













В ваших Java-приложениях вы, как правило, будете работать с различными типами объектов. И вам может понадобиться выполнять операции, такие как сортировка, поиск и итерация по этим объектам.
До введения фреймворка Collections в JDK 1.2 вы использовали бы массивы и векторы для хранения и управления группой объектов. Но у них были свои недостатки.
Фреймворк Java Collections нацелен на преодоление этих проблем, предоставляя высокопроизводительные реализации общих структур данных. Это позволяет вам сосредоточиться на написании логики приложения, а не на низкоуровневых операциях.
Затем введение обобщений в JDK 1.5 значительно улучшило фреймворк Java Collections. Обобщения позволяют вам обеспечить типовую безопасность для объектов, хранящихся в коллекции, что повышает надежность ваших приложений. Вы можете прочитать больше о Java Generics здесь.
В этой статье я проведу вас через то, как использовать фреймворк Java Collections. Мы обсудим различные типы коллекций, такие как списки, множества, очереди и карты. Я также предоставлю краткое объяснение их ключевых характеристик, таких как:
-
Внутренние механизмы
-
Обработка дубликатов
-
Поддержка null-значений
-
Упорядоченность
-
Синхронизация
-
Производительность
-
Ключевые методы
-
Общие реализации
Мы также рассмотрим некоторые примеры кода для лучшего понимания, и я затрону утилитарный класс Collections и его использование.
Содержание:
Понимание фреймворка коллекций Java
Согласно документации Java, “Коллекция — это объект, представляющий группу объектов. Фреймворк коллекций — это унифицированная архитектура для представления и манипуляции коллекциями.”
Проще говоря, фреймворк коллекций Java помогает вам управлять группой объектов и выполнять операции с ними эффективно и организованно. Он упрощает разработку приложений, предлагая различные методы для работы с группами объектов. Вы можете добавлять, удалять, искать и сортировать объекты эффективно, используя фреймворк коллекций Java.
Интерфейсы коллекций
В Java интерфейс задает контракт, который должен быть выполнен любым классом, который его реализует. Это означает, что реализующий класс должен предоставить конкретные реализации для всех методов, объявленных в интерфейсе.
В Java Collections Framework различные интерфейсы коллекций, такие как Set, List и Queue, расширяют интерфейс Collection и должны соблюдать контракт, определенный интерфейсом Collection.
Расшифровка иерархии Java Collections Framework
Посмотрите на эту определенную диаграмму из этой статьи, которая иллюстрирует иерархию коллекций Java:
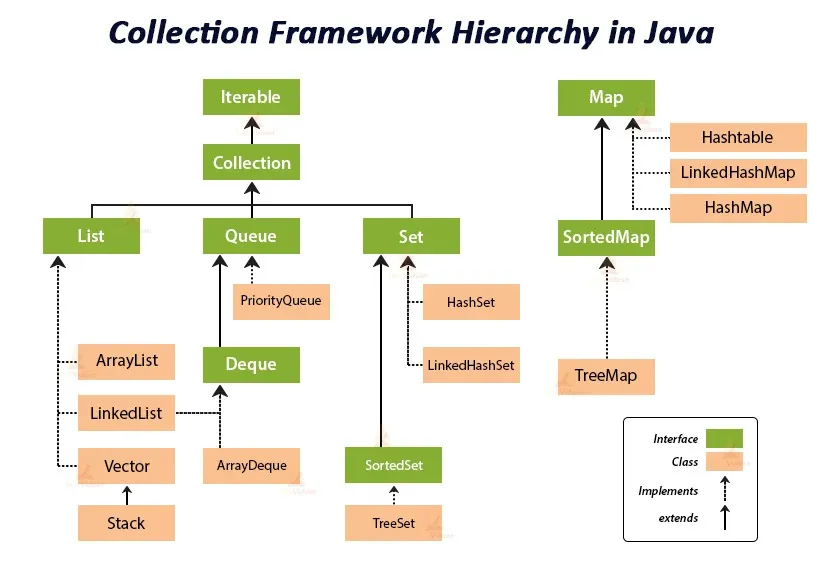
Мы начнем сверху и пойдем вниз, чтобы вы могли понять, что показывает эта диаграмма:
-
В основе Java Collections Framework находится интерфейс
Iterable, который позволяет вы выполнять итерацию по элементам коллекции. -
Интерфейс
Collectionрасширяет интерфейсIterable. Это означает, что он наследует свойства и поведение интерфейсаIterableи добавляет свое поведение для добавления, удаления и извлечения элементов. -
Специфические интерфейсы, такие как
List,SetиQueue, дополнительно расширяют интерфейсCollection. Каждый из этих интерфейсов имеет другие классы, реализующие их методы. Например,ArrayListявляется популярной реализацией интерфейсаList,HashSetреализует интерфейсSetи так далее. -
Интерфейс
Mapявляется частью Java Collections Framework, но он не расширяет интерфейсCollection, в отличие от других упомянутых выше. -
Все интерфейсы и классы в этом фреймворке являются частью пакета
java.util.
