













Configurazione di AWS CLI e AWS S3
Prima di immergerti nel comando aws s3 cp, devi avere AWS CLI installato e configurato correttamente sul tuo sistema. Non preoccuparti se non hai mai lavorato con AWS prima: il processo di configurazione è semplice e dovrebbe richiedere meno di 10 minuti.
Dividirò questo in tre fasi semplici: installare lo strumento AWS CLI, configurare le tue credenziali e creare il tuo primo bucket S3 per lo storage.
Installazione di AWS CLI
Il processo di installazione varia leggermente in base al sistema operativo che stai utilizzando.
Per i sistemi Windows:
- Passa alla pagina ufficiale della documentazione di AWS CLI
- Scarica il programma di installazione per Windows a 64 bit
- Esegui il file scaricato e segui la procedura di installazione
Per i sistemi Linux:
Esegui i seguenti tre comandi dal Terminale:
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" unzip awscliv2.zip sudo ./aws/install
Per i sistemi macOS:
Assumendo che tu abbia Homebrew installato, esegui questa riga dal Terminale:
brew install awscli
Se non hai Homebrew, utilizza invece questi due comandi:
curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg" sudo installer -pkg AWSCLIV2.pkg -target /
Per confermare un’installazione riuscita, esegui aws --version nel tuo terminale. Dovresti vedere qualcosa del genere:
Immagine 1 – Versione AWS CLI
Configurazione di AWS CLI
Con il CLI installato, è ora il momento di configurare le tue credenziali AWS per l’autenticazione.
Prima, accedi al tuo account AWS e vai al cruscotto del servizio IAM. Crea un nuovo utente con accesso programmato e collega la policy di autorizzazioni S3 appropriata:
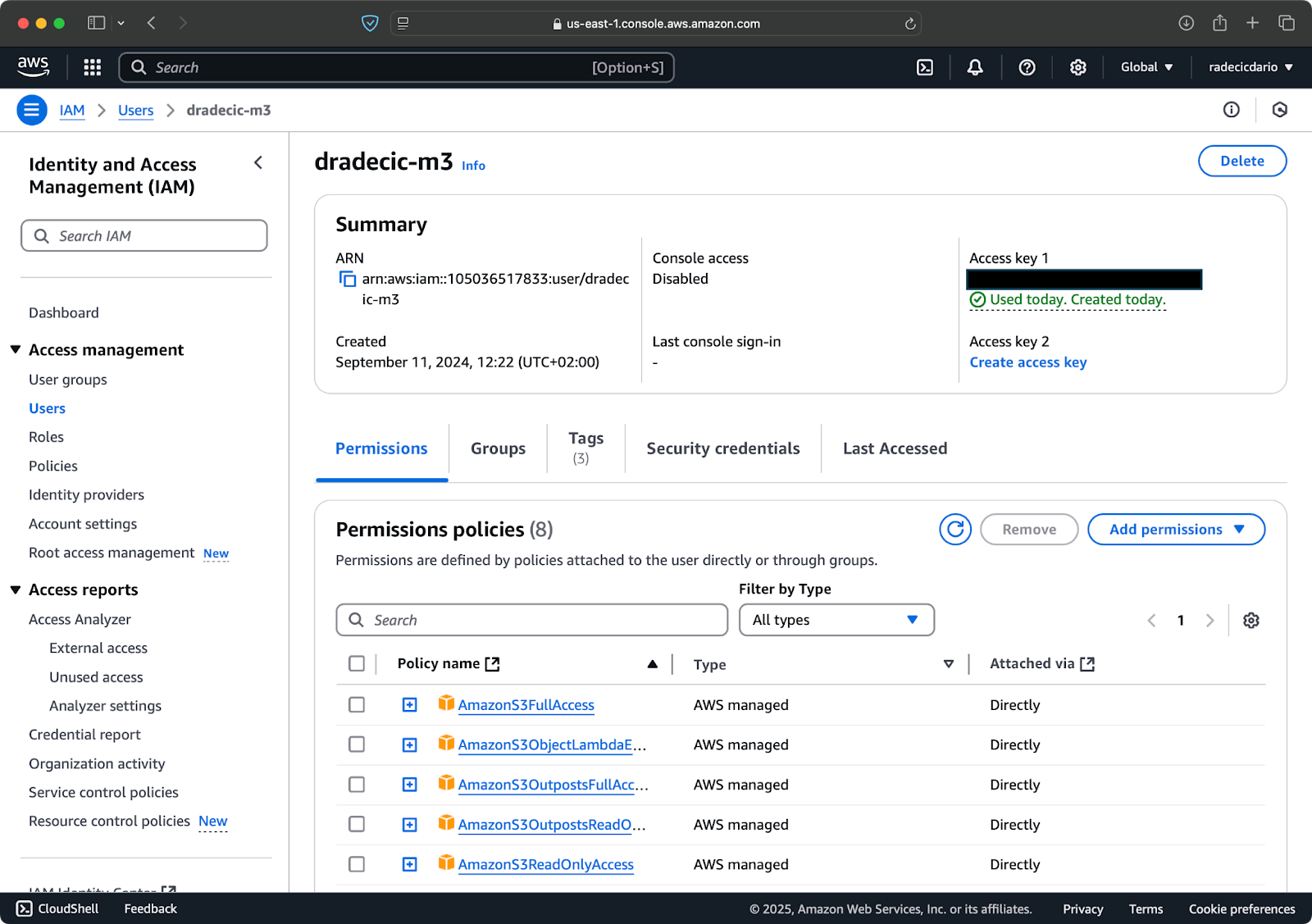
Immagine 2 – Utente IAM AWS
Successivamente, visita la scheda “Credenziali di sicurezza” e genera una nuova coppia di chiavi di accesso. Assicurati di salvare sia l’ID chiave di accesso che la chiave di accesso segreta in un luogo sicuro – Amazon non ti mostrerà di nuovo la chiave segreta dopo questa schermata:
Immagine 3 – Credenziali utente IAM AWS
Ora apri il tuo terminale ed esegui il comando aws configure. Ti verranno richieste quattro informazioni: il tuo Access key ID, Secret access key, la regione predefinita (sto usando eu-central-1) e il formato di output preferito (tipicamente json):
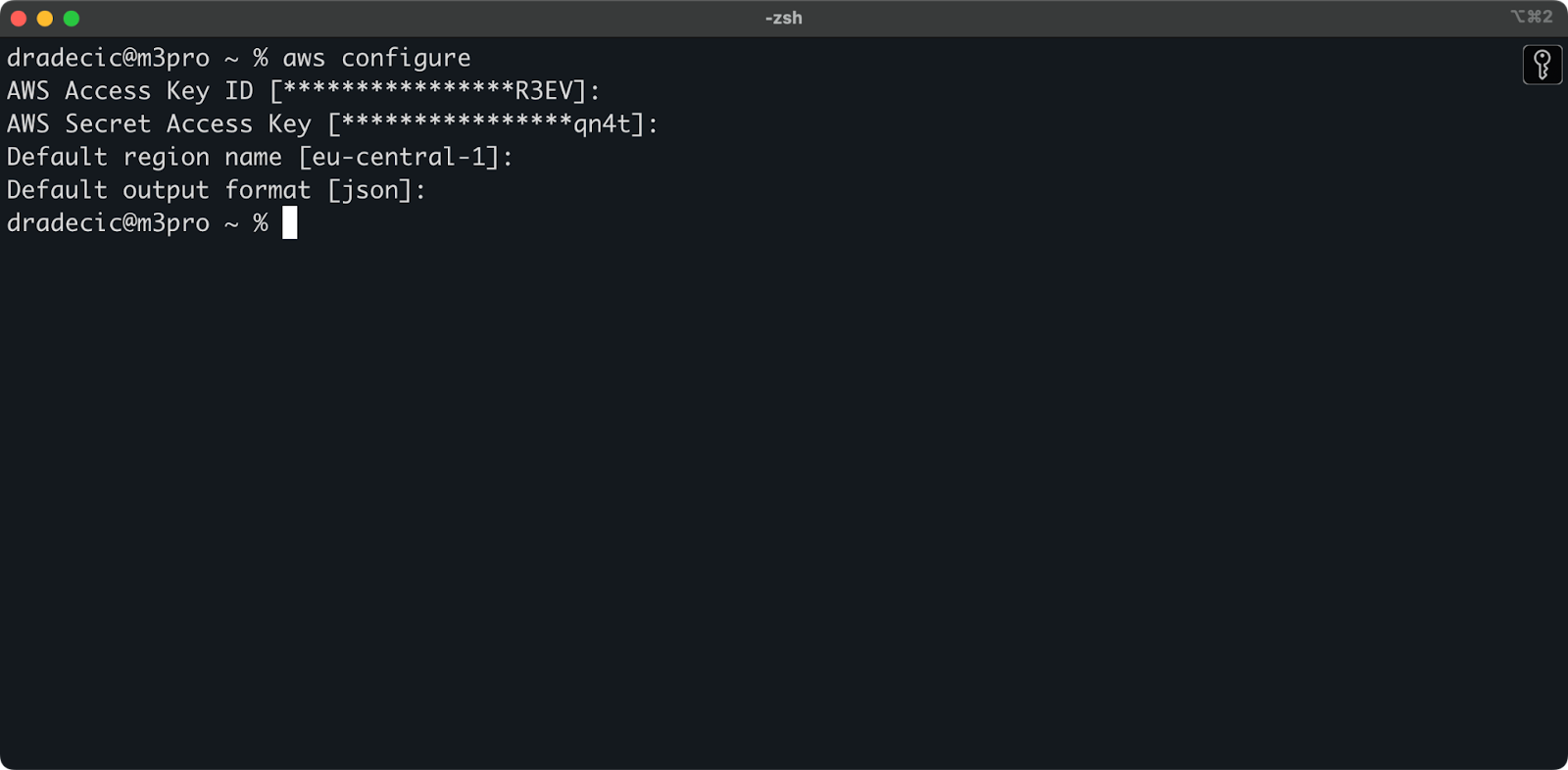
Immagine 4 – Configurazione AWS CLI
Per assicurarti che tutto sia connesso correttamente, verifica la tua identità con il seguente comando:
aws sts get-caller-identity
Se configurato correttamente, vedrai i dettagli del tuo account:
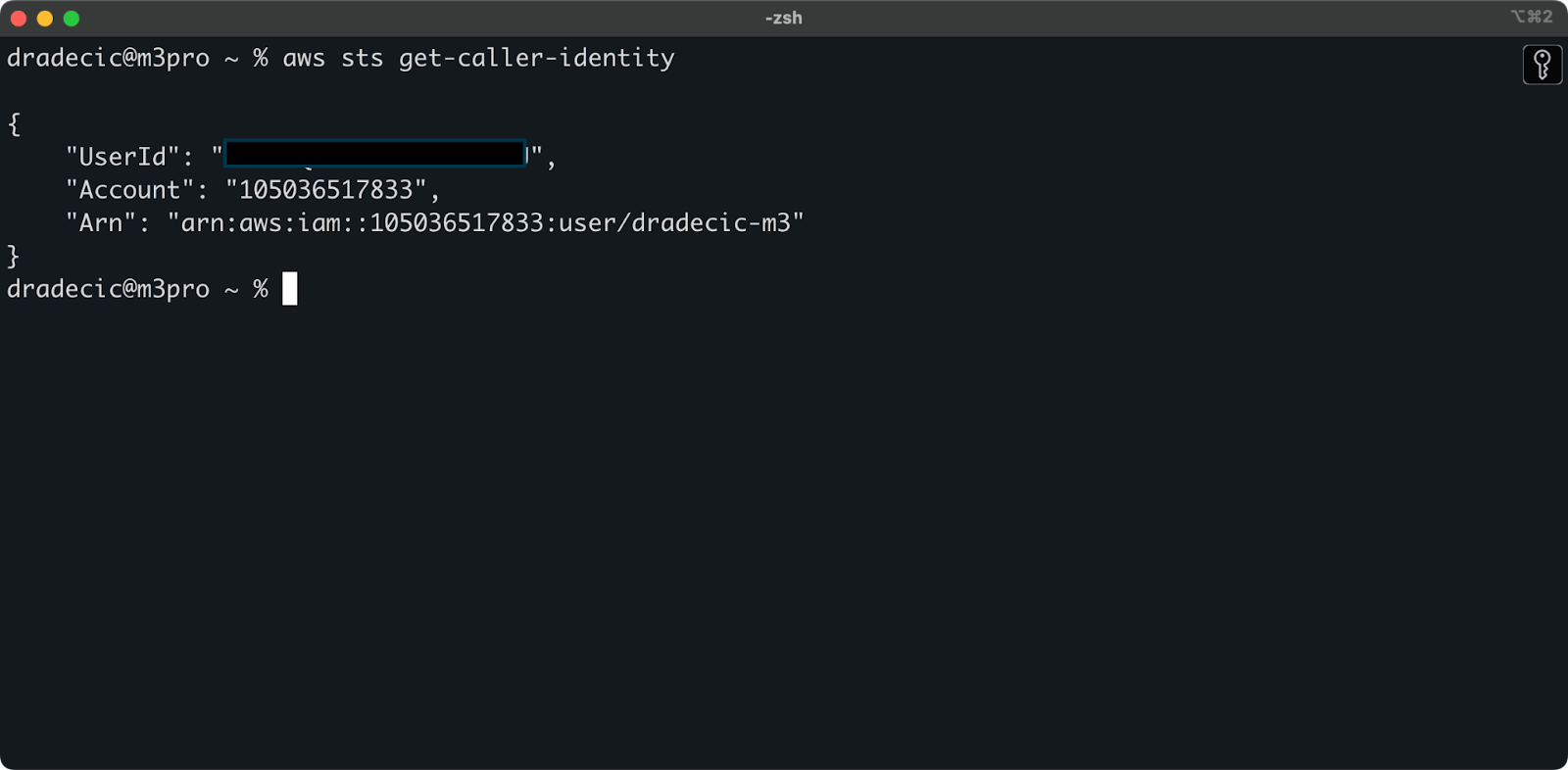
Immagine 5 – Comando di test connessione AWS CLI
Creazione di un bucket S3
Infine, devi creare un bucket S3 per memorizzare i file che copierai.
