













Настройка AWS CLI и AWS S3
Перед тем как углубиться в команду aws s3 cp, необходимо установить и правильно настроить AWS CLI на вашей системе. Не беспокойтесь, если вы никогда не работали с AWS ранее – процесс настройки прост и займет не более 10 минут.
Я разобью это на три простых этапа: установка инструмента AWS CLI, настройка ваших учетных данных и создание вашего первого S3 ведра для хранения.
Установка AWS CLI
Процесс установки немного отличается в зависимости от используемой операционной системы.
Для систем Windows:
- Перейдите на официальную страницу документации AWS CLI
- Скачайте установщик для Windows 64-bit
- Запустите загруженный файл и следуйте инструкциям мастер установки
Для систем Linux:
Выполните следующие три команды в терминале:
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" unzip awscliv2.zip sudo ./aws/install
Для систем macOS:
Если у вас установлен Homebrew, введите эту команду в терминале:
brew install awscli
Если у вас нет Homebrew, используйте эти две команды вместо этого:
curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg" sudo installer -pkg AWSCLIV2.pkg -target /
Чтобы подтвердить успешную установку, выполните aws --version в вашем терминале. Вы должны увидеть что-то вроде этого:
Изображение 1 – Версия AWS CLI
Настройка AWS CLI
После установки CLI пришло время настроить ваши учетные данные AWS для аутентификации.
Сначала войдите в свою учетную запись AWS и перейдите на панель управления службой IAM. Создайте нового пользователя с программным доступом и прикрепите соответствующую политику разрешений S3:
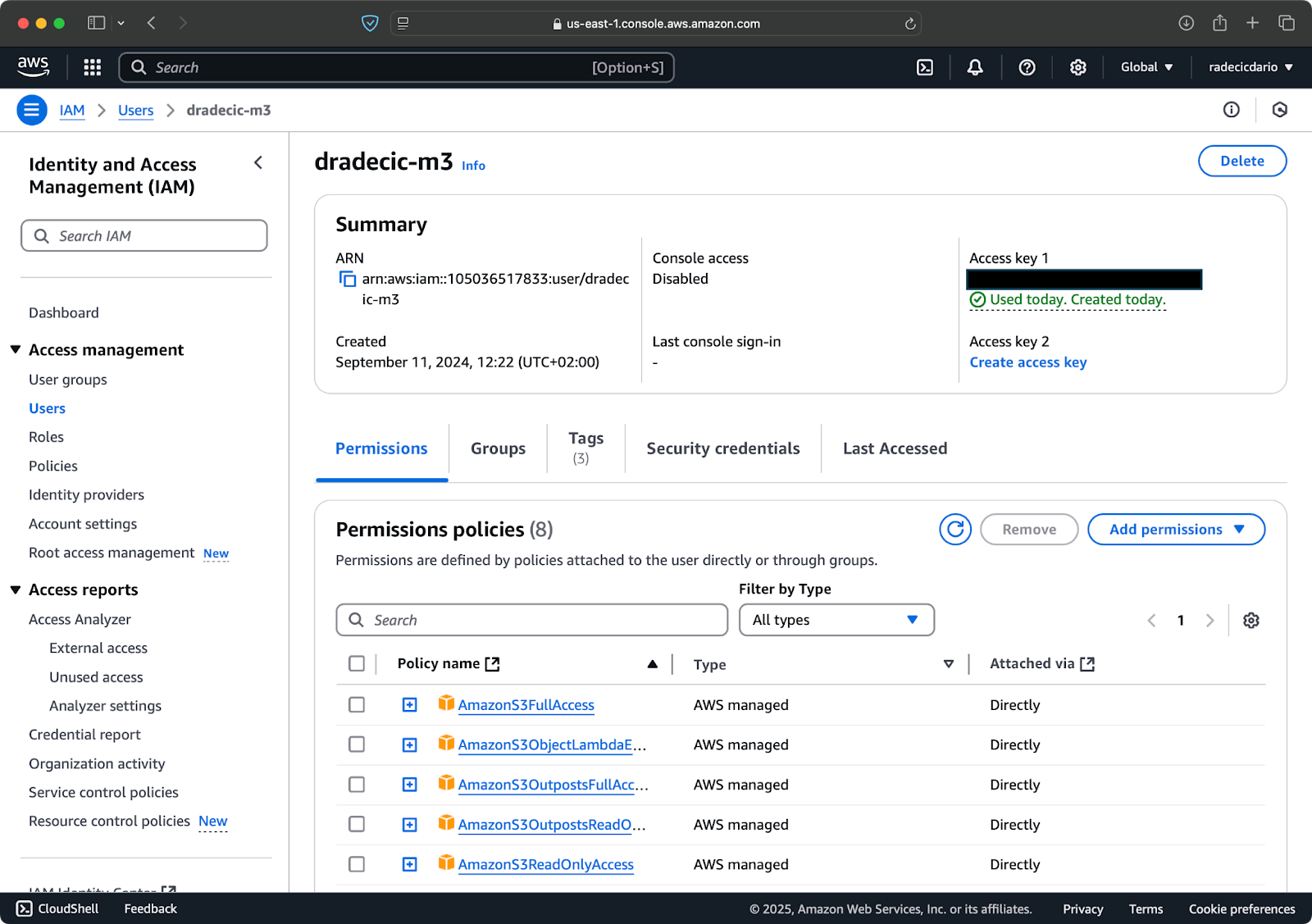
Изображение 2 – Пользователь AWS IAM
