













현대의 클라우드 네이티브 아키텍처는 분산 애플리케이션을 모니터링하기 위해 강력하고 확장 가능하며 안전한 로그 처리 솔루션을 요구합니다. 이 연구는 로그 생성을 위한 Azure Kubernetes Service(AKS), 로그 수집을 위한 Fluent Bit, 중간 집계를 위한 Azure EventHub, 포괄적인 로그 인덱싱 및 시각화를 위한 온프레미스 Apache CloudStack 클러스터에 배포된 Splunk을 사용하여 로그 수집, 집계 및 분석을 위한 하이브리드 솔루션을 제시합니다.
우리는 이 시스템의 설계, 구현 및 평가에 대해 자세히 설명하며, 이 아키텍처가 클라우드 네이티브 워크로드에 대해 신뢰할 수 있고 확장 가능한 로그 처리를 어떻게 지원하는지, 온프레미스에서 데이터에 대한 제어를 유지하면서 어떻게 수행되는지를 보여줍니다.
서론
중앙 집중식 로그 솔루션은 필수불가결하게 되었습니다. 현대 애플리케이션, 특히 마이크로서비스 아키텍처로 구축된 애플리케이션은 방대한 양의 로그를 생성하며, 종종 다양한 형식과 여러 출처에서 발생합니다. 이러한 로그는 애플리케이션 성능 모니터링, 문제 진단 및 시스템의 전반적인 신뢰성을 보장하는 주요 소스입니다. 그러나 이러한 대량의 로그 데이터를 관리하는 것은 특히 온프레미스와 클라우드 기반 인프라가 혼합된 하이브리드 클라우드 환경에서 상당한 도전 과제가 됩니다.
전통적인 로깅 솔루션은 단일 애플리케이션에 대해 효과적이지만, 마이크로서비스 기반 아키텍처의 요구 사항에서 확장하기 어렵습니다. 마이크로서비스의 동적인 성격은 독립적인 배포와 빈번한 업데이트로 인해 다양한 형식과 구조의 로그를 지속적으로 생성합니다. 이러한 로그는 실시간으로 수신, 처리 및 분석되어 실행 가능한 통찰을 제공해야 합니다. 더 나아가, 응용 프로그램이 점점 더 하이브리드 환경에서 운영되는 경우, 다양한 규정 준수 및 규제 요구 사항을 고려하여 보안 및 PII 데이터의 보호가 중요해집니다.
본 논문은 Microsoft Azure와 Apache CloudStack 자원의 결합된 능력을 활용하여 이러한 도전에 대응하는 포괄적인 솔루션을 소개합니다. Azure의 확장성과 분석 능력을 CloudStack의 온프레미스 인프라의 유연성과 비용 효율성과 통합하여, 이 솔루션은 중앙 집중식 로깅에 대한 견고하고 통합된 접근 방식을 제공합니다.
문헌 검토
마이크로서비스에서의 중앙 집중식 로그 수집은 네트워크 지연, 다양한 데이터 형식 및 여러 계층에서의 보안과 같은 도전에 직면합니다. Fluent Bit 및 FluentD와 같은 가벼운 에이전트들이 널리 사용되지만 효율적인 로그 전송은 여전히 도전입니다.
ELK 스택 및 Azure Monitor와 같은 솔루션은 중앙 집중식 로그 처리를 제공하지만 일반적으로 클라우드 전용 또는 온프레미스 전용 구현을 포함하여 하이브리드 배포의 유연성을 제한합니다. 하이브리드 클라우드 솔루션을 통해 조직은 클라우드의 확장성을 활용하면서 온프레미스 환경에서 민감한 데이터를 제어할 수 있습니다. 특히 이벤트 스트리밍 기술을 사용하는 하이브리드 로그 처리 파이프라인은 확장 가능한 로그 전송 및 집계의 필요를 해결합니다.
시스템 아키텍처
아래 그림으로 설명된 아키텍처는 Azure EventHub와 AKS를 온프레미스 Apache CloudStack 및 Splunk와 통합합니다. 각 구성 요소는 환경 간 효율적인 로그 처리 및 안전한 데이터 전송을 위해 최적화되어 있습니다.
