













Javaのアプリケーションでは、通常、さまざまなタイプのオブジェクトを扱います。そして、これらのオブジェクトに対してソート、検索、反復処理などの操作を行いたい場合があります。
JDK 1.2でのCollectionsフレームワークの導入以前は、オブジェクトのグループを保存および管理するためにArraysやVectorsを使用していましたが、それらにはそれぞれ欠点がありました。
Java Collections Frameworkは、一般的なデータ構造の高性能な実装を提供することで、これらの問題を克服しようとしています。これにより、低レベルの操作に集中するのではなく、アプリケーションロジックの記述に集中できます。
その後、JDK 1.5でのGenericsの導入により、Java Collections Frameworkが大幅に改善されました。Genericsを使用すると、コレクション内に格納されるオブジェクトの型安全性を強制できるため、アプリケーションの堅牢性が向上します。Java Genericsについて詳しくはこちらを参照してください。
この記事では、Java Collections Frameworkの使用方法について説明します。リスト、セット、キュー、マップなど、さまざまな種類のコレクションについて、その主な特性について簡単に説明します:
-
内部メカニズム
-
重複の処理
-
null値のサポート
-
順序付け
-
同期
-
パフォーマンス
-
主要なメソッド
-
一般的な実装
理解を深めるために、いくつかのコード例を紹介し、Collectionsユーティリティクラスとその使用方法に触れます。
目次:
Javaコレクションフレームワークの理解
Javaのドキュメントによると、「コレクションはオブジェクトのグループを表すオブジェクトです。コレクションフレームワークはコレクションを表現および操作するための統一されたアーキテクチャです。」
簡単に言えば、Javaコレクションフレームワークはオブジェクトのグループを効率的かつ整然に操作するのを支援します。さまざまなメソッドを提供することで、オブジェクトのグループを処理するのが簡単になり、アプリケーションを開発しやすくなります。Javaコレクションフレームワークを使用して、オブジェクトを効果的に追加、削除、検索、およびソートすることができます。
コレクションインターフェース
Javaでは、インターフェースは実装するクラスが満たさなければならない契約を指定します。つまり、実装クラスはインターフェースで宣言されたすべてのメソッドについて具体的な実装を提供しなければなりません。
Javaコレクションフレームワークでは、Set、List、QueueなどのさまざまなコレクションインターフェースがCollectionインターフェースを拡張し、Collectionインターフェースによって定義された契約に従う必要があります。
Javaコレクションフレームワークの階層を解読する
こちらの記事からの素敵な図を見て、Javaコレクションの階層を示しています:
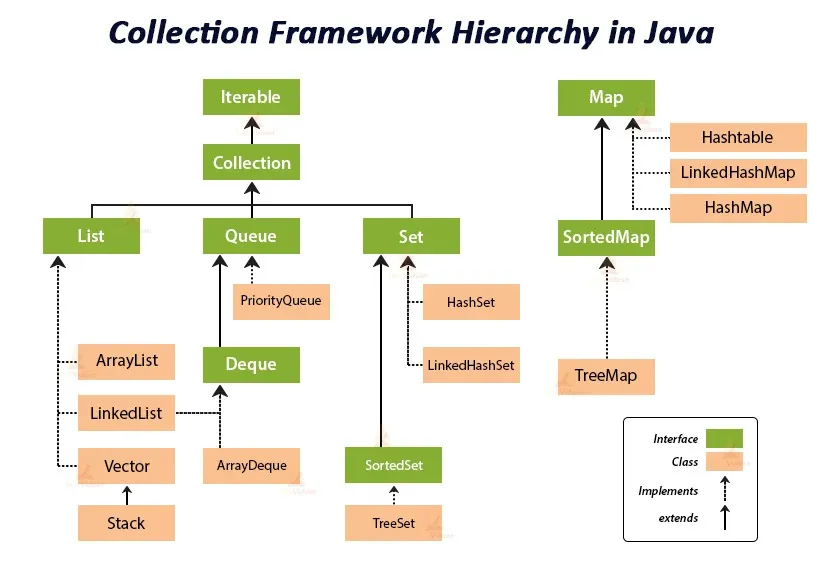
上から下に進んで、この図が何を示しているのかを理解していきましょう:
-
Javaコレクションフレームワークのルートには、コレクションの要素を反復処理できる
Iterableインターフェースがあります。 -
CollectionインターフェースはIterableインターフェースを拡張します。これは、Iterableインターフェースのプロパティと動作を継承し、要素の追加、削除、および取得のための独自の動作を追加することを意味します。 -
特定のインターフェース、例えば
List、Set、およびQueueは、Collectionインターフェースをさらに拡張しています。これらのインターフェースごとに、そのメソッドを実装する他のクラスがあります。例えば、ArrayListはListインターフェースの人気のある実装であり、HashSetはSetインターフェースを実装しています。 -
MapインターフェースはJavaコレクションフレームワークの一部ですが、他のインターフェースとは異なり、Collectionインターフェースを拡張していません。 -
このフレームワークのすべてのインターフェースとクラスは
java.utilパッケージの一部です。
注意: Javaコレクションフレームワークでの一般的な混乱の原因は、CollectionとCollectionsの違いに関するものです。Collectionはフレームワーク内のインターフェースであり、Collectionsはユーティリティクラスです。Collectionsクラスは、コレクションの要素に対して操作を実行する静的メソッドを提供します。
Javaコレクションインタフェース
これまでに、コレクションフレームワークの基盤を形成するさまざまな種類のコレクションについてお馴染みになりました。今度は、List、Set、Queue、およびMapインタフェースを詳しく見ていきます。
このセクションでは、これらのインタフェースそれぞれについて、内部メカニズムを探りながら議論していきます。重複要素の扱い方やnull値の挿入のサポートについて検討します。また、挿入時の要素の順序や同期のサポートについて理解します。同期はスレッドセーフティの概念に関わるため、重要です。その後、これらのインタフェースのいくつかの主要なメソッドを解説し、さまざまな操作に対する一般的な実装とパフォーマンスを見直します。
始める前に、同期とパフォーマンスについて簡単に話し合いましょう。
