













Данный учебник является основой компьютерного зрения, представленной в виде “Урока 2” серии; впереди еще много уроков, которые расскажут о том, как создавать свои проекты компьютерного зрения на основе глубокого обучения. Вы можете найти полную программу и оглавление здесь.
Основные выводы из этой статьи:
- Загрузка изображения с диска.
- Получение ‘Высоты’, ‘Ширины’ и ‘Глубины’ изображения.
- Нахождение компонентов R, G и B изображения.
- Рисование с использованием OpenCV.
Загрузка изображения с диска
Прежде чем выполнять какие-либо операции или манипуляции с изображением, важно загрузить изображение по своему выбору на диск. Мы будем выполнять эту деятельность с использованием OpenCV. Существует два способа выполнить эту операцию загрузки. Один способ – загрузить изображение, просто передав путь к изображению и файл изображения в функцию “imread” OpenCV. Другой способ – передать изображение через аргумент командной строки с помощью модуля python argparse.
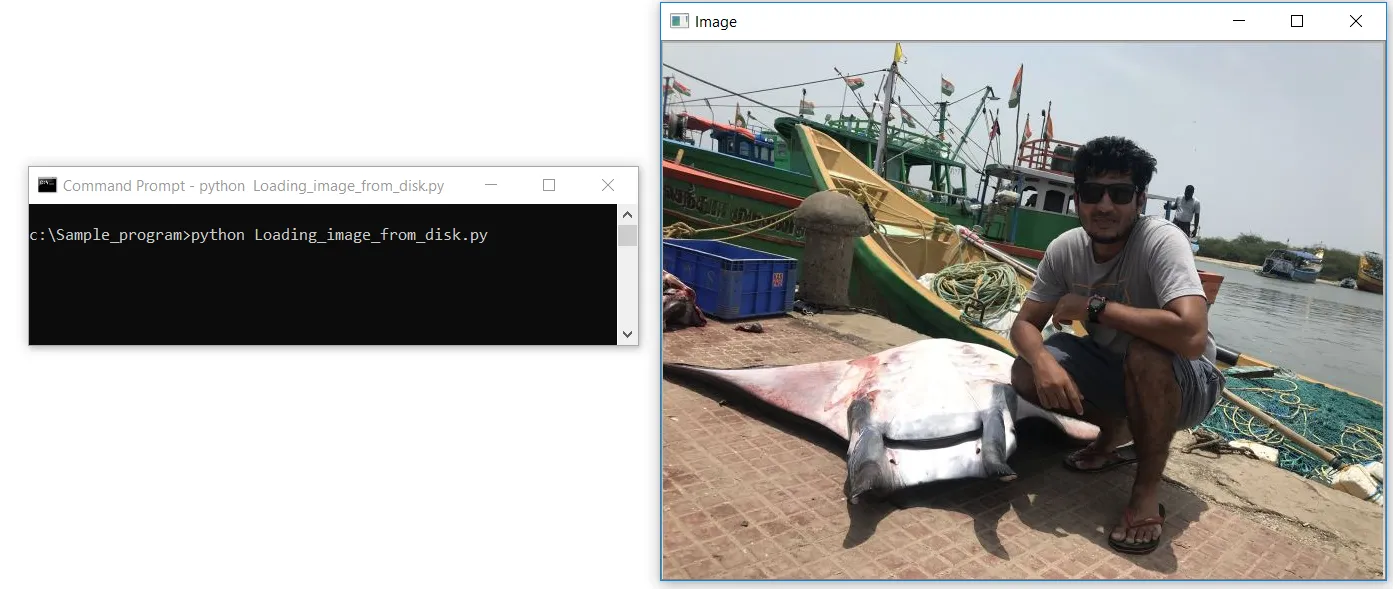
#Загрузка изображения с диска
import cv2
image = cv2.imread(“C:/Sample_program/example.jpg”)
cv2.imshow(‘Image’, image)
cv2.waitKey(0)Давайте создадим файл с именем Loading_image_from_disk.py в Notepad++. Во-первых, мы импортируем библиотеку OpenCV, которая содержит функции для обработки изображений. Библиотеку импортируем с помощью первой строки кода как cv2. Во второй строке кода мы читаем наше изображение с помощью функции cv2.imread в OpenCV, и передаем путь к изображению в качестве параметра; путь также должен содержать имя файла с расширением формата изображения .jpg, .jpeg, .png или .tiff.
