













在您的Java應用程序中,通常會使用各種類型的對象。您可能希望對這些對象執行排序、搜索和迭代等操作。
在JDK 1.2之前引入Collections框架之前,您可能會使用Arrays和Vectors來存儲和管理一組對象。但它們也有自己的缺點。
Java集合框架旨在通過提供常見數據結構的高性能實現來克服這些問題。這使您能夠專注於編寫應用程序邏輯,而不是專注於低級操作。
然後,在JDK 1.5中引入泛型顯著改進了Java集合框架。泛型讓您可以強制實施存儲在集合中的對象的類型安全性,從而增強應用程序的健壯性。您可以在此處閱讀有關Java泛型的更多信息。
在本文中,我將指導您如何使用Java集合框架。我們將討論不同類型的集合,例如列表、集合、隊列和映射。我還將簡要解釋它們的主要特徵,例如:
-
內部機制
-
重複處理
-
支持空值
-
排序
-
同步
-
性能
-
關鍵方法
-
常見實現
我們還將通過一些代碼示例來更好地理解,並將涉及Collections實用程序類及其用法。
目錄:
理解Java集合框架
根據Java 文檔,“集合是表示一組對象的對象。集合框架是一種統一的架構,用於表示和操作集合。”
簡而言之,Java集合框架幫助您有效且有組織地管理一組對象並對其執行操作。通過提供各種方法來處理對象組,使應用程序開發更加容易。您可以使用Java集合框架有效地添加、刪除、搜索和排序對象。
集合接口
在Java中,接口指定了任何實現它的類必須履行的合同。這意味著實現類必須為接口中聲明的所有方法提供具體實現。
在Java Collections Framework中,各種集合接口如Set、List和Queue都擴展了Collection接口,它們必須遵守Collection接口定義的契約。
解讀Java集合框架層次結構
查看這篇文章中介紹的Java集合層次結構示意圖:
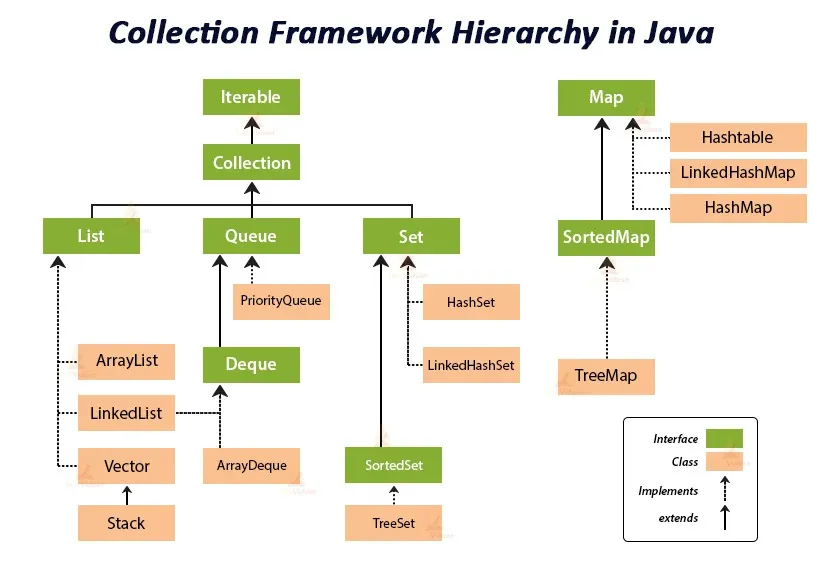
我們將從頂部開始向下進行,以便您理解這幅圖所展示的內容:
-
在Java集合框架的根部是
Iterable接口,它允許您遍歷集合的元素。 -
Collection接口擴展了Iterable接口。這意味著它繼承了Iterable接口的屬性和行為,並為添加、刪除和檢索元素添加了自己的行為。 -
特定的接口,如
List、Set和Queue,进一步扩展了Collection接口。这些接口中的每一个都有其他类来实现它们的方法。例如,ArrayList是List接口的一种常见实现,HashSet实现了Set接口,依此类推。 -
Map接口是Java集合框架的一部分,但与上述提到的其他接口不同,它并不扩展Collection接口。 -
该框架中的所有接口和类都属于
java.util包。
注意:Java集合框架中常见的混淆点在于Collection和Collections之间的区别。Collection是框架中的一个接口,而Collections是一个实用类。Collections类提供了在集合元素上执行操作的静态方法。
Java集合接口
到目前为止,您已经熟悉构成集合框架基础的不同类型集合。现在我们将更详细地查看List、Set、Queue和Map接口。
在本节中,我们将讨论这些接口,同时探索它们的内部机制。我们将研究它们如何处理重复元素,以及它们是否支持插入空值。我们还将了解插入期间元素的排序以及它们对同步的支持,这涉及线程安全的概念。然后,我们将逐个介绍这些接口的一些关键方法,并通过回顾常见实现以及它们在各种操作中的性能来结束。
在开始之前,让我们简要谈谈同步和性能。
-
同步通过多个线程控制对共享对象的访问,确保它们的完整性并防止冲突。这对于维护线程安全至关重要。
-
在選擇集合類型時,一個重要因素是其在常見操作(如插入、刪除和檢索)期間的性能。性能通常用大O符號表示。您可以在這裡了解更多。
列表
一個 List 是一個有序或順序集合。它遵循從零開始的索引,允許通過它們的索引位置插入、刪除或訪問元素。
-
內部機制:一個
List在內部由數組或鏈表支持,具體取決於實現的類型。例如,ArrayList使用數組,而LinkedList在內部使用鏈表。您可以在這裡閱讀有關LinkedList的更多信息。一個List在添加或刪除元素時會動態調整大小。基於索引的檢索使其成為一種非常高效的集合類型。 -
重複元素:
List允許存在重複元素,這意味著在List中可能會有多個具有相同值的元素。可以根據存儲的索引檢索任何值。 -
空值:
List也允許空值。由於允許重複,因此還可以擁有多個空元素。 -
排序:
List保持插入順序,這意味著元素按照它們添加的順序存儲。當您希望按照插入的確切順序檢索元素時,這非常有用。 -
同步: 一個
List默認情況下不同步,這意味著它沒有內置方法來處理同時由多個線程訪問的情況。 -
關鍵方法: 這裡是一個