Примечание: Распространённым источником путаницы в Java Collections Framework является различие между Collection и Collections. Collection — это интерфейс в рамках фреймворка, в то время как Collections — это утилитный класс. Класс Collections предоставляет статические методы, которые выполняют операции над элементами коллекции.
Интерфейсы коллекций Java
Теперь вы знакомы с различными типами коллекций, которые составляют основу фреймворка коллекций. Теперь мы более подробно рассмотрим интерфейсы List, Set, Queue и Map.
В этом разделе мы обсудим каждый из этих интерфейсов, исследуя их внутренние механизмы. Мы рассмотрим, как они обрабатывают дубликаты и поддерживают ли вставку null значений. Мы также поймём порядок элементов при вставке и их поддержку синхронизации, которая связана с концепцией безопасности потоков. Затем мы пройдёмся по нескольким ключевым методам этих интерфейсов и завершим обзором общих реализаций и их производительности для различных операций.
Прежде чем начать, давайте кратко поговорим о синхронизации и производительности.
-
Синхронизация контролирует доступ к разделяемым объектам несколькими потоками, обеспечивая их целостность и предотвращая конфликты. Это крайне важно для поддержания безопасности потоков.
-
При выборе типа коллекции одним из важных факторов является его производительность при обычных операциях, таких как вставка, удаление и извлечение. Производительность обычно выражается с использованием нотации Big-O. Вы можете узнать больше об этом здесь.
Списки
Список является упорядоченной или последовательной коллекцией элементов. Он работает с индексами, начиная с нуля, что позволяет вставлять, удалять или получать доступ к элементам по их позиции в индексе.
-
Внутренний механизм: Список внутренне поддерживается либо массивом, либо связным списком, в зависимости от типа реализации. Например,
ArrayListиспользует массив, в то время какLinkedListвнутренне использует связанный список. Вы можете узнать больше оLinkedListздесь. Список автоматически изменяет свой размер при добавлении или удалении элементов. Получение элементов на основе индексов делает его очень эффективным типом коллекции. -
Дубликаты: Дублирующие элементы допускаются в
List, что означает, что вListможет быть несколько элементов с одинаковым значением. Любое значение можно извлечь на основе индекса, под которым оно хранится. -
Пустое значение: Пустые значения также допускаются в
List. Поскольку дубликаты разрешены, можно иметь несколько пустых элементов. -
Порядок: Список сохраняет порядок вставки, что означает, что элементы сохраняются в том же порядке, в котором они были добавлены. Это полезно, если вы хотите извлекать элементы в том же порядке, в котором они были вставлены.
-
Синхронизация:
Списокпо умолчанию не синхронизирован, что означает, что у него нет встроенного способа обработки доступа несколькими потоками одновременно. -
Ключевые методы: Вот некоторые ключевые методы интерфейса
List:add(E элемент),get(int индекс),set(int индекс, E элемент),remove(int индекс)иsize(). Давайте рассмотрим, как использовать эти методы на примере программы.import java.util.ArrayList; import java.util.List; public class ListExample { public static void main(String[] args) { // Создать список List<String> list = new ArrayList<>(); // add(E элемент) list.add("Яблоко"); list.add("Банан"); list.add("Вишня"); // get(int индекс) String secondElement = list.get(1); // "Банан" // set(int индекс, E элемент) list.set(1, "Голубика"); // remove(int индекс) list.remove(0); // Удаляет "Яблоко" // size() int size = list.size(); // 2 // Печать списка System.out.println(list); // Вывод: [Голубика, Вишня] // Печать размера списка System.out.println(size); // Вывод: 2 } } -
Общие реализации:
ArrayList,LinkedList,Vector,Stack -
Производительность: Обычно операции вставки и удаления быстры в
ArrayListиLinkedList. Но получение элементов может быть медленным, потому что приходится проходить через узлы.
| Операция | ArrayList | LinkedList |
| Вставка | Быстрая в конце – O(1) амортизированная, медленная в начале или середине – O(n) | Быстрая в начале или середине – O(1), медленная в конце – O(n) |
| Удаление | Быстрое в конце – O(1) амортизированное, медленное в начале или середине – O(n) | Быстрое – O(1) при известной позиции |
| Получение | Быстрое – O(1) для произвольного доступа | Медленное – O(n) для произвольного доступа, так как включает в себя проход через |
Множества
Set – это тип коллекции, который не позволяет дубликаты элементов и представляет собой концепцию математического множества.
