













소프트웨어 開発 과정에서 실제 작동을 확인하는 명확하고 효율적인 unite test(단위 테스트)을 쓰는 것이 중요합니다. 단위 테스트는 个々의 코드 요소를 분리하고 그들이 预期대로 작동하는지 확인합니다.
유효한 단위 테스트는 오류를 잡는 뿐만 아니라, 코드가 유지 관리되고 신뢰할 수 있다는 것을 자신에게 자신감을 주는 역할을 합니다. 그러나 일반적으로 수동으로 단위 테스트 Suites(집합)을 만들기는 시간과 자원이 필요합니다.
최근에는 人工知能(AI) 분야에서 자동화를 도울 수 있는 一些 발전이 있었습니다. 今年 2월에 Meta researchers는 Large Language Models를 사용한 자동화 단위 테스트 改善에 대한 论文을 发表しました. 이것은 단위 테스트 자동화에 대한 革新的한 방법을 introduce했습니다.
그들의 연구는 이미 존재하는 단위 테스트를 분석하고 코드 квер지 를 향상시키기 위해 LLM을 사용하는 새로운 도구, TestGen-LLM에 초점을 맞추고 있습니다.
TestGen-LLM의 코드를 公表하지 않았지만, 이 글에서는 그들의 연구에 영감을 얻은 오픈 소스의 替わりの 방법을 绍介할 것입니다. 이를 통해 단위 테스트 Suites를 어떻게 생성하는지, 为何 LLM보다 좋은지, 이 기술을 사용하고 시작해 봐야 하는 곳을 배울 수 있습니다.
목차
-
결론
Meta의 TestGen-LLM
Meta의 TestGen-LLM은 대형 언어 모델(LLM)의 힘을 활용하여 단위 테스트 작성의 시간이 많이 걸리는 작업을 대신 처리합니다. Gemini나 ChatGPT와 같은 일반적인 목적의 LLM은 단위 테스트 코드, 테스트 문법, 값의 추가를 없애는 테스트 생성에 어려움을 겪을 수 있지만, TestGen-LLM은 단위 테스트를 위해 특별히 맞춤제작되었습니다.
이러한 특화는 코드 구조와 테스트 로직의 복잡함을 이해할 수 있도록 해서, 더 명확한 테스트 스위트를 생성하고 실제로 코드 커버리지를 높이는 테스트를 생성할 수 있습니다.
TestGen-LLM은 단위 테스트를 평가하고 향상의 가능성을 파악할 수 있습니다. 이를 위해 공통의 테스트 패턴을 학습했기 때문입니다. 하지만 테스트 생성만으로는 적절한 코드 커버리지를 달성할 수 없습니다.
Meta의 연구원들은 TestGen-LLM 안에 효율성을 보장하기 위한 보호措置을 구현했습니다. 이러한 보호措置은 필터로 지칭되며, 품질 관리 기구입니다. 다음과 같은 제안을 제거합니다:
-
컴파일 되지 않을 것
-
consistently 실패할 것, 또는
-
실제로 코드 커버리지를 향상시키지 않는 제안(다른 테스트에 이미 커버되어 있는 제안).
TestGen-LLM이 어떻게 작동하는가?
TestGen-LLM는 “보장된 LLM-기반 소프트웨어 엔지니어링”(Assured LLMSE) 이라는 접근法을 사용한다. TestGen-LLM은 기존의 테스트 클래스에 추가적인 테스트 사례를 추가하는 것뿐이고, 기존의 모든 테스트 사례를 보유하여 이를 통해 리그レasiョン이 발생하지 않을 것이라는 보장을 제공한다.
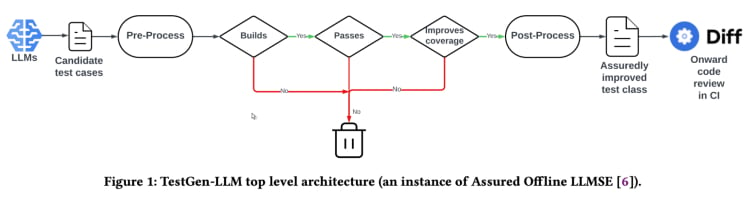
테스트 생성 workflow(TestGen_LLM 论文)
TestGen-LLM은 여러 개의 테스트를 생성한 다음, 실행되지 않는 테스트와 통과하지 않는 테스트를 過濾하고, inally, 코드 커버리지를 높이지 않는 것을 丢弃한다.
