













Questo tutorial costituisce la base della visione artificiale fornita come “Lezione 2” della serie; sono previste altre lezioni che tratteranno a fondo la creazione di progetti di visione artificiale basati su deep learning. Potete trovare il sistema di insegnamento completo e indice.
I principali concetti chiave di questo articolo:
- Caricamento di un’immagine dal disco.
- Ottenimento dell’altezza, larghezza e profondità dell’immagine.
- Ricerca dei componenti R, G e B dell’immagine.
- Disegno utilizzando OpenCV.
Caricamento di un’Immagine dal Disco
Prima di eseguire qualsiasi operazione o manipolazione di un’immagine, è importante per noi caricare un’immagine a nostra scelta sul disco. Effettueremo questa attività utilizzando OpenCV. Esistono due modi per eseguire questa operazione di caricamento. Un modo è caricare l’immagine semplicemente passando il percorso dell’immagine e il file immagine alla funzione “imread” di OpenCV. L’altro modo è passare l’immagine attraverso un argomento della riga di comando utilizzando il modulo python argparse.
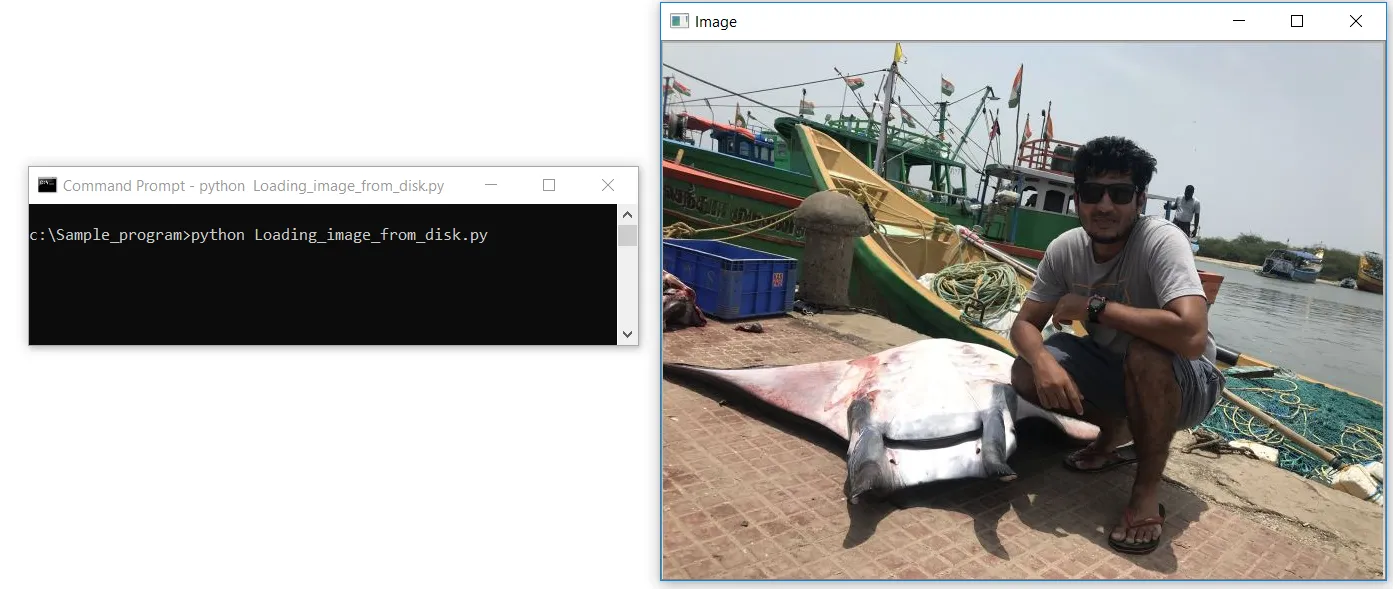
#Caricamento dell'Immagine dal disco
import cv2
image = cv2.imread(“C:/Sample_program/example.jpg”)
cv2.imshow(‘Image’, image)
cv2.waitKey(0)Creiamo un file chiamato Loading_image_from_disk.py in Notepad++. Innanzitutto, importiamo la nostra libreria OpenCV, che contiene le funzioni di elaborazione delle immagini. Importiamo la libreria utilizzando la prima riga di codice come cv2. La seconda riga di codice è dove leggiamo la nostra immagine utilizzando la funzione cv2.imread in OpenCV, e passiamo il percorso dell’immagine come parametro; il percorso dovrebbe anche contenere il nome del file con l’estensione del formato dell’immagine .jpg, .jpeg, .png o .tiff.
sintassi — // image=cv2.imread(“path/to/your/image.jpg”) //
Bisogna prestare molta attenzione nella specifica del nome dell’estensione del file. Rischiamo di ricevere il seguente errore se forniamo l’estensione errata.