Vai alla sezione del servizio S3 nel tuo AWS Console e clicca su “Crea bucket”. Ricorda che i nomi dei bucket devono essere unici a livello globale in tutta AWS. Scegli un nome distintivo, lascia le impostazioni predefinite per ora e clicca su “Crea”:
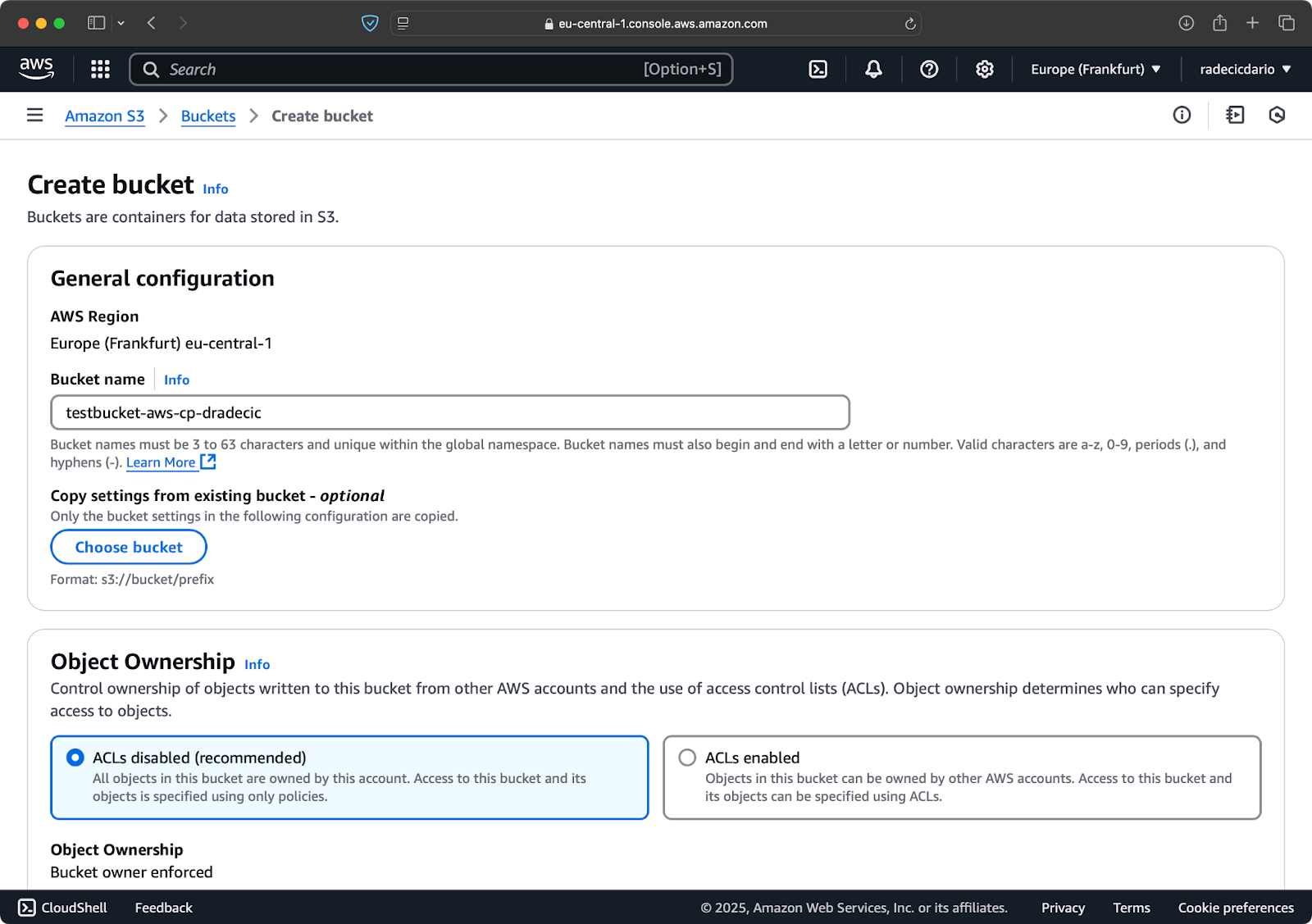
Immagine 6 – Creazione del bucket AWS
Una volta creato, il tuo nuovo bucket apparirà nella console. Puoi anche confermarne l’esistenza tramite linea di comando:
aws s3 ls
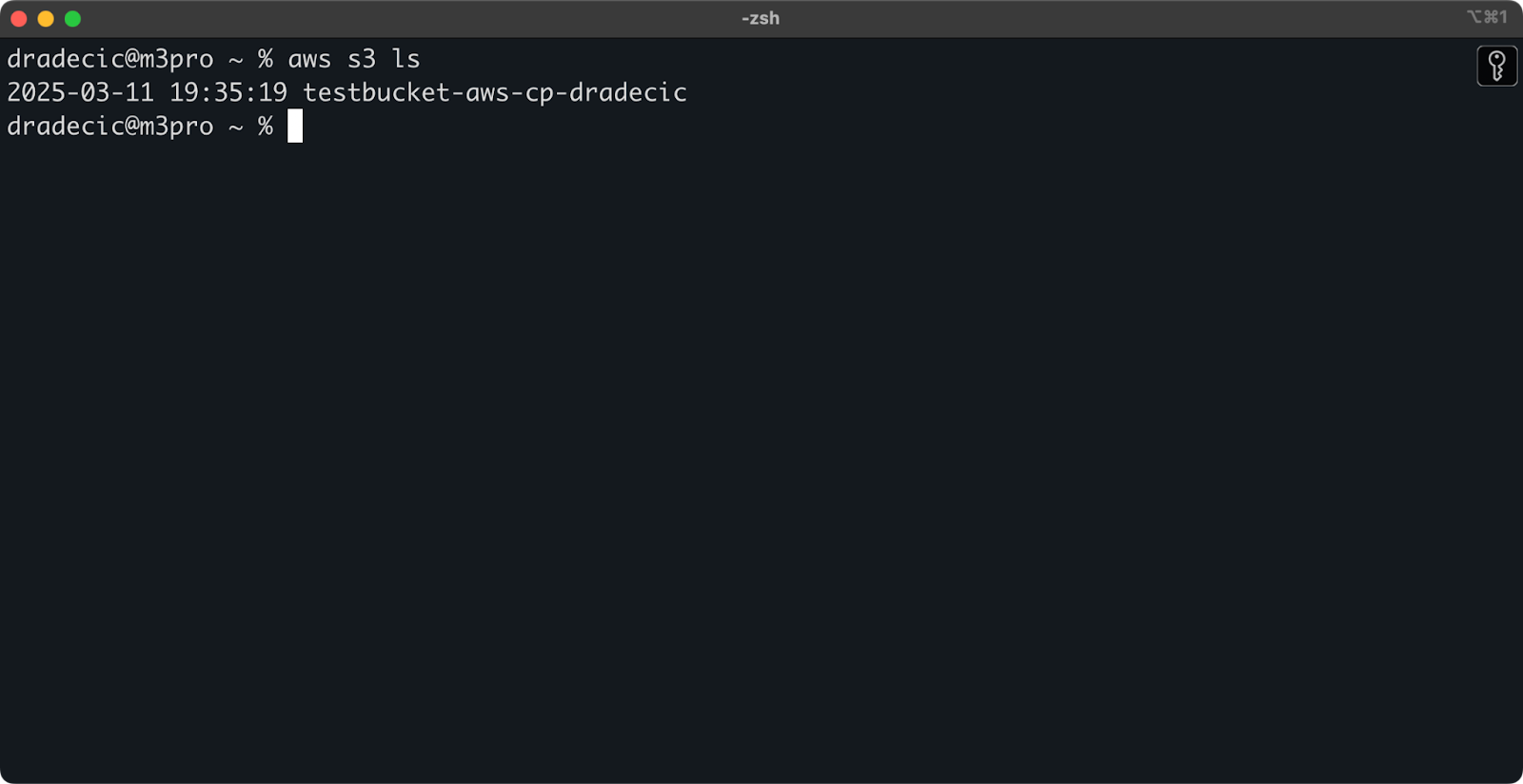
Immagine 7 – Tutti i bucket S3 disponibili
Tutti i bucket S3 sono configurati come privati per impostazione predefinita, quindi tieni presente questo. Se intendi utilizzare questo bucket per file accessibili pubblicamente, dovrai modificare le politiche del bucket di conseguenza.
Ora sei completamente attrezzato per iniziare a utilizzare il comando aws s3 cp per trasferire file. Iniziamo con le basi.
Sintassi del comando AWS S3 cp di base
Ora che hai configurato tutto, immergiamoci nell’uso di base del comando aws s3 cp. Come al solito con AWS, la bellezza sta nella semplicità, anche se il comando può gestire diversi scenari di trasferimento file.
Nella sua forma più basilare, il comando aws s3 cp segue questa sintassi:
aws s3 cp <source> <destination> [options]
Dove <sorgente> e <destinazione> possono essere percorsi di file locali o URI S3 (che iniziano con s3://). Esploriamo i tre casi d’uso più comuni.