List介面的一些關鍵方法:add(E element),get(int index),set(int index, E element),remove(int index), 和size()。讓我們看看如何在一個範例程式中使用這些方法。import java.util.ArrayList; import java.util.List; public class ListExample { public static void main(String[] args) { // 創建一個列表 List<String> list = new ArrayList<>(); // add(E element) list.add("Apple"); list.add("Banana"); list.add("Cherry"); // get(int index) String secondElement = list.get(1); // "Banana" // set(int index, E element) list.set(1, "Blueberry"); // remove(int index) list.remove(0); // 移除 "Apple" // size() int size = list.size(); // 2 // 列印列表 System.out.println(list); // 輸出: [Blueberry, Cherry] // 列印列表的大小 System.out.println(size); // 輸出: 2 } } -
常見實作:
ArrayList、LinkedList、Vector、Stack -
效能:通常,在
ArrayList和LinkedList中,插入和刪除操作都很快。但是檢索元素可能會較慢,因為必須穿越節點。
| 操作 | ArrayList | LinkedList |
| 插入 | 尾部快 – O(1)攤銷,開頭或中間較慢- O(n) | 開頭或中間快 – O(1),尾部較慢 – O(n) |
| 刪除 | 尾部快 – O(1)攤銷,開頭或中間較慢- O(n) | 如果位置已知,快 – O(1) |
| 檢索 | 快 – O(1)進行隨機訪問 | 對於隨機訪問,較慢 – O(n),因為需要穿越 |
集合
Set是一種不允許重複元素並代表數學集合概念的集合類型。
-
內部機制: 一個
Set在內部由一個HashMap支持。根據實現類型,它可以由一個HashMap、LinkedHashMap或TreeMap支持。我已經寫了一篇關於HashMap內部工作原理的詳細文章這裡。一定要去看一下。 -
重複: 由於
Set代表數學集合的概念,不允許重複元素。這確保所有元素都是獨一無二的,維護了集合的完整性。 -
Null:在
Set中最多允許一個空值,因為不允許重複。但這不適用於TreeSet實現,其中根本不允許空值。 -
Ordering:在
Set中元素的排序取決於實現類型。-
HashSet:順序不保證,元素可以放在任何位置。 -
LinkedHashSet:此實現保持插入順序,因此您可以按照插入順序檢索元素。 -
TreeSet:元素根據其自然順序插入。或者,您可以通過指定自定義比較器來控制插入順序。
-
-
同步:
Set不是同步的,這意味著您可能會遇到並發問題,如競爭條件,如果兩個或更多線程同時嘗試訪問Set物件,則可能會影響數據完整性。 -
關鍵方法: 這裡列出了
Set介面的一些關鍵方法:add(E element),remove(Object o),contains(Object o), 和size()。讓我們看看如何在一個範例程式中使用這些方法。import java.util.HashSet; import java.util.Set; public class SetExample { public static void main(String[] args) { // 建立一個集合 Set<String> set = new HashSet<>(); // 將元素加入集合 set.add("Apple"); set.add("Banana"); set.add("Cherry"); // 從集合中移除一個元素 set.remove("Banana"); // 檢查集合中是否包含一個元素 boolean containsApple = set.contains("Apple"); System.out.println("Contains Apple: " + containsApple); // 獲取集合的大小 int size = set.size(); System.out.println("Size of the set: " + size); } } -
常見實現:
HashSet、LinkedHashSet、TreeSet -
性能:
Set實現提供基本操作的快速性能,除了TreeSet,在這些操作期間性能可能相對較慢,因為內部數據結構涉及對元素進行排序。
| 操作 | HashSet | LinkedHashSet | TreeSet |
| 插入 | 快速 – O(1) | 快速 – O(1) | 較慢 – O(log n) |
| 刪除 | 快速 – O(1) | 快速 – O(1) | 較慢 – O(log n) |
| 檢索 | 快速 – O(1) | 快速 – O(1) | 較慢 – O(log n) |
佇列
佇列是用來在處理之前保存多個項目的線性元素集合,通常遵循FIFO(先進先出)順序。這意味著元素在一端添加並從另一端移除,因此最先添加到佇列的元素是最先被移除的。
-
內部機制:
佇列的內部運作可能根據其具體實現而有所不同。-
鏈結串列– 使用雙向鏈結串列來存儲元素,這意味著您可以前後遍歷,允許靈活的操作。 -
優先佇列– 由二元堆內部支持,這對檢索操作非常有效。 -
數組雙端佇列– 使用一個隨著元素添加或移除而擴展或縮小的數組實現。在這裡,元素可以從佇列的兩端添加或移除。
-
-
重複項: 在
Queue中,允許重複元素,可以插入相同值的多個實例 -
Null 值: 不能將 null 值插入
Queue中,因為根據設計,Queue的某些方法返回 null 以指示它是空的。為避免混淆,不允許使用 null 值。 -
排序:元素根據其自然順序插入。或者,您可以通過指定自定義比較器來控制插入順序。
