













In het data-gedreven wereld van vandaag de dag moeten bedrijven zich aanpassen aan de snel veranderende manier waarop data wordt beheerd, geanalyseerd en gebruikt. traditionele centraliseerde systemen en monolithische architecturen, hoewel historisch voldoende waren, zijn niet langer voldoende om aan de groeiende verwachtingen van organisaties die sneller, realtime toegang tot data-inzichten nodig hebben. Een revolutie in dit gebied is de gebeurtenisgebaseerde datamesh-architectuur, en bij combinatie met AWS-diensten wordt het een robuuste oplossing voor het adresseren van complexe data-beheer uitdagingen.
Het Data Dilemma
Veel organisaties worden geconfronteerd met significante uitdagingen wanneer ze op oude data-architecturen vertrouwen. Deze uitdagingen omvatten:
Centraliseerde, Monolithische en domeinagnostische Data Lake
Een centraliseerdedata lake is een enkele opslaglocatie voor al uw data, waardoor het gemakkelijk te beheren en te bereiken is, maar het kan mogelijk performantieproblemen geven als dit niet goed gescaald wordt. Een monolithische data lake combineert alle data-verwerkingstaken in één geïntegreerd systeem, wat het opzetten gemakkelijker maakt maar moeilijker te schalen en onderhouden kan zijn. Een domeinagnostische data lake is ontworpen om data uit elke sector of bron op te slaan, biedende flexibiliteit en breed toepasselijkheid, maar kan complexer zijn om te beheren en minder geconfigureerd zijn voor specifieke toepassingen.
Falen van traditionele architectuur drukpunten
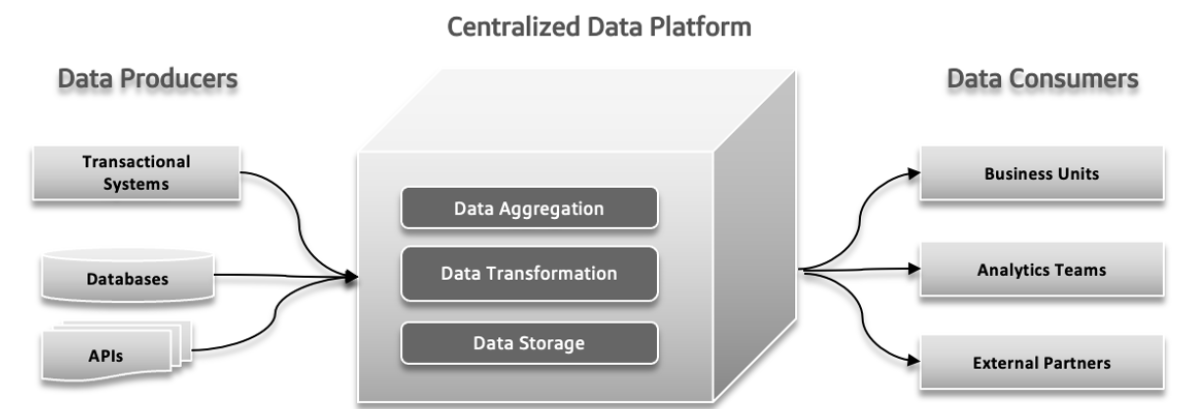
In traditionele databestandensystemen kunnen verschillende problemen optreden. Data-producenten kunnen grote hoeveelheden data of data met fouten verzenden, wat problemen op de benedenste verdiepingen veroorzaakt. Met de toenemende complexiteit van data en de deelname van meer diverse bronnen aan het systeem, kan de centrale dataplatform kan het moeilijk om de groeiende belasting te handhaven, wat resulteert in crashes en langzame prestaties. De toenemende vraag naar snelle experimenten kan het systeem overbelasten, waardoor het moeilijk is om snel te adapteren en nieuwe ideeën uit te testen. Data-reactietijden kunnen een uitdaging worden, waardoor vertragingen optreden bij het toegang en gebruik van data, wat de besluitvorming en de algehele efficiëntie beïnvloedt.
