













Editor’s Note: The following is an article written for and published in DZone’s 2024 Trend Report, Data Engineering: Enriching Data Pipelines, Expanding AI, and Expediting Analytics.
This article explores the essential strategies for leveraging real-time data streaming to drive actionable insights while future proofing systems through AI automation and vector databases. It delves into the evolving architectures and tools that empower businesses to stay agile and competitive in a data-driven world.
Real-Time Data Streaming: The Evolution and Key Considerations
Real-time data streaming has evolved from traditional batch processing, where data was processed in intervals that introduced delays, to continuously handle data as it is generated, enabling instant responses to critical events. By integrating AI, automation, and vector databases, businesses can further enhance their capabilities, using real-time insights to predict outcomes, optimize operations, and efficiently manage large-scale, complex datasets.
Necessity of Real-Time Streaming
Er is noodzaak om direct te handelen op gegevens zodra deze gegenereerd worden, vooral in scenario’s zoals fraude detectie, log-analyse of klantgedragstracking. Real-time streaming stelt organisaties in staat om gegevens onmiddellijk te vangen, te verwerken en te analyseren, waardoor ze snel kunnen reageren op dynamische gebeurtenissen, besluitvorming kunnen optimaliseren en klantervaringen in real time kunnen verbeteren.
Bronnen van Real-Time Data
Real-time data komt voort uit verschillende systemen en apparaten die voortdurend gegevens genereren, vaak in grote hoeveelheden en in formaten die moeilijk te verwerken kunnen zijn. Bronnen van real-time data zijn vaak:
- IoT-apparaten en sensoren
- Serverlogs
- App-activiteit
- Online reclame
- Evenementen van databaseveranderingen
- Website clickstreams
- Sociale mediaplatformen
- Transactiedatabases
Effectief beheren en analyseren van deze gegevensstromen vereist een robuuste infrastructuur die capable is van het omgaan met ongestructureerde en semi-gestructureerde gegevens; dit stelt bedrijven in staat waardevolle inzichten te extraheren en real-time beslissingen te nemen.
Kritieke Uitdagingen in Moderne Data Pipelines
Moderne data pipelines worden geconfronteerd met verschillende uitdagingen, waaronder het handhaven van gegevenskwaliteit, het waarborgen van juiste transformaties en het minimaliseren van pipeline-downtime:
- Slechte gegevenskwaliteit kan leiden tot foutieve inzichten.
- Data transformaties zijn complex en vereisen nauwkeurige scripting.
- Hoge downtime verstoort operaties, waardoor fault-tolerante systemen essentieel zijn.
Daarnaast is datagovernance cruciaal om gegevensconsistentie en betrouwbaarheid over processen te waarborgen. Scalabiliteit is ook een belangrijk probleem, omdat pijplijnen fluctuerende gegevensvolumes moeten aan kunnen en juiste monitoring en waarschuwingen essentieel zijn om onverwachte storingen te voorkomen en een soepele werking te waarborgen.
Geavanceerde Real-Time Data Streaming Architectures en Toepassingsscenario’s
Deze sectie demonstrates de mogelijkheden van moderne gegevenssystemen om data in beweging te verwerken en te analyseren, waardoor organisaties de tools hebben om te reageren op dynamische gebeurtenissen in milliseconden.
Stappen om een Real-Time Data Pipeline te Bouwen
Om een effectieve real-time gegevens pijplijn te creëren, is het essentieel om een reeks gestructureerde stappen te volgen die een soepele gegevensstroom, verwerking en schaalbaarheid waarborgen. Tabel 1, gedeeld hieronder, schetst de belangrijkste stappen die betrokken zijn bij het bouwen van een robuuste real-time gegevens pijplijn:
Tabel 1. Stappen om een real-time data pipeline te bouwen
| step | activities performed |
|---|---|
| 1. Data-ingestie | Stel een systeem in om gegevensstromen uit verschillende bronnen in real time te kapen |
| 2. Data-verwerking | Maak de gegevens schoon, valideren en transformeren om ervoor te zorgen dat ze klaar zijn voor analyse |
| 3. Stream-verwerking | Configureer consumenten om voortdurend gegevens te trekken, te verwerken en te analyseren |
| 4. Opslag | Sla de verwerkte gegevens op in een geschikt formaat voor downstream gebruik |
| 5. Monitoring en schalen | Implementeer hulpen om de prestaties van de pijplijn te monitoren en ervoor te zorgen dat deze kan schalen met toenemende gegevensvereisten |
Vooraanstaande Open-Source Streaming Tools
Om robuuste real-time gegevens pijplijnen te bouwen, zijn er verschillende vooraanstaande open-source hulpmiddelen beschikbaar voor gegevensingestie, opslag, verwerking en analyse, elk speelt een cruciale rol in het efficiënt beheren en verwerken van grootschalige gegevensstromen.