Copiare un file da locale a S3
Per copiare un file dal sistema locale a un bucket S3, il sorgente sarà un percorso locale e la destinazione sarà un URI S3:
aws s3 cp /Users/dradecic/Desktop/test_file.txt s3://testbucket-aws-cp-dradecic/test_file.txt
Questo comando carica il file test_file.txt dalla directory fornita nel bucket S3 specificato. Se l’operazione ha successo, vedrai un output sulla console come questo:
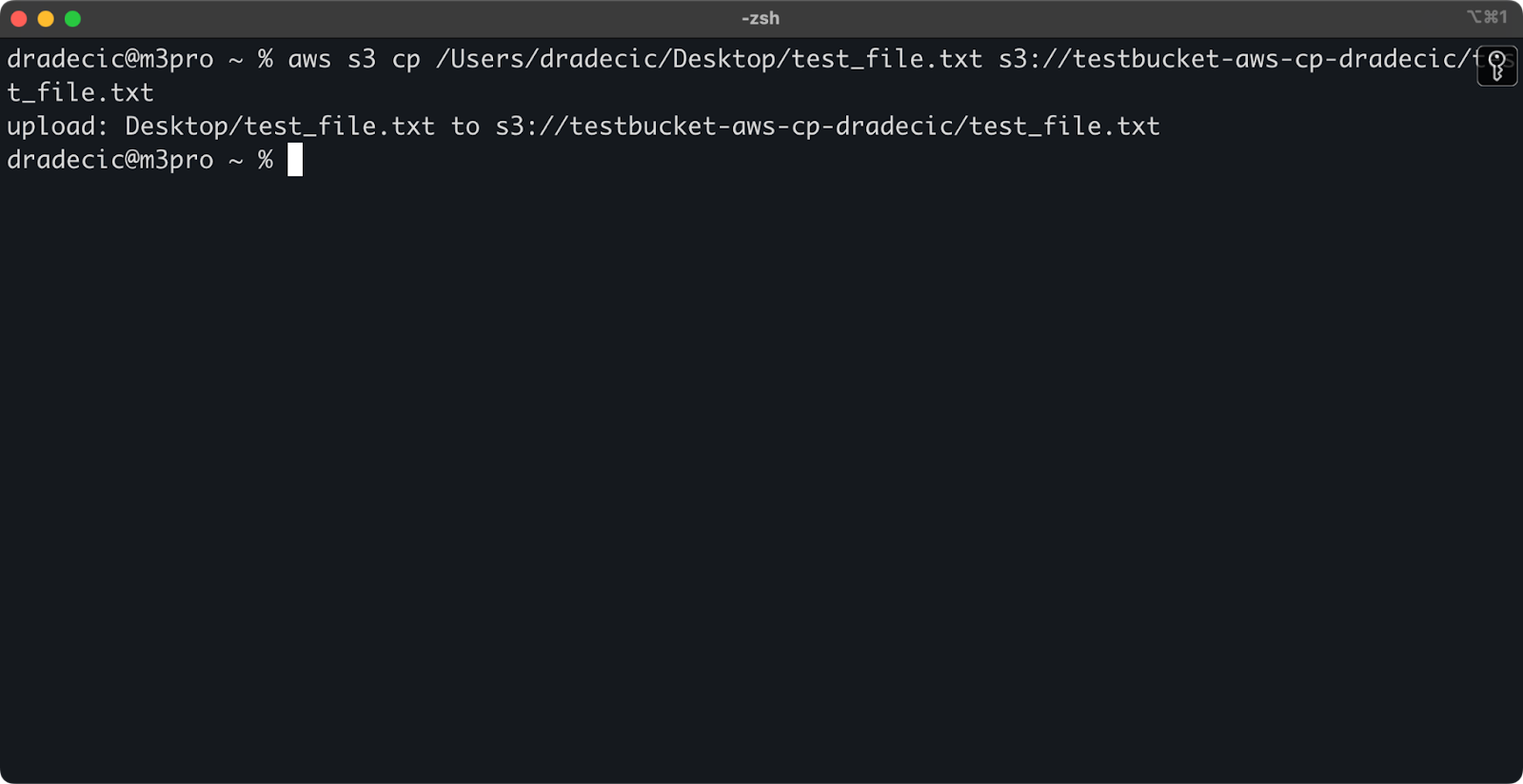
Immagine 8 – Output sulla console dopo aver copiato il file locale
E, sulla console di gestione AWS, vedrai il file caricato:
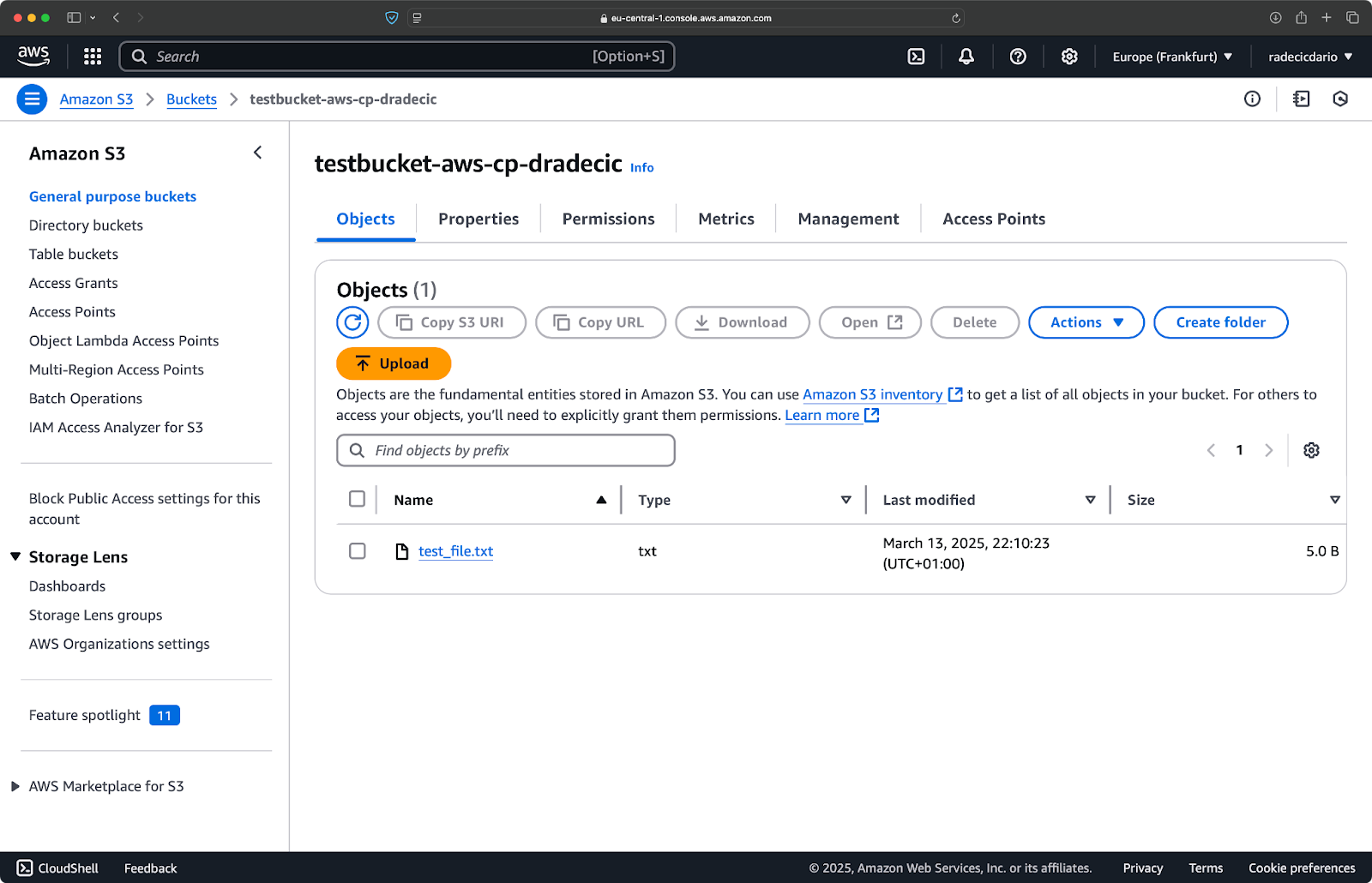
Immagine 9 – Contenuti del bucket S3
Allo stesso modo, se vuoi copiare una cartella locale nel tuo bucket S3 e metterla, diciamo, in un’altra cartella nidificata, esegui un comando simile a questo:
aws s3 cp /Users/dradecic/Desktop/test_folder s3://testbucket-aws-cp-dradecic/my-desired-folder/test_folder/ --recursive
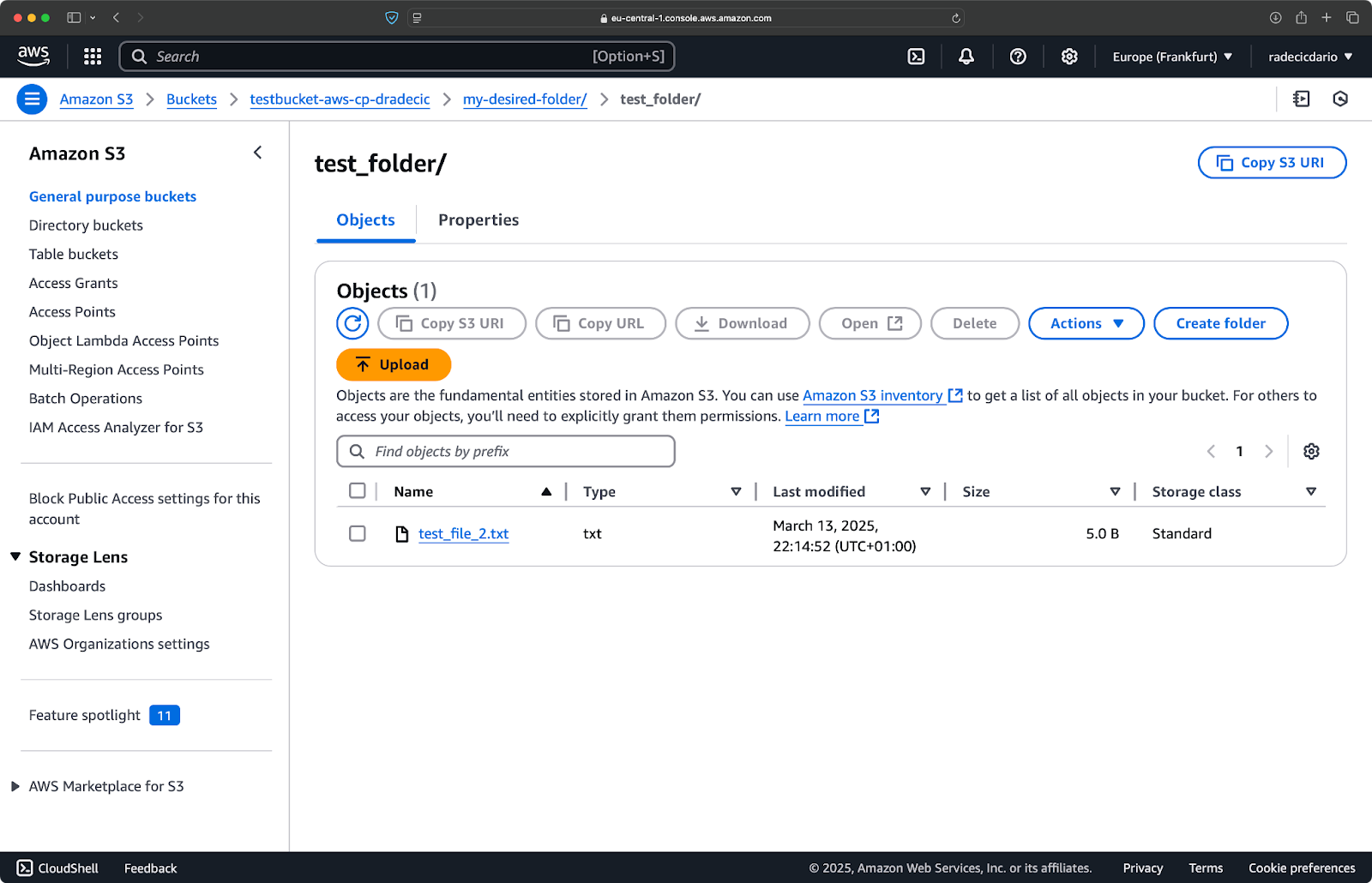
Immagine 10 – Contenuti del bucket S3 dopo aver caricato una cartella
Il flag --recursive si assicurerà che tutti i file e le sottocartelle all’interno della cartella vengano copiati.
