













AWS CLI 및 AWS S3 설정하기
aws s3 cp 명령어를 실행하기 전에 시스템에 AWS CLI가 설치되어 있고 올바르게 구성되어 있어야 합니다. AWS를 사용해본 적이 없다면 걱정하지 마세요 – 설정 과정은 쉽고 10분 미만이 소요될 것입니다.
이를 세 가지 간단한 단계로 나누어 설명하겠습니다: AWS CLI 도구 설치, 자격 증명 구성, 그리고 저장소로 사용할 첫 번째 S3 버킷 생성입니다.
AWS CLI 설치하기
설치 프로세스는 사용 중인 운영 체제에 따라 약간 다릅니다.
Windows 시스템의 경우:
- 공식 AWS CLI 문서 페이지
- 로 이동합니다.64비트 Windows 설치 프로그램
- 를 다운로드합니다.
다운로드한 파일을 실행하고 설치 마법사를 따릅니다.Linux 시스템의 경우:
터미널을 통해 다음 세 가지 명령을 실행합니다:
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" unzip awscliv2.zip sudo ./aws/install
macOS 시스템의 경우:
Homebrew가 설치되어 있다고 가정하고, 터미널에서 이 한 줄을 실행합니다:
brew install awscli
Homebrew가 없다면 대신 이 두 가지 명령을 사용합니다:
curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg" sudo installer -pkg AWSCLIV2.pkg -target /
성공적인 설치를 확인하려면 터미널에서 aws --version을 실행합니다. 다음과 같은 결과를 볼 수 있어야 합니다:
이미지 1 – AWS CLI 버전
AWS CLI 구성하기
CLI가 설치되었으니, 인증을 위한 AWS 자격 증명을 설정할 시간입니다.
먼저, AWS 계정에 접속하여 IAM 서비스 대시보드로 이동합니다. 프로그래밍 액세스를 가진 새 사용자를 생성하고 적절한 S3 권한 정책을 부착합니다:
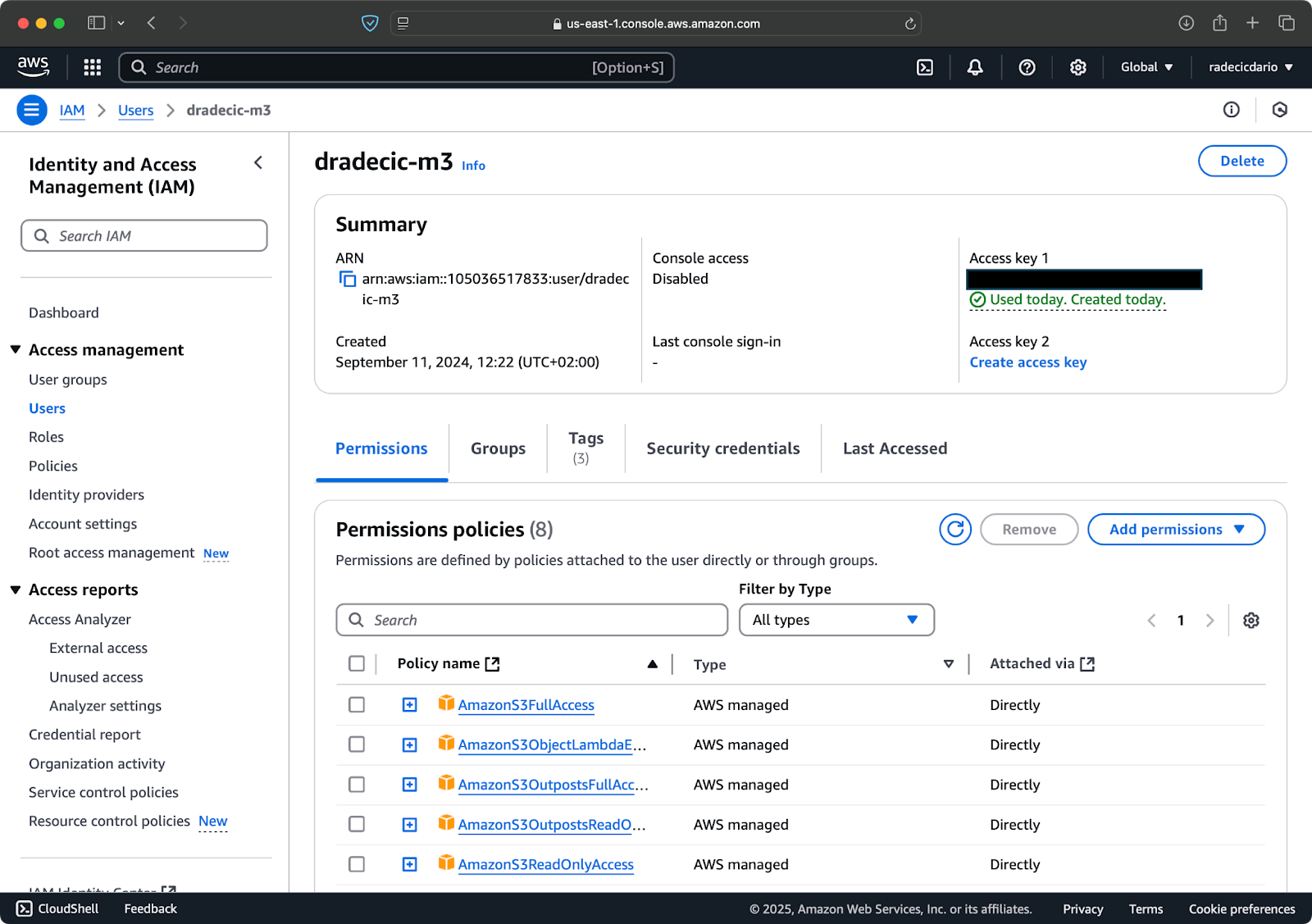
이미지 2 – AWS IAM 사용자
