













Moderne cloud-native architecturen vereisen robuuste, schaalbare en veilige logverwerkingsoplossingen om gedistribueerde applicaties te monitoren. Deze studie presenteert een hybride oplossing voor logverzameling, -aggregatie en -analyse met behulp van Azure Kubernetes Service (AKS) voor loggeneratie, Fluent Bit voor logverzameling, Azure EventHub voor tussentijdse aggregatie en Splunk dat is geïmplementeerd op een on-premises Apache CloudStack-cluster voor uitgebreide logindexering en visualisatie.
We beschrijven het ontwerp, de implementatie en de evaluatie van het systeem, waarbij we aantonen hoe deze architectuur betrouwbare en schaalbare logverwerking voor cloud-native workloads ondersteunt terwijl de controle over gegevens on-premises behouden blijft.
Inleiding
Gecentraliseerde logging oplossingen zijn onmisbaar geworden. Moderne applicaties, vooral die gebaseerd op microservices-architecturen, genereren enorme hoeveelheden logs, vaak in verschillende formaten en van meerdere bronnen. Deze logs zijn de belangrijkste bron voor het monitoren van de prestaties van applicaties, het diagnosticeren van problemen en het waarborgen van de algehele betrouwbaarheid van het systeem. Het beheren van zulke hoge volumes loggegevens vormt echter aanzienlijke uitdagingen, vooral in hybride cloudomgevingen die zowel on-premises als cloudgebaseerde infrastructuur beslaan.
Traditionele logging-oplossingen, hoewel effectief voor monolithische toepassingen, worstelen met schaalbaarheid onder de eisen van op microservices gebaseerde architecturen. De dynamische aard van microservices, gekenmerkt door onafhankelijke implementaties en frequente updates, produceert een continue stroom van logs, elk variërend in formaat en structuur. Deze logs moeten in realtime worden opgenomen, verwerkt en geanalyseerd om bruikbare inzichten te bieden. Bovendien, aangezien toepassingen steeds vaker opereren over hybride omgevingen, wordt het waarborgen van de beveiliging en PII-gegevens van cruciaal belang, gezien de gevarieerde nalevings- en regelgevende vereisten.
Deze paper introduceert een allesomvattende oplossing die deze uitdagingen aanpakt door gebruik te maken van de gecombineerde mogelijkheden van Azure en Apache CloudStack-bronnen. Door de schaalbaarheid en analysecapaciteiten van Azure te integreren met de flexibiliteit en kosteneffectiviteit van de on-premises infrastructuur van CloudStack, biedt deze oplossing een robuuste, verenigde benadering van gecentraliseerd loggen.
Literatuuroverzicht
Gecentraliseerde logverzameling in microservices staat voor uitdagingen zoals netwerklatentie, diverse gegevensformaten en beveiliging over meerdere lagen. Hoewel lichtgewicht agents zoals Fluent Bit en FluentD veel worden gebruikt, blijft efficiënt logtransport een uitdaging.
Oplossingen zoals de ELK-stack en Azure Monitor bieden gecentraliseerde logverwerking, maar omvatten doorgaans alleen cloud- of on-premises-implementaties, wat de flexibiliteit in hybride implementaties beperkt. Hybride cloudoplossingen stellen organisaties in staat om de schaalbaarheid van de cloud te benutten terwijl ze controle behouden over gevoelige gegevens in on-premises omgevingen. Hybride logverwerkingspijplijnen, vooral die met event-streamingtechnologieën, voldoen aan de behoefte aan schaalbaar logtransport en aggregatie.
Systeemarchitectuur
De architectuur, hieronder geïllustreerd, integreert Azure EventHub en AKS met on-premises Apache CloudStack en Splunk. Elke component is geoptimaliseerd voor efficiënte logverwerking en veilige gegevensoverdracht tussen omgevingen.
