













Es importante escribir pruebas unitarias claras y eficientes que funcionen realmente durante el proceso de desarrollo de software. Las pruebas unitarias separan los elementos de código individuales y confirman que funcionan como se pretende.
Las pruebas unitarias efectivas no solo atrapan errores, sino que también le ayudan a estar seguro de que su código puede ser mantenido y es confiable. Sin embargo, tarda tiempo y recursos crear manualmente una amplia suite de pruebas unitarias.
Han ocurrido algunos desarrollos recientes en inteligencia artificial que prometen ayudar a automatizar los procesos de desarrollo de pruebas unitarias. En febrero, investigadores de Meta publicaron un documento sobre Mejora de Pruebas Unitarias Automáticas utilizando Modelos de Lenguaje Largos. Esto presentó una innovadora metodología para automatizar las pruebas unitarias.
Su investigación se centra en una nueva herramienta llamada TestGen-LLM, que explora las posibilidades de utilizar los ML para analizar pruebas unitarias ya existentes y mejorarlas para aumentar la cobertura de código.
Aunque el código de TestGen-LLM no fue publicado, en este artículo presentaré una alternativa de código abierto inspirada en su investigación. Aprenderá cómo genera suites de pruebas, por qué es mejor que la mayoría de los ML y dónde conseguir sus manos en este tipo de tecnología y comenzar a probarla.
Tabla de contenidos
Meta’s TestGen-LLM
Meta’s TestGen-LLM aborda la tarea consumidera de escribir pruebas unitarias al aprovechar el poder de los Modelos de Lenguaje Largos (LLMs). Los LLMs de propósito general como Gemini o ChatGPT podrían luchar con el dominio específico del código de pruebas unitarias, la sintaxis de pruebas y la generación de pruebas que no aportan valor. Sin embargo, TestGen-LLM está específicamente adaptado para las pruebas unitarias.
Esta especialización le permite comprender las complejidades de la estructura de código y la lógica de pruebas, lo que resulta en suite de pruebas más dirigidas y generar pruebas que realmente aportan valor y aumentan la cobertura de código.
TestGen-LLM es capaz de evaluar pruebas unitarias y identificar áreas para mejoras. Logra esto a través de su comprensión de patrones de prueba comunes con los que ha sido entrenado. Sin embargo, la generación de pruebas por sí sola es insuficiente para la cobertura de código apropiada.
Los investigadores de Meta implementaron salvaguardas dentro de TestGen-LLM para asegurar la eficacia de las pruebas que escribe. Estas salvaguardas, conocidas como filters, actúan como un mecanismo de control de calidad. Ellas eliminan sugerencias que:
-
no compilarían
-
fallan consistentemente, o
-
no mejoran realmente la cobertura de código (sugerencias que ya están cubiertas por otras pruebas).
Cómo funciona TestGen-LLM?
TestGen-LLM utiliza un enfoque denominado “Ingeniería de Software basada en LLM asegurada” (Assured LLMSE). TestGen-LLM simplemente amplía una clase de prueba existente con casos de prueba adicionales, conservando todos los casos de prueba existentes y garantizando así que no habrá ninguna reacción en cadena.
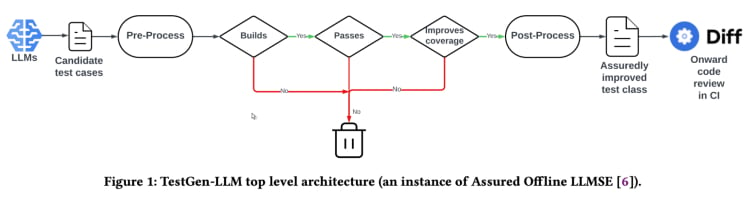
Flujo de generación de pruebas(De la revisión de TestGen_LLM)
TestGen-LLM genera una serie de pruebas, luego filtra las pruebas que no se ejecutan y descarta cualquiera que no se apruebe. Finalmente, desecha aquellas que no aumentan la cobertura del código.
Después de usar TestGen-LLM para automatizar una suite de pruebas, Meta utilizó a un revisor humano para aceptar o rechazar pruebas en las que las pruebas generadas tenían una tasa de aceptación del 73% en sus mejores casos reportados.
