













No mundo atual, baseado em dados, as empresas devem adaptar-se à rápidas mudanças no modo como os dados são gerenciados, analisados e utilizados. Sistemas centrados tradicionais e arquiteturas monolíticas, embora históricamente suficientes, já não são adequados para atender às demandas crescentes das organizações que precisam de acesso rápido, em tempo real, a insights de dados. Um framework revolucionário neste espaço é a arquitetura de rede de dados baseada em eventos, e quando combinada com serviços da AWS, torna-se uma solução robusta para abordar desafios complexos de gerenciamento de dados.
O dilema dos Dados
Muitas organizações enfrentam desafios significativos quando dependem de arquiteturas de dados desatualizadas. Estes desafios incluem:
Lago de Dados Centralizado, Monolítico e Agnóstico de Domínio
the centralized data lake is a single storage location for all your data, making it easy to manage and access but potentially causing performance issues if not scaled properly. A monolithic data lake combines all data handling processes into one integrated system, which simplifies setup but can be hard to scale and maintain. A domain-agnostic data lake is designed to store data from any industry or source, offering flexibility and broad applicability but may be complex to manage and less optimized for specific uses.
Pressure Points de Falha na Arquitetura Tradicional
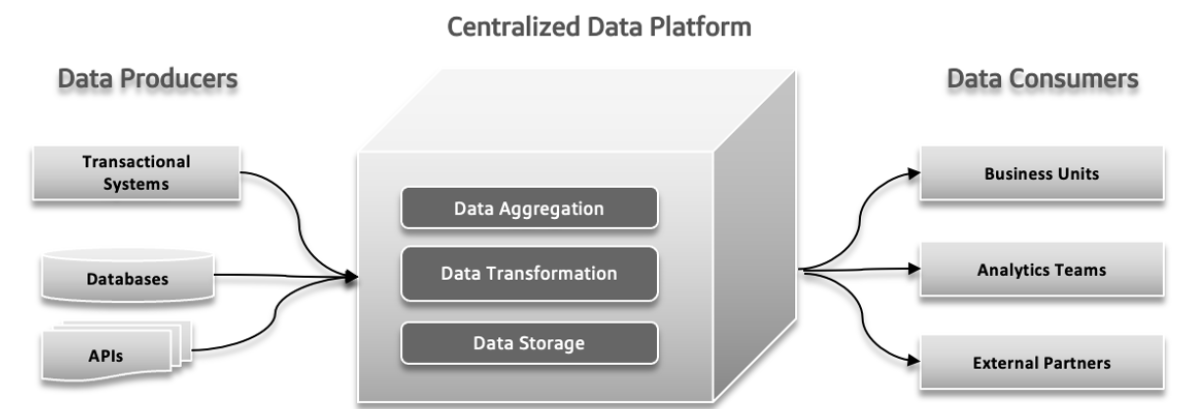
Em sistemas de dados tradicionais, podem ocorrer vários problemas. Os produtores de dados podem enviar grandes volumes de dados ou dados com erros, criando problemas ao longo do processo. Com a complexidade de dados aumentando e fontes mais diversas contribuindo para o sistema, a plataforma de dados centralizada pode ter dificuldades em lidar com a carga crescente, levando a avarias e desempenho lento. A demanda aumentada para experiências rápidas pode sobrecarregar o sistema, dificultando a adaptação rápida e a testação de novas ideias. Os tempos de resposta dos dados podem se tornar um desafio, causando atrasos na acessibilidade e utilização dos dados, afetando a tomada de decisões e a eficiência global.
Divergência entre o Landscape de Dados Operacionais e Analíticos
Na arquitetura de software, problemas como propriedade em silos, utilização de dados não clara, pipeline de dados altamente acoplados e limitações inerentes podem causar problemas significativos. A propriedade em silos ocorre quando times diferentes trabalham em isolamento, levando a problemas de coordenação e ineficiências. A falta de entendimento claro de como os dados devem ser usados ou compartilhados pode resultar em esforços duplicados e resultados inconsistentes. Os pipelines de dados acoplados, onde componentes são muito dependentes um dos outros, dificultam a adaptação ou escalonação do sistema, levando a atrasos. Finalmente, as limitações inerentes ao sistema podem abrandar a entrega de novas funcionalidades e atualizações, atrapalhando o progresso global. Solucionar estes pontos de pressão é crucial para um processo de desenvolvimento mais eficiente e responsivo.
