













現代雲原生架構需要強大、可擴展和安全的日誌處理解決方案來監控分佈式應用程序。本研究提出了一種混合解決方案,使用 Azure Kubernetes Service (AKS) 進行日誌生成,使用 Fluent Bit 進行日誌收集,使用 Azure EventHub 進行中介聚合,並在本地部署在 Apache CloudStack 集群上的 Splunk 進行全面的日誌索引和可視化。
我們詳細介紹了系統的設計、實施和評估,展示了這種架構如何支持可靠和可擴展的雲原生工作負載的日誌處理,同時保留對本地數據的控制。
介紹
集中式日誌解決方案已變得不可或缺。現代應用程序,特別是基於微服務架構構建的應用程序,生成大量的日誌,通常以各種格式且來自多個來源。這些日誌是監控應用程序性能、診斷問題並確保系統整體可靠性的關鍵來源。然而,在管理如此大量的日誌數據方面存在著重大挑戰,尤其是在涵蓋本地和基於雲的基礎設施的混合雲環境中。
傳統的日誌解決方案,雖然對於傳統應用程式非常有效,但在微服務架構的需求下很難擴展。微服務的動態特性,以獨立部署和頻繁更新為特徵,產生了一個持續的日誌流,每個日誌的格式和結構都不同。這些日誌必須在實時進行摄取、處理和分析,以提供可操作的見解。此外,隨著應用程式越來越多地在混合環境中運行,確保安全性和個人身份識別數據變得至關重要,考慮到各種合規性和監管要求。
本文介紹了一個綜合解決方案,通過充分利用Azure和Apache CloudStack資源的結合能力,解決了這些挑戰。通過將Azure的擴展性和分析能力與CloudStack的本地基礎設施的靈活性和成本效益相結合,該解決方案提供了一種強大的、統一的集中式日誌方法。
文獻回顧
微服務的集中式日誌收集面臨著像網絡延遲、多樣化的數據格式以及跨多個層面的安全性等挑戰。盡管像Fluent Bit和FluentD這樣的輕量代理廣泛使用,但高效的日誌傳輸仍然是一個挑戰。
解決方案,如ELK堆疊和Azure監控器,提供了集中式日誌處理,但通常涉及僅雲端或僅本地部署,限制了混合部署的靈活性。混合雲解決方案允許組織利用雲端的可擴展性,同時保留對本地環境中敏感數據的控制。特別是使用事件流技術的混合日誌處理管道,解決了可擴展的日誌傳輸和聚合需求。
系統架構
下圖所示的架構將Azure EventHub和AKS與本地Apache CloudStack和Splunk集成。每個組件都經過優化,以實現跨環境的高效日誌處理和安全數據傳輸。
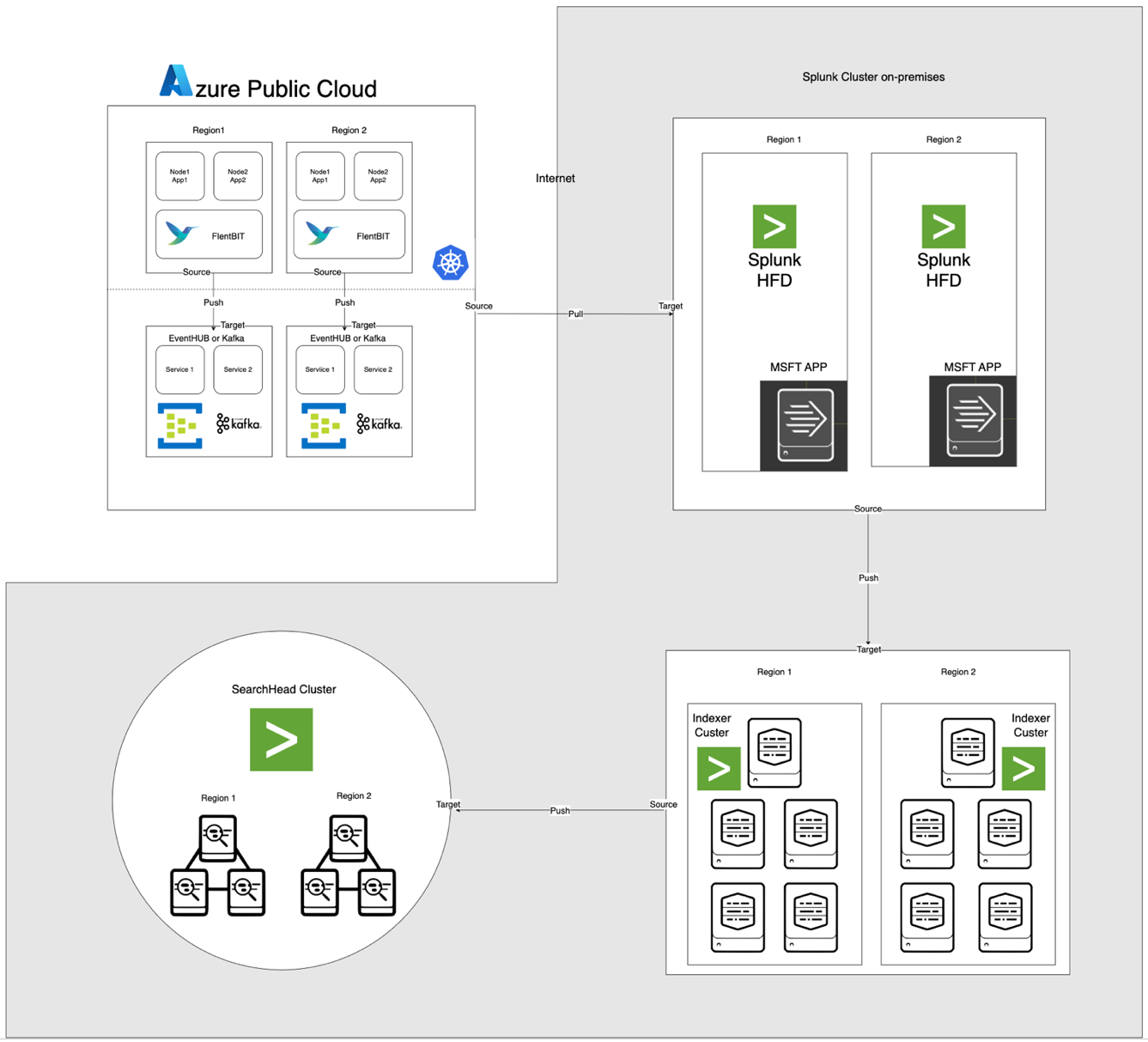
組件描述
- AKS:托管容器化應用程序並生成通過Kubernetes的日誌聚合層訪問的日誌。
- Fluent Bit:部署為DaemonSet,從AKS節點收集日誌。每個Fluent Bit實例捕獲來自/var/log/containers的日誌,對其進行過濾,並以JSON格式將其轉發到EventHub。
- Azure EventHub:作為高吞吐量消息代理,從Fluent Bit聚合日誌並將其暫時存儲,直到被Splunk的Heavy Forwarder拉取。
- Apache Kafka:作為 Fluent Bit 和 Splunk 之間可靠的橋樑。Fluent Bit 使用其 Kafka 輸出插件將日誌轉發到 Kafka,日誌在其中被暫存和處理。然後,Splunk 使用像是 Kafka Connect Splunk Sink 或自定義腳本從 Kafka 消費日誌,確保可擴展且解耦的架構。
- Splunk Heavy Forwarder (HF):在 Apache CloudStack 中安裝的 Heavy Forwarder 使用 用於 Microsoft Cloud 服務的 Splunk 附加元件 從 Azure EventHub 检索日誌。此附加元件提供無縫集成,使得 Heavy Forwarder 能夠安全連接到 EventHub,幾乎實時地檢索日誌,並在轉發到 Splunk 的索引器進行存儲和處理之前根據需要對其進行轉換。