Далее, перейдите на вкладку “Учетные данные безопасности” и сгенерируйте новую пару ключей доступа. Обязательно сохраните как Идентификатор ключа доступа, так и Секретный ключ доступа в безопасном месте – Amazon не покажет вам секретный ключ снова после этого экрана:
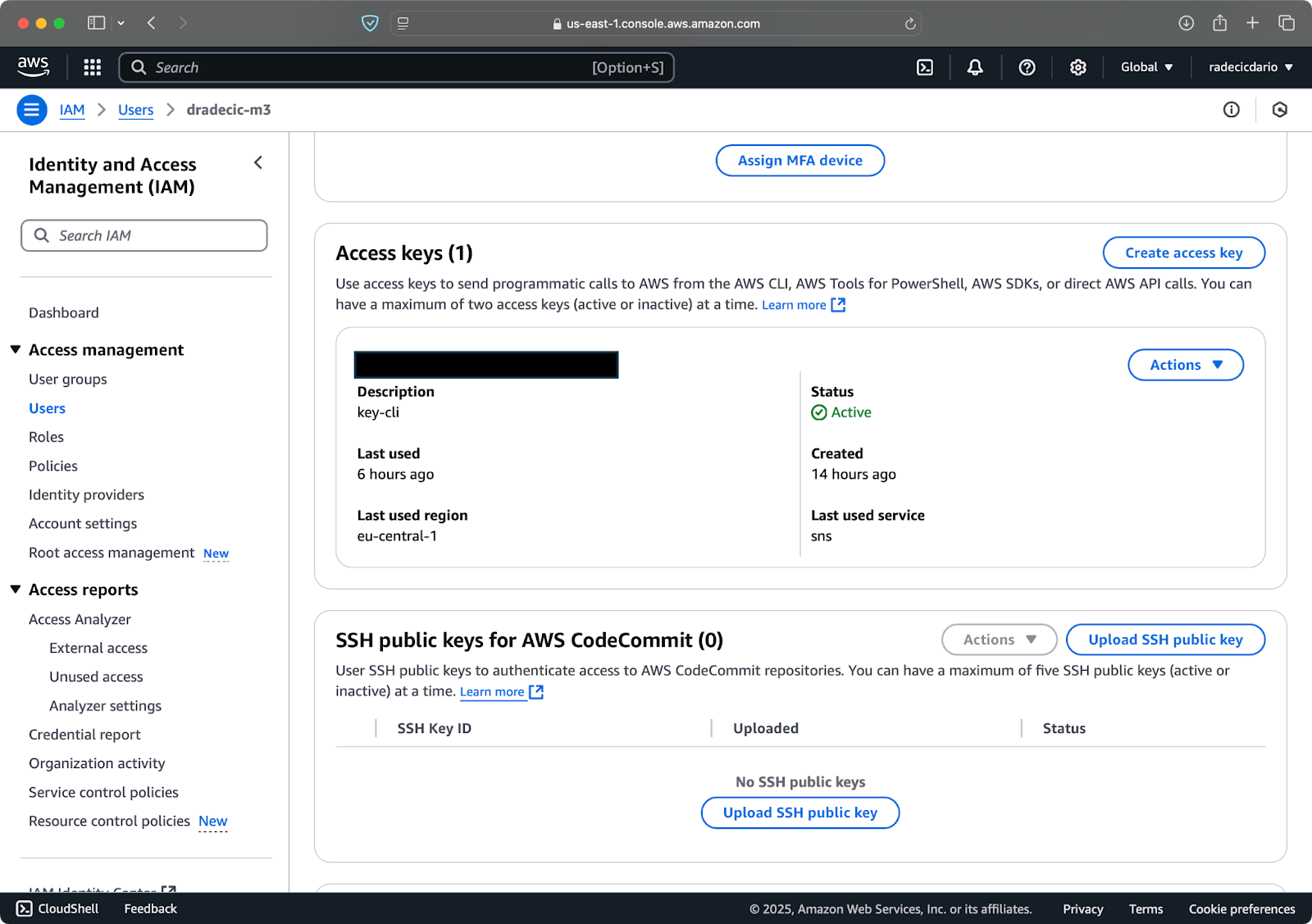
Изображение 3 – Учетные данные пользователя AWS IAM
Теперь откройте терминал и выполните команду aws configure. Вам будет предложено ввести четыре куска информации: ваш идентификатор ключа доступа, секретный ключ доступа, регион по умолчанию (я использую eu-central-1), и предпочтительный формат вывода (обычно json):
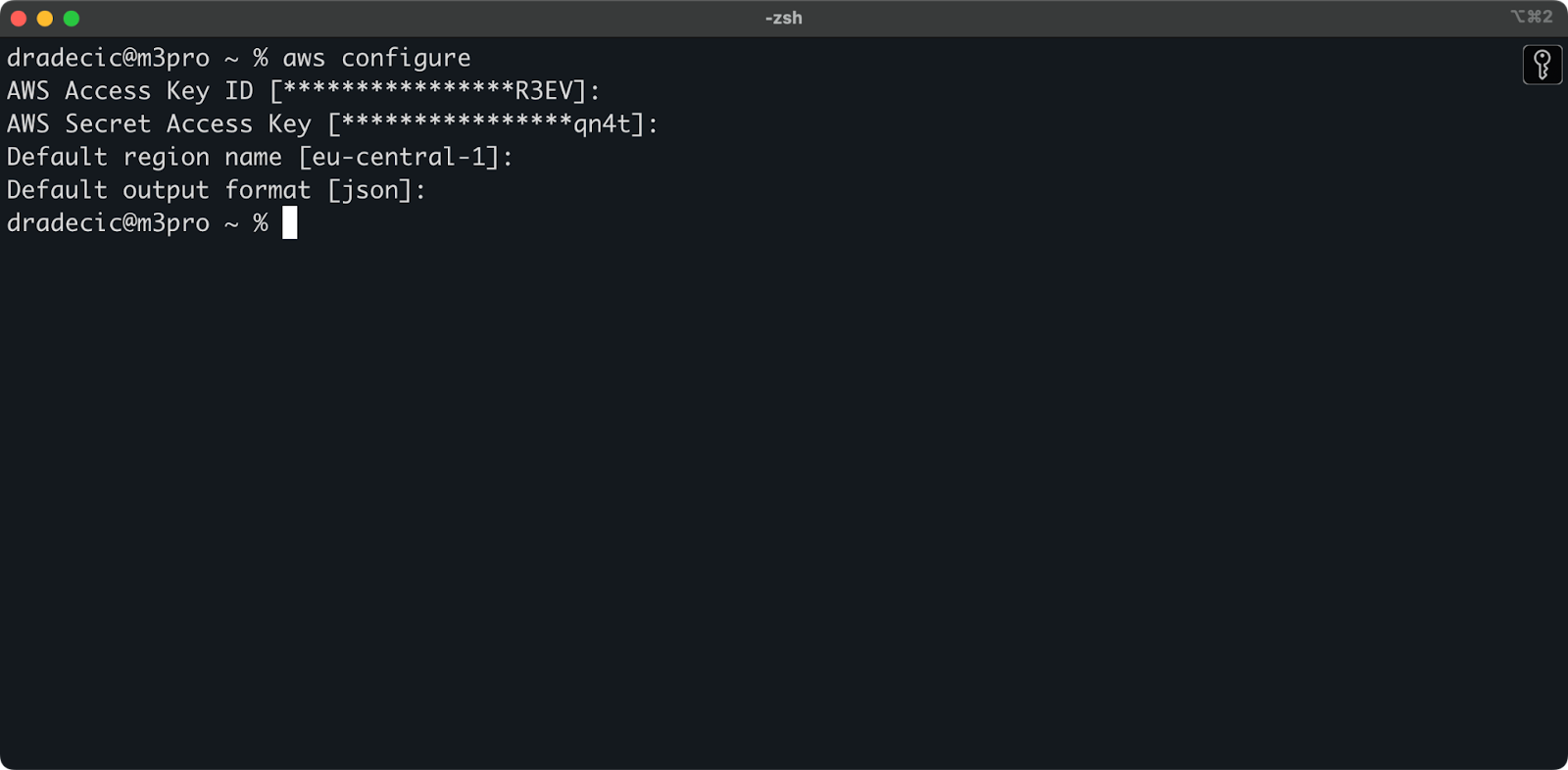
Изображение 4 – настройка AWS CLI
Чтобы убедиться, что всё подключено правильно, подтвердите вашу личность следующей командой:
aws sts get-caller-identity
Если всё настроено правильно, вы увидите детали вашей учетной записи:
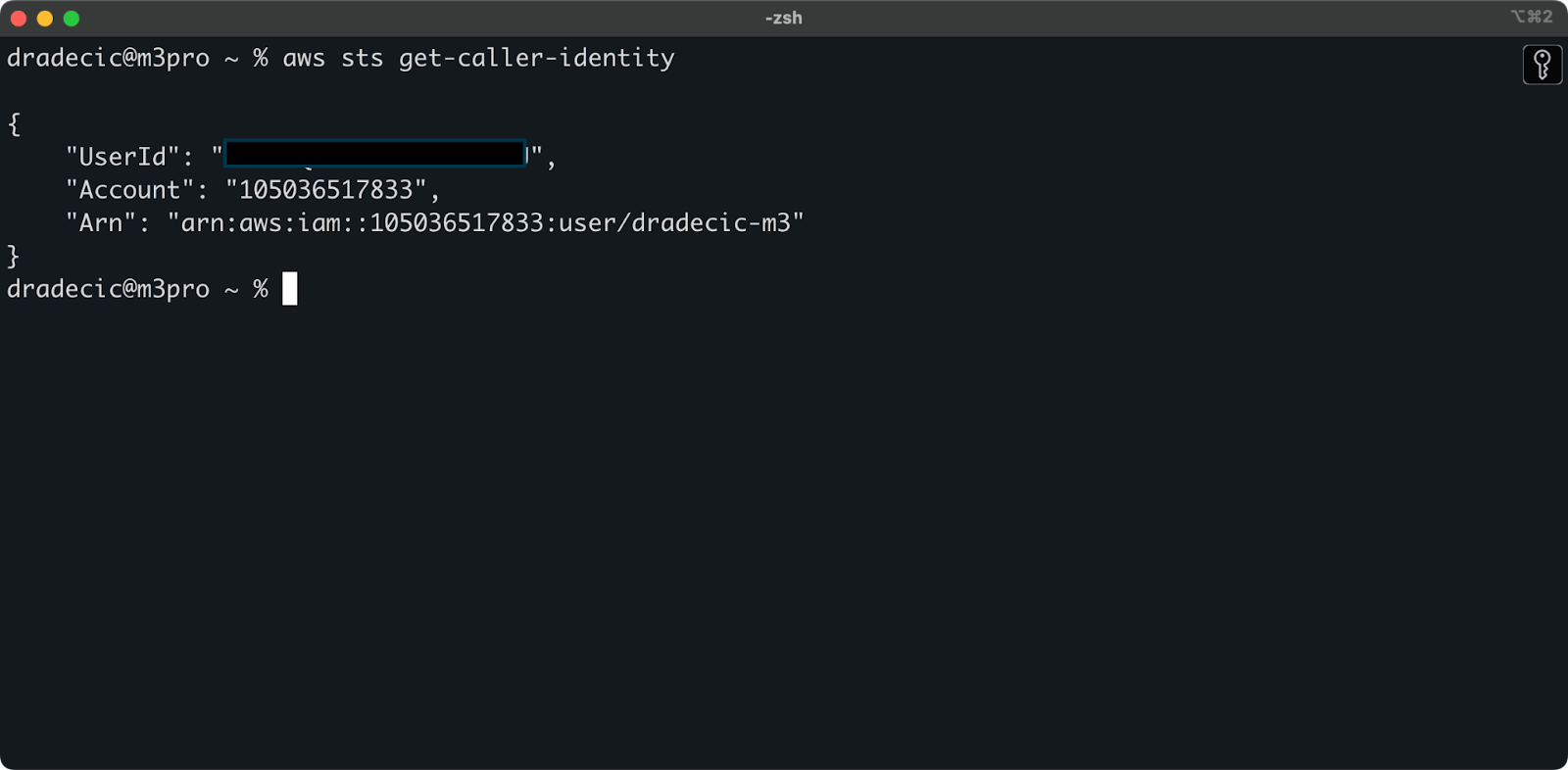
Изображение 5 – команда подключения теста AWS CLI
Создание бакета S3
Наконец, вам нужно создать бакет S3 для хранения файлов, которые вы будете копировать.
Перейдите в раздел сервиса S3 в вашей консоли AWS и нажмите “Создать бакет”. Помните, что имена бакетов должны быть уникальными во всей AWS. Выберите характерное имя, оставьте настройки по умолчанию на данный момент и нажмите “Создать”:
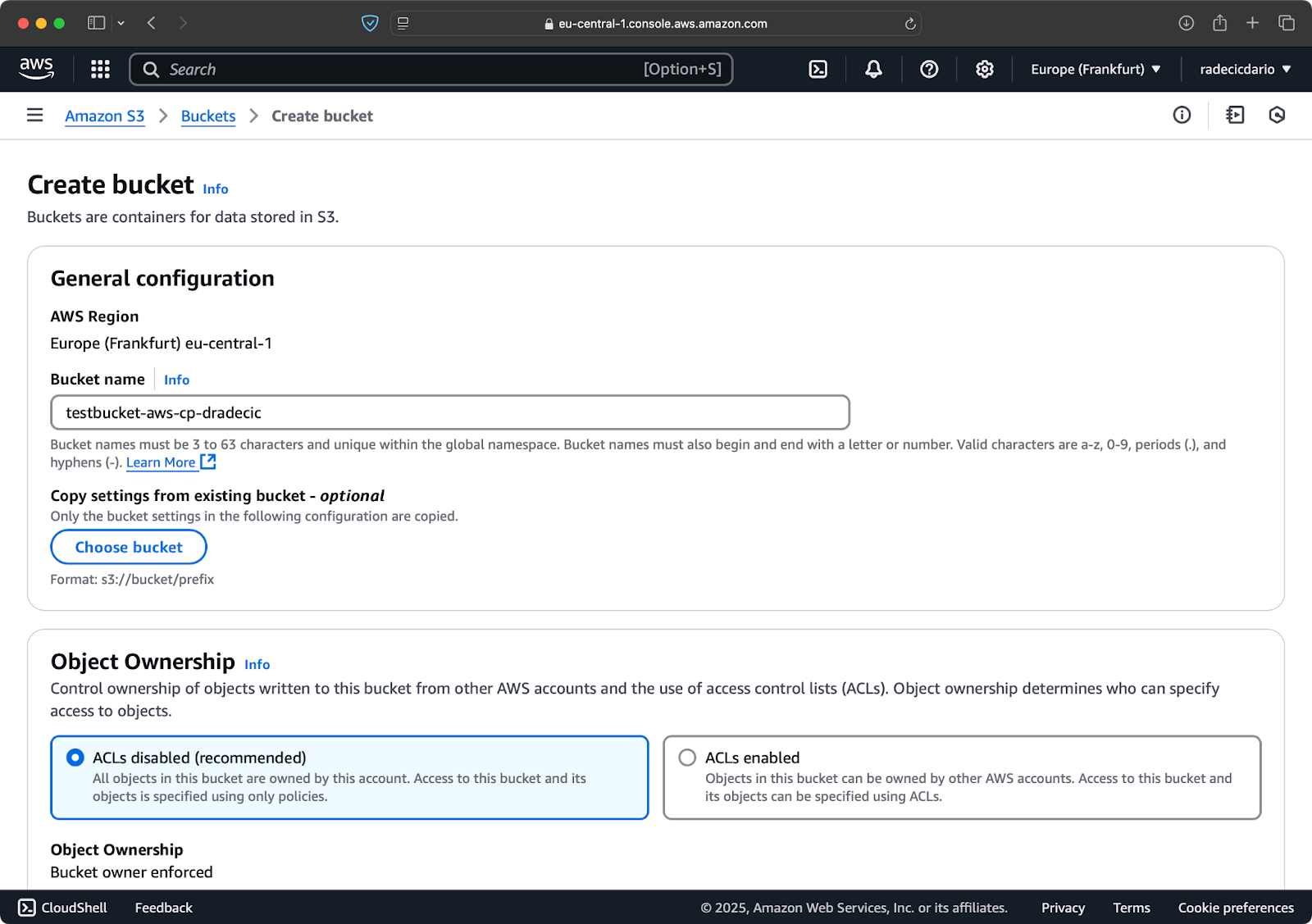
Изображение 6 – создание бакета AWS
После создания ваш новый бакет появится в консоли. Вы также можете подтвердить его существование через командную строку:
aws s3 ls
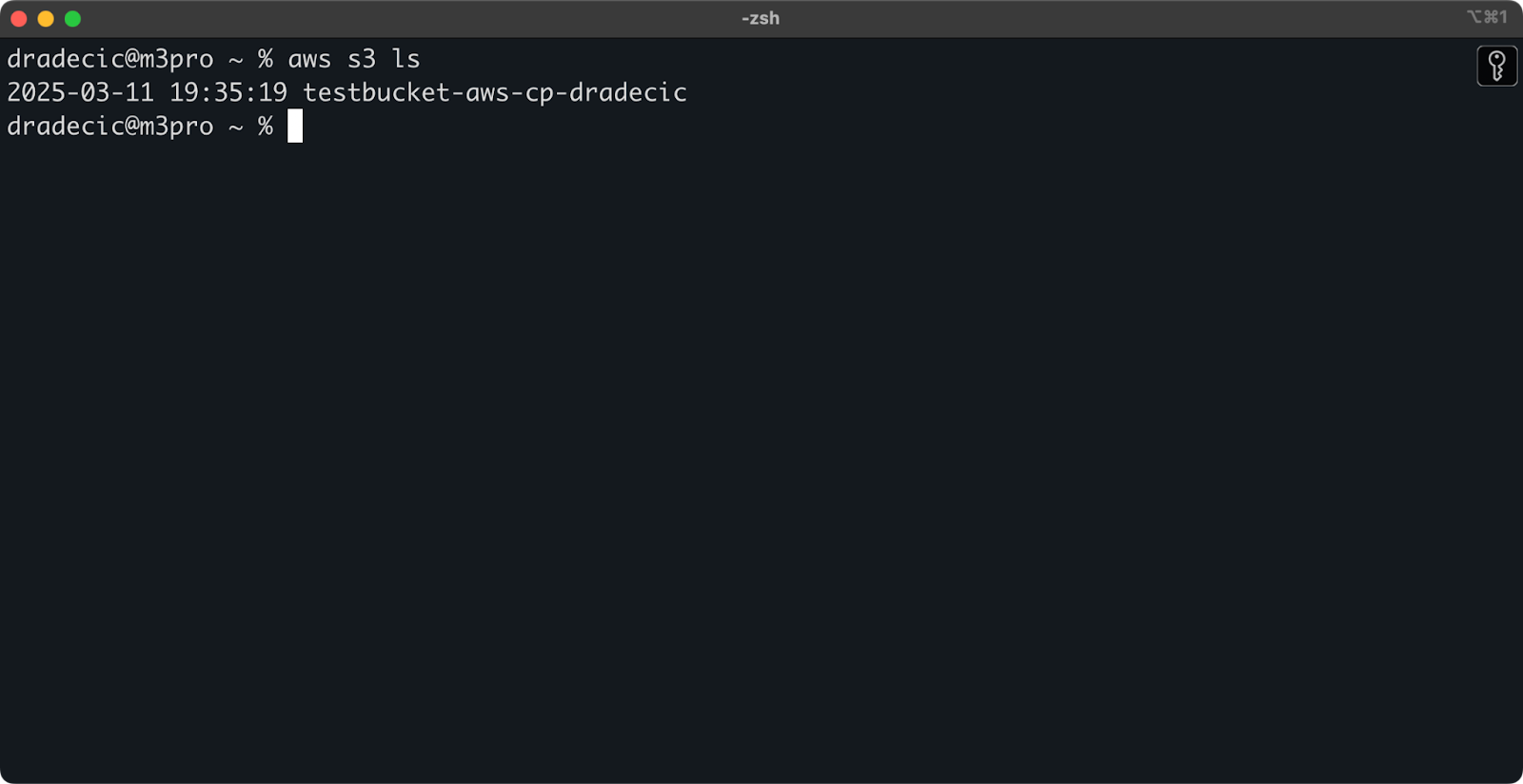
Изображение 7 – Все доступные бакеты S3
Все бакеты S3 настроены как приватные по умолчанию, поэтому имейте это в виду. Если вы планируете использовать этот бакет для общедоступных файлов, вам нужно будет изменить политики бакета соответственно.
