













現代のクラウドネイティブアーキテクチャは、分散アプリケーションを監視するために堅牢でスケーラブル、かつ安全なログ処理ソリューションを必要とします。本研究では、ログ生成のためのAzure Kubernetes Service (AKS)、ログ収集のためのFluent Bit、中間集約のためのAzure EventHub、そして包括的なログインデックス作成と可視化のためにオンプレミスのApache CloudStackクラスターにデプロイされたSplunkを使用したログ収集、集約、分析のためのハイブリッドソリューションを提案します。
システムの設計、実装、および評価の詳細を示し、このアーキテクチャがクラウドネイティブワークロードのために信頼性が高くスケーラブルなログ処理をサポートしながら、オンプレミスでのデータ管理を維持する方法を実証します。
イントロダクション
集中型ログソリューションは不可欠になっています。特にマイクロサービスアーキテクチャに基づいて構築された現代のアプリケーションは、大量のログを生成し、しばしば多様なフォーマットと複数のソースからのものです。これらのログは、アプリケーションのパフォーマンスを監視し、問題を診断し、システム全体の信頼性を確保するための重要な情報源です。しかし、こうした大量のログデータを管理することは、オンプレミスとクラウドベースのインフラストラクチャを跨ぐハイブリッドクラウド環境では重大な課題を引き起こします。
従来のログ解決策は、モノリシックなアプリケーションには効果的ですが、マイクロサービスベースのアーキテクチャの要求に対してスケーリングが困難です。マイクロサービスのダイナミックな性質は、独立した展開と頻繁な更新に特徴付けられ、フォーマットと構造が異なる連続したログストリームを生成します。これらのログは、実行可能な洞察を提供するためにリアルタイムで取り込まれ、処理され、分析される必要があります。さらに、アプリケーションがますますハイブリッド環境全体で運用されるようになるにつれ、さまざまなコンプライアンスと規制要件が考慮され、セキュリティとPIIデータの保護が最重要視されます。
この論文は、AzureとApache CloudStackリソースの組み合わせた能力を活用して、これらの課題に対処する包括的なソリューションを紹介します。Azureのスケーラビリティと分析機能をCloudStackのオンプレミスインフラストラクチャの柔軟性とコスト効率性と組み合わせることで、このソリューションは、集中型ログへの統一的アプローチを提供します。
文献レビュー
マイクロサービスにおける集中型ログ収集は、ネットワークの遅延、多様なデータ形式、および複数のレイヤーでのセキュリティなどの課題に直面しています。Fluent BitやFluentDなどの軽量エージェントが広く使用されていますが、効率的なログ輸送は依然として課題となっています。
ELKスタックやAzure Monitorなどのソリューションは、ログの集中処理を提供しますが、通常、クラウド専用またはオンプレミス専用の実装が含まれ、ハイブリッド展開での柔軟性が制限されます。ハイブリッドクラウドソリューションを使用すると、組織はクラウドの拡張性を活用しながら、オンプレミス環境での機密データのコントロールを維持できます。特にイベントストリーミング技術を使用するハイブリッドログ処理パイプラインは、拡張可能なログの転送と集約のニーズに対応します。
システムアーキテクチャ
以下に示すアーキテクチャは、Azure EventHubとAKSをオンプレミスのApache CloudStackとSplunkと統合しています。各コンポーネントは、効率的なログ処理と環境間の安全なデータ転送のために最適化されています。
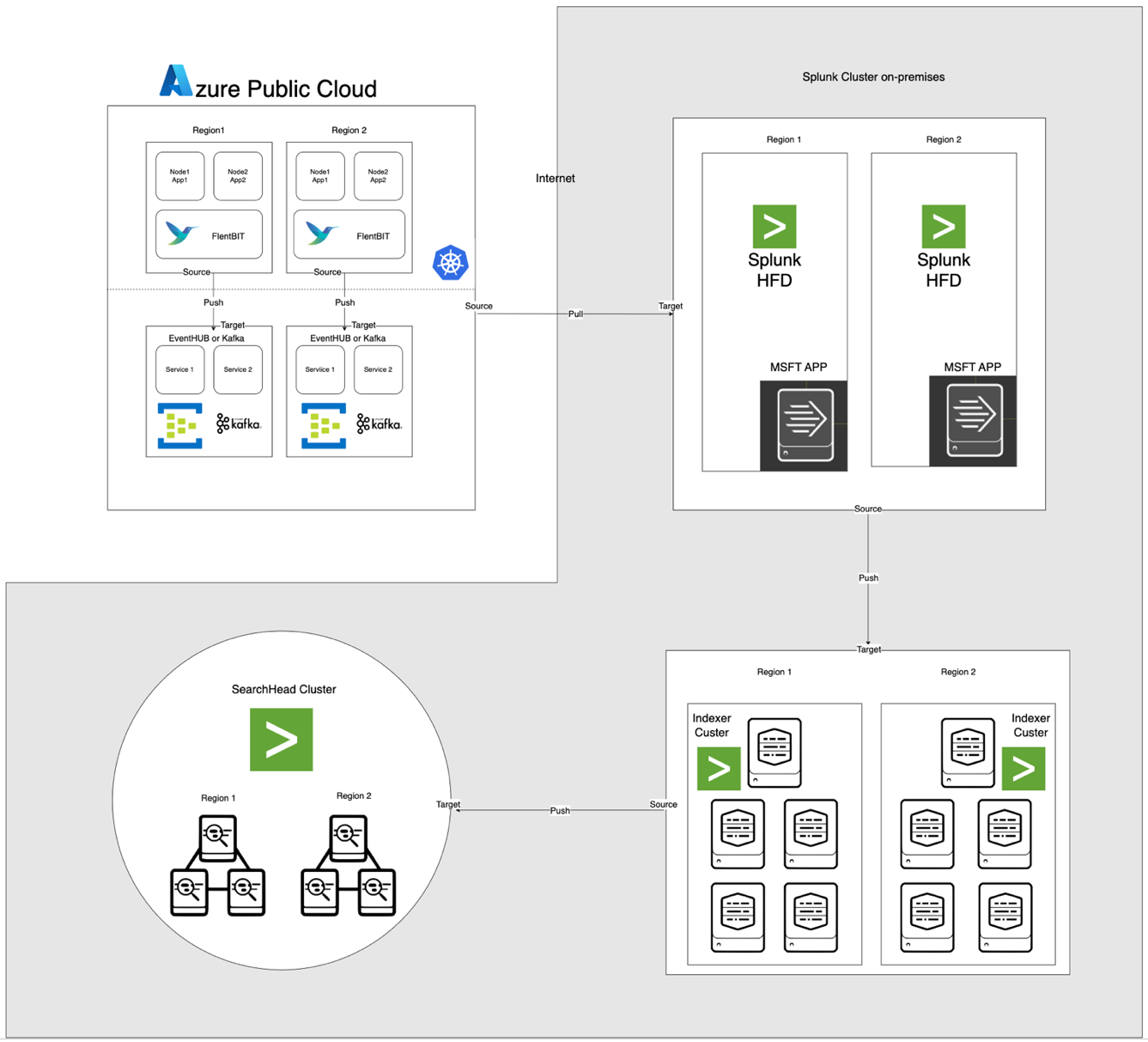
コンポーネントの説明
- AKS:コンテナ化されたアプリケーションをホストし、Kubernetesのログ集約レイヤーを介してアクセス可能なログを生成します。
