













Dieses Tutorial ist die Grundlage der Bildverarbeitung, die als „Lektion 2“ der Serie vermittelt wird; es gibt weitere Lektionen, die auf die Erstellung eigener Bildverarbeitungsprojekte auf Deep-Learning-Basis eingehen werden. Sie können das komplette Curriculum und Inhaltsverzeichnis hier finden.
Die wichtigsten Lernziele dieses Artikels:
- Laden eines Bildes von der Festplatte.
- Ermitteln der ‚Höhe‘, ‚Breite‘ und ‚Tiefe‘ des Bildes.
- Ermitteln der R, G und B-Komponenten des Bildes.
- Zeichnen mit OpenCV.
Laden eines Bildes von der Festplatte
Bevor wir Operationen oder Manipulationen an einem Bild durchführen, ist es wichtig, ein Bild unserer Wahl auf die Festplatte zu laden. Wir werden diese Aktivität mit OpenCV durchführen. Es gibt zwei Möglichkeiten, diese Ladung durchzuführen. Eine Möglichkeit besteht darin, das Bild einfach durch Übergabe des Bildpfads und des Bilddateinamens an die OpenCV-Funktion „imread“ zu laden. Die andere Möglichkeit besteht darin, das Bild über einen Befehlszeilenargument mit dem Python-Modul argparse zu übergeben.
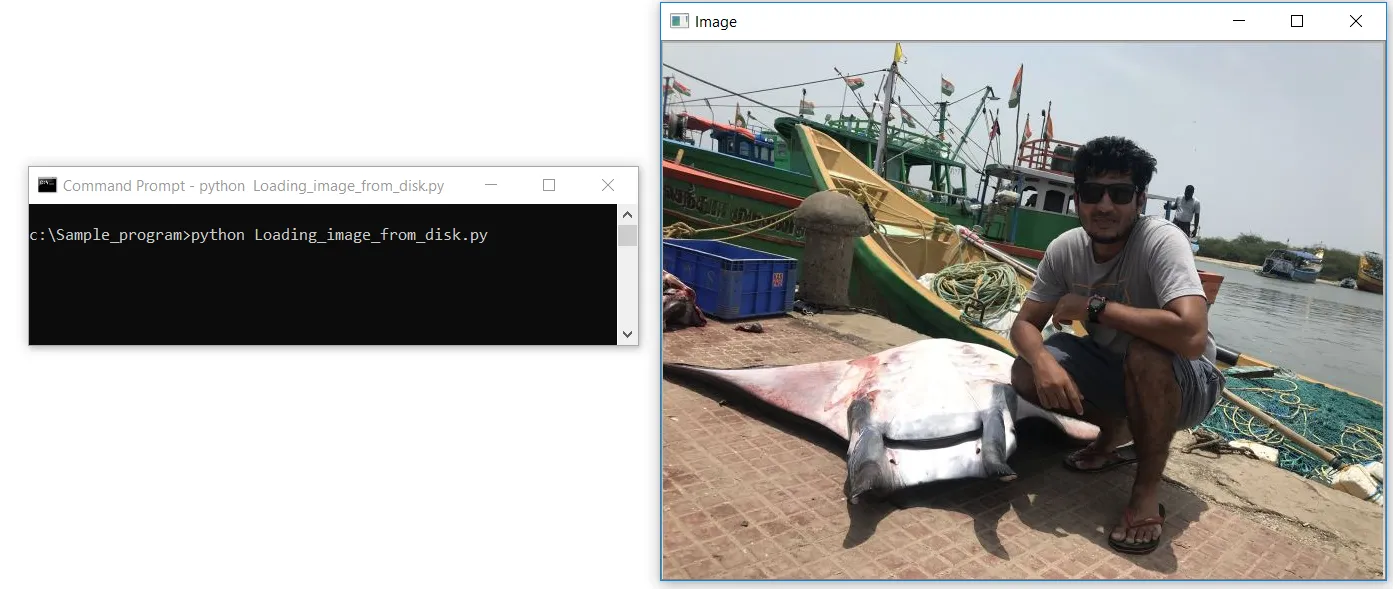
#Laden eines Bildes von der Festplatte
import cv2
image = cv2.imread(“C:/Sample_program/example.jpg”)
cv2.imshow(‘Image’, image)
cv2.waitKey(0)Lass uns eine Datei namens Loading_image_from_disk.py in Notepad++ erstellen. Zuerst importieren wir unsere OpenCV-Bibliothek, die unsere Bildverarbeitungsfunktionen enthält. Wir importieren die Bibliothek mit der ersten Codezeile als cv2. Die zweite Codezeile ist dort, wo wir unser Bild mit der cv2.imread-Funktion in OpenCV lesen, und wir den Pfad des Bildes als Parameter übergeben; der Pfad sollte auch den Dateinamen mit seiner Bildformat-Erweiterung .jpg, .jpeg, .png oder .tiff enthalten.
