













Nelle tue applicazioni Java, lavorerai tipicamente con vari tipi di oggetti. E potresti voler eseguire operazioni come ordinamento, ricerca e iterazione su questi oggetti.
Prima dell’introduzione del framework Collections in JDK 1.2, avresti utilizzato Arrays e Vettori per memorizzare e gestire un gruppo di oggetti. Ma avevano le loro problematiche.
Il Java Collections Framework mira a superare questi problemi fornendo implementazioni ad alte prestazioni di strutture dati comuni. Queste ti consentono di concentrarti sulla scrittura della logica applicativa invece di concentrarti su operazioni a basso livello.
Poi, l’introduzione dei Generics in JDK 1.5 ha migliorato significativamente il Java Collections Framework. I Generics ti permettono di imporre la sicurezza dei tipi per gli oggetti memorizzati in una collezione, il che aumenta la robustezza delle tue applicazioni. Puoi leggere di più sui Generics di Java qui.
In questo articolo, ti guiderò su come utilizzare il Java Collections Framework. Discuteremo i diversi tipi di collezioni, come Liste, Insiemi, Code e Mappe. Fornirò anche una breve spiegazione delle loro caratteristiche chiave come:
-
Meccanismi interni
-
Gestione dei duplicati
-
Supporto per valori nulli
-
Ordinamento
-
Sincronizzazione
-
Prestazioni
-
Metodi chiave
-
Implementazioni comuni
Esploreremo anche alcuni esempi di codice per una migliore comprensione e toccherò la classe utility Collections e il suo utilizzo.
Indice:
Comprensione del framework delle collezioni Java
Secondo la documentazione di Java, “Una collezione è un oggetto che rappresenta un gruppo di oggetti. Un framework delle collezioni è un’architettura unificata per rappresentare e manipolare collezioni.”
In termini semplici, il framework delle collezioni di Java ti aiuta a gestire un gruppo di oggetti e a eseguire operazioni su di essi in modo efficiente e organizzato. Rende più facile lo sviluppo di applicazioni offrendo vari metodi per gestire gruppi di oggetti. Puoi aggiungere, rimuovere, cercare e ordinare gli oggetti in modo efficace utilizzando il framework delle collezioni di Java.
Interfacce delle collezioni
In Java, un’interfaccia specifica un contratto che deve essere rispettato da qualsiasi classe che la implementa. Questo significa che la classe che implementa deve fornire implementazioni concrete per tutti i metodi dichiarati nell’interfaccia.
Nel Java Collections Framework, varie interfacce di raccolta come Set, List e Queue estendono l’interfaccia Collection, e devono aderire al contratto definito dall’interfaccia Collection.
Decodifica della gerarchia del Java Collections Framework
Guarda questo bel diagramma tratto da questo articolo che illustra la gerarchia delle collezioni Java:
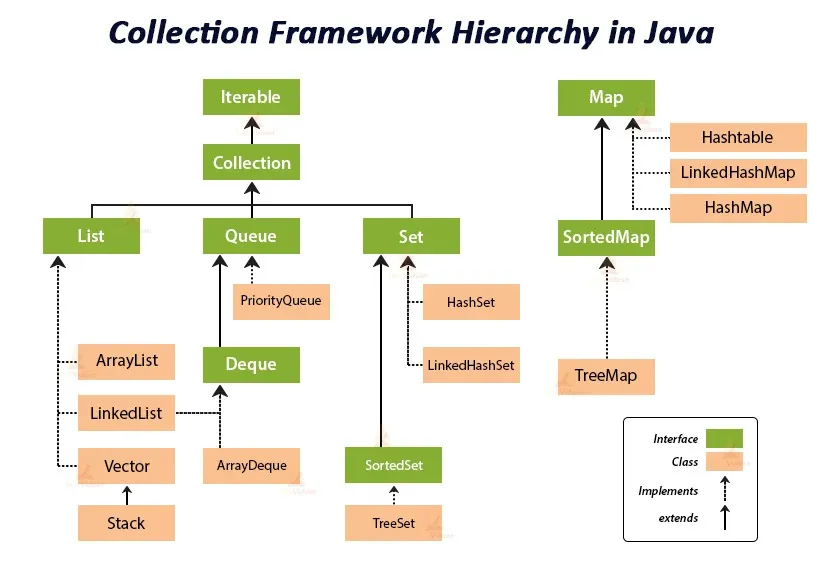