다음으로, “보안 자격 증명” 탭을 방문하여 새 액세스 키 쌍을 생성합니다. Access key ID와 Secret access key를 안전한 곳에 저장하는 것을 잊지 마세요 – 이 화면 이후에는 Amazon이 비밀 키를 다시 보여주지 않습니다:
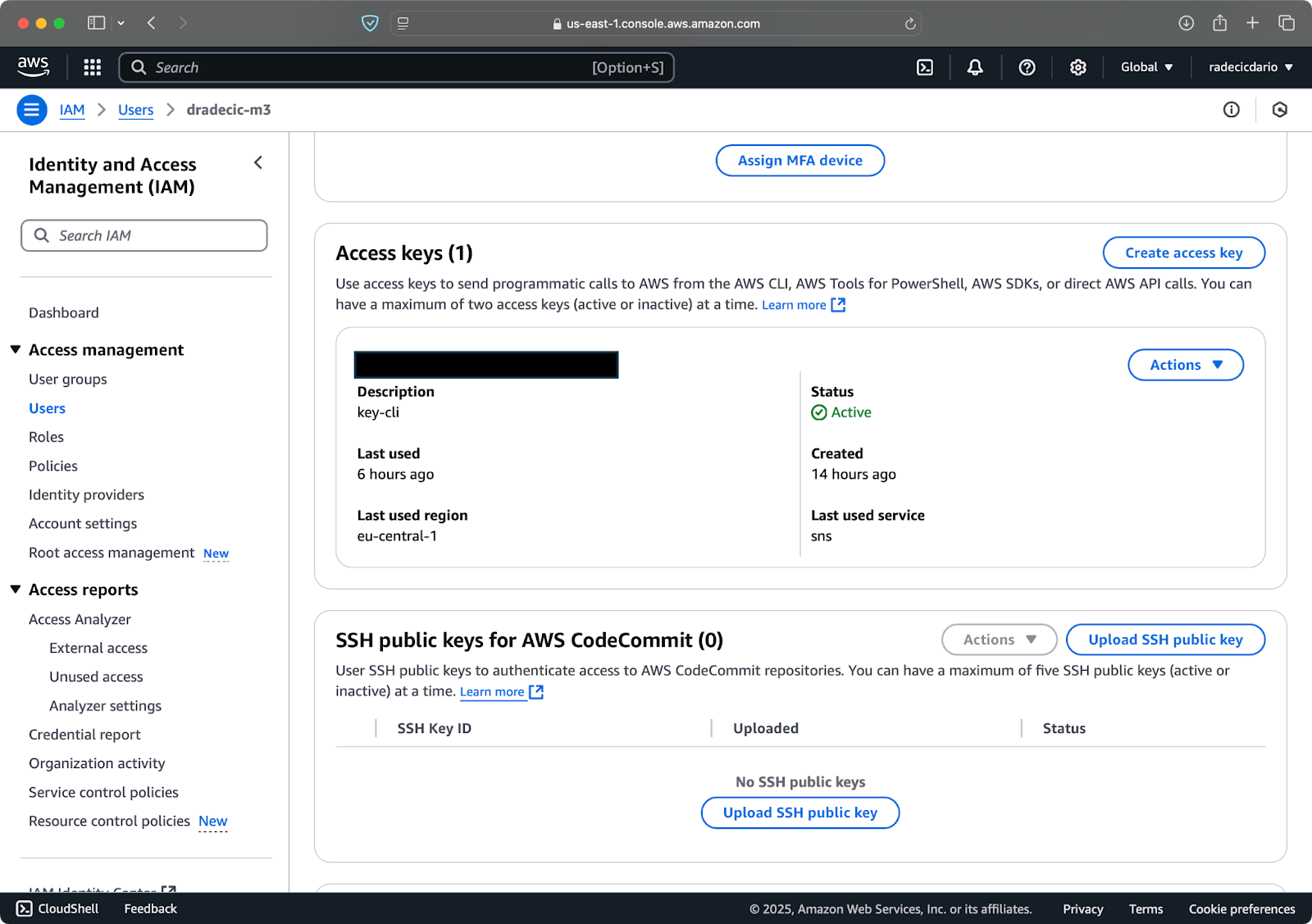
이미지 3 – AWS IAM 사용자 자격 증명
이제 터미널을 열고 aws configure 명령을 실행하십시오. 네 가지 정보를 입력해야 합니다: Access Key ID, Secret Access Key, 기본 지역(저는 eu-central-1을 사용하고 있습니다), 그리고 선호하는 출력 형식(일반적으로 json):
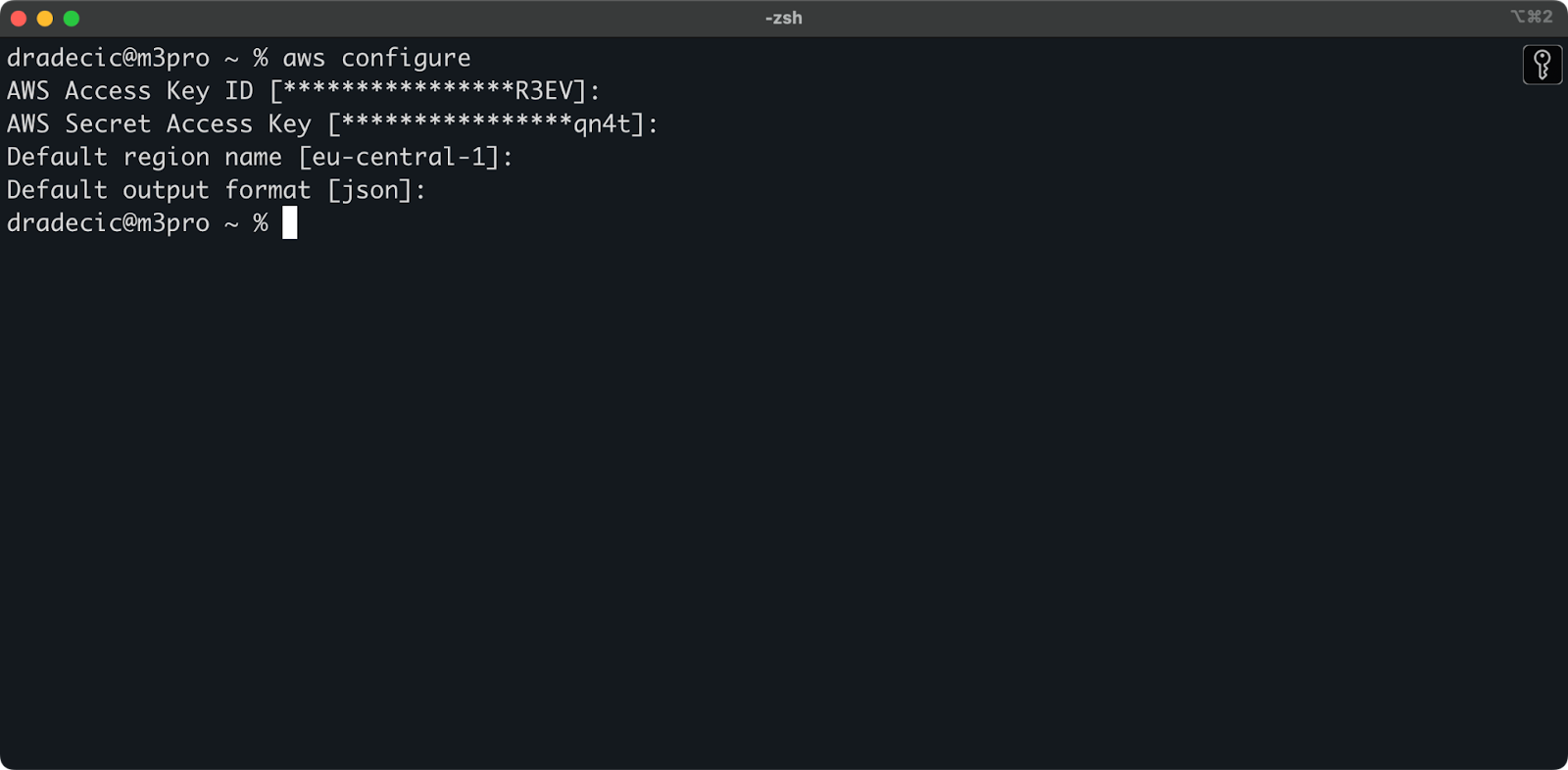
이미지 4 – AWS CLI 구성
모든 것이 올바르게 연결되었는지 확인하려면 다음 명령을 사용하여 신원을 확인하십시오:
aws sts get-caller-identity
올바르게 구성되면 계정 세부 정보가 표시됩니다:
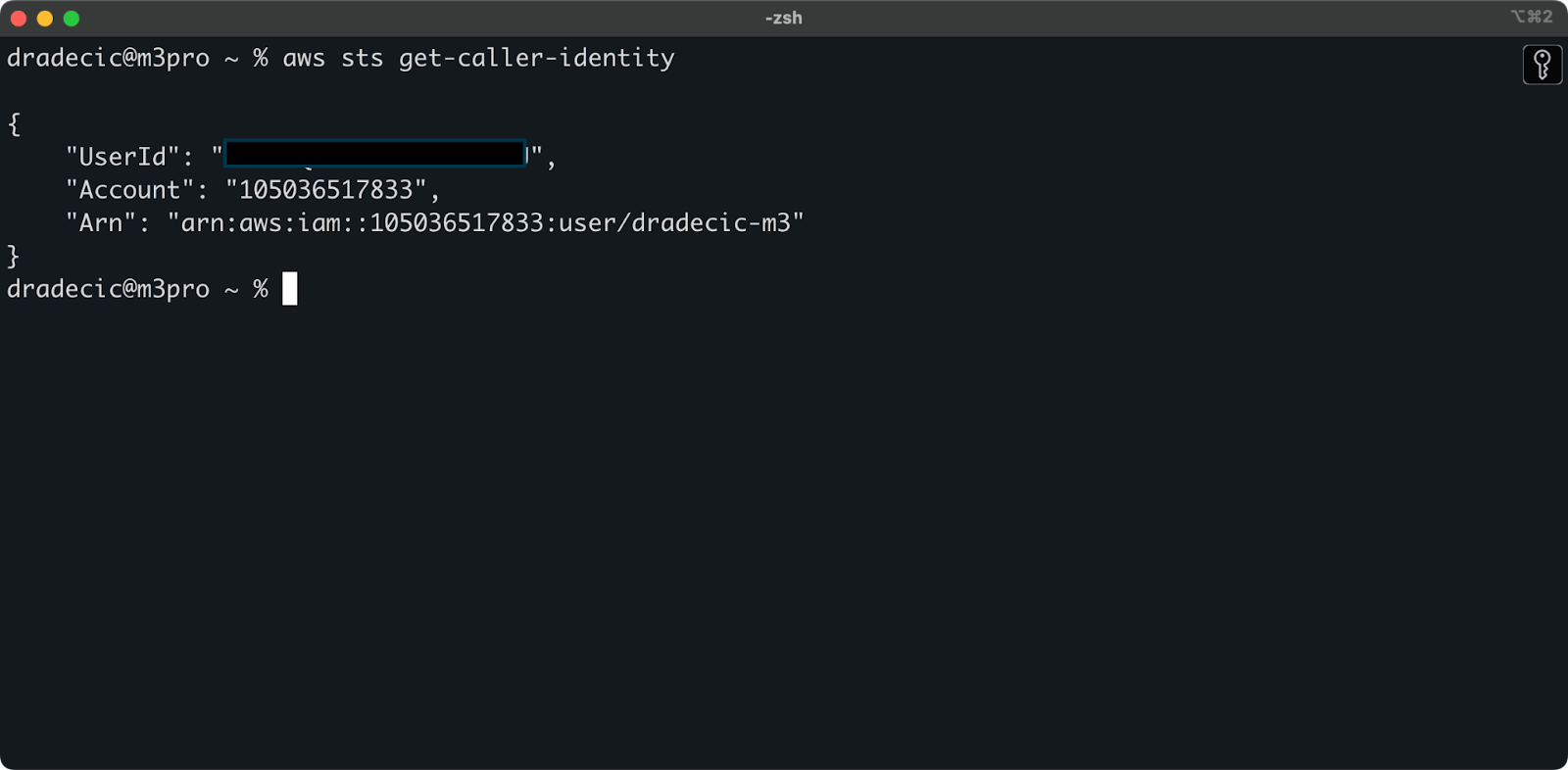
이미지 5 – AWS CLI 테스트 연결 명령
S3 버킷 생성
마지막으로 복사할 파일을 저장할 S3 버킷을 생성해야 합니다.
AWS 콘솔에서 S3 서비스 섹션으로 이동하고 “버킷 생성”을 클릭하십시오. 버킷 이름은 모든 AWS에서 전역적으로 고유해야 합니다. 독특한 이름을 선택하고 현재는 기본 설정을 유지한 채로 “생성”을 클릭하십시오:
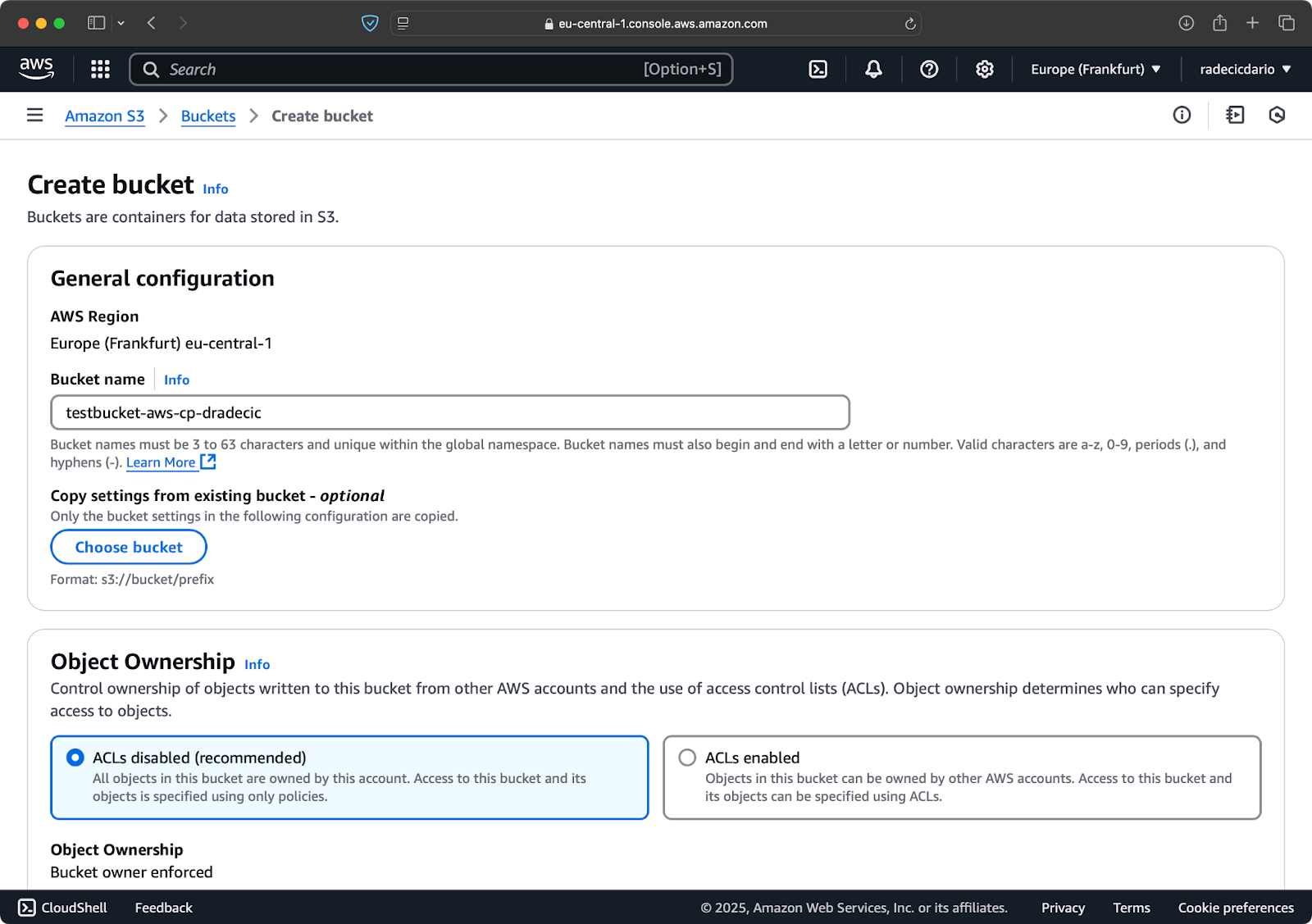
이미지 6 – AWS 버킷 생성
생성되면 새 버킷이 콘솔에 표시됩니다. 명령 줄을 통해 존재 여부를 확인할 수도 있습니다:
aws s3 ls
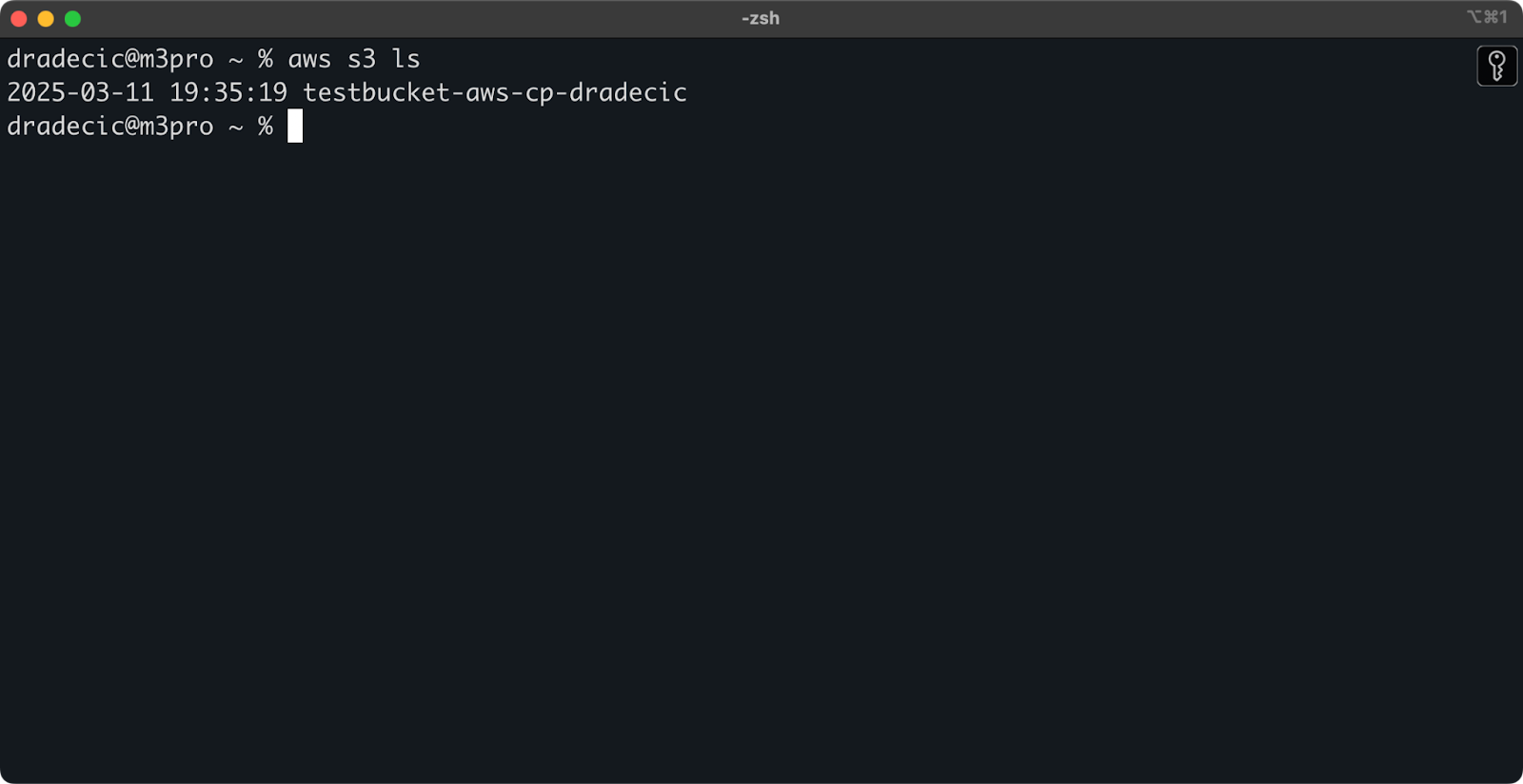
이미지 7 – 모든 사용 가능한 S3 버킷
모든 S3 버킷은 기본적으로 비공개로 구성되어 있으므로 이를 염두에 두십시오. 이 버킷을 공개적으로 접근할 파일에 사용하려면 버킷 정책을 적절히 수정해야 합니다.
