













本教程作为系列课程的“第2课”,是计算机视觉的基础;后续还有更多课程,将深入探讨如何构建基于深度学习的计算机视觉项目。完整课程大纲和目录请点击此处获取。
本文要点概述如下:
- 从磁盘加载图像。
- 获取图像的“高度”、“宽度”和“深度”。
- 查找图像的R、G、B分量。
- 使用OpenCV进行绘图。
从磁盘加载图像
在对图像进行任何操作或处理之前,我们需要将选定的图像加载到磁盘上。我们将使用OpenCV来完成这一步骤。有两种方法可以执行此加载操作。一种方法是通过简单地将图像路径和文件传递给OpenCV的“imread”函数来加载图像。另一种方法是通过命令行参数,利用Python模块argparse来传递图像。
#从磁盘加载图像
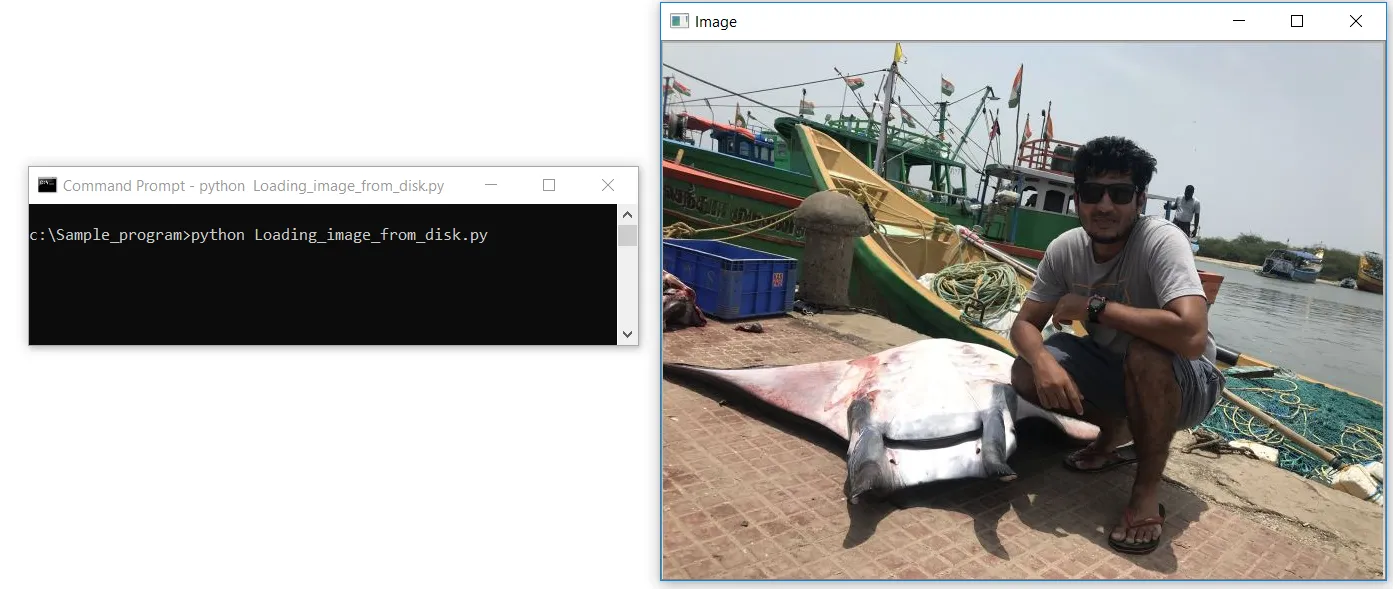
import cv2
image = cv2.imread(“C:/Sample_program/example.jpg”)
cv2.imshow(‘Image’, image)
cv2.waitKey(0)让我们在Notepad++中创建一个名为Loading_image_from_disk.py的文件。首先,我们导入OpenCV库,该库包含我们的图像处理函数。我们使用第一行代码导入库,即cv2。第二行代码是我们使用OpenCV的cv2.imread函数读取图像的地方,我们传递图像的路径作为参数;路径还应包含带有其图像格式扩展名(如.jpg、.jpeg、.png或.tiff)的文件名。
语法— // image=cv2.imread(“path/to/your/image.jpg”) //
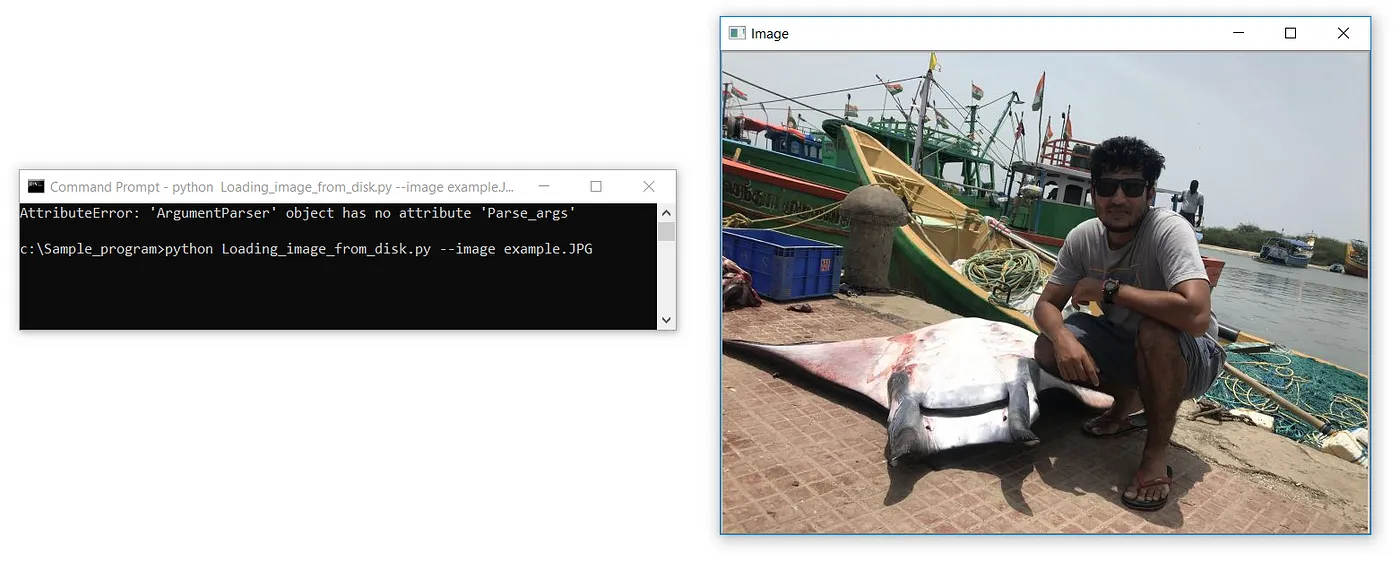
在指定文件扩展名时必须格外小心。如果我们提供了错误的扩展名,很可能会收到以下错误。
ERROR :
c:\Sample_program>python Loading_image_from_disk.py
Traceback (most recent call last):
File “Loading_image_from_disk.py”, line 4, in <module>
cv2.imshow(‘Image’, image)
cv2.error: OpenCV(4.3.0) C:\projects\opencv-python\opencv\modules\highgui\src\window.cpp:376: error: (-215:Assertion failed) size.width>0 && size.height>0 in function ‘cv::imshow’第三行代码是我们实际显示已加载图像的地方。第一个参数是一个字符串,或我们窗口的“名称”。第二个参数是加载图像的对象。