Inizieremo dalla cima e lavoreremo verso il basso in modo che tu possa capire cosa mostra questo diagramma:
-
Alla radice del Java Collections Framework c’è l’interfaccia
Iterable, che ti consente di iterare sugli elementi di una raccolta. -
L’interfaccia
Collectionestende l’interfacciaIterable. Questo significa che eredita le proprietà e il comportamento dell’interfacciaIterablee aggiunge il proprio comportamento per aggiungere, rimuovere e recuperare elementi. -
Interfacce specifiche come
List,SeteQueueestendono ulteriormente l’interfacciaCollection. Ognuna di queste interfacce ha altre classi che implementano i loro metodi. Ad esempio,ArrayListè un’implementazione popolare dell’interfacciaList,HashSetimplementa l’interfacciaSet, e così via. -
L’interfaccia
Mapfa parte del Framework delle Collezioni di Java, ma non estende l’interfacciaCollection, a differenza delle altre menzionate in precedenza. -
Tutte le interfacce e le classi in questo framework fanno parte del pacchetto
java.util.
Nota: Una fonte comune di confusione nel Java Collections Framework ruota attorno alla differenza tra Collection e Collections. Collection è un’interfaccia nel framework, mentre Collections è una classe di utilità. La classe Collections fornisce metodi statici che eseguono operazioni sugli elementi di una collezione.
Interfacce delle Collezioni Java
Adesso sei familiare con i diversi tipi di collezioni che costituiscono la base del framework delle collezioni. Ora daremo un’occhiata più da vicino alle interfacce List, Set, Queue, e Map.
In questa sezione, discuteremo ciascuna di queste interfacce esplorando i loro meccanismi interni. Esamineremo come gestiscono gli elementi duplicati e se supportano l’inserimento di valori null. Comprenderemo anche l’ordinamento degli elementi durante l’inserimento e il loro supporto alla sincronizzazione, che tratta il concetto di sicurezza dei thread. Poi passeremo in rassegna alcuni metodi chiave di queste interfacce e concluderemo esaminando le implementazioni comuni e le loro prestazioni per varie operazioni.
Prima di iniziare, parliamo brevemente di Sincronizzazione e Prestazioni.
-
La sincronizzazione controlla l’accesso agli oggetti condivisi da parte di thread multipli, garantendo la loro integrità e prevenendo conflitti. Questo è cruciale per mantenere la sicurezza dei thread.
-
Quando si sceglie un tipo di raccolta, un fattore importante è la sua performance durante le operazioni comuni come l’inserimento, la cancellazione e il recupero. La performance è generalmente espressa utilizzando la notazione Big-O. Puoi saperne di più qui.
Liste
Una List è una raccolta ordinata o sequenziale di elementi. Segue un’indicizzazione a base zero, che consente di inserire, rimuovere o accedere agli elementi utilizzando la loro posizione nell’indice.