이제 aws s3 cp 명령을 사용하여 파일을 전송할 준비가 되었습니다. 다음으로 기본 사항을 시작해 보겠습니다.
AWS S3 기본 cp 명령 구문
이제 모든 것이 구성되었으니, aws s3 cp 명령어의 기본적인 사용법을 알아보겠습니다. AWS의 경우, 명령어는 다양한 파일 전송 시나리오를 처리할 수 있지만 간결함에 미학이 있습니다.
가장 기본적인 형태로, aws s3 cp 명령어는 다음 구문을 따릅니다:
aws s3 cp <source> <destination> [options]
<source>와 <destination>은 로컬 파일 경로나 S3 URI(시작은 s3://)가 될 수 있습니다. 세 가지 가장 일반적인 사용 사례를 살펴봅시다.
로컬에서 S3로 파일 복사
로컬 시스템에서 S3 버킷으로 파일을 복사하려면, 소스는 로컬 경로이고 대상은 S3 URI여야 합니다:
aws s3 cp /Users/dradecic/Desktop/test_file.txt s3://testbucket-aws-cp-dradecic/test_file.txt
이 명령은 제공된 디렉토리에서 파일 test_file.txt을 지정된 S3 버킷에 업로드합니다. 작업이 성공하면 다음과 같은 콘솔 출력이 표시됩니다:
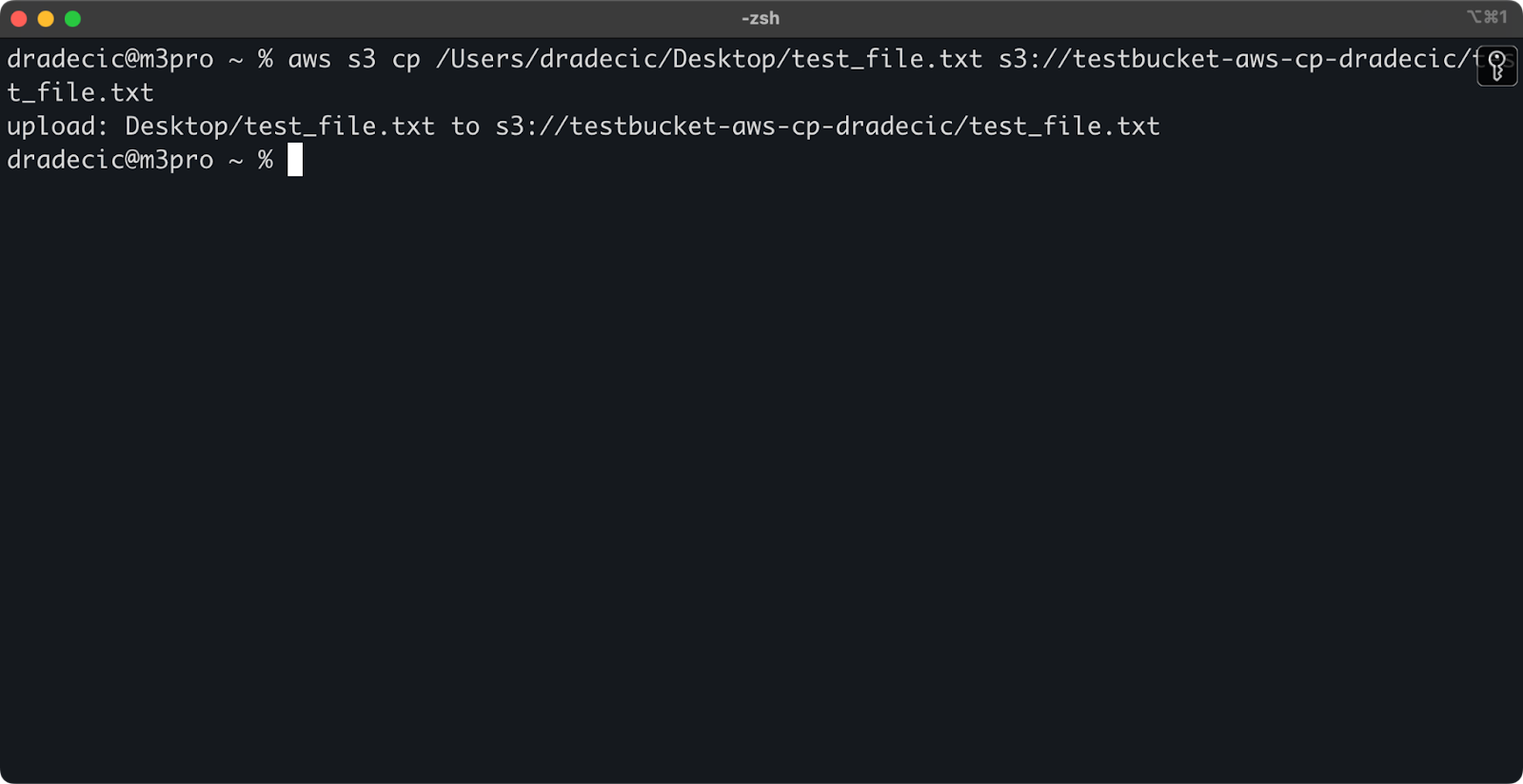
이미지 8 – 로컬 파일 복사 후 콘솔 출력
그리고 AWS 관리 콘솔에서 파일이 업로드된 것을 확인할 수 있습니다:
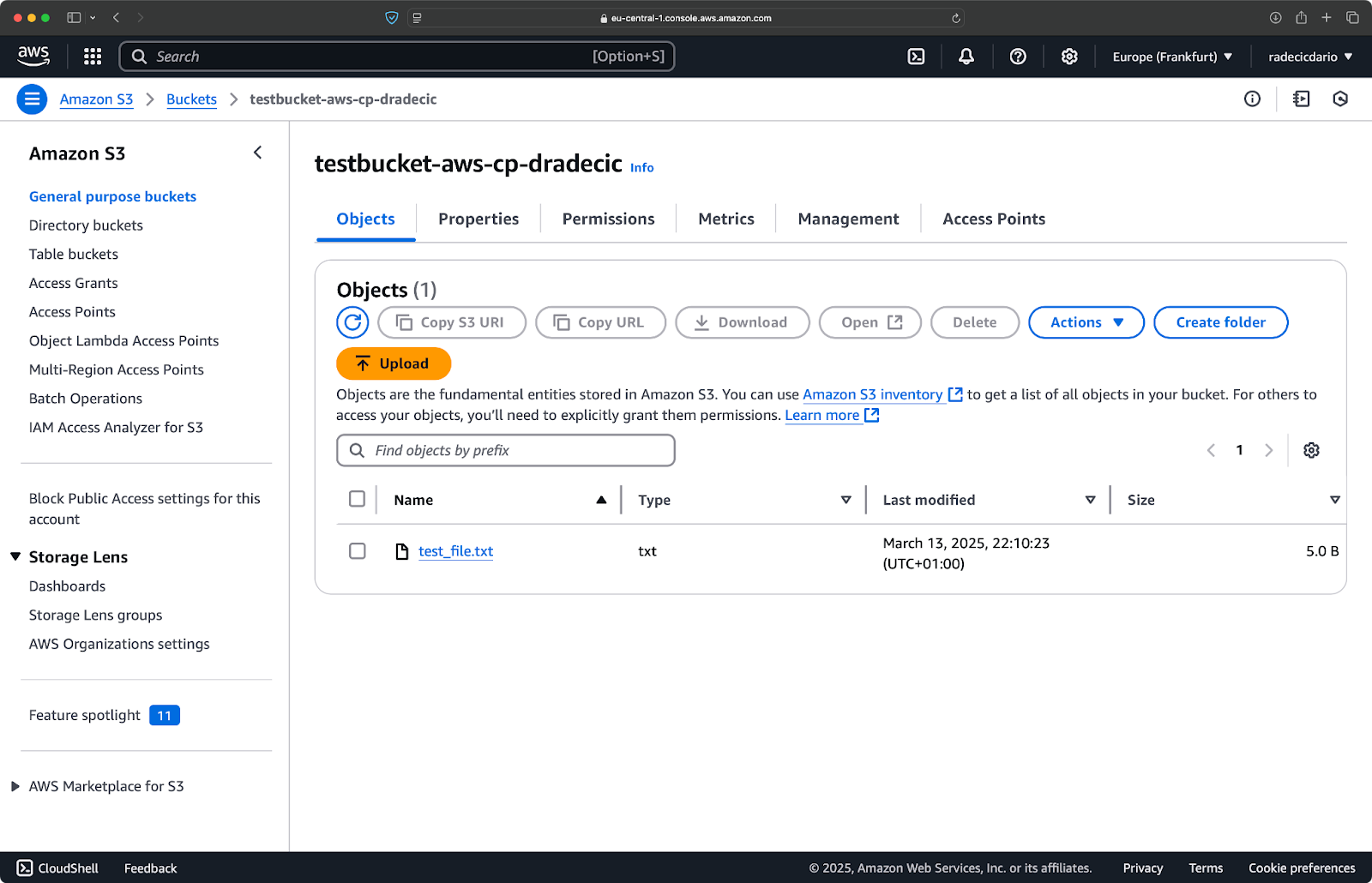
이미지 9 – S3 버킷 내용
비슷하게, 로컬 폴더를 S3 버킷으로 복사하고 다른 중첩된 폴더에 넣으려면 다음과 유사한 명령을 실행하십시오:
