













I came across one of the test cases in my previous projects where I had to click on a button to navigate to the next page. I searched for the element locator of the button on the page and ran the tests hoping it would click the button and navigate to the next page.
하지만 놀랍게도 테스트는 요소를 찾을 수 없어 실패했고, 콘솔 로그에서 NoSuchElementException을 받았습니다. 간단한 버튼을 클릭하려고 했는데 복잡성이 없었기 때문에 그 오류를 보게 되어 기분이 좋지 않았습니다.
문제를 좀 더 깊이 분석하고, DOM을 확장하고, 루트 요소를 확인하면서 버튼 찾기가 #shadow-root(open) 트리 노드 내부에 있음을 알게 되었습니다. 이로 인해 이것이 Shadow DOM 요소이기 때문에 다르게 처리해야 한다는 것을 깨달았습니다.
이 셀레늄 웹드라이버 튜토리얼에서는 Shadow DOM 요소와 셀레늄 웹드라이버에서 Shadow DOM을 자동화하는 방법에 대해 논의할 것입니다. 셀레늄에서 Shadow DOM을 자동화하기 전에 먼저 Shadow DOM이 무엇이고 왜 사용되는지 이해해 보겠습니다.
Shadow DOM이 무엇인가?
Shadow DOM은 웹 브라우저가 메인 문서 DOM 트리에 넣지 않고 DOM 요소를 렌더링할 수 있게 해주는 기능입니다. 이는 개발자와 브라우저가 접근할 수 있는 것 사이에 장벽을 만듭니다. 개발자는 중첩된 요소와 같은 방식으로 Shadow DOM에 접근할 수 없지만, 브라우저는 중첩된 요소와 같은 방식으로 해당 코드를 렌더링하고 수정할 수 있습니다.
Shadow DOM은 HTML 문서에서 캡슐화를 달성하는 방법입니다. 이를 구현함으로써 문서의 한 부분의 스타일과 동작을 다른 코드와 별도로 숨길 수 있으므로 간섭이 없습니다.
Shadow DOM은 일반 DOM 트리의 요소에 연결된 숨겨진 DOM 트리를 허용합니다. Shadow DOM 트리는 Shadow 루트로 시작하여 일반 DOM과 같은 방식으로 어떤 요소든 연결할 수 있습니다.
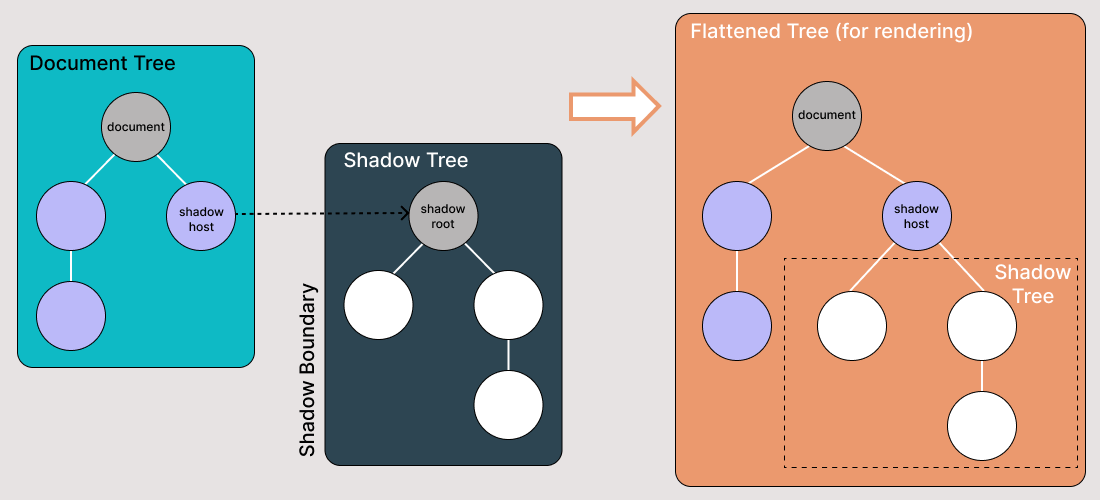
섀도우 DOM 용어의 몇 가지 조각에 대해 알아야 합니다:
- 섀도우 호스트: 섀도우 DOM이 연결된 일반 DOM 노드
- 섀도우 트리: 섀도우 DOM 내부의 DOM 트리
- 섀도우 경계는 섀도우 DOM이 끝나고 일반 DOM이 시작되는 곳입니다.
- 섀도우 루트: 섀도우 트리의 루트 노드
섀도우 DOM의 사용법은 무엇인가?
섀도우 DOM은 캡슐화를 위해 사용됩니다. 이를 통해 컴포넌트는 메인 문서에서 실수로 접근할 수 없고, 로컬 스타일 규칙을 가질 수 있는 자체 “섀도우” DOM 트리를 가질 수 있습니다.
다음은 섀도우 DOM의 몇 가지 핵심 속성입니다:
- 자체 id 공간을 가짐
- 메인 문서의 JavaScript 선택기에서 보이지 않음, 예를 들어 querySelector
- 메인 문서의 스타일이 아닌 섀도우 트리의 스타일만 사용
Selenium WebDriver를 사용하여 섀도우 DOM 요소 찾기
Selenium 로케이터를 사용하여 섀도우 DOM 요소를 찾으려고 하면, NoSuchElementException이 발생합니다. 이는 DOM에서 직접 접근할 수 없기 때문입니다.
섀도우 DOM 로케이터에 접근하기 위해 다음과 같은 전략을 사용합니다:
- JavaScriptExecutor 사용.
- Selenium WebDriver의
getShadowDom()메서드 사용.
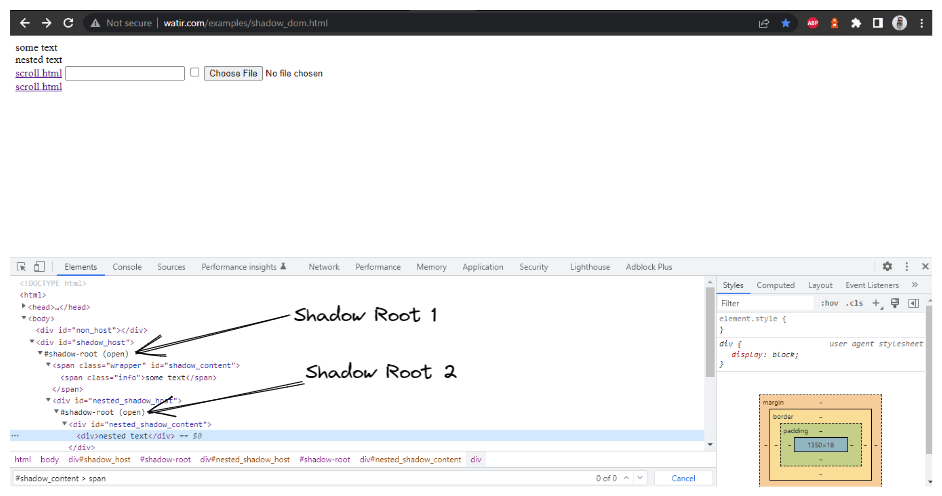
이 블로그 섹션에서는 Selenium에서 Shadow DOM을 자동화하는 방법을 살펴보겠습니다. Watir.com의 홈페이지를 예로 들어 Shadow DOM 및 중첩된 Shadow DOM 텍스트를 Selenium WebDriver로 확인해보겠습니다. 텍스트 -> 어떤 텍스트에 도달하기 전에 하나의 Shadow root 요소가 있으며, -> 중첩된 텍스트 텍스트에 도달하기 전에 두 개의 Shadow root 요소가 있습니다.