-
同期は、複数のスレッドによる共有オブジェクトへのアクセスを制御し、それらの整合性を保ち、競合を防ぐものです。これはスレッドセーフティを維持するために重要です。
-
コレクションタイプを選択する際の重要な要素の1つは、挿入、削除、および検索などの一般的な操作中のパフォーマンスです。パフォーマンスは通常、Big-O表記を使用して表されます。詳細はこちらで学ぶことができます。
リスト
Listは要素の順序付きまたは順次のコレクションです。要素は0から始まるインデックスを使用して挿入、削除、またはアクセスが可能です。
-
内部メカニズム:
Listは、実装のタイプに応じて、内部的に配列またはリンクドリストによってサポートされています。例えば、ArrayListは配列を使用し、LinkedListは内部的にリンクドリストを使用しています。LinkedListについて詳しくはこちらを参照してください。Listは、要素の追加や削除に応じて自動的にサイズを調整します。インデックスベースの検索は、非常に効率的なコレクションタイプとなります。 -
重複:
Listでは重複した要素が許可されるため、同じ値を持つ複数の要素がList内に存在することができます。格納されたインデックスに基づいて任意の値を取得できます。 -
Null:
ListではNull値も許可されています。重複が許可されているため、複数のNull要素を持つこともできます。 -
順序:
Listは挿入順序を維持し、要素が追加された順序で格納されます。要素を追加された順序で正確に取得したい場合に役立ちます。 -
同期:
Listはデフォルトでは同期されておらず、これは同時に複数のスレッドによるアクセスを処理するための組み込みの方法がないことを意味します。 -
主要なメソッド: ここでは、
Listインターフェースの主要なメソッドをいくつか紹介します:add(E element),get(int index),set(int index, E element),remove(int index), およびsize()。これらのメソッドの使用法を例プログラムで見てみましょう。import java.util.ArrayList; import java.util.List; public class ListExample { public static void main(String[] args) { // リストを作成 List<String> list = new ArrayList<>(); // add(E element) list.add("Apple"); list.add("Banana"); list.add("Cherry"); // get(int index) String secondElement = list.get(1); // "Banana" // set(int index, E element) list.set(1, "Blueberry"); // remove(int index) list.remove(0); // "Apple"を削除 // size() int size = list.size(); // 2 // リストを印刷 System.out.println(list); // 出力: [Blueberry, Cherry] // リストのサイズを印刷 System.out.println(size); // 出力: 2 } } -
一般的な実装:
ArrayList,LinkedList,Vector,Stack -
パフォーマンス: 通常、
ArrayListとLinkedListの挿入および削除操作は速いです。ただし、要素の取得は遅い場合があります。なぜなら、ノードをトラバースする必要があるからです。
| 操作 | ArrayList | LinkedList |
| 挿入 | 末尾で速い – O(1)(償却)、先頭や中間では遅い – O(n) | 先頭や中間で速い – O(1)、末尾では遅い – O(n) |
| 削除 | 末尾で速い – O(1)(償却)、先頭や中間では遅い – O(n) | 速い – 位置が既知の場合はO(1) |
| 検索 | 速い – ランダムアクセス時にはO(1) | 遅い – ランダムアクセス時にはO(n)、トラバースが必要 |
セット
Setは、重複する要素を許可せず、数学的な集合の概念を表すコレクションの一種です。
-
内部メカニズム:
Setは内部的にHashMapによって支えられています。実装タイプによって、HashMap、LinkedHashMap、またはTreeMapのいずれかがサポートされています。HashMapが内部でどのように機能するかについての詳細な記事をこちらに書きました。ぜひご覧ください。 -
重複:
Setは数学的な集合の概念を表すため、重複する要素は許可されていません。これにより、すべての要素がユニークであり、コレクションの整合性が維持されます。 -
Null:
Set内には1つのnull値しか許可されず、重複は許可されていません。ただし、TreeSetの実装ではnull値は一切許可されません。 -
Ordering:
Set内の要素の順序は実装の種類に依存します。-
HashSet: 順序は保証されず、要素は任意の位置に配置される可能性があります。 -
LinkedHashSet: この実装は挿入順序を維持するため、挿入された順序で要素を取得できます。 -
TreeSet: 要素は自然な順序に基づいて挿入されます。また、カスタム比較子を指定することで挿入順序を制御することもできます。
