













Современные облачные архитектуры требуют надежных, масштабируемых и безопасных решений по обработке журналов для мониторинга распределенных приложений. В данном исследовании представлено гибридное решение для сбора, агрегации и анализа журналов с использованием Azure Kubernetes Service (AKS) для генерации журналов, Fluent Bit для сбора журналов, Azure EventHub для промежуточной агрегации и Splunk, развернутого на кластере Apache CloudStack в локальной сети, для полного индексирования и визуализации журналов.
Мы подробно описываем дизайн, реализацию и оценку системы, демонстрируя, как данная архитектура обеспечивает надежную и масштабируемую обработку журналов для нагрузки облачных приложений, сохраняя контроль над данными локально.
Введение
Централизованные решения по журналированию стали неотъемлемой частью. Современные приложения, особенно построенные на архитектуре микросервисов, генерируют огромные объемы журналов, часто в различных форматах и из различных источников. Эти журналы являются ключевым источником для мониторинга производительности приложения, диагностики проблем и обеспечения общей надежности системы. Однако управление такими большими объемами журнальных данных представляет существенные вызовы, особенно в гибридных облачных средах, охватывающих как локальную, так и облачную инфраструктуру.
Традиционные решения по ведению журналов, хотя и эффективные для монолитных приложений, испытывают трудности с масштабированием под требования архитектур на основе микросервисов. Динамичная природа микросервисов, характеризующаяся независимыми развертываниями и частыми обновлениями, производит непрерывный поток журналов, каждый из которых различается по формату и структуре. Эти журналы должны быть приняты, обработаны и проанализированы в реальном времени для предоставления оперативной информации. Более того, по мере того как приложения все чаще работают в гибридных средах, обеспечение безопасности и конфиденциальности данных становится приоритетным, учитывая разнообразные требования в области соответствия и регулирования.
В данной статье представлено всеобъемлющее решение, которое решает эти проблемы, используя совместные возможности ресурсов Azure и Apache CloudStack. Интегрируя масштабируемость и аналитические возможности Azure с гибкостью и экономичностью инфраструктуры CloudStack на месте, это решение предлагает надежный, унифицированный подход к централизованному ведению журналов.
Обзор литературы
Централизованное сбор журналов в микросервисах сталкивается с такими проблемами, как сетевая задержка, разнообразные форматы данных и безопасность на различных уровнях. Хотя легковесные агенты, такие как Fluent Bit и FluentD, широко используются, эффективный транспорт журналов остаётся проблемой.
Решения, такие как стек ELK и Azure Monitor, предлагают централизованную обработку журналов, но обычно предполагают либо облачные, либо локальные реализации, что ограничивает гибкость в гибридных развертываниях. Гибридные облачные решения позволяют организациям использовать масштабируемость облака, сохраняя контроль над конфиденциальными данными в локальных средах. Гибридные конвейеры обработки журналов, особенно те, которые используют технологии потоковой передачи событий, отвечают на необходимость в масштабируемом транспорте и агрегации журналов.