Desafios com Big Data
Sistemas de Processamento Online Analítico (OLAP) organizam dados de uma maneira que facilita aos analistas explorarem diferentes aspectos dos dados. Para responder a consultas, esses sistemas devem transformar dados operacionais em um formato adequado à análise e lidar com grandes volumes de dados. Tradicionalmente, os data warehouses usam processos ETL (Extrair, Transformar, Carregar) para gerenciar isso. As tecnologias de big data, como o Apache Hadoop, melhoraram os data warehouses resolvendo problemas de escala e sendo de código aberto, o que permitiu que qualquer empresa usasse se conseguisse gerenciar a infraestrutura. O Hadoop apresentou uma nova abordagem permitindo dados não estruturados ou semi-estruturados, em vez de impor um esquema rígido de antemão. esta flexibilidade, onde os dados podiam ser escritos sem um esquema predefinido e estruturados depois durante as consultas, fez com que fosse mais fácil para os engenheiros de dados lidarem e integrarem dados. Adotar Hadoop frequentemente significava formar um time de dados separado: engenheiros de dados lidavam com a extração de dados, cientistas de dados gerenciavam a limpeza e a reestruturação, e analistas de dados realizavam análises. Este setup às vezes levou a problemas devido à limitada comunicação entre o time de dados e os desenvolvedores de aplicações, muitas vezes para evitar impactar os sistemas de produção.
Problema 1: Questões com as Limites do Modelo de Dados
Os dados usados para análise estão intimamente ligados à sua estrutura original, o que pode ser problemático com modelos complexos e atualizados frequentemente. As mudanças no modelo de dados afetam todos os usuários, fazendo deles vulneráveis a essas mudanças, especialmente quando o modelo envolve muitas tabelas.
Problema 2: Dados ruins, os custos de ignorar o problema
Os dados ruins frequentemente passam despercebidos até que causam problemas em um esquema, levando a problemas como tipos de dados incorretos. Como a validação muitas vezes é adiada até o final do processo, os dados ruins podem espalhar-se através de pipelines, resultando em correções caras e soluções inconsistentes. Dados ruins podem levar a perdas significativas para as empresas, como erros de cobrança custando milhões. Pesquisas indicam que os dados ruins custam às empresas trilhões anualmente, gastando substancial tempo para trabalhadores de conhecimento e cientistas de dados.
Problema 3: Falta de Propriedade Única
Os desenvolvedores de aplicativos, que são expertos no modelo de dados fonte, normalmente não comunicam esta informação para outras equipes. Seus responsáveis frequentemente terminam nas suas aplicações e bordas de banco de dados. Engenheiros de dados, que gerenciam a extração e o movimento de dados, muitas vezes trabalham reactivamente e têm controle limitado sobre as fontes de dados. Analistas de dados, removidos dos desenvolvedores, enfrentam desafios com os dados que recebem, levando a problemas de coordenação e a necessidade de soluções separadas.
Problema 4: Conexões de Dados Personalizadas
Em grandes organizações, vários times podem usar os mesmos dados mas criar seus próprios processos para gerenciá-los. Isso resulta em múltiplas cópias de dados, cada uma gerenciada independentemente, criando um caos enrolado. Fica difícil rastrear os trabalhos ETL e garantir a qualidade dos dados, levando a inaccurácias devido a fatores como problemas de sincronização e fontes de dados menos seguras. Esta abordagem dispersa desperdiça tempo, dinheiro e oportunidades.
Data mesh resolve estes problemas tratando os dados como um produto com esquemas claros, documentação e acesso padronizado, reduzindo o risco de dados ruins e melhorando a precisão e eficiência dos dados.