Meta는 TestGen-LLM을 사용하여 자동화된 테스트 모음을 사용한 이후, 인간 리뷰어를 사용하여 생성된 테스트의 수락률이 他们의 가장 좋은 보고病例에서 73%가 되었다.
论文에 따르면, TestGen-LLM은 한번의 실행에 单个 테스트를 생성하고 그 다음에 이를 이전에 開発자가 썼던 기존 테스트 모음에 추가한다고 하지만, 모든 테스트 모음에 대해 테스트를 생성하는 것은 未必하다.
TestGen-LLM의 효과를 Meta의 내부 테스트-a-thons에서 Demonstrated했다. 여기서, 도구를 사용하여 기존의 테스트 모음을 분석하고 改善 사항을 제안했다. 결과는 기대를 만족시켰다:
“TestGen-LLM의 테스트 사례 75%가 제대로 구성되었고, 57%가 신뢰성 있게 통과하며, 25%가 코드 커버리지를 높였습니다. Meta의 Instagram과 Facebook 테스트-a-thons 동안, 그れ를 적용한 모든 클azz의 11.5%를 改善 했으며, Meta 소프트웨어 엔지니어링 조직은 그것의 建议 73%를 생산적인 배포에 수락하였습니다.”.
TestGen-LLM의 建议は 시험-athon에 참가한 개발자들에 의해 有用하고 관련性 있음을 인정받았습니다.
오픈 소스 구현 (Cover-Agent)
Meta에서의 TestGen-LLM 연구는 코드에 대한 特化 훈련이 되어 있는 LLM을 사용하여 단위 테스트 생성과 자동 테스트 생성을 많이 바꿀 수 있는 빅 포ടential이 있습니다. 그러나 TestGen-LLM의 코드가 公开되지 않았기 때문에 이 기술을 사용할 수 있는 사람들은 많지 않습니다.
이 기술에 관심을 가진 개발자들은 公然 supplier code가 없다는 것에 기狈하고 있을 것입니다. 毕竟, Meta의 TestGen-LLM 연구는 자동 테스트의 미래를 예시하는 것입니다.
가장 前沿의 기술의 내부 작동을 探究할 수 있고, 그 결정 과정을 이해할 수 있고, 가능하다면 그의 발전을 도울 수 있는 것이 매우 매력적입니다. 하지만 Meta의 코드의 없음은 한가지 пре팍을 시키는 것과 동시에, Cover-Agent이라는 오픈 소스 구현이 유용한 대안으로 들어가 있습니다.
CodiumAI의 Cover-Agent는 TestGen-LLM 기반의 자동 테스트 도구의 첫 번째 오픈 소스 구현입니다. Meta의 연구를 영감으로, Cover-Agent은 현재 open-source AI-driven unit testing의 개발 前沿에 있습니다.
왜 특정 테스팅 중심의 LLM이 필요한가?
ChatGPT과 Gemini처럼 대부분의 LLM은 테스트를 생성할 수 있으므로, 새 기술을 사용해야 하는가?
ell, Cover-Agent와 TestGen-LLM은 효율적인 단위 테스트의 발전의 다음 단계로 만들어진 것입니다. 그들의 목표는 개발자가 LLM을 사용하여 테스트를 생성할 때 빠지는 일상적인 洼み를 避け는 것입니다.
-
LLM 幻覚
-
가치를 추가하지 않는 테스트를 생성
-
코드의 일부를 省略하여 low code coverage가 나는 테스트를 생성
이러한 도전들을 극복하기 위해 (특히 리gression unit tests를 위해) TestGen-LLM 研究者들은 다음과 같은 기준을 제시하여 테스트가 인정되る 전에 생성된 테스트가 충족해야 합니다.
-
생성된 테스트가 컴파일되고 제대로 실행되는가?
-
테스트가 코드 커버지를 높이는가?
-
가치를 추가하는가?
-
우리가 가지고 있을 수 있는 추가적인 요구사항을 만족하는가?
이러한 질문과 문제는 생성된 테스트가 现存的 기술을 업그레이드 시키기 전에 해결해야 하는 기본적인 문제입니다. Cover-Agent는 이러한 질문을 위임하는 것에 대해 심각히 높은 degree를 제공합니다.
Cover-Agent이 어떻게 작동하는가?