Теперь вы полностью готовы начать использовать команду aws s3 cp для передачи файлов. Давайте перейдем к основам далее.
Базовый синтаксис команды AWS S3 cp
Теперь, когда у вас все настроено, давайте перейдем к базовому использованию команды aws s3 cp. Как обычно в AWS, красота заключается в простоте, хотя команда может обрабатывать различные сценарии передачи файлов.
В своей самой базовой форме команда aws s3 cp следует такому синтаксису:
aws s3 cp <source> <destination> [options]
Где <source> и <destination> могут быть локальными путями к файлам или URI S3 (которые начинаются с s3://). Давайте рассмотрим три наиболее распространенных случая использования.
Копирование файла с локальной машины в S3
Чтобы скопировать файл с вашей локальной системы в бакет S3, исходный файл будет локальным путем, а место назначения – URI S3:
aws s3 cp /Users/dradecic/Desktop/test_file.txt s3://testbucket-aws-cp-dradecic/test_file.txt
Эта команда загружает файл test_file.txt из указанного каталога в указанный бакет S3. Если операция прошла успешно, вы увидите вывод консоли примерно такого вида:
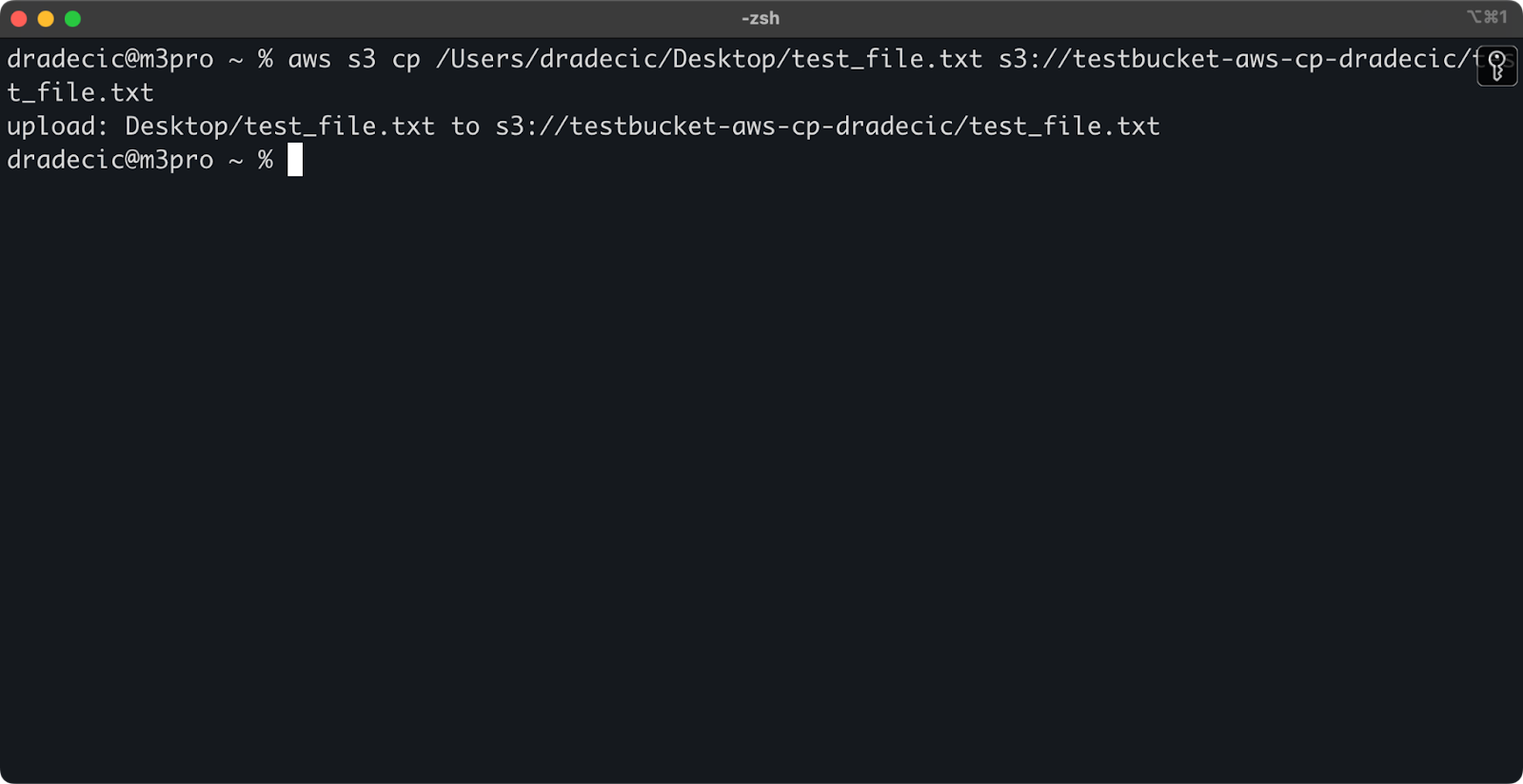
Изображение 8 – Вывод консоли после копирования локального файла
И на консоли управления AWS вы увидите загруженный файл:
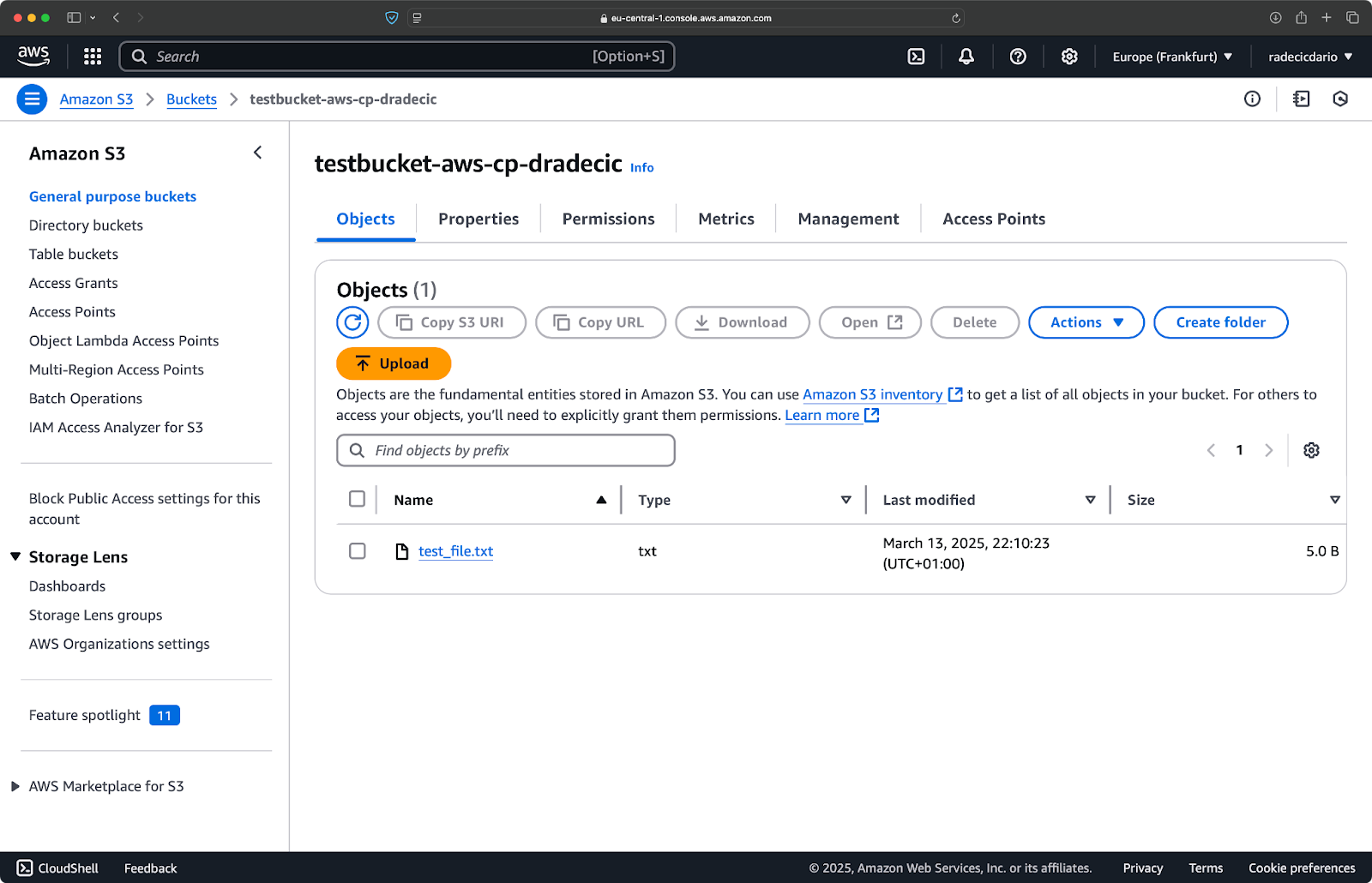
Изображение 9 – Содержимое бакета S3
Аналогично, если вы хотите скопировать локальную папку в ваш бакет S3 и поместить ее, скажем, в другую вложенную папку, выполните команду, подобную этой:
aws s3 cp /Users/dradecic/Desktop/test_folder s3://testbucket-aws-cp-dradecic/my-desired-folder/test_folder/ --recursive
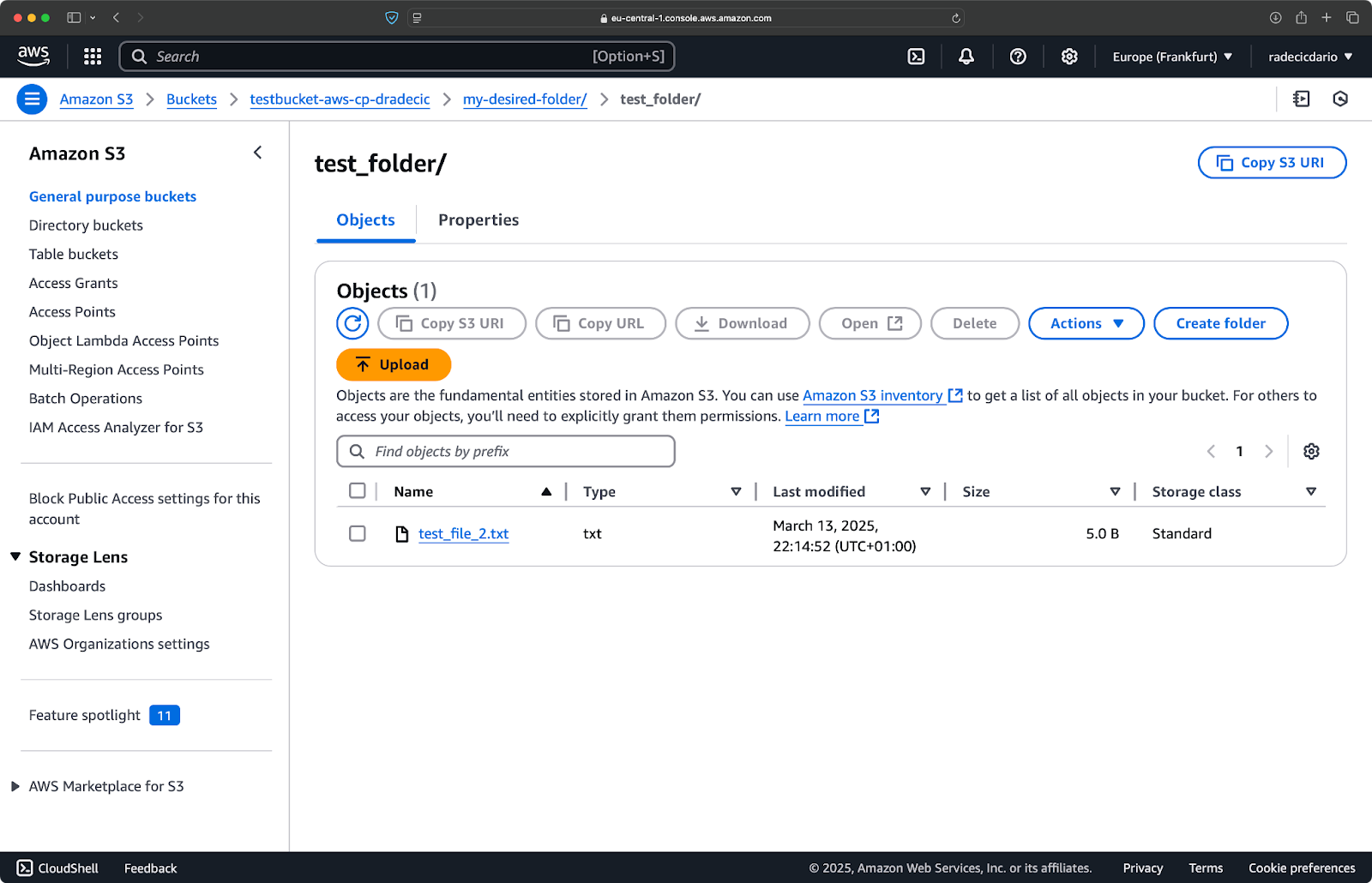
Изображение 10 – Содержимое бакета S3 после загрузки папки
Флаг --recursive гарантирует копирование всех файлов и подпапок внутри папки.