最后,调用cv2.waitKey会暂停脚本的执行,直到我们在键盘上按下一个键。使用参数“0”表示任何按键都会解除暂停执行。请随意在不包含程序最后一行代码的情况下运行您的程序,以查看差异。
#使用Argparse从磁盘读取图像
import cv2
import argparse
apr = argparse.ArgumentParser()
apr.add_argument(“-i”, “ — image”, required=True, help=”Path to the image”)
args = vars(apr.parse_args())
image = cv2.imread(args[“image”])
cv2.imshow(‘Image’, image)
cv2.waitKey(0)知道如何使用命令行参数(argparse)读取图像或文件是一项绝对必要的技能。
前两行代码是导入必要的库;在这里,我们导入OpenCV和Argparse。我们将在整个课程中重复这一点。
以下三行代码负责解析命令行参数。我们唯一需要的参数是—image:磁盘上我们图像的路径。最后,我们解析这些参数并将它们存储在一个名为args的字典中。
让我们花点时间快速讨论一下—image开关究竟是什么。—image“开关”(“开关”是“命令行参数”的同义词,这两个术语可以互换使用)是我们指定在命令行上的一个字符串。这个开关告诉我们的Loading_image_from_disk.py脚本,我们想要加载的图像在磁盘上的位置。
最后三行代码前面已经讨论过;cv2.imread函数以args[“image”]作为参数,这不过是我们通过命令提示符提供的图像。cv2.imshow显示图像,该图像已经从前一行存储在图像对象中。最后一行暂停脚本的执行,直到我们在键盘上按下一个键。
使用argparse—命令行参数的一个主要优点是,我们将能够从不同的文件夹位置加载图像,而不必在我们的程序中更改图像路径,只需动态传递图像路径,例如在执行我们的Python程序时,在命令提示符下作为参数传递“C:\CV_Material\image\sample.jpg”。
c:\Sample_program>python Loading_image_from_disk.py — image C:\CV_Material\session1.JPG
这里,我们正在执行Loading_image_from_disk.pyPython文件,从c:\sample_program位置通过传递“-image”参数以及图像路径C:\CV_Material\session1.JPG.
获取图像的‘高度’、‘宽度’和‘深度’
由于图像以NumPy数组形式表示,我们可以简单地使用`.shape`属性来检查其宽度、高度和通道数。