Verschillen Tussen operationele en analytische Datagebieden
In software-architectuur kunnen problemen zoals gecentraliseerde beheer, onduidelijke data-gebruik, zeer versmolten data-pipelines en inherente beperkingen significante problemen veroorzaken. Gecentraliseerde beheer komt voor wanneer verschillende teams in isolatie werken, wat leidt tot coördinatiewijzigingen en inefficiëntie. Het ontbreken van een duidelijke kennis van hoe data moet worden gebruikt of gedeeld kan resulteren in gekopieerde pogingen en inconsistente resultaten. Versmolten data-pipelines, waarin componenten te afhankelijk zijn van elkaar, maken het moeilijk om het systeem aan te passen of uit te breiden, wat tot vertragingen leidt. Als laatste, zijn er inherente beperkingen in het systeem die de levering van nieuwe functies en updates vertragen, wat de algehele vooruitgang behindert. Het aanpakken van deze drukpunten is crucial voor een meer efficiënte en responsieve ontwikkelingsproces.
Moeilijkheden Met Big Data
Online Analytische Processen (OLAP) systemen organiseren data in zodat het gemakkelijker is voor analyseurs om verschillende aspecten van de data te verkennen. Om vragen te beantwoorden, moeten deze systemen operationele data transformeren in een format dat geschikt is voor analyse en het behandelen van grote hoeveelheden data. Traditionele datawarehouses gebruiken ETL (Extraheer, Transformeer, Laad) processen om dit te beheren. Big data technologieën, zoals Apache Hadoop, hebben datawarehouses verbeterd door aan schaalbaarheidsproblemen te komen en open source te zijn, wat iedere bedrijf toegestaan maakte ze te gebruiken zolang ze de infrastructureel konden behandelen. Hadoop introduceerde een nieuwe aanpak door ongestructuurde of semi-gestructuurde data toe te staan in plaats van een strenge schema vooraf te forceren. Deze flexibiliteit, waar data konden worden geschreven zonder een vooraf gedefinieerd schema en later tijdens het opvragen georganiseerd werden, maakte het gemakkelijker voor data engineers om data te behandelen en te integreren. Het adopteren van Hadoop betekende vaak het vormen van een apart data team: data engineers behandelden data-extractie, data scientists hielden clean-up en herstructurering in handen, en data analysts uitvoerden analytics. Dit configuratie soms leidde tot problemen door beperkte communicatie tussen het data team en de toepassingsontwikkelaars, vaak om de productie systemen niet aan te kunnen raken.
Probleem 1: Issues With Data Model Boundaries
De gegevens die worden gebruikt voor analyse zijn nauw verbonden met hun oorspronkelijke structuur, wat een probleem kan zijn met complexe, regelmatig bijgewerkte modellen. Wijzigingen in de datamodel beïnvloeden alle gebruikers, waardoor ze kwetsbaar zijn voor deze wijzigingen, vooral wanneer het model veel tabellen bevat.
Probleem 2: Slechte Gegevens, De Kosten van het Negeren van het probleem
Slechte gegevens worden meestal niet ontdekt totdat ze problemen veroorzaken in een schema, waardoor problemen zoals verkeerde gegevens typen optreden. Omdat validatie meestal pas aan het eind van het proces plaatsvindt, kunnen slechte gegevens door pijplijnen verspreid worden, resulterend in kostbare reparaties en onconsistente oplossingen. Slechte gegevens kan leiden tot significante zakelijk verlies, zoals factuurfouten die miljoenen kosten. Onderzoek toont aan dat slechte gegevens bedrijven ieder jaar trillioenen kosten, veel tijd opslaan voor kennisarbeiders en datawetenschappers.
Probleem 3: Onbestaande Enkele Eigendom
Applicatieontwikkelaars, die deskundigen zijn in de bron datamodel, delen meestal deze informatie niet met andere teams. hun verantwoordelijkheden eindigen vaak bij hun applicatie- en databasegrens. Data-engineers, die gegevens extractie en beweging beheren, werken meestal reactief en hebben beperkte controle over de gegevensbronnen. Data-analyisten, ver weg van ontwikkelaars, komen tegen moeilijkheden te staan met de gegevens die ze ontvangen, wat tot coördinatiewijzigingen en behoefte aan aparte oplossingen leidt.
Probleem 4: Aangepaste Gegevensverbindingen
In grote organisaties gebruiken verschillende teams dezelfde gegevens, maar ontwikkelen hun eigen processen om deze te beheren. Dit resulteert in meerdere kopieën van gegevens, elkemaal onafhankelijk beheerd, waardoor een geknoei ontstaat. Het wordt moeilijk om ETL- taken te volgen en de kwaliteit van de gegevens te waarborgen, waardoor nauwkeurigheid wordt verminderd door factoren als synchronisatieproblemen en minder veilige gegevensbronnen. Deze verspreide aanpak verspilde tijd, geld en kansen.