Просто помните – в S3 фактически нет папок – структура пути является частью ключа объекта, но концептуально работает как папки.
Копирование файла из S3 на локальный
Для копирования файла с S3 на ваш локальный компьютер просто поменяйте порядок – исходный файл становится URI S3, а путь назначения – вашим локальным путем:
aws s3 cp s3://testbucket-aws-cp-dradecic/test_file.txt /Users/dradecic/Documents/s3-data/downloaded_test_file.txt
Эта команда загружает test_file.txt из вашего бакета S3 и сохраняет его как downloaded_test_file.txt в указанной директории. Вы увидите его немедленно на вашем локальном компьютере:
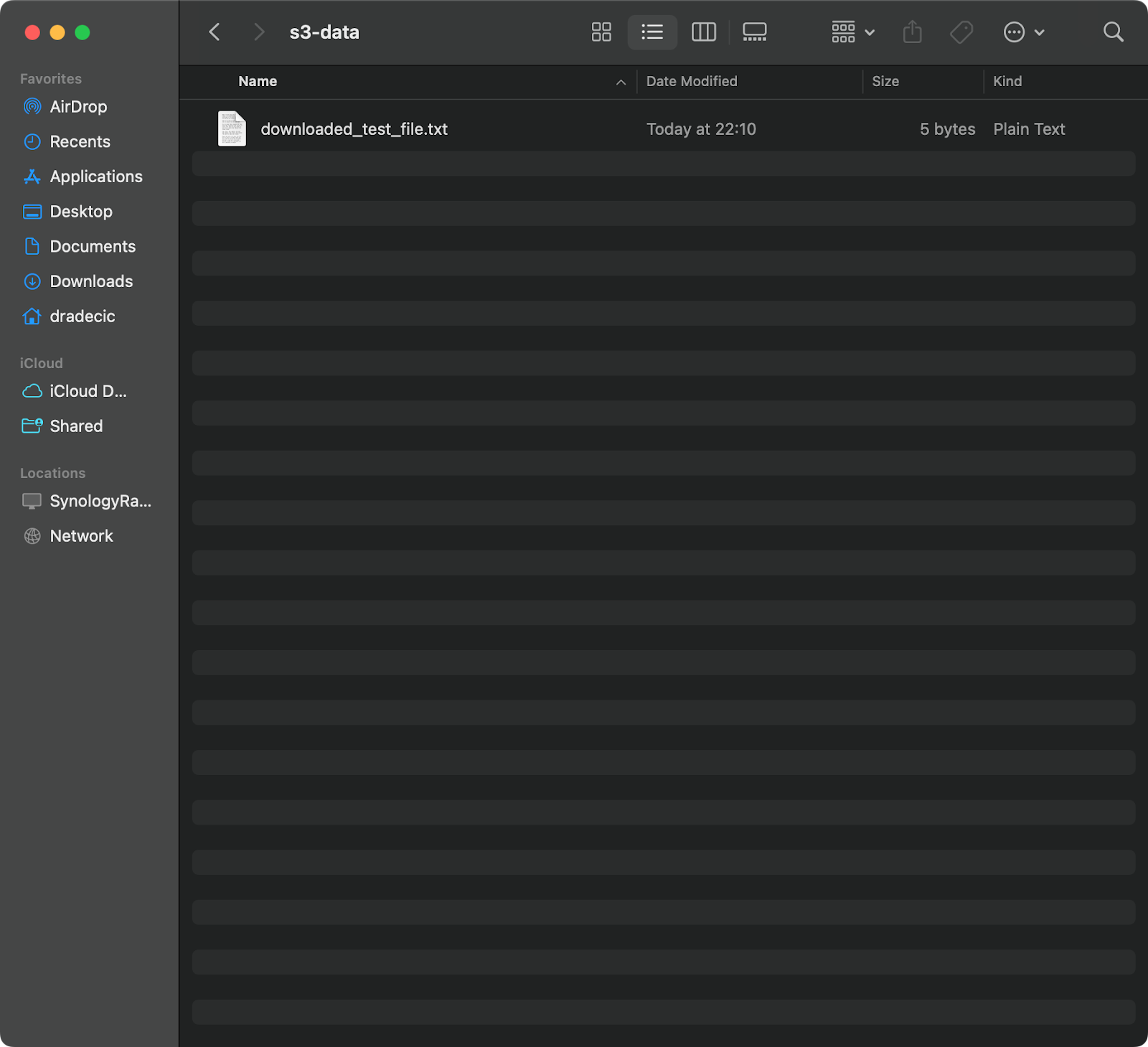
Изображение 11 – Загрузка одного файла из S3
Если вы пропустите имя файла назначения, команда будет использовать оригинальное имя файла:
aws s3 cp s3://testbucket-aws-cp-dradecic/test_file.txt .
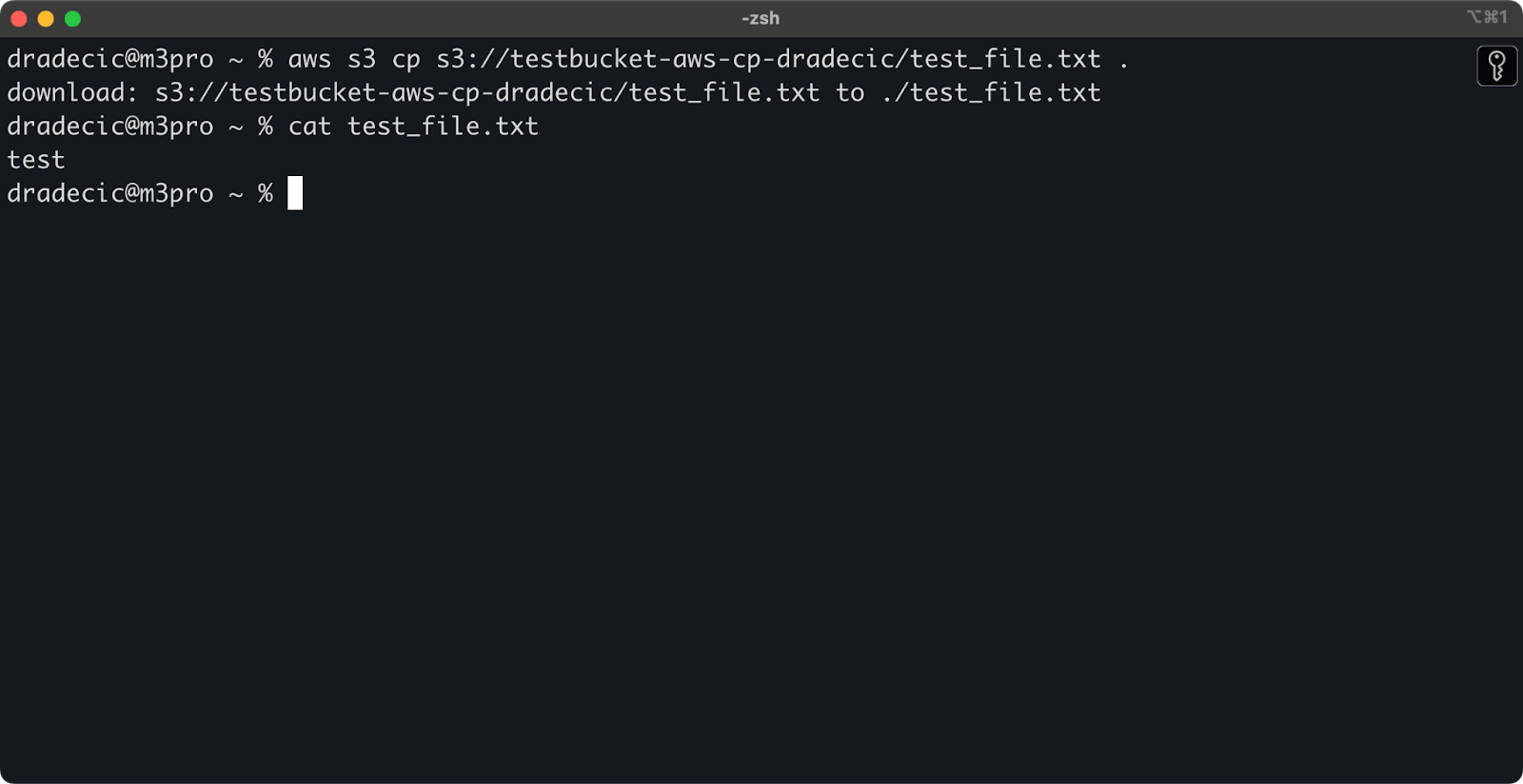
Изображение 12 – Содержимое загруженного файла
Точка (.) представляет вашу текущую директорию, поэтому это загрузит test_file.txt в ваше текущее местоположение.