Según el documento, TestGen-LLM genera una sola prueba en cada ejecución, que luego se agrega a una suite de pruebas existente que fue escrita previamente por un desarrollador. Sin embargo, no necesariamente genera pruebas para cualquier suite de pruebas dada.
La eficacia de TestGen-LLM fue demostrada en los test-a-thons internos de Meta. Allí, la herramienta se utilizó para analizar las suites de pruebas existentes y sugirió mejoras. Los resultados fueron prometedores:
“El 75% de los casos de prueba de TestGen-LLM se construyó correctamente, el 57% se aprobó con confianza, y el 25% aumentó la cobertura. Durante los test-a-thons de Instagram y Facebook de Meta, mejoró el 11,5% de todas las clases a las que se aplicó, con un 73% de sus recomendaciones aceptadas para la deploy de producción por los ingenieros de software de Meta”.
También, las recomendaciones de TestGen-LLM fueron consideradas útiles y relevantes por los desarrolladores que participaron en los test-a-thons.
Implementación de Código Abierto (Cover-Agent)
La investigación de TestGen-LLM de Meta tiene un gran potencial para cambiar la prueba de unidades y la generación automática de pruebas. La herramienta puede ayudar a mejorar la cobertura de código y acelerar la creación de pruebas al utilizar LLMs específicamente entrenadas en código. Sin embargo, esta tecnología no está disponible para cualquier persona, ya que el código de TestGen-LLM no ha sido publicado.
Los desarrolladores que se han interesado en esta tecnología probablemente se sientan frustrados por la falta de código disponible al público. Después de todo, el estudio de TestGen-LLM de Meta ofrece una pequeña muestra de lo que puede ser el futuro de las pruebas automatizadas.
Es muy atractivo poder adentrarse en los detalles internos de la nueva tecnología, comprender sus procesos de toma de decisiones y quizás incluso contribuir a su evolución. Sin embargo, mientras que la falta de código de Meta es un obstáculo, existe una implementación de código abierto llamada Cover-Agent que puede funcionar como una alternativa útil.
CodiumAI's Cover-Agent es la primera implementación de código abierto de una herramienta de prueba automatizada basada en TestGen-LLM. Inspirado en la investigación de Meta, Cover-Agent está a la vanguardia de los avances en pruebas de unidades basadas en AI de código abierto como resultado.
¿Por qué son necesarias LLMs específicas enfocadas en pruebas?
Ya que la mayoría de las LLMs (como ChatGPT y Gemini) son capaces de generar pruebas, entonces ¿por qué invertir en una nueva tecnología?
Bien, Cover-Agent y TestGen-LLM fueron creados para ser el siguiente paso en la evolución de las pruebas unitarias eficientes. Su objetivo es evitar los problemas comunes en los que se sumergen los desarrolladores al generar pruebas con LLS, tales como:
-
Hallucinación LLS
-
Generación de pruebas que no añaden valor
-
Generación de pruebas que omiten partes del código, resultando en una baja cobertura de código
Para superar estos retos ( especialmente para las pruebas de unidad de regresión) los investigadores de TestGen-LLM elaboraron los siguientes criterios que deben cumplir las pruebas generadas antes de que las pruebas sean aceptadas:
-
¿La prueba generada compila y se ejecuta correctamente?
-
¿La prueba aumenta la cobertura de código?
-
¿Añade valor?
-
¿Cumple con cualquier requisito adicional que tengamos?
Estas son preguntas y problemas fundamentales que deben resolver las pruebas generadas antes de que se consideren un avance respecto a la tecnología existente. Cover-Agent proporciona pruebas que responden a estas preguntas hasta un grado asombroso.
¿Cómo funciona Cover-Agent?
Cover-Agent forma parte de una suite de herramientas más amplia diseñada para automatizar la creación de pruebas de unidad para proyectos de software. Utilizando el modelo de IA generativa TestGen-LLM, pretende simplificar y acelerar el proceso de prueba, garantizando un desarrollo de software de alta calidad.
El sistema se compone de varios componentes:
-
Ejecutador de Pruebas: Ejecuta las órdenes o scripts para ejecutar el conjunto de pruebas y generar informes de cobertura de código.