ERROR :
c:\Sample_program>python Loading_image_from_disk.py
Traceback (most recent call last):
File “Loading_image_from_disk.py”, line 4, in <module>
cv2.imshow(‘Image’, image)
cv2.error: OpenCV(4.3.0) C:\projects\opencv-python\opencv\modules\highgui\src\window.cpp:376: error: (-215:Assertion failed) size.width>0 && size.height>0 in function ‘cv::imshow’La terza riga di codice è dove effettivamente visualizziamo l’immagine caricata. Il primo parametro è una stringa, o il “nome” della nostra finestra. Il secondo parametro è l’oggetto a cui è stata caricata l’immagine.
Infine, una chiamata a cv2.waitKey mette in pausa l’esecuzione dello script fino a quando non premiamo un tasto sulla nostra tastiera. Utilizzare un parametro di “0” indica che qualsiasi pressione di tasto sbloccherà l’esecuzione. Sentiti libero di eseguire il tuo programma senza avere l’ultima riga di codice nel tuo programma per vedere la differenza.
#Lettura dell'immagine da disco utilizzando Argparse
import cv2
import argparse
apr = argparse.ArgumentParser()
apr.add_argument(“-i”, “ — image”, required=True, help=”Path to the image”)
args = vars(apr.parse_args())
image = cv2.imread(args[“image”])
cv2.imshow(‘Image’, image)
cv2.waitKey(0)Conoscere come leggere un’immagine o un file utilizzando un argomento della riga di comando (argparse) è una competenza assolutamente necessaria.
Le prime due righe di codice sono per importare le librerie necessarie; qui, importiamo OpenCV e Argparse. Lo ripeteremo durante il corso.
Le seguenti tre righe di codice gestiscono l’analisi degli argomenti della riga di comando. L’unico argomento di cui abbiamo bisogno è — image: il percorso della nostra immagine sul disco. Infine, analizziamo gli argomenti e li memorizziamo in un dizionario chiamato args.
Prendiamoci un secondo e discutiamo rapidamente esattamente cosa sia lo switch — image. L’— image “switch” (“switch” è sinonimo di “argomento della riga di comando” e i termini possono essere usati in modo intercambiabile) è una stringa che specifichiamo nella riga di comando. Questo switch dice al nostro script Loading_image_from_disk.py dove si trova l’immagine che vogliamo caricare sul disco.
Le ultime tre righe di codice sono discusse in precedenza; la funzione cv2.imread prende args[“image”] come parametro, che non è altro che l’immagine che forniamo nella riga di comando. cv2.imshow visualizza l’immagine, che è già memorizzata in un oggetto immagine dalla riga precedente. L’ultima riga mette in pausa l’esecuzione del script fino a quando non premiamo un tasto sulla nostra tastiera.
Uno dei principali vantaggi dell’uso di un argparse — argomento della riga di comando è che saremo in grado di caricare immagini da diverse posizioni di cartelle senza dover cambiare il percorso dell’immagine nel nostro programma passando dinamicamente il percorso dell’immagine Esempio — “C:\CV_Material\image\sample.jpg” nella riga di comando come argomento durante l’esecuzione del nostro programma Python.
c:\Sample_program>python Loading_image_from_disk.py — image C:\CV_Material\session1.JPG
Qui, stiamo eseguendo il file Loading_image_from_disk.py Python dal c:\sample_program passando il parametro “image” insieme al percorso dell’immagine C:\CV_Material\session1.JPG.
Ottenere l’altezza, la larghezza e la profondità dell’immagine
Poiché le immagini sono rappresentate come array NumPy, possiamo semplicemente utilizzare l’attributo .shape per esaminare la larghezza, l’altezza e il numero di canali.