синтаксис — // image=cv2.imread(“path/to/your/image.jpg”) //
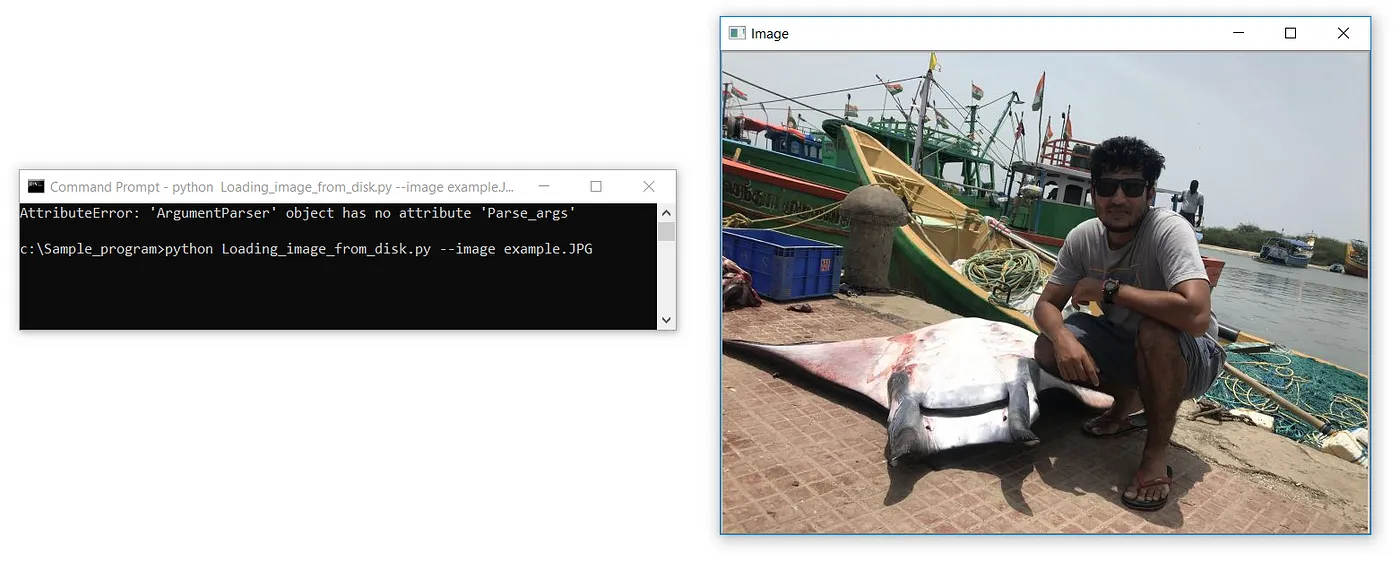
Особое внимание следует уделять при указании имени расширения файла. Вероятнее всего, мы получим следующую ошибку, если укажем неправильное расширение.
ERROR :
c:\Sample_program>python Loading_image_from_disk.py
Traceback (most recent call last):
File “Loading_image_from_disk.py”, line 4, in <module>
cv2.imshow(‘Image’, image)
cv2.error: OpenCV(4.3.0) C:\projects\opencv-python\opencv\modules\highgui\src\window.cpp:376: error: (-215:Assertion failed) size.width>0 && size.height>0 in function ‘cv::imshow’В третьей строке кода мы фактически отображаем загруженное изображение. Первый параметр – это строка, или “имя” нашего окна. Второй параметр – это объект, к которому было загружено изображение.
