













I came across one of the test cases in my previous projects where I had to click on a button to navigate to the next page. I searched for the element locator of the button on the page and ran the tests hoping it would click the button and navigate to the next page.
Pero para mi sorpresa, la prueba falló porque no pudo localizar el elemento y recibí NoSuchElementException en los registros de la consola. No estaba contento de ver ese error, ya que era un botón simple que intentaba hacer clic y no había complejidad.
Al analizar el problema más a fondo, expandiendo el DOM y verificando los elementos raíz, descubrí que el localizador del botón estaba dentro del nodo #shadow-root(open), lo que me hizo darme cuenta de que necesita ser manejado de manera diferente ya que es un elemento de Shadow DOM.
En este tutorial de Selenium WebDriver, discutiremos los elementos de Shadow DOM y cómo automatizar el DOM en Shadow en Selenium WebDriver. Antes de pasar a la automatización del DOM en Shadow en Selenium, primero entendamos qué es el Shadow DOM y por qué se usa.
¿Qué es el Shadow DOM?
Shadow DOM es una funcionalidad que permite al navegador web renderizar elementos DOM sin colocarlos en el árbol DOM principal del documento. Esto crea una barrera entre lo que el desarrollador y el navegador pueden alcanzar; el desarrollador no puede acceder al Shadow DOM de la misma manera que lo haría con elementos anidados, mientras que el navegador puede renderizar y modificar ese código de la misma manera que lo haría con elementos anidados.
El Shadow DOM es una forma de lograr la encapsulación en el documento HTML. Al implementarlo, puedes mantener el estilo y el comportamiento de una parte del documento ocultos y separados del resto del código del mismo documento para que no haya interferencia.
Shadow DOM permite que los árboles DOM ocultos se adjunten a elementos en el DOM regular; el árbol Shadow DOM comienza con una raíz Shadow, debajo de la cual puedes adjuntar cualquier elemento de la misma manera que el DOM normal.
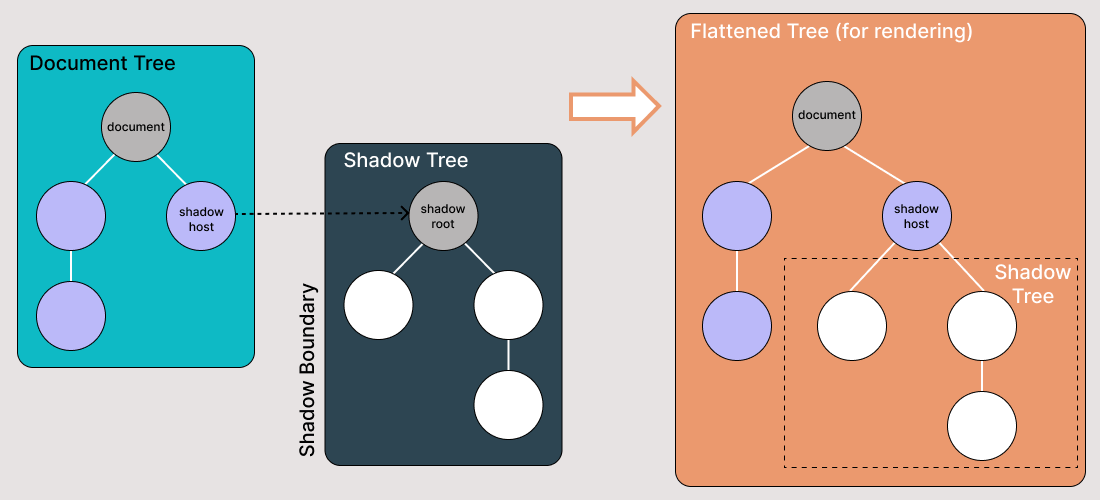
Hay algunos términos del Shadow DOM que debes conocer:
- Anfitrión de sombra: El nodo de DOM regular al que se adjunta el Shadow DOM
- Árbol de sombra: El árbol de DOM dentro del Shadow DOM
- El límite de sombra es donde termina el Shadow DOM y comienza el DOM regular.
- Raíz de sombra: El nodo raíz del árbol de sombra
¿Cuál es el uso del Shadow DOM?
Shadow DOM sirve para la encapsulación. Permite que un componente tenga su propio “árbol de sombra” de DOM que no se puede acceder accidentalmente desde el documento principal, puede tener reglas de estilo locales y más.
Aquí hay algunas de las propiedades esenciales del Shadow DOM:
- Tener su propio espacio de ids
- Invisible para selectores de JavaScript desde el documento principal, como querySelector
- Utilizar estilos solo del árbol de sombra, no del documento principal
Encontrar elementos de Shadow DOM usando Selenium WebDriver
Cuando intentamos encontrar los elementos de Shadow DOM usando localizadores de Selenium, obtenemos NoSuchElementException ya que no es directamente accesible al DOM.
Usaríamos la siguiente estrategia para acceder a los localizadores de Shadow DOM:
- Usando JavaScriptExecutor.
- Usando el método
getShadowDom()de Selenium WebDriver.
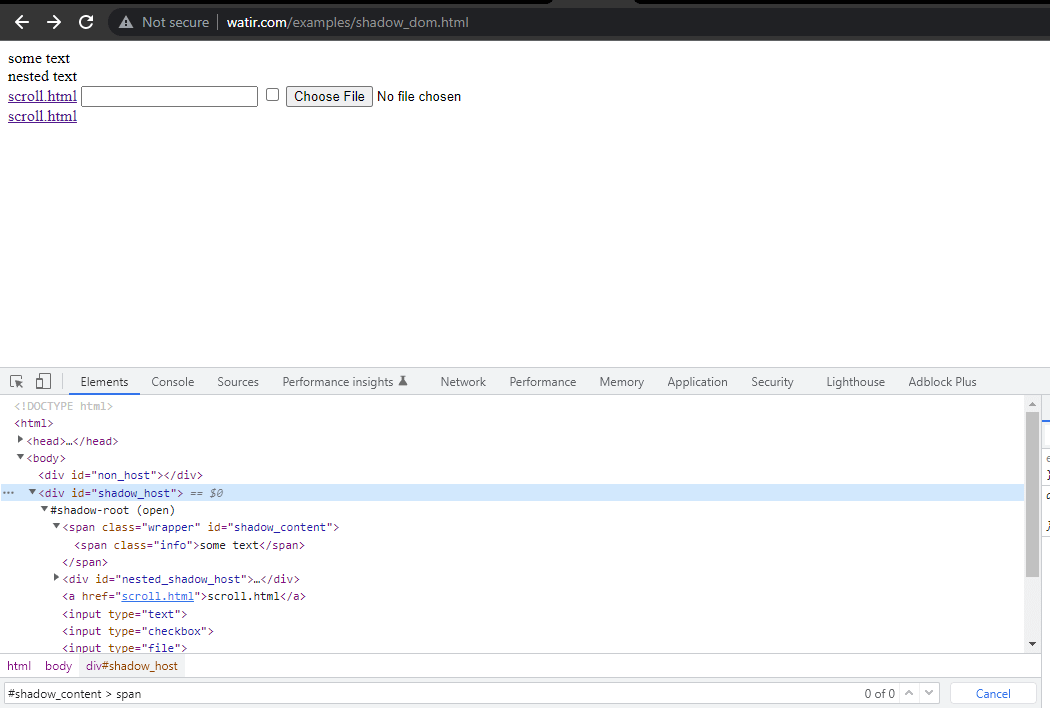
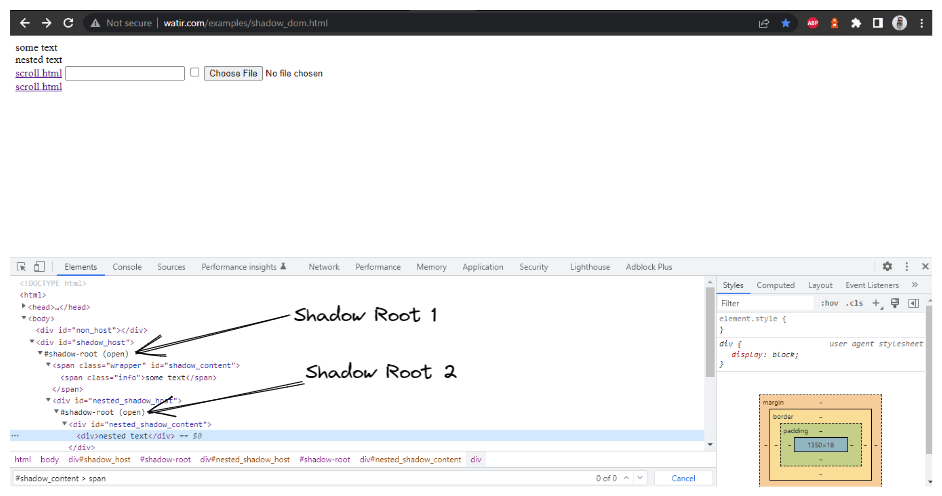
En esta sección de blog sobre la automatización del Shadow DOM en Selenium, tomemos como ejemplo la página de inicio de Watir.com y tratemos de afirmar el texto del shadow dom y el shadow dom anidado con Selenium WebDriver. Tenga en cuenta que tiene un elemento raíz de sombra antes de llegar al texto -> algún texto, y hay dos elementos raíz de sombra antes de llegar al texto -> texto anidado.