И, наконец, чтобы загрузить целый каталог, вы можете использовать команду, подобную этой:
aws s3 cp s3://testbucket-aws-cp-dradecic/my-desired-folder/test_folder /Users/dradecic/Documents/test_folder --recursive
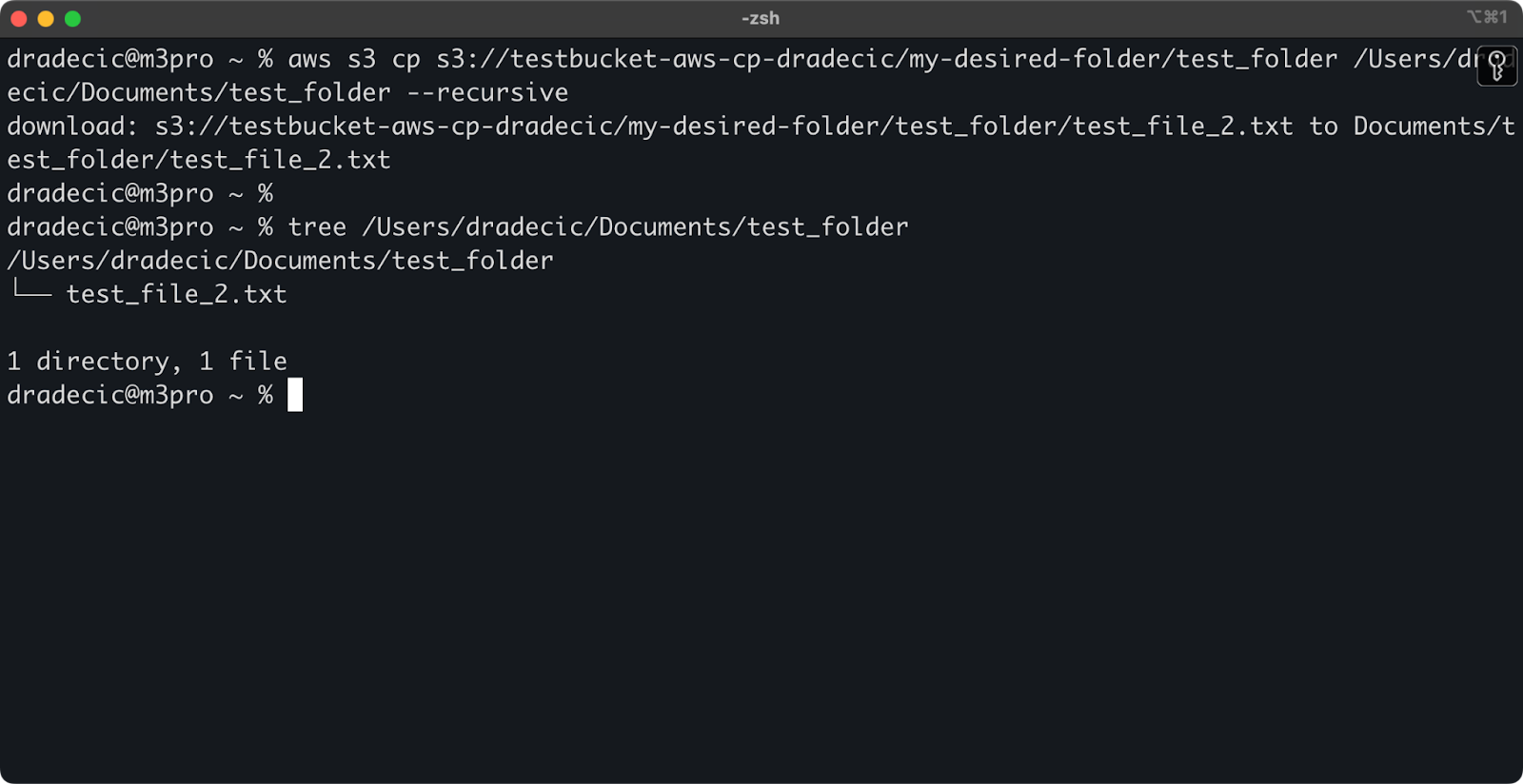
Изображение 13 – Содержимое загруженной папки
Имейте в виду, что флаг --recursive необходим при работе с несколькими файлами – без него команда завершится ошибкой, если источником является каталог.
С помощью этих базовых команд вы уже сможете выполнить большую часть задач по передаче файлов, которые вам понадобятся. Но в следующем разделе вы узнаете о более продвинутых опциях, которые предоставят вам лучший контроль над процессом копирования.
Продвинутые опции и функции AWS S3 cp
AWS предлагает несколько продвинутых опций, которые позволяют максимизировать операции копирования файлов. В этом разделе я покажу вам некоторые из наиболее полезных флагов и параметров, которые помогут вам в вашей повседневной работе.
Использование флагов –exclude и –include
Иногда вам нужно скопировать только определенные файлы, соответствующие конкретным шаблонам. Флаги --exclude и --include позволяют фильтровать файлы на основе шаблонов и дают вам точный контроль над тем, что будет скопировано.
Чтобы задать контекст, вот структура каталога, с которой я работаю:
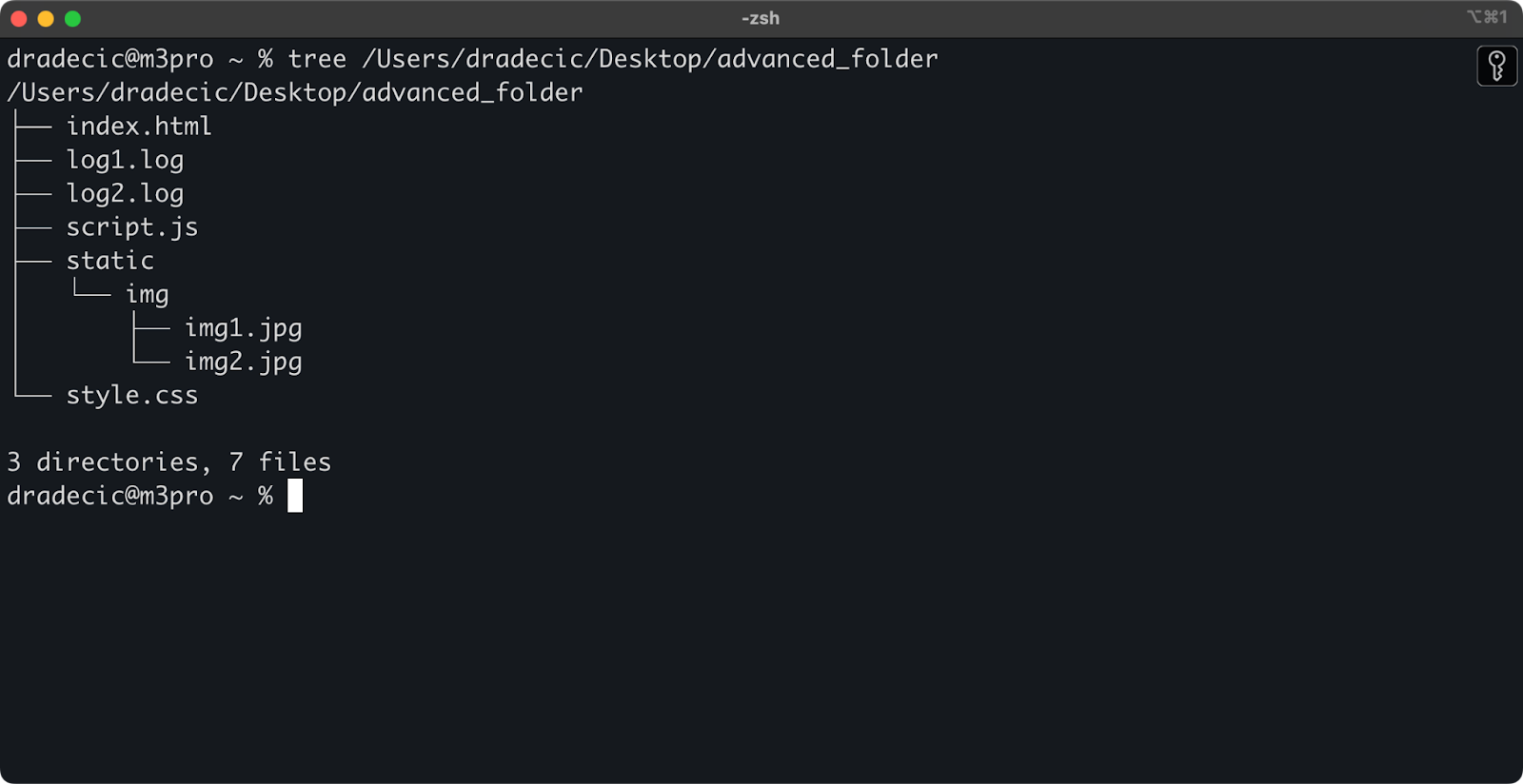
Изображение 14 – Структура каталога
Теперь, предположим, вы хотите скопировать все файлы из каталога, кроме файлов с расширением .log:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exclude "*.log"
Эта команда скопирует все файлы из каталога advanced_folder в S3, исключая любые файлы с расширением .log:
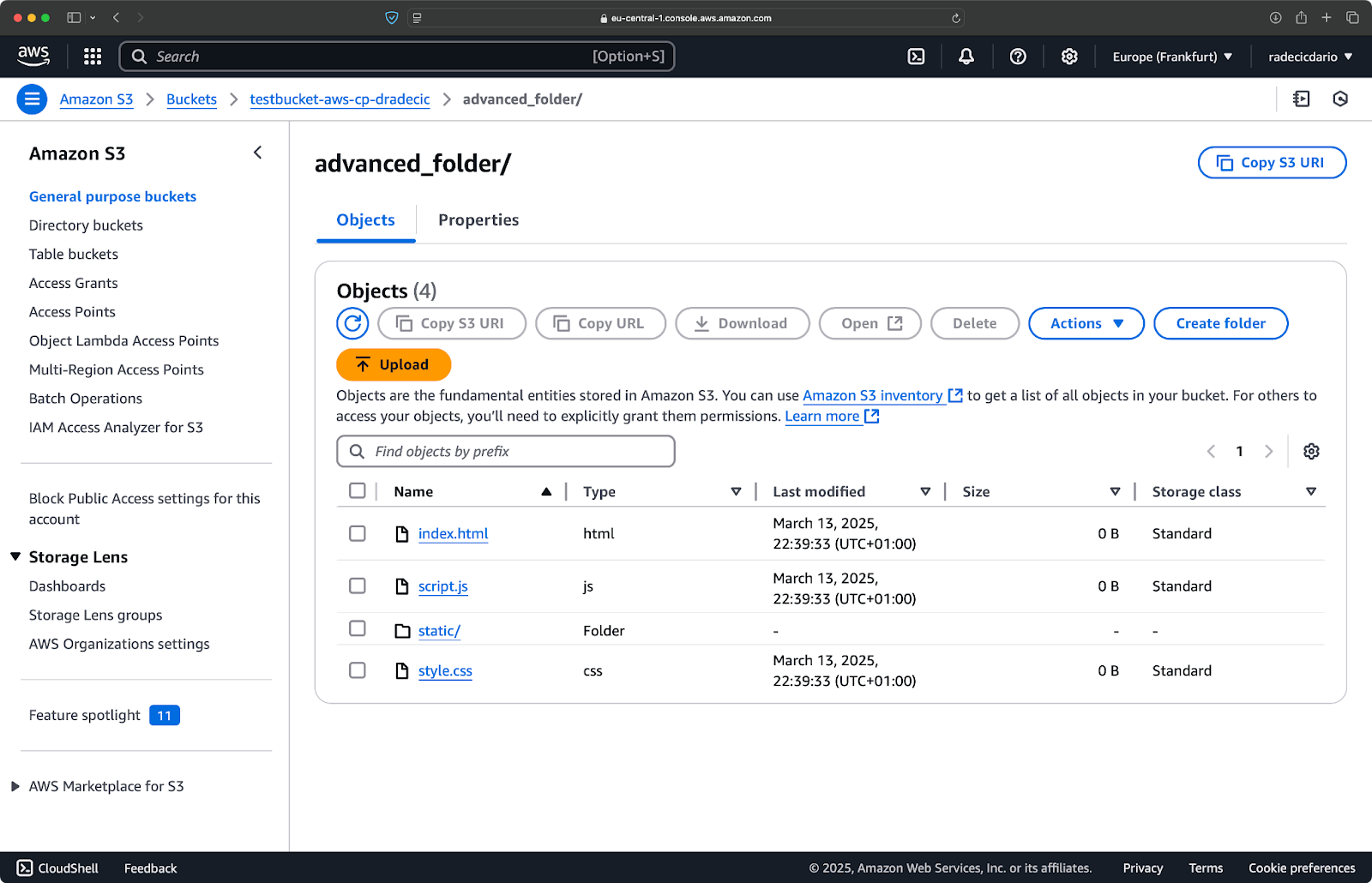
Изображение 15 – Результаты копирования папки
Вы также можете комбинировать несколько шаблонов. Предположим, вы хотите скопировать только HTML и CSS файлы из папки проекта:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exclude "*" --include "*.html" --include "*.css"
Эта команда сначала исключает все (--exclude "*"), затем включает только файлы с расширениями .html и .css. Результат выглядит так:
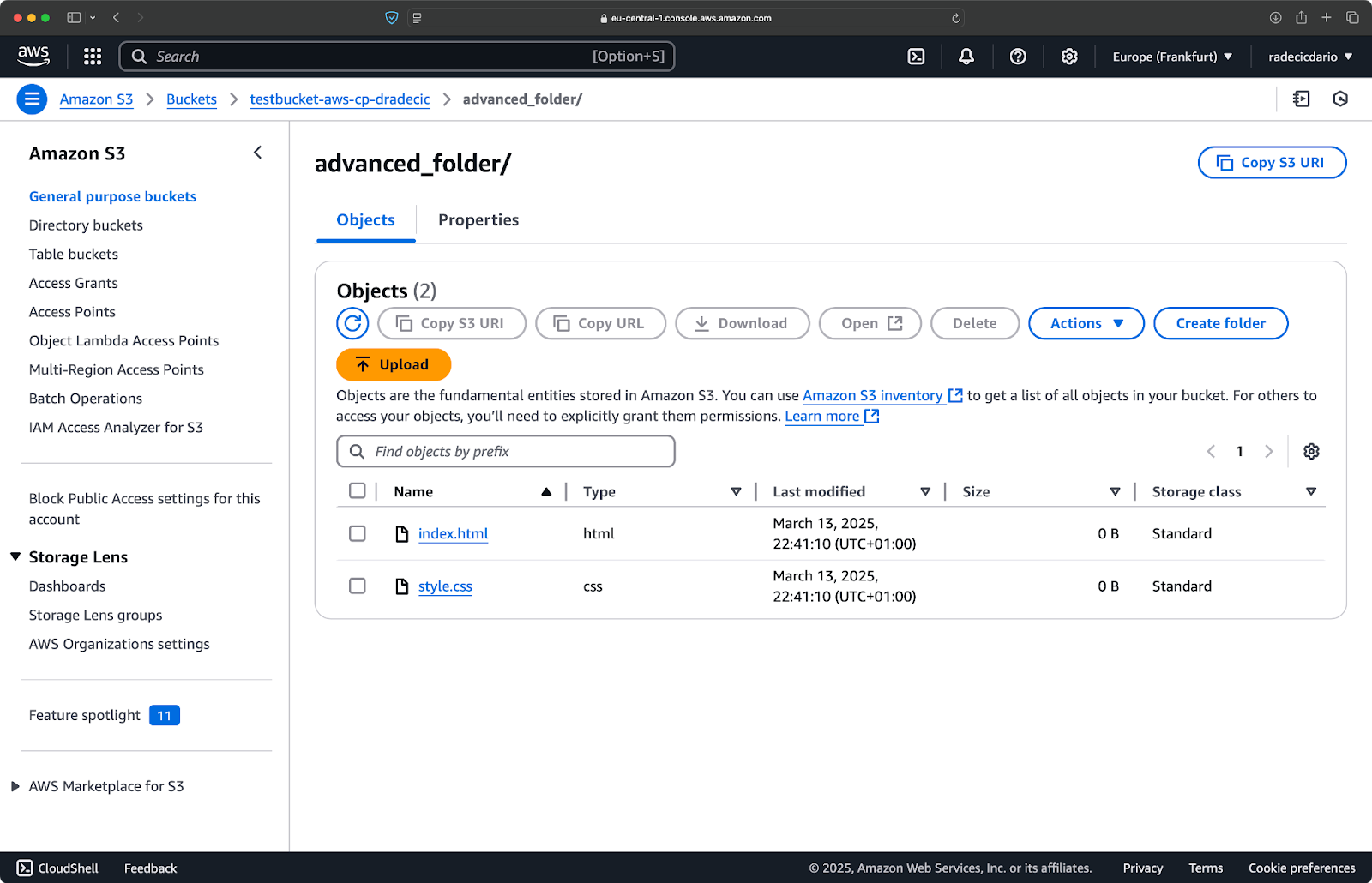
Изображение 16 – Результаты копирования папки (2)
Имейте в виду, что порядок флагов имеет значение – AWS CLI обрабатывает эти флаги последовательно, поэтому, если вы поставите --include перед --exclude, вы получите другие результаты:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --include "*.html" --include "*.css" --exclude "*"
На этот раз ничего не было скопировано в корзину:
Изображение 17 – Результаты копирования папки (3)
Указание класса хранения S3
Amazon S3 предлагает различные классы хранения, каждый из которых имеет разные затраты и характеристики извлечения. По умолчанию команда aws s3 cp загружает файлы в класс хранения Standard, но вы можете указать другой класс, используя флаг --storage-class:
aws s3 cp /Users/dradecic/Desktop/large-archive.zip s3://testbucket-aws-cp-dradecic/archives/ --storage-class GLACIER