Tieni presente – S3 in realtà non ha cartelle – la struttura del percorso fa parte della chiave dell’oggetto, ma funziona concettualmente come cartelle.
Copiare un file da S3 a locale
Per copiare un file da S3 al tuo sistema locale, basta invertire l’ordine – la fonte diventa l’URI di S3 e la destinazione è il percorso locale:
aws s3 cp s3://testbucket-aws-cp-dradecic/test_file.txt /Users/dradecic/Documents/s3-data/downloaded_test_file.txt
Questo comando scarica test_file.txt dal tuo bucket S3 e lo salva come downloaded_test_file.txt nella directory fornita. Lo vedrai immediatamente sul tuo sistema locale:
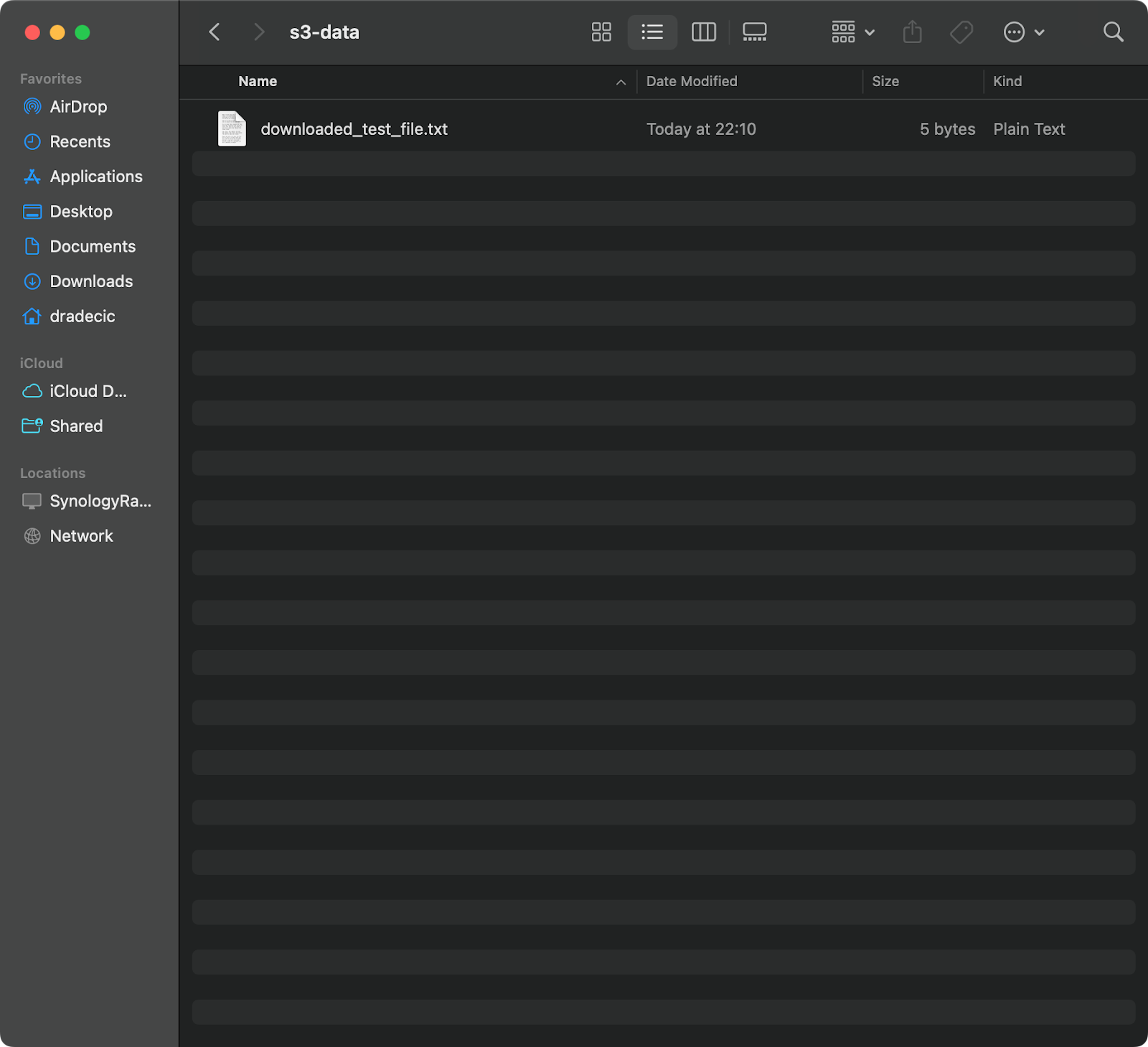
Immagine 11 – Download di un singolo file da S3
Se ometti il nome del file di destinazione, il comando utilizzerà il nome del file originale:
aws s3 cp s3://testbucket-aws-cp-dradecic/test_file.txt .
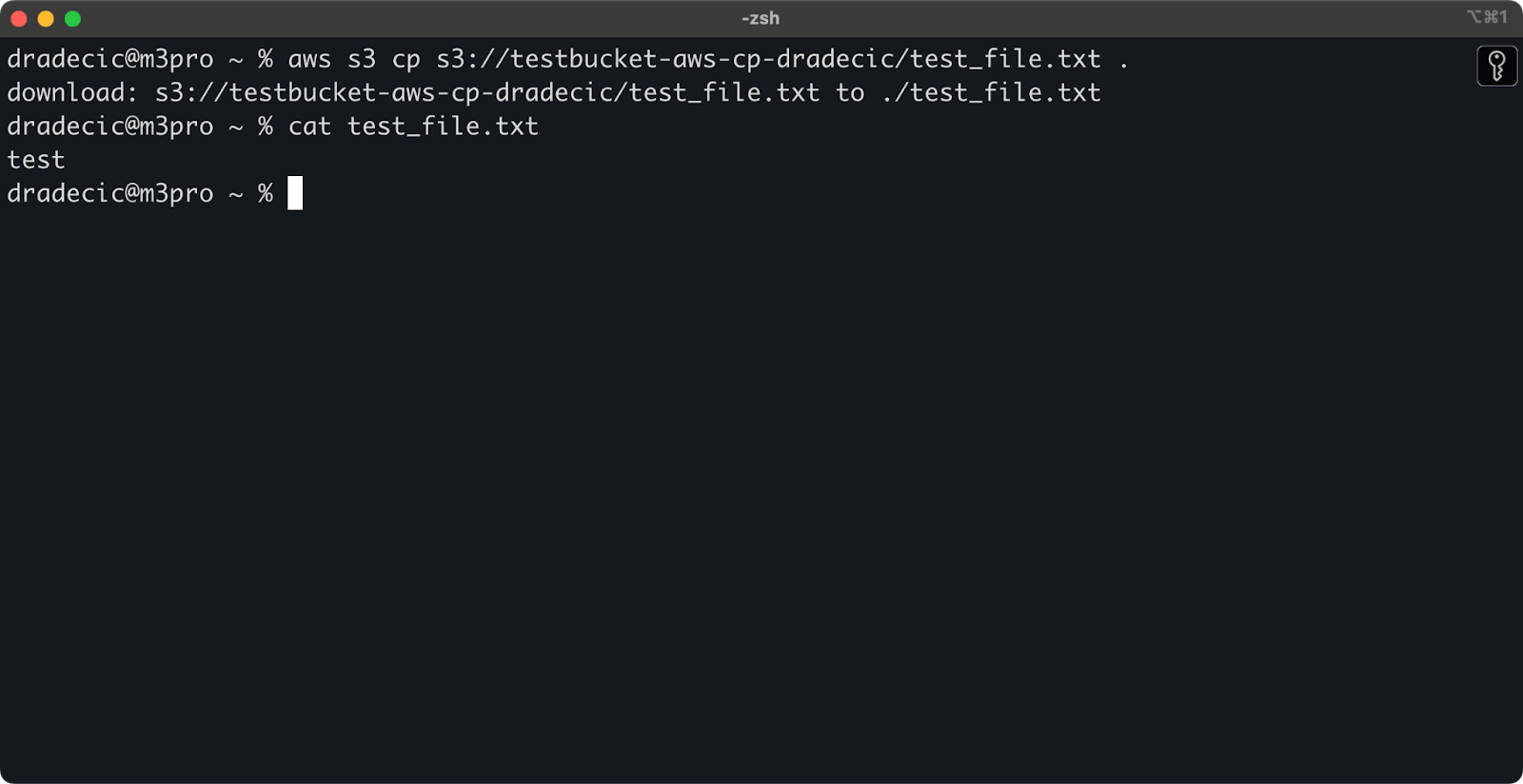
Immagine 12 – Contenuto del file scaricato
Il punto (.) rappresenta la tua directory corrente, quindi questo scaricherà test_file.txt nella tua posizione attuale.
E infine, per scaricare un’intera cartella, puoi utilizzare un comando simile a questo:
aws s3 cp s3://testbucket-aws-cp-dradecic/my-desired-folder/test_folder /Users/dradecic/Documents/test_folder --recursive
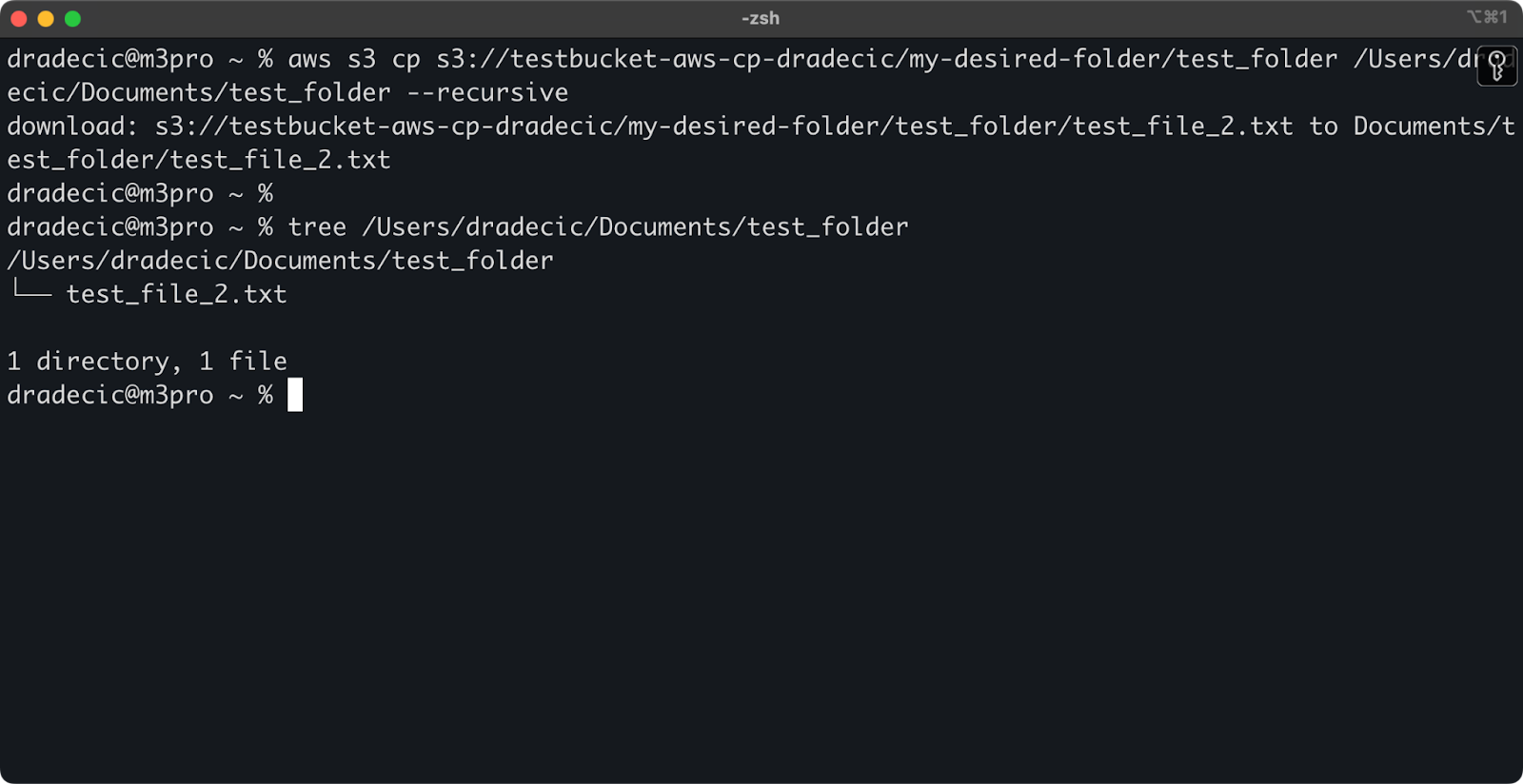
Immagine 13 – Contenuto della cartella scaricata
Tieni presente che il flag --recursive è essenziale quando si lavora con più file – senza di esso, il comando fallirà se la sorgente è una cartella.