Cover-Agent는 소프트웨어 프로젝트의 단위 테스트 생성을 자동화하기 위해 설계된 더 넓은 유틸리티 모음의 일부입니다. TestGen-LLM 생성 AI 모델을 활용하여 테스트 과정을 단순화하고 신속하게 진행하며, 고품질의 소프트웨어 개발을 보장합니다.
시스템은 여러 구성 요소로 이루어져 있습니다:
-
테스트 실행기: 테스트 스위트를 실행하고 코드 커버리지 보고서를 생성하기 위한 명령어 또는 스크립트를 실행합니다.
-
커버리지 파서: 테스트가 추가됨에 따라 코드 커버리지가 증가하는지 확인하여 새로운 테스트가 전체 테스트 효과에 기여하도록 합니다.
-
프롬프트 빌더: 코드베이스에서 필요한 데이터를 수집하고 대형 언어 모델(LLM)에 전달할 프롬프트를 구성합니다.
-
AI 호출기: 제공된 프롬프트를 기반으로 테스트를 생성하기 위해 LLM과 상호작용합니다.
이러한 구성 요소들은 TestGen-LLM과 함께 작동하여 기존 코드베이스를 개선하는 테스트만 생성되도록 보장합니다.
Cover-Agent
이aders
Cover-Agent을 사용하기 전에 다음의 요구사항을 満たす 필요가 있습니다.:
-
OPENAI_API_KEY를 您的 환경 변수에 설정하십시오. 이는OpenAI API를 호출하기 위해 필요합니다. -
코드 盖率 도구: Cobertura XML 기반의 코드 盖率 보고서가 도구의 correct functionality를 위해 필요합니다. 예를 들어 Python에서는
pytest-cov를 사용할 수 있습니다. Pytest 실행 시--cov-report=xml옵션을 추가하십시오.
설치
Cover-Agent을 저장소에서 직접 실행하는 경우, 다음을 필요로 합니다.:
-
시스템에 Python을 설치하십시오.
-
Python パッケージ 依存関係 管理に Poetry를 설치하십시오. Poetryのインストール方法はこちら에 記載されています.
独立的 실행 runtime
안녕하세요.以下의 텍스트를 한국어로 번역하였습니다.
You can install Cover-Agent as a Python Pip package or run it as a standalone executable.
Python Pip
Python Pip 패키지를 직접 GitHub에서 설치하려면 다음 명령을 실행하세요:
pip install git+https://github.com/Codium-ai/cover-agent.git
바이너리
Python 환경이 설치되지 않은 시스템에서 바이너리를 실행할 수 있습니다 (예를 들어, Python이 없는 Docker 컨테이너 내에서). 프로젝트의 릴리즈 페이지로 이동하여 시스템에 맞는 릴리스를 다운로드할 수 있습니다.
저장소 설정
모든 의존성을 설치하고 소스에서 프로젝트를 실행하려면 다음 명령을 실행하세요:
poetry install
코드 실행
실행 파일을 다운로드하거나 Pip 패키지를 설치한 후에는 Cover-Agent를 실행하여 단위 테스트를 생성하고 검증할 수 있습니다.
명령줄에서 다음 명령을 사용하여 실행하세요:
cover-agent \
--source-file-path "path_to_source_file" \
--test-file-path "path_to_test_file" \
--code-coverage-report-path "path_to_coverage_report.xml" \
--test-command "test_command_to_run" \
--test-command-dir "directory_to_run_test_command/" \
--coverage-type "type_of_coverage_report" \
--desired-coverage "desired_coverage_between_0_and_100" \
--max-iterations "max_number_of_llm_iterations" \
--included-files "<optional_list_of_files_to_include>"
이 저장소 내의 예제 프로젝트를 사용하여 이 코드를 테스트로 실행할 수 있습니다.
명령 인자
-
source-file-path: 테스트할 함수나 코드 블록을 포함하는 파일의 경로입니다.
-
test-file-path: 에이전트가 테스트를 작성할 파일의 경로입니다. 이 파일에는 최소한 하나의 테스트와 필요한 임포트 문을 포함하는 기본 프레임을 만들어두는 것이 좋습니다.
-
코드-커버리지-리포트-경로: 코드 커버리지 리포트가 저장될 경로입니다.
-
테스트-명령: 테스트를 실행할 명령(예: pytest)입니다.
-
테스트-명령-디렉터리: 테스트 명령이 실행될 디렉터리입니다. 상대 임포트 문제를避ける 위해 루트나 주요 파일의 위치를 설정하세요.
-
커버리지-유형: 사용할 커버리지 유형입니다. Cobertura는 좋은 기본값입니다.