Наконец, вызов cv2.waitKey приостанавливает выполнение скрипта до тех пор, пока мы не нажмем клавишу на клавиатуре. Использование параметра “0” указывает, что любое нажатие клавиши разблокирует выполнение. Не стесняйтесь запускать свой программу без последней строки кода, чтобы увидеть разницу.
#Чтение изображения с диска с использованием Argparse
import cv2
import argparse
apr = argparse.ArgumentParser()
apr.add_argument(“-i”, “ — image”, required=True, help=”Path to the image”)
args = vars(apr.parse_args())
image = cv2.imread(args[“image”])
cv2.imshow(‘Image’, image)
cv2.waitKey(0)Знание того, как читать изображение или файл с помощью аргумента командной строки (argparse), является абсолютно необходимым навыком.
Первые две строки кода предназначены для импорта необходимых библиотек; здесь мы импортируем OpenCV и Argparse. Это будет повторяться на протяжении всего курса.
Следующие три строки кода обрабатывают парсинг аргументов командной строки. Единственный аргумент, который нам нужен, это — image: путь к нашему изображению на диске. Наконец, мы парсим аргументы и сохраняем их в словаре под названием args.
Давайте остановимся на секунду и быстро обсудим, что именно означает — image switch. — image “switch” (“switch” является синонимом “командного аргумента командной строки” и термины могут использоваться взаимозаменяемо) — это строка, которую мы указываем в командной строке. Этот переключатель сообщает нашему скрипту Loading_image_from_disk.py, где находится изображение, которое мы хотим загрузить на диске.
Последние три строки кода обсуждались ранее; функция cv2.imread принимает args[“image”] в качестве параметра, который представляет собой просто изображение, которое мы предоставляем в командной строке. cv2.imshow отображает изображение, которое уже хранится в объекте изображения из предыдущей строки. Последняя строка приостанавливает выполнение скрипта до тех пор, пока мы не нажмем клавишу на клавиатуре.
Одним из основных преимуществ использования argparse — командного аргумента является то, что мы сможем загружать изображения из разных папок без необходимости изменять путь к изображению в нашей программе, динамически передавая путь к изображению, например, “C:\CV_Material\image\sample.jpg” в командной строке в качестве аргумента при выполнении нашей программы на Python.
c:\Sample_program>python Loading_image_from_disk.py — image C:\CV_Material\session1.JPG
Здесь мы выполняем файл Loading_image_from_disk.py Python из c:\sample_program местоположения, передавая параметр “-image” вместе с путем к изображению C:\CV_Material\session1.JPG.
Получение ‘Высоты’, ‘Ширины’ и ‘Глубины’ изображения
Так как изображения представлены в виде массивов NumPy, мы можем просто использовать атрибут .shape для исследования ширины, высоты и количества каналов.
Применяя атрибут .shape к объекту изображения, который мы только что загрузили, мы можем найти высоту, ширину и глубину изображения. Как обсуждалось в предыдущем уроке — 1, высоту и ширину изображения можно проверить, открыв изображение в MS Paint. Обратитесь к предыдущему уроку. Мы обсудим глубину изображения в предстоящих уроках. Глубина также известна как канал изображения. Цветные изображения обычно имеют 3 канала из-за состава RGB в пикселях, а градации серого изображений — 1 канал. Это то, что мы обсуждали в предыдущем Уроке-1.