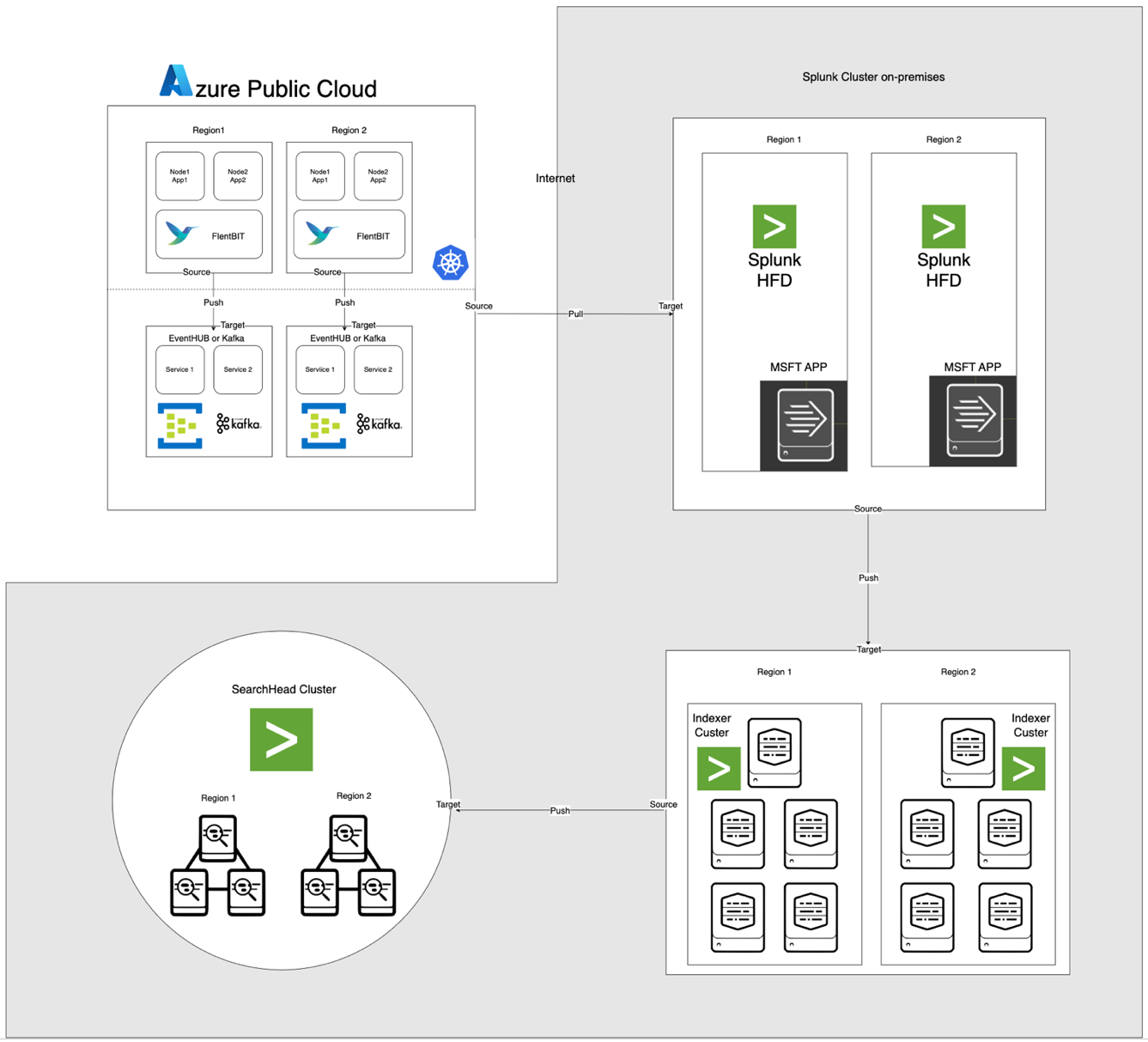
Componentbeschrijvingen
- AKS: Host containerapplicaties en genereert logs die toegankelijk zijn via de logaggregatielaag van Kubernetes.
- Fluent Bit: Geïmplementeerd als een DaemonSet, verzamelt logs van AKS-knooppunten. Elke Fluent Bit-instantie legt logs vast van /var/log/containers, filtert ze en stuurt ze in JSON-indeling naar EventHub.
- Azure EventHub: Fungeert als een high-throughput berichtbroker, die logs van Fluent Bit aggregeert en tijdelijk opslaat totdat ze worden opgehaald door de Splunk Heavy Forwarder.