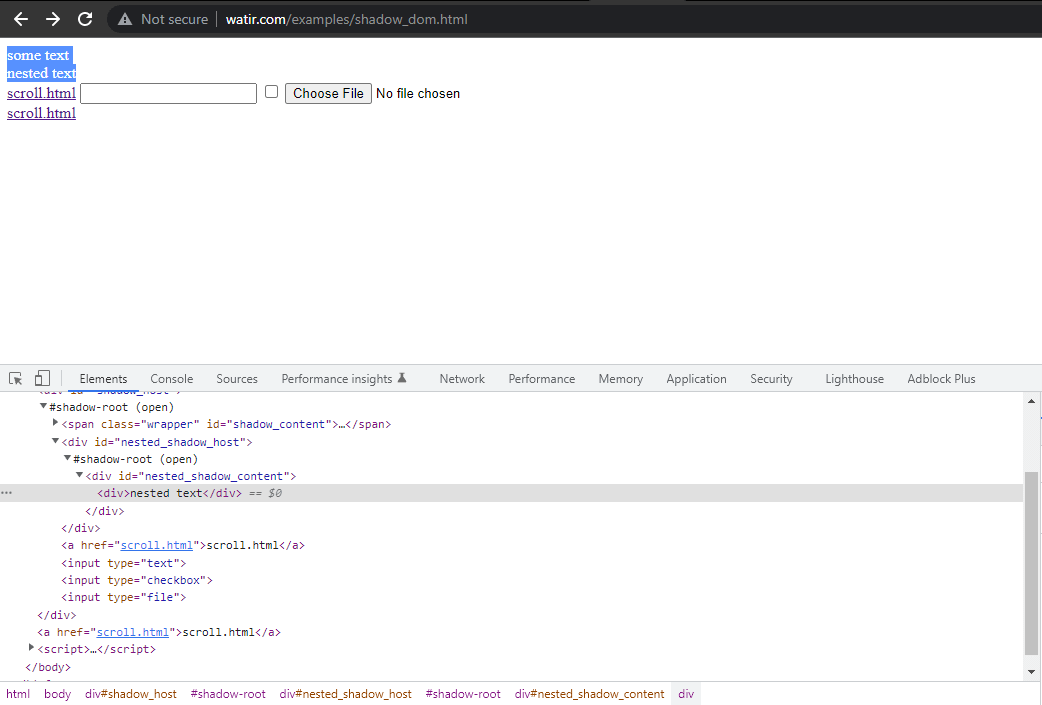
이제 cssSelector("#shadow_content > span")를 사용하여 요소를 찾으려고 하면,
해당 요소를 찾을 수 없으며 Selenium WebDriver는 NoSuchElementException을 던집니다.
다음은 홈페이지 클래스의 스크린샷으로, cssSelector(“#shadow_content > span”)를 사용하여 텍스트를 가져오려고 시도하는 코드가 있습니다.

다음은 텍스트(“어떤 텍스트”)를 확인하려고 시도하는 테스트의 스크린샷입니다.
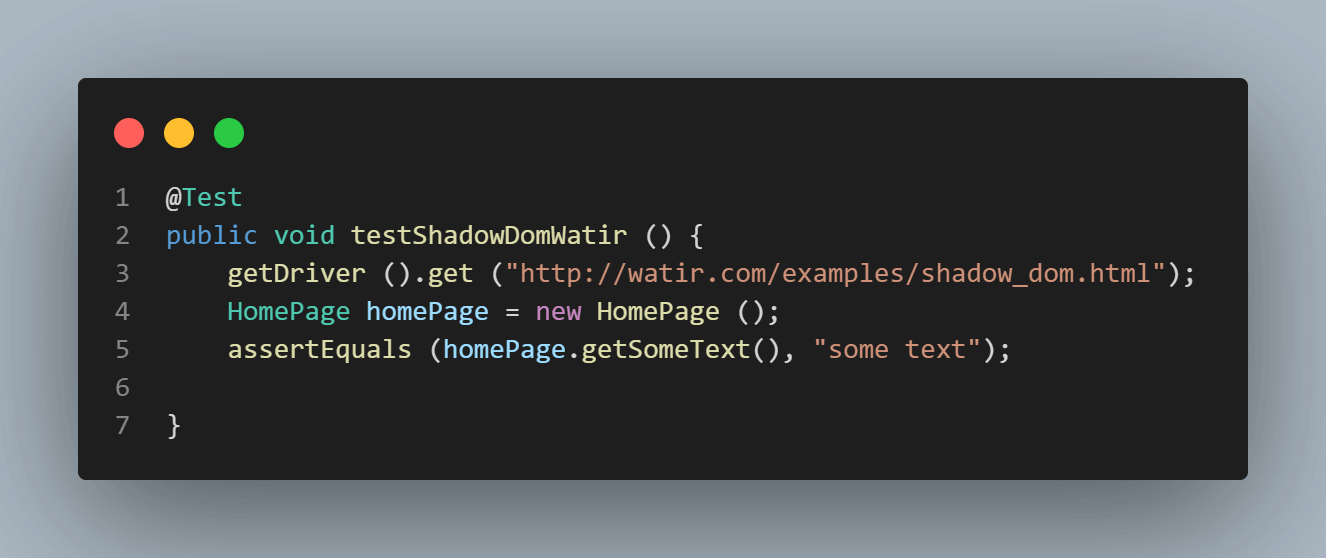
테스트 실행 중 발생한 오류는 NoSuchElementException입니다
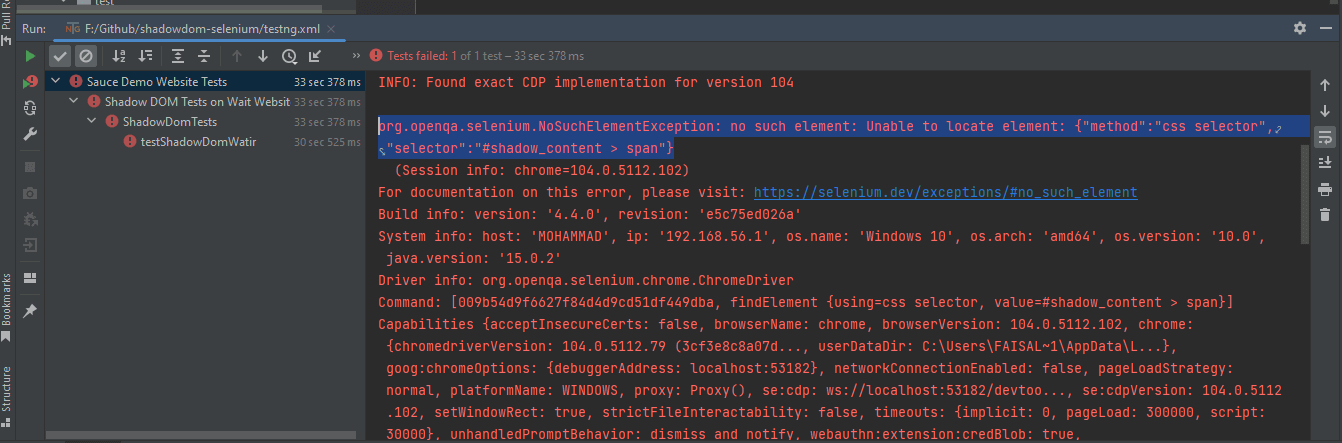
요소를 올바르게 찾으려면 Shadow root 요소를 거쳐야 합니다. 그런 다음에야 페이지에서 “어떤 텍스트” 및 “중첩된 텍스트”를 찾을 수 있습니다.
Selenium WebDriver에서 ‘getShadowDom’ 메서드를 사용하여 Shadow DOM을 찾는 방법
Selenium WebDriver 버전 4.0.0 이상의 출시와 함께 getShadowRoot() 메서드가 소개되어 Shadow root 요소를 찾는 데 도움이 되었습니다.
다음은 getShadowRoot() 메서드의 구문과 세부 사항입니다:
default SearchContext getShadowRoot()
Returns:
The ShadowRoot class represents the shadow root of a web component. With a shadow root, you can access the shadow DOM of a web component.
Throws:
NoSuchShadowRootException - If shadow root is not found.문서에 따르면 getShadowRoot() 메서드는 웹 구성요소의 Shadow DOM에 접근하기 위해 요소의 Shadow root의 표현을 반환합니다.
Shadow root를 찾을 수 없는 경우, NoSuchShadowRootException을 던집니다.
테스트를 작성하고 코드를 논의하기 전에 테스트를 작성하고 실행하는 데 사용할 도구에 대해 말씀드리겠습니다:
다음 프로그래밍 언어와 도구가 테스트를 작성하고 실행하는 데 사용되었습니다:
- 프로그래밍 언어: Java 11
- 웹 자동화 도구: Selenium WebDriver
- 테스트 실행기: TestNG
- 빌드 도구: Maven
- 클라우드 플랫폼: LambdaTest
Selenium WebDriver에서 Shadow DOM 찾기 시작하기
앞서 논의한 바와 같이, 이 Shadow DOM in Selenium 프로젝트는 Maven. TestNG를 테스트 실행기로 사용하여 생성되었습니다. Maven에 대해 자세히 알고 싶으시다면 Selenium 테스팅을 위한 Maven 시작하기에 대한 이 블로그를 확인하세요.
프로젝트가 생성되면 Selenium WebDriver 및 TestNG에 대한 의존성을 pom.xml 파일에 추가해야 합니다.
의존성 버전은 별도의 속성 블록에 설정되어 있습니다. 이렇게 하는 이유는 유지 보수성을 위해서로, 의존성을 전체 pom.xml 파일에서 검색하지 않고도 버전을 업데이트할 수 있게 해주기 때문입니다.