Data mesh helpt hiermee door gegevens als een product te behandelen met duidelijke schema’s, documentatie en standaardtoegang, waardoor het risico van slechte gegevens wordt verminderd en de nauwkeurigheid en efficiëntie van de gegevens worden verbeterd.
Data Mesh: Een moderne aanpak
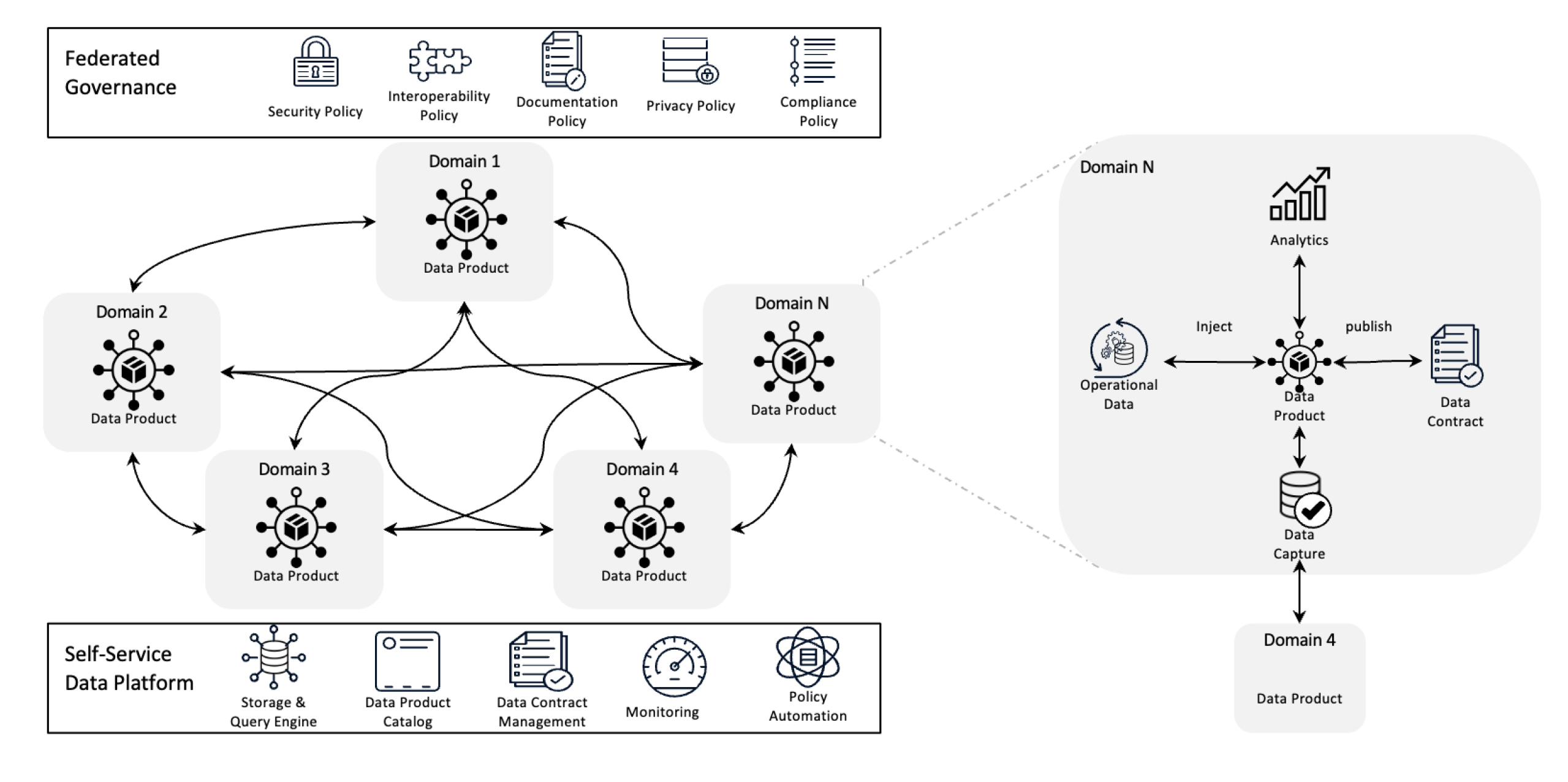
Data Mesh Architectuur
Data mesh herdefiniëert gegevensbeheer door de eigendomsverdeling decentral te maken en gegevens als een product te behandelen, ondersteund door zelfservice-infrastructure. Deze verandering geeft teams de macht om volledig controle te hebben over hun gegevens terwijl federated governance kwaliteit, compliantie en schaalbaarheid over de gehele organisatie waarborgt.