Архитектура системы
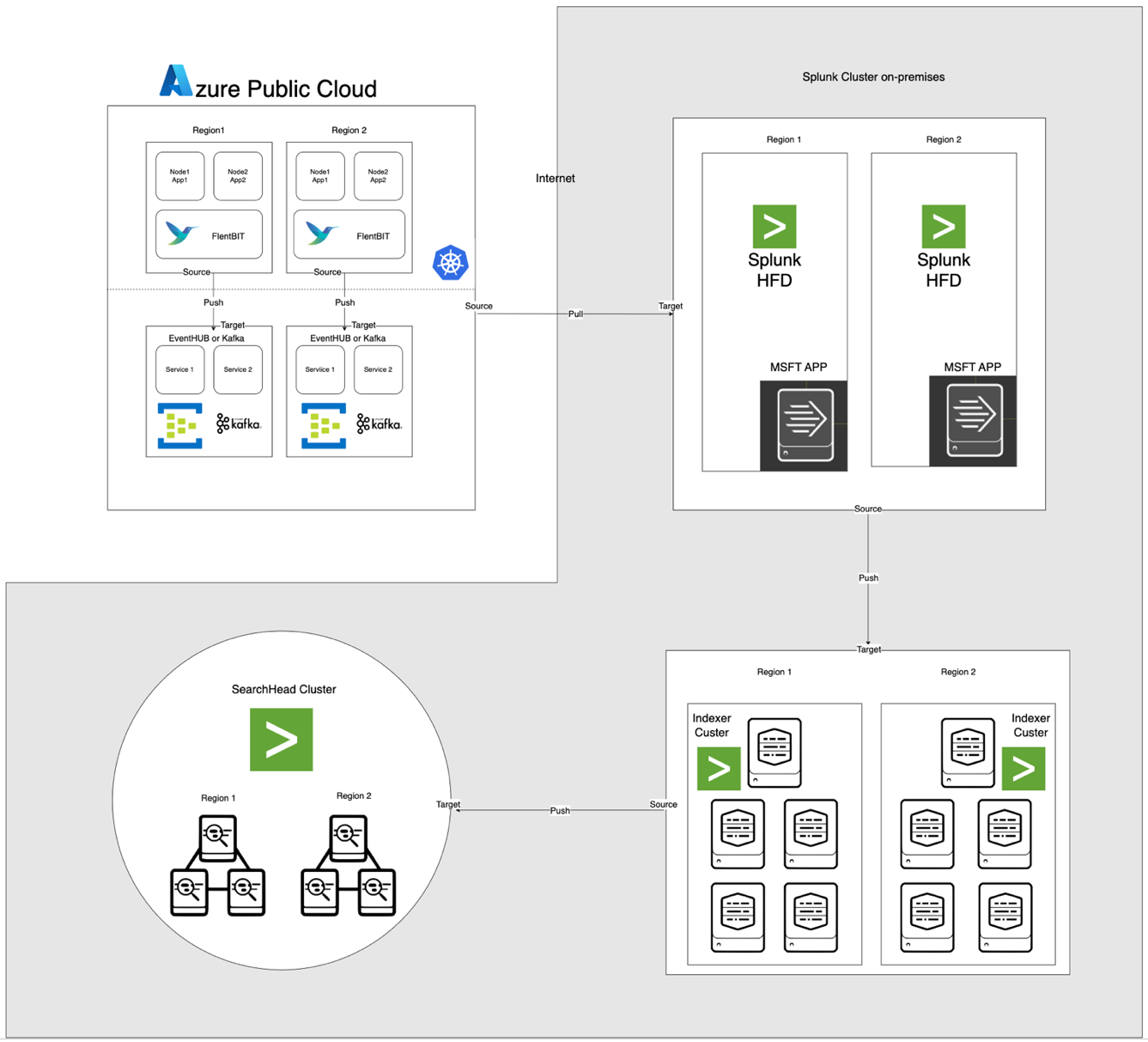
Архитектура, представленная ниже, интегрирует Azure EventHub и AKS с локальным Apache CloudStack и Splunk. Каждый компонент оптимизирован для эффективной обработки журналов и безопасной передачи данных между средами.
Описание компонентов
- AKS: Хостит контейнеризованные приложения и генерирует журналы, доступные через уровень агрегации журналов Kubernetes.
- Fluent Bit: Развернут как DaemonSet, собирает журналы с узлов AKS. Каждый экземпляр Fluent Bit захватывает журналы из /var/log/containers, фильтрует их и пересылает в формате JSON в EventHub.
- Azure EventHub: Уполняет функции брокера сообщений с высокой пропускной способностью, агрегируя журналы от Fluent Bit и временно храня их до тех пор, пока они не будут извлечены Splunk Heavy Forwarder.