aws s3 cp /Users/dradecic/Desktop/test_folder s3://testbucket-aws-cp-dradecic/my-desired-folder/test_folder/ --recursive
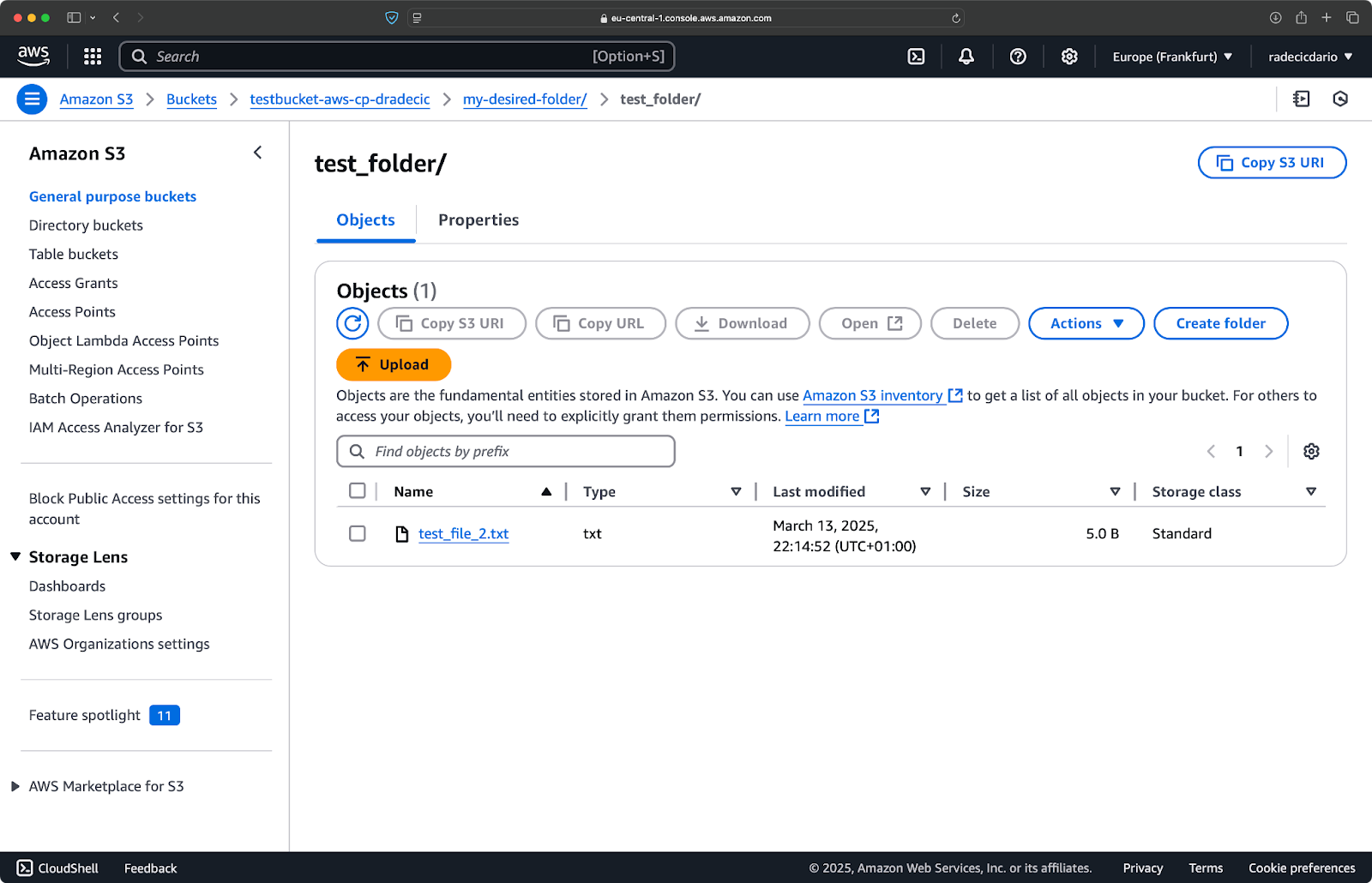
이미지 10 – 폴더 업로드 후 S3 버킷 내용
--recursive 플래그를 사용하여 폴더 내의 모든 파일과 하위 폴더가 복사되도록 합니다.
기억해야 할 점은 – S3는 실제로 폴더를 보유하지 않습니다. 경로 구조는 객체의 키의 일부일 뿐이지만 개념적으로 폴더처럼 작동합니다.
S3에서 로컬로 파일 복사
S3에서 로컬 시스템으로 파일을 복사하려면 단순히 순서를 뒤집으면 됩니다 – 소스는 S3 URI가 되고 대상은 로컬 경로가 됩니다:
aws s3 cp s3://testbucket-aws-cp-dradecic/test_file.txt /Users/dradecic/Documents/s3-data/downloaded_test_file.txt
이 명령은 S3 버킷에서 test_file.txt를 다운로드하여 제공된 디렉토리에 downloaded_test_file.txt로 저장합니다. 로컬 시스템에서 즉시 확인할 수 있습니다:
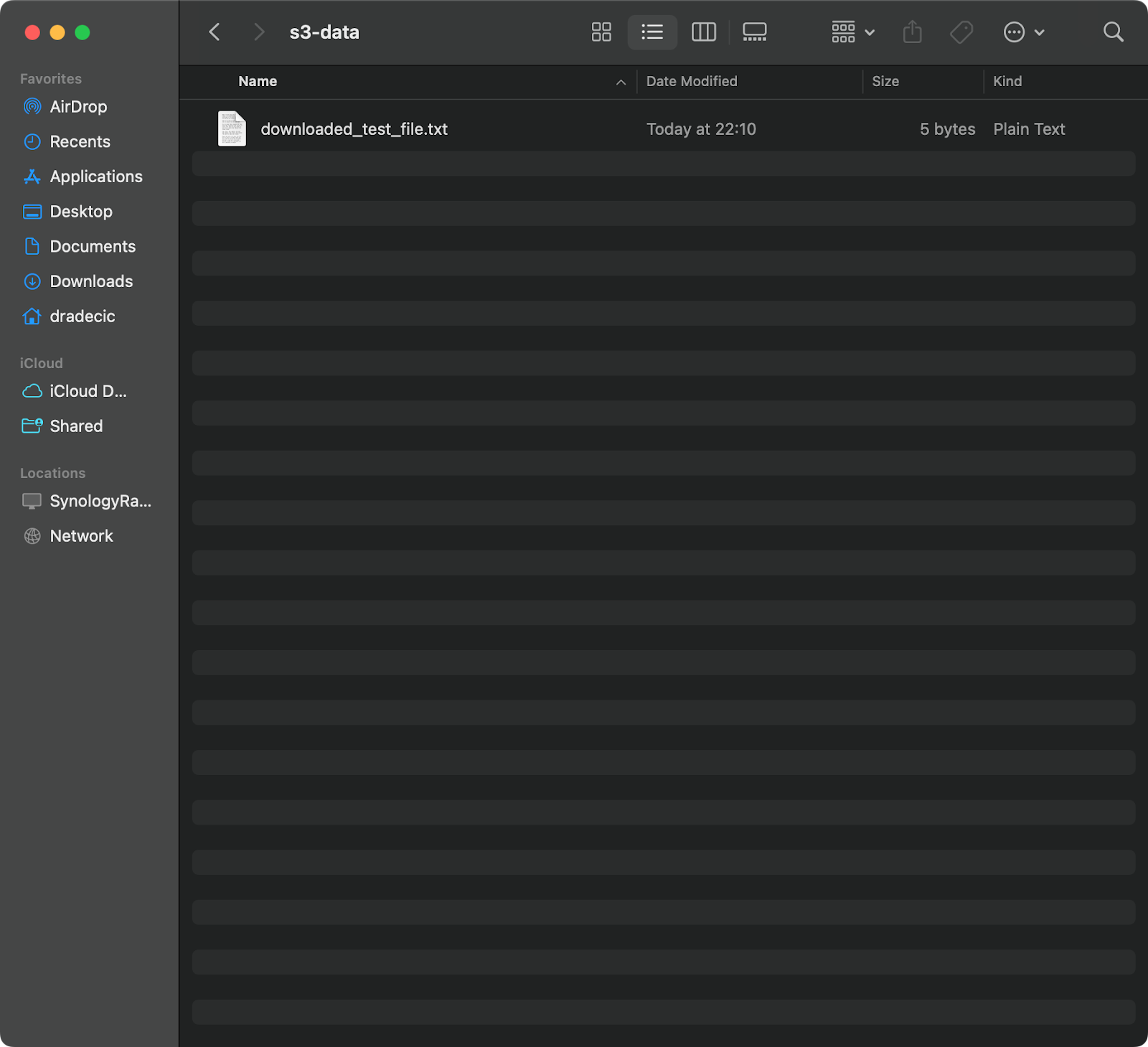
이미지 11 – S3에서 단일 파일 다운로드
대상 파일 이름을 생략하면 명령이 원래 파일 이름을 사용합니다:
aws s3 cp s3://testbucket-aws-cp-dradecic/test_file.txt .