In simpele termen is het een architectuur framework dat is ontworpen om complexe gegevens uitdagingen op te lossen door gebruik te maken van decentrale eigendomsverdeling en gedistribueerde methodes. Het wordt gebruikt om gegevens van verschillende bedrijfsonderdelen te integreren voor alomvattende gegevensanalyse. Het is ook gebouwd op sterke gegevensuitwisselings- en -goedkeuringsbeleid.
Doelstellingen van Data Mesh
Data mesh helpt diverse organisaties bij het verkrijgen van waardevolle inzichten in data op schaal; kortom, het behandelen van een steeds veranderende data-landschap, de toenemende aantal data bronnen en gebruikers, de verscheidenheid aan nodige data transformaties en de behoefte snel aanpassingen te kunnen maken.
Data mesh lost alle hierboven genoemde problemen op door de controle decentral te laten. Zo kunnen teams hun eigen data beheren zonder dat ze geconfronteerd worden met isolatie in afzonderlijke afdelingen. Deze aanpak verbeterd de schaalbaarheid door de verdeling van data verwerking en opslag, waardoor vertragingen in een enkele centrale systemen worden voorkomen. Het versnellt inzichten doordat teams direct met hun eigen data kunnen werken, waardoor de vertragingen door een centrale team worden verminderd. Elke team neemt verantwoordelijkheid voor hun eigen data, wat de kwaliteit en consistentie boost. Door middel van gemakkelijk te begrijpen data producten en zelfservice tools, zorgt data mesh ervoor dat alle teams snel toegang krijgen en hun data kunnen beheren, leidend tot snellere, efficiëntere operaties en betere alignement met de bedrijfs behoeften.
Kernprincipes van Data Mesh
- Decentrale data eigendomsrechten: Teams beheren en eigense hun data producten, waardoor ze verantwoordelijk zijn voor hun kwaliteit en beschikbaarheid.
- Data als een product: Data wordt behandeld als een product met standaardisatie toegang, versienummers en schema definities, die consistentie en gemakkelijke gebruik door afdelingen waarborgen.
- Gedelegeerde governance: Beleidsregels worden gestelde om de data integriteit, beveiliging en compliantie te behouden, terwijl nog steeds deeltijd eigendomsrechten worden toegewezen.
- Zelfservice-infrastructuur: Teams hebben toegang tot schaalbare infrastructuur die de verwerking van data ondersteunt zonder doorblokkingen of afhankelijkheid van een centraal data-team.
Hoe Helpen Evenementen Data Mesh?
Evenementen helpen een data mesh door het delen en bijwerken van data in real-time mogelijk te maken. Wanneer er iets verandert in een gebied, notificeert een evenement de andere gebieden erover, zodat iedereen altijd op de hoogte blijft zonder directe verbindingen nodig. Dit maakt het systeem flexibeler en schaalbaarder omdat het veel data kunt verwerken en gemakkelijk kan aanpassen aan veranderingen. Evenementen maken het ook gemakkelijker om te volgen hoe data wordt gebruikt en beheerd, en laten elke team hun eigen data verwerken zonder afhankelijkheid van anderen.
Tenslotte laten we kijken naar de evenementen-gebaseerde data mesh architectuur.