- Apache Kafka: Fungeert als een betrouwbare brug tussen Fluent Bit en Splunk. Fluent Bit stuurt logs door naar Kafka met behulp van de Kafka-outputplugin, waar logs tijdelijk worden opgeslagen en verwerkt. Splunk haalt vervolgens de logs op uit Kafka met behulp van connectors zoals de Kafka Connect Splunk Sink of aangepaste scripts, waardoor een schaalbare en ontkoppelde architectuur wordt gegarandeerd.
- Splunk Heavy Forwarder (HF): Geïnstalleerd in Apache CloudStack, haalt de Heavy Forwarder logs op uit Azure EventHub met behulp van de Splunk Add-on voor Microsoft Cloud Services. Deze add-on biedt een naadloze integratie, waardoor de Heavy Forwarder veilig verbinding kan maken met EventHub, logs vrijwel in realtime kan ophalen en zo nodig kan transformeren voordat ze worden doorgestuurd naar de indexer van Splunk voor opslag en verwerking
- Splunk op Apache CloudStack: Biedt log-indexering, zoekfuncties, visualisatie en waarschuwingen.
Datastroom
- Logverzameling in AKS: Fluent Bit volgt logbestanden in /var/log/containers, filtert onnodige logs uit en tagt elke log met metadata (bijv. container naam, namespace).
- Doorgifte naar EventHub: Logs worden via HTTPS naar EventHub verzonden met behulp van de azure_eventhub-outputplugin van Fluent Bit, waardoor een veilige gegevensoverdracht wordt gegarandeerd.
- Apache Kafka: Logs van AKS worden verzameld door Fluent Bit, dat draait als een DaemonSet, die ze analyseert en doorstuurt naar Apache Kafka via de Kafka output-plugin. Kafka fungeert als een buffer met een hoog doorvoervermogen, waarbij logs worden opgeslagen en gepartitioneerd voor schaalbaarheid. Splunk neemt deze logs van Kafka over met behulp van connectors of scripts, waardoor indexering, analyse en real-time monitoring mogelijk zijn.
- Logs ophalen met Splunk Heavy Forwarder: De Heavy Forwarder in Apache CloudStack maakt verbinding met EventHub met behulp van de EventHubs SDK en haalt logs op, die worden doorgestuurd naar de lokale Splunk-indexer voor opslag en verwerking.
- Opslag en analyse in Splunk: Logs worden geïndexeerd in Splunk, waardoor real-time zoekopdrachten, dashboard visualisaties en waarschuwingen op basis van logpatronen mogelijk zijn.
Methode
Fluent Bit DaemonSet-implementatie in AKS
De configuratie van Fluent Bit wordt opgeslagen in een ConfigMap en geïmplementeerd als een DaemonSet. Hieronder staat de uitgebreide configuratie voor de Fluent Bit DaemonSet:
Name: fluentbit-cm
Namespace: fluentbit
Labels: k8s-app=fluentbit
Annotations:
Data
crio-logtag.lua:
local reassemble_state = {}
function reassemble_cri_logs(tag, timestamp, record)
-- Valideer het binnenkomende record
if not record or not record.logtag or not record.log or type(record.log) == 'table' then
return 0, timestamp, record
end
-- Genereer een unieke sleutel voor herassemblage op basis van stream en tag
local reassemble_key = (record.stream or "unknown_stream") .. "::" .. tag
-- Behandel logfragmenten (logtag == 'P')
if record.logtag == 'P' then
-- Sla het fragment op in de herassembleerstaat
reassemble_state[reassemble_key] = (reassemble_state[reassemble_key] or "") .. record.log
return -1, 0, 0 -- Do not forward this fragment
end
-- Behandel het einde van een gefragmenteerde log
if reassemble_state[reassemble_key] then
-- Combineer opgeslagen fragmenten met de huidige log
record.log = (reassemble_state[reassemble_key] or "") .. (record.log or "")
-- Maak de opgeslagen staat voor deze sleutel leeg
reassemble_state[reassemble_key] = nil
return 1, timestamp, record -- Forward the reassembled log
end
-- Als er geen herassemblage nodig is, stuur de log dan ongewijzigd door
return 0, timestamp, record