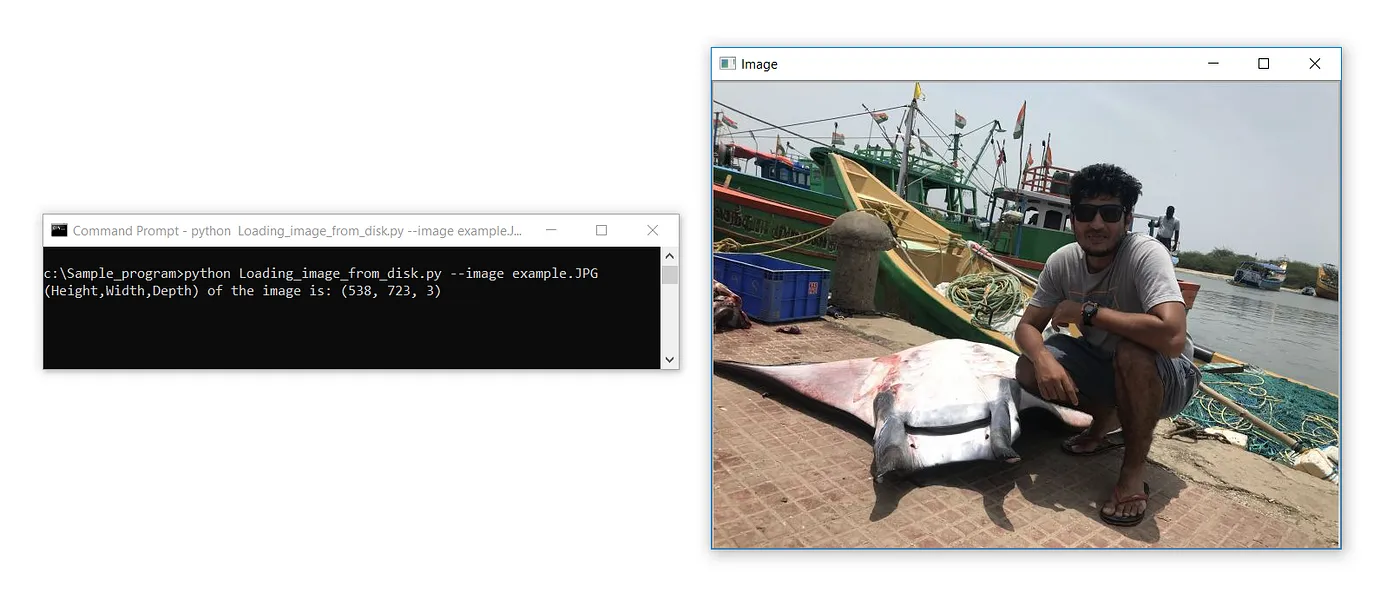
# Получение высоты, ширины и глубины изображения
import cv2
import argparse
apr = argparse.ArgumentParser()
apr.add_argument(“-i”, “ — image”, required=True, help=”Path to the image”)
args = vars(apr.parse_args())
# Единственное отличие от предыдущих кодов — применение атрибута shape к объекту изображения
print(f’(Height,Width,Depth) of the image is: {image.shape}’)
image = cv2.imread(args[“image”])
cv2.imshow(‘Image’, image)
cv2.waitKey(0)Вывод:
Высота, ширина и глубина изображения: (538, 723, 3)
Единственное отличие от предыдущих кодов — это оператор print, который применяет атрибут shape к загруженному объекту изображения. f’ — это форматированная строка F-строки, которая динамически принимает переменные и выводит их.
f’ write anything here that you want to see in the print statement: {variables, variables, object, object.attribute,}’
Здесь мы использовали {object.attribute} внутри фигурных скобок для атрибута .shape, чтобы вычислить высоту, ширину и глубину объекта изображения.
# Получение высоты, ширины и глубины по отдельности
import cv2
import argparse
apr = argparse.ArgumentParser()
apr.add_argument(“-i”, “ — image”, required=True, help=”Path to the image”)
args = vars(apr.parse_args())
image = cv2.imread(args[“image”])
# Срезы массива NumPy для получения высоты, ширины и глубины по отдельности
print(“height: %d pixels” % (image.shape[0]))
print(“width: %d pixels” % (image.shape[1]))
print(“depth: %d” % (image.shape[2]))
cv2.imshow(‘Image’, image)
cv2.waitKey(0)Вывод:
ширина: 723 пикселя
высота: 538 пикселей
глубина: 3
Здесь, вместо получения (высоты, ширины и глубины) вместе как кортежа, мы выполняем срезы массива и получаем высоту, ширину и глубину изображения по отдельности. 0-й индекс массива содержит высоту изображения, 1-й индекс содержит ширину изображения, а 2-й индекс содержит глубину изображения.