Syntax — // image=cv2.imread(„pfad/zu/deinem/bild.jpg“) //
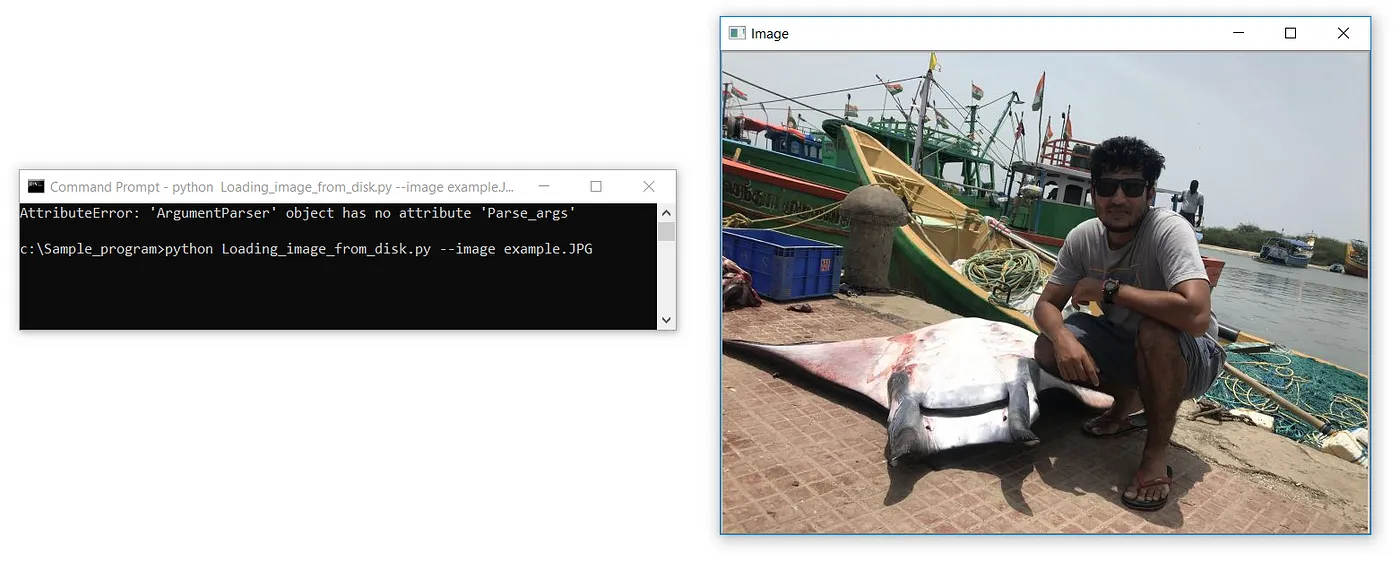
Bei der Angabe des Dateierweiterungsnamens muss absolut aufgepasst werden. Wir erhalten wahrscheinlich den folgenden Fehler, wenn wir die falsche Erweiterung angeben.
ERROR :
c:\Sample_program>python Loading_image_from_disk.py
Traceback (most recent call last):
File “Loading_image_from_disk.py”, line 4, in <module>
cv2.imshow(‘Image’, image)
cv2.error: OpenCV(4.3.0) C:\projects\opencv-python\opencv\modules\highgui\src\window.cpp:376: error: (-215:Assertion failed) size.width>0 && size.height>0 in function ‘cv::imshow’Die dritte Codezeile ist dort, wo wir das geladene Bild tatsächlich anzeigen. Der erste Parameter ist ein String oder der „Name“ unseres Fensters. Der zweite Parameter ist das Objekt, auf das das Bild geladen wurde.