Con questi comandi di base, puoi già completare la maggior parte dei compiti di trasferimento file di cui avrai bisogno. Ma nella prossima sezione, imparerai opzioni più avanzate che ti daranno un controllo migliore sul processo di copia.
Opzioni e funzionalità avanzate di AWS S3 cp
AWS offre un paio di opzioni avanzate che ti consentono di massimizzare le operazioni di copia file. In questa sezione, ti mostrerò alcuni dei flag e dei parametri più utili che ti aiuteranno con i tuoi compiti quotidiani.
Utilizzo dei flag –exclude e –include
A volte si desidera copiare solo determinati file che corrispondono a modelli specifici. I flag --exclude e --include ti permettono di filtrare i file in base ai modelli e ti offrono un controllo preciso su cosa viene copiato.
Solo per fare un esempio, questa è la struttura delle directory con cui sto lavorando:
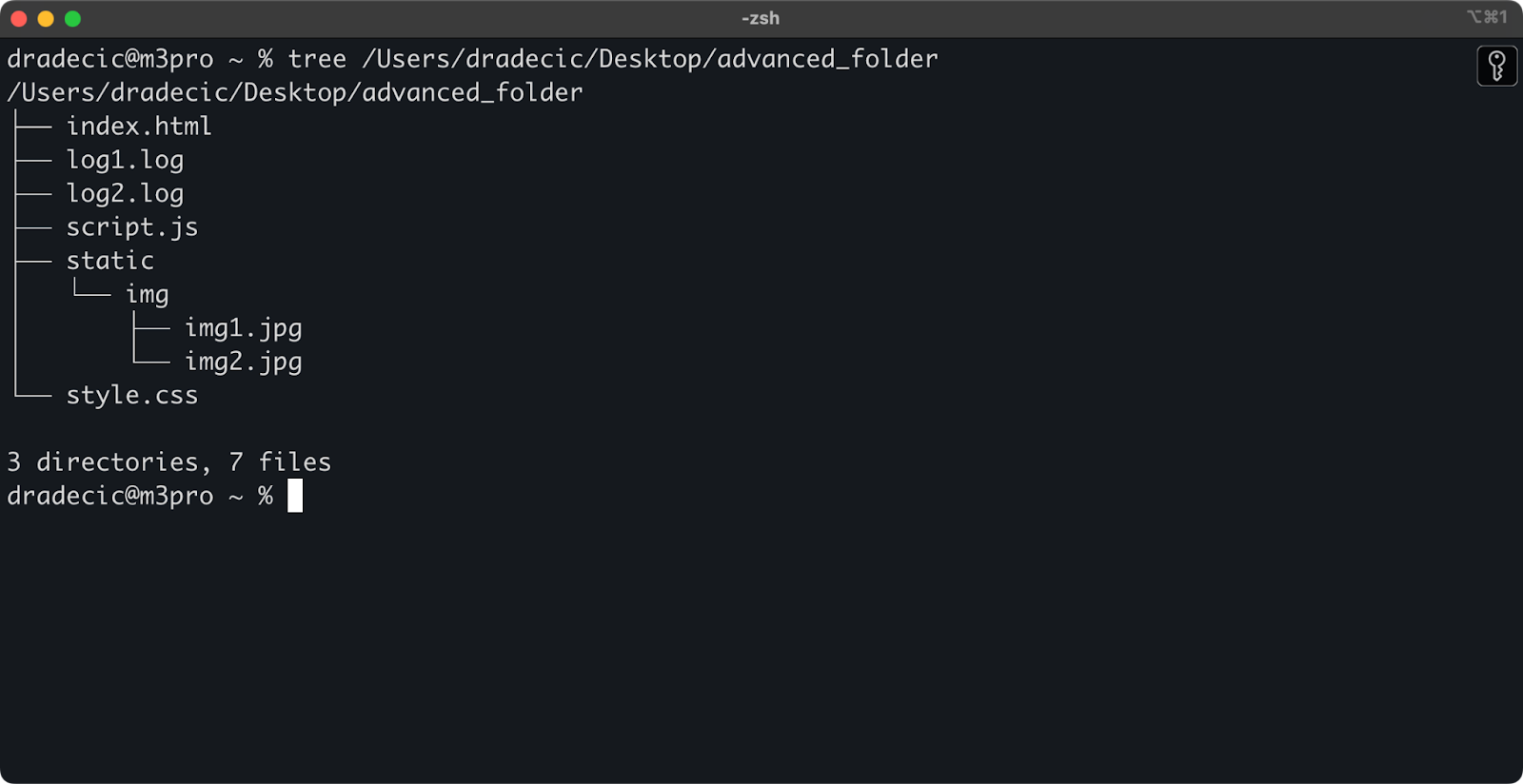
Immagine 14 – Struttura della directory
Adesso, diciamo che vuoi copiare tutti i file dalla directory tranne i file .log:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exclude "*.log"
Questo comando copierà tutti i file dalla directory advanced_folder su S3, escludendo qualsiasi file con estensione .log:
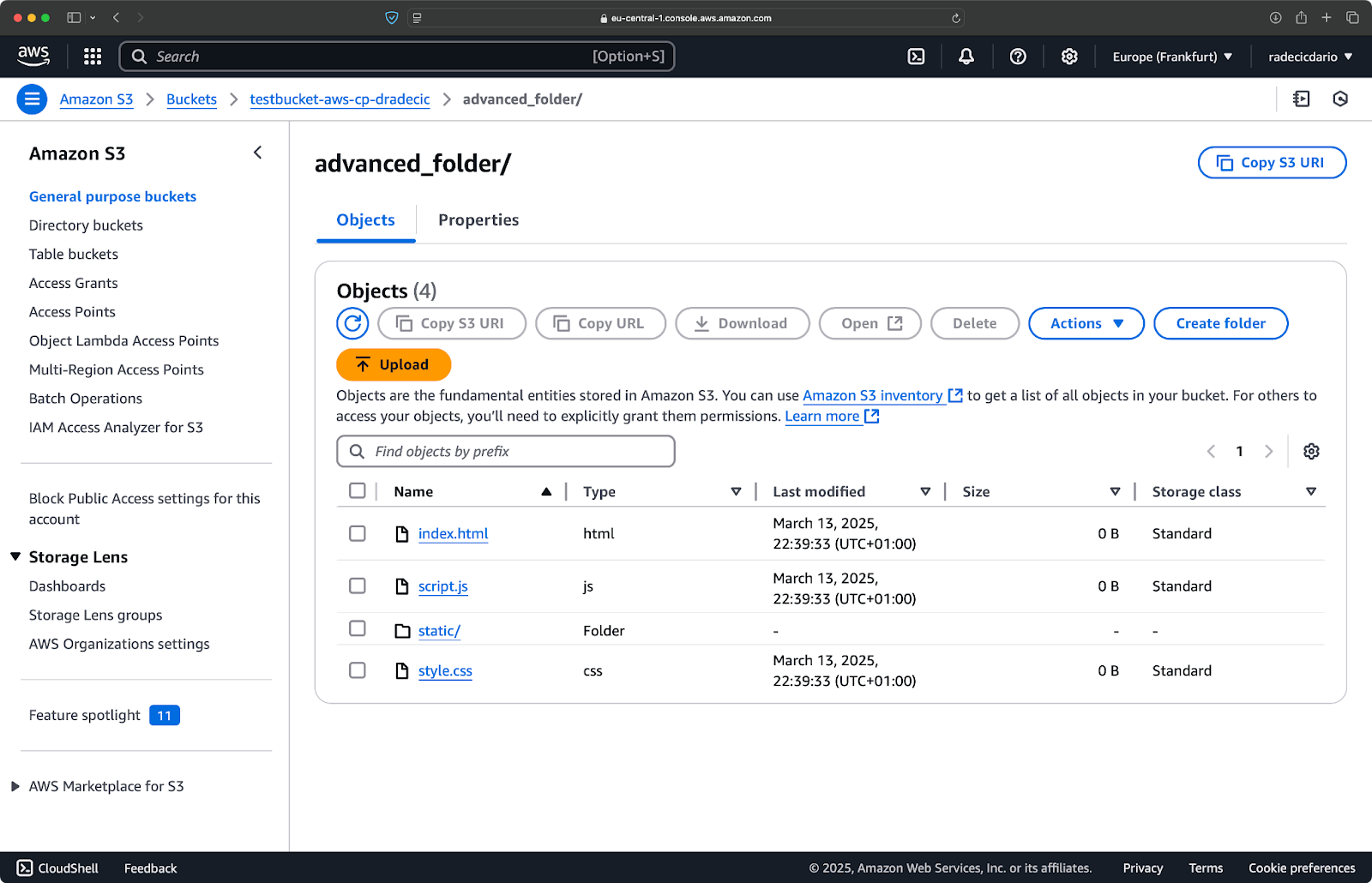
Immagine 15 – Risultati della copia della cartella
Puoi anche combinare più modelli. Diciamo che vuoi copiare solo i file HTML e CSS dalla cartella del progetto:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exclude "*" --include "*.html" --include "*.css"
Questo comando esclude prima tutto (--exclude "*"), quindi include solo i file con estensioni .html e .css. Il risultato sarà simile a questo:
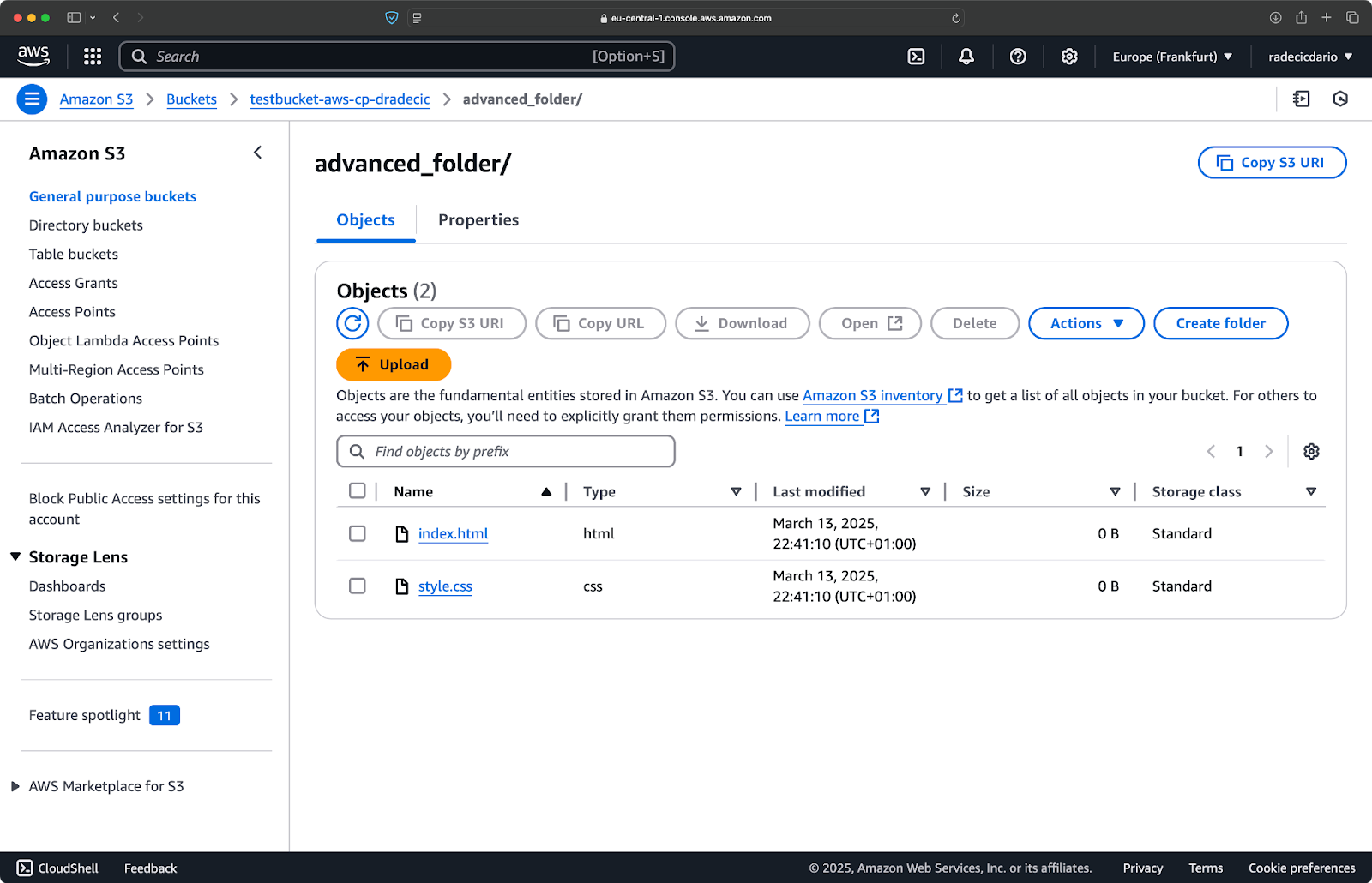
Immagine 16 – Risultati della copia della cartella (2)
Tieni presente che l’ordine dei flag è importante: AWS CLI elabora questi flag in modo sequenziale, quindi se metti --include prima di --exclude, otterrai risultati diversi:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --include "*.html" --include "*.css" --exclude "*"
Questa volta, nulla è stato copiato nel bucket:
Immagine 17 – Risultati della copia della cartella (3)
Specificare la classe di archiviazione S3
Amazon S3 offre differenti classi di archiviazione, ognuna con costi e caratteristiche di recupero diversi. Per impostazione predefinita, aws s3 cp carica i file nella classe di archiviazione Standard, ma è possibile specificare una classe diversa utilizzando il flag --storage-class:
aws s3 cp /Users/dradecic/Desktop/large-archive.zip s3://testbucket-aws-cp-dradecic/archives/ --storage-class GLACIER
Questo comando carica large-archive.zip nella classe di archiviazione Glacier, che è significativamente più economica ma ha costi di recupero più alti e tempi di recupero più lunghi:
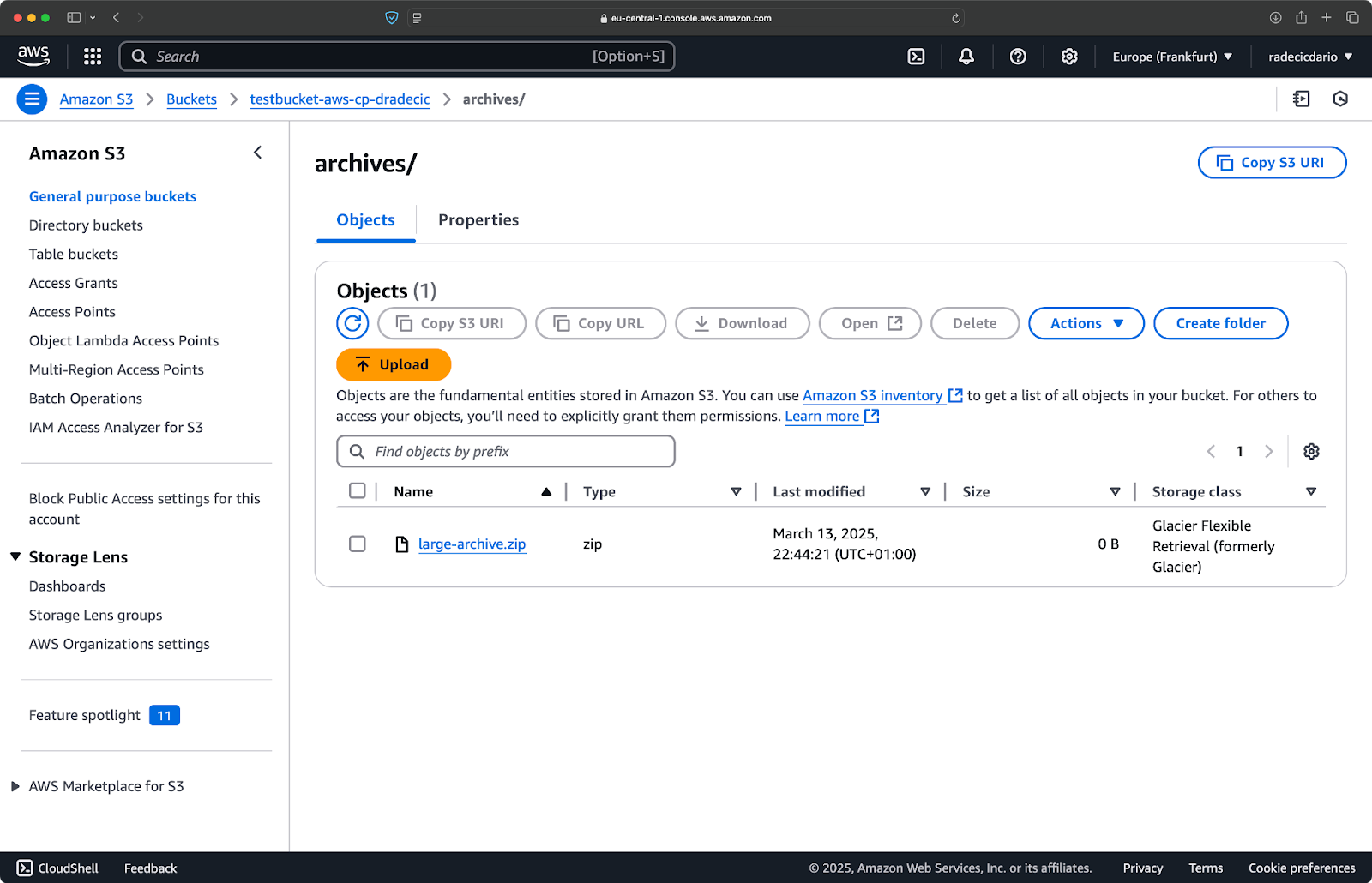
Immagine 18 – Copia dei file su S3 con classi di archiviazione diverse
Le classi di archiviazione disponibili includono:
STANDARD(predefinito): Archiviazione di uso generale con elevata durabilità e disponibilità.REDUCED_REDUNDANCY(non più consigliata): Opzione di risparmio sui costi con minore durabilità, ora deprecata.STANDARD_IA(Accesso non frequente): Archiviazione a costo inferiore per i dati accessibili meno frequentemente.ONEZONE_IA(Accesso non frequente a zona singola): Archiviazione a costo inferiore per l’accesso non frequente in una singola zona di disponibilità AWS.INTELLIGENT_TIERING: Sposta automaticamente i dati tra i livelli di archiviazione in base ai modelli di accesso.GLACIER: Archiviazione a basso costo per la conservazione a lungo termine, recupero entro pochi minuti o ore.DEEP_ARCHIVE: Archiviazione archivi a basso costo, recupero entro alcune ore, ideale per il backup a lungo termine.