- Fluent Bit:DaemonSetとして展開され、AKSノードからログを収集します。各Fluent Bitインスタンスは、/var/log/containersからログをキャプチャし、フィルタリングして、JSON形式でEventHubに転送します。
- Azure EventHub:高スループットのメッセージブローカーとして機能し、Fluent Bitからログを集約し、Splunk Heavy Forwarderによって引き出されるまで一時的に保存します。
- Apache Kafka: Fluent BitとSplunkの信頼性のあるブリッジとして機能します。Fluent BitはKafka出力プラグインを使用してログをKafkaに転送し、ログは一時的に保存および処理されます。Splunkはその後、Kafka Connect Splunk Sinkなどのコネクタを使用してKafkaからログを消費し、スケーラブルで切り離されたアーキテクチャを確保します。
- Splunk Heavy Forwarder (HF): Apache CloudStackにインストールされ、Heavy ForwarderはSplunk Add-on for Microsoft Cloud Servicesを使用してAzure EventHubからログを取得します。このアドオンはシームレスな統合を提供し、Heavy ForwarderがEventHubに安全に接続し、ログをほぼリアルタイムで取得し、必要に応じて変換してSplunkのインデクサに転送することができます。
- Apache CloudStack上のSplunk: ログのインデックス作成、検索、可視化、アラート機能を提供します。
データフロー
- AKSでのログ収集: Fluent Bitは/var/log/containers内のログファイルを監視し、不要なログをフィルタリングし、各ログにメタデータ(コンテナ名、名前空間など)を付加します。
- EventHubへの転送: Fluent Bitのazure_eventhub出力プラグインを使用して、ログをHTTPS経由でEventHubに送信し、安全なデータ転送を確保します。
- Apache Kafka: AKSからのログは、DaemonSetとして実行されるFluent Bitによって収集され、Kafka出力プラグインを介してApache Kafkaに転送されます。Kafkaは高スループットのバッファとして機能し、スケーラビリティのためにログを保存およびパーティションに分割します。Splunkは、これらのログをコネクタまたはスクリプトを使用してKafkaから受信し、インデックス作成、分析、およびリアルタイムモニタリングを可能にします。
- Splunk Heavy Forwarderによるログの取得: Apache CloudStackのHeavy Forwarderは、EventHubs SDKを使用してEventHubに接続し、ログを取得してローカルのSplunkインデクサに転送して保存および処理します。
- Splunkでのストレージと分析: ログはSplunkでインデックス化され、ログパターンに基づいてリアルタイム検索、ダッシュボードの可視化、アラートを可能にします。
手法
AKSでのFluent Bit DaemonSetの展開
Fluent Bitの構成はConfigMapに格納され、DaemonSetとして展開されます。以下は、Fluent Bit DaemonSetの拡張構成です:
Name: fluentbit-cm
Namespace: fluentbit
Labels: k8s-app=fluentbit
Annotations:
Data
crio-logtag.lua:
local reassemble_state = {}
function reassemble_cri_logs(tag, timestamp, record)
-- 受信レコードの検証
if not record or not record.logtag or not record.log or type(record.log) == 'table' then