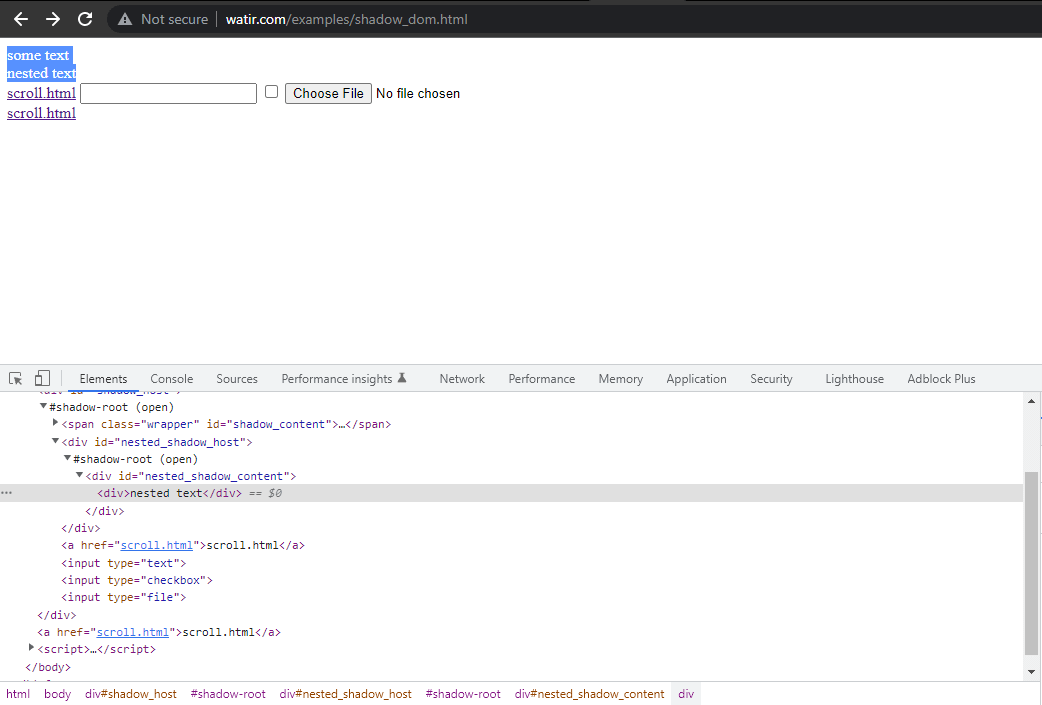
Ahora, si intentamos localizar el elemento utilizando el cssSelector("#shadow_content > span"), no se localiza, y Selenium WebDriver lanzará NoSuchElementException.
Aquí está la captura de pantalla de la clase Homepage, que tiene el código que intenta obtener texto usando
cssSelector(“#shadow_content > span”).

Aquí está la captura de pantalla de las pruebas donde intentamos afirmar el texto(“algún texto”).
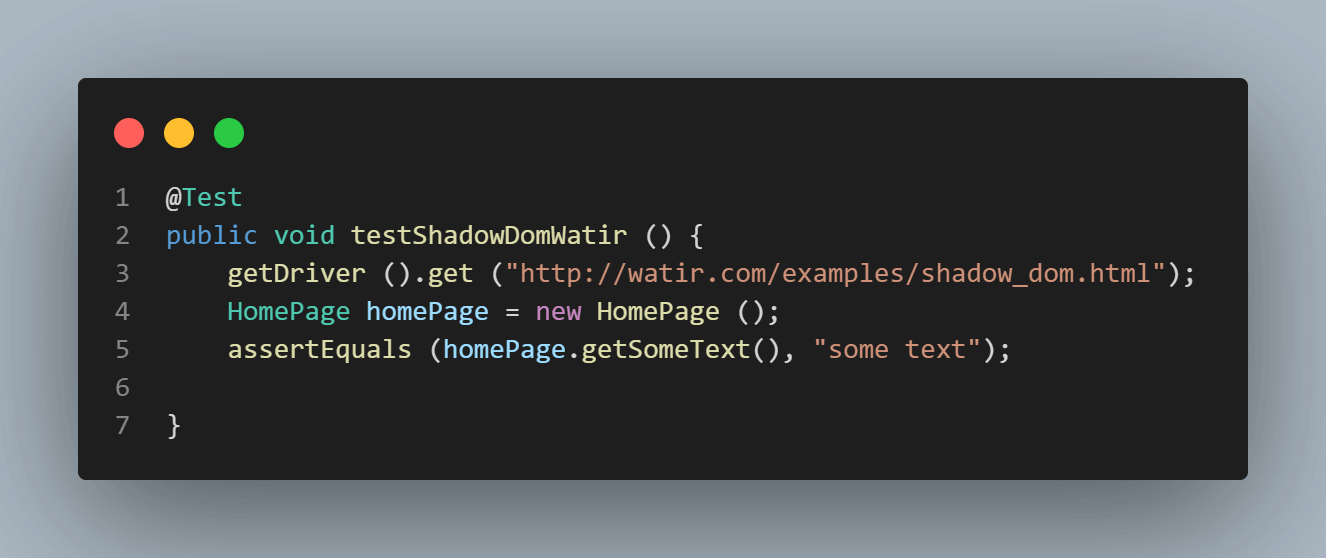
Error al ejecutar las pruebas muestra NoSuchElementException
Para localizar correctamente el elemento para el texto, necesitamos pasar por los elementos raíz de sombra. Solo entonces podríamos localizar “algún texto” y “texto anidado” en la página.
Cómo encontrar el Shadow DOM en Selenium WebDriver utilizando el método ‘getShadowDom’
Con el lanzamiento de la versión 4.0.0 y superiores de Selenium WebDriver, se introdujo el getShadowRoot() método y ayudó a localizar elementos raíz de sombra.
Aquí están la sintaxis y detalles del método getShadowRoot():
default SearchContext getShadowRoot()
Returns:
The ShadowRoot class represents the shadow root of a web component. With a shadow root, you can access the shadow DOM of a web component.
Throws:
NoSuchShadowRootException - If shadow root is not found.De acuerdo con la documentación, el método getShadowRoot() devuelve una representación de la raíz de sombra de un elemento para acceder al DOM de sombra de un componente web.
En caso de que no se encuentre la raíz de sombra, lanzará NoSuchShadowRootException.
Antes de comenzar a escribir las pruebas y discutir el código, déjame contarte sobre las herramientas que utilizaríamos para escribir y ejecutar las pruebas:
Se han utilizado los siguientes lenguajes de programación y herramientas en la escritura y ejecución de las pruebas:
- Lenguaje de Programación: Java 11
- Herramienta de Automatización Web: Selenium WebDriver
- Ejecutor de Pruebas: TestNG
- Herramienta de Construcción: Maven
- Plataforma en la Nube: LambdaTest
Empezando a Buscar el DOM de Sombra en Selenium WebDriver
Como se mencionó anteriormente, este proyecto sobre el DOM de sombra en Selenium ha sido creado utilizando Maven. TestNG se utiliza como ejecutor de pruebas. Para obtener más información sobre Maven, puedes leer este blog sobre empezar con Maven para pruebas de Selenium.