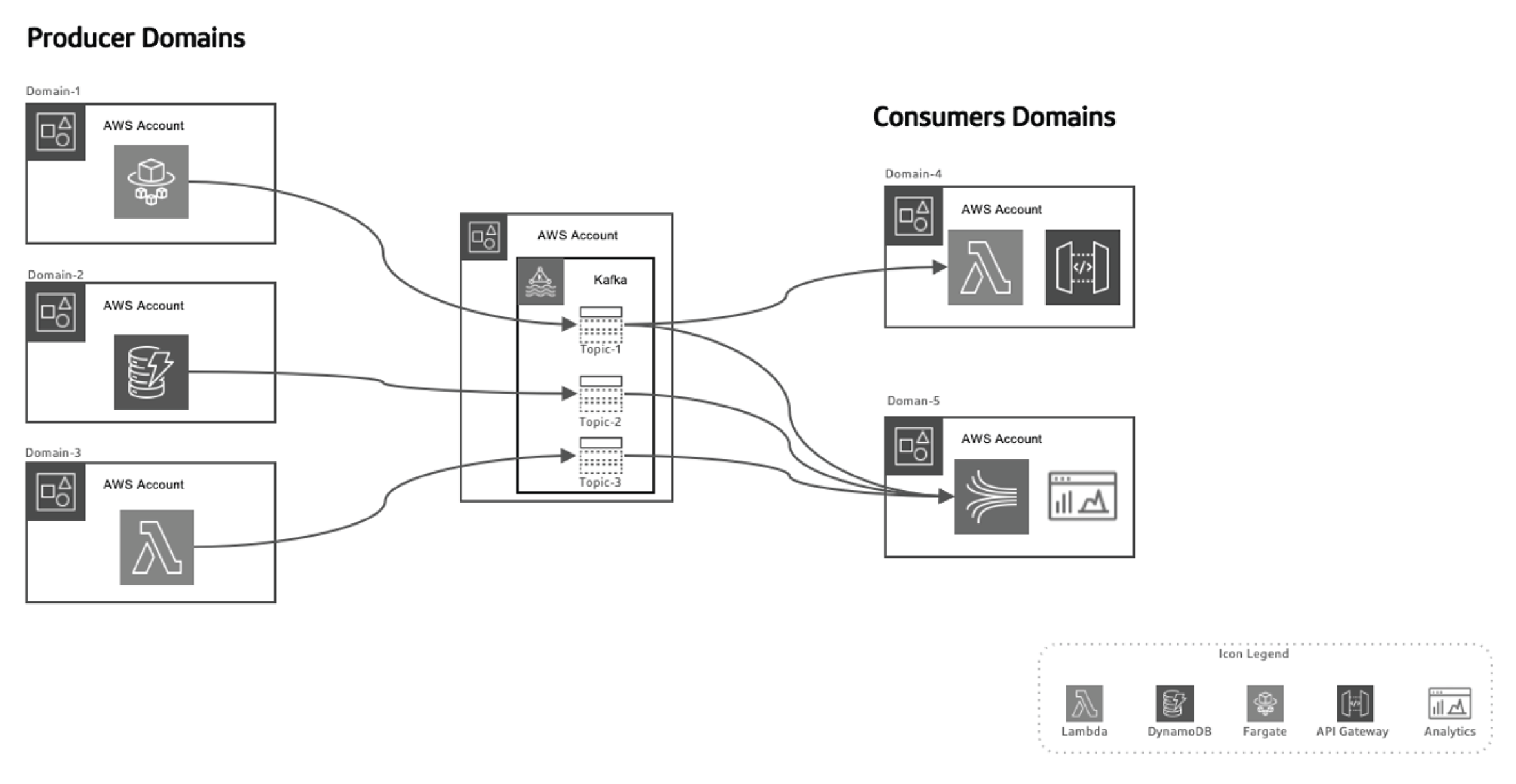
Deze evenementen-gebaseerde aanpak laat ons de data producers van de data consumenten scheiden, waardoor het systeem schaalbaarder wordt als domeinen over tijd evolueren zonder dat er grote veranderingen aan de architectuur nodig zijn. Producenten zijn verantwoordelijk voor het genereren van evenementen, die vervolgens naar een data-in-transit systeem worden verzonden. De streaming platform stelt zeker dat deze evenementen betrouwbaar worden afgehandeld. Wanneer een producent microservice of datastore een nieuw evenement publiceert, wordt het opgeslagen in een specifiek topic. Dit activeert luisteraars op de kant van de consumenten, zoals Lambda-functies of Kinesis, om het evenement te verwerken en het op de nodige manier te gebruiken.
Hebben We AWS Gebruikt voor Evenementen-gebaseerde Data Mesh Architectuur
AWS biedt een suite aan diensten die perfect aan de event-gebaseerde data mesh-model kunnen worden toegevoegd, waardoor organisaties hun data-infrastructuur kunnen schaalbaar maken, gegarandeerd real-time data-levering kunnen bieden en hoog niveaus van governance en beveiliging kunnen behouden.
Hieronder zie je hoe verschillende AWS-diensten in deze architectuur passen:
AWS Kinesis voor Real-Time Event Streaming
In een event-gebaseerde data mesh is real-time streaming een cruciale factor. AWS Kinesis biedt de mogelijkheid om op schaal real-time streaming data te verzamelen, te verwerken en te analyseren.
Kinesis biedt verschillende componenten:
- Kinesis Data Streams: Ontvang real-time gebeurtenissen en verwerkt ze met meerdere consumenten gelijktijdig.
- Kinesis Data Firehose: Levert eventstromen direct aan S3, Redshift of Elasticsearch voor verdere verwerking en analyse.
