













Configurando el AWS CLI y AWS S3
Antes de sumergirte en el comando aws s3 cp, necesitas tener AWS CLI instalado y correctamente configurado en tu sistema. No te preocupes si nunca has trabajado con AWS antes: el proceso de configuración es fácil y debería tardar menos de 10 minutos.
Dividiré esto en tres fases simples: instalar la herramienta AWS CLI, configurar tus credenciales y crear tu primer bucket S3 para almacenamiento.
Instalando el AWS CLI
El proceso de instalación varía ligeramente según el sistema operativo que estés utilizando.
Para sistemas Windows:
- Navega a la página de documentación oficial de AWS CLI
- Descarga el instalador de 64 bits para Windows
- Ejecuta el archivo descargado y sigue el asistente de instalación
Para sistemas Linux:
Ejecuta los siguientes tres comandos a través de la Terminal:
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" unzip awscliv2.zip sudo ./aws/install
Para sistemas macOS:
Suponiendo que tienes Homebrew instalado, ejecuta esta línea en la Terminal:
brew install awscli
Si no tienes Homebrew, usa estos dos comandos en su lugar:
curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg" sudo installer -pkg AWSCLIV2.pkg -target /
Para confirmar una instalación exitosa, ejecuta aws --version en tu terminal. Deberías ver algo como esto:
Imagen 1 – Versión de AWS CLI
Configurando el AWS CLI
Con el CLI instalado, es hora de configurar tus credenciales de AWS para la autenticación.
Primero, accede a tu cuenta de AWS y navega al panel de servicio IAM. Crea un nuevo usuario con acceso programático y adjunta la política de permisos adecuada para S3:
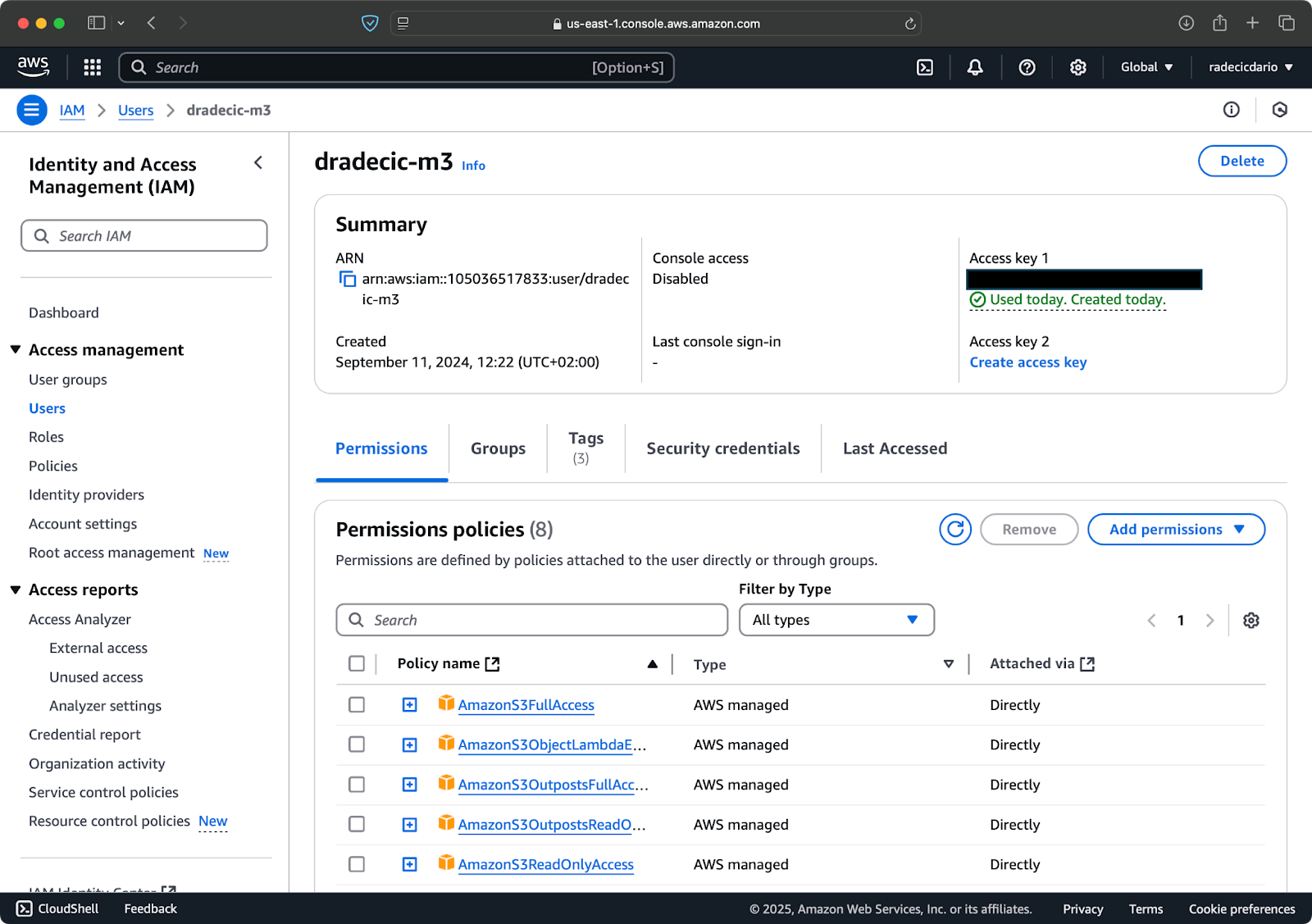
Imagen 2 – Usuario de AWS IAM
Luego, visita la pestaña “Credenciales de seguridad” y genera un nuevo par de claves de acceso. Asegúrate de guardar tanto el ID de clave de acceso como la clave de acceso secreta en un lugar seguro; Amazon no te mostrará la clave secreta nuevamente después de esta pantalla:
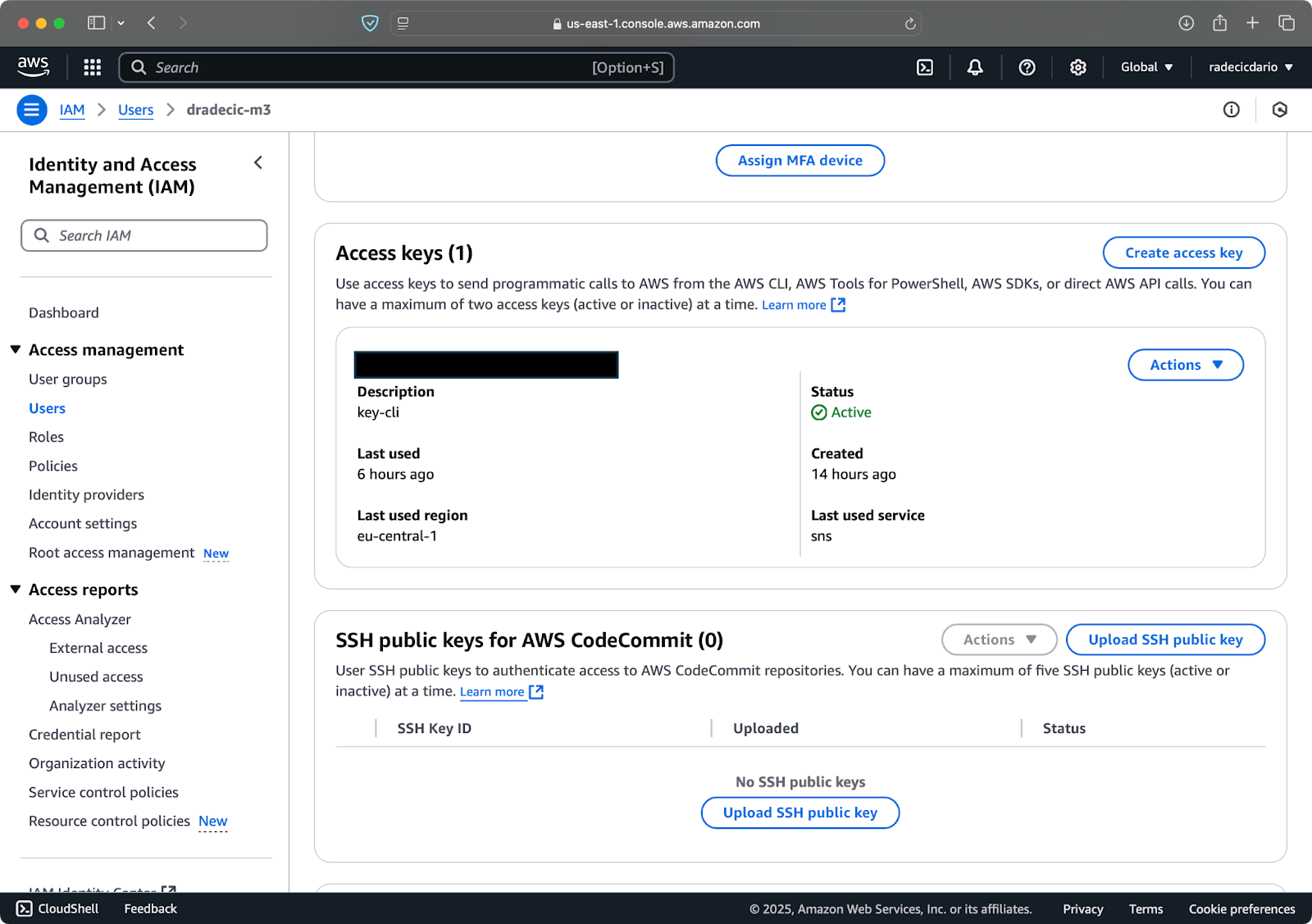
Imagen 3 – Credenciales del usuario de AWS IAM
Ahora abre tu terminal y ejecuta el comando aws configure. Se te pedirán cuatro piezas de información: tu ID de clave de acceso, clave de acceso secreta, región predeterminada (estoy utilizando eu-central-1), y formato de salida preferido (típicamente json):
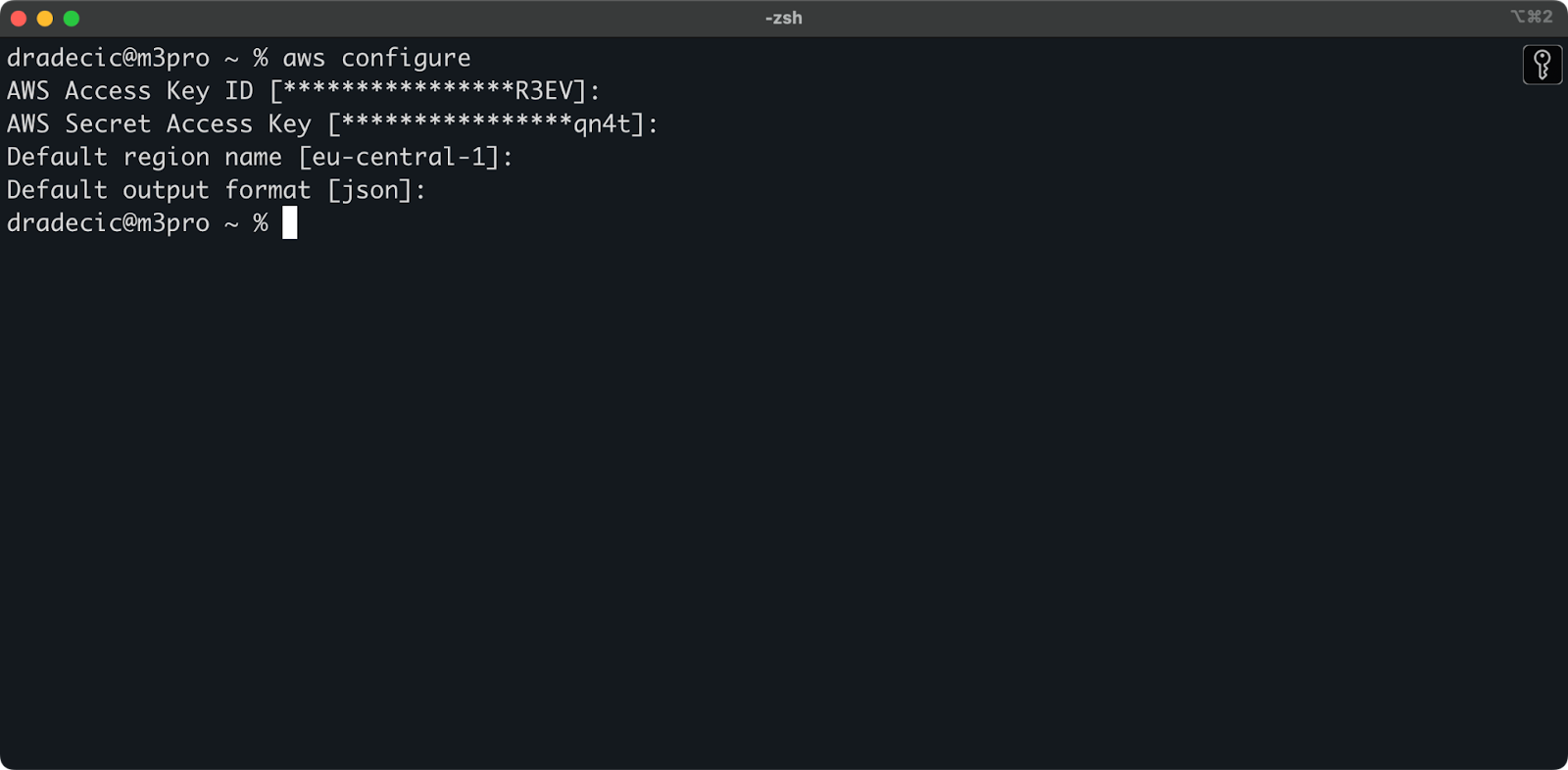
Imagen 4 – Configuración de AWS CLI
Para asegurarte de que todo esté conectado correctamente, verifica tu identidad con el siguiente comando:
aws sts get-caller-identity
Si está configurado correctamente, verás los detalles de tu cuenta:
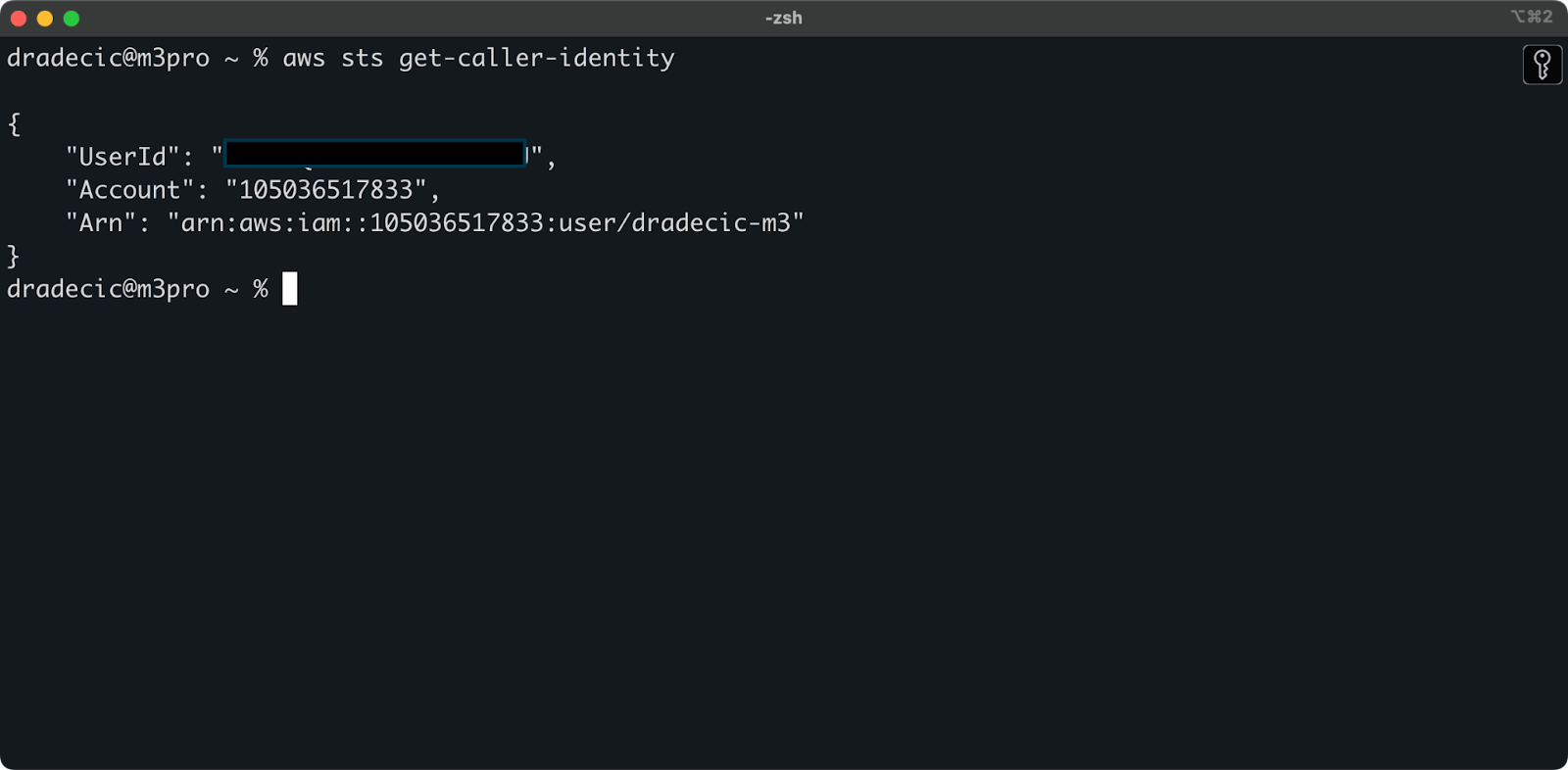
Imagen 5 – Comando de prueba de conexión de AWS CLI
Creando un cubo S3
Finalmente, necesitas crear un cubo S3 para almacenar los archivos que vas a copiar.
Dirígete a la sección de servicios de S3 en tu Consola de AWS y haz clic en “Crear cubo”. Recuerda que los nombres de los cubos deben ser globalmente únicos en todo AWS. Elige un nombre distintivo, deja la configuración predeterminada por ahora, y haz clic en “Crear”:
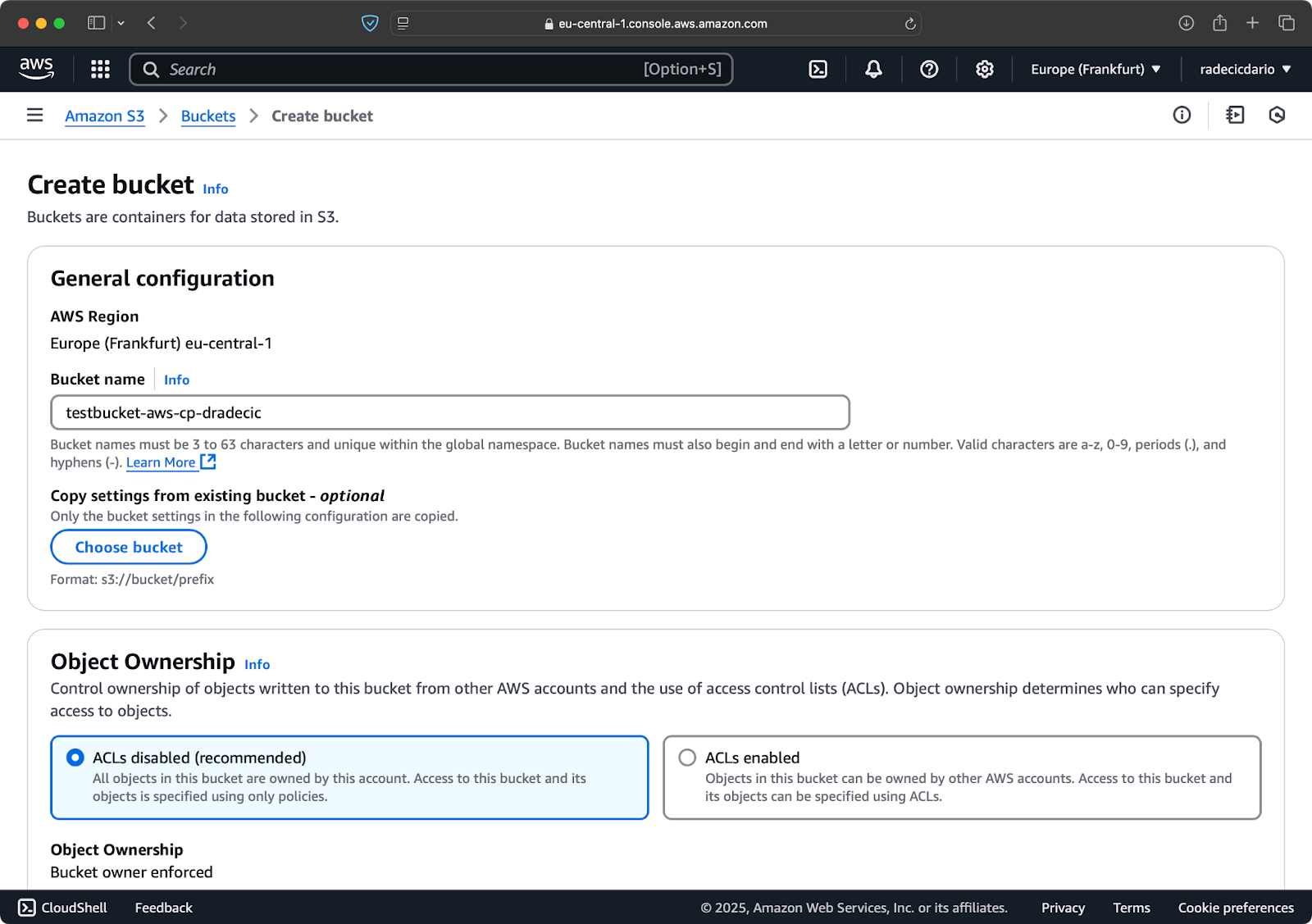
Imagen 6 – Creación de cubo AWS