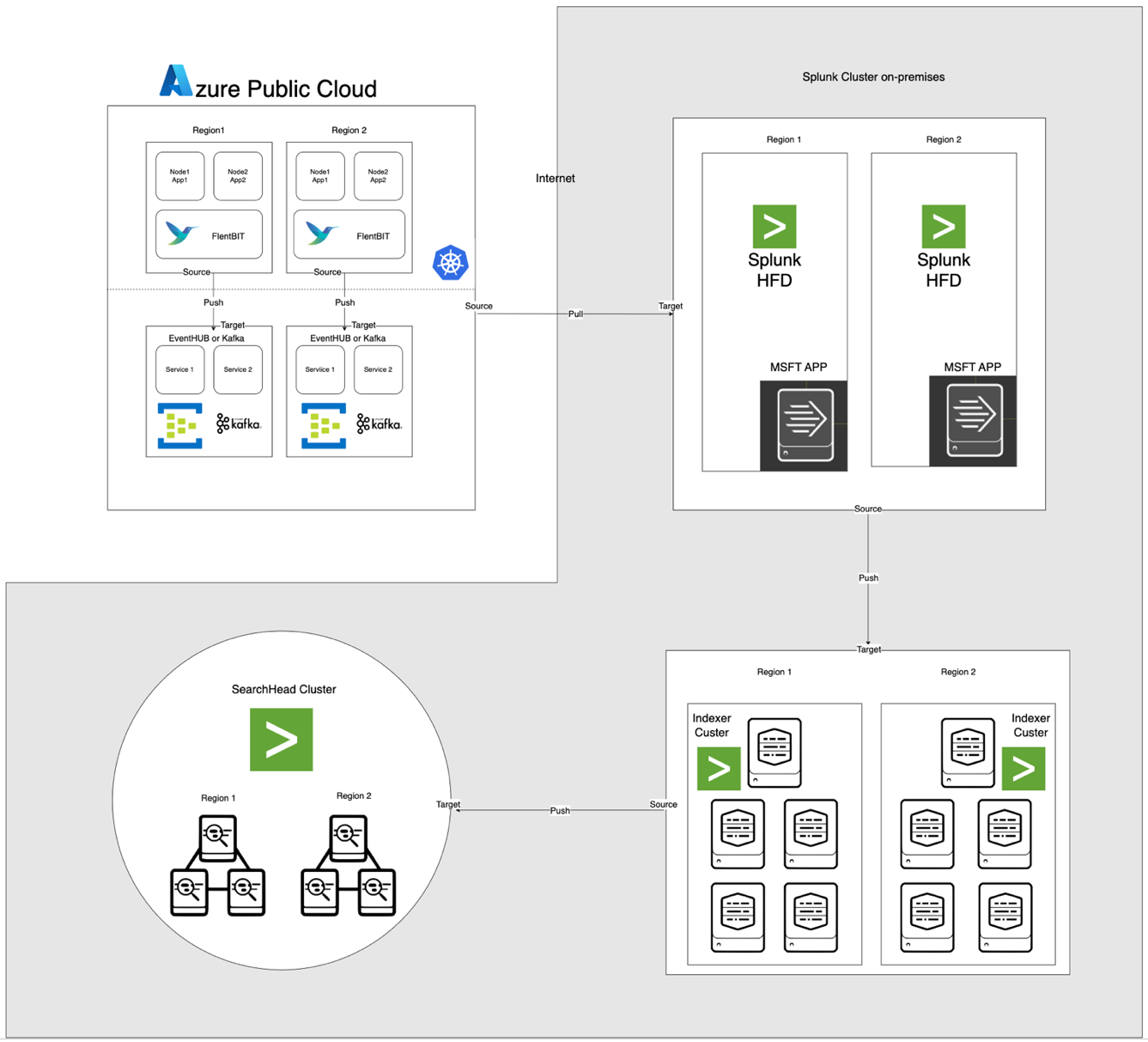
구성 요소 설명
- AKS: 컨테이너화된 응용 프로그램을 호스팅하고 Kubernetes의 로그 집계 레이어를 통해 접근 가능한 로그를 생성합니다.
- Fluent Bit: DaemonSet으로 배포되며 AKS 노드에서 로그를 수집합니다. 각 Fluent Bit 인스턴스는 /var/log/containers에서 로그를 캡처하고 필터링한 후 JSON 형식으로 EventHub로 전달합니다.
- Azure EventHub: 고처럼 메시지 브로커로 작동하여 Fluent Bit에서 로그를 집계하고 Splunk Heavy Forwarder에 의해 가져올 때까지 일시적으로 저장합니다.