-
-
Synchronization:
Setは同期されていません。つまり、複数のスレッドが同時にSetオブジェクトにアクセスしようとすると競合状態のような並行性の問題が発生する可能性があり、データの整合性に影響を及ぼす可能性があります。 -
主なメソッド: ここでは、
Setインターフェースのいくつかの主なメソッドを紹介します:add(E element),remove(Object o),contains(Object o), およびsize()。これらのメソッドを使用する方法を例のプログラムで見てみましょう。import java.util.HashSet; import java.util.Set; public class SetExample { public static void main(String[] args) { // セットを作成する Set<String> set = new HashSet<>(); // セットに要素を追加する set.add("Apple"); set.add("Banana"); set.add("Cherry"); // セットから要素を削除する set.remove("Banana"); // セットに要素が含まれているか確認する boolean containsApple = set.contains("Apple"); System.out.println("Contains Apple: " + containsApple); // セットのサイズを取得する int size = set.size(); System.out.println("Size of the set: " + size); } } -
一般的な実装:
HashSet,LinkedHashSet,TreeSet -
パフォーマンス: 基本的な操作において
Setの実装は高速ですが、TreeSetの場合は内部のデータ構造が要素をソートするため、比較的遅い場合があります。
| 操作 | HashSet | LinkedHashSet | TreeSet |
| 挿入 | 高速 – O(1) | 高速 – O(1) | 遅い – O(log n) |
| 削除 | 高速 – O(1) | 高速 – O(1) | 遅い – O(log n) |
| 取得 | 高速 – O(1) | 高速 – O(1) | 遅い – O(log n) |
キュー
Queueは、複数のアイテムを処理前に保持するために使用される要素の線形コレクションです。通常、FIFO(先入れ先出し)の順序に従います。これは、要素が一方の端に追加され、他方から削除されることを意味し、したがって、キューに追加された最初の要素が最初に削除されます。
-
内部メカニズム:
Queueの内部動作は、その特定の実装に基づいて異なることがあります。-
LinkedList– 要素を格納するために双方向リンクリストを使用し、前方および後方の両方向に移動できるため、柔軟な操作が可能です。 -
PriorityQueue– 内部的にはバイナリヒープで支えられており、取得操作に非常に効率的です。 -
ArrayDeque– 要素が追加または削除されると配列が拡張または縮小されます。ここでは、キューの両端から要素を追加または削除できます。
-
-
重複:
Queueでは、重複した要素を許可し、同じ値の複数のインスタンスを挿入できます -
Null:
Queueに null 値を挿入することはできません。なぜなら、Queueの一部のメソッドが空であることを示すために null を返すためです。混乱を避けるため、null 値は許可されていません。 -
順序: 要素はその自然な順序に基づいて挿入されます。あるいは、カスタムコンパレータを指定することで挿入順序を制御することもできます。
-
同期:
Queueはデフォルトでは同期されていません。しかし、スレッドセーフを実現するために、ConcurrentLinkedQueueやBlockingQueueの実装を使用することができます。 -
主なメソッド:
Queueインターフェースの主なメソッドには、add(E element)、offer(E element)、poll()、およびpeek()があります。これらのメソッドを例のプログラムでどのように使用するかを見てみましょう。import java.util.LinkedList; import java.util.Queue; public class QueueExample { public static void main(String[] args) { // LinkedListを使用してキューを作成 Queue<String> queue = new LinkedList<>(); // 要素を挿入するためにaddメソッドを使用し、挿入に失敗した場合は例外をスロー queue.add("Element1"); queue.add("Element2"); queue.add("Element3"); // 要素を挿入するためにofferメソッドを使用し、挿入に失敗した場合はfalseを返す queue.offer("Element4"); // キューを表示 System.out.println("Queue: " + queue); // 最初の要素を覗く(削除はされない) String firstElement = queue.peek(); System.out.println("Peek: " + firstElement); // 出力は "Element1" // 最初の要素を取得して削除する String polledElement = queue.poll(); System.out.println("Poll: " + polledElement); // 出力は "Element1" // Poll後のキューを表示 System.out.println("Queue after poll: " + queue); } } -