return 0, timestamp, record
end
-- ストリームとタグに基づいて再結合用の一意のキーを生成
local reassemble_key = (record.stream or "unknown_stream") .. "::" .. tag
-- ログ断片の処理 (logtag == 'P')
if record.logtag == 'P' then
-- ログ断片を再結合状態に保存
reassemble_state[reassemble_key] = (reassemble_state[reassemble_key] or "") .. record.log
return -1, 0, 0 -- Do not forward this fragment
end
-- ログの断片化の終了の処理
if reassemble_state[reassemble_key] then
-- 保存された断片を現在のログと結合
record.log = (reassemble_state[reassemble_key] or "") .. (record.log or "")
-- このキーの保存された状態をクリア
reassemble_state[reassemble_key] = nil
return 1, timestamp, record -- Forward the reassembled log
end
-- 再結合が不要な場合は、ログをそのまま転送
return 0, timestamp, record
end
INCLUDE filter-kubernetes.conf
filter-kubernetes.conf:
[FILTER]
Name kubernetes
Match test.app.splunk.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Kube_Tag_Prefix test.app.splunk.var.log.containers
Merge_Log On
Merge_Log_Key log_processed
K8S-Logging.Parser On
K8S-Logging.Exclude On
Labels Off
Annotations Off
Keep_Log Off
fluentbit.conf:
[SERVICE]
Flush 1
Log_Level info
Daemon on
Parsers_File parsers.conf
HTTP_Server On
HTTP_Listen 0.0.0.0
HTTP_Port 2020
Health_Check On
HC_Errors_Count 1
HC_Retry_Failure_Count 1
HC_Period 5
INCLUDE input-kubernetes.conf
INCLUDE output-kafka.conf
input-kubernetes.conf:
[INPUT]
Name tail
Tag test.app.splunk*
Alias test.app.splunk-input
Path /var/log/containers/*test.app.splunk.log
Parser cri
DB /var/log/flb_kube.db
Buffer_Chunk_Size 256K
Buffer_Max_Size 24MB
Mem_Buf_Limit 1GB
Skip_Long_Lines On
Refresh_Interval 5
output-kafka.conf:
[OUTPUT]
Name kafka
Alias test.app.splunk-output
Match test.app.splunk.*
Brokers prod-region-logs-premium.servicebus.windows.net:9094
Topics test.app.splunk