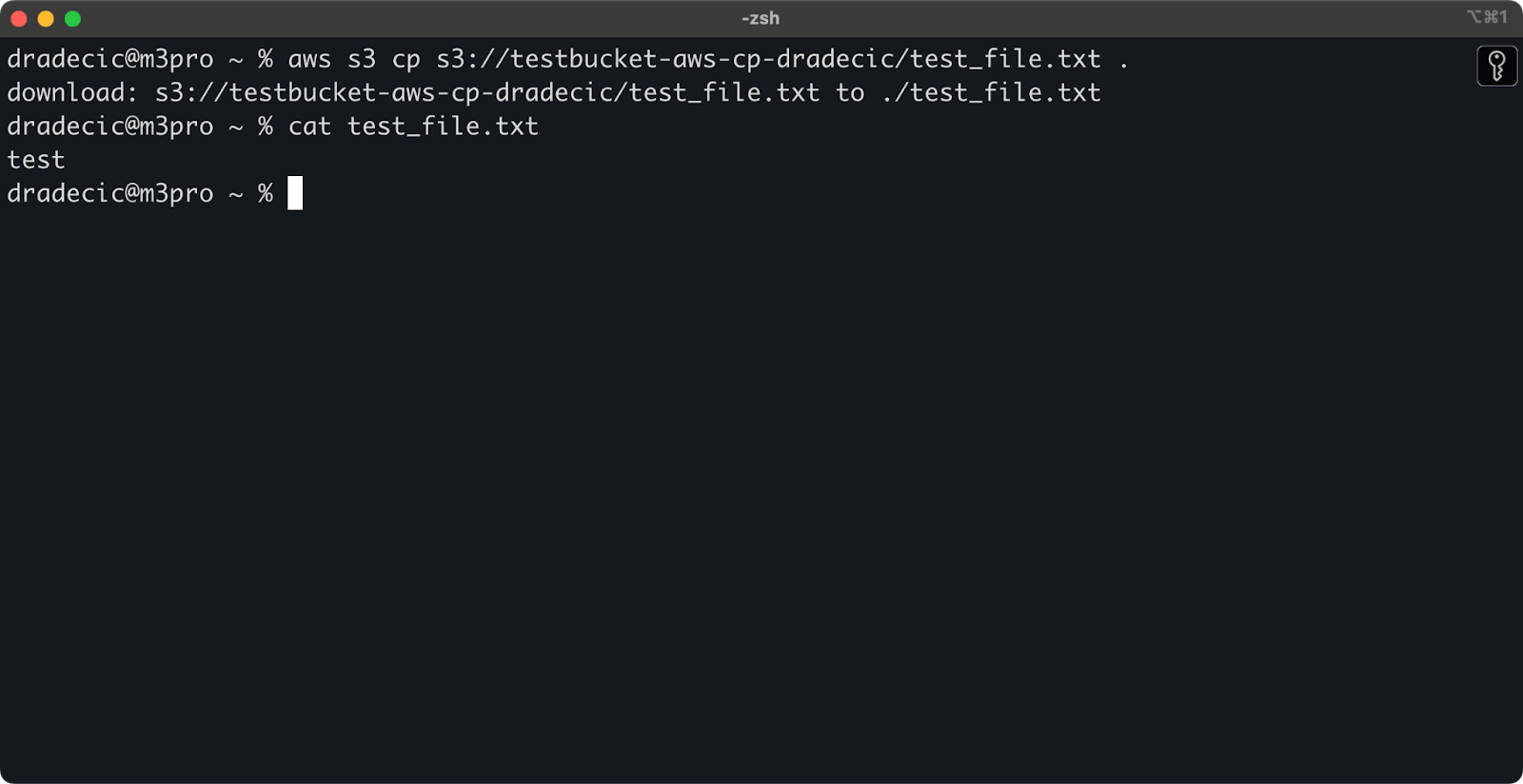
이미지 12 – 다운로드된 파일의 내용
점(.)은 현재 디렉토리를 나타내므로 이렇게 하면 test_file.txt를 현재 위치로 다운로드합니다.
마지막으로 전체 디렉토리를 다운로드하려면 다음과 유사한 명령을 사용할 수 있습니다:
aws s3 cp s3://testbucket-aws-cp-dradecic/my-desired-folder/test_folder /Users/dradecic/Documents/test_folder --recursive
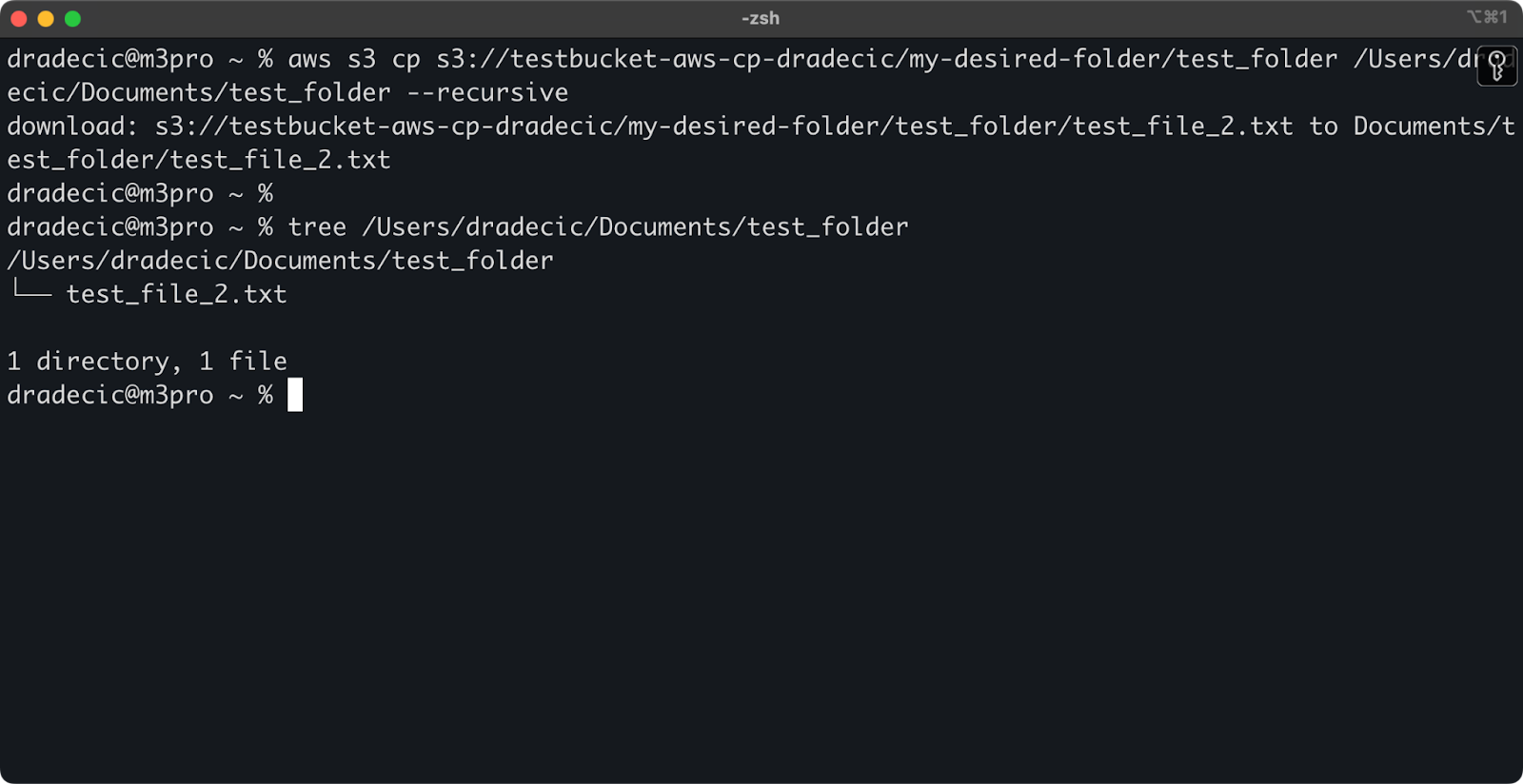
이미지 13 – 다운로드된 폴더의 내용
--recursive 플래그는 여러 파일을 처리할 때 필수적이며, 이 플래그가 없으면 소스가 디렉토리인 경우 명령이 실패합니다.
이러한 기본 명령어로 이미 대부분의 파일 전송 작업을 수행할 수 있습니다. 그러나 다음 섹션에서는 복사 프로세스를 더 잘 제어할 수 있는 고급 옵션에 대해 더 자세히 알아보겠습니다.
고급 AWS S3 cp 옵션 및 기능
AWS는 파일 복사 작업을 최대화할 수 있는 몇 가지 고급 옵션을 제공합니다. 이 섹션에서는 일상적인 작업에 도움이 될 가장 유용한 플래그와 매개변수 중 일부를 안내해 드리겠습니다.
–exclude 및 –include 플래그 사용
가끔 특정 패턴과 일치하는 파일만 복사하고 싶을 때가 있습니다. --exclude 및 --include 플래그를 사용하면 패턴을 기반으로 파일을 필터링할 수 있으며, 복사할 대상을 정확히 제어할 수 있습니다.
먼저 작업 중인 디렉토리 구조는 다음과 같습니다:
이미지 14 – 디렉토리 구조
이제 디렉토리에서 .log 파일을 제외한 모든 파일을 복사하려고 합니다:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exclude "*.log"
이 명령은 .log 확장자를 가진 파일을 제외하고 advanced_folder 디렉토리의 모든 파일을 S3로 복사합니다:
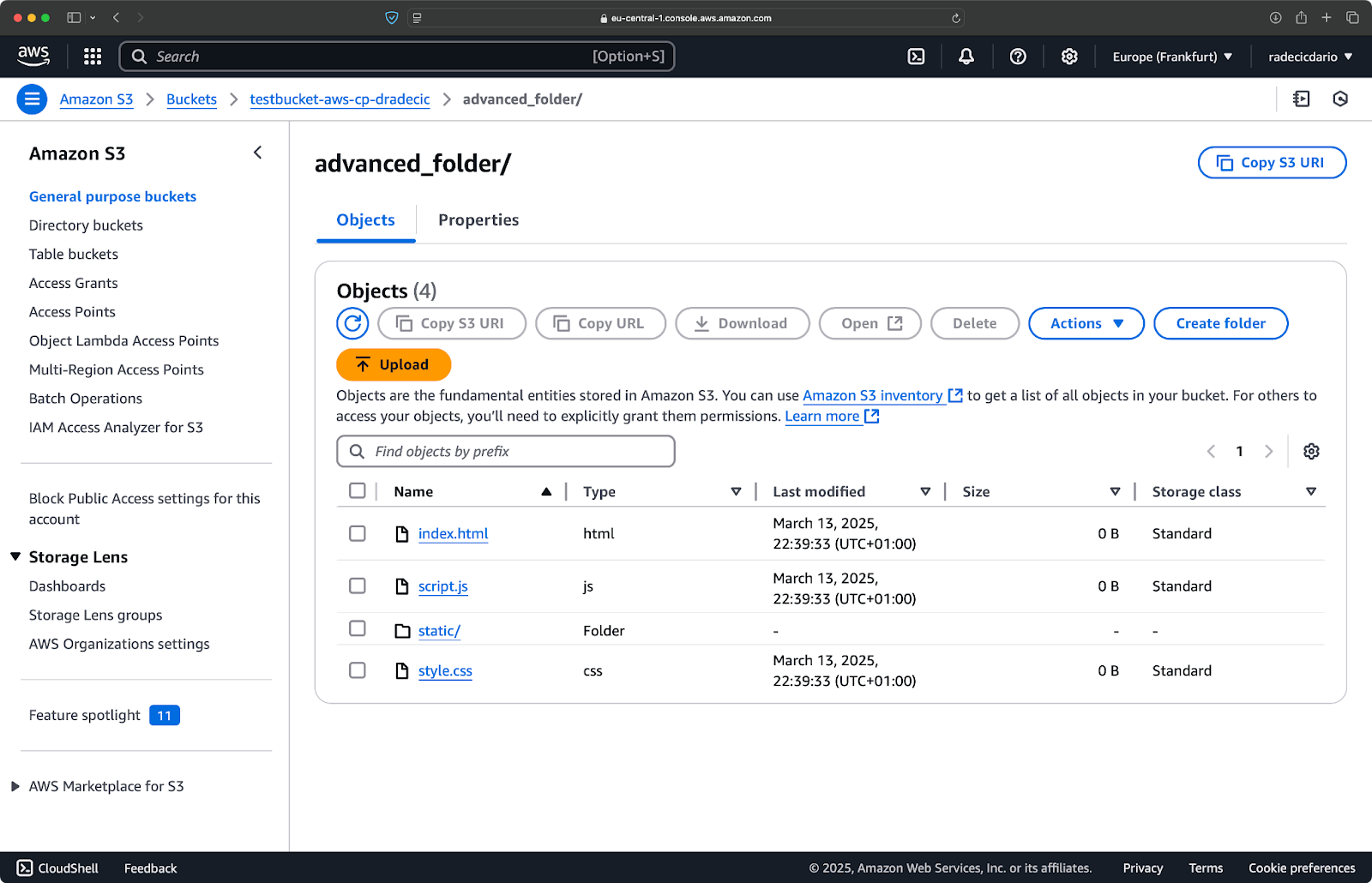
이미지 15 – 폴더 복사 결과
다중 패턴을 결합할 수도 있습니다. 프로젝트 폴더에서 HTML 및 CSS 파일만 복사하려는 경우를 생각해 봅시다:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exclude "*" --include "*.html" --include "*.css"
이 명령은 먼저 모든 것을 제외한 다음(--exclude "*"), .html 및 .css 확장자를 가진 파일만 포함합니다. 결과는 다음과 같습니다:
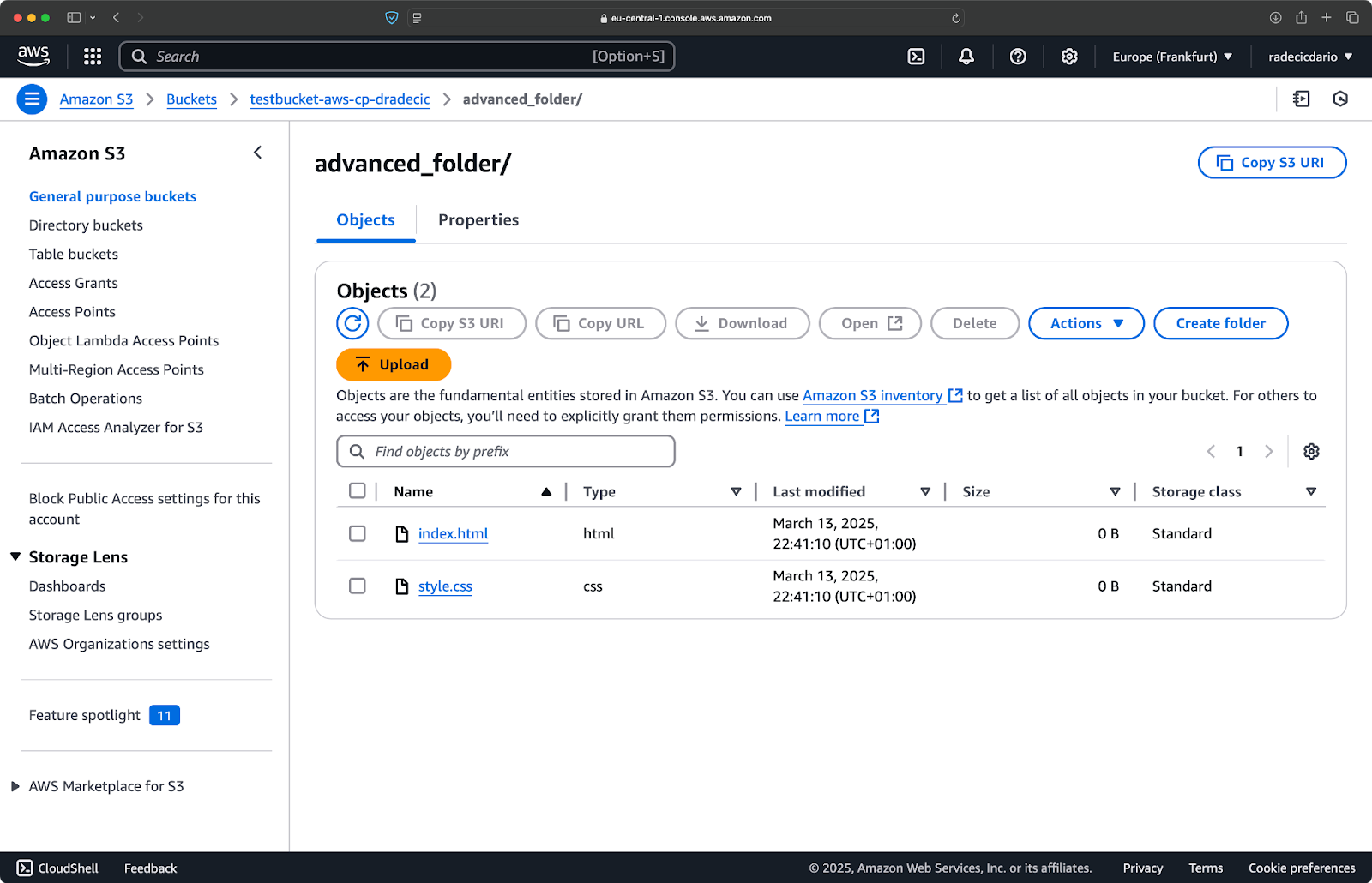
이미지 16 – 폴더 복사 결과 (2)
플래그의 순서가 중요하다는 점을 기억하세요 – AWS CLI는 이러한 플래그를 순차적으로 처리하므로 --exclude 앞에 --include를 놓으면 다른 결과가 나옵니다:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --include "*.html" --include "*.css" --exclude "*"