end
INCLUDE filter-kubernetes.conf
filter-kubernetes.conf:
[FILTER]
Name kubernetes
Match test.app.splunk.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Kube_Tag_Prefix test.app.splunk.var.log.containers
Merge_Log On
Merge_Log_Key log_processed
K8S-Logging.Parser On
K8S-Logging.Exclude On
Labels Off
Annotations Off
Keep_Log Off
fluentbit.conf:
[SERVICE]
Flush 1
Log_Level info
Daemon on
Parsers_File parsers.conf
HTTP_Server On
HTTP_Listen 0.0.0.0
HTTP_Port 2020
Health_Check On
HC_Errors_Count 1
HC_Retry_Failure_Count 1
HC_Period 5
INCLUDE input-kubernetes.conf
INCLUDE output-kafka.conf
input-kubernetes.conf:
[INPUT]
Name tail
Tag test.app.splunk*
Alias test.app.splunk-input
Path /var/log/containers/*test.app.splunk.log
Parser cri
DB /var/log/flb_kube.db
Buffer_Chunk_Size 256K
Buffer_Max_Size 24MB
Mem_Buf_Limit 1GB
Skip_Long_Lines On
Refresh_Interval 5
output-kafka.conf:
[OUTPUT]
Name kafka
Alias test.app.splunk-output
Match test.app.splunk.*
Brokers prod-region-logs-premium.servicebus.windows.net:9094
Topics test.app.splunk
Retry_Limit 5
rdkafka.security.protocol SASL_SSL
rdkafka.sasl.mechanism PLAIN
rdkafka.sasl.username $ConnectionString
rdkafka.sasl.password Endpoint=sb://prod-region-logs-premium.servicebus.windows.net/;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=***********************************************=
[OUTPUT]
parsers.conf:
[PARSER]
Name cri
Format regex
Regex ^(? - [INPUT] sectie specificeert logverzameling vanuit de /var/log/containers map.
- [FILTER] sectie verrijkt logs met Kubernetes metadata.
- [OUTPUT] sectie configureert Fluent Bit om logs door te sturen naar EventHub in JSON-indeling.
Azure EventHub-configuratie
EventHub vereist een namespace, een specifieke EventHub-instantie en toegangsbeheer via gedeelde toegangspolicies.
- Namespace en EventHub-instelling: Maak een namespace en EventHub-instantie in Azure, stel een verzendbeleid in en haal de verbindingsreeks op.
- Configuratie voor hoge doorvoer: EventHub is geconfigureerd met een hoog partitieaantal om schaalbaarheid, buffering en gelijktijdige gegevensstromen van Fluent Bit te ondersteunen.
Splunk Heavy Forwarder-configuratie in Apache CloudStack
Splunk Heavy Forwarder haalt logs op uit EventHub en stuurt ze door naar de indexer van Splunk.
- Add-on voor Microsoft Cloud Services: Installeer de add-on om EventHub-connectiviteit in te schakelen. Configureer de invoer in
inputs.conf:
[azure_eventhub://eventhub_name]
index = <index_name>
eventhub_namespace = <namespace>
shared_access_key_name = <access_key_name>
shared_access_key = <access_key>
batch_size = 500
interval = 30
sourcetype = _json
disabled = 0- Batchverwerking: Stel batch_size in op 500 en interval op 30 seconden om gegevensinname te optimaliseren en de frequentie van netwerkoproepen te verminderen.
Splunk-indexering en visualisatie
- Data-verrijking: Logs worden verrijkt met aanvullende metadata in Splunk door middel van veldextracties.
- Zoekopdrachten en dashboards: SPL-query’s maken real-time zoekopdrachten mogelijk, en aangepaste dashboards bieden visualisatie van logpatronen.
- Waarschuwingen: Waarschuwingen zijn geconfigureerd om te worden geactiveerd bij specifieke logpatronen, zoals hoge foutpercentages of herhaalde waarschuwingen van specifieke containers.
Prestaties en Schaalbaarheid
Tests tonen aan dat het systeem hoge doorvoer van log-inname aankan, met de buffermogelijkheden van EventHub die gegevensverlies voorkomen tijdens netwerkonderbrekingen. Het gebruik van Fluent Bit op AKS-nodes blijft minimaal, en de indexer van Splunk verwerkt de logvolumes efficiënt met passende indexering en filterconfiguraties.