- Apache Kafka: Является надежным мостом между Fluent Bit и Splunk. Fluent Bit пересылает логи в Kafka с помощью своего плагина вывода Kafka, где логи временно хранятся и обрабатываются. Splunk затем потребляет логи из Kafka, используя такие коннекторы, как Kafka Connect Splunk Sink или пользовательские скрипты, обеспечивая масштабируемую и разъединенную архитектуру.
- Splunk Heavy Forwarder (HF): Установлен в Apache CloudStack, Heavy Forwarder получает логи из Azure EventHub с помощью Splunk Add-on for Microsoft Cloud Services. Этот аддон обеспечивает бесшовную интеграцию, позволяя Heavy Forwarder безопасно подключаться к EventHub, получать логи в почти реальном времени и преобразовывать их при необходимости перед пересылкой в индексатор Splunk для хранения и обработки
- Splunk на Apache CloudStack: Предоставляет индексацию логов, поиск, визуализацию и оповещение.
Поток данных
- Сбор логов в AKS: Fluent Bit отслеживает лог-файлы в /var/log/containers, фильтруя ненужные логи и помечая каждый лог метаданными (например, имя контейнера, пространство имен).
- Пересылка в EventHub: Логи отправляются в EventHub по HTTPS с использованием плагина вывода azure_eventhub от Fluent Bit, обеспечивая безопасную передачу данных.
- Apache Kafka: Логи с AKS собираются Fluent Bit, работающим как DaemonSet, который разбирает и пересылает их в Apache Kafka через его плагин вывода Kafka. Kafka действует как буфер высокой пропускной способности, храня и разбивая логи для масштабируемости. Splunk принимает эти логи из Kafka с помощью коннекторов или скриптов, обеспечивая индексацию, анализ и мониторинг в реальном времени.
- Получение логов с помощью Splunk Heavy Forwarder: Тяжелый пересыльщик в Apache CloudStack подключается к EventHub с помощью SDK EventHubs и извлекает логи, пересылая их в локальный индексатор Splunk для хранения и обработки.
- Хранение и анализ в Splunk: Логи индексируются в Splunk, что позволяет проводить поиск в реальном времени, создавать визуализации панелей и уведомления на основе шаблонов логов.
Методология
Развертывание Fluent Bit DaemonSet в AKS
Конфигурация Fluent Bit хранится в ConfigMap и развертывается как DaemonSet. Ниже приведена расширенная конфигурация для DaemonSet Fluent Bit:
Name: fluentbit-cm
Namespace: fluentbit
Labels: k8s-app=fluentbit
Annotations:
Data
crio-logtag.lua:
local reassemble_state = {}
function reassemble_cri_logs(tag, timestamp, record)
-- Проверить входную запись
if not record or not record.logtag or not record.log or type(record.log) == 'table' then
return 0, timestamp, record
end
-- Создать уникальный ключ для повторной сборки на основе потока и тега
local reassemble_key = (record.stream or "unknown_stream") .. "::" .. tag
-- Обработать фрагменты логов (logtag == 'P')
if record.logtag == 'P' then
-- Сохранить фрагмент в состояние повторной сборки
reassemble_state[reassemble_key] = (reassemble_state[reassemble_key] or "") .. record.log
return -1, 0, 0 -- Do not forward this fragment
end
-- Обработать конец фрагментированного лога
if reassemble_state[reassemble_key] then
-- Объединить сохраненные фрагменты с текущим логом
record.log = (reassemble_state[reassemble_key] or "") .. (record.log or "")
-- Очистить сохраненное состояние для этого ключа
reassemble_state[reassemble_key] = nil
return 1, timestamp, record -- Forward the reassembled log
end
-- Если повторная сборка не требуется, пересылать лог как есть
return 0, timestamp, record
end
INCLUDE filter-kubernetes.conf
filter-kubernetes.conf:
[FILTER]
Name kubernetes