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>io.github.mfaisalkhatri</groupId>
<artifactId>shadowdom-selenium</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<selenium.java.version>4.4.0</selenium.java.version>
<testng.version>7.6.1</testng.version>
<webdrivermanager.version>5.2.1</webdrivermanager.version>
<maven.compiler.version>3.10.1</maven.compiler.version>
<surefire-version>3.0.0-M7</surefire-version>
<java.release.version>11</java.release.version>
<maven.source.encoding>UTF-8</maven.source.encoding>
<suite-xml>testng.xml</suite-xml>
<argLine>-Dfile.encoding=UTF-8 -Xdebug -Xnoagent</argLine>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.seleniumhq.selenium/selenium-java -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>${selenium.java.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.testng/testng -->
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>${testng.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.github.bonigarcia</groupId>
<artifactId>webdrivermanager</artifactId>
<version>${webdrivermanager.version}</version>
<exclusions>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>${maven.compiler.version}</version>
<configuration>
<release>${java.release.version}</release>
<encoding>${maven.source.encoding}</encoding>
<forceJavacCompilerUse>true</forceJavacCompilerUse>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>${surefire-version}</version>
<executions>
<execution>
<goals>
<goal>test</goal>
</goals>
</execution>
</executions>
<configuration>
<useSystemClassLoader>false</useSystemClassLoader>
<properties>
<property>
<name>usedefaultlisteners</name>
<value>false</value>
</property>
</properties>
<suiteXmlFiles>
<suiteXmlFile>${suite-xml}</suiteXmlFile>
</suiteXmlFiles>
<argLine>${argLine}</argLine>
</configuration>
</plugin>
</plugins>
</build>
</project>이제 코드로 넘어가 보겠습니다. 이 프로젝트에서는 코드 중복을 줄이고 테스트 케이스 유지 보수를 개선하는 데 도움이 되는 페이지 오브젝트 모델(POM)을 사용했습니다.
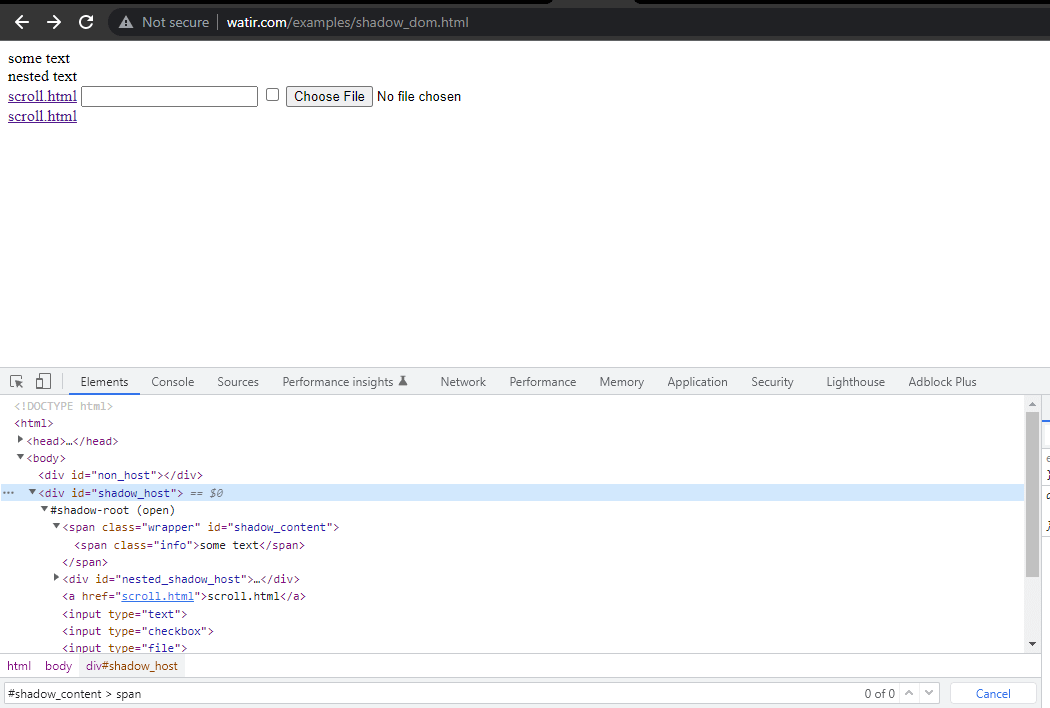
먼저 HomePage에서 ” some text “와 ” nested text “의 위치를 찾겠습니다.
public class HomePage {
public SearchContext expandRootElement (WebElement element) {