通过在刚加载的图像对象上应用`.shape`属性,我们可以获取图像的高度、宽度和深度。如前一课—1所述,图像的高度和宽度可通过在MS Paint中打开图像进行交叉验证。请参考前一课。我们将在后续课程中讨论图像的深度,深度也称为图像的通道。彩色图像通常有3个通道,因为其像素由RGB组成,而灰度图像则有1个通道。这一点我们在前一课-1中已经讨论过。
# 获取图像的高度、宽度和深度
import cv2
import argparse
apr = argparse.ArgumentParser()
apr.add_argument(“-i”, “ — image”, required=True, help=”Path to the image”)
args = vars(apr.parse_args())
# 与前述代码的唯一区别——在图像对象上应用了shape属性
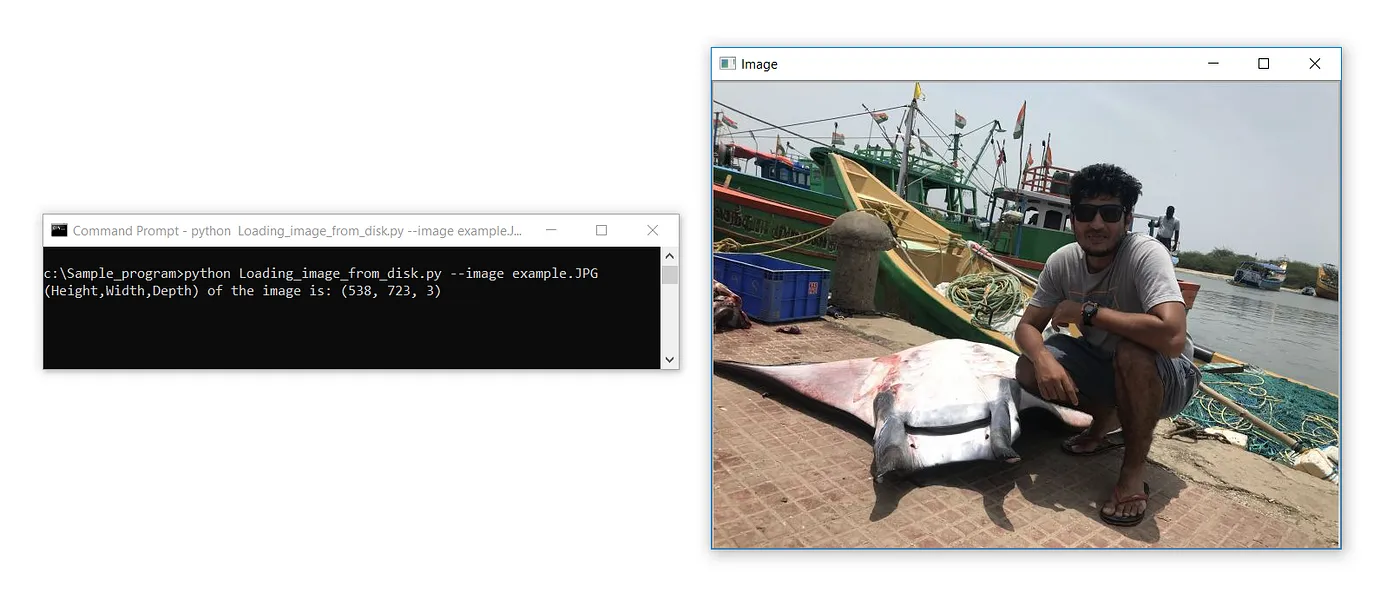
print(f’(Height,Width,Depth) of the image is: {image.shape}’)
image = cv2.imread(args[“image”])
cv2.imshow(‘Image’, image)
cv2.waitKey(0)输出:
图像的高度、宽度和深度为:(538, 723, 3)
与前述代码的唯一区别在于,打印语句对加载的图像对象应用了`shape`属性。f’是F-字符串或格式化字符串,它动态地接受变量并进行打印。
f’ write anything here that you want to see in the print statement: {variables, variables, object, object.attribute,}’
在此,我们通过花括号内的{object.attribute}来获取.shape属性,从而计算图像对象的高度、宽度和深度。
#单独获取高度、宽度和深度
import cv2
import argparse
apr = argparse.ArgumentParser()
apr.add_argument(“-i”, “ — image”, required=True, help=”Path to the image”)
args = vars(apr.parse_args())
image = cv2.imread(args[“image”])
#使用NumPy数组切片分别获取高度、宽度和深度
print(“height: %d pixels” % (image.shape[0]))
print(“width: %d pixels” % (image.shape[1]))
print(“depth: %d” % (image.shape[2]))
cv2.imshow(‘Image’, image)
cv2.waitKey(0)输出:
宽度: 723像素
高度: 538像素
深度: 3
这里,我们不是一次性获取(高度、宽度和深度)作为一个元组。而是通过数组切片,分别获取图像的高度、宽度和深度。数组的第0个索引包含图像的高度,第1个索引包含图像的宽度,第2个索引包含图像的深度。
查找图像的R、G和B成分

输出:
图像在位置(321, 308)处的蓝绿红成分值为: (238, 242, 253)
注意y值在x值之前传递的方式——这种语法一开始可能感觉反直觉,但它与我们访问矩阵中值的方式一致:首先指定行号,然后是列号。这样,我们得到一个元组,表示图像的蓝、绿和红成分。
我们还可以通过反向操作改变给定位置像素的颜色。
#在(x,y)位置查找图像的R、B、G值
import cv2
import argparse
apr = argparse.ArgumentParser()
apr.add_argument(“-i”, “ — image”, required=True, help=”Path to the image”)
args = vars(apr.parse_args())
image = cv2.imread(args[“image”])
#从用户处接收像素坐标值[y,x],以计算RGB值
[y,x] = list(int(x.strip()) for x in input().split(‘,’))
#提取接收像素坐标的(蓝、绿、红)值
(b,g,r) = image[y,x]
print(f’The Blue Green Red component value of the image at position {(y,x)} is: {(b,g,r)}’)
cv2.imshow(‘Image’, image)
cv2.waitKey(0)(b,g,r) = image[y,x] 转换为 image[y,x] = (b,g,r)
这里我们将颜色(BGR)分配给图像像素坐标。让我们尝试将红色分配给位置(321,308)的像素,并通过打印该位置的像素BGR来验证这一点。
# 反向操作,将RGB值分配给我们选择的像素
import cv2
import argparse
apr = argparse.ArgumentParser()
apr.add_argument(“-i”, “ — image”, required=True, help=”Path to the image”)
args = vars(apr.parse_args())
image = cv2.imread(args[“image”])
# 从用户接收像素坐标值[y,x],需要计算RGB值
[y,x] = list(int(x.strip()) for x in input().split(‘,’))
# 提取接收到的像素坐标的(蓝色,绿色,红色)值
image[y,x] = (0,0,255)