Open-source hulpmiddelen voor gegevensingestie:
- Apache NiFi, met zijn nieuwste 2.0.0-M3 versie, biedt verbeterde schaalbaarheid en real-time verwerking capabilities.
- Apache Airflow wordt gebruikt voor het orkestreren van complexe workflows.
- Apache StreamSets biedt continue gegevensstroom monitoring en verwerking.
- Airbyte vereenvoudigt gegevensextractie en laden, waardoor het een sterke keuze is voor het beheren van diverse gegevensingestiebehoefte.
Open-source hulpmiddelen voor gegevensopslag:
- Apache Kafka wordt breed gebruikt voor het bouwen van real-time pijplijnen en streaming-toepassingen vanwege zijn hoge schaalbaarheid, fouttolerantie en snelheid.
- Apache Pulsar, een gedistribueerd berichtensysteem, biedt sterke schaalbaarheid en duurzaamheid, waardoor het ideaal is voor het afhandelen van grootschalige berichten.
- NATS.io is een hoogpresterend berichtensysteem, vaak gebruikt in IoT en cloud-native toepassingen, dat ontworpen is voor microservices-architecturen en lichtgewicht, snelle communicatie biedt voor real-time gegevensbehoefte.
- Apache HBase, een gedistribueerde database gebaseerd op HDFS, biedt sterke consistentie en hoge doorvoer, waardoor het ideaal is voor het opslaan van grote hoeveelheden real-time gegevens in een NoSQL-omgeving.
Open-source tools voor gegevensverwerking:
- Apache Spark valt op door zijn in-memory cluster computing, die snelle verwerking biedt voor zowel batch- als streaming-toepassingen.
- Apache Flink is ontworpen voor hoogpresterende gedistribueerde streamverwerking en ondersteunt batchbanen.
- Apache Storm staat bekend om zijn vermogen om meer dan een miljoen records per seconde te verwerken, waardoor het uiterst snel en schaalbaar is.
- Apache Apex biedt geïntegreerde stroom- en batchverwerking.
- Apache Beam biedt een flexibel model dat werkt met meerdere uitvoeringssystemen zoals Spark en Flink.
- Apache Samza, ontwikkeld door LinkedIn, integreert goed met Kafka en behandelt stroomverwerking met een focus op schaalbaarheid en fouttolerantie.
- Heron, ontwikkeld door Twitter, is een real-time analysepplatform dat zeer compatibel is met Storm maar biedt betere prestaties en resource-isolatie, waardoor het geschikt is voor hoge snelheid stroomverwerking op schaal.
Open-source tools voor gegevensanalyse:
- Apache Kafka staat bekend om de hoge doorvoer en lage latentie bij het verwerken van real-time gegevensstromen.
- Apache Flink biedt krachtige stroomverwerking, ideaal voor toepassingen die distribute, stateful berekeningen vereisen.
- Apache Spark Streaming integreert met het bredere Spark-ecosysteem en behandelst zowel real-time als batchgegevens binnen hetzelfde platform.
- Apache Druid en Pinot fungeren als real-time analytische databases, die OLAP-mogelijkheden bieden die het mogelijk maken om grote gegevenssets in real time te bevragen, wat ze bijzonder nuttig maakt voor dashboards en business intelligence-toepassingen.
Implementatiegevallen
Real-world implementaties van real-time gegevenspijplijnen tonen de diverse manieren waarop deze architecturen cruciale toepassingen in verschillende industrieën ondersteunen, prestaties, besluitvorming en operationele efficiëntie verbeteren.
Financiële marktgegevensstreaming voor high-frequency trading systemen
In high-frequency trading systemen, waar milliseconden het verschil kunnen maken tussen winst en verlies, worden Apache Kafka of Apache Pulsar gebruikt voor hoge doorvoersnelheid gegevensingestie. Apache Flink of Apache Storm behandelen low-latency verwerking om ervoor te zorgen dat handelsbeslissingen onmiddellijk worden genomen. Deze pijplijnen moeten extreme schaalbaarheid en fouttolerantie ondersteunen, omdat elke systeemuitval of verwerkingvertraging kan leiden tot gemiste handelskansen of financiële verliezen.