Una vez que se crea el proyecto, necesitamos agregar la dependencia para Selenium WebDriver, y TestNG en el archivo pom.xml.
Las versiones de las dependencias se establecen en un bloque de propiedades separado. Esto se hace por razones de mantenibilidad, de modo que si necesitamos actualizar las versiones, podemos hacerlo fácilmente sin buscar la dependencia en todo el archivo pom.xml.
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>io.github.mfaisalkhatri</groupId>
<artifactId>shadowdom-selenium</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<selenium.java.version>4.4.0</selenium.java.version>
<testng.version>7.6.1</testng.version>
<webdrivermanager.version>5.2.1</webdrivermanager.version>
<maven.compiler.version>3.10.1</maven.compiler.version>
<surefire-version>3.0.0-M7</surefire-version>
<java.release.version>11</java.release.version>
<maven.source.encoding>UTF-8</maven.source.encoding>
<suite-xml>testng.xml</suite-xml>
<argLine>-Dfile.encoding=UTF-8 -Xdebug -Xnoagent</argLine>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.seleniumhq.selenium/selenium-java -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>${selenium.java.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.testng/testng -->
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>${testng.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.github.bonigarcia</groupId>
<artifactId>webdrivermanager</artifactId>
<version>${webdrivermanager.version}</version>
<exclusions>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>${maven.compiler.version}</version>
<configuration>
<release>${java.release.version}</release>
<encoding>${maven.source.encoding}</encoding>
<forceJavacCompilerUse>true</forceJavacCompilerUse>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>${surefire-version}</version>
<executions>
<execution>
<goals>
<goal>test</goal>
</goals>
</execution>
</executions>
<configuration>
<useSystemClassLoader>false</useSystemClassLoader>
<properties>
<property>
<name>usedefaultlisteners</name>
<value>false</value>
</property>
</properties>
<suiteXmlFiles>
<suiteXmlFile>${suite-xml}</suiteXmlFile>
</suiteXmlFiles>
<argLine>${argLine}</argLine>
</configuration>
</plugin>
</plugins>
</build>
</project>Pasemos ahora al código; se ha utilizado el Modelo de Objeto de Página (POM) en este proyecto ya que es útil para reducir la duplicación de código y mejorar el mantenimiento de casos de prueba.
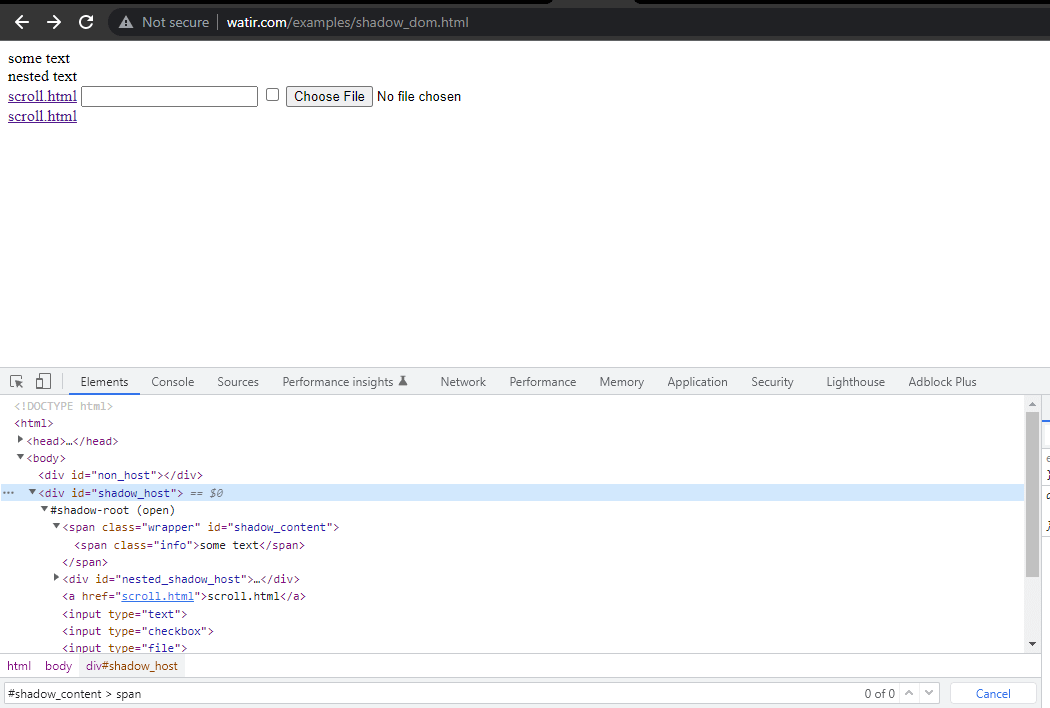
Primero, encontraríamos el localizador para “algún texto” y “texto anidado” en la Página de Inicio.
public class HomePage {
public SearchContext expandRootElement (WebElement element) {
SearchContext shadowRoot = (SearchContext) ((JavascriptExecutor) getDriver ()).executeScript (