이번에는 버킷으로 아무 것도 복사되지 않았습니다:
이미지 17 – 폴더 복사 결과 (3)
S3 스토리지 클래스 지정
Amazon S3는 서로 다른 저장 클래스를 제공하며 각각 다른 비용과 검색 특성을 갖고 있습니다. 기본적으로 aws s3 cp는 파일을 표준 저장 클래스에 업로드하지만 --storage-class 플래그를 사용하여 다른 클래스를 지정할 수 있습니다:
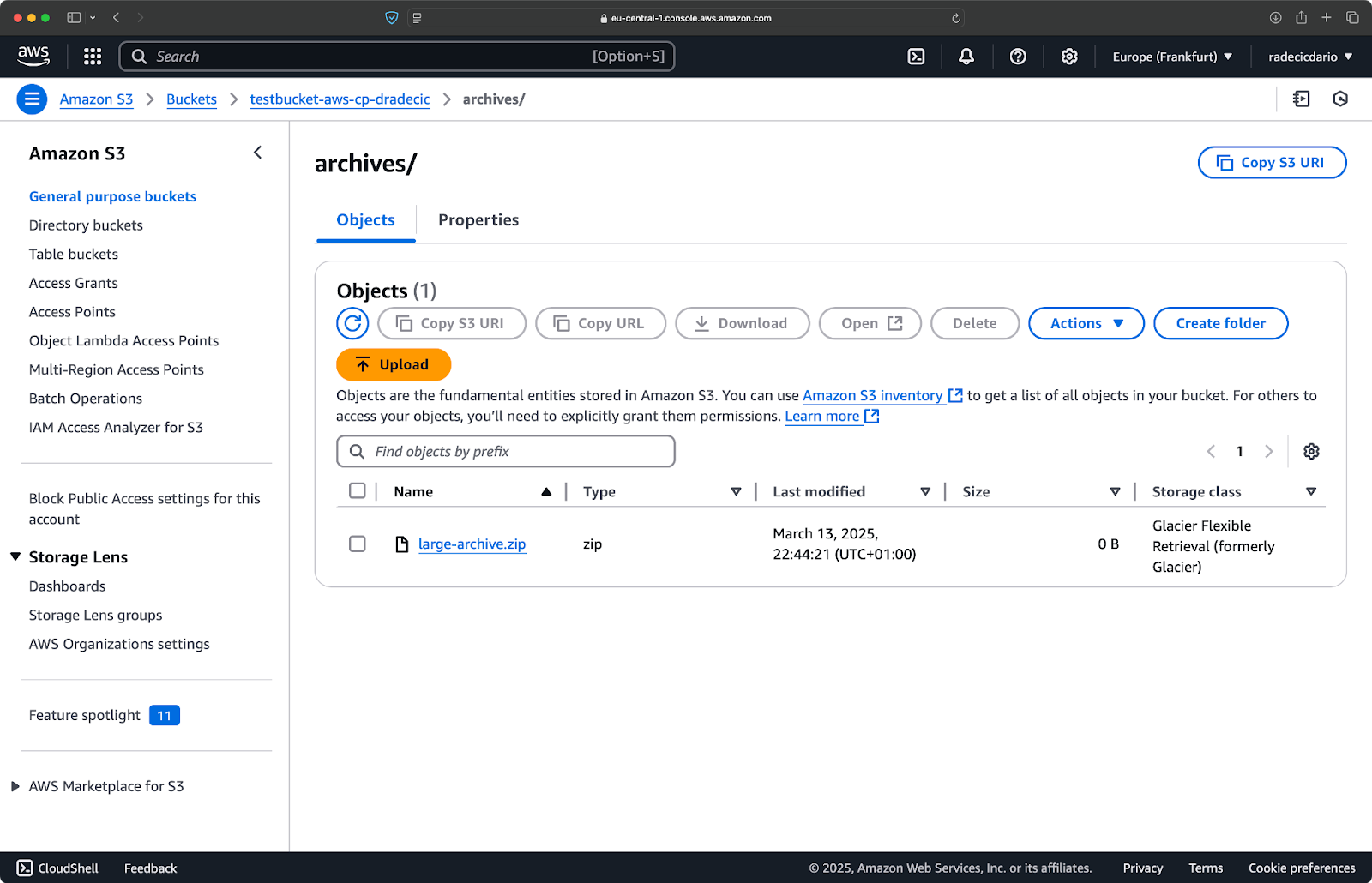
aws s3 cp /Users/dradecic/Desktop/large-archive.zip s3://testbucket-aws-cp-dradecic/archives/ --storage-class GLACIER
이 명령은 large-archive.zip을 크게 저렴하지만 검색 비용이 높고 검색 시간이 긴 Glacier 저장 클래스로 업로드합니다:
이미지 18 – 다른 저장 클래스로 파일을 S3에 복사
사용 가능한 저장 클래스는 다음과 같습니다:
STANDARD(기본값): 높은 내구성과 가용성을 갖는 일반용 저장소.REDUCED_REDUNDANCY(더 이상 권장되지 않음): 내구성이 낮고 비용 절감 옵션, 현재는 사용 중단됨.STANDARD_IA(적은 액세스): 덜 자주 액세스되는 데이터를 위한 저렴한 저장소.ONEZONE_IA(단일 존 적은 액세스): 단일 AWS 가용 영역 내에서의 저렴한, 적은 액세스 저장소.INTELLIGENT_TIERING: 액세스 패턴에 따라 데이터를 저장 계층간 이동하는 자동화 기능.GLACIER: 장기 보존을 위한 저렴한 아카이브 저장소, 몇 분에서 몇 시간 내에 검색 가능.DEEP_ARCHIVE: 가장 저렴한 아카이브 저장소, 몇 시간 내에 검색 가능, 장기 백업에 이상적.
즉시 액세스할 필요가 없는 파일을 백업하는 경우 GLACIER 또는 DEEP_ARCHIVE를 사용하면 상당한 저장 비용을 절약할 수 있습니다.
–exact-timestamps 플래그를 사용하여 파일 동기화
S3에 있는 파일을 업데이트할 때 이미 존재하는 파일을 복사하고 싶을 수 있습니다. --exact-timestamps 플래그는 소스와 대상 간의 타임스탬프를 비교하여 이를 돕습니다.
다음은 예시입니다:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exact-timestamps
이 플래그를 사용하면 명령이 S3에 이미 있는 파일과 타임스탬프가 다른 경우에만 파일을 복사합니다. 이는 많은 파일을 정기적으로 업데이트할 때 전송 시간과 대역폭 사용을 줄일 수 있습니다.
그래서 이것이 유용한 이유는 무엇일까요? 변경되지 않은 자산을 전송하지 않고 응용 프로그램 파일을 업데이트하려는 배포 시나리오를 상상해보세요.
--exact-timestamps 는 동기화를 수행하는 데 유용하지만 보다 정교한 해결책이 필요한 경우 aws s3 cp 대신 aws s3 sync을 사용하는 것을 고려해보세요. sync 명령은 디렉터리를 동기화하는 데 특별히 설계되었으며 이를 위한 추가 기능을 갖추고 있습니다. 저는 AWS S3 Sync 튜토리얼에서 sync 명령에 대해 모두 설명했습니다.