Эта команда загружает large-archive.zip в класс хранения Glacier, который значительно дешевле, но имеет более высокие затраты на извлечение и более длительное время извлечения:
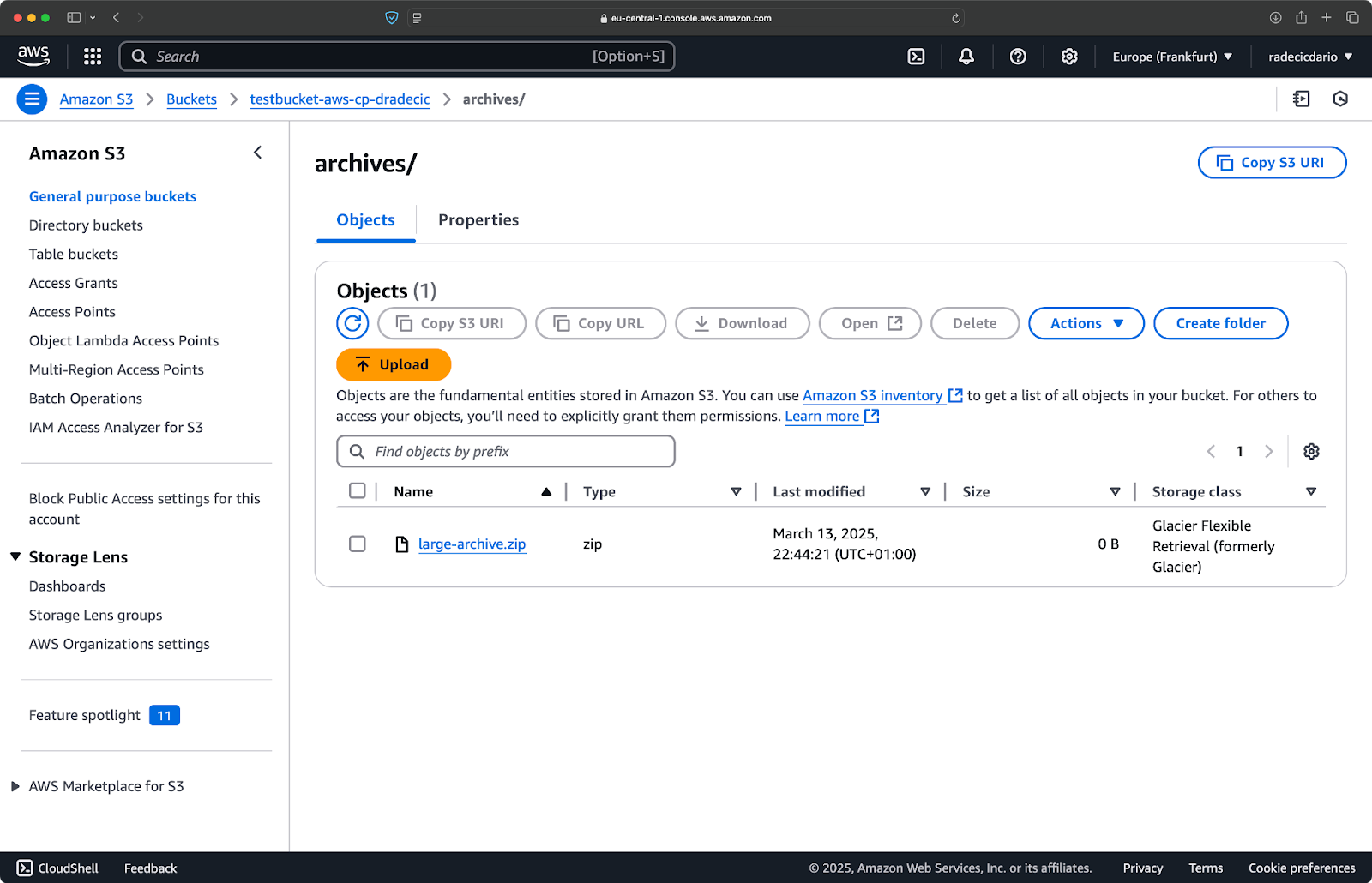
Изображение 18 – Копирование файлов в S3 с различными классами хранения
Доступные классы хранения включают:
STANDARD(по умолчанию): Общее назначение хранения с высокой долговечностью и доступностью.REDUCED_REDUNDANCY(больше не рекомендуется): Более низкая долговечность, вариант для экономии средств, сейчас устарел.STANDARD_IA(Редкий доступ): Хранение с низкой стоимостью для данных, к которым обращаются реже.ONEZONE_IA(Редкий доступ в одной зоне): Хранение с низкой стоимостью и редким доступом в одной зоне доступности AWS.INTELLIGENT_TIERING: Автоматически перемещает данные между уровнями хранения в зависимости от паттернов доступа.GLACIER: Дешевая архивная память для долгосрочного хранения, извлечение в течение минут до часов.DEEP_ARCHIVE: Самое дешевое архивное хранилище, извлечение в течение часов, идеально для долгосрочного резервного копирования.
Если вы делаете резервное копирование файлов, к которым вам не нужен немедленный доступ, использование GLACIER или DEEP_ARCHIVE может существенно сэкономить ваши затраты на хранение.
Синхронизация файлов с флагом –exact-timestamps
При обновлении файлов в S3, которые уже существуют, вам может понадобиться копировать только те файлы, которые изменились. Флаг --exact-timestamps помогает с этим, сравнивая временные метки между исходным и целевым местоположением.
Вот пример:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exact-timestamps
С этим флагом команда будет копировать файлы только в том случае, если их временные метки отличаются от файлов, уже находящихся в S3. Это может сократить время передачи и использование полосы пропускания, когда вы регулярно обновляете большой набор файлов.
Итак, зачем это полезно? Просто представьте себе сценарии развертывания, когда вы хотите обновить файлы приложения без лишней передачи неизмененных ресурсов.
Хотя --exact-timestamps полезен для выполнения синхронизации, если вам нужно более сложное решение, рассмотрите использование aws s3 sync вместо aws s3 cp. Команда sync была специально разработана для синхронизации каталогов и имеет дополнительные возможности для этой цели. Я подробно рассказал об этой команде в руководстве AWS S3 Sync tutorial.
С этими расширенными опциями у вас теперь есть более тонкий контроль над операциями с файлами в S3. Вы можете выбирать конкретные файлы, оптимизировать затраты на хранение и эффективно обновлять файлы. В следующем разделе вы узнаете, как автоматизировать эти операции с помощью сценариев и запланированных задач.
Автоматизация передачи файлов с помощью AWS S3 cp
До сих пор вы узнали, как вручную копировать файлы в и из S3 с помощью командной строки. Одним из самых больших преимуществ использования aws s3 cp является возможность легко автоматизировать эти передачи, что сэкономит вам кучу времени.
Давайте исследуем, как вы можете интегрировать команду aws s3 cp в сценарии и запланированные задания для автоматической передачи файлов без участия пользователя.