-
목표-커버리지: 커버리지 목표입니다. 더 높은 것이 더 좋지만, 100%는 종종 실용적이지 않습니다.
-
최대-_ITERATIONS: 에이전트가 테스트 코드를 생성하도록 재시도해야 하는 횟수입니다. 더 많은 반복 수는 OpenAI 토큰 사용량이 증가할 수 있습니다.
-
additional-instructions: 코드가 특정 방식으로 작성되도록 보장하기 위한 프롬프트입니다. 예를 들어, 여기서는 코드가 테스트 클래스 내에서 작동하도록 형식화되어야 함을 지정합니다.
명령을 실행하면 에이전트는 테스트를 작성하고 반복합니다.
Cover-Agent 사용 방법
Cover-Agent를 시험해 볼 시간입니다. 우리는 간단한 calculator.py 앱을 사용하여 수동 테스트와 자동 테스트의 코드 커버리지를 비교할 것입니다.
수동 테스트
def add(a, b):
return a + b
def subtract(a, b):
return a - b
def multiply(a, b):
return a * b
def divide(a, b):
if b == 0:
raise ValueError("Cannot divide by zero")
return a / b
이것은 테스트 폴더에 있는 test_calculator.py입니다.
# tests/test_calculator.py
from calculator import add, subtract, multiply, divide
class TestCalculator:
def test_add(self):
assert add(2, 3) == 5
코드 커버리지를 확인하려면 앞서 언급한 pytest의 확장기능인 pytest-cov를 설치해야 합니다.
pip install pytest-cov
다음 명령으로 커버리지 분석을 실행합니다:
pytest --cov=calculator
출력 결과는:
Name Stmts Miss Cover
-----------------------------------
calculator.py 10 5 50%
-----------------------------------
TOTAL 10 5 50%
위 출력 결과는 calculator.py의 10개 문장 중 5개가 실행되지 않았음을 보여주며, 50%의 코드 커버리지로 결과물입니다. 더 큰 코드 베이스의 경우 이는 심각한 문제가 될 수 있으며, 후퇴를 유발할 수 있습니다.
이제 cover-agent가 더 나은 결과를 내는지 확인해봅시다.
Cover-Agent로 자동 테스트
Codium의 Cover-Agent를 설정하려면 다음 단계를 따릅니다:
처음으로 Cover-Agent를 설치하세요:
pip install git+https://github.com/Codium-ai/cover-agent.git
OpenAI API를 사용하기 위해서는 OPENAI_API_KEY이 的环境变量에 설정되어 있어야 합니다.
다음으로 终端에서 테스트를 생성하는 명령어를 써봅시다:
cover-agent \
--source-file-path "calculator.py" \
--test-file-path "tests/test_calculator.py" \
--code-coverage-report-path "coverage.xml" \
--test-command "pytest --cov=. --cov-report=xml --cov-report=term" \
--test-command-dir "./" \
--coverage-type "cobertura" \
--desired-coverage 80 \
--max-iterations 3 \
--openai-model "gpt-4o" \
--additional-instructions "Since I am using a test class, each line of code (including the first line) needs to be prepended with 4 whitespaces. This is extremely important to ensure that every line returned contains that 4 whitespace indent; otherwise, my code will not run."
이렇게 다음과 같은 코드가 생성되ます:
import pytest
from calculator import add, subtract, multiply, divide
class TestCalculator:
def test_add(self):
assert(add(2, 3), 5
def test_subtract(self):
"""
Test subtracting two numbers.
"""
assert subtract(5, 3) == 2
assert subtract(3, 5) == -2
def test_multiply(self):
"""
Test multiplying two numbers.
"""
assert multiply(2, 3) == 6
assert multiply(-2, 3) == -6
assert multiply(2, -3) == -6
assert multiply(-2, -3) == 6
def test_divide(self):
"""
Test dividing two numbers.
"""
assert divide(6, 3) == 2
assert divide(-6, 3) == -2
assert divide(6, -3) == -2
assert divide(-6, -3) == 2
def test_divide_by_zero(self):
"""
Test dividing by zero, should raise ValueError.
"""
with pytest.raises(ValueError, match="Cannot divide by zero"):
divide(5, 0)
어쩌구 어쩌구 대신에 에이전트가 에러를 확인하는 테스트도 써냈어요.