"return arguments[0].shadowRoot", element);
return shadowRoot;
}
public String getSomeText () {
return getDriver ().findElement (By.cssSelector ("#shadow_content > span"))
.getText ();
}
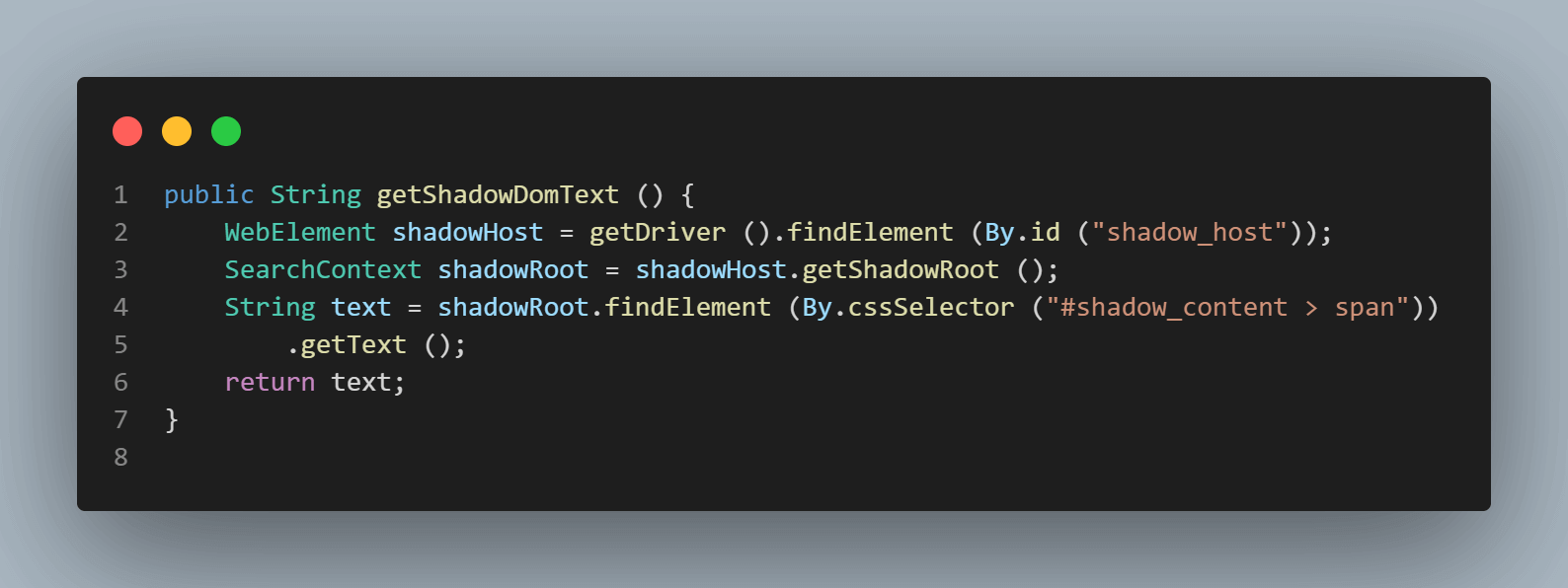
public String getShadowDomText () {
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRoot = shadowHost.getShadowRoot ();
String text = shadowRoot.findElement (By.cssSelector ("#shadow_content > span"))
.getText ();
return text;
}
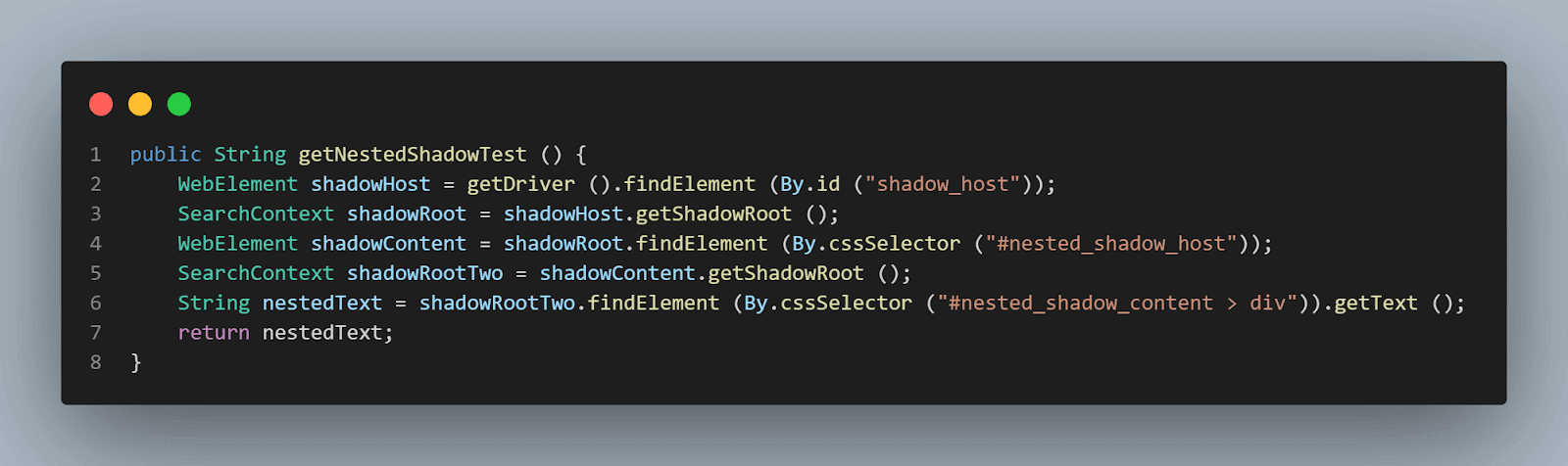
public String getNestedShadowText () {
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRoot = shadowHost.getShadowRoot ();
WebElement shadowContent = shadowRoot.findElement (By.cssSelector ("#nested_shadow_host"));
SearchContext shadowRootTwo = shadowContent.getShadowRoot ();
String nestedText = shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div")).getText ();
return nestedText;
}
public String getNestedText() {
WebElement nestedText = getDriver ().findElement (By.id ("shadow_host")).getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_host")).getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_content > div"));
return nestedText.getText ();
}
public String getNestedTextUsingJSExecutor () {
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRootOne = expandRootElement (shadowHost);
WebElement nestedShadowHost = shadowRootOne.findElement (By.cssSelector ("#nested_shadow_host"));
SearchContext shadowRootTwo = expandRootElement (nestedShadowHost);
return shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div"))
.getText ();
}
}Explicación del Código
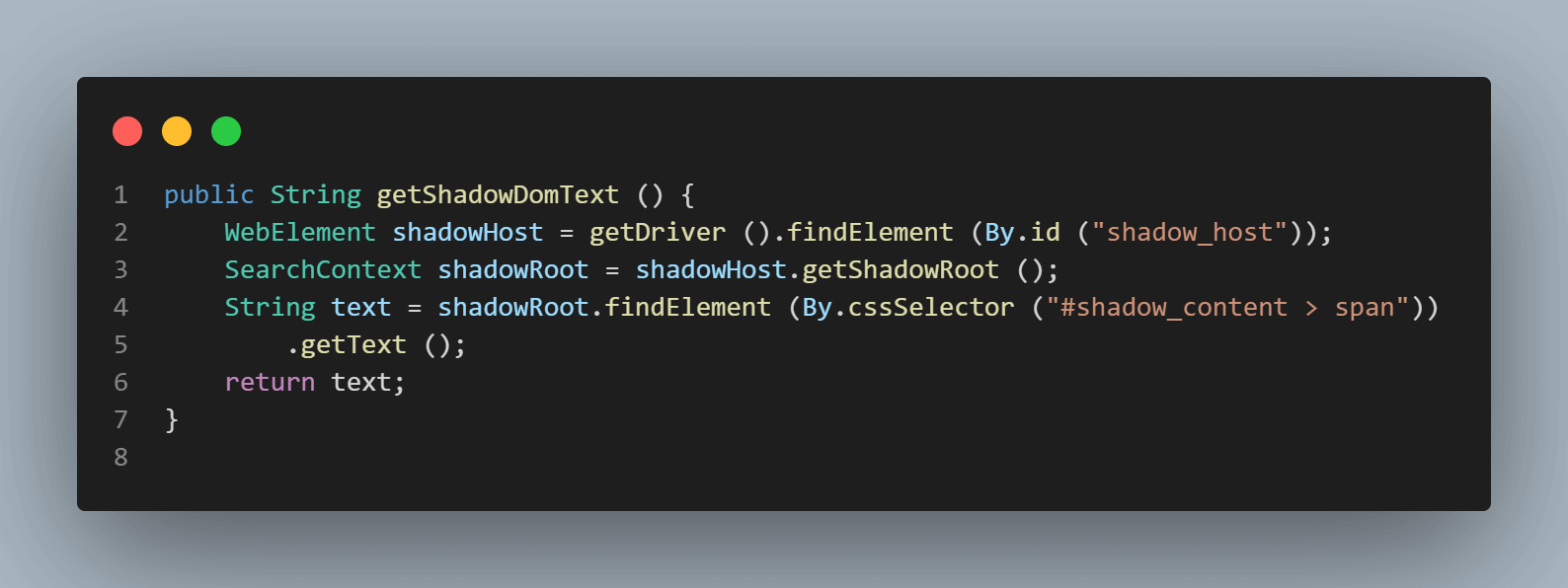
El primer elemento que localizaremos estará en el < div id = "shadow_host" > utilizando la estrategia de localizador – id.
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));Luego, buscamos el primer Shadow Root en el DOM junto a él. Para esto, hemos utilizado la interfaz SearchContext. El Shadow Root se devuelve utilizando el método getShadowRoot(). Si revisas la captura de pantalla anterior, #shadow-root (open) está junto al < div id = "shadow_host" >.
Para localizar el texto – “algún texto,” solo hay un elemento de Shadow DOM que necesitamos atravesar.
La siguiente línea de código nos ayuda a obtener el elemento raíz de Shadow.
SearchContext shadowRoot = downloadsManager.getShadowRoot();Una vez que se encuentra el Shadow Root, podemos buscar el elemento para localizar el texto – “algún texto.” La siguiente línea de código nos ayuda a obtener el texto:
String text = shadowRoot.findElement (By.cssSelector ("#shadow_content > span"))
.getText ();A continuación, encontremos el localizador de “texto anidado,” que tiene un elemento Shadow root anidado, y descubramos cómo localizar su elemento.