-
Mechanismo interno: Una
Listè supportata internamente da un array o da una lista concatenata, a seconda del tipo di implementazione. Ad esempio, unArrayListutilizza un array, mentre unLinkedListutilizza una lista concatenata internamente. Puoi leggere di più suLinkedListqui. UnaListridimensiona dinamicamente se stessa all’aggiunta o alla rimozione degli elementi. Il recupero basato sull’indicizzazione lo rende un tipo di collezione molto efficiente. -
Duplicati: Gli elementi duplicati sono ammessi in una
List, il che significa che possono esserci più elementi con lo stesso valore in unaList. Qualsiasi valore può essere recuperato in base all’indice in cui è memorizzato. -
Valore Null: Anche i valori Null sono ammessi in una
List. Poiché i duplicati sono consentiti, è possibile avere anche più elementi Null. -
Ordinamento: Una
Listmantiene l’ordine di inserimento, il che significa che gli elementi sono memorizzati nello stesso ordine in cui sono stati aggiunti. Questo è utile quando si desidera recuperare gli elementi nell’ordine esatto in cui sono stati inseriti. -
Sincronizzazione: Una
Listanon è sincronizzata per impostazione predefinita, il che significa che non ha un modo integrato per gestire l’accesso da parte di più thread contemporaneamente. -
Metodi chiave: Ecco alcuni metodi chiave di un’interfaccia
List:add(E elemento),get(int indice),set(int indice, E elemento),remove(int indice)esize(). Vediamo come utilizzare questi metodi con un esempio di programma.import java.util.ArrayList; import java.util.List; public class EsempioLista { public static void main(String[] args) { // Creare una lista List<String> lista = new ArrayList<>(); // add(E elemento) lista.add("Mela"); lista.add("Banana"); lista.add("Ciliegia"); // get(int indice) String secondoElemento = lista.get(1); // "Banana" // set(int indice, E elemento) lista.set(1, "Mirtillo"); // remove(int indice) lista.remove(0); // Rimuove "Mela" // size() int dimensione = lista.size(); // 2 // Stampare la lista System.out.println(lista); // Output: [Mirtillo, Ciliegia] // Stampare la dimensione della lista System.out.println(dimensione); // Output: 2 } } -
Implementazioni comuni:
ArrayList,LinkedList,Vector,Stack -
Performance: Tipicamente, le operazioni di inserimento e cancellazione sono veloci sia in
ArrayListche inLinkedList. Ma il recupero degli elementi può essere lento poiché è necessario attraversare i nodi.
| Operazione | ArrayList | LinkedList |
| Inserimento | Veloce alla fine – O(1) ammortizzato, lento all’inizio o in mezzo – O(n) | Veloce all’inizio o in mezzo – O(1), lento alla fine – O(n) |
| Cancellazione | Veloce alla fine – O(1) ammortizzato, lento all’inizio o in mezzo – O(n) | Veloce – O(1) se la posizione è nota |
| Ricerca | Veloce – O(1) per l’accesso casuale | Lento – O(n) per l’accesso casuale, poiché comporta un attraversamento |
Insiemi
Un Set è un tipo di collezione che non consente elementi duplicati e rappresenta il concetto di un insieme matematico.
-
Mecanismo interno: Un
Setè internamente supportato da unHashMap. A seconda del tipo di implementazione, è supportato da unHashMap,LinkedHashMap, o unTreeMap. Ho scritto un articolo dettagliato su come funziona internamenteHashMapqui. Assicurati di darci un’occhiata. -
Duplicati: Poiché un
Setrappresenta il concetto di un insieme matematico, gli elementi duplicati non sono ammessi. Ciò garantisce che tutti gli elementi siano unici, mantenendo l’integrità della collezione. -
Null: È consentito un massimo di un valore nullo in un
Setperché i duplicati non sono ammessi. Ma questo non si applica all’implementazioneTreeSet, dove i valori nulli non sono affatto consentiti. -
Ordinamento: L’ordinamento degli elementi in un
Setdipende dal tipo di implementazione.-
HashSet: L’ordine non è garantito e gli elementi possono essere collocati in qualsiasi posizione. -
LinkedHashSet: Questa implementazione mantiene l’ordine di inserimento, quindi puoi recuperare gli elementi nello stesso ordine in cui sono stati inseriti. -
TreeSet: Gli elementi vengono inseriti in base al loro ordine naturale. In alternativa, puoi controllare l’ordine di inserimento specificando un comparatore personalizzato.
-
-
Sincronizzazione: Un
Setnon è sincronizzato, il che significa che potresti incontrare problemi di concorrenza, come le race condition, che possono influire sull’integrità dei dati se due o più thread cercano di accedere contemporaneamente a un oggettoSet -
Metodi chiave: Ecco alcuni metodi chiave di un’interfaccia
Set:add(E elemento),remove(Object o),contains(Object o)esize(). Vediamo come utilizzare questi metodi con un programma di esempio.import java.util.HashSet; import java.util.Set; public class SetExample { public static void main(String[] args) { // Crea un insieme Set<String> set = new HashSet<>(); // Aggiungi elementi all'insieme set.add("Mela"); set.add("Banana"); set.add("Ciliegia"); // Rimuovi un elemento dall'insieme set.remove("Banana"); // Verifica se l'insieme contiene un elemento boolean contieneMela = set.contains("Mela"); System.out.println("Contiene Mela: " + contieneMela); // Ottieni la dimensione dell'insieme int dimensione = set.size(); System.out.println("Dimensione dell'insieme: " + dimensione); } } -
Implementazioni comuni:
HashSet,LinkedHashSet,TreeSet -
Prestazioni: Le implementazioni di
Setoffrono prestazioni elevate per le operazioni di base, tranne per unTreeSet, dove le prestazioni possono essere relativamente più lente poiché la struttura dati interna implica l’ordinamento degli elementi durante queste operazioni.