Data Mesh: Uma Abordagem Moderna
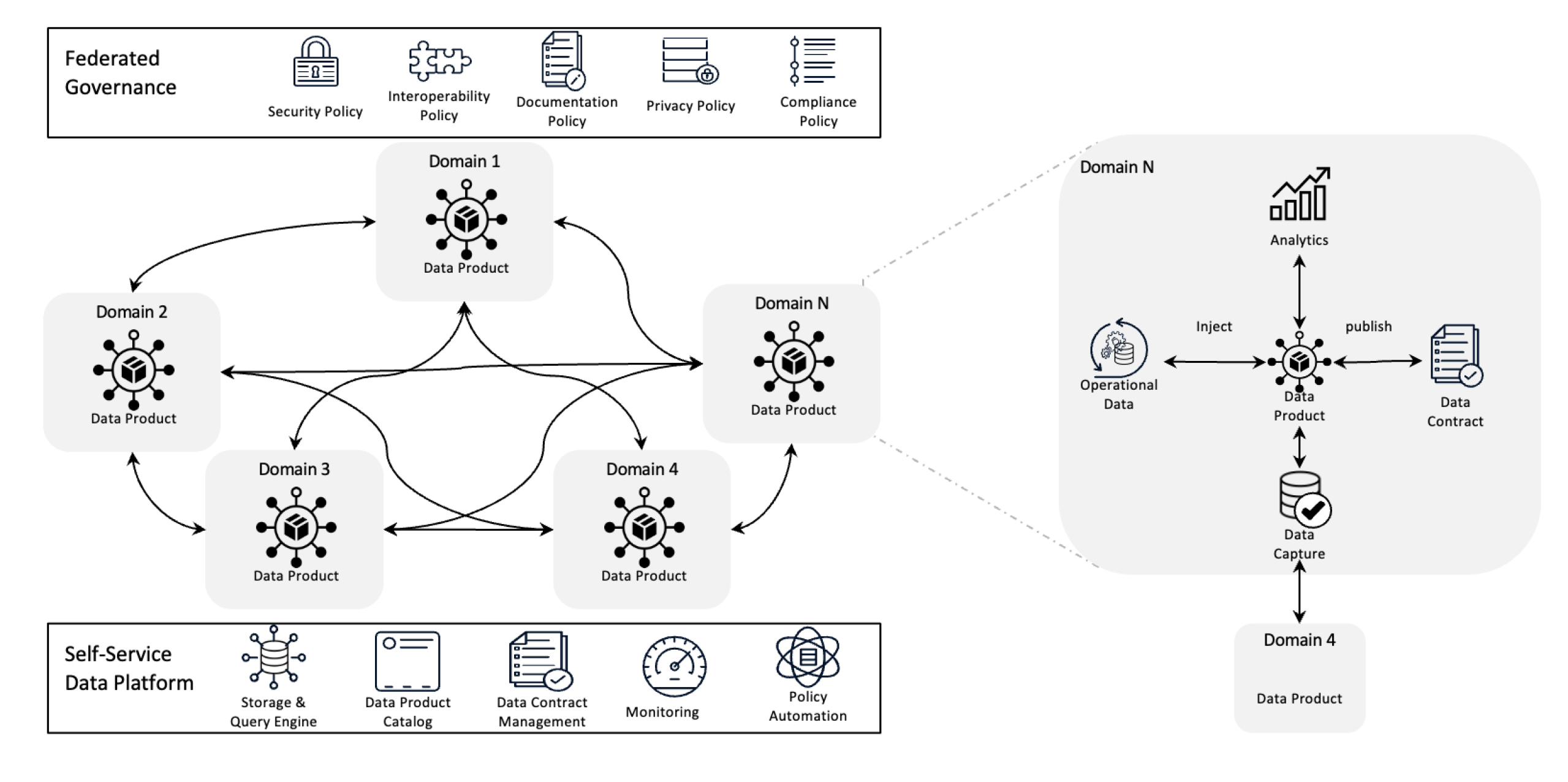
Arquitetura de Data Mesh
O data mesh redefine o gerenciamento de dados através da descentralização de propriedade e do tratamento dos dados como um produto, com apoio à infraestrutura de auto-serviço. Essa mudança empodera times para tomar controle total sobre seus dados enquanto a governança federada garante qualidade, cumprimento de regras e escalabilidade à escala da organização.