SearchContext shadowRoot = (SearchContext) ((JavascriptExecutor) getDriver ()).executeScript (
"return arguments[0].shadowRoot", element);
return shadowRoot;
}
public String getSomeText () {
return getDriver ().findElement (By.cssSelector ("#shadow_content > span"))
.getText ();
}
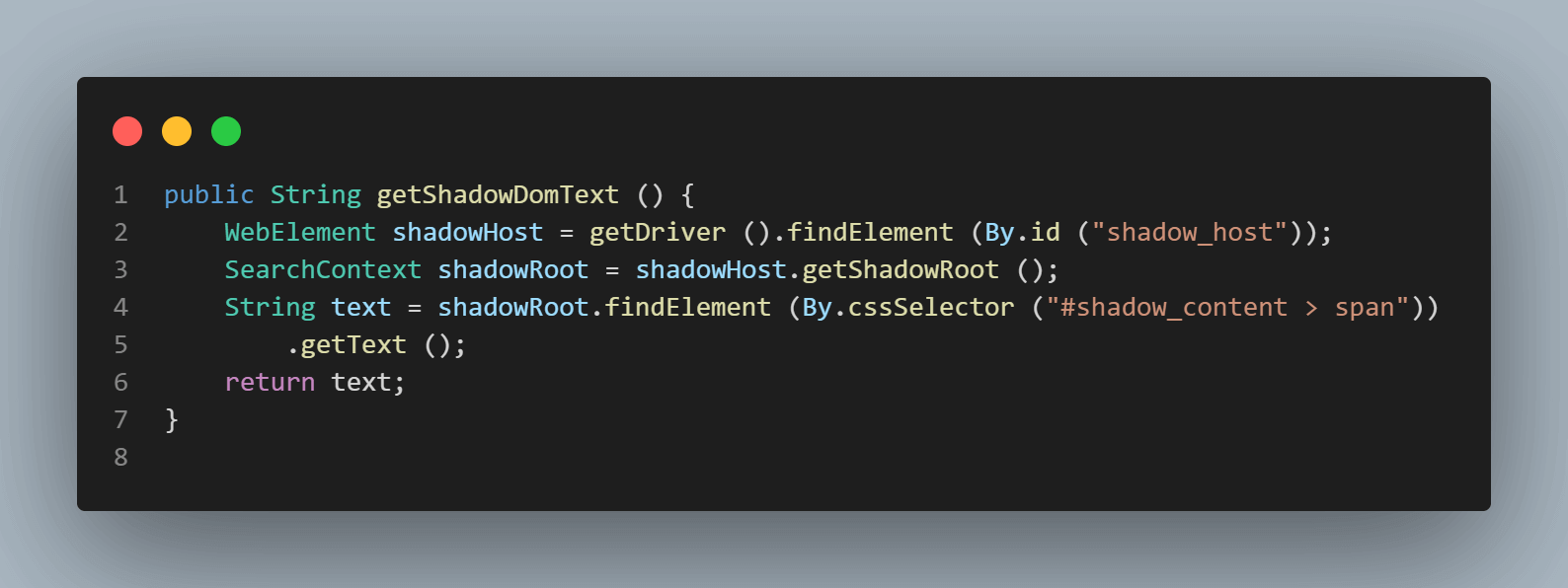
public String getShadowDomText () {
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRoot = shadowHost.getShadowRoot ();
String text = shadowRoot.findElement (By.cssSelector ("#shadow_content > span"))
.getText ();
return text;
}
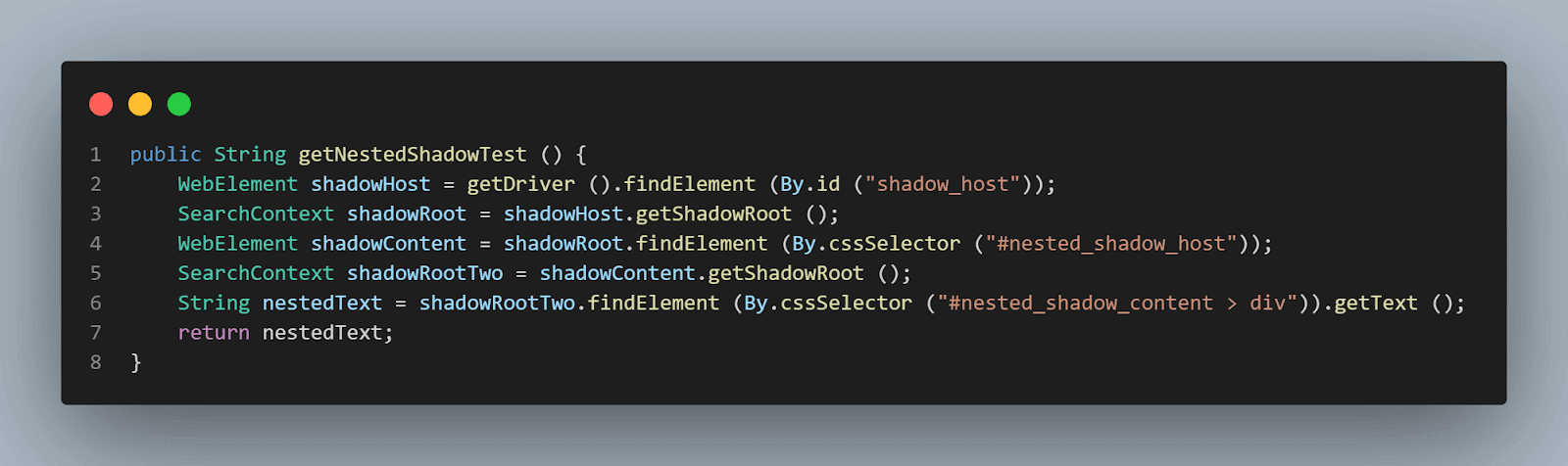
public String getNestedShadowText () {
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRoot = shadowHost.getShadowRoot ();
WebElement shadowContent = shadowRoot.findElement (By.cssSelector ("#nested_shadow_host"));
SearchContext shadowRootTwo = shadowContent.getShadowRoot ();
String nestedText = shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div")).getText ();
return nestedText;
}
public String getNestedText() {
WebElement nestedText = getDriver ().findElement (By.id ("shadow_host")).getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_host")).getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_content > div"));
return nestedText.getText ();
}
public String getNestedTextUsingJSExecutor () {
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRootOne = expandRootElement (shadowHost);
WebElement nestedShadowHost = shadowRootOne.findElement (By.cssSelector ("#nested_shadow_host"));
SearchContext shadowRootTwo = expandRootElement (nestedShadowHost);
return shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div"))
.getText ();
}
}Code Walkthrough
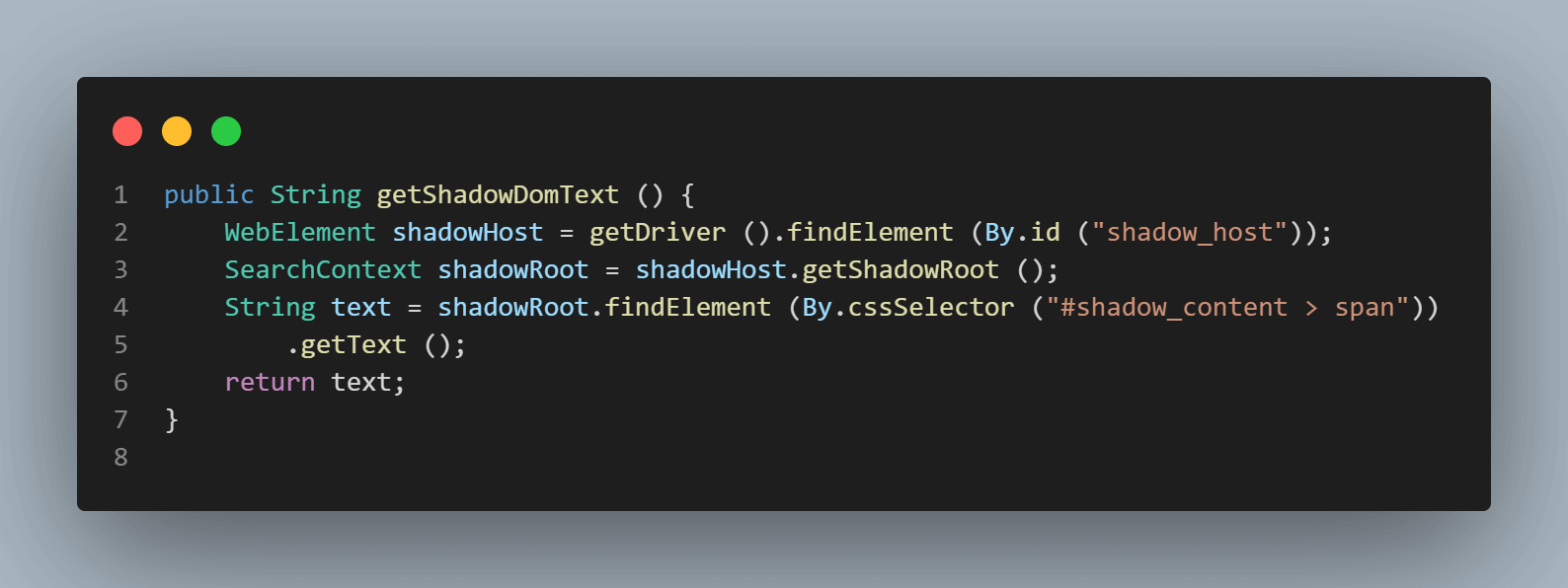
우선 < div id = "shadow_host" > 내부의 첫 번째 요소를 위치시킬 것입니다. 이를 위해 위치 전략 – id를 사용했습니다.
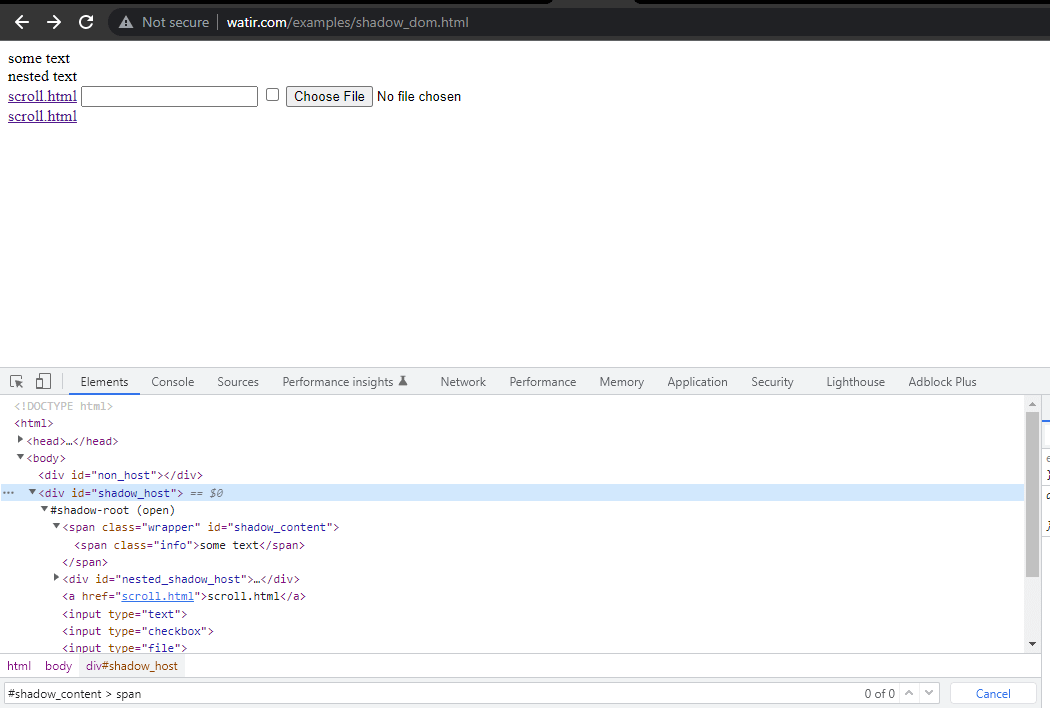
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));다음으로 DOM에서 그 옆에 있는 첫 번째 Shadow Root를 검색합니다. 이를 위해 SearchContext 인터페이스를 사용했습니다. Shadow Root는 getShadowRoot() 메서드를 사용하여 반환됩니다. 위의 스크린샷을 확인하면 #shadow-root (open)가 < div id = "shadow_host" > 옆에 있음을 알 수 있습니다.
텍스트 – ” some text, “를 찾기 위해서는 하나의 Shadow DOM 요소만 통과해야 합니다.