Beveiliging
HTTPS wordt gebruikt om communicatie tussen AKS en EventHub te beveiligen, terwijl Splunk HF veilige sleutels gebruikt om te authenticeren bij EventHub. Elk onderdeel in de pijplijn implementeert opnieuw pogingsmechanismen om gegevensintegriteit te behouden.
Resourcegebruik
- Fluent Bit gebruikt gemiddeld 100-150 MiB geheugen en 0,2-0,3 CPU op AKS-nodes.
- Het resourcegebruik van EventHub wordt dynamisch aangepast op basis van partitie- en doorvoerconfiguraties.
- De belasting van Splunk HF wordt gebalanceerd door batchverwerking, waarbij gegevensoverdracht wordt geoptimaliseerd zonder Apache CloudStack-bronnen te overbelasten.
Betrouwbaarheid en Fouttolerantie
De oplossing maakt gebruik van EventHub’s buffering om logretentie te waarborgen in geval van downstreamstoringen. EventHub ondersteunt ook opnieuw pogingsbeleid, wat de gegevensintegriteit en betrouwbaarheid verder verbetert.
Discussie
Voordelen van Hybride Cloud Architectuur
Deze architectuur biedt flexibiliteit, schaalbaarheid en beveiliging door Azure-services te combineren met controle op locatie. Het maakt ook gebruik van cloudgebaseerde streaming- en bufferingmogelijkheden zonder de gegevenssoevereiniteit in gevaar te brengen.
Beperkingen
Hoewel EventHub betrouwbare gegevensaggregatie biedt, nemen de kosten toe met doorvoereenheden, waardoor het essentieel is om logforwardingconfiguraties te optimaliseren. Bovendien introduceert gegevensoverdracht tussen cloud- en on-premises omgevingen mogelijke latentie.
Toekomstige Toepassingen
Deze architectuur kan worden uitgebreid door machine learning te integreren voor anomaliedetectie in logs of door ondersteuning toe te voegen voor meerdere cloudproviders om logverwerking en multi-cloud veerkracht verder te schalen.
Conclusie
Deze studie toont de effectiviteit aan van een hybride logverwerkingspijplijn die gebruikmaakt van cloud- en on-premises middelen. Door Azure Kubernetes Service (AKS), Azure EventHub en Splunk op Apache CloudStack te integreren, creëren we een schaalbare en veerkrachtige oplossing voor gecentraliseerd logbeheer en -analyse. De architectuur lost belangrijke uitdagingen op in gedistribueerd loggen, waaronder hoge gegevensthroughput, beveiliging en fouttolerantie.
Het gebruik van Fluent Bit als een lichtgewicht logverzamelaar in AKS zorgt voor efficiënte gegevensverzameling met minimale resource-overhead. De buffering-mogelijkheden van Azure EventHub zorgen voor betrouwbare logaggregatie en tijdelijke opslag, waardoor het goed geschikt is om variabel logverkeer aan te kunnen en de gegevensintegriteit te behouden in het geval van connectiviteitsproblemen. De Splunk Heavy Forwarder en Splunk-implementatie in Apache CloudStack stellen organisaties in staat controle te behouden over logopslag en -analyse, terwijl ze profiteren van de schaalbaarheid en flexibiliteit van cloudresources.
Deze aanpak biedt aanzienlijke voordelen voor organisaties die een hybride cloudopstelling vereisen, zoals verbeterde controle over gegevens, naleving van vereisten voor gegevensresidentie en de flexibiliteit om mee te schalen met de vraag. Toekomstig werk kan de integratie van machine learning verkennen om loganalyse te verbeteren, geautomatiseerde anomaliedetectie mogelijk te maken en uitbreiding naar een multi-cloudopstelling om veerkracht en veelzijdigheid te vergroten. Dit onderzoek biedt een fundamentele architectuur die aanpasbaar is aan de evoluerende behoeften van moderne, gedistribueerde systemen in bedrijfsomgevingen.
Referenties
Azure Event Hubs en Kafka
Hybride monitoring en logging
- Hybride en Multi-Cloud Monitoring Patronen
- Hybride Cloud Monitoring Strategieën
Splunk Integratie
- Splunking Azure Event Hubs
- Azure Data in Splunk Platform
AKS Implementatie
Source:
https://dzone.com/articles/bridging-cloud-and-on-premises-log-processing