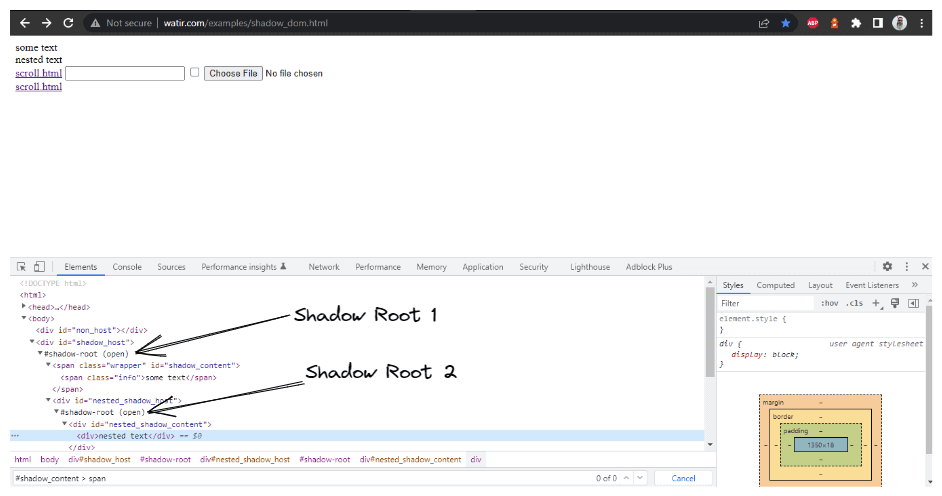
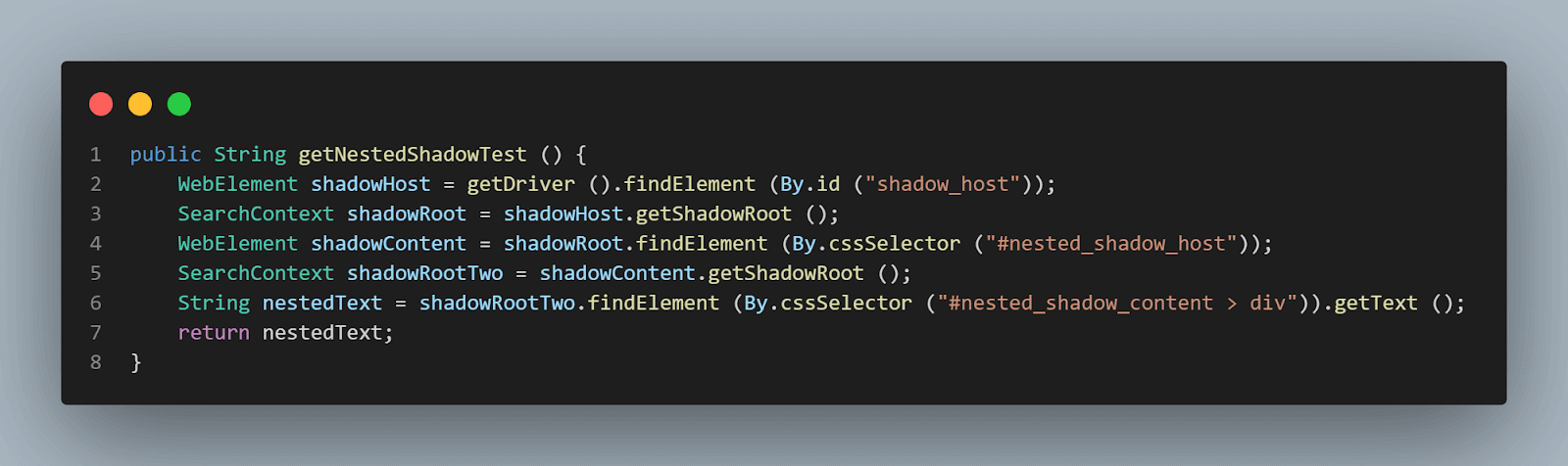
método getNestedShadowText():
Partiendo desde el principio, como se discutió en la sección anterior, necesitamos localizar < div id = "shadow_host" > utilizando la estrategia de localización – id.
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));Luego, necesitamos encontrar el elemento Shadow Root utilizando el método getShadowRoot(); una vez que obtengamos el elemento Shadow root, tendremos que buscar el segundo Shadow root utilizando cssSelector para localizar:
<div id ="nested_shadow_host">
SearchContext shadowRoot = shadowHost.getShadowRoot ();
WebElement shadowContent = shadowRoot.findElement (By.cssSelector ("#nested_shadow_host"));A continuación, necesitamos encontrar el segundo elemento Shadow Root utilizando el método getShadowRoot(). Finalmente, es hora de localizar el elemento real para obtener el texto – “texto anidado.”
El siguiente fragmento de código nos ayudará a localizar el texto:
SearchContext shadowRootTwo = shadowContent.getShadowRoot ();
String nestedText = shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div"Escribir el Código de Manera Fluida
En la sección anterior de este blog sobre Shadow DOM en Selenium, vimos un camino largo desde donde tenemos que localizar el elemento real con el que queremos trabajar, y tenemos que hacer múltiples inicializaciones de las interfaces WebElement y SearchContext y escribir múltiples líneas de código para localizar un solo elemento con el que trabajar.
También tenemos una manera fluida de escribir todo este código, y así es como puedes hacerlo:
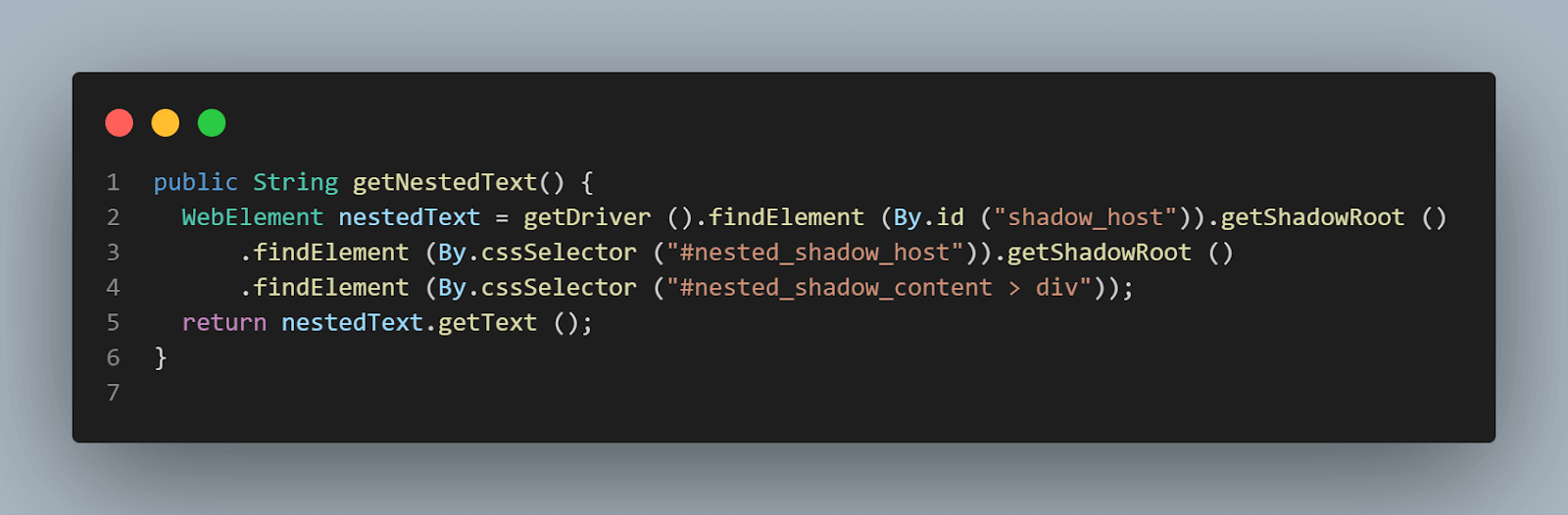
public String getNestedText() {
WebElement nestedText = getDriver ().findElement (By.id ("shadow_host"))
.getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_host"))
.getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_content > div"));
return nestedText.getText ();
}El diseño de la Interfaz Fluida depende en gran medida de la concatenación de métodos. El patrón de Interfaz Fluida nos ayuda a escribir un código fácilmente legible que puede comprenderse sin necesidad de esforzarse en entender técnicamente el código. Este término fue acuñado por primera vez en 2005 por Eric Evans y Martin Fowler.
Este es el método de concatenación que realizaríamos para localizar el elemento.