Em termos simples, é um framework arquitetural que é projetado para resolver desafios de dados complexos usando propriedade descentralizada e métodos distribuídos. Ele é usado para integrar dados de vários domínios de negócios para análises de dados abrangentes. Também é construído com base em fortes políticas de partilha e governança de dados.
Objetivos do Data Mesh
A mesh de dados ajuda diferentes organizações a obter insights valiosos em escala no que diz respeito a dados; em resumo, lidar com um cenário de dados em constante mudança, o aumento do número de fontes de dados e usuários, a variedade de transformações de dados necessárias, e a necessidade de adaptar-se rapidamente a mudanças.
A mesh de dados resolve todos os problemas mencionados acima através da descentralização do controle, permitindo que times gerem seus próprios dados sem que estes sejam isolados em departamentos separados. Esta abordagem melhora a escalabilidade distribuindo o processamento e o armazenamento de dados, o que ajuda a evitar lentidões the sistemas centrais. Ele acelera insights permitindo que times trabalhem diretamente com seus próprios dados, reduzindo atrasos causados por esperar por equipes centrais. Cada time assume responsabilidade por seus próprios dados, o que aumenta a qualidade e a consistência. Utilizando produtos de dados fáceis de entender e ferramentas de autosserviço, a mesh de dados garante que todos os times possam acessar e gerenciar seus dados rapidamente, levando a operações mais rápidas e eficientes e melhor alinhamento com as necessidades do negócio.
Princípios Chave da Mesh de Dados
- Proprietário de dados descentralizado: Times detêm e gerem seus produtos de dados, fazendo deles responsáveis pela sua qualidade e disponibilidade.
- Dado como um produto: Dados são tratados como produtos com acesso padronizado, versão e definições de esquema, garantindo consistência e facilidade de uso entre departamentos.
- Governança federada: Políticas são estabelecidas para manter a integridade dos dados, a segurança e a conformidade, enquanto ainda permite a propriedade descentralizada.
- Infraestrutura de automação: As equipes têm acesso a infraestrutura escalável que suporta a ingestão, processamento e consulta de dados sem estafetas ou dependência de equipes de dados centralizadas.
Como as Eventos Ajudam a Mesh de Dados?