| Operazione | HashSet | LinkedHashSet | TreeSet |
| Inserimento | Veloce – O(1) | Veloce – O(1) | Più lento – O(log n) |
| Cancellazione | Veloce – O(1) | Veloce – O(1) | Più lento – O(log n) |
| Recupero | Veloce – O(1) | Veloce – O(1) | Più lento – O(log n) |
Code
Una Queue è una collezione lineare di elementi utilizzata per contenere più oggetti prima dell’elaborazione, solitamente seguendo l’ordine FIFO (first-in-first-out). Ciò significa che gli elementi vengono aggiunti a un’estremità e rimossi dall’altra, quindi il primo elemento aggiunto alla coda è il primo a essere rimosso.
-
Meccanismo interno: Il funzionamento interno di una
Queuepuò differire in base alla sua specifica implementazione.-
LinkedList– utilizza una lista doppiamente collegata per memorizzare gli elementi, il che significa che puoi attraversare sia in avanti che all’indietro, consentendo operazioni flessibili. -
PriorityQueue– è supportata internamente da un heap binario, che è molto efficiente per le operazioni di recupero. -
ArrayDeque– è implementata utilizzando un array che si espande o si riduce man mano che gli elementi vengono aggiunti o rimossi. Qui, gli elementi possono essere aggiunti o rimossi da entrambe le estremità della coda.
-
-
Duplicati: In una
Queue, sono ammessi elementi duplicati, consentendo l’inserimento di più istanze dello stesso valore -
Null: Non è possibile inserire un valore nullo in una
Queueperché, per design, alcuni metodi di unaQueuerestituiscono null per indicare che è vuota. Per evitare confusione, i valori nulli non sono ammessi. -
Ordinamento: Gli elementi vengono inseriti in base al loro ordine naturale. In alternativa, puoi controllare l’ordine di inserimento specificando un comparatore personalizzato.
-
Sincronizzazione: Una
Queuenon è sincronizzata per impostazione predefinita. Tuttavia, puoi utilizzare un’implementazione diConcurrentLinkedQueueoBlockingQueueper ottenere la sicurezza dei thread. -
Metodi chiave: Ecco alcuni metodi chiave di un’interfaccia
Queue:add(E elemento),offer(E elemento),poll()epeek(). Vediamo come utilizzare questi metodi con un esempio di programma.import java.util.LinkedList; import java.util.Queue; public class QueueExample { public static void main(String[] args) { // Crea una coda usando LinkedList Queue<String> coda = new LinkedList<>(); // Utilizza il metodo add per inserire elementi, restituisce un'eccezione se l'inserimento fallisce coda.add("Elemento1"); coda.add("Elemento2"); coda.add("Elemento3"); // Utilizza il metodo offer per inserire elementi, restituisce false se l'inserimento fallisce coda.offer("Elemento4"); // Visualizza la coda System.out.println("Coda: " + coda); // Controlla il primo elemento (non lo rimuove) String primoElemento = coda.peek(); System.out.println("Controlla: " + primoElemento); // produce "Elemento1" // Preleva il primo elemento (lo recupera e lo rimuove) String elementoPrelevato = coda.poll(); System.out.println("Prelevato: " + elementoPrelevato); // produce "Elemento1" // Visualizza la coda dopo il prelievo System.out.println("Coda dopo il prelievo: " + coda); } } -
Implementazioni comuni:
LinkedList,PriorityQueue,ArrayDeque -
Prestazioni: Implementazioni come
LinkedListeArrayDequesono generalmente veloci per l’aggiunta e la rimozione di elementi. LaPriorityQueueè un po’ più lenta perché inserisce gli elementi in base all’ordine di priorità impostato.