다음으로 다시 全面 코드 � Chainage를 실험해봅시다:
pytest --cov=calculator
결과:
Name Stmts Miss Cover
-----------------------------------
calculator.py 10 0 100%
-----------------------------------
TOTAL 10 0 100%
이 예시에서 100% 코드 全面 코드 janage를 달성했습니다. larger code base를 가진 경우, 과정은 상당히 같습니다. 자세한 내용은 이 guide을 읽어 보시면 좋을 것 같아요.
Cover-Agent는 중요한 한 단계를 앞서고 있지만, 이 기술이 まだ 초기 段階이라고 알아야 합니다. 계속적인 연구와 개발이 추가적인 精致화와 보다 広範囲의 채용을 위해 중요합니다. 이 open source tool에 대한 기여를 codiumAI가 초대하고 있습니다.
Open Source Cover-Agent의 이점
Open source 性质이있는 Cover-Agent은 다양한 이점이 있습니다. 그 중에서도 다음과 같은 것들이 있습니다:
-
접근 가능성: LLM-based 테스팅 실험을 위한 개방형 소스 性质이 있으며 다양한 背境의 開発자들에게 이용 가능합니다.이는 사용자 수를 증가시키고 좋은 기술의 개발과 더 많은 응용 사례의 도입을 도울 것입니다.
-
협업: 개발자들은 기여, 개선 제안, 새로운 기능 제안하고 문제 보고할 수 있으며, Cover-Agent은 개발자들이 완벽한 프로젝트가 되기 위해 빨라지고 발전하ます.
-
투명성: 내부 操作에 대한 정보가 사용할 수 있으며, 이는 신뢰를 促进하고 기술의 가능성을 높이게 됩니다.
또한, Cover-Agent은 개방 소스의 avantages를 가지고 있을 뿐만 아니라 개발자들에게 자신의 특징의 강한 집합을 제공합니다 :
- 간단한 접근: 개발자는 LLM-based testing을 쉽게 설치하고 실험할 수 있으며, 이는 기술의 능력을 직접 탐구하고 workflow에 이를 他们的工作流程中几乎没有干扰。
-
특정 필요에 대한 사용자 정의: Cover-Agent의 오픈소스 성격으로 개발자들이 도구를 자신의 특정 프로젝트 요구사항에 맞출 수 있습니다. 이로 인해 LLM 모델을 수정하고, 코드베이스를 더욱 잘 반영하도록 훈련 데이터를 조정하거나, Cover-Agent를 기존의 테스트 프레임워크와 통합할 수 있습니다. 이러한 수준의 사용자 정의는 개발자들이 LLM-기반 테스트의 기능을 자신의 프로젝트 요구에 맞게 활용할 수 있게 해줍니다.
-
쉬운 통합: VSCode(인기 있는 코드 편집기)와 쉽게 통합되어 있어 기존의 워크플로와의 통합을 매우 쉽게 만듭니다. 또한 기존의 사람이 작성한 테스트와도 쉽게 통합할 수 있습니다.
How Can You Contribute to Cover-Agent?
Cover-Agent 소스 코드는 이 GitHub 저장소를 통해 공개되어 있습니다. 다양한 背境의 開発자들이 제품을 실험하고 이 新区段 기술을 더욱 나은 것을 도울 수 있는 기여를 제공하라고 그들은 促しています.
결론
LLM(Large Language Model)기반 테스트 개선 도구는 개발자들이 단위 테스트를 접근하는 방식을 革新하기 위한 极大的な 潜力을 보여줍니다. 코드에 특화된 대형 언어 모델을 활용하여, 이러한 도구는 테스트 생성을 간편하게 만들고, 코드 커버rage를 改善하고, ultimately 소프트웨어 品質를 높이는 데 도울 수 있습니다.
Meta의 TestGen-LLM 연구가 가치 있는 见解을 제공하였지만, 공개되어 있는 코드의 없어서 일반적인 자신감과 진행되는 개발을 방지합니다. 幸運的是, Cover-Agent는 즉시 접근 가능한 및 カスタマ이징 가능한 솔루션을 제공합니다. 개발자는 LLM기반 테스팅을 실험하고 이에 대한 발전에 기여 할 수 있습니다.
TestGen-LLM과 Cover-Agent의 潜力은 hugh, 開発者의 기여로 進められる 것이 더욱 자신감이 있습니다. 자동 테스트 생성을 革新하는 데 중요한 도구가 되어야 합니다.
Source:
https://www.freecodecamp.org/news/automated-unit-testing-with-testgen-llm-and-cover-agent/