- 在 Apache CloudStack 上的 Splunk:提供日誌索引、搜索、可視化和警報。
數據流
- 在 AKS 中的日誌收集:Fluent Bit 對 /var/log/containers 中的日誌文件進行跟蹤,過濾掉不必要的日誌並為每個日誌添加元數據(例如容器名稱、命名空間)。
- 轉發到 EventHub:使用 Fluent Bit 的 azure_eventhub 輸出插件通過 HTTPS 將日誌發送到 EventHub,確保安全的數據傳輸。
- Apache Kafka:從AKS收集的日誌由作為DaemonSet運行的Fluent Bit 收集,解析並通過其Kafka輸出插件將其轉發到Apache Kafka。 Kafka作為高吞吐量緩衝,用於存儲和分區日誌以實現可擴展性。 Splunk使用連接器或腳本從Kafka中提取這些日誌,實現索引、分析和實時監控。
- 使用Splunk Heavy Forwarder拉取日誌:Apache CloudStack中的Heavy Forwarder使用EventHubs SDK連接到EventHub,拉取日誌,將其轉發到本地Splunk索引器進行存儲和處理。
- 在Splunk中進行存儲和分析:日誌在Splunk中進行索引,實現實時搜索、儀表板可視化和基於日誌模式的警報。
方法
在AKS中部署Fluent Bit DaemonSet
Fluent Bit的配置存儲在ConfigMap中並部署為DaemonSet。以下是Fluent Bit DaemonSet的擴展配置:
Name: fluentbit-cm
Namespace: fluentbit
Labels: k8s-app=fluentbit
Annotations:
Data
crio-logtag.lua:
local reassemble_state = {}
function reassemble_cri_logs(tag, timestamp, record)
-- 驗證傳入記錄
if not record or not record.logtag or not record.log or type(record.log) == 'table' then
return 0, timestamp, record
end
-- 基於流和標籤生成用於重新組合的唯一密鑰
local reassemble_key = (record.stream or "unknown_stream") .. "::" .. tag
-- 處理日誌片段(logtag == 'P')
if record.logtag == 'P' then
-- 將片段存儲在重新組合狀態中
reassemble_state[reassemble_key] = (reassemble_state[reassemble_key] or "") .. record.log
return -1, 0, 0 -- Do not forward this fragment
end
-- 處理分段日誌的結束
if reassemble_state[reassemble_key] then
-- 將存儲的片段與當前日誌結合
record.log = (reassemble_state[reassemble_key] or "") .. (record.log or "")
-- 清除此密鑰的存儲狀態
reassemble_state[reassemble_key] = nil
return 1, timestamp, record -- Forward the reassembled log
end
-- 如果不需要重新組合,則將日誌按原樣轉發
return 0, timestamp, record
end
INCLUDE filter-kubernetes.conf
filter-kubernetes.conf:
[FILTER]
Name kubernetes
Match test.app.splunk.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Kube_Tag_Prefix test.app.splunk.var.log.containers