Una vez creado, tu nuevo cubo aparecerá en la consola. También puedes confirmar su existencia a través de la línea de comandos:
aws s3 ls
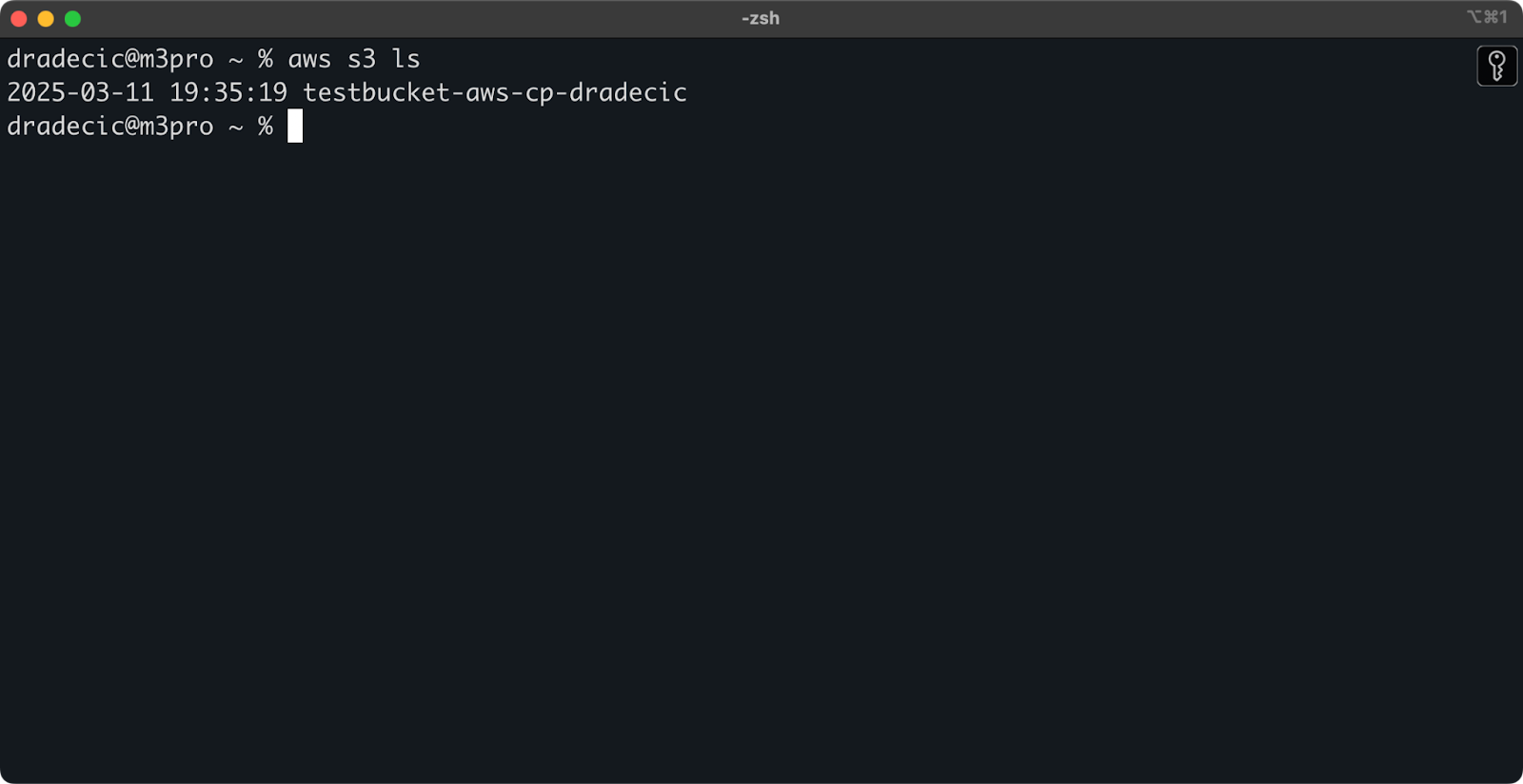
Imagen 7 – Todos los cubos S3 disponibles
Todos los cubos S3 están configurados como privados de forma predeterminada, así que tenlo en cuenta. Si tienes la intención de usar este cubo para archivos de acceso público, deberás modificar las políticas del cubo en consecuencia.
Ahora estás completamente equipado para comenzar a usar el comando aws s3 cp para transferir archivos. Veamos los conceptos básicos a continuación.
Sintaxis básica del comando AWS S3 cp
Ahora que tienes todo configurado, sumerjámonos en el uso básico del comando aws s3 cp. Como es habitual con AWS, la belleza radica en la simplicidad, aunque el comando pueda manejar diferentes escenarios de transferencia de archivos.
En su forma más básica, el comando aws s3 cp sigue esta sintaxis:
aws s3 cp <source> <destination> [options]
Donde <source> y <destination> pueden ser rutas de archivos locales o URIs de S3 (que comienzan con s3://). Exploremos los tres casos de uso más comunes.
Copiando un archivo desde local a S3
Para copiar un archivo desde tu sistema local a un bucket de S3, la fuente será una ruta local y el destino será un URI de S3:
aws s3 cp /Users/dradecic/Desktop/test_file.txt s3://testbucket-aws-cp-dradecic/test_file.txt
Este comando sube el archivo test_file.txt desde el directorio proporcionado al bucket de S3 especificado. Si la operación es exitosa, verás una salida en la consola como esta:
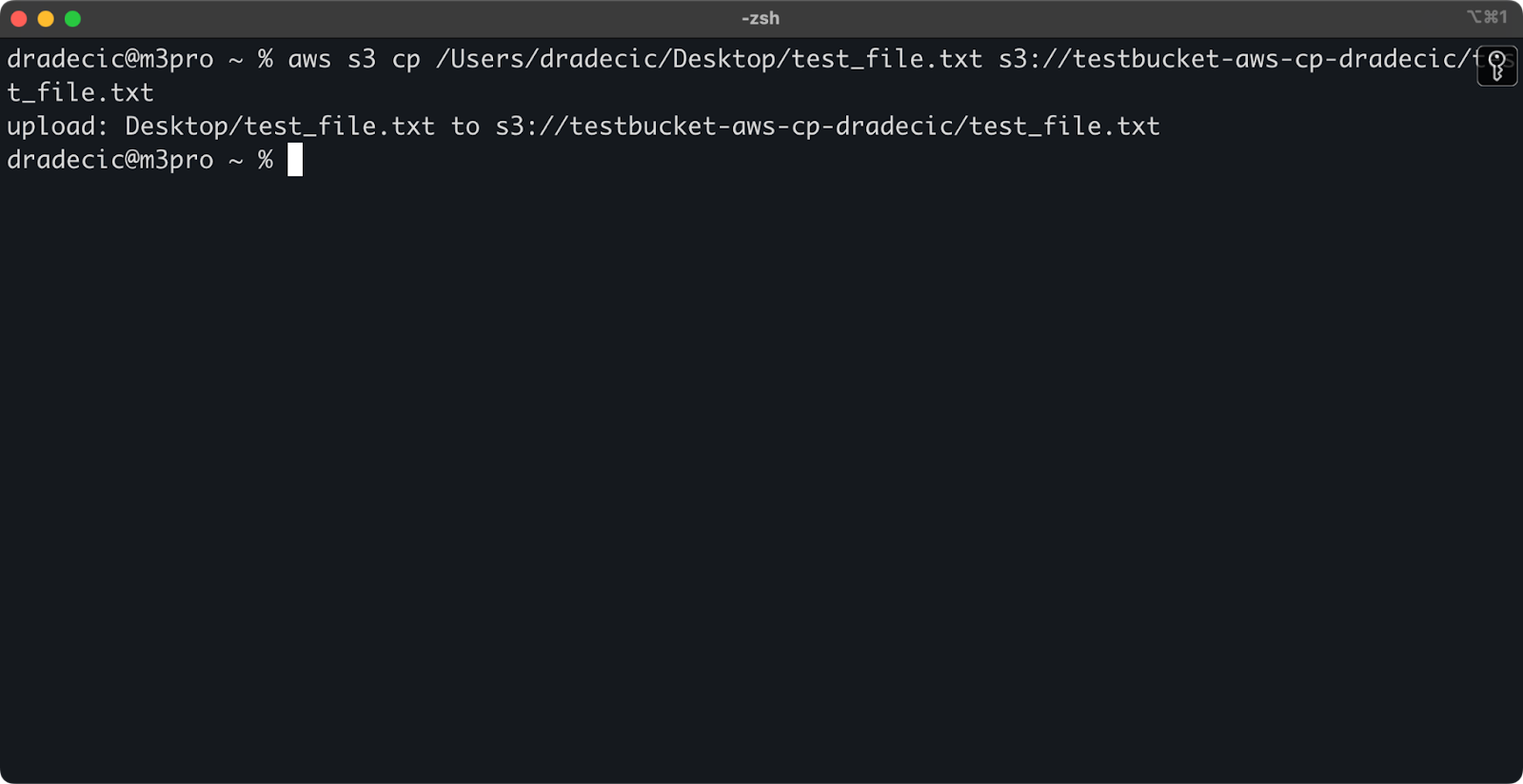