이러한 고급 옵션을 사용하면 이제 S3 파일 작업을 훨씬 더 정밀하게 제어할 수 있습니다. 특정 파일을 대상으로 지정하고 저장 비용을 최적화하며 파일을 효율적으로 업데이트할 수 있습니다. 다음 섹션에서는 이러한 작업을 스크립트와 예약된 작업을 사용하여 자동화하는 방법을 배우게 됩니다.
AWS S3 cp를 사용하여 파일 전송 자동화
지금까지 명령 줄을 사용하여 S3로 파일을 수동으로 복사하고 이동하는 방법을 배웠습니다. aws s3 cp를 사용하는 가장 큰 장점 중 하나는 이러한 전송을 쉽게 자동화할 수 있다는 것이며, 이를 통해 시간을 많이 절약할 수 있습니다.
aws s3 cp 명령을 스크립트와 예약 작업으로 통합하는 방법을 살펴보겠습니다.
스크립트에서 AWS S3 cp 사용
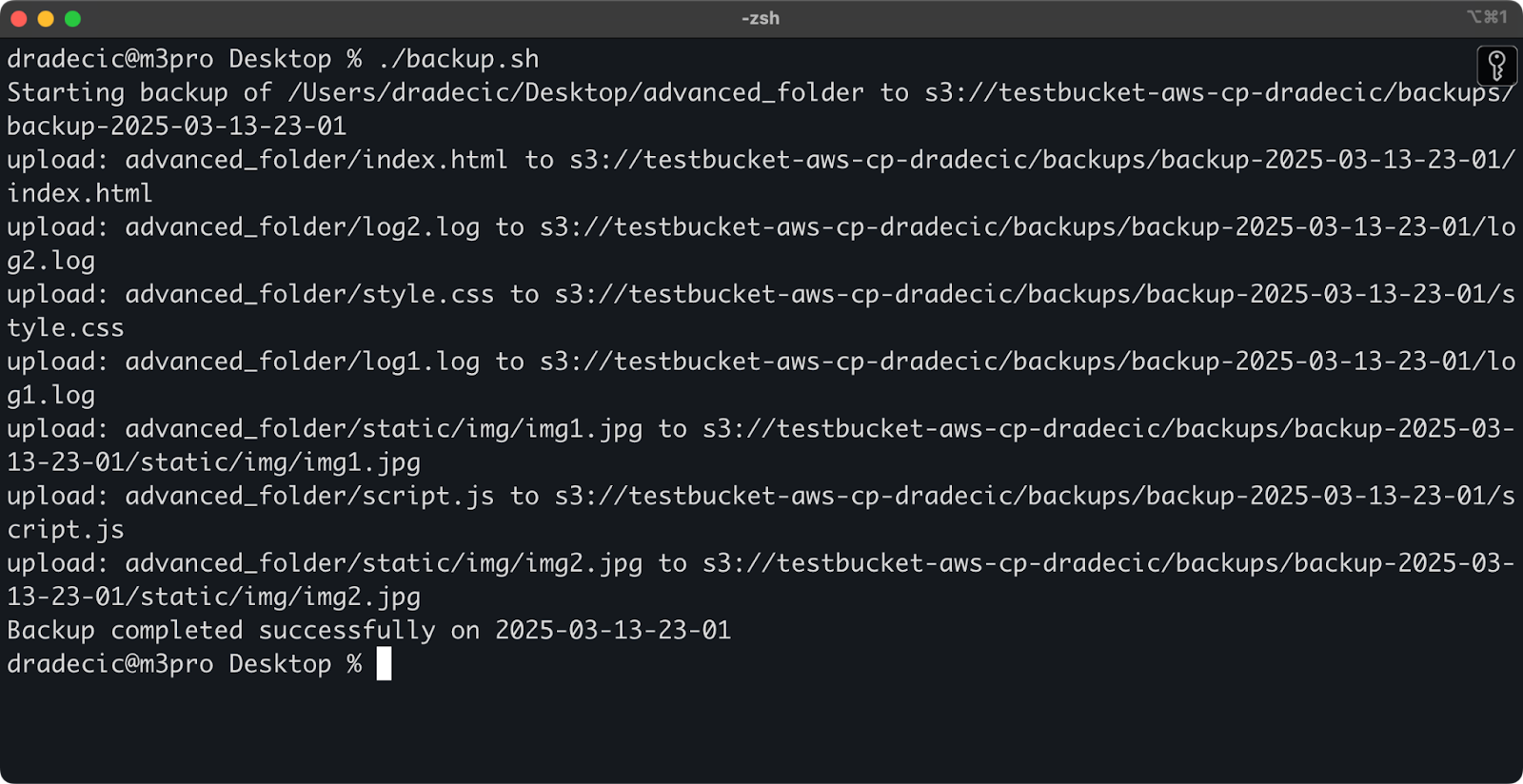
다음은 디렉토리를 S3로 백업하고 백업에 타임스탬프를 추가하며 오류 처리 및 로깅을 파일에 구현하는 간단한 bash 스크립트 예제입니다:
#!/bin/bash # 변수 설정 SOURCE_DIR="/Users/dradecic/Desktop/advanced_folder" BUCKET="s3://testbucket-aws-cp-dradecic/backups" DATE=$(date +%Y-%m-%d-%H-%M) BACKUP_NAME="backup-$DATE" LOG_FILE="/Users/dradecic/logs/s3-backup-$DATE.log" # 로그 디렉토리가 있는지 확인 mkdir -p "$(dirname "$LOG_FILE")" # 백업 생성 및 출력 로깅 echo "Starting backup of $SOURCE_DIR to $BUCKET/$BACKUP_NAME" | tee -a $LOG_FILE aws s3 cp $SOURCE_DIR $BUCKET/$BACKUP_NAME --recursive 2>&1 | tee -a $LOG_FILE # 백업이 성공적으로 이루어졌는지 확인 if [ $? -eq 0 ]; then echo "Backup completed successfully on $DATE" | tee -a $LOG_FILE else echo "Backup failed on $DATE" | tee -a $LOG_FILE fi
이를 backup.sh로 저장하고 chmod +x backup.sh로 실행 가능하게 만들면 재사용 가능한 백업 스크립트가 됩니다!
다음 명령을 사용하여 스크립트를 실행할 수 있습니다:
./backup.sh
이미지 19 – 터미널에서 실행되는 스크립트
즉시 버킷의 backups 폴더에 백업이 저장됩니다:
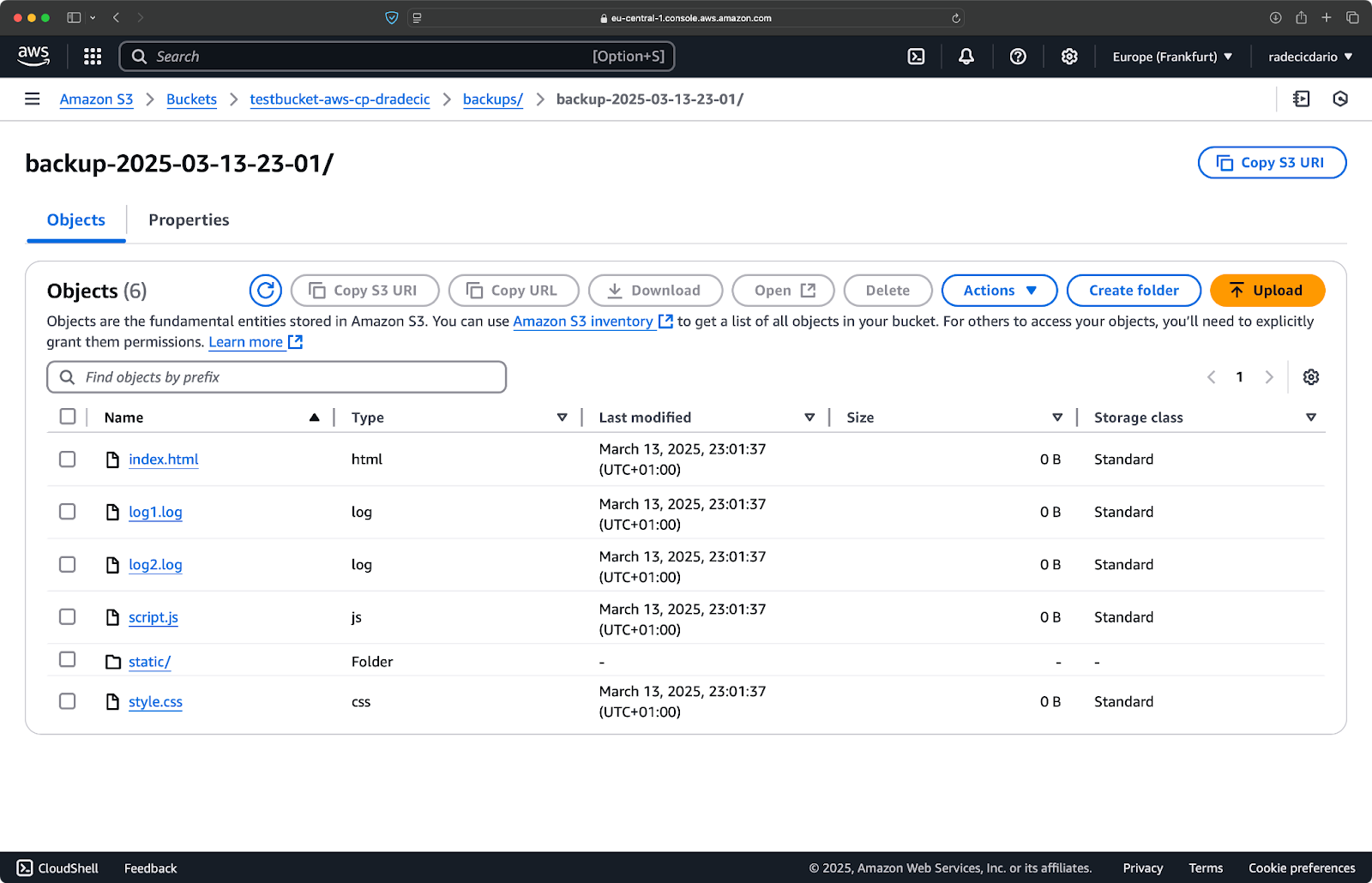
이미지 20 – S3 버킷에 저장된 백업
다음 단계는 스케줄에 맞춰 스크립트를 실행하도록 예약하는 것입니다.
cron 작업으로 파일 전송 예약
이제 스크립트가 준비되었으므로 다음 단계는 특정 시간에 자동으로 실행되도록 스케줄하는 것입니다.
만약 Linux 또는 macOS를 사용 중이라면 백업 일정을 예약하는 데 cron을 사용할 수 있습니다. 매일 자정에 백업 스크립트를 실행하는 cron 작업을 설정하는 방법은 다음과 같습니다:
1. crontab을 편집하려면 엽니다:
crontab -e
2. 매일 자정에 스크립트를 실행하는 다음 라인을 추가합니다:
0 0 * * * /path/to/your/backup.sh
이미지 21 – 매일 스크립트 실행을 위한 Cron 작업
Cron 작업 형식은 분 시 일 월 요일 명령입니다. 몇 가지 더 많은 예제는 다음과 같습니다:
- 매 시간 실행:
0 * * * * /path/to/your/backup.sh - 매주 월요일 오전 9시에 실행:
0 9 * * 1 /path/to/your/backup.sh - 매월 1일에 실행:
0 0 1 * * /path/to/your/backup.sh
이로써 끝입니다! 이제 backup.sh 스크립트가 예약된 간격으로 실행됩니다.
