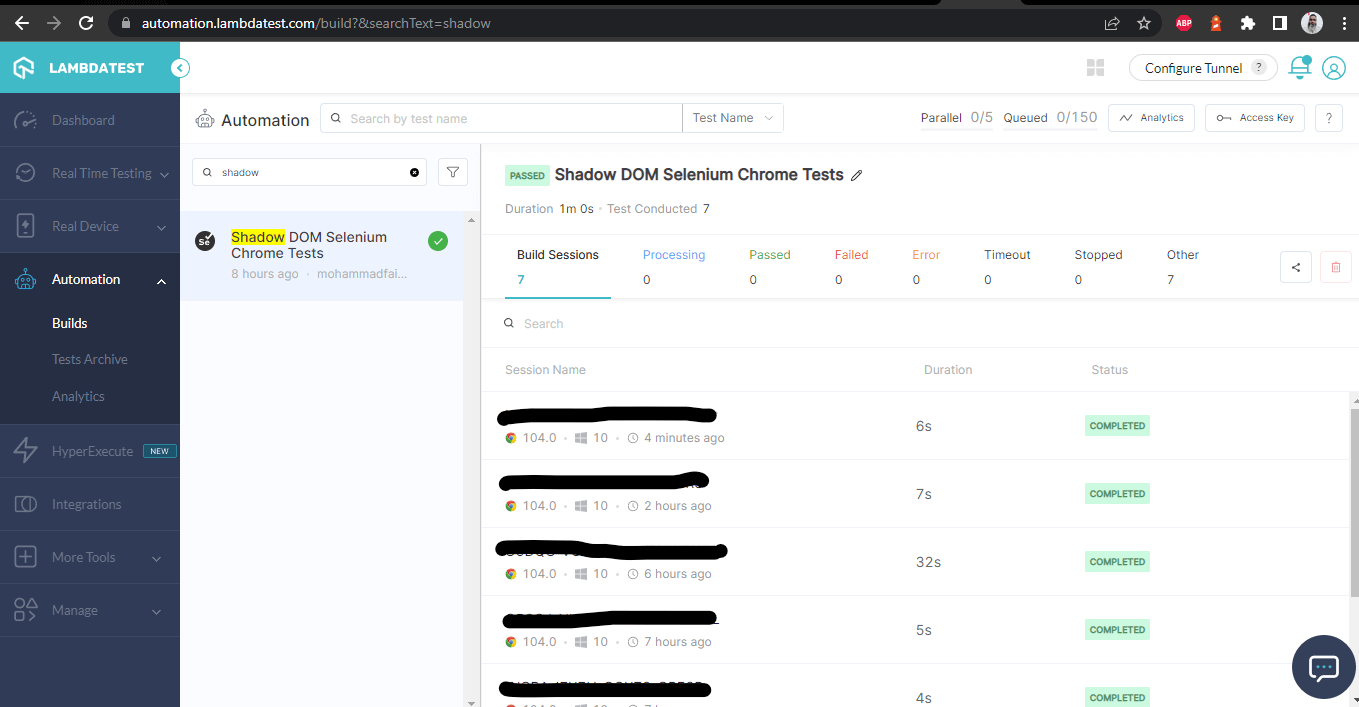 LambdaTest Dashboard
LambdaTest Dashboard
De volgende screenshots laten de details zien van de build en de tests die werden uitgevoerd voor het automatiseren van Shadow DOM in Selenium. Nogmaals, de testnaam, browserven, browserversie, OS-naam, respectievelijke OS-versie en schermresolutie zijn allemaal correct zichtbaar voor elke test.
Het bevat ook de video van de test die werd uitgevoerd, waardoor een beter idee wordt gegeven over hoe tests werden uitgevoerd op het apparaat.