Schließlich pausiert ein Aufruf von cv2.waitKey die Ausführung des Skripts, bis wir eine Taste auf unserer Tastatur drücken. Mit einem Parameter von „0“ wird angezeigt, dass das Drücken einer beliebigen Taste die Ausführung fortsetzt. Führen Sie Ihr Programm gerne ohne die letzte Codezeile in Ihrem Programm aus, um den Unterschied zu sehen.
#Bild von der Festplatte mit Argparse lesen
import cv2
import argparse
apr = argparse.ArgumentParser()
apr.add_argument(“-i”, “ — image”, required=True, help=”Path to the image”)
args = vars(apr.parse_args())
image = cv2.imread(args[“image”])
cv2.imshow(‘Image’, image)
cv2.waitKey(0)Das Lesen eines Bildes oder einer Datei mit einem Befehlszeilenargument (argparse) ist eine absolut notwendige Fähigkeit.
Die ersten beiden Codezeilen dienen zum Import der notwendigen Bibliotheken; hier importieren wir OpenCV und Argparse. Wir werden dies im Verlauf des Kurses immer wieder tun.
Die folgenden drei Codezeilen behandeln das Parsen der Kommandozeilenargumente. Das einzige Argument, das wir benötigen, ist — image: dem Pfad zu unserem Bild auf der Festplatte. Schließlich parsen wir die Argumente und speichern sie in einem Wörterbuch namens args.
Nehmen wir uns einen Moment Zeit und diskutieren kurz genau, was der — image Schalter ist. Der — image „Schalter“ („Schalter“ ist ein Synonym für „Kommandozeilenargument“ und die Begriffe können synonym verwendet werden) ist ein String, den wir in der Kommandozeile angeben. Dieser Schalter teilt unserem Loading_image_from_disk.py Skript mit, wo das Bild, das wir laden möchten, auf der Festplatte gespeichert ist.
Die letzten drei Codezeilen wurden bereits diskutiert; die cv2.imread-Funktion nimmt args[“image”] als Parameter, was nichts anderes ist als das Bild, das wir in der Eingabeaufforderung angeben. cv2.imshow zeigt das Bild an, das bereits in einem Bildobjekt aus der vorherigen Zeile gespeichert ist. Die letzte Zeile pausiert die Ausführung des Skripts, bis wir eine Taste auf unserer Tastatur drücken.
Einer der Hauptvorteile der Verwendung eines argparse — Kommandozeilenarguments ist, dass wir Bilder aus verschiedenen Ordnerpositionen laden können, ohne den Bildpfad in unserem Programm dynamisch durch Übergeben des Bildpfads bei der Ausführung unseres Python-Programms ändern zu müssen. Ex — “ C:\CV_Material\image\sample.jpg “ in der Eingabeaufforderung als Argument.
c:\Sample_program>python Loading_image_from_disk.py — image C:\CV_Material\session1.JPG
Hier führen wir die Loading_image_from_disk.py Python-Datei von der c:\sample_program Position aus, indem wir das “-image”-Parameter zusammen mit dem Pfad des Bildes C:\CV_Material\session1.JPG. übergeben.
Erhalten der ‘Höhe’, ‘Breite’ und ‘Tiefe’ des Bildes
Da Bilder als NumPy-Arrays dargestellt werden, können wir einfach das Attribut .shape verwenden, um die Breite, Höhe und die Anzahl der Kanäle zu untersuchen.
Indem wir das Attribut .shape auf dem gerade geladenen Bildobjekt anwenden, können wir die Höhe, Breite und Tiefe des Bildes ermitteln. Wie in der vorherigen Lektion — 1 besprochen, können die Höhe und Breite des Bildes durch Öffnen des Bildes in MS Paint überprüft werden. Siehe die vorherige Lektion. Wir werden in den kommenden Lektionen über die Tiefe des Bildes sprechen. Die Tiefe wird auch als Kanal eines Bildes bezeichnet. Farbbilder haben normalerweise 3 Kanäle aufgrund der RGB-Zusammensetzung in ihren Pixeln und Graustufenbilder haben 1 Kanal. Das haben wir in der vorherigen Lektion-1 besprochen.