Нахождение компонентов R, G и B изображения

Вывод:
Значение компонентов Синий Зелёный Красный изображения в позиции (321, 308) равно: (238, 242, 253)
Обратите внимание, как значение y передаётся перед значением x — этот синтаксис может показаться неинтуитивным сначала, но он согласуется с тем, как мы получаем значения в матрице: сначала указываем номер строки, затем номер столбца. Оттуда мы получаем кортеж, представляющий компоненты Синий, Зелёный и Красный изображения.
Мы также можем изменить цвет пикселя в заданной позиции, обратив операцию.
# Нахождение R, B, G изображения в позиции (x, y)
import cv2
import argparse
apr = argparse.ArgumentParser()
apr.add_argument(“-i”, “ — image”, required=True, help=”Path to the image”)
args = vars(apr.parse_args())
image = cv2.imread(args[“image”])
# Получение значения координат пикселя как [y, x] от пользователя, для которых нужно вычислить значения RGB
[y,x] = list(int(x.strip()) for x in input().split(‘,’))
# Извлечение значений (Синий, зелёный, красный) полученных координат пикселя
(b,g,r) = image[y,x]
print(f’The Blue Green Red component value of the image at position {(y,x)} is: {(b,g,r)}’)
cv2.imshow(‘Image’, image)
cv2.waitKey(0)(b,g,r) = image[y,x] to image[y,x] = (b,g,r)
Здесь мы присваиваем цвет в (BGR) пикселю изображения по координатам. Давайте попробуем, назначив красный цвет пикселю в позиции (321,308), и проверим это, выведя BGR пикселя в указанной позиции.
# Отмена операции назначения значения RGB пикселю по своему выбору
import cv2
import argparse
apr = argparse.ArgumentParser()
apr.add_argument(“-i”, “ — image”, required=True, help=”Path to the image”)
args = vars(apr.parse_args())
image = cv2.imread(args[“image”])
# Получение значения координат пикселя [y,x] от пользователя, для которого должны быть вычислены значения RGB
[y,x] = list(int(x.strip()) for x in input().split(‘,’))
# Извлечение значений (Синий, Зеленый, Красный) полученной координаты пикселя
image[y,x] = (0,0,255)
(b,g,r) = image[y,x]
print(f’The Blue Green Red component value of the image at position {(y,x)} is: {(b,g,r)}’)
cv2.imshow(‘Image’, image)
cv2.waitKey(0)Вывод:
Значения компонентов Синий, Зеленый и Красный изображения в позиции (321, 308) равны (0, 0, 255)
В приведенном выше коде мы получаем координату пикселя через командную строку, введя значение, как показано на рисунке 2.6 ниже, и назначаем красный цвет координате пикселя, присваивая (0,0,255), то есть (Синий, Зеленый, Красный), и проверяем это, выводя введенную координату пикселя.