一般的な実装:
LinkedList,PriorityQueue,ArrayDeque -
パフォーマンス:
LinkedListやArrayDequeのような実装は通常、アイテムの追加や削除が速いです。PriorityQueueは優先順位に基づいてアイテムを挿入するため、やや遅いです。
| 操作 | LinkedList | PriorityQueue | ArrayDeque |
| 挿入 | 最初や中間部分では高速 – O(1)、末尾では遅い – O(n) | 遅い – O(log n) | 高速 – O(1)、遅い – O(n)、内部配列のリサイズが必要な場合 |
| 削除 | 高速 – 位置が既知の場合はO(1) | 遅い – O(log n) | 高速 – O(1)、遅い – O(n)、内部配列のリサイズが必要な場合 |
| 取得 | ランダムアクセスの場合は遅い – O(n)、トラバースが必要 | 高速 – O(1) | 高速 – O(1) |
マップ
Mapは、各キーが単一の値にマッピングされるキー値ペアのコレクションを表します。 Map はJava Collectionフレームワークの一部ですが、java.util.Collection インターフェースを拡張していません。
-
内部メカニズム:
Mapは、ハッシュ法の概念に基づいたHashTableを使用して内部的に機能します。このトピックについて詳細な記事を書いているので、深く理解するために読んでみてください。 -
重複:
Mapはデータをキーと値のペアとして保存します。ここでは、各キーが一意であるため、重複するキーは許可されません。ただし、重複する値は許可されます。 -
Null: 重複するキーを許可しないため、
Mapには1つだけnullキーを持つことができます。重複する値が許可されるため、複数のnull値を持つことができます。TreeMapの実装では、キーを基準に要素をソートするため、キーをnullにすることはできません。ただし、null値は許可されます。 -
順序:
Mapの挿入順序は実装によって異なります:-
HashMap– 挿入順序はハッシングの概念に基づいて決定されるため、保証されません。 -
LinkedHashMap– 挿入順序が保存され、要素を追加された順序で取得することができます。 -
TreeMap– 要素は自然な順序に基づいて挿入されます。また、カスタムコンパレータを指定することで挿入順序を制御することもできます。
-
-
同期:
Mapはデフォルトでは同期化されません。ただし、Collections.synchronizedMap()またはConcurrentHashMapの実装を使用してスレッドセーフを実現することができます。 -
主なメソッド: 以下は
Mapインターフェースの主なメソッドです:put(K key, V value),get(Object key),remove(Object key),containsKey(Object key), およびkeySet()。これらのメソッドを例題プログラムでどのように使用するかを見ていきましょう。import java.util.HashMap; import java.util.Map; import java.util.Set; public class MapMethodsExample { public static void main(String[] args) { // 新しいHashMapを作成 Map<String, Integer> map = new HashMap<>(); // put(K key, V value) - キーと値のペアをマップに挿入 map.put("Apple", 1); map.put("Banana", 2); map.put("Orange", 3); // get(Object key) - キーに関連付けられた値を返す Integer value = map.get("Banana"); System.out.println("'Banana'の値: " + value); // remove(Object key) - 指定されたキーのキーと値のペアを削除 map.remove("Orange"); // containsKey(Object key) - マップが指定されたキーを含むかどうかをチェック boolean hasApple = map.containsKey("Apple"); System.out.println("'Apple'を含む: " + hasApple); // keySet() - マップに含まれるキーのセットビューを返す Set<String> keys = map.keySet(); System.out.println("マップ内のキー: " + keys); } } -
一般的な実装:
HashMap,LinkedHashMap,TreeMap,Hashtable,ConcurrentHashMap -
パフォーマンス:
HashMapの実装は、以下の表に示される効率的なパフォーマンス特性を主に理由として広く使用されています。