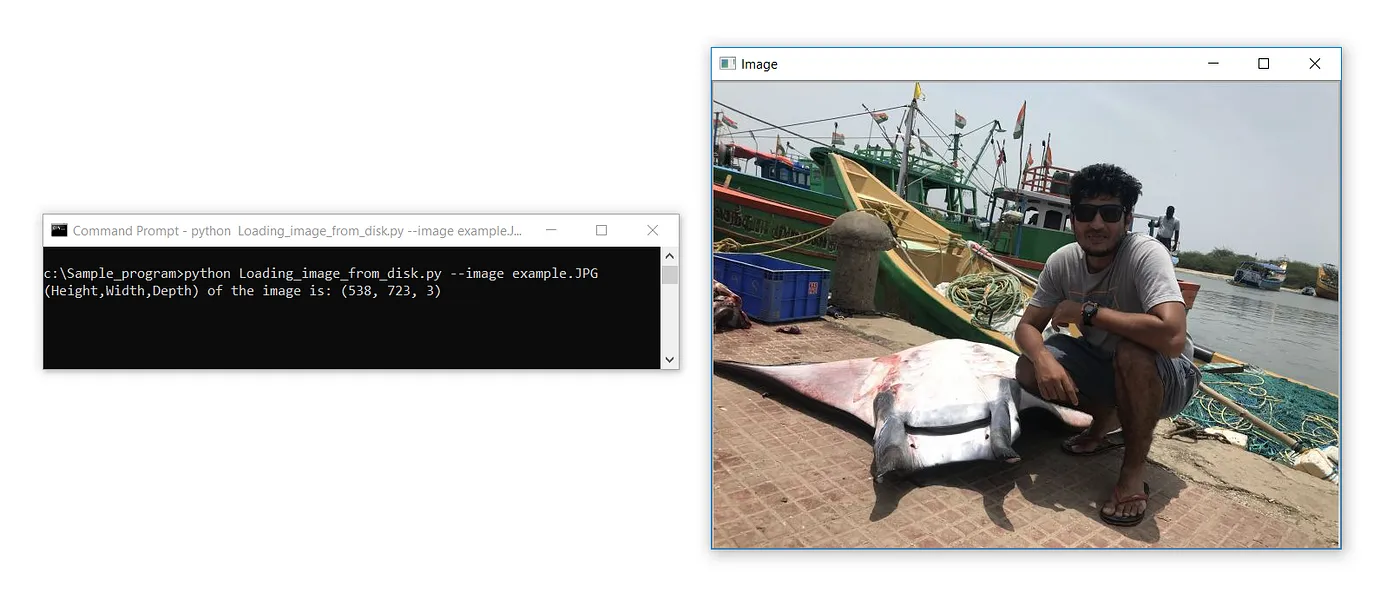
#Ermittlung von Höhe, Breite und Tiefe eines Bildes
import cv2
import argparse
apr = argparse.ArgumentParser()
apr.add_argument(“-i”, “ — image”, required=True, help=”Path to the image”)
args = vars(apr.parse_args())
# Einziger Unterschied zu den vorherigen Codes — Anwendung des shape-Attributs auf das Bildobjekt
print(f’(Height,Width,Depth) of the image is: {image.shape}’)
image = cv2.imread(args[“image”])
cv2.imshow(‘Image’, image)
cv2.waitKey(0)Ausgabe:
(Höhe, Breite, Tiefe) des Bildes ist: (538, 723, 3)
Der einzige Unterschied zu den vorherigen Codes ist die print-Anweisung, die das shape-Attribut auf das geladene Bildobjekt anwendet. f’ ist der F-String, eine formatierte Zeichenkette, die Variablen dynamisch aufnimmt und ausgibt.
f’ write anything here that you want to see in the print statement: {variables, variables, object, object.attribute,}’
Hier haben wir {object.attribute} innerhalb der geschweiften Klammern für das .shape-Attribut verwendet, um die Höhe, Breite und Tiefe des Bildobjekts zu berechnen.
#Erhaltung der Höhe, Breite und Tiefe separat
import cv2
import argparse
apr = argparse.ArgumentParser()
apr.add_argument(“-i”, “ — image”, required=True, help=”Path to the image”)
args = vars(apr.parse_args())
image = cv2.imread(args[“image”])
#NumPy-Array-Slicing zur separaten Erhaltung der Höhe, Breite und Tiefe
print(“height: %d pixels” % (image.shape[0]))
print(“width: %d pixels” % (image.shape[1]))
print(“depth: %d” % (image.shape[2]))
cv2.imshow(‘Image’, image)
cv2.waitKey(0)Ausgabe:
Breite: 723 Pixel
Höhe: 538 Pixel
Tiefe: 3
Hier erhalten wir anstelle der (Höhe, Breite und Tiefe) zusammen als Tupel. Wir führen Array-Slicing durch und erhalten die Höhe, Breite und Tiefe des Bildes individuell. Der 0. Index des Arrays enthält die Höhe des Bildes, der 1. Index die Breite des Bildes und der 2. Index die Tiefe des Bildes.