Se stai effettuando il backup di file a cui non hai bisogno di accedere immediatamente, l’utilizzo di GLACIER o DEEP_ARCHIVE può farti risparmiare notevolmente sui costi di archiviazione.
Sincronizzazione dei file con il flag –exact-timestamps
Quando si aggiornano file in S3 che esistono già, potresti voler copiare solo i file che sono stati modificati. Il flag --exact-timestamps aiuta in questo confrontando i timestamp tra la sorgente e la destinazione.
Ecco un esempio:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exact-timestamps
Con questo flag, il comando copierà solo i file se i loro timestamp differiscono dai file già presenti in S3. Questo può ridurre il tempo di trasferimento e l’utilizzo della larghezza di banda quando si aggiornano regolarmente un gran numero di file.
Quindi, a cosa serve questo? Immagina scenari di distribuzione in cui vuoi aggiornare i file dell’applicazione senza trasferire inutilmente asset invariati.
Anche se --exact-timestamps è utile per eseguire una sorta di sincronizzazione, se hai bisogno di una soluzione più sofisticata, considera di utilizzare aws s3 sync invece di aws s3 cp. Il comando sync è stato progettato appositamente per mantenere le directory sincronizzate e ha capacità aggiuntive a questo scopo. Ho scritto tutto sul comando sync nel Tutorial di sincronizzazione AWS S3.
Con queste opzioni avanzate, ora hai un controllo più preciso sulle operazioni sui file S3. Puoi mirare a file specifici, ottimizzare i costi di archiviazione e aggiornare efficientemente i tuoi file. Nella sezione successiva, imparerai ad automatizzare queste operazioni utilizzando script e attività programmate.
Automazione dei trasferimenti di file con AWS S3 cp
Fino ad ora, hai imparato come copiare manualmente file da e verso S3 usando la riga di comando. Uno dei più grandi vantaggi nell’utilizzare aws s3 cp è che puoi facilmente automatizzare questi trasferimenti, il che ti risparmierà un sacco di tempo.
Esploriamo come puoi integrare il comando aws s3 cp in script e lavori pianificati per trasferimenti di file senza intervento manuale.
Utilizzo di AWS S3 cp negli script
Ecco un semplice esempio di script bash che esegue il backup di una directory su S3, aggiunge un timestamp al backup e implementa la gestione degli errori e il logging su un file:
#!/bin/bash # Imposta le variabili SOURCE_DIR="/Users/dradecic/Desktop/advanced_folder" BUCKET="s3://testbucket-aws-cp-dradecic/backups" DATE=$(date +%Y-%m-%d-%H-%M) BACKUP_NAME="backup-$DATE" LOG_FILE="/Users/dradecic/logs/s3-backup-$DATE.log" # Assicurati che la directory dei log esista mkdir -p "$(dirname "$LOG_FILE")" # Crea il backup e registra l'output echo "Starting backup of $SOURCE_DIR to $BUCKET/$BACKUP_NAME" | tee -a $LOG_FILE aws s3 cp $SOURCE_DIR $BUCKET/$BACKUP_NAME --recursive 2>&1 | tee -a $LOG_FILE # Controlla se il backup è stato eseguito con successo if [ $? -eq 0 ]; then echo "Backup completed successfully on $DATE" | tee -a $LOG_FILE else echo "Backup failed on $DATE" | tee -a $LOG_FILE fi
Salva questo come backup.sh, rendilo eseguibile con chmod +x backup.sh, e avrai uno script di backup riutilizzabile!