Использование AWS S3 cp в сценариях
Вот простой пример сценария bash, который создает резервную копию каталога в S3, добавляет временную метку к резервной копии и реализует обработку ошибок и ведение журнала в файл:
#!/bin/bash # Установить переменные SOURCE_DIR="/Users/dradecic/Desktop/advanced_folder" BUCKET="s3://testbucket-aws-cp-dradecic/backups" DATE=$(date +%Y-%m-%d-%H-%M) BACKUP_NAME="backup-$DATE" LOG_FILE="/Users/dradecic/logs/s3-backup-$DATE.log" # Обеспечить существование каталога журналов mkdir -p "$(dirname "$LOG_FILE")" # Создать резервную копию и зарегистрировать вывод echo "Starting backup of $SOURCE_DIR to $BUCKET/$BACKUP_NAME" | tee -a $LOG_FILE aws s3 cp $SOURCE_DIR $BUCKET/$BACKUP_NAME --recursive 2>&1 | tee -a $LOG_FILE # Проверить, была ли успешной резервная копия if [ $? -eq 0 ]; then echo "Backup completed successfully on $DATE" | tee -a $LOG_FILE else echo "Backup failed on $DATE" | tee -a $LOG_FILE fi
Сохраните это как backup.sh, сделайте его исполняемым с помощью chmod +x backup.sh, и у вас будет многоразовый сценарий резервного копирования!
Затем запустите его с помощью следующей команды:
./backup.sh
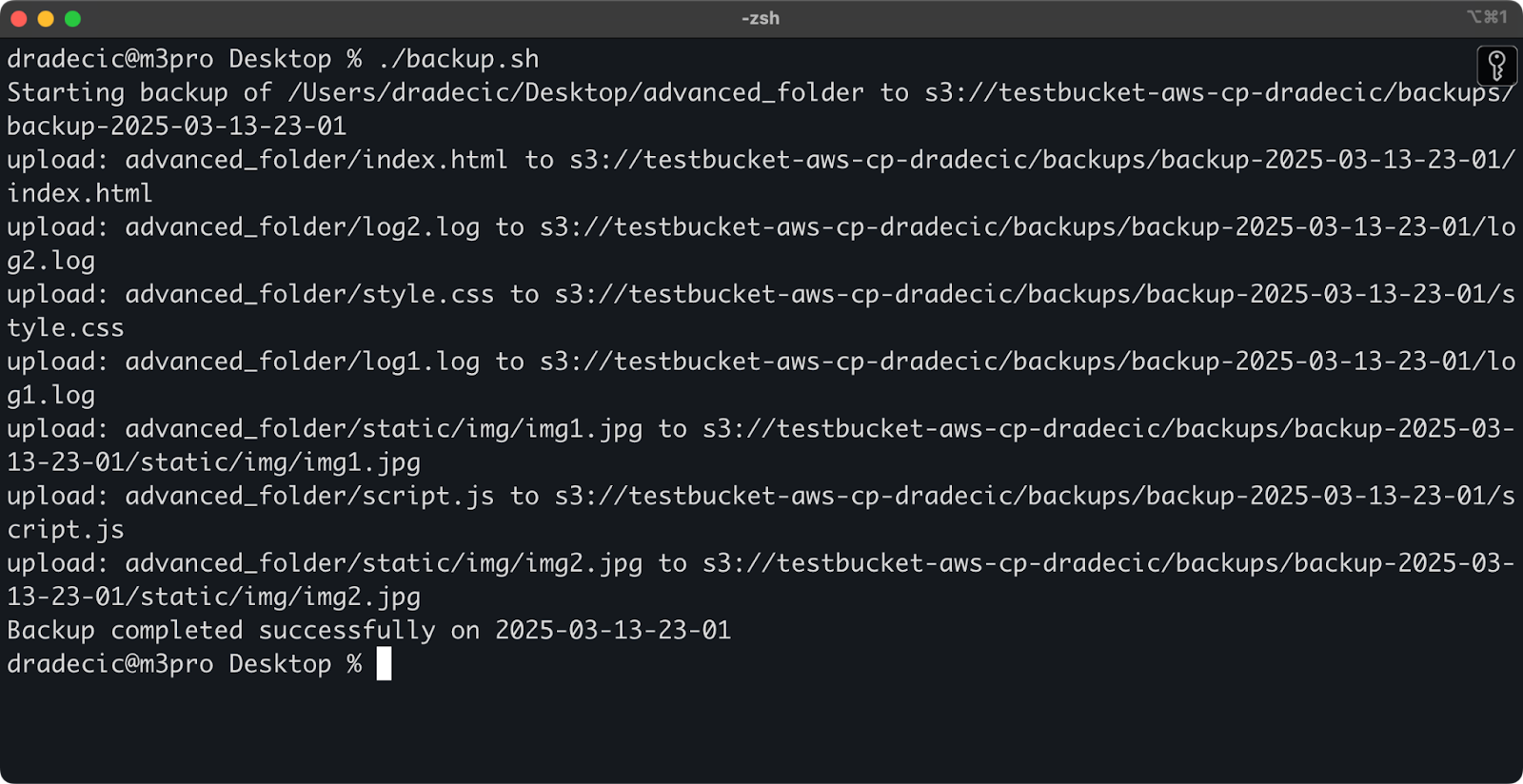
Изображение 19 – Сценарий запущен в терминале
Сразу после этого папка backups на ведре будет заполнена:
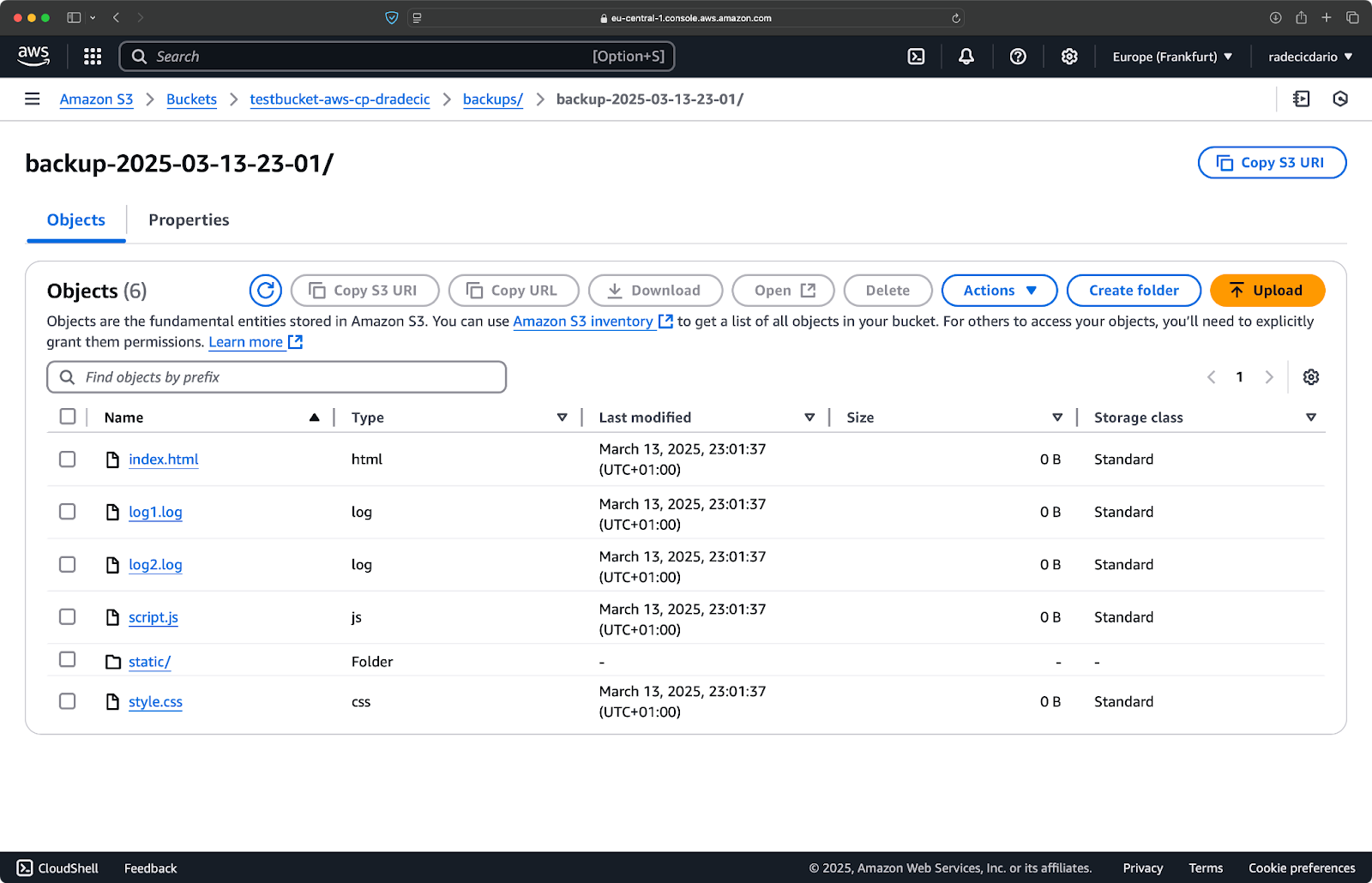
Изображение 20 – Резервное копирование сохранено в ведре S3
Давайте перейдем на следующий уровень, запустив сценарий по расписанию.
Планирование передачи файлов с помощью cron-заданий
Теперь, когда у вас есть сценарий, следующим шагом будет запланировать его автоматический запуск в определенное время.
Если вы используете Linux или macOS, вы можете использовать cron для планирования ваших резервных копий. Вот как настроить cron-задачу для запуска вашего скрипта резервного копирования каждый день в полночь:
1. Откройте ваш crontab для редактирования:
crontab -e
2. Добавьте следующую строку для запуска вашего скрипта ежедневно в полночь:
0 0 * * * /path/to/your/backup.sh
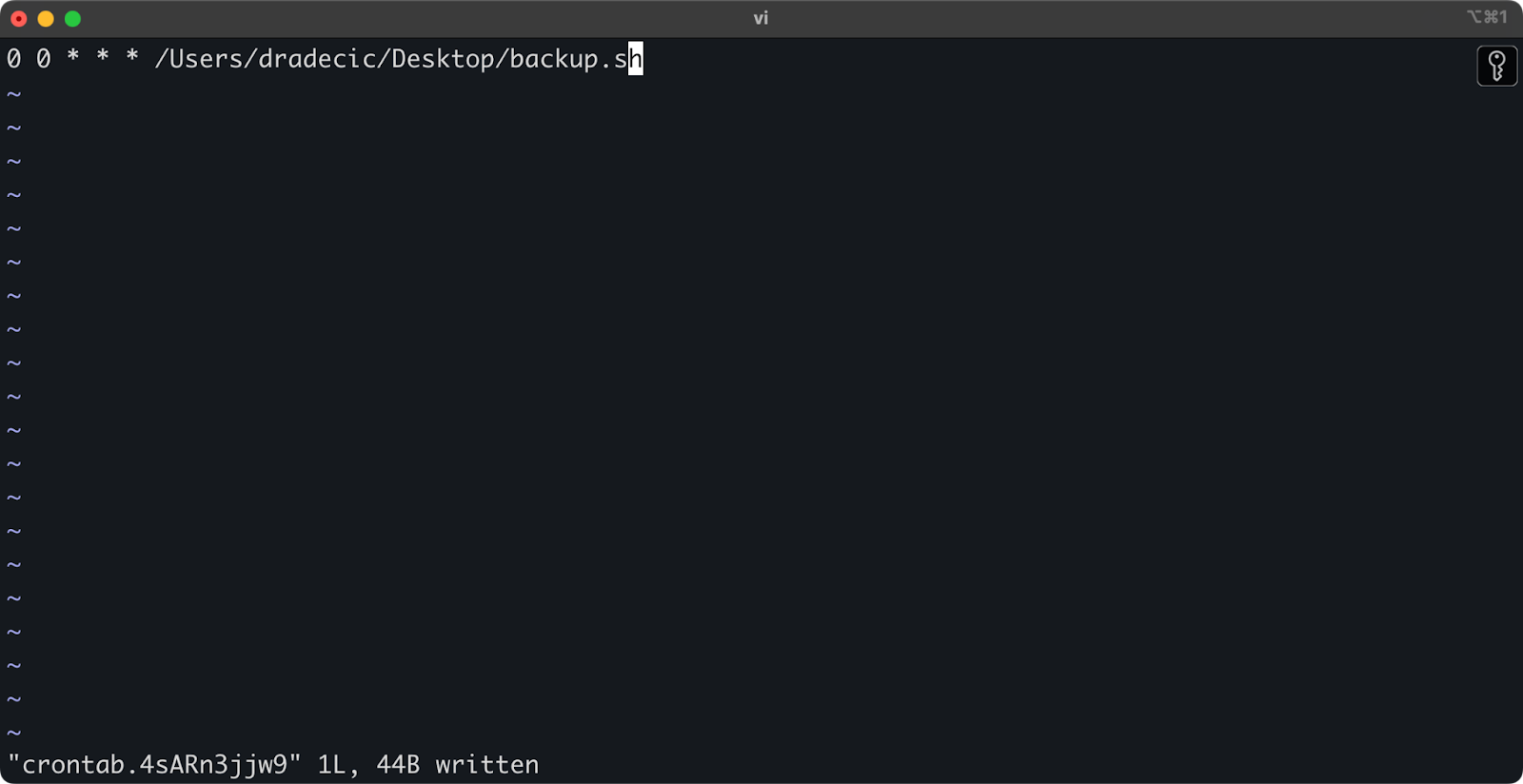
Изображение 21 – Cron job для запуска скрипта ежедневно
Формат для cron-задач минута час день-месяца месяц день-недели команда. Вот еще несколько примеров:
- Запуск каждый час:
0 * * * * /путь/к/вашему/backup.sh - Запуск каждый понедельник в 9 утра:
0 9 * * 1 /путь/к/вашему/backup.sh - Запуск первого числа каждого месяца:
0 0 1 * * /путь/к/вашему/backup.sh
И все, что нужно! Скрипт backup.sh теперь будет запускаться в заданном интервале.