Eventos ajudam a mesh de dados permitindo que diferentes partes do sistema compartilhem e atualizem dados em tempo real. Quando algo muda em uma área, um evento notifica outras áreas sobre isso, então todos ficam atualizados sem precisar de conexões diretas. Isso torna o sistema mais flexível e escalável, pois ele pode lidar com muitos dados e adaptar-se a mudanças facilmente. Os eventos também tornam mais fácil rastrear como os dados são usados e gerenciados, e deixam cada time lidar com seus próprios dados sem depender de outros.
Finalmente, vamos olhar para a arquitetura de mesh de dados com base em eventos.
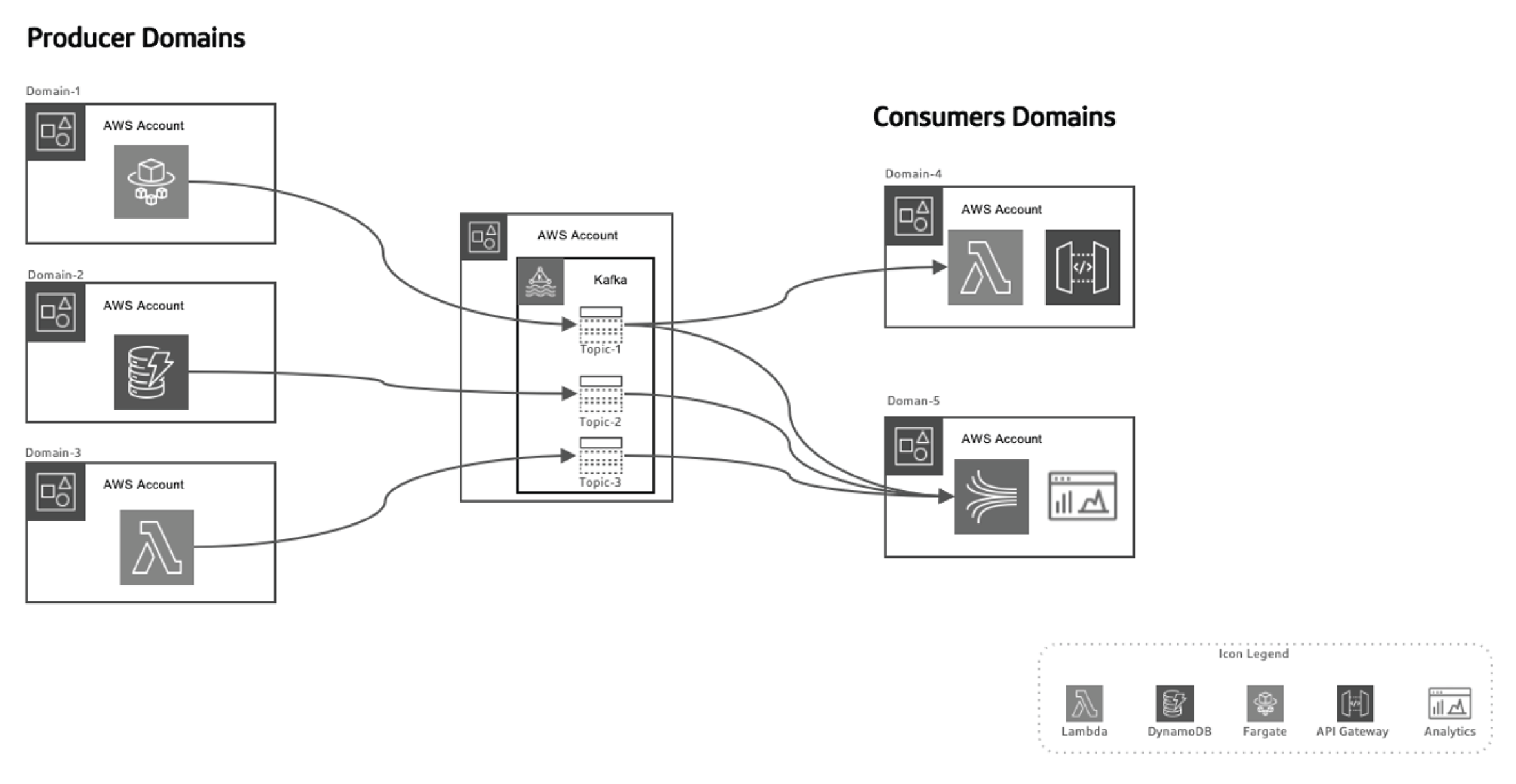
Este approach baseado em eventos permite separar os produtores de dados dos consumidores, tornando o sistema mais escalável conforme os domínios evoluem ao longo do tempo sem necessidade de grandes mudanças na arquitetura. Os produtores estão responsáveis por gerar eventos, que são então enviados para um sistema de dados em trânsito. A plataforma de streaming garante que esses eventos sejam entregues de forma confiável. Quando um microserviço de produtor ou armazenamento de dados publica um novo evento, ele é armazenado em um tópico específico. Isso dispara ouvintes no lado do consumidor, como funções Lambda ou Kinesis, para processar o evento e usá-lo conforme necessário.
Aproveitando o AWS para a Arquitetura de Mesh de Dados Baseada em Eventos
AWS oferece uma suite de serviços que complementam perfeitamente o modelo de malha de dados baseado em eventos, permitindo que as organizações escalem sua infraestrutura de dados, garantam a entrega de dados em tempo real e mantenham altos níveis de governança e segurança.
Veja como os diversos serviços da AWS se encaixam nesta arquitetura:
AWS Kinesis para Streaming de Eventos em Tempo Real
Em um modelo de malha de dados baseado em eventos, o streaming em tempo real é um elemento crucial. O AWS Kinesis fornece a capacidade de coletar, processar e analisar dados de streaming em tempo real em escala.
O Kinesis oferece vários componentes:
- Kinesis Data Streams: Ingere eventos em tempo real e processue-os concorrentemente com vários consumidores.
- Kinesis Data Firehose: Envia stream de eventos diretamente para o S3, Redshift ou Elasticsearch para processamento e análise adicionais.
- Kinesis Data Analytics: Processa dados em tempo real para obter insights em tempo real, permitindo loops de feedback imediatos em pipelines de processamento de dados.