S3 파일 전송을 자동화하는 것이 좋습니다. 특히 다음과 같은 시나리오에 유용합니다:
- 중요 데이터의 매일 백업
- 제품 이미지를 웹사이트에 동기화
- 로그 파일을 장기 저장소로 이동
- 웹사이트 파일을 업데이트하여 배포
이러한 자동화 기술은 수동 개입 없이 파일 전송을 처리하는 안정적인 시스템을 구축하는 데 도움이 됩니다. 한 번 작성하기만 하면 그 후에는 잊어버리고 넘어갈 수 있습니다.
다음 섹션에서는 aws s3 cp 작업을 더 안전하고 효율적으로 수행하기 위한 몇 가지 모범 사례를 다룰 것입니다.
AWS S3 cp 사용의 모범 사례
‘aws s3 cp’ 명령어는 쉽게 사용할 수 있지만 문제가 발생할 수 있습니다.
최상의 방법을 따른다면 일반적인 함정을 피하고 성능을 최적화하며 데이터를 안전하게 유지할 수 있습니다. 파일 전송 작업을 더 효율적으로 만들기 위해 이러한 방법을 살펴보겠습니다.
효율적인 파일 관리
S3를 사용할 때 파일을 논리적으로 구성하면 향후 시간과 머리 아픔을 절약할 수 있습니다.
먼저, 일관된 버킷 및 접두사 명명 규칙을 설정하세요. 예를 들어, 환경, 애플리케이션 또는 날짜별로 데이터를 구분할 수 있습니다:
s3://company-backups/production/database/2023-03-13/ s3://company-backups/staging/uploads/2023-03/
이러한 종류의 조직은 다음을 쉽게 만듭니다:
- 필요할 때 특정 파일을 찾기
- 적절한 수준에서 버킷 정책 및 권한 적용
- 아카이빙하거나 이전 데이터를 삭제하기 위한 라이프사이클 규칙 설정
또 다른 팁: 큰 파일 세트를 전송할 때 먼저 작은 파일을 그룹화하여 (zip 또는 tar를 사용하여) 업로드하는 것을 고려하십시오. 이렇게 하면 S3로의 API 호출 수가 줄어들어 비용을 낮출 수 있고 전송 속도를 높일 수 있습니다.
# 수천 개의 작은 로그 파일을 복사하는 대신 # 먼저 tar하여 업로드하십시오 tar -czf example-logs-2025-03.tar.gz /var/log/application/ aws s3 cp example-logs-2025-03.tar.gz s3://testbucket-aws-cp-dradecic/logs/2025/03/
대규모 데이터 전송 처리
대형 파일이나 여러 파일을 한꺼번에 복사할 때, 프로세스를 더 신뢰할 수 있고 효율적으로 만드는 몇 가지 기술이 있습니다.
스크립트에서 실행할 때 --quiet 플래그를 사용할 수 있습니다:출력을 줄입니다 :
aws s3 cp large-directory/ s3://testbucket-aws-cp-dradecic/backups/ --recursive --quiet
각 파일의 진행 정보를 억제하여 로그를 더 관리하기 쉽게 만들고 성능도 약간 향상시킵니다.
매우 큰 파일의 경우, 멀티파트 업로드를 고려해보세요. --multipart-threshold 플래그를 사용하세요:
aws s3 cp huge-file.iso s3://testbucket-aws-cp-dradecic/backups/ --multipart-threshold 100MB
위 설정은 AWS CLI에게 100MB보다 큰 파일을 여러 부분으로 분할하여 업로드하도록 지시합니다. 이렇게 하는 것에는 몇 가지 이점이 있습니다:
- 연결이 끊기면 영향을 받는 부분만 다시 시도하면 됩니다.
- 부품은 병렬로 업로드될 수 있어 처리량을 증가시킬 수 있습니다.
- 대용량 업로드를 일시 중지하고 다시 시작할 수 있습니다.
지역 간 데이터 전송시에는 빠른 업로드를 위해 S3 전송 가속을 고려해보세요:
aws s3 cp large-file.zip s3://testbucket-aws-cp-dradecic/backups/ --endpoint-url https://s3-accelerate.amazonaws.com
위 방법은 전송을 아마존의 엣지 네트워크를 통해 라우팅하여 지역 간 전송 속도를 크게 향상시킬 수 있습니다.
보안 보장
클라우드에서 데이터를 다룰 때 보안은 항상 최우선 과제여야 합니다.
먼저 IAM 권한이 최소 권한의 원칙을 따르는지 확인하십시오.각 작업에 필요한 구체적인 권한만 부여하십시오.
다음은 사용자에게 할당할 수 있는 예시 정책입니다:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject" ], "Resource": "arn:aws:s3:::testbucket-aws-cp-dradecic/backups/*" } ] }
해당 정책은 “my-bucket”의 “backups” 접두사로만 파일을 복사할 수 있게 합니다.
보안을 높이는 추가적인 방법은 민감한 데이터에 대한 암호화를 활성화하는 것입니다. 업로드 시 서버 측 암호화를 지정할 수 있습니다:
aws s3 cp confidential.docx s3://testbucket-aws-cp-dradecic/ --sse AES256
또는 보다 안전한 경우에는 AWS 키 관리 서비스(KMS)를 사용합니다:
aws s3 cp secret-data.json s3://testbucket-aws-cp-dradecic/ --sse aws:kms --sse-kms-key-id myKMSKeyId
그러나 매우 민감한 작업의 경우에는 S3용 VPC 엔드포인트를 사용하는 것이 좋습니다. 이렇게 하면 교통이 AWS 네트워크 내에서 유지되고 완전히 공개 인터넷을 피할 수 있습니다.
다음 섹션에서는이 명령을 사용할 때 마주치는 일반적인 문제를 해결하는 방법을 배우게 됩니다.
AWS S3 cp 오류 해결
한 가지 확실한 것은 aws s3 cp를 사용할 때 가끔 문제에 부딪힐 것이라는 것입니다. 그러나 일반적인 오류와 그 해결책을 이해하면 계획대로 되지 않을 때 시간과 불편함을 절약할 수 있습니다.
이 섹션에서는 가장 빈번한 문제와 그 해결 방법을 안내해 드리겠습니다.
일반적인 오류 및 해결책
Error: “Access Denied”
가장 흔히 마주치게 되는 오류 중 하나일 것입니다:
upload failed: ./myfile.txt to s3://testbucket-aws-cp-dradecic/myfile.txt An error occurred (AccessDenied) when calling the PutObject operation: Access Denied
이는 일반적으로 세 가지 사항 중 하나를 의미합니다:
- 당신의 IAM 사용자는 작업을 수행할 충분한 권한이 없습니다.
- 버킷 정책이 액세스를 제한하고 있습니다.
- AWS 자격 증명이 만료되었습니다.
문제 해결 방법:
s3:PutObject(업로드용) 또는s3:GetObject(다운로드용) 권한이 필요한지 확인하려면 IAM 권한을 확인하세요.- 버킷 정책이 작업을 제한하지 않는지 확인하세요.
- 만료된 경우 자격 증명을 업데이트하려면
aws configure를 실행하세요.
Error: “No such file or directory”
이 오류는 복사하려는 로컬 파일 또는 디렉토리가 존재하지 않을 때 발생합니다:
upload failed: ./missing-file.txt to s3://testbucket-aws-cp-dradecic/missing-file.txt An error occurred (404) when calling the PutObject operation: Not Found
문제 해결 방법은 간단합니다 – 파일 경로를 주의 깊게 확인하세요. 경로는 대소문자를 구분하므로 이 점을 염두에 두세요. 또한 상대 경로를 사용할 때 올바른 디렉토리에 있는지 확인하세요.
Error: “The specified bucket does not exist”
이 오류가 표시되는 경우:
upload failed: ./myfile.txt to s3://testbucket-aws-cp-dradecic/myfile.txt An error occurred (NoSuchBucket) when calling the PutObject operation: The specified bucket does not exist
다음을 확인하세요:
- 버킷 이름에 오타가 있는지 확인하세요.
- 올바른 AWS 지역을 사용하고 있는지 확인합니다.
- 버킷이 실제로 존재하는지 확인합니다(이미 삭제되었을 수도 있습니다).
올바른 이름을 확인하려면 aws s3 ls를 사용하여 모든 버킷을 나열할 수 있습니다.
에러: “연결 시간 초과”
네트워크 문제로 연결 시간 초과가 발생할 수 있습니다:
upload failed: ./largefile.zip to s3://testbucket-aws-cp-dradecic/largefile.zip An error occurred (RequestTimeout) when calling the PutObject operation: Request timeout
이를 해결하려면:
- 인터넷 연결 상태를 확인합니다.
- 더 작은 파일을 사용하거나 대용량 파일의 경우 멀티파트 업로드를 활성화해 보세요.
- 더 나은 성능을 위해 AWS Transfer Acceleration을 사용해 보세요.
업로드 실패 처리
대용량 파일을 전송할 때 오류가 발생할 가능성이 훨씬 높습니다. 그런 경우, 실패를 원만하게 처리하려고 노력해 보세요.
예를 들어, 스크립트에서 오류 진단을 쉽게하기 위해 --only-show-errors 플래그를 사용할 수 있습니다:
aws s3 cp large-directory/ s3://testbucket-aws-cp-dradecic/ --recursive --only-show-errors
이렇게 하면 성공적인 전송 메시지를 억제하고 오류만 표시하여 대용량 전송의 문제 해결이 훨씬 쉬워집니다.
전송 중단을 처리하기 위해 --recursive 명령은 대상에 이미 동일한 크기의 파일이 있는 경우 자동으로 건너뜁니다. 그러나 더 철저하게 하려면AWS CLI의 내장 재시도를 사용하여 네트워크 문제에 대비하기 위해 환경 변수를 설정할 수 있습니다:
export AWS_RETRY_MODE=standard export AWS_MAX_ATTEMPTS=5 aws s3 cp large-file.zip s3://testbucket-aws-cp-dradecic/
이렇게 하면 AWS CLI가 작업 실패를 최대 5회 자동으로 재시도하도록 지시합니다.
그러나 매우 큰 데이터셋의 경우 cp 대신 aws s3 sync을 사용하는 것이 좋습니다. 이는 중단을 더 잘 처리할 수 있도록 설계되었습니다:
aws s3 sync large-directory/ s3://testbucket-aws-cp-dradecic/large-directory/
sync 명령은 대상에 이미 있는 파일과 다른 파일만 전송하므로, 중단된 대규모 전송을 다시 시작하는 데 완벽합니다.
이러한 일반적인 오류를 이해하고 스크립트에 적절한 오류 처리를 구현하면, S3 복사 작업을 훨씬 견고하고 안정적으로 만들 수 있습니다.
AWS S3 cp를 요약하면
결론적으로, aws s3 cp 명령은 로컬 파일을 S3로 복사하거나 그 반대로 복사하는 데 한 번에 처리할 수 있는 솔루션입니다.
이 글에서 이 모든 것을 배웠습니다. 기초 지식과 환경 구성에서 시작하여 파일 복사를 위한 예약 및 자동화된 스크립트 작성으로 마무리했습니다. 또한 특히 대용량 파일을 이동할 때 발생하는 일반적인 오류와 문제에 대한 대처 방법도 배웠습니다.
따라서, 개발자, 데이터 전문가 또는 시스템 관리자이면이 명령을 유용하게 사용할 수 있을 것으로 생각됩니다. 편안하게 사용하려면 정기적으로 사용하는 것이 가장 좋습니다. 기본 원칙을 이해하고 직업의 지루한 부분을 자동화하는 데 시간을 투자하십시오.
AWS에 대해 더 알아보려면 DataCamp의 다음 강좌를 따르십시오:
DataCamp을 사용하여 AWS 자격증 시험 준비도 할 수 있습니다 – AWS 클라우드 실무자 (CLF-C02).