다음 코드 줄은 우리에게 Shadow root 요소를 얻는 데 도움이 됩니다.
SearchContext shadowRoot = downloadsManager.getShadowRoot();Shadow Root가 발견되면 텍스트 – ” some text “를 찾을 요소를 검색할 수 있습니다. 다음 코드 줄은 우리에게 텍스트를 얻는 데 도움이 됩니다.
String text = shadowRoot.findElement (By.cssSelector ("#shadow_content > span"))
.getText ();다음으로, “중첩된 텍스트,“의 위치를 찾아보겠습니다. 이 텍스트는 중첩된 Shadow root 요소를 가지고 있으며, 이 요소를 어떻게 찾을 수 있는지 알아보겠습니다.
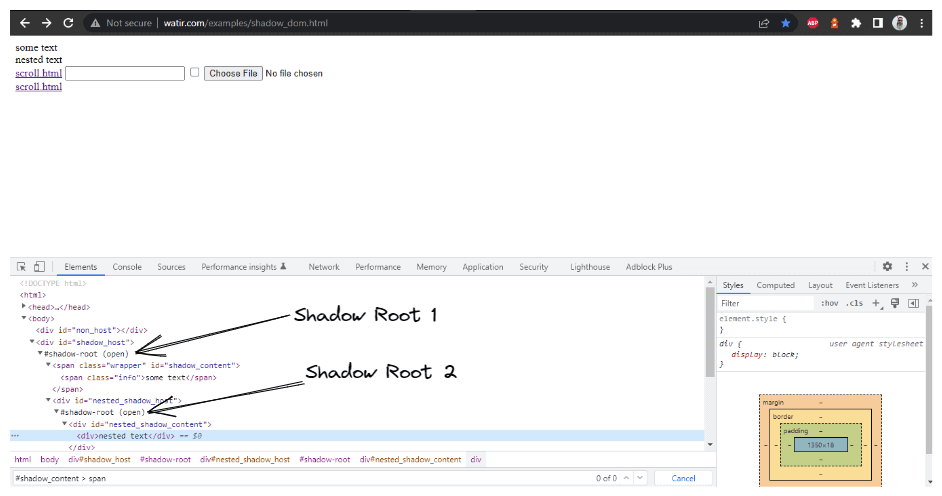
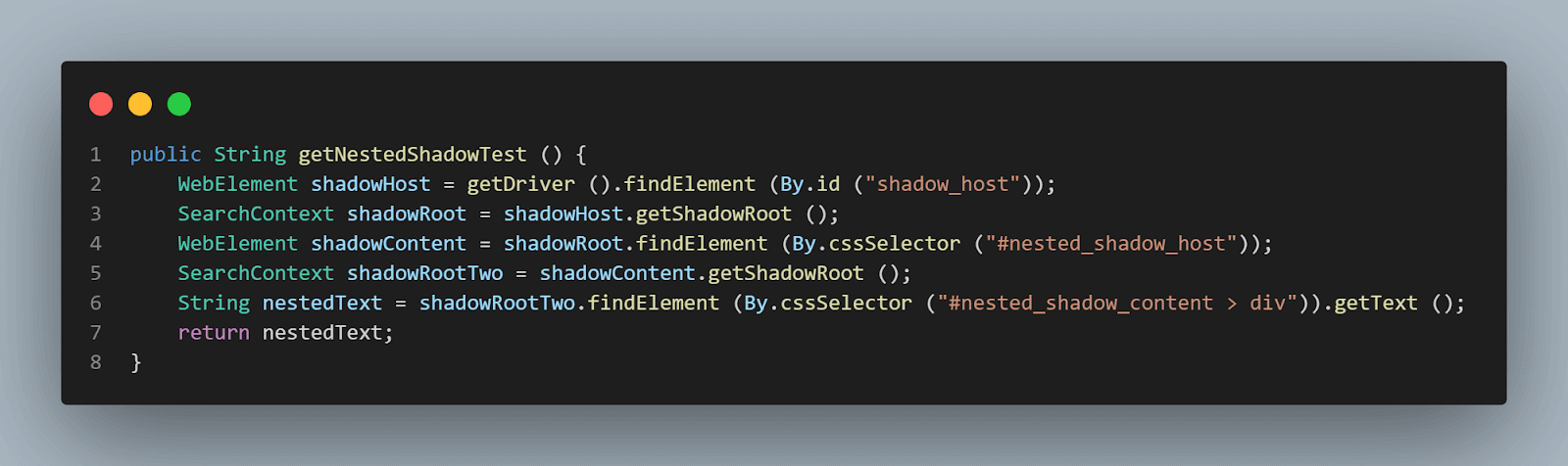
getNestedShadowText() 메서드:
위의 섹션에서 논의한 대로 시작하여, 위치 전략을 사용하여 < div id = "shadow_host" >를 찾아야 합니다. – id.
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));그 후, getShadowRoot() 메서드를 사용하여 Shadow Root 요소를 찾아야 합니다; Shadow root 요소를 얻은 후에는 cssSelector를 사용하여 두 번째 Shadow root를 찾아야 합니다:
<div id ="nested_shadow_host">
SearchContext shadowRoot = shadowHost.getShadowRoot ();
WebElement shadowContent = shadowRoot.findElement (By.cssSelector ("#nested_shadow_host")); 다음으로, getShadowRoot() 메서드를 사용하여 두 번째 Shadow Root 요소를 찾아야 합니다. 마지막으로, 실제 요소를 찾아서 텍스트 – “중첩된 텍스트.”를 얻을 시간입니다.
다음 코드 라인은 텍스트를 찾는 데 도움이 됩니다:
SearchContext shadowRootTwo = shadowContent.getShadowRoot ();
String nestedText = shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div"코드를 유연하게 작성하기
이 블로그의 Shadow DOM in Selenium 섹션에서 우리는 실제로 작업하고자 하는 요소를 찾아야 하는 긴 과정을 살펴보았으며, WebElement 및 SearchContext 인터페이스의 여러 초기화를 수행하고 하나의 요소를 찾아 작업하기 위해 여러 줄의 코드를 작성해야 했습니다.
이 모든 코드를 유연하게 작성할 수도 있으며, 다음과 같이 할 수 있습니다:
public String getNestedText() {
WebElement nestedText = getDriver ().findElement (By.id ("shadow_host"))
.getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_host"))
.getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_content > div"));
return nestedText.getText ();
}‘플루언트 인터페이스’의 디자인은 방대하게 메서드 체이닝에 의존합니다. 플루언트 인터페이스 패턴은 기술적으로 코드를 이해하지 않고도 읽기 쉬운 코드를 작성할 수 있게 도와줍니다. 이 용어는 2005년에 Eric Evans와 Martin Fowler에 의해 처음으로 만들어졌습니다.
우리가 원하는 요소를 찾기 위해 수행할 메서드 체이닝입니다.
이 코드는 위의 단계들과 동일한 작업을 수행합니다.
- 먼저 id를 사용하여 shadow_host 요소를 찾은 다음,
getShadowRoot()메서드를 사용하여 Shadow Root 요소를 얻겠습니다. - 다음으로, CSS 선택자를 사용하여 nested_shadow_host 요소를 검색하고,
getShadowRoot()메서드를 사용하여 Shadow Root 요소를 얻겠습니다. - 마지막으로, cssSelector – nested_shadow_content > div를 사용하여 “중첩 텍스트“를 얻겠습니다.
JavaScriptExecutor를 사용하여 Selenium에서 Shadow DOM 찾기
위의 코드 예시에서는 getShadowRoot() 메서드를 사용하여 요소를 찾았습니다. 이제 Selenium WebDriver에서 JavaScriptExecutor를 사용하여 Shadow root 요소를 어떻게 찾을 수 있는지 알아보겠습니다.
getNestedTextUsingJSExecutor() 메서드가 HomePage 클래스 내부에 생성되었으며,
여기서 우리는 매개변수로 전달된 WebElement를 기반으로 Shadow Root 요소를 확장할 것입니다. DOM에서(위의 스크린샷에서 볼 수 있듯이), 텍스트를 가져오기 위한 실제 로케이터에 도달하기 전에 두 개의 Shadow Root 요소를 확장해야 했습니다. 따라서 매번 같은 JavaScript 실행기 코드를 복사 붙여넣기하는 대신 expandRootElement() 메서드가 생성되었습니다.
우리는 JavaScriptExecutor와 함께 도움을 줄 것인 SearchContext 인터페이스를 구현할 것이며, 이는 매개변수로 전달된 WebElement를 기반으로 Shadow root 요소를 반환할 것입니다.
public SearchContext expandRootElement (WebElement element) {
SearchContext shadowRoot = (SearchContext) ((JavascriptExecutor) getDriver ()).executeScript (
"return arguments[0].shadowRoot", element);
return shadowRoot;
}
getNestedTextUsingJSExecutor() 메서드
우리가 처음으로 찾을 요소는 < div id = "shadow_host" >로, 로케이터 전략으로 id를 사용합니다.