Рисование с использованием OpenCV
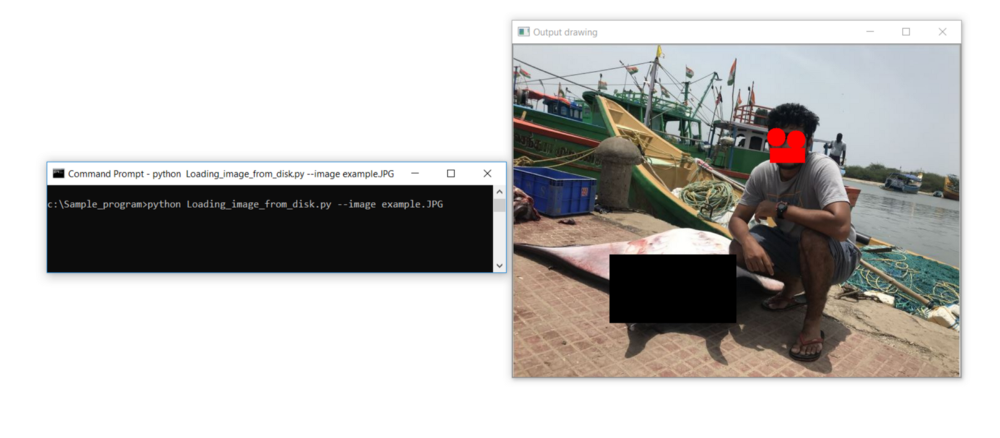
Давайте научимся рисовать различные фигуры, такие как прямоугольники, квадраты и круги, используя OpenCV, нарисовав круги, чтобы замаскировать мои глаза, прямоугольники для маскировки моих губ и прямоугольников для маскировки рыбы мантра-рей рядом со мной.
Вывод должен выглядеть следующим образом:

Это фото замаскировано фигурами с использованием MS Paint; мы попытаемся сделать то же самое, используя OpenCV, нарисовав круги вокруг моих глаз и прямоугольники для маскировки моих губ и рыбы мантра-рей рядом со мной.
Мы используем метод cv2.rectangle для рисования прямоугольника и метод cv2.circle для рисования круга в OpenCV.
cv2.rectangle(image, (x1, y1), (x2, y2), (Blue, Green, Red), Thickness)
Метод cv2.rectangle принимает изображение в качестве первого аргумента, на котором мы хотим нарисовать наш прямоугольник. Мы хотим нарисовать на загруженном объекте изображения, поэтому передаем его в метод. Второй аргумент – это начальная (x1, y1) позиция нашего прямоугольника — здесь мы начинаем наш прямоугольник с точек (156 и 340). Затем мы должны указать конечную (x2, y2) точку для прямоугольника. Мы решаем завершить наш прямоугольник в (360, 450). Следующий аргумент – это цвет прямоугольника, который мы хотим нарисовать; в данном случае мы передаем черный цвет в формате BGR, то есть (0,0,0). Наконец, последний аргумент, который мы передаем, – это толщина линии. Мы даем -1, чтобы нарисовать сплошные фигуры, как видно на рис. 2.6.
Таким же образом мы используем метод cv2.circle для рисования круга.
cv2.circle(image, (x, y), r, (Blue, Green, Red), Thickness)
Метод cv2.circle принимает изображение в качестве первого аргумента, на котором мы хотим нарисовать наш прямоугольник. Мы хотим нарисовать на загруженном объекте изображения, поэтому передаем его в метод. Второй аргумент – это центр (x, y) позиции нашего круга — здесь мы взяли наш круг в точке (343, 243). Следующий аргумент – это радиус круга, который мы хотим нарисовать. Следующий аргумент – это цвет круга; в данном случае мы передаем красный цвет в формате BGR, то есть (0,0,255). Наконец, последний аргумент, который мы передаем, – это толщина линии. Мы даем -1, чтобы нарисовать сплошные фигуры, как видно на рис. 2.6.
Хорошо! Зная все это, давайте попробуем выполнить то, с чего начали. Чтобы нарисовать фигуры на изображении, нам нужно определить начальные и конечные (x, y) координаты маскируемой области, чтобы передать их соответствующему методу.
Как?
Мы снова воспользуемся помощью MS Paint. Помещая курсор над одной из координат (верхний левый угол) или (нижний правый угол) области для маскирования, координаты отображаются в выделенной части MS Paint, как показано на рис. 2.7.