Utilizzando l’attributo .shape sull’oggetto immagine che abbiamo appena caricato, possiamo trovare l’altezza, la larghezza e la profondità dell’immagine. Come discusso nella lezione precedente — 1, l’altezza e la larghezza dell’immagine possono essere verificate esaminando l’immagine in MS Paint. Fare riferimento alla lezione precedente. Discuteremo della profondità dell’immagine nelle lezioni successive. La profondità è anche conosciuta come canale di un’immagine. Le immagini a colori sono generalmente di 3 canali a causa della composizione RGB nei suoi pixel e le immagini in scala di grigi sono di 1 canale. Questo è qualcosa che abbiamo discusso nella Lezione-1.
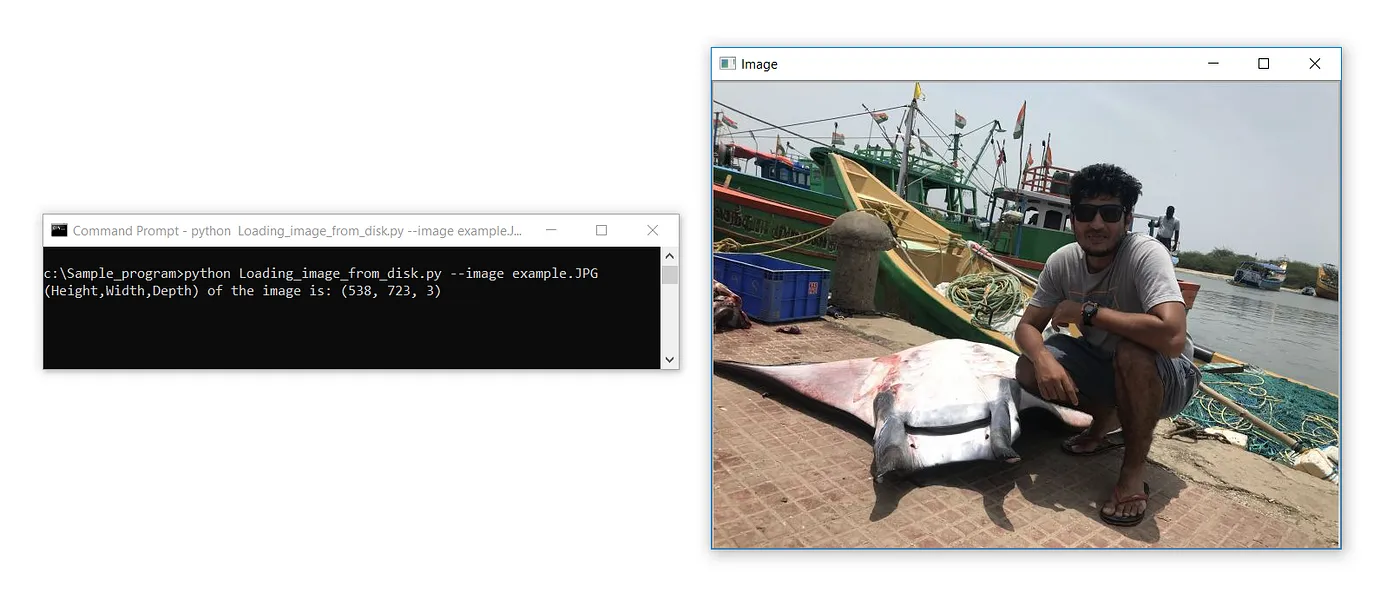
#Ottenere Altezza, Larghezza e Profondità di un'Immagine
import cv2
import argparse
apr = argparse.ArgumentParser()
apr.add_argument(“-i”, “ — image”, required=True, help=”Path to the image”)
args = vars(apr.parse_args())
# Differenza rispetto ai codici precedenti — attributo shape applicato all'oggetto immagine
print(f’(Height,Width,Depth) of the image is: {image.shape}’)
image = cv2.imread(args[“image”])
cv2.imshow(‘Image’, image)
cv2.waitKey(0)Output:
(Altezza, Larghezza, Profondità) dell’immagine è: (538, 723, 3)
L’unica differenza rispetto ai codici precedenti è la dichiarazione di stampa che applica l’attributo shape all’oggetto immagine caricato. f’è la stringa formattata F che accetta variabili in modo dinamico e stampa.
f’ write anything here that you want to see in the print statement: {variables, variables, object, object.attribute,}’
Qui, abbiamo utilizzato {object.attribute} all’interno delle parentesi graffe per l’attributo .shape per calcolare l’altezza, la larghezza e la profondità dell’oggetto immagine.