- 아파치 카프카: Fluent Bit과 Splunk 사이의 신뢰할 수 있는 다리 역할을 합니다. Fluent Bit은 카프카 출력 플러그인을 사용하여 로그를 카프카로 전달하며, 여기서 로그는 일시적으로 저장되고 처리됩니다. Splunk는 그런 다음 카프카에서 로그를 가져와 Kafka Connect Splunk Sink 또는 사용자 정의 스크립트와 같은 커넥터를 사용하여 확장 가능하고 분리된 아키텍처를 보장합니다.
- Splunk Heavy Forwarder (HF): Apache CloudStack에 설치된 Heavy Forwarder는 Azure EventHub에서 로그를 가져오며, 이때 Microsoft Cloud Services용 Splunk 애드온을 사용합니다. 이 애드온은 Heavy Forwarder가 EventHub에 안전하게 연결되어 로그를 거의 실시간으로 가져와 필요에 따라 변환한 후 스토리지 및 처리를 위해 Splunk의 인덱서로 전달할 수 있도록 원활한 통합을 제공합니다.
- 아파치 CloudStack에서 Splunk: 로그 색인, 검색, 시각화 및 경고 기능을 제공합니다.
데이터 흐름
- AKS에서 로그 수집: Fluent Bit은 /var/log/containers의 로그 파일을 추적하여 불필요한 로그를 걸러내고 각 로그에 메타데이터(예: 컨테이너 이름, 네임스페이스)를 태깅합니다.
- EventHub로 전달: Fluent Bit의 azure_eventhub 출력 플러그인을 사용하여 로그를 HTTPS를 통해 EventHub로 전송하여 안전한 데이터 전송을 보장합니다.
- 아파치 카프카: AKS의 로그는 플루언트 비트에 의해 수집되며 데몬셋으로 실행되며 카프카 출력 플러그인을 통해 아파치 카프카로 파싱 및 전달됩니다. 카프카는 확장 가능성을 위해 로그를 저장하고 파티셔닝하는 고처리량 버퍼로 작동합니다. Splunk는 커넥터 또는 스크립트를 사용하여 이러한 로그를 카프카에서 가져와 색인화, 분석 및 실시간 모니터링을 가능하게 합니다.
- Splunk Heavy Forwarder를 사용하여 로그 가져오기: 아파치 클라우드스택의 헤비 포워더는 EventHubs SDK를 사용하여 EventHub에 연결하고 로그를 가져와 로컬 스플렁크 인덱서로 전달하여 저장 및 처리합니다.
- 스플렁크에서의 저장 및 분석: 로그는 스플렁크에 색인화되어 실시간 검색, 대시보드 시각화 및 로그 패턴에 기반한 경고가 가능해집니다.
방법론
AKS에서의 플루언트 비트 데몬셋 배포
플루언트 비트의 구성은 ConfigMap에 저장되어 데몬셋으로 배포됩니다. 다음은 플루언트 비트 데몬셋을 위한 확장된 구성입니다:
Name: fluentbit-cm
Namespace: fluentbit
Labels: k8s-app=fluentbit
Annotations:
Data
crio-logtag.lua:
local reassemble_state = {}
function reassemble_cri_logs(tag, timestamp, record)
-- 수신된 레코드 유효성 검사
if not record or not record.logtag or not record.log or type(record.log) == 'table' then
return 0, timestamp, record
end
-- 스트림 및 태그에 기반한 재조립을 위한 고유 키 생성
local reassemble_key = (record.stream or "unknown_stream") .. "::" .. tag
-- 로그 단편 처리 (logtag == 'P')
if record.logtag == 'P' then
-- 단편을 재조립 상태로 저장
reassemble_state[reassemble_key] = (reassemble_state[reassemble_key] or "") .. record.log
return -1, 0, 0 -- Do not forward this fragment
end
-- 단편화된 로그의 끝 처리
if reassemble_state[reassemble_key] then
-- 저장된 단편을 현재 로그와 결합
record.log = (reassemble_state[reassemble_key] or "") .. (record.log or "")
-- 이 키에 대한 저장된 상태 지우기
reassemble_state[reassemble_key] = nil
return 1, timestamp, record -- Forward the reassembled log
end
-- 재조립이 필요하지 않은 경우 로그를 그대로 전달
return 0, timestamp, record
end
INCLUDE filter-kubernetes.conf
filter-kubernetes.conf:
[FILTER]
Name kubernetes
Match test.app.splunk.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Kube_Tag_Prefix test.app.splunk.var.log.containers