-
同步:默認情況下,
Queue不是同步的。但是,您可以使用ConcurrentLinkedQueue或BlockingQueue實現來實現線程安全。 -
關鍵方法: 這裡是
Queue介面的一些關鍵方法:add(E element),offer(E element),poll(), 以及peek()。讓我們看看如何使用這些方法,附帶一個範例程式。import java.util.LinkedList; import java.util.Queue; public class QueueExample { public static void main(String[] args) { // 使用 LinkedList 創建一個 Queue Queue<String> queue = new LinkedList<>(); // 使用 add 方法插入元素,如果插入失敗則拋出異常 queue.add("Element1"); queue.add("Element2"); queue.add("Element3"); // 使用 offer 方法插入元素,如果插入失敗則返回 false queue.offer("Element4"); // 顯示 queue System.out.println("Queue: " + queue); // 查看第一個元素(不將其移除) String firstElement = queue.peek(); System.out.println("Peek: " + firstElement); // 輸出 "Element1" // 取出並移除第一個元素 String polledElement = queue.poll(); System.out.println("Poll: " + polledElement); // 輸出 "Element1" // 取出元素後顯示 queue System.out.println("Queue after poll: " + queue); } } -
常見實現:
LinkedList、PriorityQueue、ArrayDeque -
性能: 像
LinkedList和ArrayDeque的實現通常在添加和刪除項目時很快。PriorityQueue會稍慢一些,因為它根據設置的優先順序插入項目。
| 操作 | LinkedList | PriorityQueue | ArrayDeque |
| 插入 | 開頭或中間快 – O(1),結尾慢 – O(n) | 較慢 – O(log n) | 快 – O(1),慢 – O(n),如果涉及內部陣列的調整 |
| 刪除 | 如果位置已知則快 – O(1) | 較慢 – O(log n) | 快 – O(1),慢 – O(n),如果涉及內部陣列的調整 |
| 檢索 | 對於隨機存取較慢 – O(n),因為需要遍歷 | 快 – O(1) | 快 – O(1) |
映射
Map 代表一組鍵-值對,每個鍵對應單個值。儘管 Map 是 Java 集合框架的一部分,但它並不擴展 java.util.Collection 介面。
-
內部機制:一個
Map在內部使用基於雜湊概念的HashTable來運作。我已經撰寫了一篇詳細的文章,請閱讀以深入了解。 -
重複項:一個
Map將資料存儲為鍵-值對。在這裡,每個鍵都是唯一的,因此不允許重複的鍵。但是允許重複的值。 -
空值:由於不允許重複的鍵,一個
Map只能有一個空鍵。由於允許重複的值,它可以有多個空值。在TreeMap實現中,鍵不能為空,因為它根據鍵對元素進行排序。然而,空值是被允許的。 -
順序:
Map的插入順序取決於實現方式:-
HashMap– 插入順序無法保證,因為它們是基於哈希概念決定的。 -
LinkedHashMap– 保留插入順序,可以按照添加到集合中的相同順序檢索元素。 -
TreeMap– 元素根據其自然順序進行插入。或者,您可以通過指定自定義比較器來控制插入順序。
-
-
同步:
Map預設並不同步。但您可以使用Collections.synchronizedMap()或ConcurrentHashMap實現來達成執行緒安全。 -
關鍵方法: 這裡是一些
Map介面的關鍵方法:put(K key, V value),get(Object key),remove(Object key),containsKey(Object key), 和keySet()。讓我們看看如何使用這些方法來撰寫範例程式。import java.util.HashMap; import java.util.Map; import java.util.Set; public class MapMethodsExample { public static void main(String[] args) { // 創建一個新的HashMap Map<String, Integer> map = new HashMap<>(); // put(K key, V value) - 將鍵-值對插入映射 map.put("Apple", 1); map.put("Banana", 2); map.put("Orange", 3); // get(Object key) - 返回與鍵關聯的值 Integer value = map.get("Banana"); System.out.println("Value for 'Banana': " + value); // remove(Object key) - 刪除指定鍵的鍵-值對 map.remove("Orange"); // containsKey(Object key) - 檢查映射是否包含指定鍵 boolean hasApple = map.containsKey("Apple"); System.out.println("Contains 'Apple': " + hasApple); // keySet() - 返回映射中包含的鍵的集合視圖 Set<String> keys = map.keySet(); System.out.println("Keys in map: " + keys); } } -