Este código hace lo mismo que hicimos en los pasos anteriores.
- Primero, localizaremos el elemento shadow_host utilizando su id, después obtendremos el elemento Shadow Root usando el método
getShadowRoot(). - A continuación, buscaremos el elemento nested_shadow_host utilizando el selector CSS y obtendremos el elemento Shadow Root usando el método
getShadowRoot(). - Finalmente, obtendremos el texto “texto anidado” utilizando el selector CSS – nested_shadow_content > div.
Cómo Encontrar Shadow DOM en Selenium Usando JavaScriptExecutor
En los ejemplos de código anteriores, localizamos elementos usando el método getShadowRoot(). Veamos ahora cómo podemos localizar los elementos raíz de Shadow utilizando JavaScriptExecutor en Selenium WebDriver.
Se ha creado el método getNestedTextUsingJSExecutor() dentro de la Clase HomePage,
donde expandiremos el Shadow Root elemento basado en el WebElement que pasamos como parámetro. En el DOM (como se muestra en la captura de pantalla anterior), vimos que hay dos elementos Shadow Root que necesitamos expandir antes de llegar al localizador real para obtener el texto – texto anidado. Por lo tanto, se creó el método expandRootElement() en lugar de copiar y pegar el mismo código de JavaScript Executor cada vez.
Implementaremos la interfaz SearchContext, lo que nos ayudará con el JavaScriptExecutor y devolverá el elemento Shadow root basado en el WebElement que pasamos como parámetro.
public SearchContext expandRootElement (WebElement element) {
SearchContext shadowRoot = (SearchContext) ((JavascriptExecutor) getDriver ()).executeScript (
"return arguments[0].shadowRoot", element);
return shadowRoot;
}
método getNestedTextUsingJSExecutor()
El primer elemento que localizaremos será el <div id="shadow_host"> utilizando la estrategia de localizador – id.
A continuación, expandiremos el Elemento Raíz basado en el WebElement shadow_host que buscamos.
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRootOne = expandRootElement (shadowHost);Después de expandir el Shadow Root uno, podemos buscar otro WebElement utilizando cssSelector para localizar:
<div id ="nested_shadow_host">
WebElement nestedShadowHost = shadowRootOne.findElement (By.cssSelector ("#nested_shadow_host"));
SearchContext shadowRootTwo = expandRootElement (nestedShadowHost);Finalmente, ahora es el momento de localizar el elemento real para obtener el texto – “texto anidado.”
La siguiente línea de código nos ayudará a localizar el texto:
shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div"))
.getText ();Demostración
En esta sección del artículo sobre Shadow DOM en Selenium, escribamos rápidamente una prueba y verifiquemos que los selectores que encontramos en los pasos anteriores nos proporcionan el texto requerido. Podemos ejecutar afirmaciones en el código que escribimos para verificar que lo que esperamos del código está funcionando.
@Test
public void testShadowDomWatir () {
getDriver ().get ("http://watir.com/examples/shadow_dom.html");
HomePage homePage = new HomePage ();
// assertEquals (homePage.getSomeText(), "some text");
assertEquals (homePage.getShadowDomText (), "some text");
assertEquals (homePage.getNestedShadowText (),"nested text");
assertEquals (homePage.getNestedText (), "nested text");
assertEquals (homePage.getNestedTextUsingJSExecutor (), "nested text");
}Esta es solo una prueba simple para afirmar que los textos se muestran correctamente como se esperaba. Verificaremos eso utilizando la afirmación assertEquals() en TestNG.
En el valor real, proporcionaríamos el método que acabamos de escribir para obtener el texto de la página, y en el valor esperado, pasaríamos el texto “some text” o “nested text,” dependiendo de las afirmaciones que estemos realizando.
Se proporcionan cuatro declaraciones assertEquals en la prueba.
- Comprobando el elemento Shadow DOM utilizando el método
getShadowRoot():
- Comprobando el elemento Shadow DOM anidado utilizando el método
getShadowRoot():
- Comprobando el elemento Shadow DOM anidado utilizando el método
getShadowRoot()y escribiendo de manera fluida:
Ejecución
Hay dos formas de ejecutar las pruebas para automatizar Shadow DOM en Selenium:
- Desde el IDE utilizando TestNG
- Desde la CLI utilizando Maven
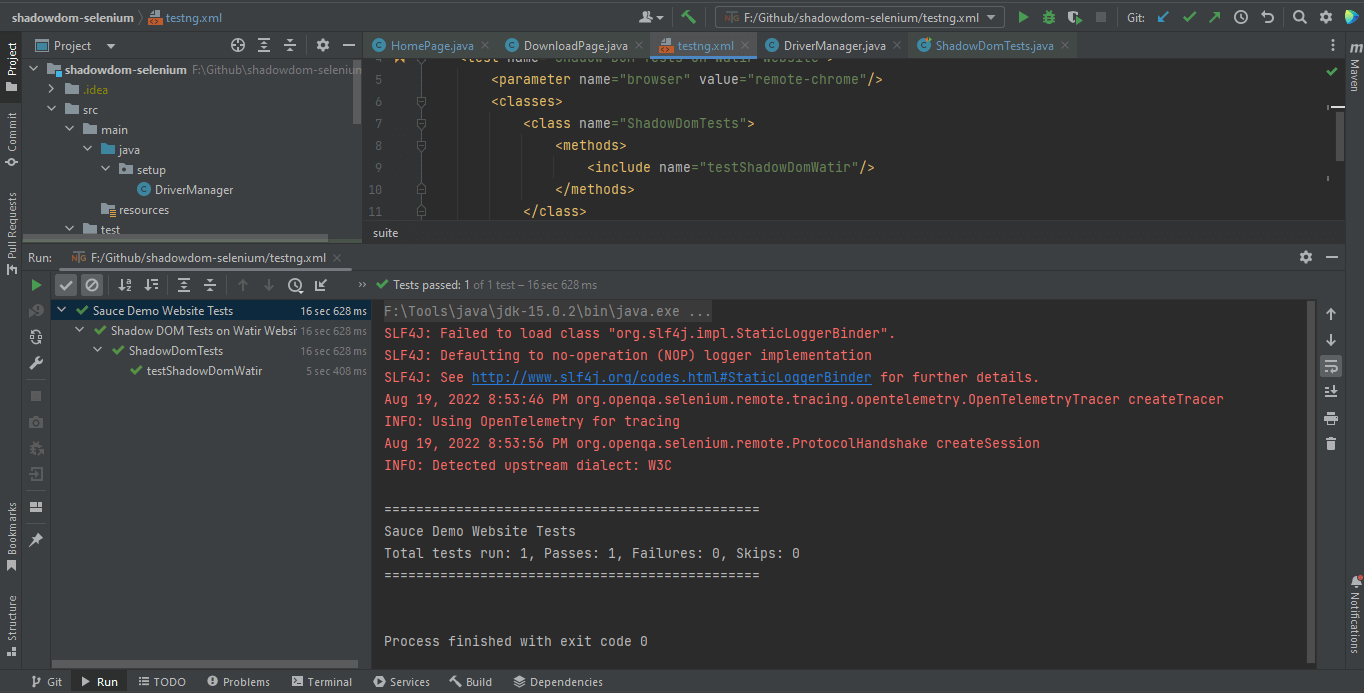
Automatizando Shadow DOM en Selenium WebDriver Utilizando TestNG
TestNG se utiliza como ejecutor de pruebas. Por lo tanto, se ha creado un archivo testng.xml, mediante el cual ejecutaremos las pruebas haciendo clic derecho en el archivo y seleccionando la opción Ejecutar ‘…\testng.xml’. Pero antes de ejecutar las pruebas, debemos agregar el nombre de usuario y la clave de acceso de LambdaTest en las Configuraciones de Ejecución ya que estamos leyendo el nombre de usuario y la clave de acceso desde la Propiedad del Sistema.
LambdaTest ofrece pruebas en navegadores cruzados en una granja de navegadores en línea de más de 3000 navegadores reales y sistemas operativos para ayudarlo a ejecutar pruebas en Java tanto localmente como en la nube. Puede acelerar sus pruebas de Selenium con Java y reducir el tiempo de ejecución de las pruebas en varias veces al ejecutar pruebas en paralelo en varios navegadores y configuraciones de SO.