Merge_Log On
Merge_Log_Key log_processed
K8S-Logging.Parser On
K8S-Logging.Exclude On
Labels Off
Annotations Off
Keep_Log Off
fluentbit.conf:
[SERVICE]
Flush 1
Log_Level info
Daemon on
Parsers_File parsers.conf
HTTP_Server On
HTTP_Listen 0.0.0.0
HTTP_Port 2020
Health_Check On
HC_Errors_Count 1
HC_Retry_Failure_Count 1
HC_Period 5
INCLUDE input-kubernetes.conf
INCLUDE output-kafka.conf
input-kubernetes.conf:
[INPUT]
Name tail
Tag test.app.splunk*
Alias test.app.splunk-input
Path /var/log/containers/*test.app.splunk.log
Parser cri
DB /var/log/flb_kube.db
Buffer_Chunk_Size 256K
Buffer_Max_Size 24MB
Mem_Buf_Limit 1GB
Skip_Long_Lines On
Refresh_Interval 5
output-kafka.conf:
[OUTPUT]
Name kafka
Alias test.app.splunk-output
Match test.app.splunk.*
Brokers prod-region-logs-premium.servicebus.windows.net:9094
Topics test.app.splunk
Retry_Limit 5
rdkafka.security.protocol SASL_SSL
rdkafka.sasl.mechanism PLAIN
rdkafka.sasl.username $ConnectionString
rdkafka.sasl.password Endpoint=sb://prod-region-logs-premium.servicebus.windows.net/;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=***********************************************=
[OUTPUT]
parsers.conf:
[PARSER]
Name cri
Format regex
Regex ^(? - [INPUT] 섹션은 /var/log/containers 디렉토리에서 로그 수집을 지정합니다.
- [FILTER] 섹션은 Kubernetes 메타데이터로 로그를 보강합니다.
- [OUTPUT] 섹션은 Fluent Bit을 구성하여 JSON 형식으로 로그를 EventHub으로 전송합니다.
Azure EventHub 구성
EventHub은 네임스페이스, 특정 EventHub 인스턴스 및 공유 액세스 정책을 통해 액세스 제어가 필요합니다.
- 네임스페이스 및 EventHub 설정: Azure에서 네임스페이스 및 EventHub 인스턴스를 생성하고, 전송 정책을 설정하고 연결 문자열을 검색합니다.
- 고 처리량 구성: EventHub은 Fluent Bit에서 동시 데이터 스트림, 버퍼링 및 확장성을 지원하기 위해 높은 파티션 수로 구성됩니다.
Apache CloudStack에서 Splunk Heavy Forwarder 구성
Splunk Heavy Forwarder는 EventHub에서 로그를 검색하여 Splunk의 인덱서로 전달합니다.
- Microsoft Cloud Services용 추가 구성: EventHub 연결을 활성화하려면 추가 구성을 설치하세요.
inputs.conf에서 입력을 구성하세요:
[azure_eventhub://eventhub_name]
index = <index_name>
eventhub_namespace = <namespace>
shared_access_key_name = <access_key_name>
shared_access_key = <access_key>
batch_size = 500
interval = 30
sourcetype = _json
disabled = 0- 일괄 처리: 데이터 흡수를 최적화하고 네트워크 호출 빈도를 줄이려면 batch_size를 500으로 설정하고 인터벌을 30초로 설정하세요.
Splunk 인덱싱 및 시각화
- 데이터 보강: Splunk에서 추가 메타데이터로 로그를 보강합니다.
- 검색 및 대시보드: SPL 쿼리를 통해 실시간 검색이 가능하며, 사용자 정의 대시보드는 로그 패턴을 시각화합니다.
- 알림: 특정 로그 패턴(예: 높은 오류율 또는 특정 컨테이너에서 반복되는 경고)이 트리거되도록 경고가 구성됩니다.
성능 및 확장성
시스템이 고처리량 로그 적재를 처리할 수 있음을 보여주는 테스트에서 EventHub의 버퍼링 기능이 네트워크 중단 중에 데이터 손실을 방지합니다. AKS 노드에서 Fluent Bit 리소스 사용량은 최소이며, 적절한 색인 및 필터링 구성으로 Splunk의 인덱서가 로그 볼륨을 효율적으로 처리합니다.