-
Внутренний механизм:
Setвнутренне поддерживаетсяHashMap. В зависимости от типа реализации, это поддерживается либоHashMap,LinkedHashMap, либоTreeMap. Я написал подробную статью о том, как работаетHashMapвнутренне здесь. Обязательно ознакомьтесь с ней. -
Дубликаты: Поскольку
Setпредставляет собой концепцию математического множества, дублирующиеся элементы не допускаются. Это гарантирует, что все элементы уникальны, обеспечивая целостность коллекции. -
Null: Максимально допустимо одно значение null в
Set, поскольку дубликаты не допускаются. Но это не относится к реализацииTreeSet, где значение null вообще не допускается. -
Ordering: Порядок элементов в
Setзависит от типа реализации.-
HashSet: Порядок не гарантирован, элементы могут располагаться в любой позиции. -
LinkedHashSet: Данная реализация сохраняет порядок вставки, поэтому элементы можно извлечь в том же порядке, в котором они были вставлены. -
TreeSet: Элементы вставляются на основе их естественного порядка. В качестве альтернативы вы можете контролировать порядок вставки, указав пользовательский компаратор.
-
-
Синхронизация:
Setне синхронизирован, что означает возможность возникновения проблем с параллелизмом, таких как состояния гонки, которые могут повлиять на целостность данных, если два или более потока попытаются одновременно получить доступ к объектуSet -
Ключевые методы: Вот некоторые ключевые методы интерфейса
Set:add(E element),remove(Object o),contains(Object o)иsize(). Давайте посмотрим, как использовать эти методы на примере программы.import java.util.HashSet; import java.util.Set; public class SetExample { public static void main(String[] args) { // Создаем множество Set<String> set = new HashSet<>(); // Добавляем элементы в множество set.add("Яблоко"); set.add("Банан"); set.add("Вишня"); // Удаляем элемент из множества set.remove("Банан"); // Проверяем, содержит ли множество элемент boolean containsApple = set.contains("Яблоко"); System.out.println("Содержит яблоко: " + containsApple); // Получаем размер множества int size = set.size(); System.out.println("Размер множества: " + size); } } -
Общие реализации:
HashSet,LinkedHashSet,TreeSet -
Производительность: Реализации
Setобеспечивают быструю производительность для базовых операций, за исключениемTreeSet, где производительность может быть относительно медленнее, так как внутренняя структура данных включает сортировку элементов во время этих операций.
| Операция | HashSet | LinkedHashSet | TreeSet |
| Вставка | Быстро – O(1) | Быстро – O(1) | Медленнее – O(log n) |
| Удаление | Быстро – O(1) | Быстро – O(1) | Медленнее – O(log n) |
| Получение | Быстро – O(1) | Быстро – O(1) | Медленнее – O(log n) |
Очереди
Очередь – это линейная коллекция элементов, используемая для хранения нескольких элементов перед их обработкой, обычно следуя порядку FIFO (первым пришел – первым ушел). Это означает, что элементы добавляются с одного конца и удаляются с другого, поэтому первый добавленный в очередь элемент будет первым удаленным.
-
Внутренний механизм: Внутренние механизмы
Queueмогут различаться в зависимости от их конкретной реализации.-
LinkedList– использует двусвязный список для хранения элементов, что позволяет переходить как вперед, так и назад, обеспечивая гибкие операции. -
PriorityQueue– внутренне поддерживается бинарной кучей, что делает его очень эффективным для операций получения. -
ArrayDeque– реализован с использованием массива, который расширяется или сжимается при добавлении или удалении элементов. Здесь элементы могут добавляться или удаляться с обоих концов очереди.
-
-
Дубликаты: В
Очередиразрешены дублирующиеся элементы, что позволяет вставлять несколько экземпляров одного и того же значения. -
Ноль: Вы не можете вставить нулевое значение в
Очередь, потому что по дизайну некоторые методыОчередивозвращают null, чтобы указать, что она пуста. Чтобы избежать путаницы, нулевые значения не допускаются. -
Порядок: Элементы вставляются в соответствии с их естественным порядком. В качестве альтернативы вы можете контролировать порядок вставки, указав пользовательский компаратор.