Merge_Log On
Merge_Log_Key log_processed
K8S-Logging.Parser On
K8S-Logging.Exclude On
Labels Off
Annotations Off
Keep_Log Off
fluentbit.conf:
[SERVICE]
Flush 1
Log_Level info
Daemon on
Parsers_File parsers.conf
HTTP_Server On
HTTP_Listen 0.0.0.0
HTTP_Port 2020
Health_Check On
HC_Errors_Count 1
HC_Retry_Failure_Count 1
HC_Period 5
INCLUDE input-kubernetes.conf
INCLUDE output-kafka.conf
input-kubernetes.conf:
[INPUT]
Name tail
Tag test.app.splunk*
Alias test.app.splunk-input
Path /var/log/containers/*test.app.splunk.log
Parser cri
DB /var/log/flb_kube.db
Buffer_Chunk_Size 256K
Buffer_Max_Size 24MB
Mem_Buf_Limit 1GB
Skip_Long_Lines On
Refresh_Interval 5
output-kafka.conf:
[OUTPUT]
Name kafka
Alias test.app.splunk-output
Match test.app.splunk.*
Brokers prod-region-logs-premium.servicebus.windows.net:9094
Topics test.app.splunk
Retry_Limit 5
rdkafka.security.protocol SASL_SSL
rdkafka.sasl.mechanism PLAIN
rdkafka.sasl.username $ConnectionString
rdkafka.sasl.password Endpoint=sb://prod-region-logs-premium.servicebus.windows.net/;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=***********************************************=
[OUTPUT]
parsers.conf:
[PARSER]
Name cri
Format regex
Regex ^(? - [輸入]部分指定從 /var/log/containers 目錄收集日誌。
- [過濾器]部分使用 Kubernetes 元數據豐富日誌。
- [輸出]部分配置 Fluent Bit 將日誌以 JSON 格式轉發到 EventHub。
Azure EventHub 配置
EventHub 需要命名空間、特定的 EventHub 實例,以及通過共享訪問策略進行訪問控制。
- 命名空間和 EventHub 設置:在 Azure 中創建一個命名空間和 EventHub 實例,設置一個發送策略,並檢索連接字符串。
- 高吞吐量配置:配置 EventHub 具有高分區計數,以支持擴展性、緩衝和從 Fluent Bit 的並發數據流。
在 Apache CloudStack 中的 Splunk 重型轉發器配置
Splunk 重型轉發器從 EventHub 检索日志並將其轉發到 Splunk 的索引器。
- Microsoft 云服務的附加組件:安裝該附加組件以啟用 EventHub 連接。在
inputs.conf中配置輸入:
[azure_eventhub://eventhub_name]
index = <index_name>