- Kinesis Data Analytics: Verwerkt data in real-time om on-the-fly inzichten te halen, waardoor directe terugkoppelingen mogelijk zijn in data-verwerkingspijplijnen.
AWS Lambda voor Event Processing
AWS Lambda is de kern van serverloze eventverwerking in de data mesh-architectuur. Met zijn mogelijkheid automatisch schalen en inkomende datastromen verwerken zonder behoefte aan serverbeheer,
Lambda is de ideale keuze voor:
- Processing Kinesis streams in real-time
- Invoke API Gateway requests in response to specific events
- Interact with DynamoDB, S3, or other AWS services to store, process, or analyze data
AWS SNS and SQS for Event Distribution
AWS Simple Notification Service (SNS) fungeert als het primaire evenementen-uitzendingssysteem, door real-time meldingen te versturen over gedistribueerde systemen. AWS Simple Queue Service (SQS) zorgt ervoor dat berichten tussen ontkoppelde services betrouwbaar worden afgeleverd, zelfs bij gedeeltelijke systeemstoringen. Deze services stellen ontkoppelde microservices in staat om te communiceren zonder directe afhankelijkheden, waardoor het systeem schaalbaar en fouttolerant blijft.
AWS DynamoDB voor Real-Time Gegevensbeheer
In gedecentraliseerde architecturen biedt DynamoDB een schaalbare, low-latency NoSQL-database die evenementengegevens in real-time kan opslaan, wat het ideaal maakt voor het opslaan van de resultaten van gegevensverwerkingspijplijnen. Het ondersteunt het Outbox-patroon, waarbij evenementen die door de applicatie worden gegenereerd, worden opgeslagen
in DynamoDB en geconsumeerd door de streamingdienst (bijv. Kinesis of Kafka).
AWS Glue voor Federated Data Catalog en ETL
AWS Glue biedt een volledig beheerde data catalog en ETL-service, essentieel voor federated data governance in de data mesh. Glue helpt bij het catalogiseren, voorbereiden en transformeren van gegevens in gedistribueerde domeinen, waardoor ontdekbaarheid, governance en integratie binnen de organisatie worden gewaarborgd.
AWS Lake Formation en S3 voor Data Lakes
Terwijl de data mesh architectuur afscheidt van centraliseerde data lakes, spelen S3 en AWS Lake Formation een cruciale rol in het opslaan, beveiligen en catalogiseren van data die tussen verschillende domeinen stroomt, waardoor langetermijnopslag, governance en compliantie worden gewaarborgd.
Eventge drijven Data Mesh in actie met AWS en Python
Eventproducent: AWS Kinesis + Python
In dit voorbeeld gebruiken we AWS Kinesis om gebeurtenissen te streamen wanneer een nieuwe klant wordt aangemaakt:
import boto3
import json
kinesis = boto3.client('kinesis')
def send_event(event):
kinesis.put_record(
StreamName="CustomerStream",
Data=json.dumps(event),
PartitionKey=event['customer_id']
)
def create_customer_event(customer_id, name):
event = {
'event_type': 'CustomerCreated',
'customer_id': customer_id,
'name': name
}
send_event(event)
# Simulate a new customer creation
create_customer_event('123', 'ABC XYZ')
Eventverwerking: AWS Lambda + Python
Deze Lambda-functie consumeert Kinesis-gebeurtenissen en verwerkt ze in realtime.
import json
import boto3
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('CustomerData')
def lambda_handler(event, context):
for record in event['Records']:
payload = json.loads(record['kinesis']['data'])
if payload['event_type'] == 'CustomerCreated':
process_customer_created(payload)
def process_customer_created(event):
table.put_item(
Item={
'customer_id': event['customer_id'],
'name': event['name']
}
)
print(f"Stored customer data: {event['customer_id']} - {event['name']}")
Conclusie
door middel van AWS-diensten zoals Kinesis, Lambda, DynamoDB en Glue, kunnen organisaties het gehele potentieel van de eventge drijvende data mesh architectuur volledig realiseren. Deze architectuur biedt agility, scalability en realtime inzichten, waardoor organisaties concurrerend blijven in het snel evoluerende data-landschap. Het aanvaarden van een eventge drijvende data mesh architectuur is niet alleen een technische verbetering maar een strategische noodzaak voor bedrijven die willen blijven bestaan in de era van grote data en verspreide systemen.
Source:
https://dzone.com/articles/event-driven-data-mesh-architecture-with-aws