Match test.app.splunk.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Kube_Tag_Prefix test.app.splunk.var.log.containers
Merge_Log On
Merge_Log_Key log_processed
K8S-Logging.Parser On
K8S-Logging.Exclude On
Labels Off
Annotations Off
Keep_Log Off
fluentbit.conf:
[SERVICE]
Flush 1
Log_Level info
Daemon on
Parsers_File parsers.conf
HTTP_Server On
HTTP_Listen 0.0.0.0
HTTP_Port 2020
Health_Check On
HC_Errors_Count 1
HC_Retry_Failure_Count 1
HC_Period 5
INCLUDE input-kubernetes.conf
INCLUDE output-kafka.conf
input-kubernetes.conf:
[INPUT]
Name tail
Tag test.app.splunk*
Alias test.app.splunk-input
Path /var/log/containers/*test.app.splunk.log
Parser cri
DB /var/log/flb_kube.db
Buffer_Chunk_Size 256K
Buffer_Max_Size 24MB
Mem_Buf_Limit 1GB
Skip_Long_Lines On
Refresh_Interval 5
output-kafka.conf:
[OUTPUT]
Name kafka
Alias test.app.splunk-output
Match test.app.splunk.*
Brokers prod-region-logs-premium.servicebus.windows.net:9094
Topics test.app.splunk
Retry_Limit 5
rdkafka.security.protocol SASL_SSL
rdkafka.sasl.mechanism PLAIN
rdkafka.sasl.username $ConnectionString
rdkafka.sasl.password Endpoint=sb://prod-region-logs-premium.servicebus.windows.net/;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=***********************************************=
[OUTPUT]
parsers.conf:
[PARSER]
Name cri
Format regex
Regex ^(? - [INPUT] раздел указывает сбор журналов из каталога /var/log/containers.
- [FILTER] раздел обогащает журналы метаданными Kubernetes.
- [OUTPUT] раздел настраивает Fluent Bit на пересылку журналов в EventHub в формате JSON.
Настройка Azure EventHub
Для работы с EventHub необходимо указать пространство имен, конкретный экземпляр EventHub и настроить управление доступом через общие политики доступа.
- Настройка пространства имен и EventHub: Создайте пространство имен и экземпляр EventHub в Azure, установите политику отправки и получите строку подключения.
- Настройка для повышенной пропускной способности: EventHub настроен с высоким количеством разделов для поддержки масштабируемости, буферизации и параллельных потоков данных от Fluent Bit.
Настройка Splunk Heavy Forwarder в Apache CloudStack
Splunk Heavy Forwarder извлекает журналы из EventHub и пересылает их на индексатор Splunk.
- Дополнение для облачных служб Microsoft: Установите дополнение для подключения к EventHub. Настройте ввод в
inputs.conf:
[azure_eventhub://eventhub_name]
index = <index_name>
eventhub_namespace = <namespace>
shared_access_key_name = <access_key_name>
shared_access_key = <access_key>
batch_size = 500
interval = 30
sourcetype = _json
disabled = 0- Пакетная обработка: Установите batch_size равным 500 и interval равным 30 секунд для оптимизации приема данных и снижения частоты сетевых вызовов.
Индексация и визуализация в Splunk
- Обогащение данных: Журналы обогащаются дополнительными метаданными в Splunk с использованием извлечения полей.
- Поиск и панели инструментов: Запросы SPL обеспечивают поиск в реальном времени, а настраиваемые панели инструментов обеспечивают визуализацию шаблонов журналов.
- Оповещения: Оповещения настраиваются для срабатывания на определенные шаблоны журналов, такие как высокие уровни ошибок или повторяющиеся предупреждения от конкретных контейнеров.
Производительность и Масштабируемость
Тесты показывают, что система способна обрабатывать высокопроизводительный прием журналов, а возможности буферизации EventHub предотвращают потерю данных в случае сетевых сбоев. Использование ресурсов Fluent Bit на узлах AKS остается минимальным, и индексатор Splunk эффективно обрабатывает объем журналов с помощью соответствующих конфигураций индексации и фильтрации.