(b,g,r) = image[y,x]
print(f’The Blue Green Red component value of the image at position {(y,x)} is: {(b,g,r)}’)
cv2.imshow(‘Image’, image)
cv2.waitKey(0)输出:
图像在位置(321, 308)的蓝色、绿色和红色分量值为(0, 0, 255)
在上面的代码中,我们通过命令提示符输入如图2.6所示的值来接收像素坐标,并通过分配(0,0,255)即(蓝色,绿色,红色)来为像素坐标分配红色,并通过打印输入的像素坐标来验证这一点。
使用OpenCV绘图
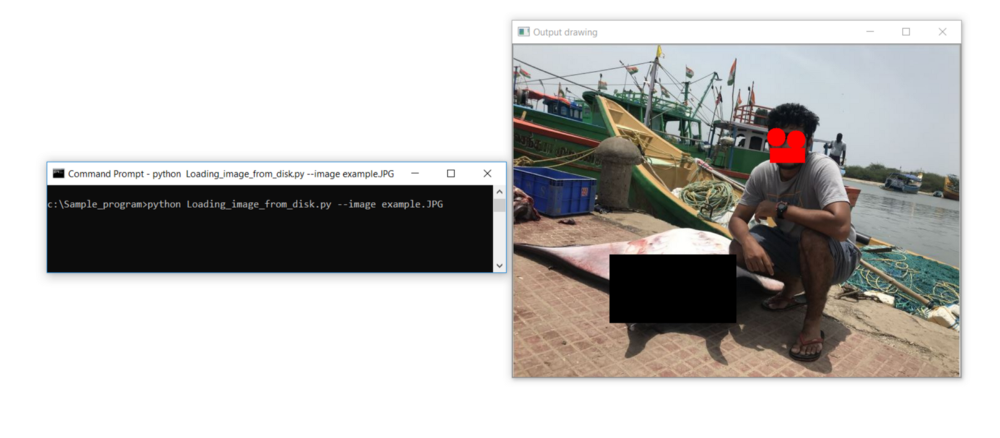
让我们学习如何使用OpenCV绘制不同的形状,如矩形、正方形和圆形,通过绘制圆圈来遮盖我的眼睛,矩形来遮盖我的嘴唇,以及矩形来遮盖我旁边的mantra-ray鱼。
输出应如下所示:

这张照片使用MS Paint进行了形状遮盖;我们将尝试使用OpenCV通过在我的眼睛周围绘制圆圈和矩形来遮盖我的嘴唇和我旁边的matra-ray鱼来实现相同的效果。
我们使用cv2.rectangle方法在OpenCV中绘制矩形,使用cv2.circle方法绘制圆圈。
cv2.rectangle(image, (x1, y1), (x2, y2), (Blue, Green, Red), Thickness)
cv2.rectangle方法的第一个参数是我们要在其上绘制矩形的图像。这里,我们将加载的图像对象传递给该方法。第二个参数是矩形的起始(x1, y1)位置,我们在此从(156, 340)开始绘制矩形。接着,必须提供矩形的结束(x2, y2)点,我们决定在(360, 450)处结束矩形。接下来的参数是矩形的颜色,此处我们以BGR格式传入黑色,即(0,0,0)。最后一个参数是线条的粗细,我们传入-1以绘制实心形状,如图2.6所示。
同样,我们使用cv2.circle方法来绘制圆。
cv2.circle(image, (x, y), r, (Blue, Green, Red), Thickness)
cv2.circle方法的第一个参数是我们要在其上绘制圆的图像。这里,我们将已加载的图像对象传递给该方法。第二个参数是圆心的(x, y)位置,我们在此将圆心设在(343, 243)。接下来的参数是圆的半径。再之后的参数是圆的颜色,此处我们以BGR格式传入红色,即(0,0,255)。最后一个参数是线条的粗细,我们同样传入-1以绘制实心形状,如图2.6所示。
好的!了解这些之后,让我们开始尝试完成我们的目标。为了在图像中绘制形状,我们需要确定遮罩区域的起点和终点(x,y)坐标,以便将其传递给相应的方法。
如何操作?