| Operazione | LinkedList | PriorityQueue | ArrayDeque |
| Inserimento | Veloce all’inizio o in mezzo – O(1), lento alla fine – O(n) | Più lento – O(log n) | Veloce – O(1), Lento – O(n), se comporta il ridimensionamento dell’array interno |
| Eliminazione | Veloce – O(1) se la posizione è conosciuta | Più lento – O(log n) | Veloce – O(1), Lento – O(n), se comporta il ridimensionamento dell’array interno |
| Ricerca | Lento – O(n) per l’accesso casuale, poiché comporta il attraversamento | Veloce – O(1) | Veloce – O(1) |
Mappe
Una Mappa rappresenta una collezione di coppie chiave-valore, con ogni chiave che mappa a un singolo valore. Anche se la Mappa fa parte del framework delle Collezioni di Java, non estende l’interfaccia java.util.Collection.
-
Mechanismo interno: Una
Mapfunziona internamente utilizzando unaHashTablebasata sul concetto di hashing. Ho scritto un dettagliato articolo su questo argomento, quindi leggilo per una comprensione più approfondita. -
Duplicati: Una
Mapmemorizza i dati come coppie chiave-valore. Qui, ogni chiave è univoca, quindi le chiavi duplicate non sono ammesse. Ma i valori duplicati sono permessi. -
Null: Poiché le chiavi duplicate non sono ammesse, una
Mappuò avere solo una chiave nulla. Poiché i valori duplicati sono permessi, può avere più valori nulli. Nell’implementazione diTreeMap, le chiavi non possono essere null perché ordina gli elementi in base alle chiavi. Tuttavia, i valori nulli sono ammessi. -
Ordinamento: L’ordine di inserimento di un
Mapvaria a seconda dell’implementazione:-
HashMap– l’ordine di inserimento non è garantito in quanto è determinato sulla base del concetto di hashing. -
LinkedHashMap– l’ordine di inserimento è preservato e puoi recuperare gli elementi nello stesso ordine in cui sono stati aggiunti alla collezione. -
TreeMap– Gli elementi sono inseriti in base al loro ordine naturale. In alternativa, puoi controllare l’ordine di inserimento specificando un comparatore personalizzato.
-
-
Sincronizzazione: Una
Mapnon è sincronizzata per impostazione predefinita. Ma è possibile utilizzare le implementazioniCollections.synchronizedMap()oConcurrentHashMapper garantire la sicurezza dei thread. -
Metodi chiave: Ecco alcuni metodi chiave di un’interfaccia
Map:put(K key, V value),get(Object key),remove(Object key),containsKey(Object key)ekeySet(). Vediamo come utilizzare questi metodi con un programma di esempio.import java.util.HashMap; import java.util.Map; import java.util.Set; public class EsempioMetodiMappa { public static void main(String[] args) { // Crea una nuova HashMap Map<String, Integer> mappa = new HashMap<>(); // put(K key, V value) - Inserisce coppie chiave-valore nella mappa mappa.put("Mela", 1); mappa.put("Banana", 2); mappa.put("Arancia", 3); // get(Object key) - Restituisce il valore associato alla chiave Integer valore = mappa.get("Banana"); System.out.println("Valore per 'Banana': " + valore); // remove(Object key) - Rimuove la coppia chiave-valore per la chiave specificata mappa.remove("Arancia"); // containsKey(Object key) - Controlla se la mappa contiene la chiave specificata boolean haMela = mappa.containsKey("Mela"); System.out.println("Contiene 'Mela': " + haMela); // keySet() - Restituisce una vista insieme delle chiavi contenute nella mappa Set<String> chiavi = mappa.keySet(); System.out.println("Chiavi nella mappa: " + chiavi); } } -
Implementazioni comuni:
HashMap,LinkedHashMap,TreeMap,Hashtable,ConcurrentHashMap -
Prestazioni: L’implementazione
HashMapè ampiamente utilizzata principalmente a causa delle sue caratteristiche di prestazione efficienti illustrate nella tabella sottostante.