Ermittlung der R, G und B-Komponenten des Bildes

Ausgabe:
Der Blau-Grün-Rot-Komponentenwert des Bildes an der Position (321, 308) ist: (238, 242, 253)
Beachten Sie, wie der y-Wert vor dem x-Wert übergeben wird – diese Syntax mag zunächst ungewohnt erscheinen, ist aber mit der Art und Weise, wie wir Werte in einer Matrix abrufen: Zuerst geben wir die Zeilennummer an, dann die Spaltennummer. Von dort aus erhalten wir ein Tupel, das die Bild-Blau-, Grün- und Rot-Komponenten darstellt.
Wir können auch die Farbe eines Pixels an einer bestimmten Position durch Umkehrung der Operation ändern.
#Ermittlung von R,B,G des Bildes an der (x,y)-Position
import cv2
import argparse
apr = argparse.ArgumentParser()
apr.add_argument(“-i”, “ — image”, required=True, help=”Path to the image”)
args = vars(apr.parse_args())
image = cv2.imread(args[“image”])
# Empfangen Sie den Pixel-Koordinatenwert als [y,x] vom Benutzer, für den die RGB-Werte berechnet werden müssen
[y,x] = list(int(x.strip()) for x in input().split(‘,’))
# Extrahieren Sie die (Blau,grün,rot)-Werte der empfangenen Pixel-Koordinate
(b,g,r) = image[y,x]
print(f’The Blue Green Red component value of the image at position {(y,x)} is: {(b,g,r)}’)
cv2.imshow(‘Image’, image)
cv2.waitKey(0)(b,g,r) = image[y,x] to image[y,x] = (b,g,r)
Hier weisen wir der Farbe in (BGR) das Bildpixel-Koordinat zu. Versuchen wir, dem Pixel an der Position (321,308) die Farbe ROT zuzuweisen und das gleiche durch Drucken der BGR des Pixels an der gegebenen Position zu validieren.
#Umkehren der Operation zur Zuweisung des RGB-Werts zum gewünschten Pixel
import cv2
import argparse
apr = argparse.ArgumentParser()
apr.add_argument(“-i”, “ — image”, required=True, help=”Path to the image”)
args = vars(apr.parse_args())
image = cv2.imread(args[“image”])
# Empfangen des Pixel-Koordinatenwerts als [y,x] vom Benutzer, für den die RGB-Werte berechnet werden müssen
[y,x] = list(int(x.strip()) for x in input().split(‘,’))
# Extrahieren der (Blau, grün, rot) Werte des empfangenen Pixel-Koordinaten
image[y,x] = (0,0,255)
(b,g,r) = image[y,x]
print(f’The Blue Green Red component value of the image at position {(y,x)} is: {(b,g,r)}’)
cv2.imshow(‘Image’, image)
cv2.waitKey(0)Ausgabe:
Die Blau-, Grün- und Rotkomponentenwerte des Bildes an der Position (321, 308) sind (0, 0, 255)
Im obigen Code erhalten wir das Pixel-Koordinat über die Kommandozeile, indem wir den Wert wie in Fig 2.6 unten gezeigt eingeben, und weisen dem Pixel-Koordinat die Farbe ROT zu, indem wir (0,0,255) zugewiesen haben, d.h. (Blau, Grün, Rot), und validieren das gleiche durch Drucken des eingegebenen Pixel-Koordinaten.
Zeichnen mit OpenCV
Lernen wir, wie man verschiedene Formen wie Rechtecke, Quadrate und Kreise mit OpenCV zeichnet, indem wir Kreise zeichnen, um meine Augen zu maskieren, Rechtecke, um meine Lippen zu maskieren, und Rechtecke, um den Mantarochen neben mir zu maskieren.
Die Ausgabe sollte so aussehen:

Dieses Foto ist mit Formen mit MS Paint maskiert; wir werden versuchen, dasselbe mit OpenCV zu tun, indem wir Kreise um meine Augen zeichnen und Rechtecke, um meine Lippen und den Mantarochen neben mir zu maskieren.