| 操作 | HashMap | LinkedHashMap | TreeMap |
| 挿入 | 高速 – O(1) | 高速 – O(1) | 遅い – O(log n) |
| 削除 | 高速 – O(1) | 高速 – O(1) | 遅い – O(log n) |
| 取得 | 高速 – O(1) | 高速 – O(1) | 遅い – O(log n) |
コレクションユーティリティクラス
この記事の冒頭で強調されているように、Collections ユーティリティクラスには、コレクションの要素に対して一般的に使用される操作を実行するためのいくつかの便利な静的メソッドがあります。これらのメソッドは、アプリケーション内の冗長なコードを削減し、ビジネスロジックに集中できるようにします。
以下は、いくつかの主要な機能とメソッド、およびそれらが行う内容が簡潔にリストアップされています:
-
ソート:
Collections.sort(List<T>)– このメソッドはリストの要素を昇順でソートするために使用されます。 -
検索:
Collections.binarySearch(List<T>, key)– このメソッドは、ソートされたリスト内の特定の要素を検索してそのインデックスを返すために使用されます。 -
逆順:
Collections.reverse(List<T>)– このメソッドはリスト内の要素の順序を逆にするために使用されます。 -
最小/最大操作:
Collections.min(Collection<T>)およびCollections.max(Collection<T>)– これらのメソッドは、それぞれコレクション内の最小および最大の要素を見つけるために使用されます。 -
同期化:
Collections.synchronizedList(List<T>)– このメソッドは、リストをスレッドセーフにするために使用されます。 -
変更不可能なコレクション:
Collections.unmodifiableList(List<T>)– このメソッドはリストの読み取り専用ビューを作成し、変更を防ぎます。
以下は、Collectionsユーティリティクラスのさまざまな機能をデモンストレーションするサンプルJavaプログラムです。
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class CollectionsExample {
public static void main(String[] args) {
List<Integer> numbers = new ArrayList<>();
numbers.add(5);
numbers.add(3);
numbers.add(8);
numbers.add(1);
// ソート
Collections.sort(numbers);
System.out.println("Sorted List: " + numbers);
// 検索
int index = Collections.binarySearch(numbers, 3);
System.out.println("Index of 3: " + index);
// 逆順
Collections.reverse(numbers);
System.out.println("Reversed List: " + numbers);
// 最小/最大操作
int min = Collections.min(numbers);
int max = Collections.max(numbers);
System.out.println("Min: " + min + ", Max: " + max);
// 同期
List<Integer> synchronizedList = Collections.synchronizedList(numbers);
System.out.println("Synchronized List: " + synchronizedList);
// 変更不可能なコレクション
List<Integer> unmodifiableList = Collections.unmodifiableList(numbers);
System.out.println("Unmodifiable List: " + unmodifiableList);
}
}
このプログラムでは、ソート、検索、逆順、最小値および最大値の検出、同期、Collectionsユーティリティクラスを使用した変更不可能なリストの作成などをデモンストレーションしています。
結論
この記事では、Javaコレクションフレームワークについて学び、Javaアプリケーション内のオブジェクトグループを管理する方法について紹介しました。リスト、セット、キュー、マップなどのさまざまなコレクションタイプ、およびそれらのキー特性と各タイプがそれらをサポートする方法について探求しました。
パフォーマンス、同期、および主要メソッドについて学び、ニーズに適したデータ構造を選択するための貴重な知識を得ました。
これらの概念を理解することで、Javaコレクションフレームワークを十分に活用し、効率的なコードを書き、堅牢なアプリケーションを構築することができます。
この記事が興味深いと感じたら、freeCodeCampの他の記事もチェックして、LinkedInでつながりましょう。
Source:
https://www.freecodecamp.org/news/java-collections-framework-reference-guide/