다음으로, 우리가 찾은 shadow_host WebElement를 기반으로 Root 요소를 확장할 것입니다.
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRootOne = expandRootElement (shadowHost);Shadow Root를 한 번 확장한 후, cssSelector를 사용하여 다음을 찾을 수 있습니다.
<div id ="nested_shadow_host">
WebElement nestedShadowHost = shadowRootOne.findElement (By.cssSelector ("#nested_shadow_host"));
SearchContext shadowRootTwo = expandRootElement (nestedShadowHost);마지막으로, 이제 텍스트를 가져오기 위한 실제 요소를 찾을 시간입니다. – “중첩된 텍스트.”
다음 코드 라인은 텍스트를 찾는 데 도움이 됩니다.
shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div"))
.getText ();데모
이 글에서 Selenium의 Shadow DOM에 관한 이 섹션에서는 빠르게 테스트를 작성하고 이전 단계에서 찾은 위치 지정자가 우리에게 필요한 텍스트를 제공하는지 확인해 보겠습니다. 우리는 작성한 코드에 대한 확인을 실행하여 코드에서 기대하는 내용이 작동하는지 확인할 수 있습니다.
@Test
public void testShadowDomWatir () {
getDriver ().get ("http://watir.com/examples/shadow_dom.html");
HomePage homePage = new HomePage ();
// assertEquals (homePage.getSomeText(), "some text");
assertEquals (homePage.getShadowDomText (), "some text");
assertEquals (homePage.getNestedShadowText (),"nested text");
assertEquals (homePage.getNestedText (), "nested text");
assertEquals (homePage.getNestedTextUsingJSExecutor (), "nested text");
}이는 텍스트가 예상대로 정확하게 표시되는지 확인하기 위한 간단한 테스트입니다. TestNG에서 assertEquals() 어설션을 사용하여 확인할 것입니다.
실제 값으로는 페이지에서 텍스트를 가져오는 방법을 제공하고, 예상 값으로는 “some text” 또는 “nested text,” 어설션을 수행할 때 달라지는 텍스트를 전달합니다.
테스트에서 제공되는 assertEquals 문은 네 가지입니다.
- Shadow DOM 요소를
getShadowRoot()메서드를 사용하여 확인:
- 중첩된 Shadow DOM 요소를
getShadowRoot()메서드를 사용하여 확인:
- 중첩된 Shadow DOM 요소를
getShadowRoot()메서드를 사용하여 유연하게 작성:
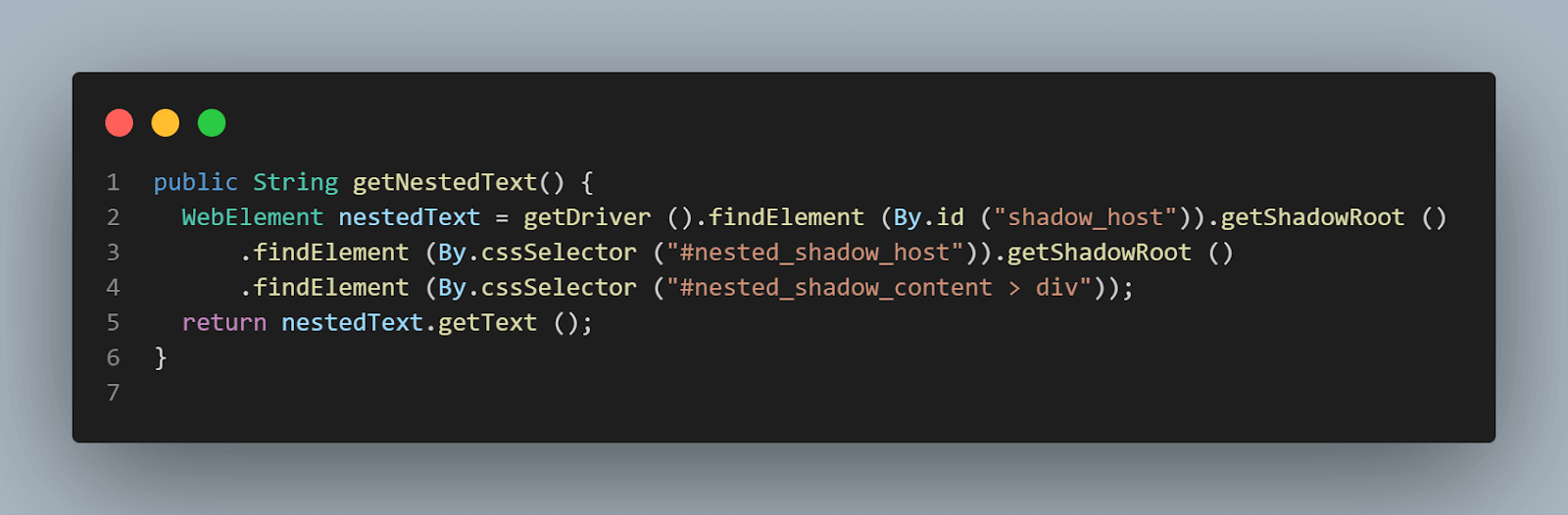
실행
Selenium에서 Shadow DOM을 자동화하기 위한 테스트를 실행하는 두 가지 방법이 있습니다:
- TestNG를 사용하여 IDE에서
- Maven을 사용하여 CLI에서
TestNG를 사용하여 Selenium WebDriver에서 Shadow DOM 자동화
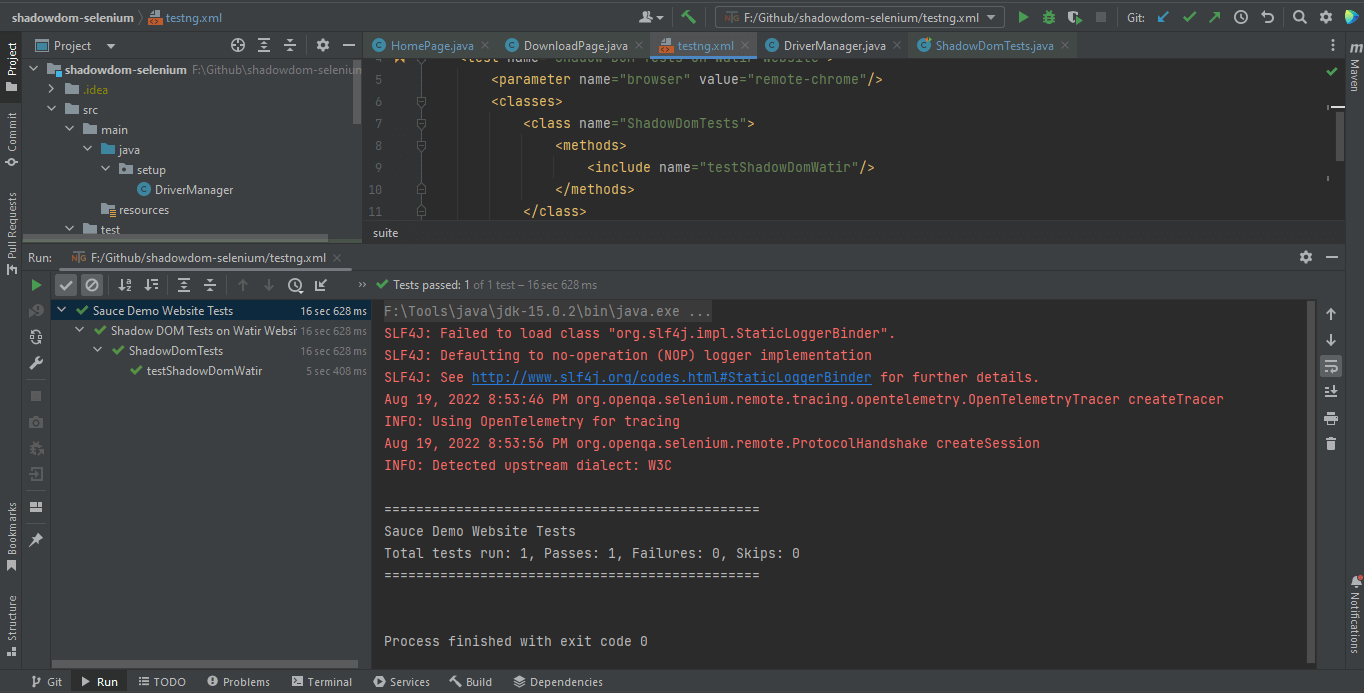
TestNG를 테스트 실행기로 사용하므로 testng.xml 파일을 생성하였고, 이를 통해 파일을 우클릭하고 Run ‘…\testng.xml’ 옵션을 선택하여 테스트를 실행할 것입니다. 그러나 테스트를 실행하기 전에 Run Configurations에 LambdaTest 사용자 이름과 액세스 키를 추가해야 합니다. 이는 사용자 이름과 액세스 키를 시스템 속성에서 읽고 있기 때문입니다.