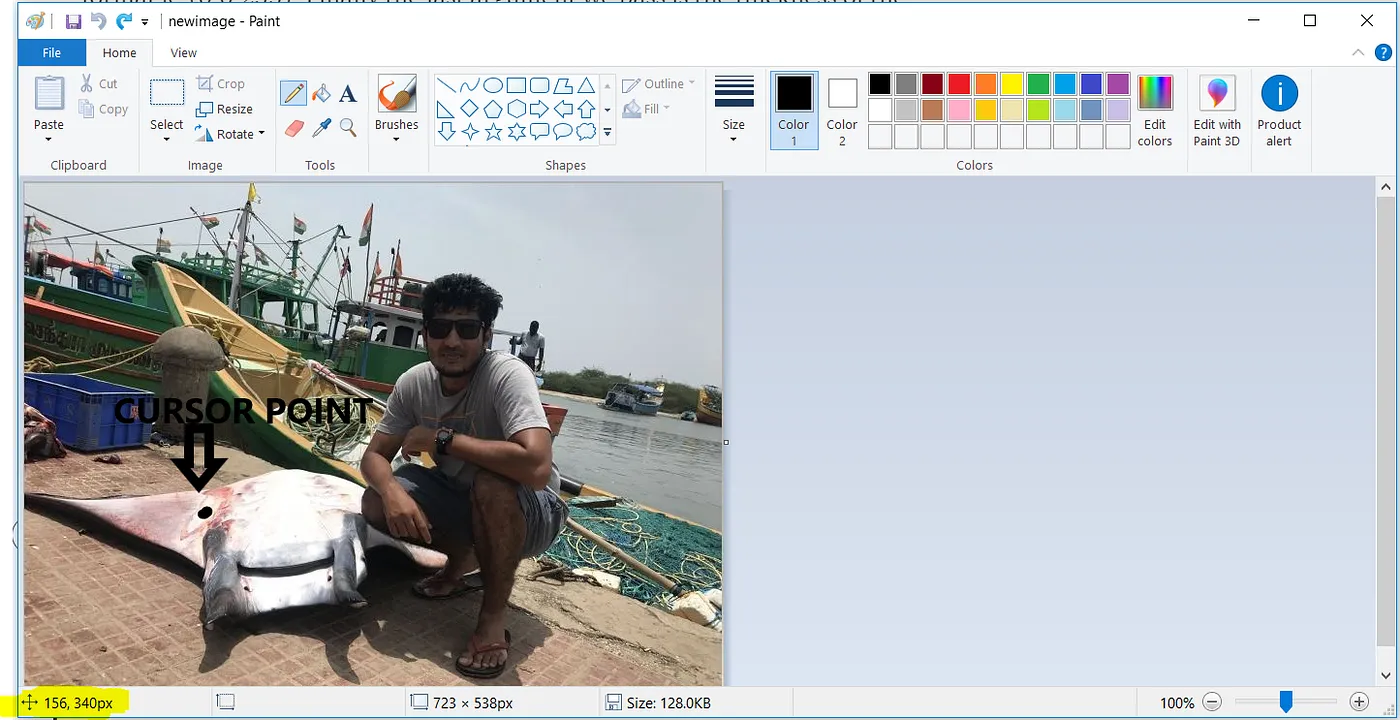
Таким же образом мы возьмем все координаты (x1, y1) (x2, y2) для всех маскируемых областей, как показано на рис. 2.8.

#Рисование с помощью OpenCV для маскировки глаз, рта и объектов поблизости
import cv2
import argparse
apr = argparse.ArgumentParser()
apr.add_argument(“-i”, “ — image”, required=True, help=”Path to the image”)
args = vars(apr.parse_args())
image = cv2.imread(args[“image”])
cv2.rectangle(image, (415, 168), (471, 191), (0, 0, 255), -1)
cv2.circle(image, (425, 150), 15, (0, 0, 255), -1)
cv2.circle(image, (457, 154), 15, (0, 0, 255), -1)
cv2.rectangle(image, (156, 340), (360, 450), (0, 0, 0), -1)
#показать результирующее изображение
cv2.imshow(“Output drawing “, image)
cv2.waitKey(0)Результат:
Source:
https://dzone.com/articles/computer-vision-tutorial-2-image-basics