Puoi quindi eseguirlo con il seguente comando:
./backup.sh
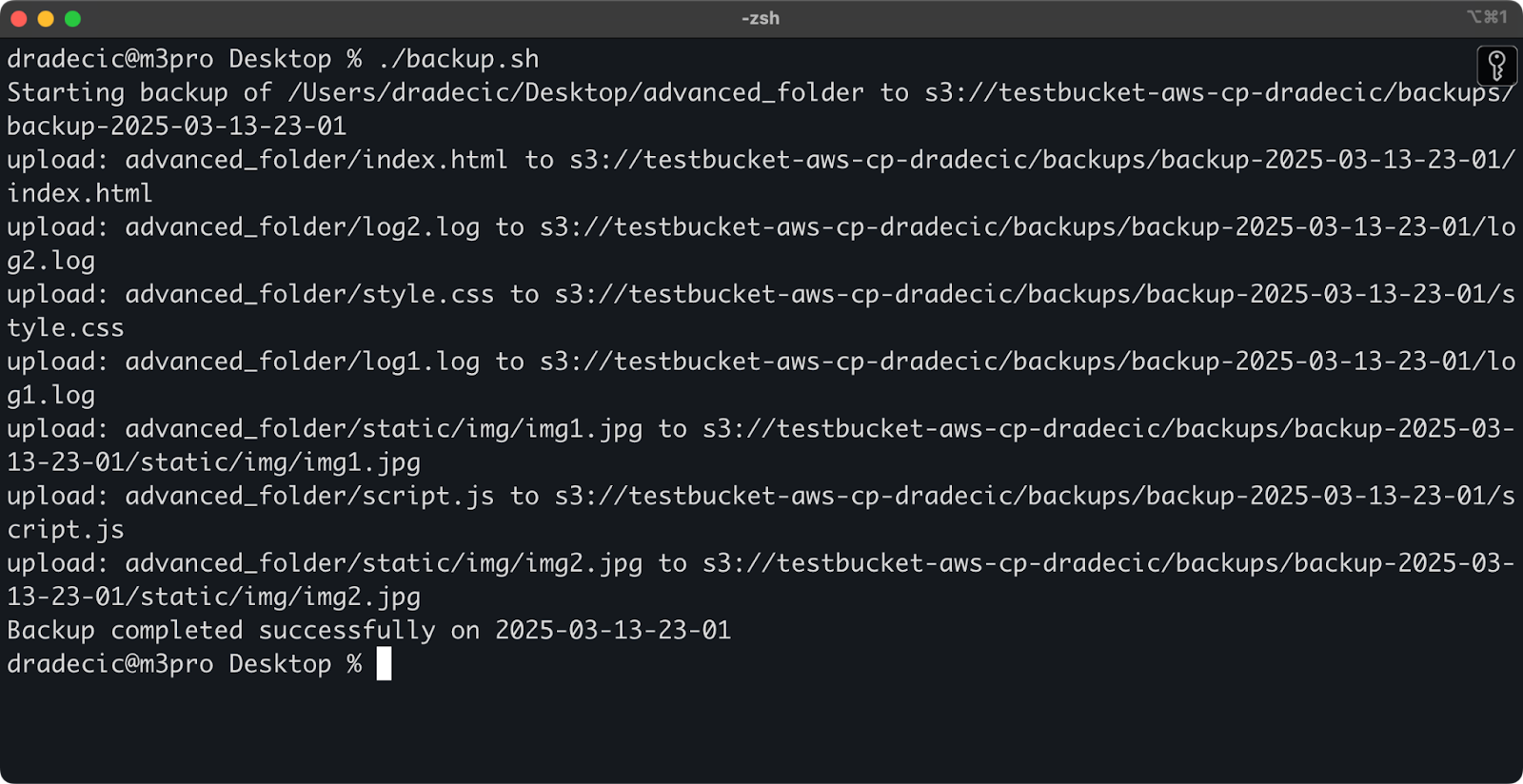
Immagine 19 – Esecuzione dello script nel terminale
Immediatamente dopo, la cartella backups nel bucket verrà popolata:
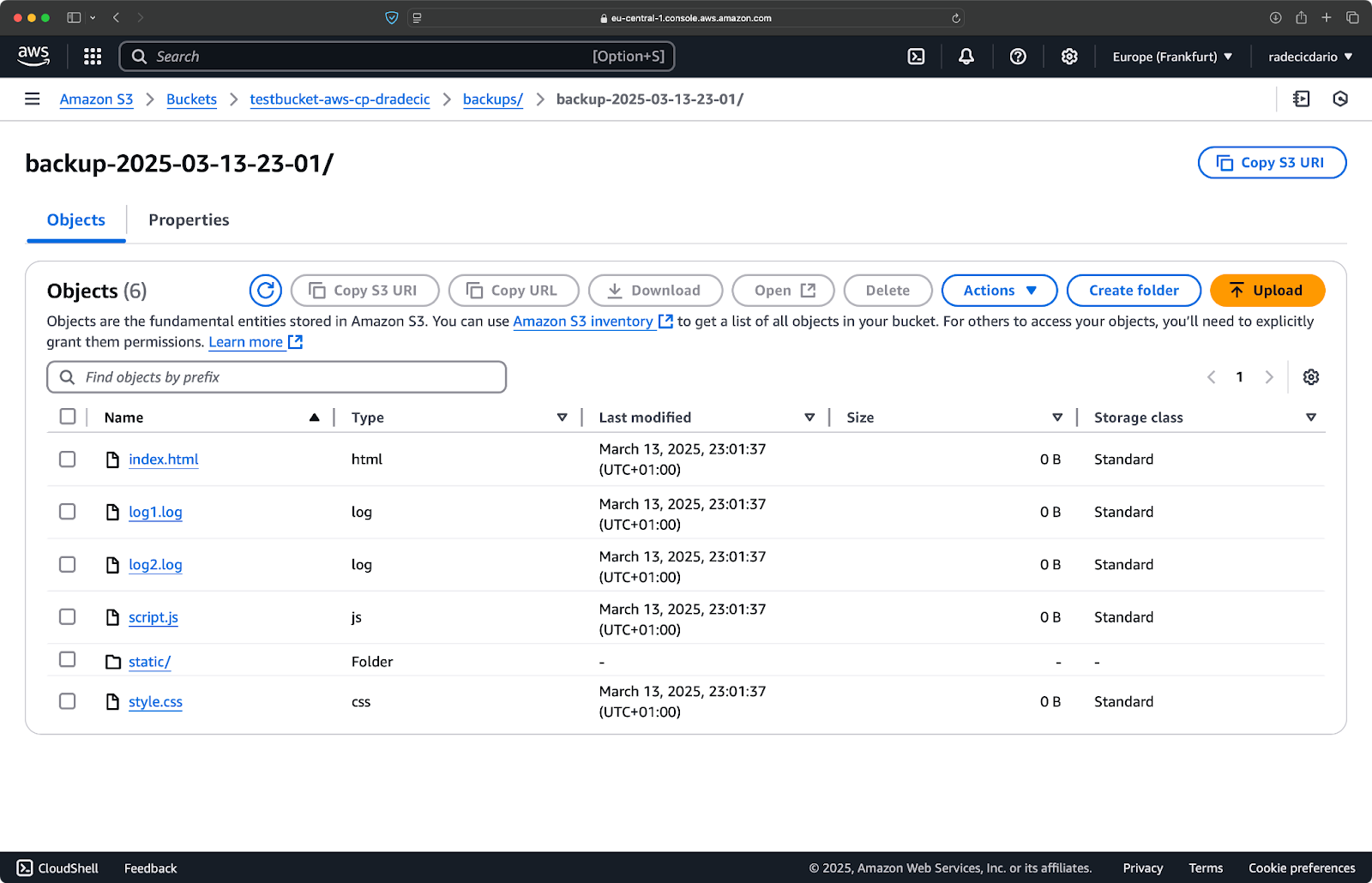
Immagine 20 – Backup memorizzato su bucket S3
Portiamo questo ad un livello successivo eseguendo lo script su un programma orario.
Pianificazione dei trasferimenti di file con lavori cron
Ora che hai uno script, il prossimo passo è pianificarlo per eseguirsi automaticamente in determinati orari.
Se sei su Linux o macOS, puoi utilizzare cron per pianificare i tuoi backup. Ecco come configurare un lavoro cron per eseguire lo script di backup ogni giorno a mezzanotte:
1. Apri il tuo crontab per modificarlo:
crontab -e
2. Aggiungi la seguente riga per eseguire lo script giornaliero a mezzanotte:
0 0 * * * /path/to/your/backup.sh
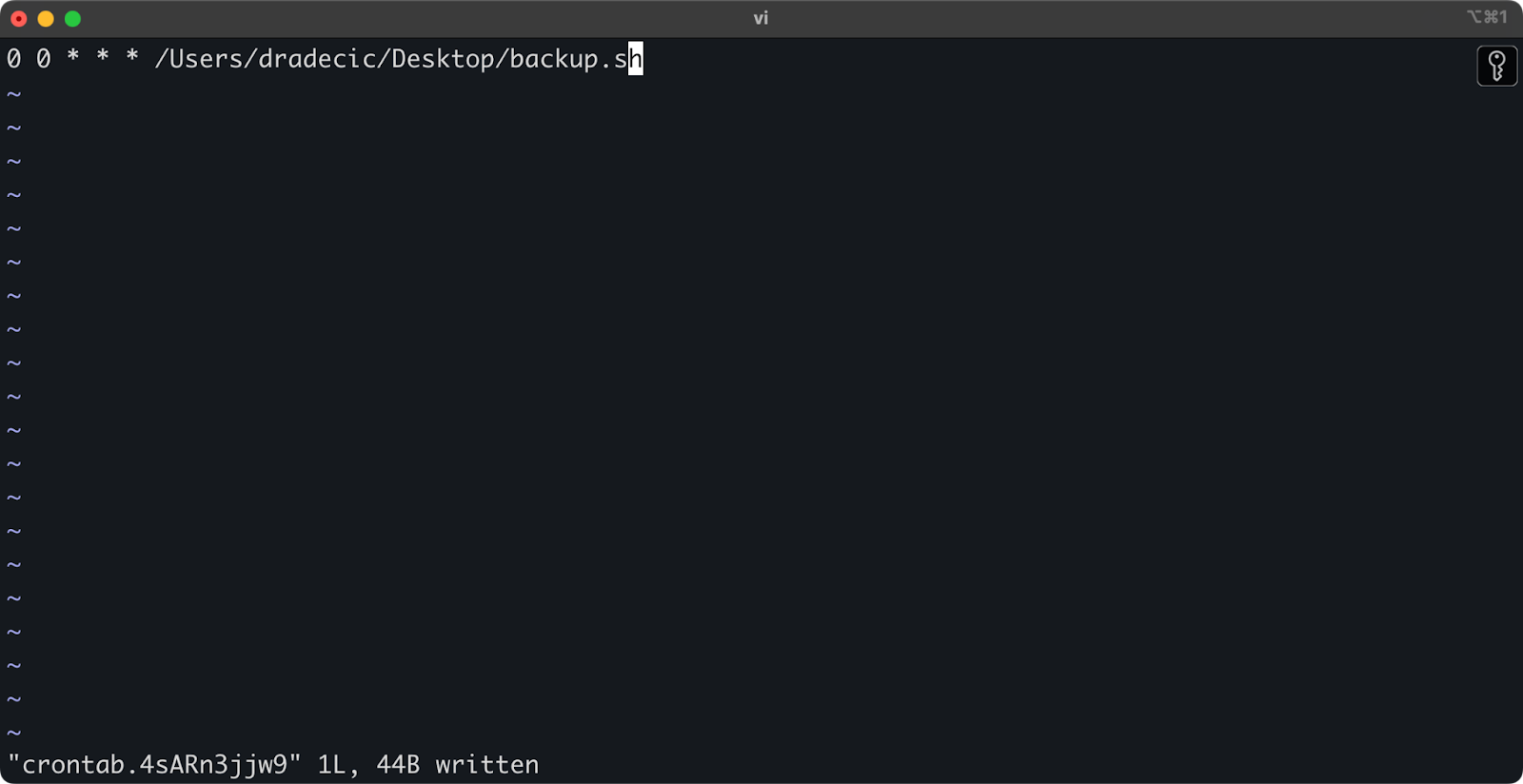
Immagine 21 – Lavoro cron per eseguire lo script giornaliero
Il formato per i lavori cron è minuto ora giorno-del-mese mese giorno-della-settimana comando. Ecco alcuni esempi aggiuntivi:
- Esegui ogni ora:
0 * * * * /percorso/del/tuo/backup.sh - Esegui ogni lunedì alle 9 del mattino:
0 9 * * 1 /percorso/del/tuo/backup.sh - Esegui il primo di ogni mese:
0 0 1 * * /percorso/del/tuo/backup.sh
E questo è tutto! Lo script backup.sh verrà ora eseguito all’intervallo pianificato.