AWS Lambda para Processamento de Eventos
O AWS Lambda é a infraestrutura central do processamento de eventos sem servidores na arquitetura de malha de dados. Com a capacidade de dimensionar automaticamente e processar fluxos de dados entrantes sem a necessidade de gerenciamento de servidores,
Lambda é a opção ideal para:
- Processar stream de Kinesis em tempo real
- Chamar solicitações de API Gateway em resposta a eventos específicos
- Interagir com DynamoDB, S3 ou outros serviços da AWS para armazenar, processar ou analisar dados
AWS SNS e SQS para Distribuição de Eventos
AWS Serviço de Notificação Simples (SNS) atua como o principal sistema de transmissão de eventos, enviando notificações em tempo real em sistemas distribuídos. AWS Serviço de Fila Simples (SQS) garante que as mensagens entre serviços desacoplados sejam entregues de forma confiável, mesmo em caso de falhas parciais do sistema. Esses serviços permitem que microsserviços desacoplados interajam sem dependências diretas, garantindo que o sistema permaneça escalável e tolerante a falhas.
AWS DynamoDB para Gerenciamento de Dados em Tempo Real
Em arquiteturas descentralizadas, o DynamoDB fornece um banco de dados NoSQL escalável e de baixa latência que pode armazenar dados de eventos em tempo real, tornando-o ideal para armazenar os resultados de pipelines de processamento de dados. Ele suporta o padrão Outbox, onde os eventos gerados pelo aplicativo são armazenados
no DynamoDB e consumidos pelo serviço de streaming (por exemplo, Kinesis ou Kafka).
AWS Glue para Catálogo de Dados Federado e ETL
O AWS Glue oferece um serviço de catálogo de dados e ETL totalmente gerenciado, essencial para a governança de dados federados na malha de dados. O Glue ajuda a catalogar, preparar e transformar dados em domínios distribuídos, garantindo a descoberta, governança e integração em toda a organização.
AWS Lake Formation e S3 para Data Lakes
Enquanto a arquitetura de data mesh se move away de data lakes centralizados, S3 e AWS Lake Formation desempenham um papel crucial em armazenar, segurar, e catalogar dados que fluem entre vários domínios, garantindo armazenamento de longo prazo, governança e conformidade.
Event-Driven Data Mesh em Ação Com AWS e Python
Event Producer: AWS Kinesis + Python
Neste exemplo, usamos AWS Kinesis para transmitir eventos quando um novo cliente é criado:
import boto3
import json
kinesis = boto3.client('kinesis')
def send_event(event):
kinesis.put_record(
StreamName="CustomerStream",
Data=json.dumps(event),
PartitionKey=event['customer_id']
)
def create_customer_event(customer_id, name):
event = {
'event_type': 'CustomerCreated',
'customer_id': customer_id,
'name': name
}
send_event(event)
# Simulate a new customer creation
create_customer_event('123', 'ABC XYZ')
Event Processing: AWS Lambda + Python
Esta função Lambda consome eventos Kinesis e os processa em tempo real.
import json
import boto3
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('CustomerData')
def lambda_handler(event, context):
for record in event['Records']:
payload = json.loads(record['kinesis']['data'])
if payload['event_type'] == 'CustomerCreated':
process_customer_created(payload)
def process_customer_created(event):
table.put_item(
Item={
'customer_id': event['customer_id'],
'name': event['name']
}
)
print(f"Stored customer data: {event['customer_id']} - {event['name']}")
Conclusão
Ao aproveitar serviços AWS como Kinesis, Lambda, DynamoDB e Glue, as organizações podem totalizar o potencial de arquitetura de data mesh com eventos dirigidos. Esta arquitetura oferece agilidade, escalabilidade e insights em tempo real, garantindo que as organizações permaneçam competitivas no cenário de dados em rápida evolução de hoje em dia. Adotar uma arquitetura de data mesh com eventos dirigidos não é apenas uma melhoria técnica, mas um imperativo estratégico para as empresas que querem prosperer na era de big data e sistemas distribuídos.
Source:
https://dzone.com/articles/event-driven-data-mesh-architecture-with-aws