LambdaTest는 3000개 이상의 실제 브라우저와 운영 체제로 구성된 온라인 브라우저 팜에서 크로스 브라우저 테스팅을 제공하므로 로컬이나 클라우드에서 Java 테스트를 실행할 수 있습니다. 다양한 브라우저와 OS 구성에서 병렬 테스트를 실행하여 Java와 Selenium 테스팅을 가속화하고 테스트 실행 시간을 여러 배 줄일 수 있습니다.
- 다음과 같이 Run Configuration에 값을 추가하세요:
- Dusername =
< LambdaTest username > - DaccessKey =
< LambdaTest access key >
- Dusername =
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd">
<suite name="Sauce Demo Website Tests">
<test name="Shadow DOM Tests on Watir Website">
<parameter name="browser" value="remote-chrome"/>
<classes>
<class name="ShadowDomTests">
<methods>
<include name="testShadowDomWatir"/>
</methods>
</class>
</classes>
</test> <!-- Test -->
</suite>Intellij IDE를 사용하여 Selenium에서 Shadow DOM을 로컬로 실행한 테스트의 스크린샷입니다.
Maven을 사용하여 Selenium WebDriver에서 Shadow DOM 자동화
Maven을 사용하여 테스트를 실행하려면 다음 단계를 수행하여 Selenium에서 Shadow DOM을 자동화해야 합니다:
- Command Prompt/Terminal을 엽니다.
- 프로젝트의 루트 폴더로 이동합니다.
- 다음 명령어를 입력하세요:
mvn clean install -Dusername=< LambdaTest username > -DaccessKey=< LambdaTest accessKey >.
다음은 IntelliJ에서 캡처한 스크린샷으로, Maven을 사용하여 테스트의 실행 상태를 보여줍니다:
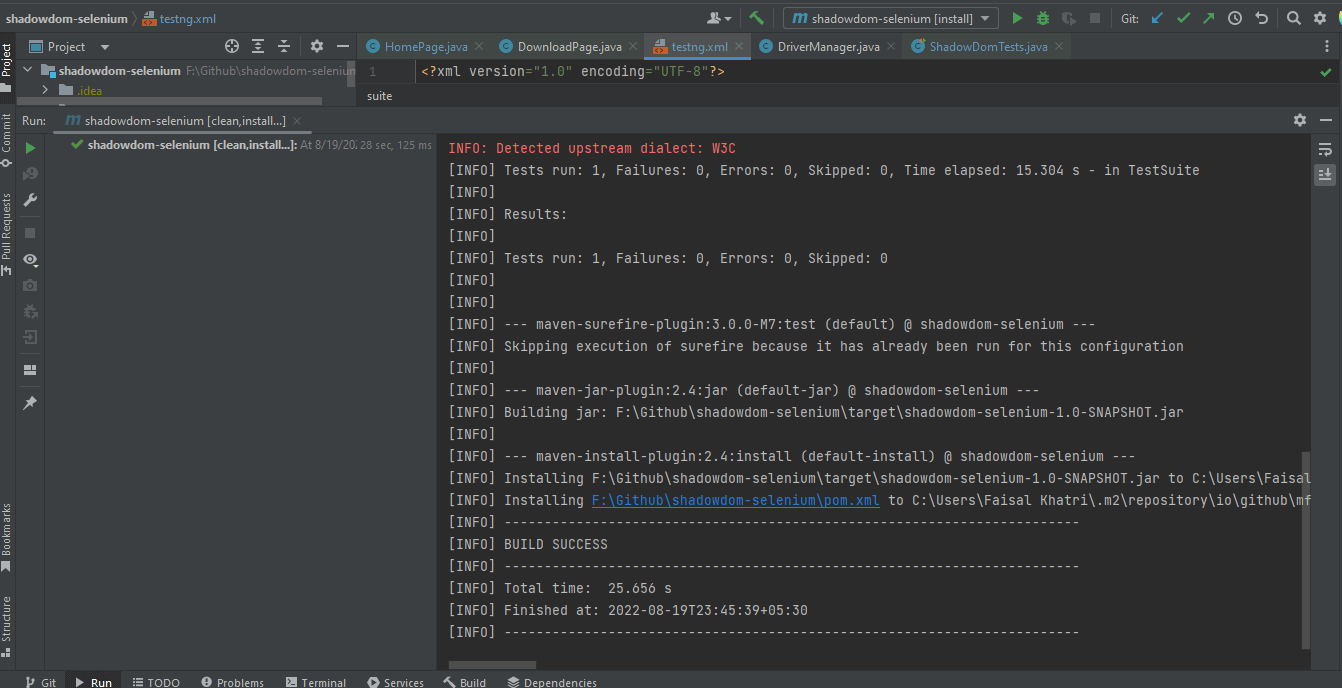
테스트가 성공적으로 실행되면 LambdaTest 대시보드를 확인하여 모든 동영상 녹화, 스크린샷, 기기 로그 및 테스트 실행의 단계별 세분화된 세부 정보를 볼 수 있습니다. 아래 스크린샷을 확인하세요. 이는 자동화된 앱 테스트에 대한 대시보드의 개요를 제공합니다.
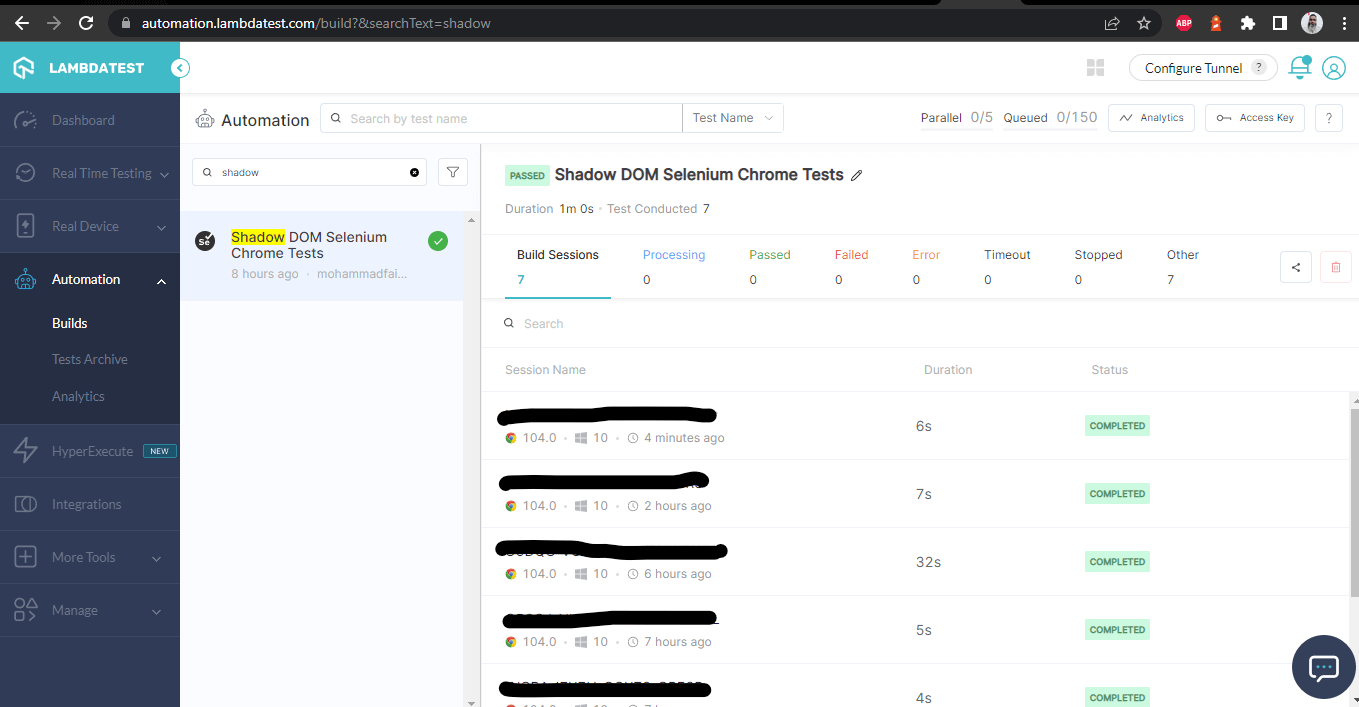 LambdaTest 대시보드
LambdaTest 대시보드
다음 스크린샷은 Selenium에서 Shadow DOM을 자동화하기 위해 실행된 빌드와 테스트의 세부 정보를 보여줍니다. 다시 말하지만, 테스트 이름, 브라우저 이름, 브라우저 버전, OS 이름, 해당 OS 버전 및 화면 해상도가 모든 테스트에 대해 정확하게 표시됩니다.