Retry_Limit 5
rdkafka.security.protocol SASL_SSL
rdkafka.sasl.mechanism PLAIN
rdkafka.sasl.username $ConnectionString
rdkafka.sasl.password Endpoint=sb://prod-region-logs-premium.servicebus.windows.net/;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=***********************************************=
[OUTPUT]
parsers.conf:
[PARSER]
Name cri
Format regex
Regex ^(? - [INPUT]セクションは/var/log/containersディレクトリからのログ収集を指定します。
- [FILTER]セクションはKubernetesのメタデータでログをエンリッチします。
- [OUTPUT]セクションはFluent Bitを構成して、JSON形式でログをEventHubに転送します。
Azure EventHubの構成
EventHubには名前空間、特定のEventHubインスタンス、および共有アクセスポリシーを介したアクセス制御が必要です。
- 名前空間とEventHubの設定: Azureで名前空間とEventHubインスタンスを作成し、送信ポリシーを設定し、接続文字列を取得します。
- 高スループット用の構成: EventHubは高いパーティション数で構成され、スケーラビリティ、バッファリング、およびFluent Bitからの同時データストリームをサポートします。
Apache CloudStackでのSplunk Heavy Forwarderの構成
Splunk Heavy ForwarderはEventHubからログを取得し、Splunkのインデクサに転送します。
- Microsoft Cloud Services用のアドオン: EventHubの接続を有効にするためにアドオンをインストールします。
inputs.confで入力を構成します:
[azure_eventhub://eventhub_name]
index = <index_name>
eventhub_namespace = <namespace>
shared_access_key_name = <access_key_name>
shared_access_key = <access_key>
batch_size = 500
interval = 30
sourcetype = _json
disabled = 0- バッチ処理: データ取り込みを最適化し、ネットワーク呼び出しの頻度を減らすために、batch_sizeを500、intervalを30秒に設定します。
Splunkのインデクシングと可視化
- データのエンリッチメント: Splunkでフィールド抽出を使用してログに追加のメタデータをエンリッチします。
- 検索とダッシュボード: SPLクエリを使用してリアルタイム検索が可能であり、カスタムダッシュボードはログパターンの可視化を提供します。
- アラート: アラートは特定のログパターン(例: 高いエラー率や特定のコンテナからの繰り返し警告など)をトリガーするように構成されています。
パフォーマンスとスケーラビリティ
テストによると、システムは高スループットのログ取り込みを処理でき、EventHubのバッファリング機能によりネットワークの中断中にデータが失われることがありません。AKSノード上のFluent Bitリソース使用量は最小限であり、適切なインデックス設定とフィルター設定によりSplunkのインデクサがログボリュームを効率的に処理しています。
セキュリティ
AKSとEventHub間の通信を保護するためにHTTPSが使用されており、Splunk HFはEventHubとの認証に安全なキーを使用しています。パイプライン内の各コンポーネントにはデータの整合性を維持するための再試行メカニズムが実装されています。