Wir verwenden die Methode cv2.rectangle, um ein Rechteck zu zeichnen, und die Methode cv2.circle, um einen Kreis in OpenCV zu zeichnen.
cv2.rectangle(image, (x1, y1), (x2, y2), (Blue, Green, Red), Thickness)
Die Methode cv2.rectangle nimmt als erstes Argument ein Bild, auf dem wir unseren Rechteck zeichnen möchten. Wir möchten auf das geladene Bildobjekt zeichnen, also übergeben wir es an die Methode. Das zweite Argument ist der Startpunkt (x1, y1) unseres Rechtecks — hier beginnen wir unser Rechteck an den Punkten (156 und 340). Dann müssen wir einen Endpunkt (x2, y2) für das Rechteck angeben. Wir entscheiden uns dafür, unser Rechteck bei (360, 450) zu beenden. Das nächste Argument ist die Farbe des Rechtecks, das wir zeichnen möchten; in diesem Fall übergeben wir die Farbe Schwarz im BGR-Format, also (0,0,0). Zuletzt übergeben wir das Argument für die Strichdicke. Wir geben -1, um solide Formen zu zeichnen, wie in Abbildung 2.6 zu sehen.
Ebenso verwenden wir die Methode cv2.circle, um einen Kreis zu zeichnen.
cv2.circle(image, (x, y), r, (Blue, Green, Red), Thickness)
Die Methode cv2.circle nimmt als erstes Argument ein Bild, auf dem wir unseren Kreis zeichnen möchten. Wir möchten auf das geladene Bildobjekt zeichnen, also übergeben wir es an die Methode. Das zweite Argument ist der Mittelpunkt (x, y) unseres Kreises — hier haben wir unseren Kreis an dem Punkt (343, 243) genommen. Das nächste Argument ist der Radius des Kreises, den wir zeichnen möchten. Das folgende Argument ist die Farbe des Kreises; in diesem Fall übergeben wir die Farbe Rot im BGR-Format, also (0,0,255). Zuletzt übergeben wir das Argument für die Strichdicke. Wir geben -1, um solide Formen zu zeichnen, wie in Abbildung 2.6 zu sehen.