#Ottenimento Separato dell'Altezza, Larghezza e Profondità
import cv2
import argparse
apr = argparse.ArgumentParser()
apr.add_argument(“-i”, “ — image”, required=True, help=”Path to the image”)
args = vars(apr.parse_args())
image = cv2.imread(args[“image”])
#Slicing dell'array NumPy per ottenere separatamente l'altezza, la larghezza e la profondità
print(“height: %d pixels” % (image.shape[0]))
print(“width: %d pixels” % (image.shape[1]))
print(“depth: %d” % (image.shape[2]))
cv2.imshow(‘Image’, image)
cv2.waitKey(0)Output:
larghezza: 723 pixel
altezza: 538 pixel
profondità: 3
Qui, invece di ottenere (altezza, larghezza e profondità) insieme come tupla. Effettuiamo il slicing dell’array e otteniamo separatamente l’altezza, la larghezza e la profondità dell’immagine. L’indice 0 dell’array contiene l’altezza dell’immagine, l’indice 1 contiene la larghezza dell’immagine e l’indice 2 contiene la profondità dell’immagine.
Trovare i Componenti R, G e B dell’Immagine

Output:
Il valore del componente Blu Verde Rosso dell’immagine nella posizione (321, 308) è: (238, 242, 253)
Notate come il valore y viene passato prima del valore x — questa sintassi potrebbe sembrare controintuitiva all’inizio, ma è coerente con il modo in cui accediamo ai valori in una matrice: prima specifichiamo il numero di riga, poi il numero di colonna. Da lì, otteniamo una tupla che rappresenta i componenti Blu, Verde e Rosso dell’immagine.
Possiamo anche cambiare il colore di un pixel in una posizione specifica invertendo l’operazione.
#Trovare R, B, G dell'Immagine nella Posizione (x, y)
import cv2
import argparse
apr = argparse.ArgumentParser()
apr.add_argument(“-i”, “ — image”, required=True, help=”Path to the image”)
args = vars(apr.parse_args())
image = cv2.imread(args[“image”])
# Ricevere il valore delle coordinate pixel come [y, x] dall'utente, per cui devono essere calcolati i valori RGB
[y,x] = list(int(x.strip()) for x in input().split(‘,’))
# Estrarre i valori (Blu, verde, rosso) delle coordinate pixel ricevute
(b,g,r) = image[y,x]
print(f’The Blue Green Red component value of the image at position {(y,x)} is: {(b,g,r)}’)
cv2.imshow(‘Image’, image)
cv2.waitKey(0)(b,g,r) = image[y,x] to image[y,x] = (b,g,r)
Qui assegniamo il colore in (BGR) al pixel dell’immagine nelle coordinate specificate. Proviamo assegnando il colore rosso al pixel nella posizione (321,308) e verifichiamo l’operazione stampando i valori BGR del pixel nella posizione data.
#Invertendo l'operazione per assegnare un valore RGB al pixel a nostra scelta
import cv2
import argparse
apr = argparse.ArgumentParser()
apr.add_argument(“-i”, “ — image”, required=True, help=”Path to the image”)
args = vars(apr.parse_args())
image = cv2.imread(args[“image”])
# Ricevere il valore delle coordinate pixel [y,x] dall'utente, per cui devono essere calcolati i valori RGB
[y,x] = list(int(x.strip()) for x in input().split(‘,’))
# Estrarre i valori (Blue, green, red) del pixel ricevuto nelle coordinate
image[y,x] = (0,0,255)
(b,g,r) = image[y,x]
print(f’The Blue Green Red component value of the image at position {(y,x)} is: {(b,g,r)}’)
cv2.imshow(‘Image’, image)
cv2.waitKey(0)Output:
I valori delle componenti Blu, Verde e Rossa dell’immagine nella posizione (321, 308) sono (0, 0, 255)
Nel codice sopra, riceviamo le coordinate del pixel attraverso il prompt dei comandi inserendo il valore come mostrato nella Figura 2.6 e assegniamo il colore rosso al pixel delle coordinate specificate assegnando (0,0,255) cioè (Blue, Green, Red), verificando l’operazione stampando le coordinate del pixel di input.
Disegnare con OpenCV
Impariamo a disegnare diverse forme come rettangoli, quadrati e cerchi utilizzando OpenCV disegnando cerchi per mascherare i miei occhi, rettangoli per mascherare i miei labbra e rettangoli per mascherare il pesce manta vicino a me.