-
Синхронизация:
Очередьпо умолчанию не синхронизирована. Но вы можете использовать реализациюConcurrentLinkedQueueилиBlockingQueueдля обеспечения безопасности потоков. -
Ключевые методы: Вот некоторые ключевые методы интерфейса
Queue:add(E element),offer(E element),poll()иpeek(). Давайте посмотрим, как использовать эти методы на примере программы.import java.util.LinkedList; import java.util.Queue; public class QueueExample { public static void main(String[] args) { // Создаем очередь, используя LinkedList Queue<String> queue = new LinkedList<>(); // Используем метод add для вставки элементов, выбрасывает исключение, если вставка не удалась queue.add("Element1"); queue.add("Element2"); queue.add("Element3"); // Используем метод offer для вставки элементов, возвращает false, если вставка не удалась queue.offer("Element4"); // Отображаем очередь System.out.println("Очередь: " + queue); // Заглянем в первый элемент (не удаляет его) String firstElement = queue.peek(); System.out.println("Peek: " + firstElement); // выводит "Element1" // Извлекаем первый элемент (получаем и удаляем его) String polledElement = queue.poll(); System.out.println("Poll: " + polledElement); // выводит "Element1" // Отображаем очередь после извлечения System.out.println("Очередь после извлечения: " + queue); } } -
Общие реализации:
LinkedList,PriorityQueue,ArrayDeque -
Производительность: Реализации, такие как
LinkedListиArrayDeque, обычно быстрые при добавлении и удалении элементов.PriorityQueueнемного медленнее, потому что вставляет элементы на основе заданного порядка приоритета.
| Операции | LinkedList | PriorityQueue | ArrayDeque |
| Вставка | Быстрая в начале или середине – O(1), медленная в конце – O(n) | Медленная – O(log n) | Быстрая – O(1), медленная – O(n), если требуется изменение размера внутреннего массива |
| Удаление | Быстрое – O(1), если известна позиция | Медленное – O(log n) | Быстрое – O(1), медленное – O(n), если требуется изменение размера внутреннего массива |
| Поиск | Медленный – O(n) для произвольного доступа, так как включает обход | Быстрый – O(1) | Быстрый – O(1) |
Отображения
Map представляет собой коллекцию пар ключ-значение, где каждый ключ отображается на одно значение. Хотя Map является частью Java Collection Framework, он не расширяет интерфейс java.util.Collection.
-
Внутренний механизм:
Mapработает внутренне с использованиемHashTableна основе концепции хэширования. Я написал подробную статью на эту тему, так что прочтите ее для более глубокого понимания. -
Дубликаты:
Mapхранит данные в виде пар ключ-значение. Здесь каждый ключ уникален, поэтому дубликаты ключей не допускаются. Однако допускаются дубликаты значений. -
Null: Поскольку дубликаты ключей не допускаются, в
Mapможет быть только один пустой ключ. Так как дубликаты значений допускаются, в нем могут быть несколько пустых значений. В реализацииTreeMapключи не могут быть пустыми, потому что элементы сортируются на основе ключей. Однако пустые значения допускаются. -
Упорядочивание: Порядок вставки в
Mapзависит от реализации:-
HashMap– порядок вставки не гарантируется, поскольку он определяется на основе хеширования. -
LinkedHashMap– порядок вставки сохраняется, и вы можете извлечь элементы в том же порядке, в котором они были добавлены в коллекцию. -
TreeMap– Элементы вставляются на основе их естественного порядка. Кроме того, можно управлять порядком вставки, указав пользовательский компаратор.