Imagen 8 – Salida en la consola después de copiar el archivo local
Y, en la consola de administración de AWS, verás tu archivo subido:
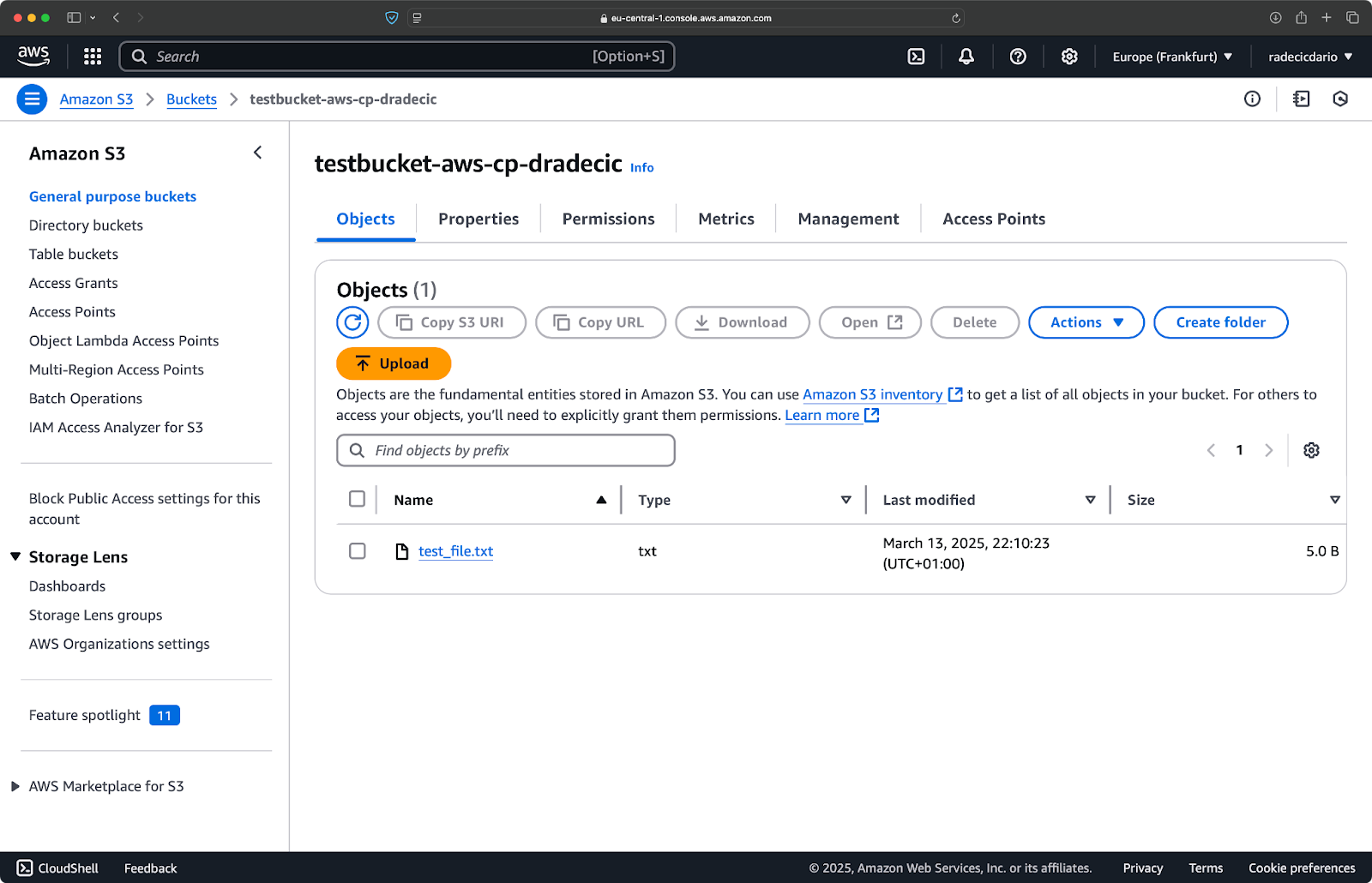
Imagen 9 – Contenidos del bucket de S3
De manera similar, si deseas copiar una carpeta local a tu bucket de S3 y colocarla, digamos, en otra carpeta anidada, ejecuta un comando similar a este:
aws s3 cp /Users/dradecic/Desktop/test_folder s3://testbucket-aws-cp-dradecic/my-desired-folder/test_folder/ --recursive
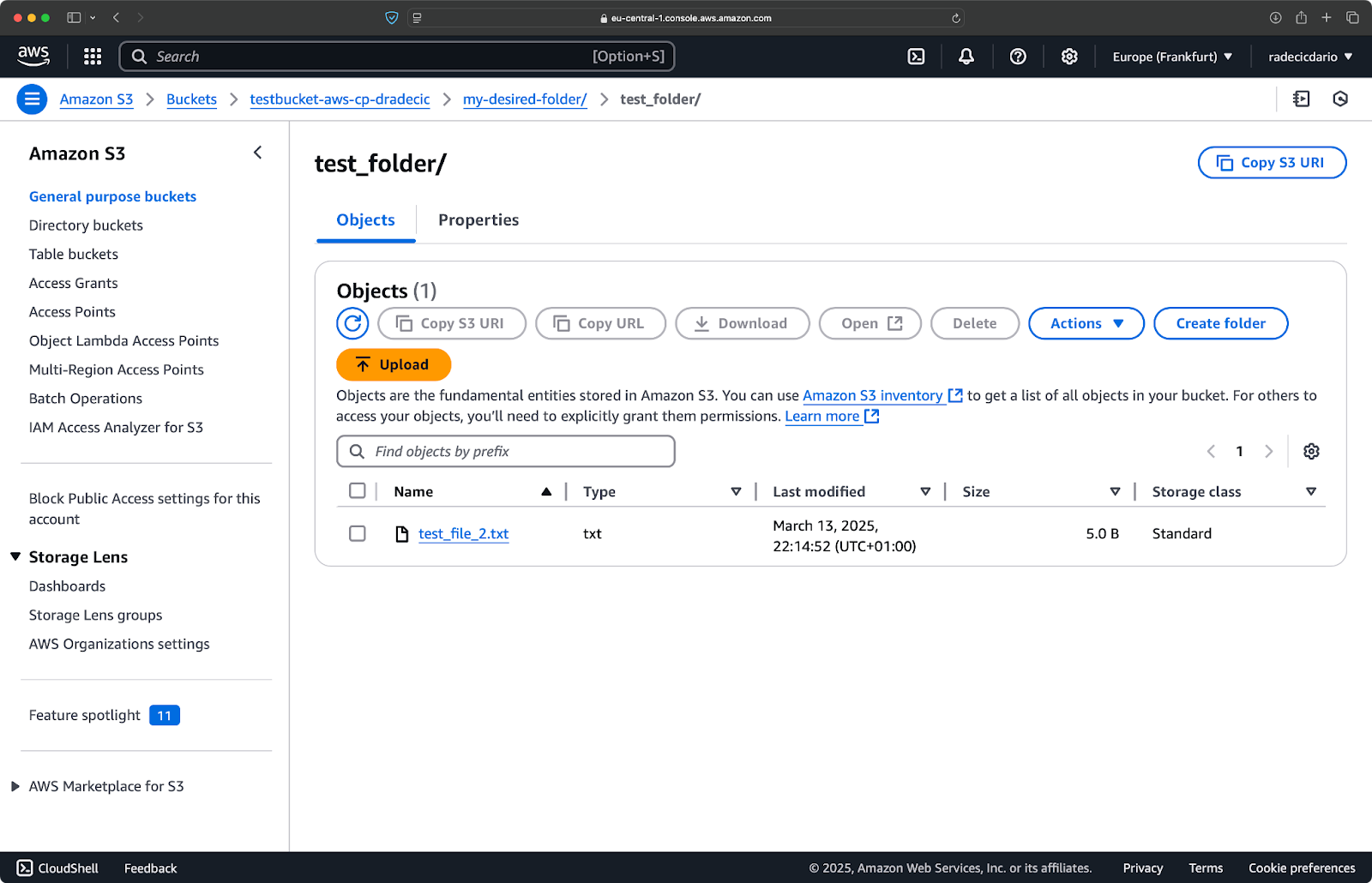
Imagen 10 – Contenidos del bucket de S3 después de subir una carpeta
La bandera --recursive se asegurará de que se copien todos los archivos y subcarpetas dentro de la carpeta.
Ten en cuenta – S3 en realidad no tiene carpetas, la estructura de la ruta es parte de la clave del objeto, pero funciona conceptualmente como carpetas.
Copiando un archivo desde S3 a local
Para copiar un archivo de S3 a tu sistema local, simplemente invierte el orden: la fuente se convierte en la URI de S3 y el destino es tu ruta local:
aws s3 cp s3://testbucket-aws-cp-dradecic/test_file.txt /Users/dradecic/Documents/s3-data/downloaded_test_file.txt
Este comando descarga test_file.txt desde tu bucket de S3 y lo guarda como downloaded_test_file.txt en el directorio proporcionado. Lo verás inmediatamente en tu sistema local:
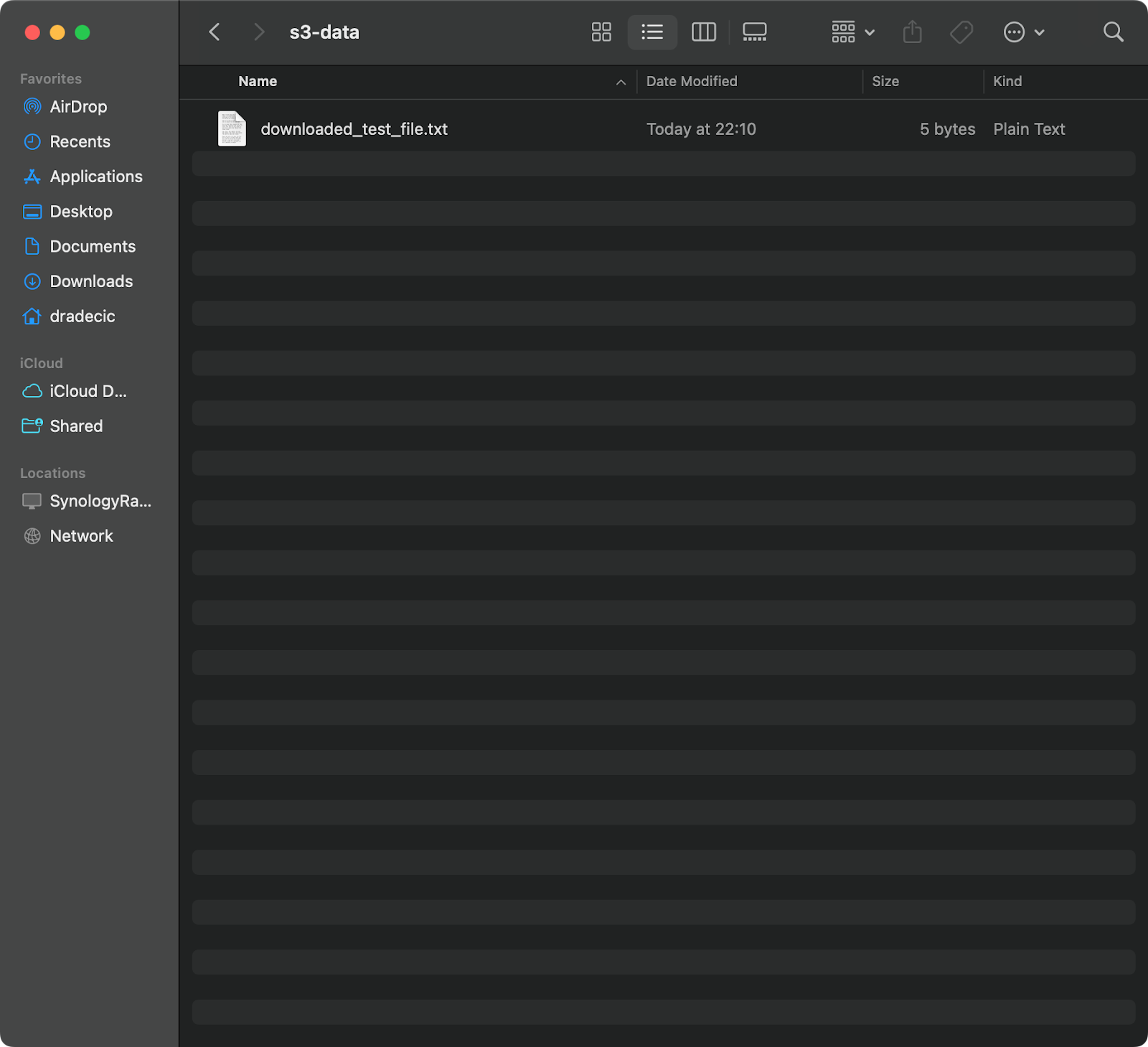
Imagen 11 – Descargando un solo archivo de S3
Si omites el nombre del archivo de destino, el comando usará el nombre de archivo original:
aws s3 cp s3://testbucket-aws-cp-dradecic/test_file.txt .