eventhub_namespace = <namespace>
shared_access_key_name = <access_key_name>
shared_access_key = <access_key>
batch_size = 500
interval = 30
sourcetype = _json
disabled = 0- 批處理:將 batch_size 設置為 500,將間隔設置為 30 秒,以優化數據載入並降低網絡調用的頻率。
Splunk 索引和可視化
- 數據豐富:在 Splunk 中使用字段提取在日誌中豐富額外的元數據。
- 搜索和儀表板: SPL查詢可實現即時搜索,自定義儀表板可提供日誌模式的可視化。
- 警報: 警報配置為在特定日誌模式觸發,例如高錯誤率或特定容器重複警告。
性能和可擴展性
測試顯示系統可以處理高吞吐量的日誌輸入,EventHub的緩衝功能可在網絡中斷期間防止數據丟失。在AKS節點上,Fluent Bit的資源使用保持最低,Splunk的索引器通過適當的索引和篩選配置有效處理日誌量。
安全性
使用HTTPS加密來確保AKS和EventHub之間的通信,而Splunk HF使用安全金鑰與EventHub進行身份驗證。管道中的每個組件實現重試機制以保持數據完整性。
資源利用率
- 在AKS節點上,Fluent Bit的平均記憶體使用量為100-150 MiB,CPU使用率為0.2-0.3。
- 根據分區和吞吐量配置,EventHub的資源使用量會動態調整。
- 通過批處理平衡Splunk HF的負載,優化數據傳輸,而不會過載Apache CloudStack資源。
可靠性和容錯性
解決方案使用EventHub的緩衝功能,以確保在下游故障情況下保留日誌。EventHub還支持重試策略,進一步增強數據完整性和可靠性。
討論
混合雲架構的優勢
這種架構通過將Azure服務與本地控制相結合,提供了靈活性、可擴展性和安全性。它還利用了基於雲的流式傳輸和緩衝功能,而不會影響數據主權。
限制
雖然EventHub提供可靠的數據聚合,但隨著吞吐量單位的增加,成本也會增加,因此優化日誌轉發配置至關重要。此外,雲端與本地環境之間的數據傳輸可能會引入潛在的延遲。
未來應用
可以通過集成機器學習進行日誌異常檢測或添加對多個雲服務提供商的支持,進一步擴展這種架構,以實現日誌處理和多雲彈性擴展。
結論
本研究展示了利用雲端和本地資源構建的混合日誌處理管道的有效性。通過集成Azure Kubernetes Service(AKS)、Azure EventHub和基於Apache CloudStack的Splunk,我們為集中式日誌管理和分析創建了可擴展和具韌性的解決方案。該架構解決了分散式日誌記錄中的關鍵挑戰,包括高數據吞吐量、安全性和容錯能力。
在AKS中使用Fluent Bit作為輕量級日誌收集器可確保以最少的資源開銷進行高效的數據收集。Azure EventHub的緩衝功能可以可靠地進行日誌聚合和臨時存儲,使其非常適合處理變化的日誌流量並在連接問題發生時保持數據完整性。Splunk Heavy Forwarder和在Apache CloudStack中部署Splunk使組織能夠保持對日誌存儲和分析的控制,同時受益於雲資源的可擴展性和靈活性。
這種方法為需要混合雲配置的組織提供了顯著的優勢,例如增強對數據的控制、符合數據存儲要求以及根據需求擴展的靈活性。未來的工作可以探索整合機器學習來增強日誌分析、自動異常檢測以及擴展到多雲環境以提高彈性和多功能性。這項研究提供了一種適應現代企業環境中不斷變化需求的基礎架構。
參考資料
Azure Event Hubs和Kafka
混合監控和記錄
- 混合和多雲監控模式
- 混合雲監控策略
Splunk 整合
- 將 Azure Event Hubs 輸入 Splunk
- 將 Azure 資料輸入 Splunk 平台
AKS 部署
Source:
https://dzone.com/articles/bridging-cloud-and-on-premises-log-processing