Безопасность
HTTPS используется для обеспечения безопасности связи между AKS и EventHub, в то время как Splunk HF использует защищенные ключи для аутентификации в EventHub. Каждый компонент в конвейере реализует механизмы повторной попытки для поддержания целостности данных.
Использование ресурсов
- Средний объем памяти и использования ЦП Fluent Bit на узлах AKS составляет 100-150 MiB и 0,2-0,3 соответственно.
- Использование ресурсов EventHub динамически корректируется на основе конфигураций разделов и пропускной способности.
- Нагрузка Splunk HF балансируется путем пакетной обработки, оптимизируя передачу данных без перегрузки ресурсов Apache CloudStack.
Надежность и Устойчивость к Ошибкам
Решение использует буферизацию EventHub для обеспечения сохранения журналов в случае сбоев вниз по потоку. EventHub также поддерживает политики повторной попытки, дополнительно повышая целостность и надежность данных.
Обсуждение
Преимущества гибридной облачной архитектуры
Эта архитектура обеспечивает гибкость, масштабируемость и безопасность, комбинируя услуги Azure с локальным контролем. Она также использует облачные возможности потоковой передачи и буферизации без ущерба для суверенитета данных.
Ограничения
Хотя EventHub предлагает надежную агрегацию данных, затраты увеличиваются с ростом количества единиц пропускной способности, что делает необходимым оптимизировать конфигурации пересылки логов. Кроме того, передача данных между облачной и локальной средой может привести к потенциальной задержке.
Будущие приложения
Эту архитектуру можно расширить, интегрировав машинное обучение для обнаружения аномалий в логах или добавив поддержку нескольких облачных провайдеров для дальнейшего масштабирования обработки логов и устойчивости в многооблачной среде.
Заключение
Это исследование демонстрирует эффективность гибридного конвейера обработки логов, использующего облачные и локальные ресурсы. Интегрируя Azure Kubernetes Service (AKS), Azure EventHub и Splunk на Apache CloudStack, мы создаем масштабируемое и устойчивое решение для централизованного управления и анализа логов. Архитектура решает ключевые задачи распределенного логирования, включая высокую пропускную способность данных, безопасность и отказоустойчивость.
Использование Fluent Bit в качестве легкого сборщика логов в AKS обеспечивает эффективный сбор данных с минимальной нагрузкой на ресурсы. Возможности буферизации Azure EventHub позволяют обеспечить надежную агрегацию логов и временное хранение, что делает его отлично подходящим для обработки переменного трафика логов и поддержания целостности данных в случае проблем с подключением. Splunk Heavy Forwarder и развертывание Splunk в Apache CloudStack позволяют организациям сохранить контроль над хранением и аналитикой логов, а также воспользоваться масштабируемостью и гибкостью облачных ресурсов.
Такой подход предлагает значительные преимущества для организаций, нуждающихся в гибридной облачной среде, такие как улучшенный контроль над данными, соответствие требованиям к местоположению данных и гибкость масштабирования по мере необходимости. Дальнейшая работа может исследовать интеграцию машинного обучения для улучшения анализа логов, автоматизированное обнаружение аномалий и расширение к многоплатформенной среде для увеличения устойчивости и гибкости. Это исследование предоставляет фундаментальную архитектуру, которая адаптируется к изменяющимся потребностям современных распределенных систем в корпоративной среде.
Ссылки
Azure Event Hubs и Kafka
Гибридный мониторинг и журналирование
- Гибридные и многооблачные шаблоны мониторинга
- Стратегии мониторинга гибридного облака
Интеграция Splunk
- Применение Splunk к Azure Event Hubs
- Данные Azure в платформе Splunk
Развертывание AKS
Source:
https://dzone.com/articles/bridging-cloud-and-on-premises-log-processing