IoT en real-time sensorgegevensverwerking
Real-time data pipelines ingen data van IoT-sensoren, die informatie zoals temperatuur, druk of beweging vastleggen, en verwerken de gegevens met minimale latentie. Apache Kafka wordt gebruikt om de gegevensinvoer van sensoren te behandelen, terwijl Apache Flink of Apache Spark Streaming real-time analyses en gebeurtenisdetectie mogelijk maken. Figuur 1 hieronder gedeeld, toont de stappen van streamprocessing voor IoT van gegevensbronnen naar dashboarding:
Figuur 1. Streamprocessing voor IoT
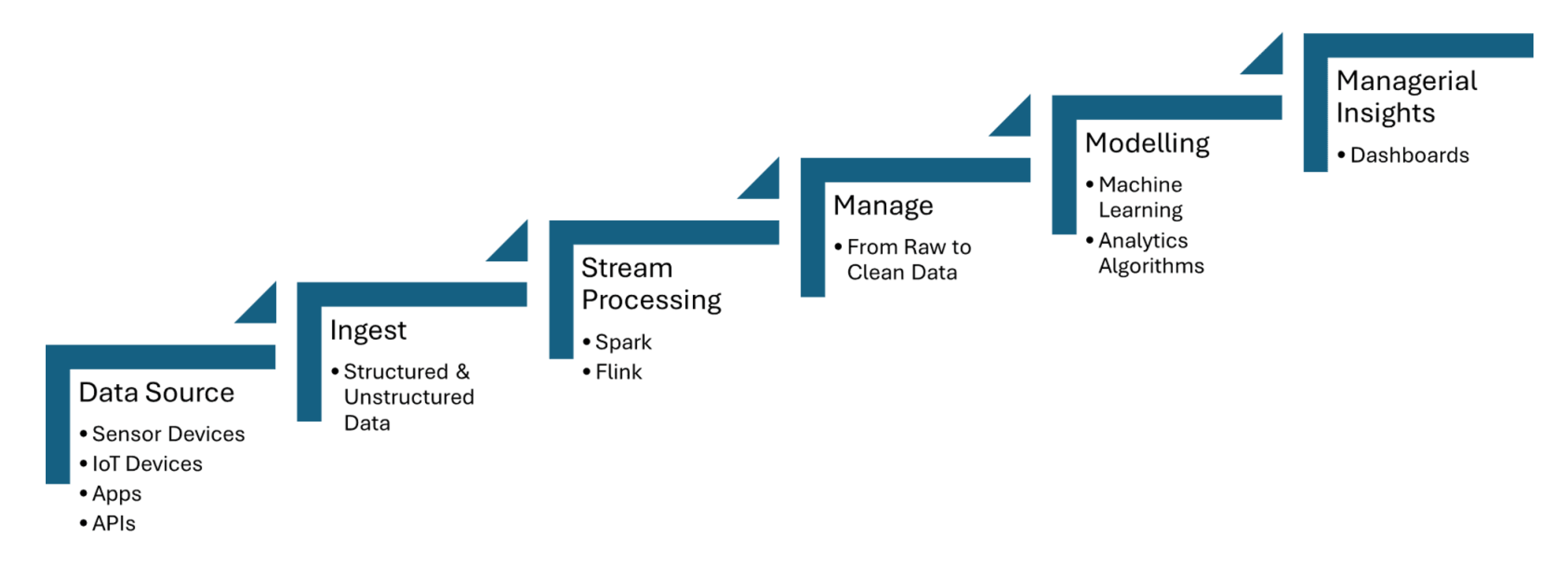
Bedrogdetectie uit transactiegegevens streaming
Transactiegegevens worden in real time ingezogen met tools zoals Apache Kafka, die grote hoeveelheden streaminggegevens van meerdere bronnen afhandelt, zoals banktransacties of betalingsgateways. Streamprocessingframes zoals Apache Flink of Apache Spark Streaming worden gebruikt om machine learning-modellen of regelgebaseerde systemen toe te passen die afwijkingen in transactiepatronen detecteren, zoals ongewoon uitgavegedrag of geografische inconsistenties.
Hoe AI-automatisering Intelligente pijplijnen en vector databases aanstuurt
Intelligente workflows maken gebruik van real-time gegevensverwerking en vector databases om besluitvorming te verbeteren, operaties te optimaliseren en de efficiëntie van grootschalige gegevensomgevingen te verbeteren.