-
-
Синхронизация:
Mapне синхронизирован по умолчанию. Однако для обеспечения потокобезопасности можно использовать методыCollections.synchronizedMap()или реализацииConcurrentHashMap. -
Основные методы: Вот некоторые ключевые методы интерфейса
Map:put(K key, V value),get(Object key),remove(Object key),containsKey(Object key)иkeySet(). Давайте посмотрим, как использовать эти методы на примере программы.import java.util.HashMap; import java.util.Map; import java.util.Set; public class MapMethodsExample { public static void main(String[] args) { // Создаем новый HashMap Map<String, Integer> map = new HashMap<>(); // put(K key, V value) - Вставляет пары ключ-значение в карту map.put("Apple", 1); map.put("Banana", 2); map.put("Orange", 3); // get(Object key) - Возвращает значение, связанное с ключом Integer value = map.get("Banana"); System.out.println("Значение для 'Banana': " + value); // remove(Object key) - Удаляет пару ключ-значение для указанного ключа map.remove("Orange"); // containsKey(Object key) - Проверяет, содержит ли карта указанный ключ boolean hasApple = map.containsKey("Apple"); System.out.println("Содержит 'Apple': " + hasApple); // keySet() - Возвращает представление набора ключей, содержащихся в карте Set<String> keys = map.keySet(); System.out.println("Ключи в карте: " + keys); } } -
Общие реализации:
HashMap,LinkedHashMap,TreeMap,Hashtable,ConcurrentHashMap -
Производительность: Реализация
HashMapшироко используется в основном из-за ее эффективных характеристик производительности, изображенных в таблице ниже.
| Операция | HashMap | LinkedHashMap | TreeMap |
| Вставка | Быстро – O(1) | Быстро – O(1) | Медленно – O(log n) |
| Удаление | Быстро – O(1) | Быстро – O(1) | Медленно – O(log n) |
| Поиск | Быстро – O(1) | Быстро – O(1) | Медленно – O(log n) |
Класс Collections Utility
Как было отмечено в начале этой статьи, у класса утилит Collections есть несколько полезных статических методов, которые позволяют выполнять часто используемые операции над элементами коллекции. Эти методы помогают уменьшить шаблонный код в вашем приложении и позволяют сосредоточиться на бизнес-логике.
Вот несколько ключевых функций и методов, вместе с их кратким описанием:
-
Сортировка:
Collections.sort(List<T>)– этот метод используется для сортировки элементов списка в порядке возрастания. -
Поиск:
Collections.binarySearch(List<T>, key)– этот метод используется для поиска конкретного элемента в отсортированном списке и возврата его индекса. -
Обратный порядок:
Collections.reverse(List<T>)– этот метод используется для изменения порядка элементов в списке на обратный. -
Операции Min/Max:
Collections.min(Collection<T>)иCollections.max(Collection<T>)– эти методы используются для поиска минимальных и максимальных элементов в коллекции соответственно. -
Синхронизация:
Collections.synchronizedList(List<T>)– этот метод используется для обеспечения потокобезопасности списка путем его синхронизации. -
Неизменяемые коллекции:
Collections.unmodifiableList(List<T>)– этот метод используется для создания только для чтения представления списка, предотвращая изменения.
Вот пример программы на Java, которая демонстрирует различные функции класса Collections:
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class CollectionsExample {
public static void main(String[] args) {
List<Integer> numbers = new ArrayList<>();
numbers.add(5);
numbers.add(3);
numbers.add(8);
numbers.add(1);
// Сортировка
Collections.sort(numbers);
System.out.println("Sorted List: " + numbers);
// Поиск
int index = Collections.binarySearch(numbers, 3);
System.out.println("Index of 3: " + index);
// Обратный порядок
Collections.reverse(numbers);
System.out.println("Reversed List: " + numbers);
// Операции Min/Max
int min = Collections.min(numbers);
int max = Collections.max(numbers);
System.out.println("Min: " + min + ", Max: " + max);
// Синхронизация
List<Integer> synchronizedList = Collections.synchronizedList(numbers);
System.out.println("Synchronized List: " + synchronizedList);
// Неизменяемые коллекции
List<Integer> unmodifiableList = Collections.unmodifiableList(numbers);
System.out.println("Unmodifiable List: " + unmodifiableList);
}
}
Эта программа демонстрирует сортировку, поиск, обращение, нахождение минимальных и максимальных значений, синхронизацию и создание неизменяемого списка с использованием класса Collections.
Заключение
В этой статье вы узнали о Java Collections Framework и о том, как он помогает управлять группами объектов в приложениях на Java. Мы исследовали различные типы коллекций, такие как списки, множества, очереди и карты, и получили представление о некоторых ключевых характеристиках и о том, как каждый из этих типов их поддерживает.
Вы узнали о производительности, синхронизации и ключевых методах, получив ценные знания о выборе правильных структур данных для ваших нужд.
Понимая эти концепции, вы сможете в полной мере использовать Java Collections Framework, что позволит вам писать более эффективный код и создавать надежные приложения.
Если вам понравилась эта статья, не стесняйтесь ознакомиться с моими другими статьями на freeCodeCamp и связаться со мной в LinkedIn.
Source:
https://www.freecodecamp.org/news/java-collections-framework-reference-guide/