- Agregue los valores en la Configuración de Ejecución como se menciona a continuación:
- Dusername =
< Nombre de usuario de LambdaTest > - DaccessKey =
< Clave de acceso de LambdaTest >
- Dusername =
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd">
<suite name="Sauce Demo Website Tests">
<test name="Shadow DOM Tests on Watir Website">
<parameter name="browser" value="remote-chrome"/>
<classes>
<class name="ShadowDomTests">
<methods>
<include name="testShadowDomWatir"/>
</methods>
</class>
</classes>
</test> <!-- Test -->
</suite>Aquí está la captura de pantalla de la ejecución de la prueba localmente para Shadow DOM en Selenium usando Intellij IDE.
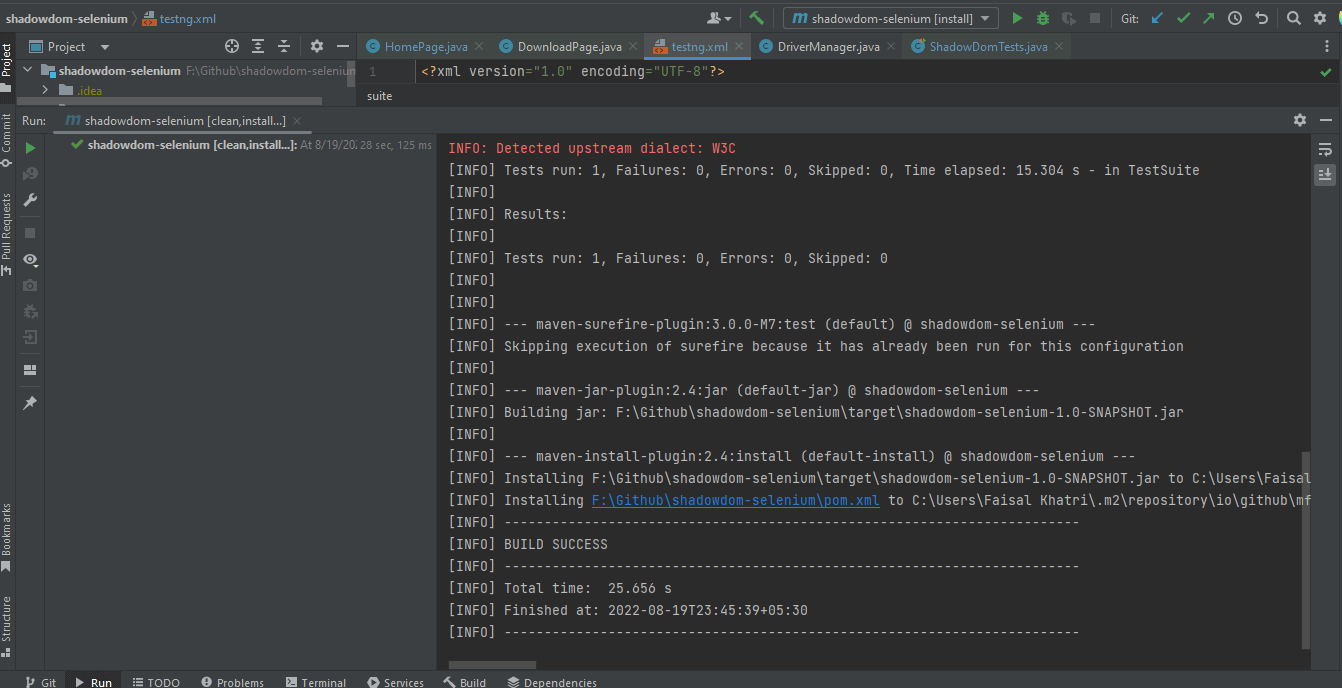
Automatización de Shadow DOM en Selenium WebDriver Usando Maven
Para ejecutar las pruebas usando Maven, se deben seguir los siguientes pasos para automatizar Shadow DOM en Selenium:
- Abra la ventana de comandos/Terminal.
- Navegue hasta la carpeta raíz del proyecto.
- Escriba el comando:
mvn clean install -Dusername=< Nombre de usuario de LambdaTest > -DaccessKey=< Clave de acceso de LambdaTest >.
A continuación se muestra la captura de pantalla de IntelliJ, que muestra el estado de ejecución de las pruebas utilizando Maven:
Una vez que las pruebas se ejecutan con éxito, podemos consultar el Panel de Control de LambdaTest y ver todos los registros de video, capturas de pantalla, registros de dispositivos y detalles granulares paso a paso de la ejecución de la prueba. Echa un vistazo a las capturas de pantalla a continuación, que te darán una idea justa del panel de control para pruebas automatizadas de aplicaciones.
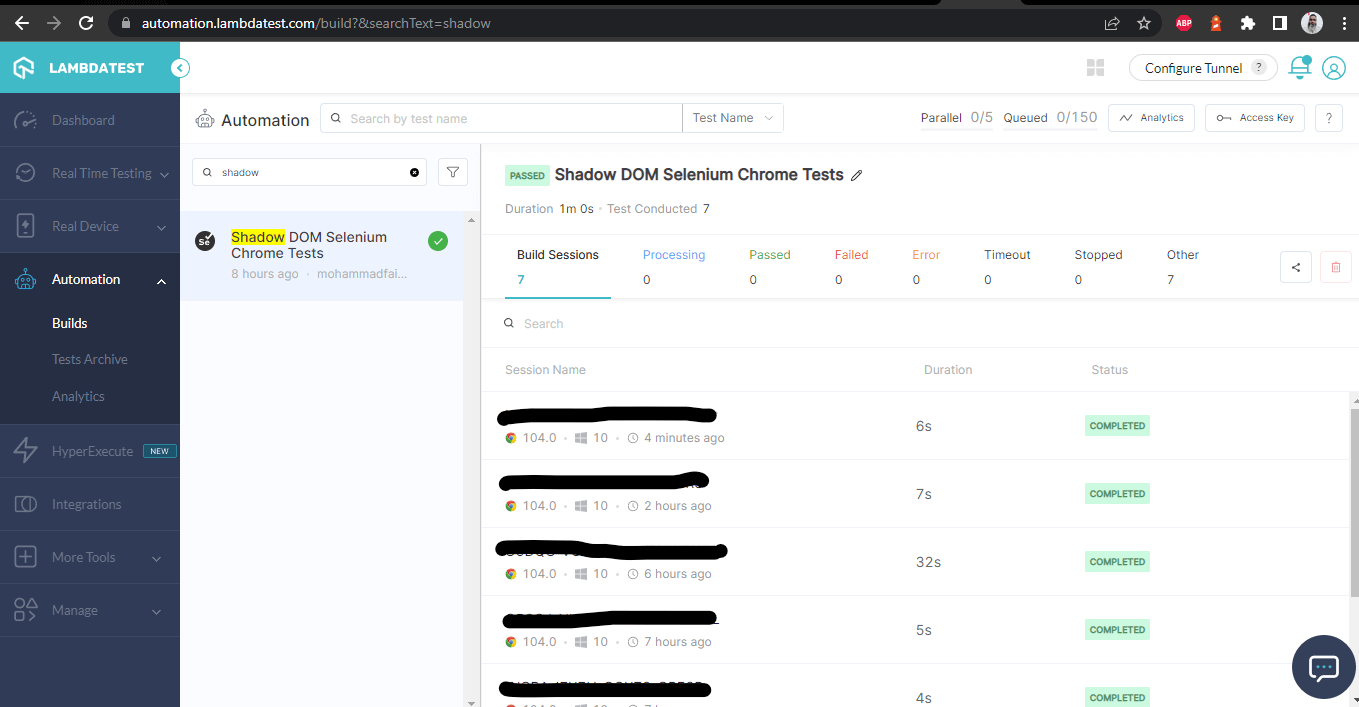 Panel de Control de LambdaTest
Panel de Control de LambdaTest
Las siguientes capturas de pantalla muestran los detalles de la compilación y las pruebas que se realizaron para automatizar Shadow DOM en Selenium. Una vez más, el nombre de la prueba, el nombre del navegador, la versión del navegador, el nombre del sistema operativo, la versión correspondiente del sistema operativo y la resolución de pantalla son todos visibles correctamente para cada prueba.