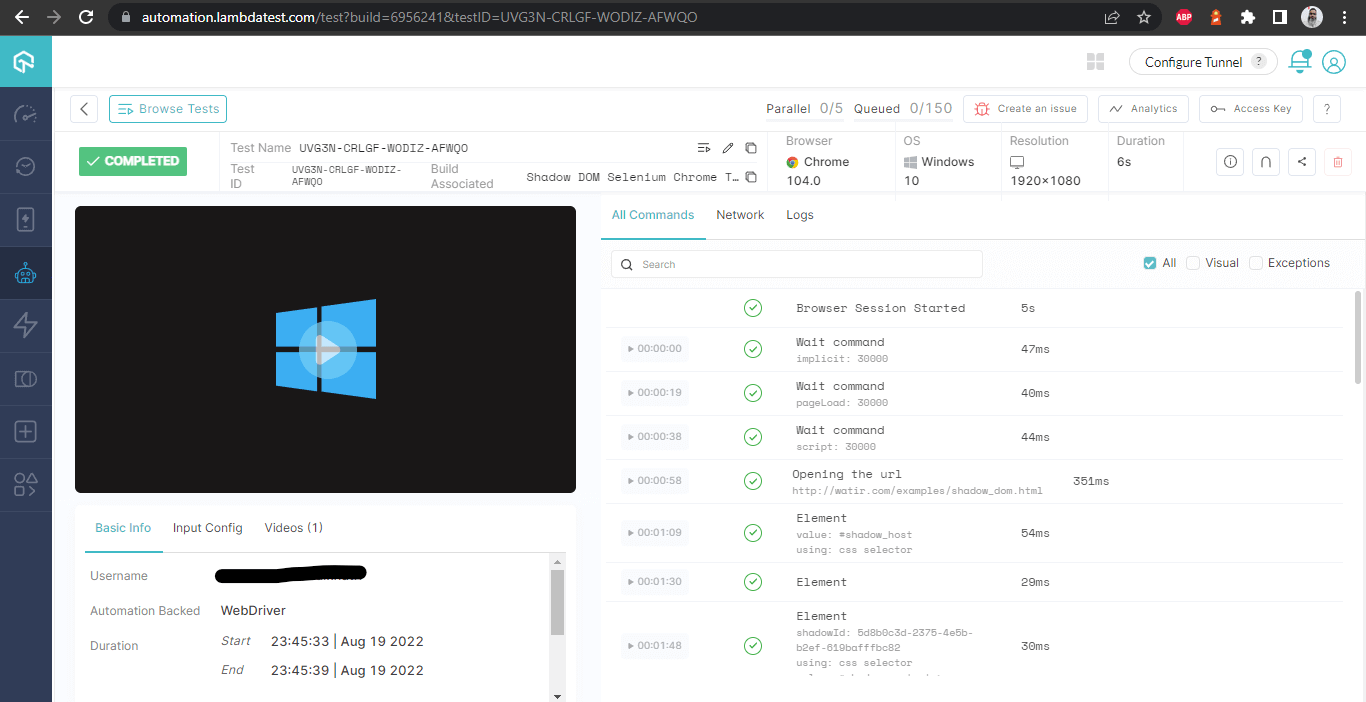 Bouwdossier
Bouwdossier
Deze schermafbeelding toont alle metrische gegevens in detail, die van grote hulp zijn vanuit het perspectief van de tester om te controleren welke test werd uitgevoerd op welke browser en om daaropvolgend de logboeken te bekijken voor het automatiseren van Shadow DOM in Selenium.