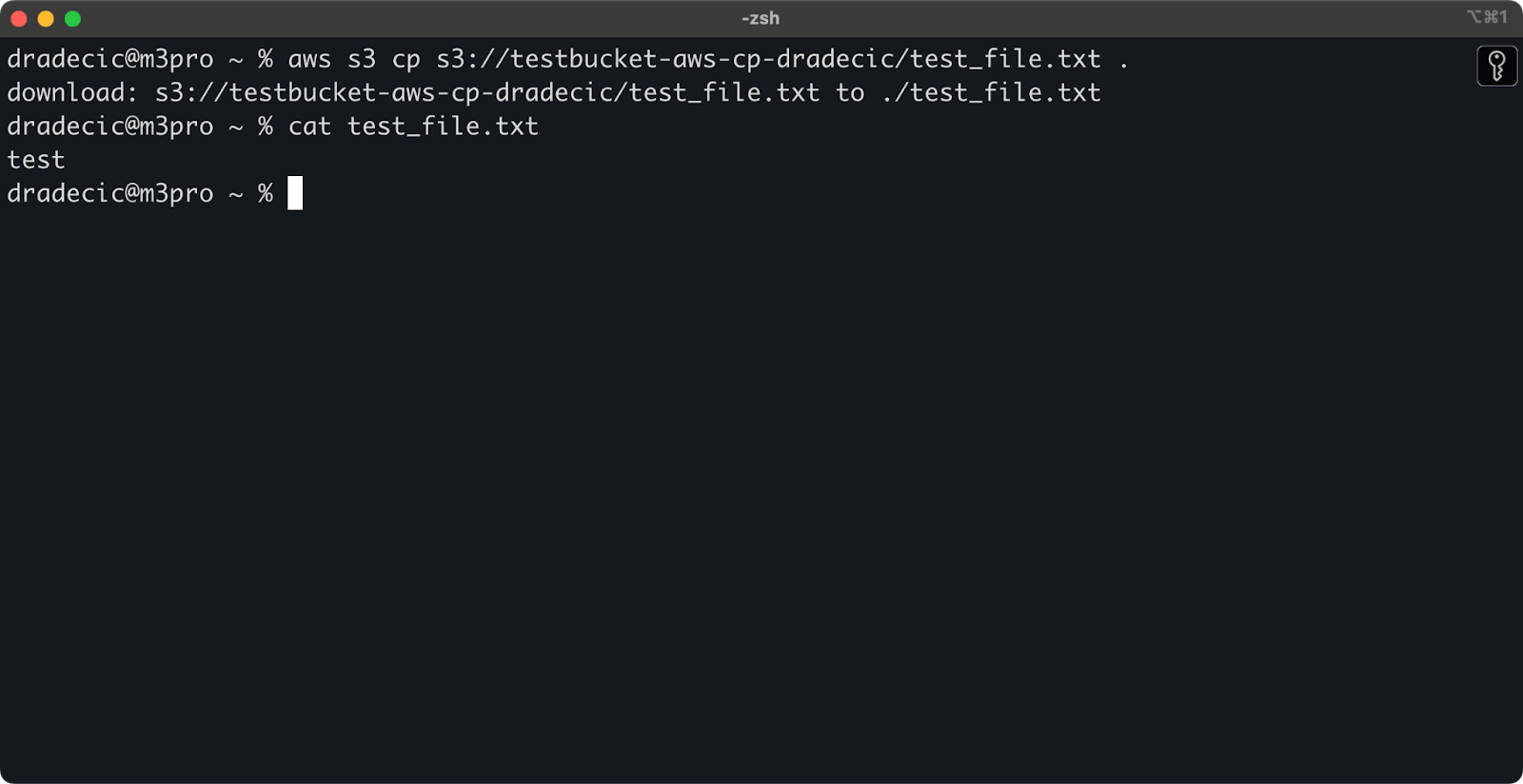
Imagen 12 – Contenido del archivo descargado
El punto (.) representa tu directorio actual, por lo que esto descargará test_file.txt a tu ubicación actual.
Y finalmente, para descargar un directorio completo, puedes usar un comando similar a este:
aws s3 cp s3://testbucket-aws-cp-dradecic/my-desired-folder/test_folder /Users/dradecic/Documents/test_folder --recursive
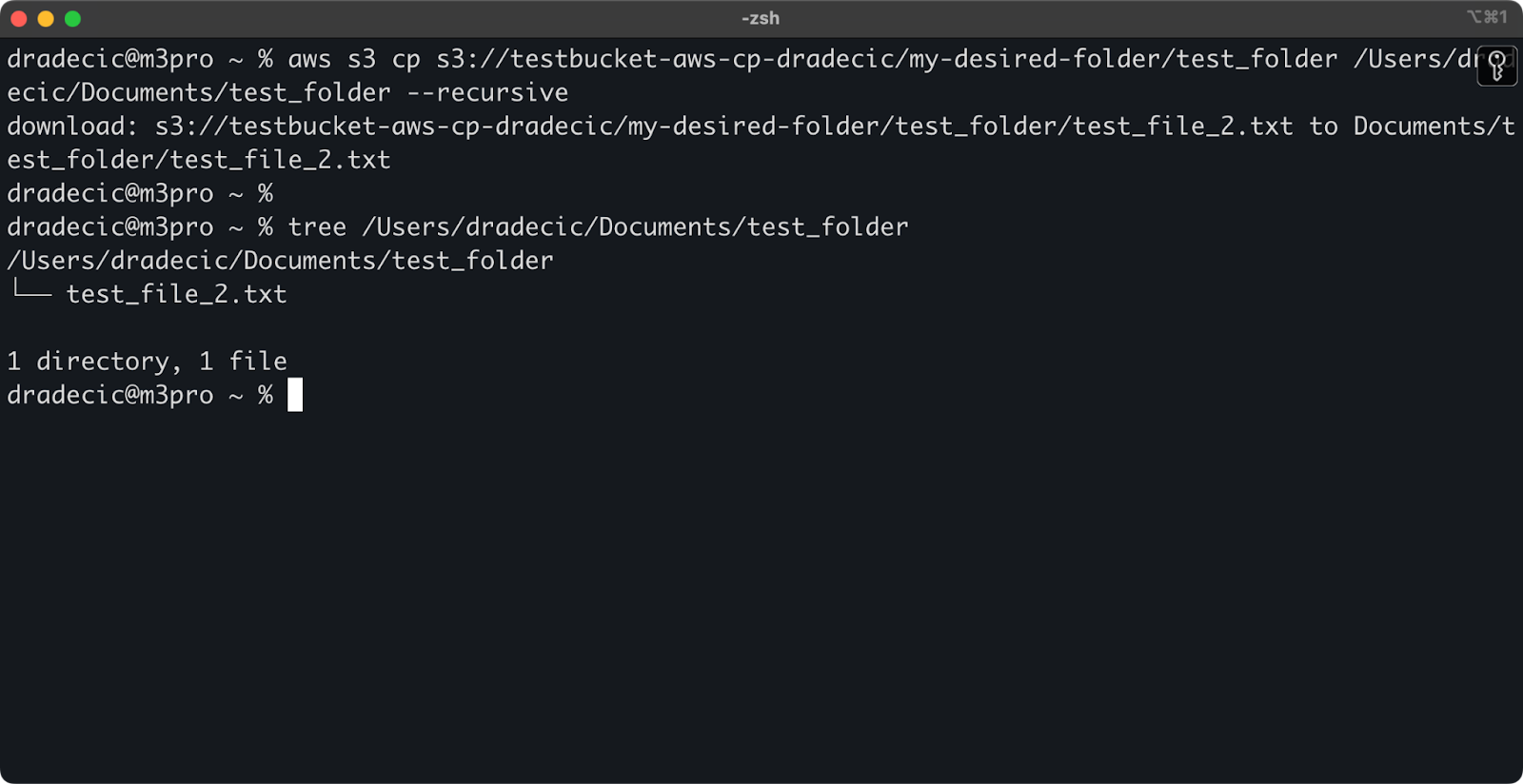
Imagen 13 – Contenido de la carpeta descargada
Ten en cuenta que la bandera --recursive es esencial al trabajar con varios archivos; sin ella, el comando fallará si la fuente es un directorio.
Con estos comandos básicos, ya puedes realizar la mayoría de las tareas de transferencia de archivos que necesitarás. Pero en la siguiente sección, aprenderás opciones más avanzadas que te darán un mejor control sobre el proceso de copiado.
Opciones y características avanzadas de cp de AWS S3
AWS ofrece un par de opciones avanzadas que te permiten maximizar las operaciones de copiado de archivos. En esta sección, te mostraré algunas de las banderas y parámetros más útiles que te ayudarán con tus tareas diarias.
Usando las banderas –exclude y –include
A veces solo quieres copiar ciertos archivos que coincidan con patrones específicos. Las banderas --exclude y --include te permiten filtrar archivos basados en patrones, y te brindan un control preciso sobre qué se copia.