Data Pipeline Automatisering
Gegevenspipelines automatisering stelt de efficiënte afhandeling van grootschalige gegevensingestie, transformatie en analyse taken zonder handmatige tussenkomst in. Apache Airflow zorgt ervoor dat taken op de juiste tijd en in de juiste volgorde automatisch worden geactiveerd. Apache NiFi faciliteert geautomatiseerd gegevensstroombeheer, waardoor real-time gegevensingestie, transformatie en routing mogelijk is. Apache Kafka waarborgt dat gegevensverwerking voortdurend en efficiënt wordt uitgevoerd.
Pipeline Orchestration Frameworks
Pipeline orchestration frameworks zijn essentieel voor het automatiseren en beheren van gegevensworkflows op een gestructureerde en efficiënte manier. Apache Airflow biedt functies zoals afhankelijkheidsbeheer en monitoring. Luigi richt zich op het bouwen van complexe pijplijnen van batch jobs. Dagster en Prefect bieden dynamisch pijplijnbeheer en verbeterde foutafhandeling.
Adaptive Pipelines
Adaptive pijplijnen zijn ontworpen om dynamisch aan te passen aan veranderende gegevensomgevingen, zoals fluctuaties in gegevensvolume, structuur of bronnen. Apache Airflow of Prefect mogelijkheden voor real-time responsiviteit door het automatiseren van taakafhankelijkheden en planning op basis van huidige pijplijnomstandigheden. Deze pijplijnen kunnen frameworks zoals Apache Kafka gebruiken voor schaalbare gegevensstreaming en Apache Spark voor adaptieve gegevensverwerking, waardoor efficiënt gebruik van middelen wordt gewaarborgd.
Streaming Pipelines
Een streamingpijplijn voor het vullen van een vector database voor real-time retrieval-augmented generation (RAG) kan volledig worden gebouwd met hulpmiddelen zoals Apache Kafka en Apache Flink. De verwerkte streaminggegevens worden vervolgens omgezet in embeddings en opgeslagen in een vector database, waardoor efficiënte semantische zoekopdrachten mogelijk zijn. Deze real-time architectuur zorgt ervoor dat grote taalmodellen (LLMs) toegang hebben tot actuele, contextueel relevante informatie, wat de nauwkeurigheid en betrouwbaarheid van RAG-gebaseerde toepassingen zoals chatbots of aanbevelingsmotoren verbetert.
Data Streaming als Data Fabric voor Generative AI
Real-time data streaming maakt real-time inname, verwerking en ophalen van enorme hoeveelheden gegevens mogelijk die LLMs nodig hebben voor het genereren van nauwkeurige en actuele reacties. Terwijl Kafka helpt bij streaming, verwerkt Flink deze streams in real time, waardoor gegevens worden verrijkt en contextueel relevant voordat ze worden gevoed aan vector databases.
De Weg Vooruit: Toekomstbestendige Data Pijplijnen
De integratie van real-time data streaming, AI-automatisering en vector databases biedt transformatief potentieel voor bedrijven. Voor AI-automatisering stelt het integreren van real-time datastromen met frameworks zoals TensorFlow of PyTorch bedrijven in staat tot real-time besluitvorming en continue modelupdates. Voor real-time contextuele gegevensopslag biedt het gebruik van databases zoals Faiss of Milvus hulp bij snelle semantische zoekopdrachten, die cruciaal zijn voor toepassingen zoals RAG.
Conclusie
Belangrijke inzichten zijn de cruciale rol van tools zoals Apache Kafka en Apache Flink voor schaalbare, lage latentie data streaming, samen met TensorFlow of PyTorch voor real-time AI-automatisering, en FAISS of Milvus voor snelle semantische zoekopdrachten in toepassingen zoals RAG. Het waarborgen van gegevenskwaliteit, het automatiseren van workflows met tools zoals Apache Airflow, en het implementeren van robuuste monitoring en fouttolerantie mechanismen zullen bedrijven helpen om wendbaar te blijven in een data-gedreven wereld en hun besluitvormingscapaciteiten te optimaliseren.
Additional resources:
- AI Automation Essentials door Tuhin Chattopadhyay, DZone Refcard
- Essentie van Apache Kafka door Sudip Sengupta, DZone Refcard
- Aan de slag met Grote Taalmodellen door Tuhin Chattopadhyay, DZone Refcard
- Aan de slag met Vector Databases door Miguel Garcia, DZone Refcard
Dit is een uittreksel uit DZone’s Trendrapport 2024,
Data Engineering: Verrijken van Data Pipelines, Uitbreiden van AI en Versnellen van Analytics.
Source:
https://dzone.com/articles/the-data-pipeline-movement