También tiene el video de la prueba que se realizó, lo que da una mejor idea de cómo se ejecutaron las pruebas en el dispositivo.
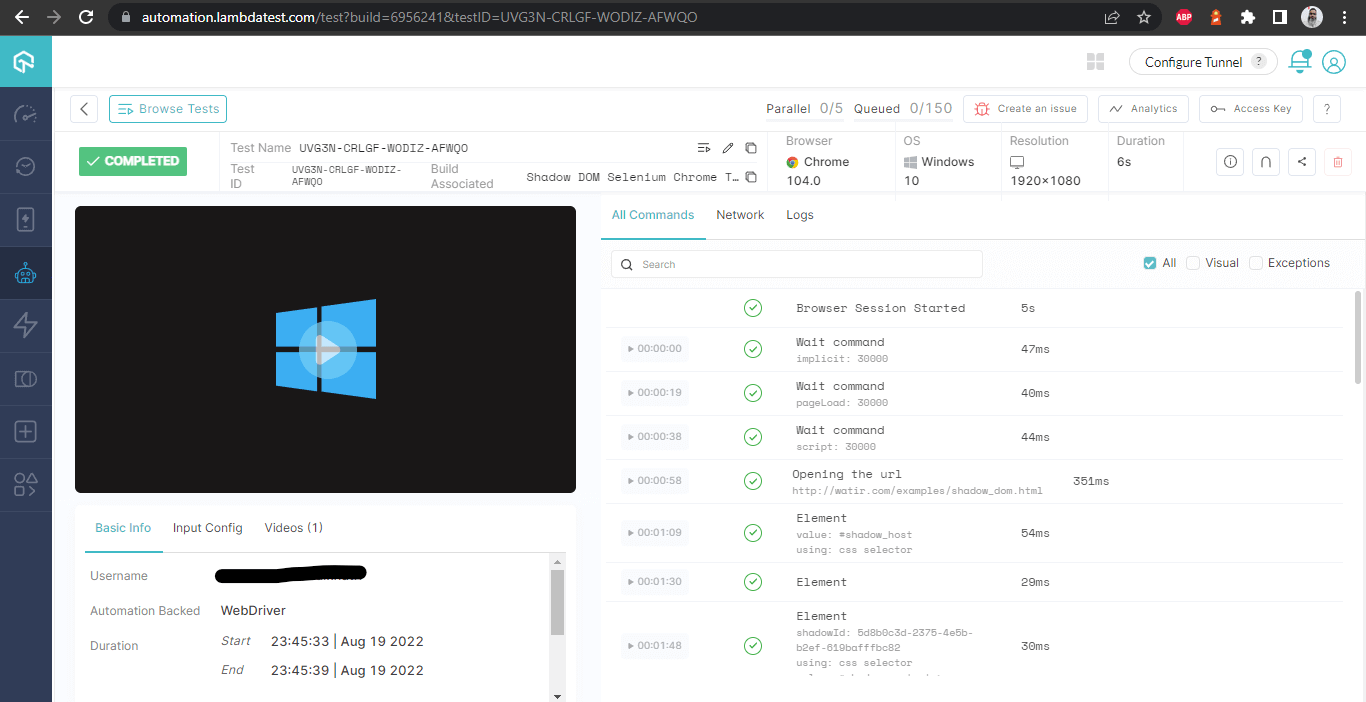 Detalles de la Compilación
Detalles de la Compilación
Esta pantalla muestra todos los metrícas en detalle, que son muy útiles desde el punto de vista del tester para verificar qué prueba se realizó en qué navegador y, en consecuencia, ver los registros para automatizar Shadow DOM en Selenium.
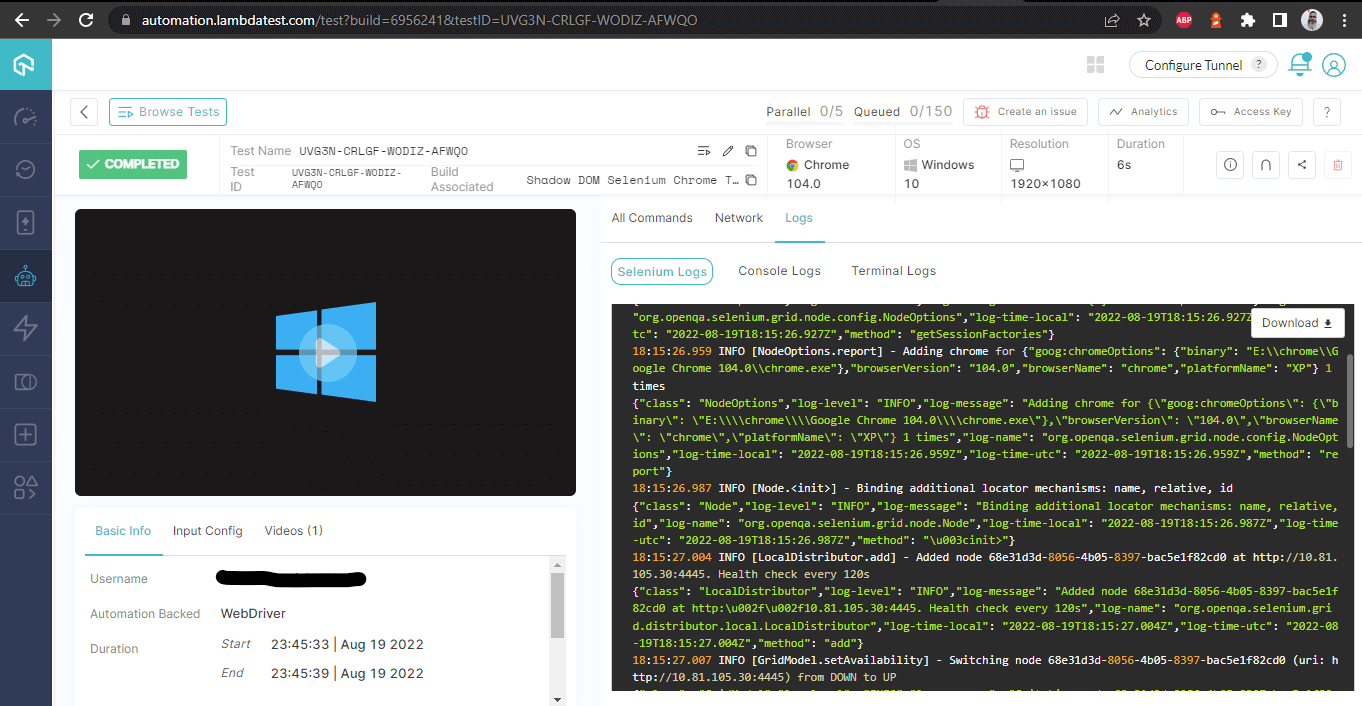 Detalles de Construcción – con registros
Detalles de Construcción – con registros
Puedes acceder a los resultados de las pruebas más recientes, su estado y el número total de pruebas aprobadas o fallidas en el Tablero de Análisis de LambdaTest. Además, puedes ver capturas de pantalla de las ejecuciones de pruebas recientemente realizadas en la sección de Resumen de Pruebas.
Conclusión
En este blog sobre la automatización del Shadow DOM en Selenium, discutimos cómo encontrar elementos del Shadow DOM y automatizarlos utilizando el método getShadowRoot() introducido en la versión 4.0.0 y superiores de Selenium WebDriver.
También discutimos la localización y automatización de los elementos del Shadow DOM utilizando JavaScriptExecutor en Selenium WebDriver y ejecutando las pruebas en la Plataforma de LambdaTest, que muestra detalles granulares de las pruebas que se ejecutaron con registros de Selenium WebDriver.
I hope this blog on Shadow DOM in Selenium gives you a fair idea about automating Shadow DOM elements using Selenium WebDriver.
¡Feliz prueba!
Source:
https://dzone.com/articles/how-to-automate-shadow-dom-in-selenium-webdriver