Автоматизация передачи файлов в S3 – это правильный путь. Это особенно полезно для сценариев, таких как:
- Ежедневное резервное копирование важных данных
- Синхронизация изображений продуктов на сайт
- Перемещение файлов журналов в долгосрочное хранилище
- Развертывание обновленных файлов сайта
Техники автоматизации, подобные этим, помогут вам создать надежную систему, которая обрабатывает передачу файлов без ручного вмешательства. Вам просто нужно написать это один раз, а затем можете забыть об этом.
В следующем разделе я расскажу о некоторых bewst практиках, чтобы сделать ваши операции aws s3 cp более безопасными и эффективными.
Лучшие практики использования AWS S3 cp
Хотя команда aws s3 cp проста в использовании, могут возникнуть проблемы.
Следуя bew practices, вы избежите распространенных ошибок, оптимизируете производительность и обеспечите безопасность ваших данных. Давайте рассмотрим эти практики, чтобы сделать ваши операции по передаче файлов более эффективными.
Эффективное управление файлами
При работе с S3 логическое организовывание ваших файлов сэкономит вам время и головную боль в дальнейшем.
Во-первых, установите согласованное соглашение об именовании ведра и префикса. Например, вы можете разделять свои данные по окружению, приложению или дате:
s3://company-backups/production/database/2023-03-13/ s3://company-backups/staging/uploads/2023-03/
Этот тип организации упрощает:
- Поиск конкретных файлов, когда они вам нужны.
- Применение политик корзин и разрешений на правильном уровне.
- Настройка правил жизненного цикла для архивации или удаления старых данных.
Еще один совет: При передаче больших наборов файлов рассмотрите возможность сначала группировать небольшие файлы вместе (с использованием zip или tar) перед загрузкой. Это уменьшает количество вызовов API к S3, что может снизить затраты и ускорить передачу.
# Вместо копирования тысяч небольших файлов с журналами # сначала упакуйте их в tar, затем загрузите tar -czf example-logs-2025-03.tar.gz /var/log/application/ aws s3 cp example-logs-2025-03.tar.gz s3://testbucket-aws-cp-dradecic/logs/2025/03/
Обработка передачи больших объемов данных
При копировании больших файлов или множества файлов существуют несколько техник, которые делают процесс более надежным и эффективным.
Вы можете использовать флаг --quiet длясокращения вывода при запуске в скриптах:
aws s3 cp large-directory/ s3://testbucket-aws-cp-dradecic/backups/ --recursive --quiet
Это подавляет информацию о ходе выполнения для каждого файла, что делает журналы более управляемыми. Также это немного улучшает производительность.
Для очень больших файлов рассмотрите возможность использования многокомпонентных загрузок с флагом --multipart-threshold:
aws s3 cp huge-file.iso s3://testbucket-aws-cp-dradecic/backups/ --multipart-threshold 100MB
Указанная настройка сообщает AWS CLI, что файлы размером более 100 МБ следует разбивать на несколько частей для загрузки. Это имеет несколько преимуществ:
- Если соединение прерывается, нужно повторно загрузить только затронутую часть.
- Части могут быть загружены параллельно, что потенциально увеличивает пропускную способность.
- Вы можете приостановить и возобновить большие загрузки.
При передаче данных между регионами рассмотрите использование S3 Transfer Acceleration для более быстрых загрузок:
aws s3 cp large-file.zip s3://testbucket-aws-cp-dradecic/backups/ --endpoint-url https://s3-accelerate.amazonaws.com
Вышеупомянутый метод направляет вашу передачу через краевую сеть Amazon, что может значительно ускорить межрегиональные передачи.
Обеспечение безопасности
Безопасность всегда должна быть приоритетом при работе с вашими данными в облаке.
Во-первых, убедитесь, что ваши IAM разрешения соответствуют принципу наименьших привилегий.Предоставляйте только те разрешения, которые необходимы для каждой задачи..
Вот пример политики, которую вы можете назначить пользователю:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject" ], "Resource": "arn:aws:s3:::testbucket-aws-cp-dradecic/backups/*" } ] }
Эта политика позволяет копировать файлы только к и от префикса “backups” в “my-bucket”.
Дополнительный способ повышения безопасности – включение шифрования для конфиденциальных данных. Вы можете указать шифрование на стороне сервера при загрузке:
aws s3 cp confidential.docx s3://testbucket-aws-cp-dradecic/ --sse AES256
Или, для большей безопасности, используйте службу управления ключами AWS (KMS):
aws s3 cp secret-data.json s3://testbucket-aws-cp-dradecic/ --sse aws:kms --sse-kms-key-id myKMSKeyId
Однако для крайне чувствительных операций рассмотрите использование точек подключения VPC для S3. Это позволит сохранить ваш трафик внутри сети AWS и полностью избежать общественного интернета.
В следующем разделе вы узнаете, как устранить распространенные проблемы, с которыми вы можете столкнуться при работе с этой командой.
Устранение ошибок при копировании файлов в AWS S3
Одно можно сказать наверняка – время от времени у вас возникнут проблемы при работе с aws s3 cp. Но, понимая распространенные ошибки и их решения, вы сэкономите время и избежите разочарования, когда что-то пойдет не по плану.
В этом разделе я покажу вам наиболее часто встречающиеся проблемы и способы их устранения.
Распространенные ошибки и их устранение
Ошибка: “Отказано в доступе”
Это, вероятно, самая распространенная ошибка, с которой вы столкнетесь:
upload failed: ./myfile.txt to s3://testbucket-aws-cp-dradecic/myfile.txt An error occurred (AccessDenied) when calling the PutObject operation: Access Denied
Обычно это означает одно из трех вещей:
- Вашему IAM-пользователю не хватает прав для выполнения операции.
- Политика ведра ограничивает доступ.
- Ваши учетные данные AWS истекли.
Для устранения неполадок:
- Проверьте ваши IAM-права, чтобы убедиться, что у вас есть необходимые разрешения
s3:PutObject(для загрузок) илиs3:GetObject(для загрузок). - Проверьте, не ограничивают ли ваши действия политика ведра.
- Запустите
aws configure, чтобы обновить свои учетные данные, если они истекли.
Ошибка: “Нет такого файла или директории”
Эта ошибка возникает, когда локальный файл или директория, которые вы пытаетесь скопировать, не существуют:
upload failed: ./missing-file.txt to s3://testbucket-aws-cp-dradecic/missing-file.txt An error occurred (404) when calling the PutObject operation: Not Found
Решение простое – внимательно проверьте пути к вашим файлам. Пути чувствительны к регистру, поэтому имейте это в виду. Также убедитесь, что вы находитесь в правильной директории при использовании относительных путей.
Ошибка: “Указанный бакет не существует”
Если вы видите эту ошибку:
upload failed: ./myfile.txt to s3://testbucket-aws-cp-dradecic/myfile.txt An error occurred (NoSuchBucket) when calling the PutObject operation: The specified bucket does not exist
Проверьте на наличие:
- Опечаток в имени вашего бакета.
- Проверьте, используете ли вы правильный регион AWS.
- Существует ли в действительности данный ведро (оно могло быть удалено).
Вы можете перечислить все свои ведра с помощью aws s3 ls, чтобы подтвердить правильное имя.
Ошибка: “Время ожидания подключения истекло”
Проблемы с сетью могут вызывать превышение времени ожидания подключения:
upload failed: ./largefile.zip to s3://testbucket-aws-cp-dradecic/largefile.zip An error occurred (RequestTimeout) when calling the PutObject operation: Request timeout
Для устранения этой проблемы:
- Проверьте ваше интернет-соединение.
- Попробуйте использовать более маленькие файлы или включить многопоточную загрузку для больших файлов.
- Рассмотрите возможность использования ускорения передачи AWS для повышения производительности.
Обработка ошибок при загрузке
Ошибки гораздо чаще возникают при передаче больших файлов. В таком случае старайтесь обрабатывать сбои грациозно.
Например, вы можете использовать флаг --only-show-errors, чтобы упростить диагностику ошибок в скриптах:
aws s3 cp large-directory/ s3://testbucket-aws-cp-dradecic/ --recursive --only-show-errors
Это подавляет успешные сообщения о передаче, отображая только ошибки, что значительно облегчает устранение неполадок при передаче больших объемов данных.
Для обработки прерванных передач, команда --recursive автоматически пропускает файлы, которые уже существуют в пункте назначения с таким же размером. Однако, чтобы быть более тщательным, вы можете использовать встроенные повторы AWS CLI для проблем сети, установив эти переменные среды:
export AWS_RETRY_MODE=standard export AWS_MAX_ATTEMPTS=5 aws s3 cp large-file.zip s3://testbucket-aws-cp-dradecic/
Это указывает AWS CLI автоматически повторять неудачные операции до 5 раз.
Но для очень больших наборов данных рассмотрите использование aws s3 sync вместо cp, так как он предназначен для лучшей обработки прерываний:
aws s3 sync large-directory/ s3://testbucket-aws-cp-dradecic/large-directory/
Команда sync будет передавать только файлы, отличающиеся от тех, что уже есть в пункте назначения, что делает ее идеальной для возобновления прерванных крупных передач.
Если вы понимаете эти распространенные ошибки и внедряете правильную обработку ошибок в ваши скрипты, вы сделаете ваши операции копирования в S3 намного более надежными и надежными.
Подводя итоги AWS S3 cp
В заключение, команда aws s3 cp – это универсальный инструмент для копирования локальных файлов в S3 и наоборот.
Вы узнали все об этом в этой статье. Вы начали с фундаментальных вещей и конфигурации среды, и закончили написанием запланированных и автоматизированных скриптов для копирования файлов. Вы также узнали, как справляться с некоторыми распространенными ошибками и сложностями при перемещении файлов, особенно больших.
Итак, если вы разработчик, профессионал в области данных или системный администратор, я думаю, что вы найдете эту команду полезной. Лучший способ освоить ее – это использовать ее регулярно. Убедитесь, что вы понимаете основы, а затем потратите некоторое время на автоматизацию утомительных аспектов вашей работы.
Чтобы узнать больше об AWS, следуйте этим курсам от DataCamp:
Вы даже можете использовать DataCamp для подготовки к экзаменам на сертификаты AWS – Практикующий в области облачных технологий AWS (CLF-C02).