リソース利用
- Fluent BitはAKSノード上で平均100-150 MiBのメモリと0.2-0.3 CPUを使用しています。
- EventHubのリソース使用量はパーティションとスループットの構成に基づいて動的に調整されます。
- Splunk HFの負荷はバッチ処理を通じてバランスが取られ、Apache CloudStackリソースを過負荷にしないようにデータ転送が最適化されています。
信頼性と障害耐性
このソリューションはEventHubのバッファリングを使用して、下流の障害が発生した場合でもログの保持を確保しています。EventHubはさらにデータの整合性と信頼性を高めるための再試行ポリシーをサポートしています。
議論
ハイブリッドクラウドアーキテクチャの利点
このアーキテクチャは、Azureサービスとオンプレミスの制御を組み合わせることで、柔軟性、スケーラビリティ、セキュリティを提供します。また、クラウドベースのストリーミングおよびバッファリング機能を活用し、データの主権を損なうことなく適用できます。
制限事項
EventHubは信頼性の高いデータ集約を提供しますが、スループットユニットが増加するとコストも増加し、ログの転送構成を最適化する必要があります。また、クラウドとオンプレミス環境間のデータ転送には潜在的な遅延が生じる可能性があります。
将来の応用
このアーキテクチャは、ログ内の異常検出に機械学習を統合したり、複数のクラウドプロバイダーをサポートしてログ処理とマルチクラウドの弾力性をさらに拡張することができます。
結論
この研究は、クラウドとオンプレミスリソースを活用したハイブリッドログ処理パイプラインの効果を示しています。Azure Kubernetes Service(AKS)、Azure EventHub、およびApache CloudStack上のSplunkを統合することで、集中化されたログ管理と分析のための拡張可能で耐障害性のあるソリューションを作成します。このアーキテクチャは、分散ログ記録における高データスループット、セキュリティ、耐障害性などの主要な課題に対処しています。
Fluent Bitを軽量なログ収集ツールとしてAKSで使用することで、リソースオーバーヘッドを最小限に抑えた効率的なデータ収集が実現します。Azure EventHubのバッファリング機能は、信頼性のあるログ集約と一時的なストレージを可能にし、接続問題が発生した際でもデータ整合性を維持しながら、変動するログトラフィックに対応するのに適しています。Splunk Heavy ForwarderとApache CloudStack内のSplunkデプロイメントにより、組織はログストレージと分析に対する制御を維持しながら、クラウドリソースのスケーラビリティと柔軟性の恩恵を受けることができます。
このアプローチは、データに対する制御の強化、データ居住要件へのコンプライアンス、需要に応じたスケールの柔軟性など、ハイブリッドクラウド構成を必要とする組織にとって重要な利点を提供します。今後の研究では、ログ分析の強化、自動異常検出、そしてレジリエンスと多様性を高めるためのマルチクラウド構成への拡張を目的とした機械学習の統合を探ることができるでしょう。この研究は、企業環境における現代の分散システムの進化するニーズに適応可能な基盤アーキテクチャを提供します。
参考文献
Azure Event HubsとKafka
ハイブリッドモニタリングとロギング
- ハイブリッドおよびマルチクラウド監視パターン
- ハイブリッドクラウド監視戦略
Splunk 統合
- Azure Event Hubs の Splunk 化
- Azure Data を Splunk プラットフォームに
AKS デプロイメント
Source:
https://dzone.com/articles/bridging-cloud-and-on-premises-log-processing