Solo para preparar el escenario, esta es la estructura de directorios con la que estoy trabajando:
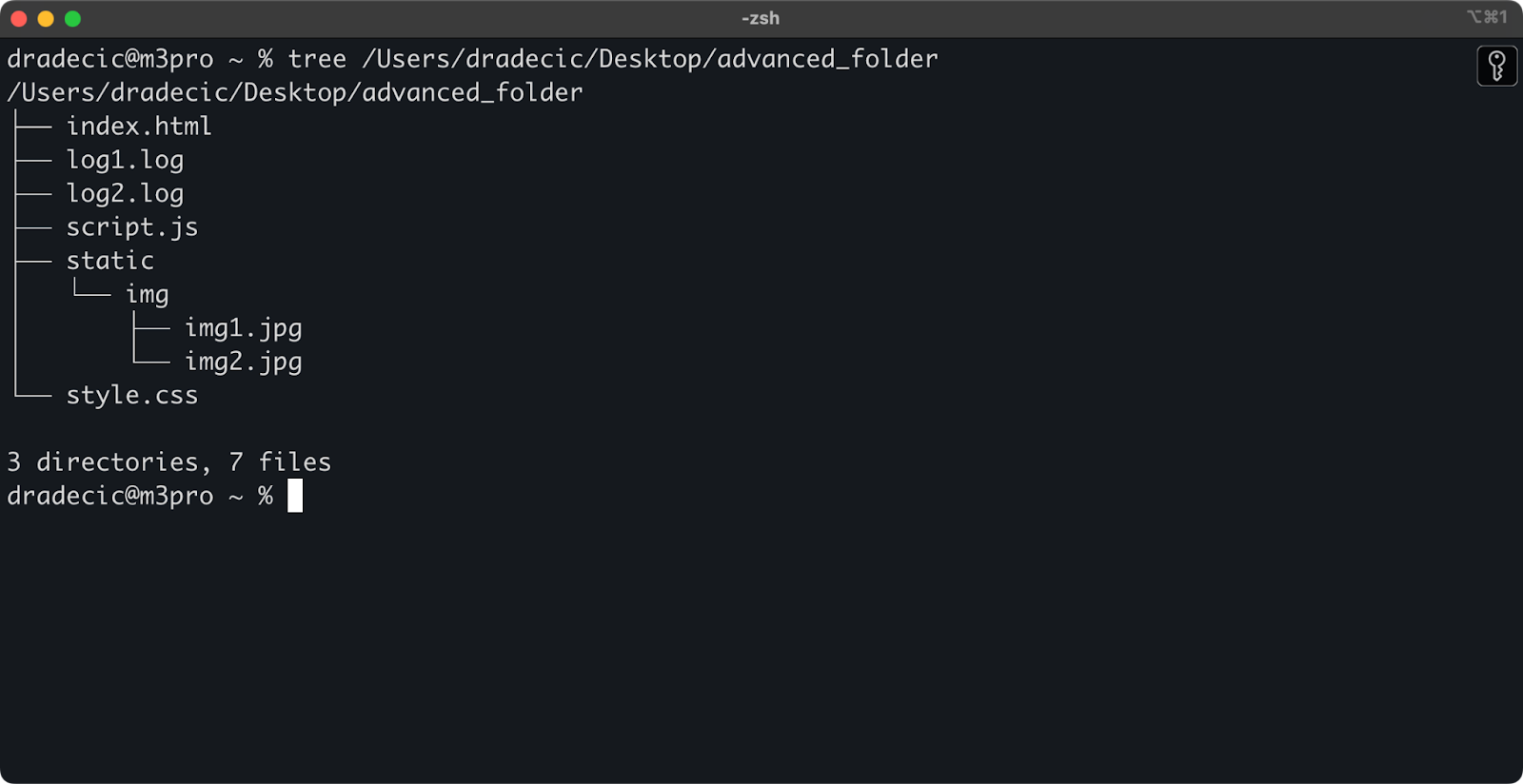
Imagen 14 – Estructura de directorios
Ahora, digamos que quieres copiar todos los archivos del directorio excepto los archivos .log:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exclude "*.log"
Este comando copiará todos los archivos desde el directorio advanced_folder a S3, excluyendo cualquier archivo con la extensión .log:
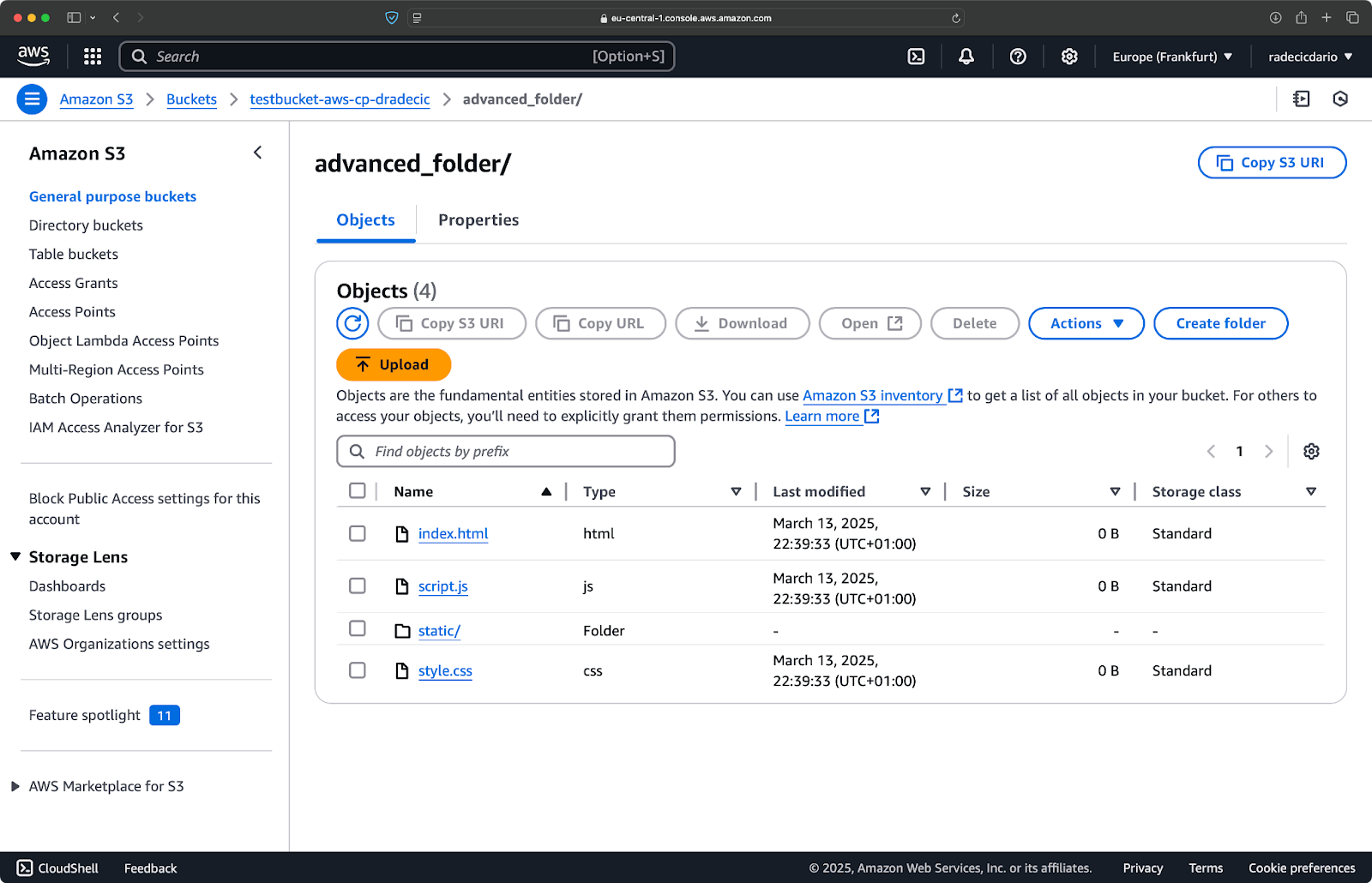
Imagen 15 – Resultados de copia de carpeta
También puedes combinar múltiples patrones. Digamos que quieres copiar solo los archivos HTML y CSS de la carpeta del proyecto:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exclude "*" --include "*.html" --include "*.css"
Este comando primero excluye todo (--exclude "*"), luego incluye solo los archivos con extensiones .html y .css. El resultado se ve así:
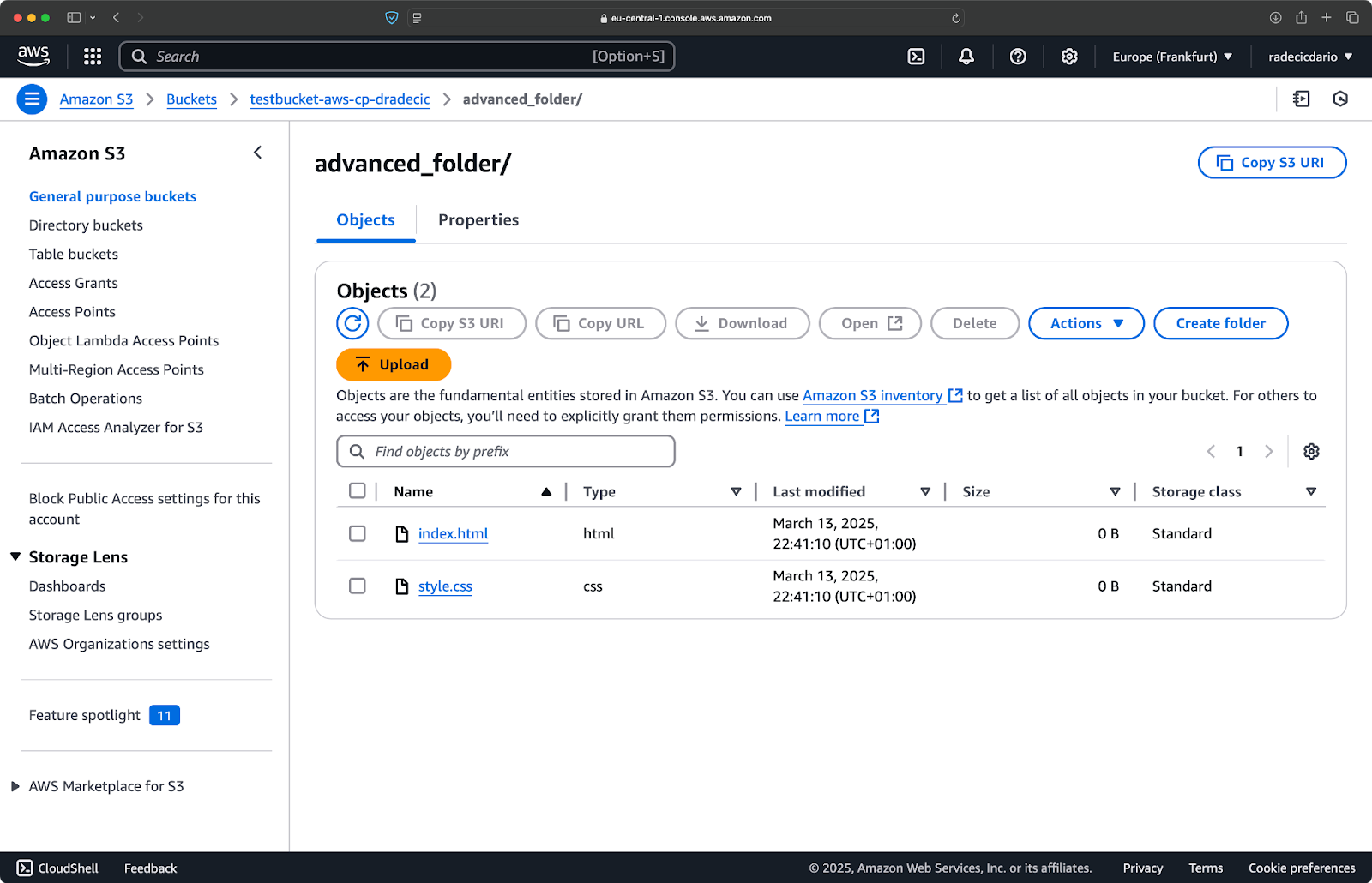
Imagen 16 – Resultados de copia de carpeta (2)
Ten en cuenta que el orden de las banderas es importante: AWS CLI procesa estas banderas de forma secuencial, por lo que si pones --include antes de --exclude, obtendrás resultados diferentes:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --include "*.html" --include "*.css" --exclude "*"
Esta vez, no se copió nada al bucket:
Imagen 17 – Resultados de copia de carpeta (3)
Especificar la clase de almacenamiento S3
Amazon S3 ofrece diferentes clases de almacenamiento, cada una con diferentes costos y características de recuperación. De forma predeterminada, aws s3 cp sube archivos a la clase de almacenamiento Standard, pero puedes especificar una clase diferente usando la bandera --storage-class:
aws s3 cp /Users/dradecic/Desktop/large-archive.zip s3://testbucket-aws-cp-dradecic/archives/ --storage-class GLACIER
Este comando sube large-archive.zip a la clase de almacenamiento Glacier, que es considerablemente más económica pero tiene costos de recuperación más altos y tiempos de recuperación más largos:
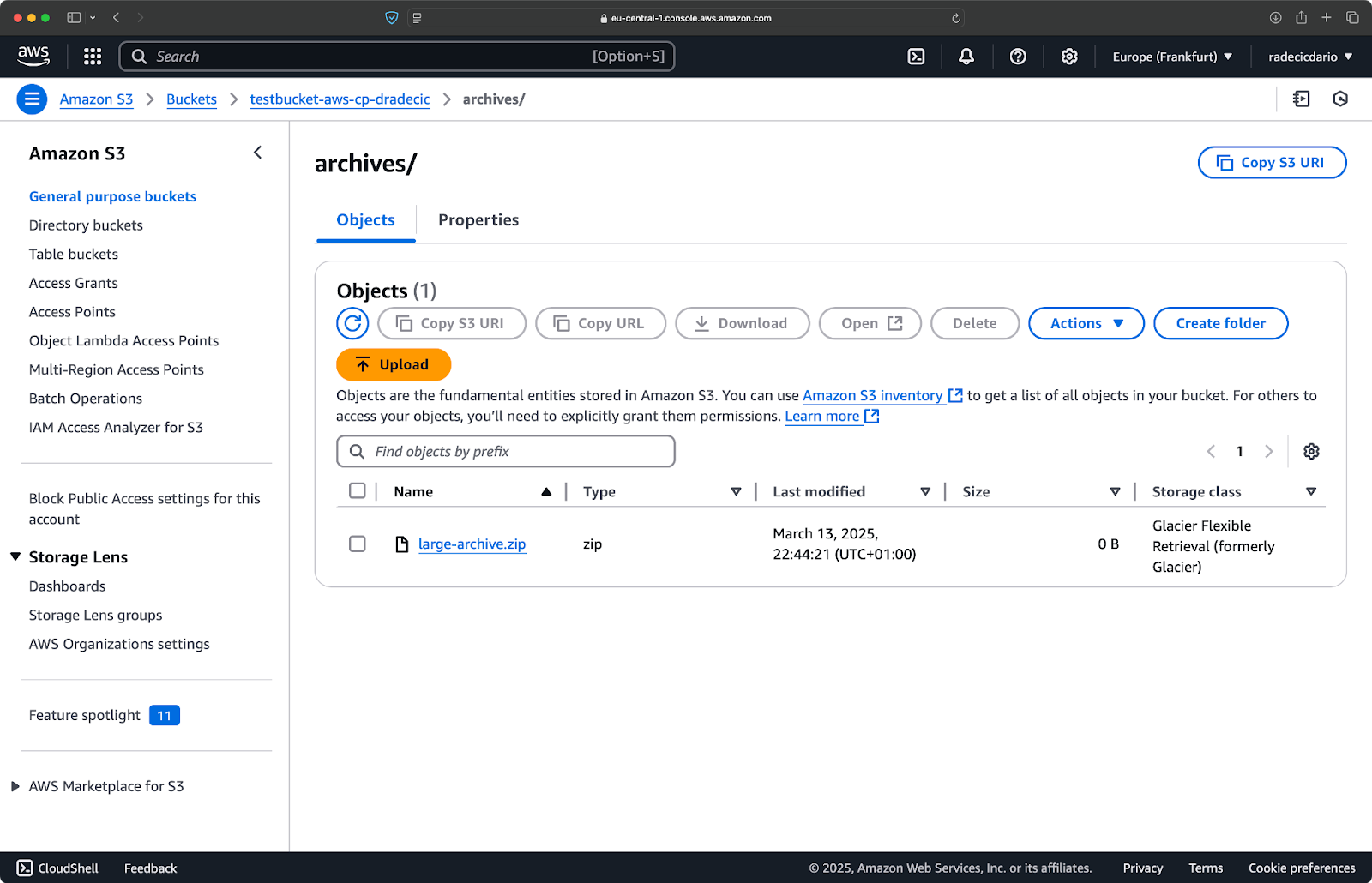
Imagen 18 – Copiar archivos a S3 con diferentes clases de almacenamiento
Las clases de almacenamiento disponibles incluyen:
STANDARD(predeterminado): Almacenamiento de propósito general con alta durabilidad y disponibilidad.REDUCED_REDUNDANCY(no recomendada actualmente): Menor durabilidad, opción de ahorro de costos, ahora obsoleta.STANDARD_IA(Infrequent Access): Almacenamiento de menor costo para datos accedidos con poca frecuencia.ONEZONE_IA(Single Zone Infrequent Access): Almacenamiento de acceso poco frecuente en una sola Zona de Disponibilidad de AWS.INTELLIGENT_TIERING: Mueve automáticamente datos entre niveles de almacenamiento según los patrones de acceso.GLACIER: Almacenamiento de archivo de bajo costo para retención a largo plazo, recuperación en minutos u horas.DEEP_ARCHIVE: Almacenamiento de archivo más económico, recuperación en horas, ideal para copias de seguridad a largo plazo.
Si estás respaldando archivos a los que no necesitas acceso inmediato, usar GLACIER o DEEP_ARCHIVE puede ahorrarte costos significativos de almacenamiento.
Sincronizar archivos con la bandera –exact-timestamps