L’output dovrebbe apparire così:

Questa foto è mascherata con forme utilizzando MS Paint; proveremo a fare lo stesso utilizzando OpenCV disegnando cerchi attorno ai miei occhi e rettangoli per mascherare le mie labbra e il pesce manta accanto a me.
Utilizziamo il metodo cv2.rectangle per disegnare un rettangolo e il metodo cv2.circle per disegnare un cerchio in OpenCV.
cv2.rectangle(image, (x1, y1), (x2, y2), (Blue, Green, Red), Thickness)
Il metodo cv2.rectangle accetta un’immagine come primo argomento su cui vogliamo disegnare il nostro rettangolo. Vogliamo disegnare sull’oggetto immagine caricato, quindi lo passiamo al metodo. Il secondo argomento è la posizione iniziale (x1, y1) del nostro rettangolo — qui, iniziamo il nostro rettangolo ai punti (156 e 340). Quindi, dobbiamo fornire un punto finale (x2, y2) per il rettangolo. Decidiamo di terminare il nostro rettangolo in (360, 450). L’argomento successivo è il colore del rettangolo che vogliamo disegnare; qui, in questo caso, stiamo passando il colore nero in formato BGR, cioè (0,0,0). Infine, l’ultimo argomento che passiamo è lo spessore della linea. Diamo -1 per disegnare forme solide, come visto in Fig 2.6.
Allo stesso modo, usiamo il metodo cv2.circle per disegnare il cerchio.
cv2.circle(image, (x, y), r, (Blue, Green, Red), Thickness)
Il metodo cv2.circle accetta un’immagine come primo argomento su cui vogliamo disegnare il nostro rettangolo. Vogliamo disegnare sull’oggetto immagine che abbiamo caricato, quindi lo passiamo al metodo. Il secondo argomento è la posizione centrale (x, y) del nostro cerchio — qui, abbiamo preso il nostro cerchio al punto (343, 243). L’argomento successivo è il raggio