Okay! Kenntnisse in diesbezüglichen Hinsichten vorausgesetzt, versuchen wir, das zu erreichen, was wir begonnen haben. Um die Formen in der Abbildung zu zeichnen, müssen wir den Start- und Endkoordinaten (x, y) der Maskierungsregionen identifizieren, um sie an die entsprechenden Methoden weiterzugeben.
Wie?
Wir werden noch einmal die Hilfe von MS Paint in Anspruch nehmen. Indem wir den Cursor über eines der Koordinaten (oben links) oder (unten rechts) der zu maskierenden Region positionieren, werden die Koordinaten im hervorgehobenen Bereich von MS Paint wie in Abbildung 2.7 gezeigt angezeigt.
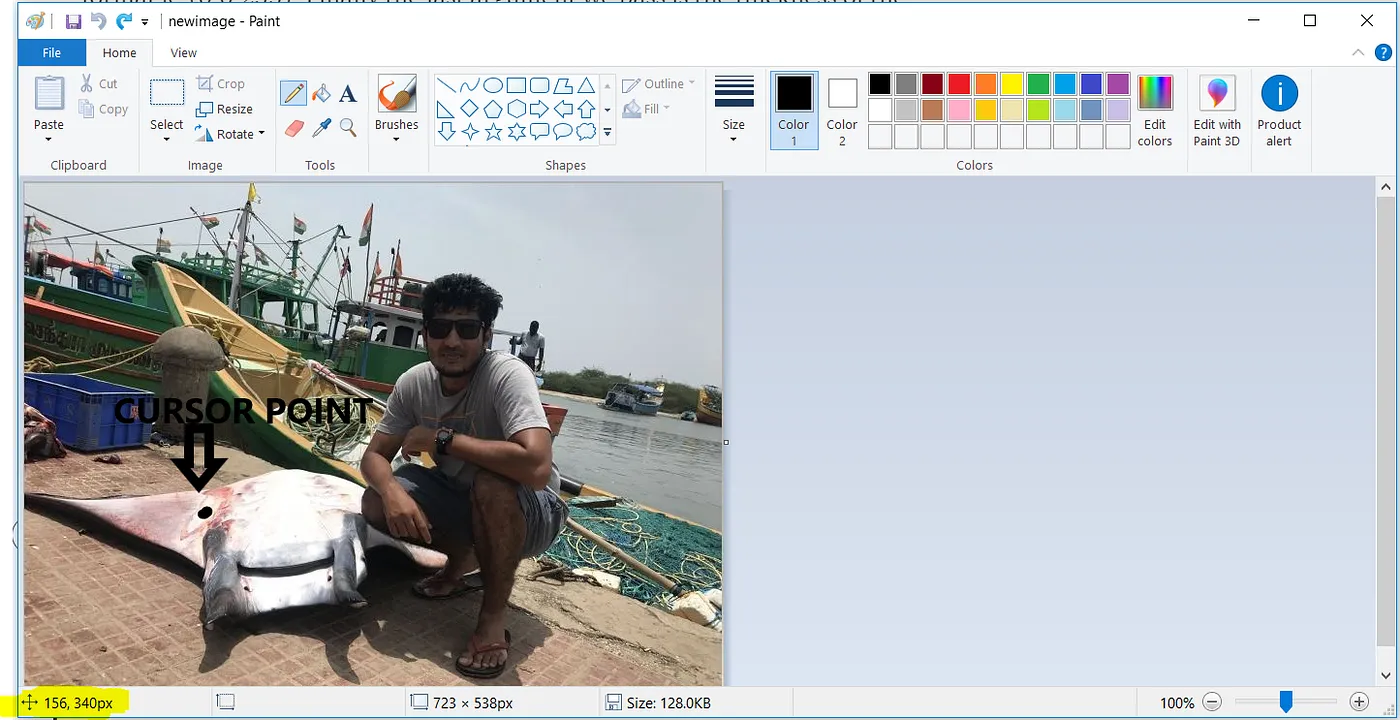
Ebenso werden wir alle Koordinaten (x1, y1) (x2, y2) für alle Maskierungsregionen wie in Abbildung 2.8 gezeigt erfassen.

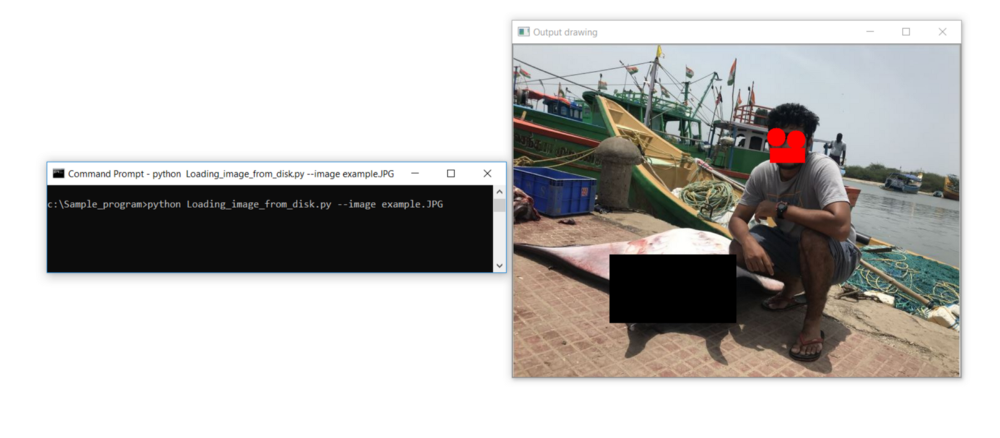
#Zeichnen mit OpenCV zur Maskierung von Augen, Mund und Objekten in der Nähe
import cv2
import argparse
apr = argparse.ArgumentParser()
apr.add_argument(“-i”, “ — image”, required=True, help=”Path to the image”)
args = vars(apr.parse_args())
image = cv2.imread(args[“image”])
cv2.rectangle(image, (415, 168), (471, 191), (0, 0, 255), -1)
cv2.circle(image, (425, 150), 15, (0, 0, 255), -1)
cv2.circle(image, (457, 154), 15, (0, 0, 255), -1)
cv2.rectangle(image, (156, 340), (360, 450), (0, 0, 0), -1)
#zeige das Ausgabebild
cv2.imshow(“Output drawing “, image)
cv2.waitKey(0)Ergebnis:
Source:
https://dzone.com/articles/computer-vision-tutorial-2-image-basics