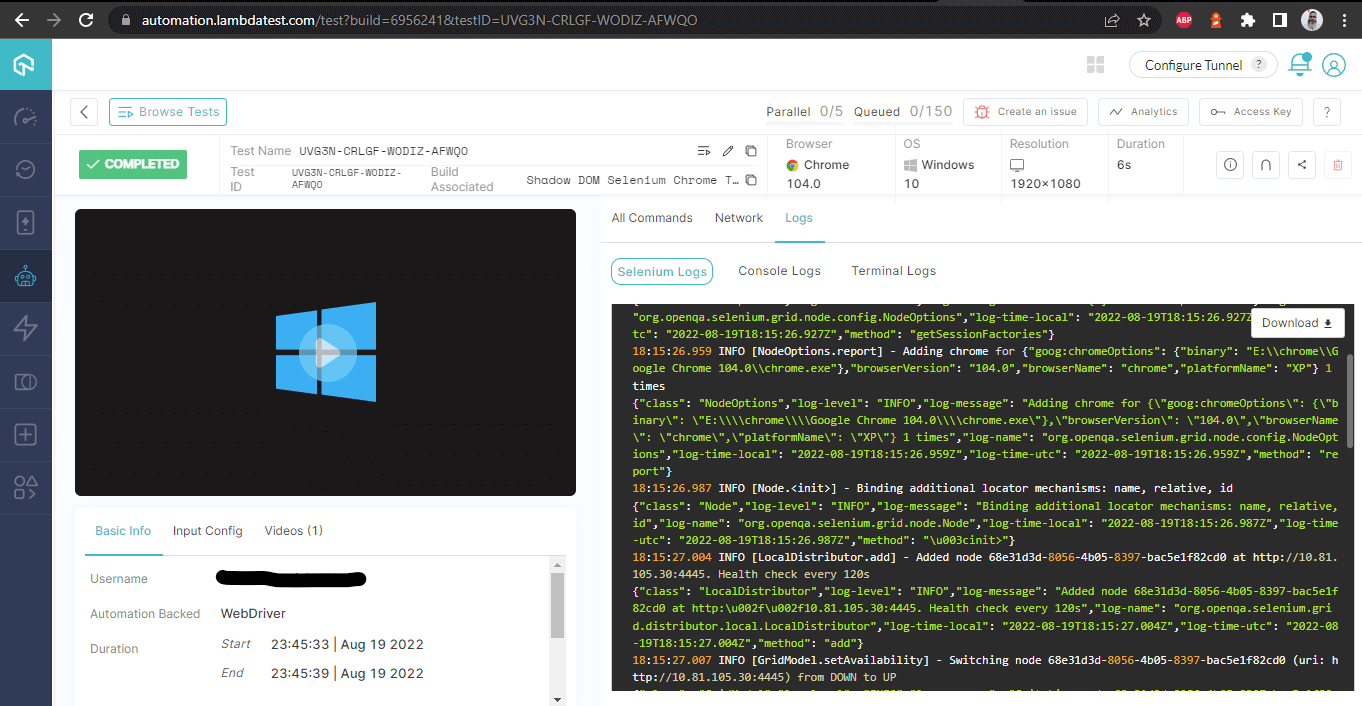 Bouwdetails – met logs
Bouwdetails – met logs
U kunt de nieuwste testresultaten, hun status en het totale aantal geslaagde of mislukte tests in het LambdaTest Analytics Dashboard inzien. Bovendien kunt u in de sectie Testoverzicht momentopnames van onlangs uitgevoerde testruns bekijken.
Conclusie
In deze blog over automatisering van Shadow DOM in Selenium bespraken we hoe u Shadow DOM-elementen kunt vinden en ze kunt automatiseren met behulp van de getShadowRoot() methode geïntroduceerd in versie 4.0.0 en hoger van Selenium WebDriver.
We bespraken ook het lokaliseren en automatiseren van Shadow DOM-elementen met behulp van JavaScriptExecutor in Selenium WebDriver en het uitvoeren van de tests op het platform van LambdaTest, dat gedetailleerde informatie geeft over de tests die zijn uitgevoerd met Selenium WebDriver-logs.
I hope this blog on Shadow DOM in Selenium gives you a fair idea about automating Shadow DOM elements using Selenium WebDriver.
Veel plezier met testen!
Source:
https://dzone.com/articles/how-to-automate-shadow-dom-in-selenium-webdriver