또한 기기에서 실행된 테스트의 동영상이 있어 테스트가 어떻게 실행되었는지에 대한 더 나은 이해를 제공합니다.
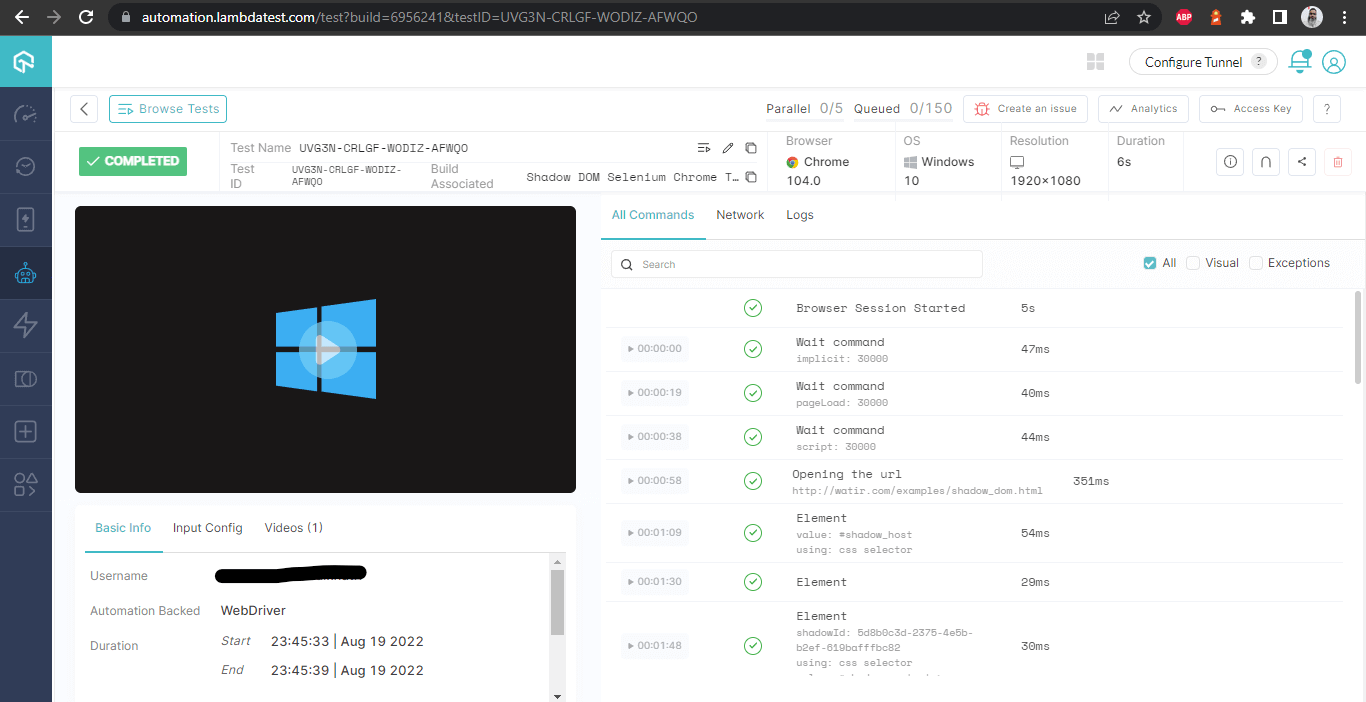 빌드 세부 정보
빌드 세부 정보
이 화면은 테스터의 관점에서 매우 유용한 모든 메트릭을 자세히 보여주며, 어떤 테스트가 어떤 브라우저에서 실행되었는지 확인하고 Selenium에서 Shadow DOM을 자동화하기 위한 로그를 참조할 수 있습니다.
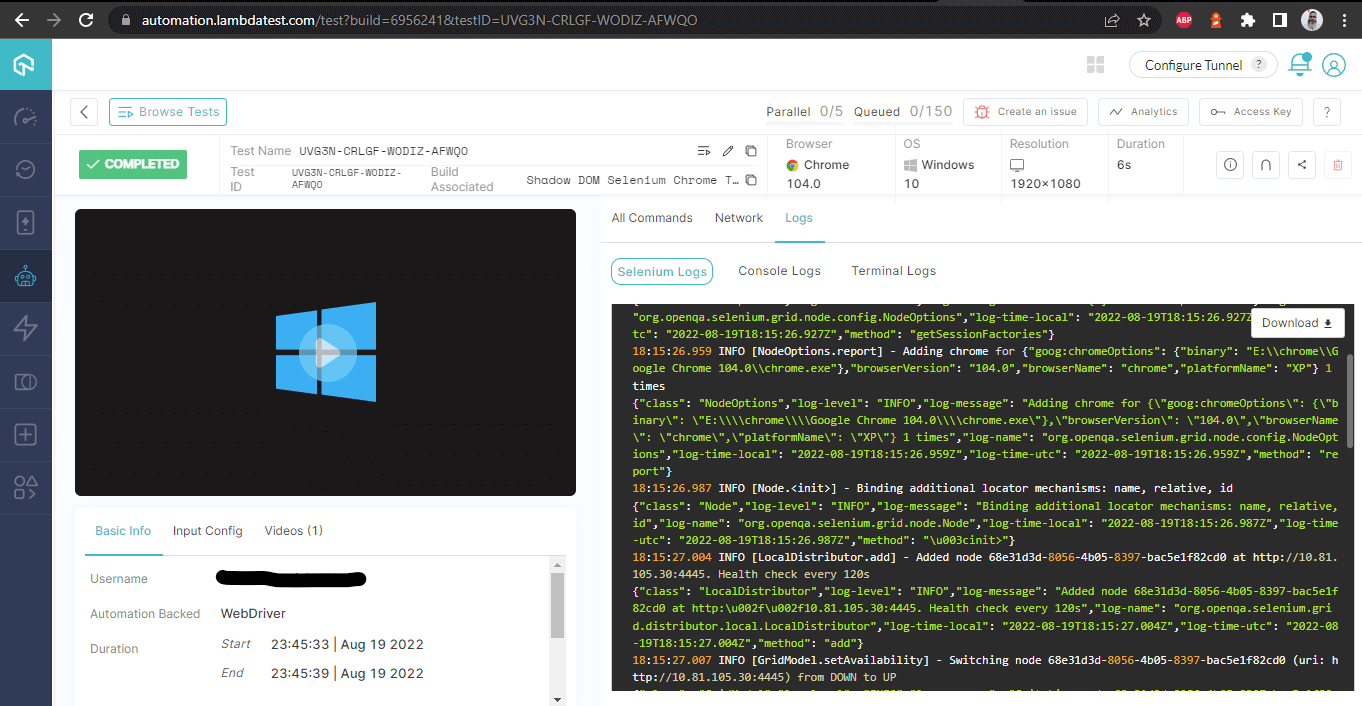 빌드 세부 사항 – 로그와 함께
빌드 세부 사항 – 로그와 함께
최신 테스트 결과, 그 상태, 그리고 통과 또는 실패한 테스트의 전체 수를 LambdaTest 분석 대시보드에서 확인할 수 있습니다. 또한, 최근에 실행된 테스트 실행의 스냅샷을 테스트 개요 섹션에서 볼 수 있습니다.
결론
이 블로그에서는 Selenium에서 Shadow DOM을 자동화하는 방법에 대해 논의했습니다. Shadow DOM 요소를 찾고 이를 자동화하기 위해 Selenium WebDriver의 4.0.0 이상 버전에 도입된 getShadowRoot() 메서드를 사용하는 방법을 설명했습니다.
또한, Selenium WebDriver에서 JavaScriptExecutor를 사용하여 Shadow DOM 요소를 찾고 자동화하는 방법과 Selenium WebDriver 로그와 함께 테스트의 세부 사항을 보여주는 LambdaTest 플랫폼에서 테스트를 실행하는 방법에 대해 논의했습니다.
I hope this blog on Shadow DOM in Selenium gives you a fair idea about automating Shadow DOM elements using Selenium WebDriver.
테스팅 재미있게 하세요!
Source:
https://dzone.com/articles/how-to-automate-shadow-dom-in-selenium-webdriver