L’automazione dei trasferimenti dei file su S3 è una buona soluzione. È particolarmente utile per scenari come:
- Copie di backup giornaliere dei dati importanti
- Sincronizzazione delle immagini del prodotto su un sito web
- Trasferimento dei file di log su archiviazione a lungo termine
- Implementazione di file aggiornati del sito web
Tecniche di automazione come queste ti aiuteranno a configurare un sistema affidabile che gestisce i trasferimenti di file senza intervento manuale. Devi scriverlo una sola volta e poi puoi dimenticartene.
Nella sezione successiva, tratterò alcune best practices per rendere le tue operazioni aws s3 cp più sicure ed efficienti.
Best Practices per l’Uso di AWS S3 cp
Anche se il comando aws s3 cp è facile da usare, le cose possono andare storte.
Seguendo le migliori pratiche, eviterai errori comuni, ottimizzerai le performance e manterrai sicuri i tuoi dati. Esploriamo queste pratiche per rendere più efficienti le tue operazioni di trasferimento file.
Gestione efficiente dei file
Quando si lavora con S3, organizzare logicamente i file ti farà risparmiare tempo e mal di testa in futuro.
Prima di tutto, stabilisci una convenzione di denominazione costante per secchio e prefisso. Ad esempio, puoi separare i tuoi dati per ambiente, applicazione o data:
s3://company-backups/production/database/2023-03-13/ s3://company-backups/staging/uploads/2023-03/
Questo tipo di organizzazione rende più facile:
- Trovare file specifici quando ne hai bisogno.
- Applicare politiche di bucket e permessi al livello giusto.
- Impostare regole di ciclo di vita per l’archiviazione o l’eliminazione di dati obsoleti.
Un altro consiglio: Quando trasferisci grandi quantità di file, considera di raggruppare prima i file piccoli (utilizzando zip o tar) prima di caricarli. Questo riduce il numero di chiamate API a S3, il che può abbattere i costi e velocizzare i trasferimenti.
# Invece di copiare migliaia di piccoli file di log # comprimili prima, poi caricali tar -czf example-logs-2025-03.tar.gz /var/log/application/ aws s3 cp example-logs-2025-03.tar.gz s3://testbucket-aws-cp-dradecic/logs/2025/03/
Gestione dei trasferimenti di grandi dati
Quando si copiano file di grandi dimensioni o molti file contemporaneamente, ci sono alcune tecniche per rendere il processo più affidabile ed efficiente.
Puoi utilizzare il flag --quiet per ridurre l’output durante l’esecuzione in script:
aws s3 cp large-directory/ s3://testbucket-aws-cp-dradecic/backups/ --recursive --quiet
Questo sopprime le informazioni sul progresso per ogni file, rendendo i log più gestibili. Migliora anche leggermente le prestazioni.
Per file molto grandi, considera di utilizzare upload multipart con il flag --multipart-threshold:
aws s3 cp huge-file.iso s3://testbucket-aws-cp-dradecic/backups/ --multipart-threshold 100MB
La configurazione sopra indicata dice all’AWS CLI di dividere i file più grandi di 100MB in più parti per l’upload. Questo porta alcuni vantaggi:
- Se la connessione cade, è necessario ritentare solo la parte interessata.
- Le parti possono essere caricate in parallelo, aumentando potenzialmente il throughput.
- È possibile mettere in pausa e riprendere grandi caricamenti.
Quando si trasferiscono dati tra regioni, considera l’utilizzo di S3 Transfer Acceleration per caricamenti più veloci:
aws s3 cp large-file.zip s3://testbucket-aws-cp-dradecic/backups/ --endpoint-url https://s3-accelerate.amazonaws.com
Ciò instrada il tuo trasferimento attraverso la rete perimetrale di Amazon, che può velocizzare significativamente i trasferimenti tra regioni.
Garantire la sicurezza
La sicurezza dovrebbe sempre essere una priorità assoluta quando si lavora con i propri dati nel cloud.
Prima di tutto, assicurati che le tue autorizzazioni IAM rispettino il principio del minimo privilegio.Concedi solo le autorizzazioni specifiche necessarie per ciascun compito.
Ecco un esempio di policy che puoi assegnare all’utente:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject" ], "Resource": "arn:aws:s3:::testbucket-aws-cp-dradecic/backups/*" } ] }
Questa policy consente di copiare file solo da e verso il prefisso “backups” nel bucket “my-bucket”.
Un ulteriore modo per aumentare la sicurezza è abilitare la crittografia per i dati sensibili. Puoi specificare la crittografia lato server durante il caricamento:
aws s3 cp confidential.docx s3://testbucket-aws-cp-dradecic/ --sse AES256
Oppure, per maggiore sicurezza, utilizza il servizio AWS Key Management (KMS):
aws s3 cp secret-data.json s3://testbucket-aws-cp-dradecic/ --sse aws:kms --sse-kms-key-id myKMSKeyId
Tuttavia, per operazioni altamente sensibili, considera di utilizzare i punti di accesso VPC per S3. Questo mantiene il tuo traffico all’interno della rete AWS ed evita completamente Internet pubblico.
Nella sezione successiva, imparerai come risolvere i problemi comuni che potresti incontrare quando lavori con questo comando.
Problemi di risoluzione dei problemi di AWS S3 cp
Una cosa è certa: incontrerai occasionalmente problemi quando lavori con aws s3 cp. Ma, comprendendo gli errori comuni e le loro soluzioni, risparmierai tempo e frustrazione quando le cose non vanno come previsto.
In questa sezione, ti mostrerò i problemi più frequenti e come risolverli.
Errori comuni e soluzioni
Errore: “Accesso negato”
Questo è probabilmente l’errore più comune che incontrerai:
upload failed: ./myfile.txt to s3://testbucket-aws-cp-dradecic/myfile.txt An error occurred (AccessDenied) when calling the PutObject operation: Access Denied
Di solito significa una delle tre cose:
- Il tuo utente IAM non ha le autorizzazioni sufficienti per eseguire l’operazione.
- La policy del bucket sta limitando l’accesso.
- Le tue credenziali AWS sono scadute.
Per risolvere il problema:
- Verifica le tue autorizzazioni IAM per assicurarti di avere le necessarie autorizzazioni
s3:PutObject(per gli upload) os3:GetObject(per i download). - Verifica che la policy del bucket non stia limitando le tue azioni.
- Esegui
aws configureper aggiornare le tue credenziali se sono scadute.
Errore: “File o directory non esistente”
Questo errore si verifica quando il file o la directory locale che stai cercando di copiare non esiste:
upload failed: ./missing-file.txt to s3://testbucket-aws-cp-dradecic/missing-file.txt An error occurred (404) when calling the PutObject operation: Not Found
La soluzione è semplice – controlla attentamente i percorsi dei file. I percorsi sono sensibili alle maiuscole e minuscole, quindi tienilo presente. Assicurati inoltre di trovarti nella directory corretta quando utilizzi percorsi relativi.
Errore: “Il bucket specificato non esiste”
Se visualizzi questo errore:
upload failed: ./myfile.txt to s3://testbucket-aws-cp-dradecic/myfile.txt An error occurred (NoSuchBucket) when calling the PutObject operation: The specified bucket does not exist
Controlla:
- Errori di battitura nel nome del bucket.
- Se stai utilizzando la regione AWS corretta.
- Se il bucket esiste effettivamente (potrebbe essere stato eliminato).
Puoi elencare tutti i tuoi bucket con aws s3 ls per confermare il nome corretto.
Errore: “Connessione scaduta”
Problemi di rete possono causare timeout della connessione:
upload failed: ./largefile.zip to s3://testbucket-aws-cp-dradecic/largefile.zip An error occurred (RequestTimeout) when calling the PutObject operation: Request timeout
Per risolvere questo:
- Controlla la tua connessione internet.
- Prova a utilizzare file più piccoli o abilita gli upload multipart per i file di grandi dimensioni.
- Considera di utilizzare l’Accelerazione del Trasferimento di AWS per ottenere prestazioni migliori.
Gestione dei fallimenti di upload
Gli errori sono molto più probabili durante il trasferimento di file di grandi dimensioni. In tal caso, cerca di gestire i fallimenti in modo adeguato.
Ad esempio, puoi utilizzare il flag --only-show-errors per semplificare la diagnosi degli errori negli script:
aws s3 cp large-directory/ s3://testbucket-aws-cp-dradecic/ --recursive --only-show-errors
Questo nasconde i messaggi di trasferimento riusciti, mostrando solo gli errori, rendendo così molto più semplice il debug dei trasferimenti di grandi dimensioni.
Per gestire trasferimenti interrotti, il comando --recursive salterà automaticamente i file che esistono già nella destinazione con la stessa dimensione. Tuttavia, per essere più accurati, puoi utilizzare i tentativi integrati nell’AWS CLI per problemi di rete impostando queste variabili d’ambiente:
export AWS_RETRY_MODE=standard export AWS_MAX_ATTEMPTS=5 aws s3 cp large-file.zip s3://testbucket-aws-cp-dradecic/
Questo dice all’AWS CLI di riprovare automaticamente le operazioni fallite fino a 5 volte.
Ma per dataset molto grandi, considera di utilizzare aws s3 sync invece di cp, poiché è progettato per gestire interruzioni in modo migliore:
aws s3 sync large-directory/ s3://testbucket-aws-cp-dradecic/large-directory/
Il comando sync trasferirà solo i file diversi da quelli già presenti nella destinazione, rendendolo perfetto per riprendere trasferimenti di file di grandi dimensioni interrotti.
Se comprendi questi errori comuni e implementi una gestione degli errori adeguata nei tuoi script, renderai le tue operazioni di copia su S3 molto più robuste e affidabili.
Riassumendo, AWS S3 cp
Per concludere, il comando aws s3 cp è un unico punto di riferimento per copiare file locali su S3 e viceversa.
Hai imparato tutto a riguardo in questo articolo. Sei partito dai fondamentali e dalla configurazione dell’ambiente, e sei arrivato a scrivere script pianificati e automatizzati per la copia dei file. Hai anche imparato come affrontare alcuni errori e sfide comuni nel trasferimento di file, specialmente quelli di grandi dimensioni.
Quindi, se sei uno sviluppatore, un professionista dei dati o un amministratore di sistema, penso che troverai utile questo comando. Il modo migliore per sentirti a tuo agio con esso è utilizzarlo regolarmente. Assicurati di comprendere i fondamenti e poi dedica del tempo ad automatizzare le parti noiose del tuo lavoro.
Per saperne di più su AWS, segui questi corsi di DataCamp:
Puoi anche utilizzare DataCamp per prepararti agli esami di certificazione AWS – Praticante Cloud AWS (CLF-C02).