del cerchio che vogliamo disegnare. L’argomento successivo è il colore del cerchio; qui, in questo caso, stiamo passando il colore rosso in formato BGR, cioè (0,0,255). Infine, l’ultimo argomento che passiamo è lo spessore della linea. Diamo -1 per disegnare forme solide, come visto in Fig 2.6.
Ok! Sapendo tutto questo, proviamo a portare a termine ciò che abbiamo iniziato. Per disegnare le forme nell’immagine, dobbiamo identificare le coordinate di inizio e fine (x,y) della regione da mascherare per passarle al metodo corrispondente.
Come?
Richiameremo in aiuto MS Paint ancora una volta. Posizionando il cursore su una delle coordinate (in alto a sinistra) o (in basso a destra) della regione da mascherare, le coordinate vengono visualizzate nella porzione evidenziata di MS Paint come mostrato in Fig 2.7.
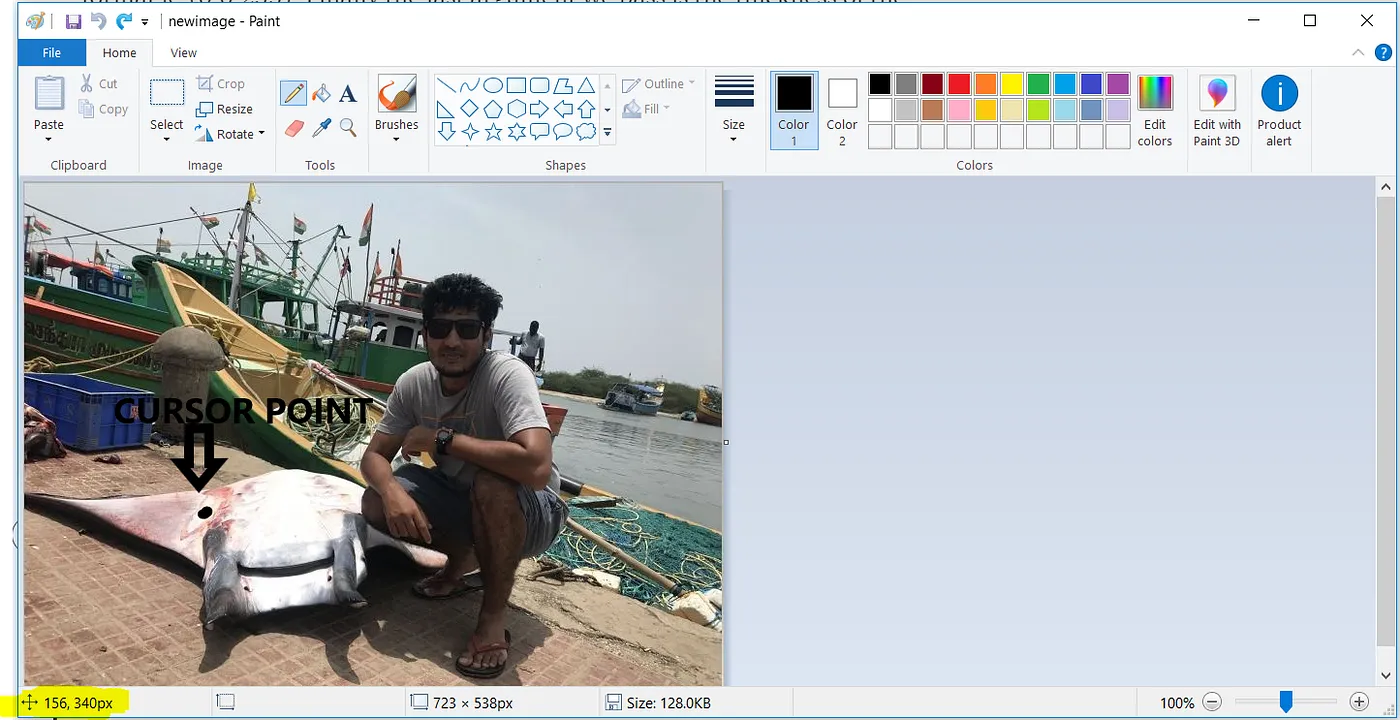
Allo stesso modo, prenderemo tutte le coordinate (x1,y1) (x2,y2) per tutte le regioni da mascherare come mostrato in Fig 2.8.

#Disegnare usando OpenCV per mascherare occhi, bocca e oggetti vicini
import cv2
import argparse
apr = argparse.ArgumentParser()
apr.add_argument(“-i”, “ — image”, required=True, help=”Path to the image”)
args = vars(apr.parse_args())
image = cv2.imread(args[“image”])
cv2.rectangle(image, (415, 168), (471, 191), (0, 0, 255), -1)
cv2.circle(image, (425, 150), 15, (0, 0, 255), -1)
cv2.circle(image, (457, 154), 15, (0, 0, 255), -1)
cv2.rectangle(image, (156, 340), (360, 450), (0, 0, 0), -1)
#Mostrare l'immagine di output
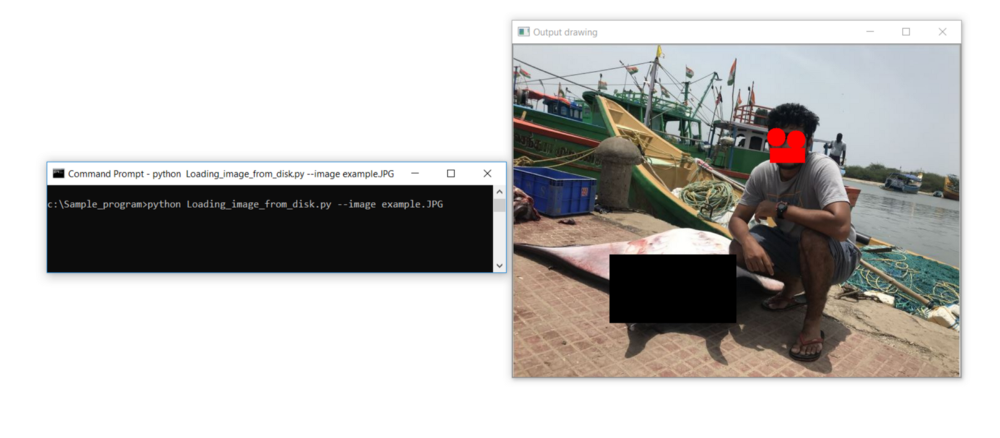
cv2.imshow(“Output drawing “, image)
cv2.waitKey(0)Risultato:
Source:
https://dzone.com/articles/computer-vision-tutorial-2-image-basics