常見實現:
HashMap,LinkedHashMap,TreeMap,Hashtable,ConcurrentHashMap -
性能:
HashMap實現因其在下表中展示的高效性能特徵而被廣泛使用。
| 操作 | HashMap | LinkedHashMap | TreeMap |
| 插入 | 快 – O(1) | 快 – O(1) | 較慢 – O(log n) |
| 刪除 | 快 – O(1) | 快 – O(1) | 較慢 – O(log n) |
| 檢索 | 快 – O(1) | 快 – O(1) | 較慢 – O(log n) |
集合實用類
正如本文開頭所強調的,Collections實用類具有幾個有用的靜態方法,讓您可以對集合元素執行常用操作。這些方法幫助您減少應用程序中的樣板代碼,讓您專注於業務邏輯。
以下是一些主要功能和方法,以及它們的簡要列表:
-
排序:
Collections.sort(List<T>)– 這個方法用於將列表元素按升序排序。 -
搜索:
Collections.binarySearch(List<T>, key)– 此方法用於在已排序列表中搜索特定元素並返回其索引。 -
反向排序:
Collections.reverse(List<T>)– 此方法用於反轉列表中元素的順序。 -
最小/最大操作:
Collections.min(Collection<T>)和Collections.max(Collection<T>)– 這些方法分別用於找到集合中的最小和最大元素。 -
同步化:
Collections.synchronizedList(List<T>)– 此方法用於通過同步使列表線程安全。 -
不可修改的集合:
Collections.unmodifiableList(List<T>)– 此方法用於創建列表的只讀視圖,防止修改。
這是一個示範 Collections 工具類別各種功能的 Java 範例程式:
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class CollectionsExample {
public static void main(String[] args) {
List<Integer> numbers = new ArrayList<>();
numbers.add(5);
numbers.add(3);
numbers.add(8);
numbers.add(1);
// 排序
Collections.sort(numbers);
System.out.println("Sorted List: " + numbers);
// 搜尋
int index = Collections.binarySearch(numbers, 3);
System.out.println("Index of 3: " + index);
// 反向排序
Collections.reverse(numbers);
System.out.println("Reversed List: " + numbers);
// 最小/最大操作
int min = Collections.min(numbers);
int max = Collections.max(numbers);
System.out.println("Min: " + min + ", Max: " + max);
// 同步
List<Integer> synchronizedList = Collections.synchronizedList(numbers);
System.out.println("Synchronized List: " + synchronizedList);
// 不可修改的集合
List<Integer> unmodifiableList = Collections.unmodifiableList(numbers);
System.out.println("Unmodifiable List: " + unmodifiableList);
}
}
本程式演示了使用 Collections 工具類別的排序、搜尋、反轉、尋找最小和最大值、同步以及創建不可修改列表的功能。
結論
在本文中,您已了解 Java 集合框架以及它如何幫助管理 Java 應用程式中的物件群組。我們探討了各種集合類型,如列表、集合、佇列和映射,並深入了解這些類型的一些關鍵特徵及其支持的功能。
您學習了性能、同步和關鍵方法,獲得了選擇適合您需求的數據結構的寶貴見解。
通過理解這些概念,您可以充分利用Java集合框架,從而撰寫更高效的代碼並構建健壯的應用程序。
如果您覺得這篇文章有趣,歡迎查看我在freeCodeCamp上的其他文章,並在LinkedIn上與我聯繫。
Source:
https://www.freecodecamp.org/news/java-collections-framework-reference-guide/