Cuando actualizas archivos en S3 que ya existen, es posible que solo desees copiar archivos que han cambiado. La bandera --exact-timestamps ayuda con esto al comparar las marcas de tiempo entre el origen y el destino.
Aquí tienes un ejemplo:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exact-timestamps
Con esta bandera, el comando solo copiará archivos si sus marcas de tiempo difieren de los archivos que ya están en S3. Esto puede reducir el tiempo de transferencia y el uso de ancho de banda cuando actualizas regularmente un gran conjunto de archivos.
Entonces, ¿por qué es esto útil? Solo imagina escenarios de implementación donde deseas actualizar los archivos de tu aplicación sin transferir innecesariamente activos que no han cambiado.
Si bien --exact-timestamps es útil para realizar algún tipo de sincronización, si necesitas una solución más sofisticada, considera usar aws s3 sync en lugar de aws s3 cp. El comando sync fue diseñado específicamente para mantener directorios en sincronía y tiene capacidades adicionales para este propósito. Escribí todo sobre el comando sync en el tutorial de AWS S3 Sync.
Con estas opciones avanzadas, ahora tienes un control mucho más preciso sobre tus operaciones de archivos en S3. Puedes dirigirte a archivos específicos, optimizar los costos de almacenamiento y actualizar tus archivos de manera eficiente. En la siguiente sección, aprenderás a automatizar estas operaciones utilizando scripts y tareas programadas.
Automatizando Transferencias de Archivos con AWS S3 cp
Hasta ahora, has aprendido cómo copiar archivos manualmente hacia y desde S3 usando la línea de comandos. Una de las mayores ventajas de usar aws s3 cp es que puedes automatizar fácilmente estas transferencias, lo que te ahorrará un montón de tiempo.
¡Vamos a explorar cómo puedes integrar el comando aws s3 cp en scripts y trabajos programados para transferencias de archivos sin intervención manual!
Usando AWS S3 cp en scripts
Aquí tienes un ejemplo de un script bash simple que realiza una copia de seguridad de un directorio en S3, agrega una marca de tiempo a la copia de seguridad, e implementa manejo de errores y registro en un archivo:
#!/bin/bash # Establecer variables SOURCE_DIR="/Users/dradecic/Desktop/advanced_folder" BUCKET="s3://testbucket-aws-cp-dradecic/backups" DATE=$(date +%Y-%m-%d-%H-%M) BACKUP_NAME="backup-$DATE" LOG_FILE="/Users/dradecic/logs/s3-backup-$DATE.log" # Asegurar que el directorio de logs exista mkdir -p "$(dirname "$LOG_FILE")" # Crear la copia de seguridad y registrar la salida echo "Starting backup of $SOURCE_DIR to $BUCKET/$BACKUP_NAME" | tee -a $LOG_FILE aws s3 cp $SOURCE_DIR $BUCKET/$BACKUP_NAME --recursive 2>&1 | tee -a $LOG_FILE # Verificar si la copia de seguridad fue exitosa if [ $? -eq 0 ]; then echo "Backup completed successfully on $DATE" | tee -a $LOG_FILE else echo "Backup failed on $DATE" | tee -a $LOG_FILE fi
Guarda esto como backup.sh, hazlo ejecutable con chmod +x backup.sh, ¡y tendrás un script de copia de seguridad reutilizable!
Luego puedes ejecutarlo con el siguiente comando:
./backup.sh
Imagen 19 – Script ejecutándose en la terminal
Inmediatamente después, la carpeta de backups en el bucket se poblara:
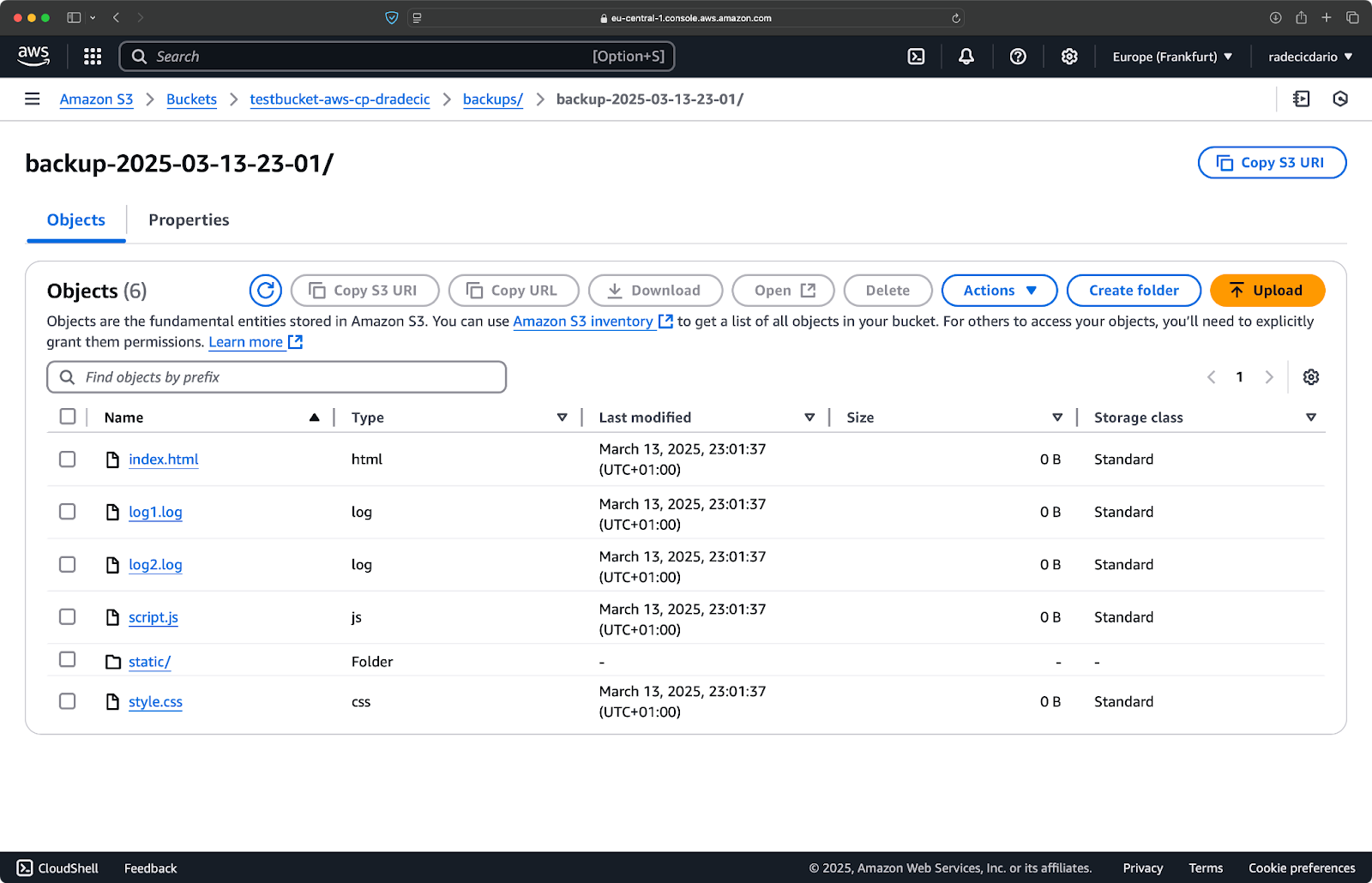
Imagen 20 – Copia de seguridad almacenada en el bucket de S3
Llevemos esto al siguiente nivel ejecutando el script en un horario programado.