보안
AKS와 EventHub 간 통신을 보호하기 위해 HTTPS를 사용하며, Splunk HF는 EventHub와의 인증을 위해 안전한 키를 사용합니다. 파이프라인의 각 구성 요소는 데이터 무결성을 유지하기 위한 재시도 메커니즘을 구현합니다.
자원 활용
- Fluent Bit은 AKS 노드에서 평균 100-150 MiB의 메모리와 0.2-0.3 CPU를 사용합니다.
- EventHub의 리소스 사용량은 파티션 및 처리량 구성에 따라 동적으로 조정됩니다.
- Splunk HF의 부하는 일괄 처리를 통해 균형을 유지하여 Apache CloudStack 리소스를 과부하시키지 않고 데이터 전송을 최적화합니다.
신뢰성 및 내결함성
솔루션은 EventHub의 버퍼링을 사용하여 하류 장애가 발생한 경우에도 로그 유지를 보장합니다. EventHub는 재시도 정책을 지원하여 데이터 무결성과 신뢰성을 더욱 향상시킵니다.
토론
하이브리드 클라우드 아키텍처의 장점
이 아키텍처는 Azure 서비스와 온프레미스 제어를 결합하여 유연성, 확장성 및 보안을 제공합니다. 또한 데이터 주권을 훼손하지 않고 클라우드 기반의 스트리밍 및 버퍼링 기능을 활용합니다.
제한 사항
EventHub는 신뢰할 수 있는 데이터 집계를 제공하지만 처리량 단위가 증가함에 따라 비용이 증가하므로 로그 전달 구성을 최적화하는 것이 중요합니다. 또한 클라우드와 온프레미스 환경 간의 데이터 전송은 잠재적인 지연을 초래할 수 있습니다.
미래 응용
이 아키텍처는 로그에서 이상 감지를 위해 기계 학습을 통합하거나 다중 클라우드 제공업체 지원을 추가하여 로그 처리 및 다중 클라우드 내구성을 더 확장할 수 있습니다.
결론
본 연구는 클라우드 및 온프레미스 리소스를 활용한 하이브리드 로그 처리 파이프라인의 효과를 입증합니다. Azure Kubernetes Service (AKS), Azure EventHub 및 Apache CloudStack의 Splunk를 통합하여 중앙 집중식 로그 관리 및 분석을 위한 확장 가능하고 견고한 솔루션을 만듭니다. 이 아키텍처는 고 데이터 처리량, 보안 및 오류 허용성을 포함한 분산 로깅의 주요 도전에 대응합니다.
AKS에서 경량 로그 수집기로서의 Fluent Bit 사용은 최소한의 자원 소모로 효율적인 데이터 수집을 보장합니다. Azure EventHub의 버퍼링 기능을 통해 신뢰할 수 있는 로그 집계와 임시 저장이 가능해져 다양한 로그 트래픽을 처리하고 연결 문제 발생 시 데이터 무결성을 유지하는 데 적합해집니다. Splunk Heavy Forwarder와 Apache CloudStack 내 Splunk 배포는 조직이 로그 저장 및 분석에 대한 통제를 유지하면서 클라우드 자원의 확장성과 유연성을 누릴 수 있도록 합니다.
이 접근법은 하이브리드 클라우드 설정이 필요한 조직에게 상당한 이점을 제공합니다. 데이터에 대한 향상된 통제, 데이터 거주 요구 사항 준수, 수요에 따른 확장성을 갖고 있습니다. 향후 작업에서는 기계 학습 통합을 통해 로그 분석을 향상시키고 자동 이상 징후 감지를 확대하여 다중 클라우드 설정으로 확장하여 회복력과 다양성을 확대할 수 있습니다. 이 연구는 기업 환경의 현대적이고 분산된 시스템의 변화하는 요구 사항에 적응 가능한 기본 아키텍처를 제공합니다.
참고문헌
Azure Event Hubs 및 Kafka
하이브리드 모니터링 및 로깅
- 하이브리드 및 멀티 클라우드 모니터링 패턴
- 하이브리드 클라우드 모니터링 전략
스플렁크 통합
- 스플렁크 Azure 이벤트 허브
- 스플렁크 플랫폼으로의 Azure 데이터
AKS 배포
Source:
https://dzone.com/articles/bridging-cloud-and-on-premises-log-processing