| Operazione | HashMap | LinkedHashMap | TreeMap |
| Inserimento | Veloce – O(1) | Veloce – O(1) | Più lento – O(log n) |
| Cancellazione | Veloce – O(1) | Veloce – O(1) | Più lento – O(log n) |
| Recupero | Veloce – O(1) | Veloce – O(1) | Più lento – O(log n) |
Classe di utilità Collections
Come evidenziato all’inizio di questo articolo, la classe di utilità Collections ha diversi utili metodi statici che ti permettono di eseguire operazioni comunemente utilizzate sugli elementi di una collezione. Questi metodi ti aiutano a ridurre il codice ripetitivo nella tua applicazione e ti permettono di concentrarti sulla logica di business.
Ecco alcune caratteristiche chiave e metodi, insieme a ciò che fanno, elencati brevemente:
-
Ordinamento:
Collections.sort(List<T>)– questo metodo è utilizzato per ordinare gli elementi di una lista in ordine crescente. -
Ricerca:
Collections.binarySearch(List<T>, chiave)– questo metodo è utilizzato per cercare un elemento specifico in una lista ordinata e restituire il suo indice. -
Ordine inverso:
Collections.reverse(List<T>)– questo metodo è utilizzato per invertire l’ordine degli elementi in una lista. -
Operazioni Min/Max:
Collections.min(Collection<T>)eCollections.max(Collection<T>)– questi metodi sono utilizzati per trovare rispettivamente gli elementi minimi e massimi in una collezione. -
Sincronizzazione:
Collections.synchronizedList(List<T>)– questo metodo è utilizzato per rendere una lista thread-safe sincronizzandola. -
Collezioni non modificabili:
Collections.unmodifiableList(List<T>)– questo metodo viene utilizzato per creare una vista in sola lettura di una lista, impedendo modifiche.
Ecco un programma Java di esempio che dimostra varie funzionalità della classe di utilità Collections:
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class CollectionsExample {
public static void main(String[] args) {
List<Integer> numbers = new ArrayList<>();
numbers.add(5);
numbers.add(3);
numbers.add(8);
numbers.add(1);
// Ordinamento
Collections.sort(numbers);
System.out.println("Sorted List: " + numbers);
// Ricerca
int index = Collections.binarySearch(numbers, 3);
System.out.println("Index of 3: " + index);
// Ordine inverso
Collections.reverse(numbers);
System.out.println("Reversed List: " + numbers);
// Operazioni Min/Max
int min = Collections.min(numbers);
int max = Collections.max(numbers);
System.out.println("Min: " + min + ", Max: " + max);
// Sincronizzazione
List<Integer> synchronizedList = Collections.synchronizedList(numbers);
System.out.println("Synchronized List: " + synchronizedList);
// Collezioni non modificabili
List<Integer> unmodifiableList = Collections.unmodifiableList(numbers);
System.out.println("Unmodifiable List: " + unmodifiableList);
}
}
Questo programma dimostra l’ordinamento, la ricerca, l’inversione, la ricerca dei valori minimi e massimi, la sincronizzazione e la creazione di un elenco non modificabile utilizzando la classe di utilità Collections.
Conclusione
In questo articolo, hai appreso del Framework delle Collezioni di Java e di come aiuti a gestire gruppi di oggetti nelle applicazioni Java. Abbiamo esplorato vari tipi di collezioni come Liste, Insiemi, Code e Mappe e acquisito conoscenze su alcune delle caratteristiche principali e su come ciascuno di questi tipi le supporta.
Hai appreso delle prestazioni, della sincronizzazione e dei metodi chiave, acquisendo preziose informazioni per scegliere le strutture dati giuste per le tue esigenze.
Comprendendo questi concetti, puoi sfruttare appieno il Framework delle Collezioni di Java, consentendoti di scrivere codice più efficiente e costruire applicazioni robuste.
Se hai trovato interessante questo articolo, non esitare a dare un’occhiata ai miei altri articoli su freeCodeCamp e a connetterti con me su LinkedIn.
Source:
https://www.freecodecamp.org/news/java-collections-framework-reference-guide/