Programando transferencias de archivos con trabajos cron
Ahora que tienes un script, el siguiente paso es programarlo para que se ejecute automáticamente en momentos específicos.
Si estás en Linux o macOS, puedes usar cron para programar tus copias de seguridad. Así es como puedes configurar un trabajo cron para ejecutar tu script de copia de seguridad todos los días a medianoche:
1. Abre tu crontab para editarlo:
crontab -e
2. Agrega la siguiente línea para ejecutar tu script diariamente a medianoche:
0 0 * * * /path/to/your/backup.sh
Imagen 21 – Trabajo cron para ejecutar el script diariamente
El formato para los trabajos cron es minuto hora día-del-mes mes día-de-la-semana comando. Aquí tienes algunos ejemplos más:
- Ejecutar cada hora:
0 * * * * /ruta/hacia/tu/backup.sh - Ejecutar cada lunes a las 9 AM:
0 9 * * 1 /ruta/hacia/tu/backup.sh - Ejecutar el 1ro de cada mes:
0 0 1 * * /ruta/hacia/tu/backup.sh
¡Y listo! El script backup.sh se ejecutará ahora en el intervalo programado.
Automatizar las transferencias de archivos a S3 es una buena opción. Es especialmente útil para escenarios como:
- Copias de seguridad diarias de datos importantes
- Sincronización de imágenes de productos en un sitio web
- Movimiento de archivos de registro a almacenamiento a largo plazo
- Implementación de archivos actualizados del sitio web
Técnicas de automatización como estas te ayudarán a configurar un sistema confiable que maneja transferencias de archivos sin intervención manual. Solo tienes que escribirlo una vez y luego puedes olvidarte de ello.
En la siguiente sección, cubriré algunas mejores prácticas para hacer que tus operaciones aws s3 cp sean más seguras y eficientes.
Mejores Prácticas para Usar AWS S3 cp
Mientras que el comando aws s3 cp es fácil de usar, las cosas pueden salir mal.
Si sigues las mejores prácticas, evitarás problemas comunes, optimizarás el rendimiento y mantendrás seguros tus datos. Vamos a explorar estas prácticas para hacer que tus operaciones de transferencia de archivos sean más eficientes.
Gestión eficiente de archivos
Al trabajar con S3, organizar tus archivos de forma lógica te ahorrará tiempo y dolores de cabeza en el futuro.
En primer lugar, establece una convención de nomenclatura consistente para el bucket y el prefijo. Por ejemplo, puedes separar tus datos por entorno, aplicación o fecha:
s3://company-backups/production/database/2023-03-13/ s3://company-backups/staging/uploads/2023-03/
Este tipo de organización facilita:
- Encontrar archivos específicos cuando los necesitas.
- Aplicar políticas de bucket y permisos en el nivel correcto.
- Configurar reglas de ciclo de vida para archivar o eliminar datos antiguos.
Otro consejo: Al transferir grandes conjuntos de archivos, considera agrupar primero los archivos pequeños (usando zip o tar) antes de subirlos. Esto reduce el número de llamadas a la API de S3, lo que puede disminuir costos y acelerar las transferencias.
# En lugar de copiar miles de pequeños archivos de registro # comprímelos primero, luego súbelos tar -czf example-logs-2025-03.tar.gz /var/log/application/ aws s3 cp example-logs-2025-03.tar.gz s3://testbucket-aws-cp-dradecic/logs/2025/03/
Manejo de transferencias de datos grandes
Cuando estás copiando archivos grandes o muchos archivos a la vez, hay algunas técnicas para hacer el proceso más confiable y eficiente.
Puedes usar la bandera --quiet para reducir la salida al ejecutar en scripts:
aws s3 cp large-directory/ s3://testbucket-aws-cp-dradecic/backups/ --recursive --quiet
Esto suprime la información de progreso para cada archivo, lo que hace que los registros sean más manejables. También mejora ligeramente el rendimiento.
Para archivos muy grandes, considera usar cargas multipartes con la bandera --multipart-threshold:
aws s3 cp huge-file.iso s3://testbucket-aws-cp-dradecic/backups/ --multipart-threshold 100MB
La configuración anterior indica a AWS CLI que debe dividir archivos mayores a 100MB en múltiples partes para la carga. Hacerlo tiene un par de beneficios:
- Si la conexión se interrumpe, solo la parte afectada necesita ser reintentada.
- Las partes se pueden subir en paralelo, aumentando potencialmente el rendimiento.
- Puedes pausar y reanudar cargas grandes.
Cuando se transfieren datos entre regiones, considera usar Aceleración de Transferencia de S3 para cargas más rápidas:
aws s3 cp large-file.zip s3://testbucket-aws-cp-dradecic/backups/ --endpoint-url https://s3-accelerate.amazonaws.com
Lo anterior dirige tu transferencia a través de la red de borde de Amazon, lo que puede acelerar significativamente las transferencias entre regiones.
Asegurando la seguridad
La seguridad siempre debe ser una prioridad principal al trabajar con tus datos en la nube.
Primero, asegúrate de que tus permisos IAM sigan el principio de menor privilegio.Solo otorga los permisos específicos necesarios para cada tarea.
Aquí tienes un ejemplo de política que puedes asignar al usuario:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject" ], "Resource": "arn:aws:s3:::testbucket-aws-cp-dradecic/backups/*" } ] }
Esta política permite copiar archivos hacia y desde solo el prefijo “backups” en “mi-bucket”.
Una forma adicional de aumentar la seguridad es mediante habilitando el cifrado para datos sensibles. Puedes especificar el cifrado en el lado del servidor al subir archivos:
aws s3 cp confidential.docx s3://testbucket-aws-cp-dradecic/ --sse AES256
O, para mayor seguridad, utiliza el Servicio de Administración de Claves de AWS (KMS):
aws s3 cp secret-data.json s3://testbucket-aws-cp-dradecic/ --sse aws:kms --sse-kms-key-id myKMSKeyId
Sin embargo, para operaciones altamente sensibles, considera utilizar Endpoints de VPC para S3. Esto mantiene tu tráfico dentro de la red de AWS y evita por completo internet público.
En la siguiente sección, aprenderás cómo solucionar problemas comunes que podrías encontrar al trabajar con este comando.
Resolución de Errores de AWS S3 cp
Una cosa es segura: ocasionalmente te encontrarás con problemas al trabajar con aws s3 cp. Sin embargo, al comprender los errores comunes y sus soluciones, ahorrarás tiempo y frustración cuando las cosas no salgan como se planeó.
En esta sección, te mostraré los problemas más frecuentes y cómo solucionarlos.
Errores comunes y soluciones
Error: “Acceso Denegado”
Este es probablemente el error más común que encontrarás:
upload failed: ./myfile.txt to s3://testbucket-aws-cp-dradecic/myfile.txt An error occurred (AccessDenied) when calling the PutObject operation: Access Denied
Esto suele significar una de tres cosas:
- Tu usuario IAM no tiene permisos suficientes para realizar la operación.
- La política del bucket está restringiendo el acceso.
- Tus credenciales de AWS han expirado.
Para solucionar problemas:
- Verifica tus permisos IAM para asegurarte de que tienes el necesario
s3:PutObject(para subir) os3:GetObject(para descargar). - Verifica que la política del bucket no esté restringiendo tus acciones.
- Ejecuta
aws configurepara actualizar tus credenciales si han caducado.
Error: “No existe el archivo o directorio”
Este error ocurre cuando el archivo o directorio local que estás intentando copiar no existe:
upload failed: ./missing-file.txt to s3://testbucket-aws-cp-dradecic/missing-file.txt An error occurred (404) when calling the PutObject operation: Not Found
La solución es simple: verifica cuidadosamente tus rutas de archivo. Las rutas distinguen entre mayúsculas y minúsculas, así que tenlo en cuenta. Además, asegúrate de estar en el directorio correcto al usar rutas relativas.
Error: “El bucket especificado no existe”
Si ves este error:
upload failed: ./myfile.txt to s3://testbucket-aws-cp-dradecic/myfile.txt An error occurred (NoSuchBucket) when calling the PutObject operation: The specified bucket does not exist
Verifica:
- Posibles errores en el nombre de tu bucket.
- Si estás utilizando la región correcta de AWS.
- Si el bucket realmente existe (podría haber sido eliminado).
Puedes listar todos tus buckets con aws s3 ls para confirmar el nombre correcto.
Error: “Se agotó el tiempo de conexión”
Los problemas de red pueden causar tiempos de conexión agotados:
upload failed: ./largefile.zip to s3://testbucket-aws-cp-dradecic/largefile.zip An error occurred (RequestTimeout) when calling the PutObject operation: Request timeout
Para resolver esto:
- Verifica tu conexión a internet.
- Intenta usar archivos más pequeños o habilitar cargas multipart para archivos grandes.
- Considera usar la Aceleración de Transferencia de AWS para un mejor rendimiento.
Manejo de fallos de carga
Los errores son mucho más propensos a ocurrir al transferir archivos grandes. Cuando ese es el caso, intenta manejar los fallos con gracia.
Por ejemplo, puedes usar la bandera --only-show-errors para facilitar el diagnóstico de errores en scripts:
aws s3 cp large-directory/ s3://testbucket-aws-cp-dradecic/ --recursive --only-show-errors
Esto suprime los mensajes de transferencia exitosos, mostrando solo errores, lo que facilita la resolución de problemas en transferencias grandes.
Para manejar transferencias interrumpidas, el comando --recursive omitirá automáticamente los archivos que ya existen en el destino con el mismo tamaño. Sin embargo, para ser más exhaustivo, puede usar los reintentos integrados de la AWS CLI para problemas de red configurando estas variables de entorno:
export AWS_RETRY_MODE=standard export AWS_MAX_ATTEMPTS=5 aws s3 cp large-file.zip s3://testbucket-aws-cp-dradecic/
Esto le indica a la AWS CLI que intente automáticamente las operaciones fallidas hasta 5 veces.
Pero para conjuntos de datos muy grandes, considere usar aws s3 sync en lugar de cp, ya que está diseñado para manejar interrupciones de manera más efectiva:
aws s3 sync large-directory/ s3://testbucket-aws-cp-dradecic/large-directory/
El comando sync solo transferirá archivos que son diferentes de lo que ya está en el destino, lo que lo hace perfecto para reanudar transferencias grandes interrumpidas.
Si entiendes estos errores comunes e implementas un manejo adecuado de errores en tus scripts, harás que tus operaciones de copia en S3 sean mucho más robustas y confiables.
Resumiendo AWS S3 cp
Para concluir, el comando aws s3 cp es una solución integral para copiar archivos locales a S3 y viceversa.
Aprendiste todo sobre esto en este artículo. Comenzaste desde los fundamentos y la configuración del entorno, y terminaste escribiendo scripts programados y automatizados para copiar archivos. También aprendiste cómo abordar algunos errores y desafíos comunes al mover archivos, especialmente los grandes.
Entonces, si eres desarrollador, profesional de datos o administrador de sistemas, creo que encontrarás este comando útil. La mejor manera de familiarizarse con él es usándolo regularmente. Asegúrate de entender los fundamentos y luego dedica tiempo a automatizar las partes tediosas de tu trabajo.
Para obtener más información sobre AWS, sigue estos cursos de DataCamp:
Incluso puedes usar DataCamp para prepararte para los exámenes de certificación de AWS – Practicante de la Nube de AWS (CLF-C02).