我们将再次借助MS Paint的帮助。通过将光标放置在遮罩区域的一个坐标点(左上角或右下角)上,坐标会显示在MS Paint中高亮的部分,如图2.7所示。
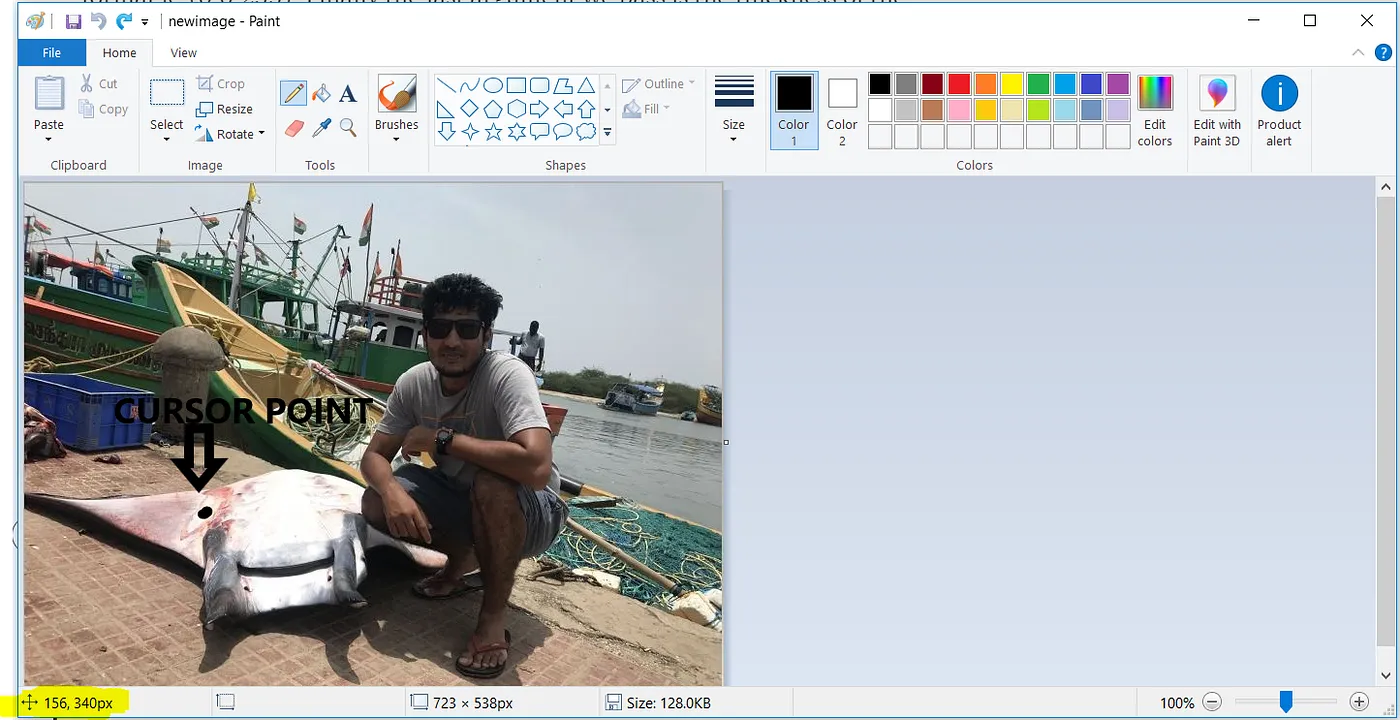
同样地,我们将获取所有遮罩区域的坐标(x1,y1)(x2,y2),如图2.8所示。

#使用OpenCV绘制以遮盖眼睛、嘴巴及附近物体
import cv2
import argparse
apr = argparse.ArgumentParser()
apr.add_argument(“-i”, “ — image”, required=True, help=”Path to the image”)
args = vars(apr.parse_args())
image = cv2.imread(args[“image”])
cv2.rectangle(image, (415, 168), (471, 191), (0, 0, 255), -1)
cv2.circle(image, (425, 150), 15, (0, 0, 255), -1)
cv2.circle(image, (457, 154), 15, (0, 0, 255), -1)
cv2.rectangle(image, (156, 340), (360, 450), (0, 0, 0), -1)
#显示输出图像
cv2.imshow(“Output drawing “, image)
cv2.waitKey(0)结果:
Source:
https://dzone.com/articles/computer-vision-tutorial-2-image-basics