-
Analizador de Cobertura: Valida que la cobertura de código aumenta conforme se agregaron pruebas, garantizando que las nuevas pruebas contribuyen al efectividad global de las pruebas.
-
Constructor de Propósito: Recolecta los datos necesarios desde la base de código y construye el propósito que se pasará al Modelo de Lenguaje Larga (LLM).
-
Llamador de AI: Interactúa con el LLM para generar pruebas basadas en el propósito proporcionado.
Estos componentes trabajan juntos con TestGen-LLM para generar solo pruebas que se garanticen que mejoren la base de código existente.
Cómo utilizar Cover-Agent
Requisitos
Antes de comenzar a utilizar Cover-Agent debe tener los siguientes requisitos:
-
OPENAI_API_KEYconfigurado en las variables de entorno, que es necesario para llamar a laAPI de OpenAI. -
Herramienta de Cobertura de Código: Se necesita un informe de cobertura de código en formato Cobertura XML para que la herramienta funcione correctamente. Por ejemplo, en Python podría usar
pytest-cov.Agregue la opción--cov-report=xmlal ejecutar Pytest.
Instalación
Si estás ejecutando Cover-Agent directamente desde el repositorio, también necesitarás:
-
Python instalado en tu sistema.
-
Poetry instalado para la gestión de dependencias de paquetes de Python. Puedes encontrar las instrucciones de instalación de Poetry aquí.
Ejecución independiente
Puede instalar Cover-Agent como un paquete de Python Pip o ejecutarlo como un ejecutable independiente.
Python Pip
Para instalar el paquete de Python Pip directamente a través de GitHub, ejecute el siguiente comando:
pip install git+https://github.com/Codium-ai/cover-agent.git
Binario
Puede ejecutar el binario sin tener ningún entorno de Python instalado en su sistema (por ejemplo, dentro de un contenedor Docker que no contenga Python). Puede descargar la versión para su sistema navegando hasta la página de lanzamiento del proyecto.
Configuración del Repositorio
Ejecute el siguiente comando para instalar todas las dependencias y ejecutar el proyecto desde la fuente:
poetry install
Ejecución del Código
Después de descargar el ejecutable o instalar el paquete Pip, ahora puede ejecutar Cover-Agent para generar y validar pruebas unitarias.
Ejéctelo desde la línea de comandos usando el siguiente comando:
cover-agent \
--source-file-path "path_to_source_file" \
--test-file-path "path_to_test_file" \
--code-coverage-report-path "path_to_coverage_report.xml" \
--test-command "test_command_to_run" \
--test-command-dir "directory_to_run_test_command/" \
--coverage-type "type_of_coverage_report" \
--desired-coverage "desired_coverage_between_0_and_100" \
--max-iterations "max_number_of_llm_iterations" \
--included-files "<optional_list_of_files_to_include>"
Puede usar los proyectos de ejemplo de este repositorio para ejecutar este código como una prueba.
Argumentos de Comando
-
source-file-path: Ruta del archivo que contiene las funciones o bloque de código que queremos probar.
-
test-file-path: Ruta del archivo donde se escribirán las pruebas por parte del agente. Es mejor crear un esqueleto de este archivo con al menos una prueba y las declaraciones de importación necesarias.
-
ruta-informe-cobertura-codigo: Ruta donde se guarda el informe de cobertura de código.
-
comando-prueba: Comando para ejecutar las pruebas (por ejemplo pytest).
-
directorio-comando-prueba: Directorio donde se debe ejecutar el comando de prueba. Establecer esto en la raíz o en la ubicación de su archivo principal para evitar problemas con las importaciones relativas.
-
tipo-cobertura: Tipo de cobertura a utilizar. Cobertura es un buen valor predeterminado.
-
cobertura-deseada: Meta de cobertura. Mayor es mejor, aunque 100% a menudo es impráctico.
-
max-iteraciones: Número de veces que el agente debe reintentar generar código de prueba. Más iteraciones pueden llevar a un mayor uso de tokens de OpenAI.
- instrucciones-adicionales: Prompts para asegurar que el código sea escrito de una manera específica. Por ejemplo, aquí especificamos que el código debe estar formateado para funcionar dentro de una clase de prueba.
Al ejecutar el comando, el agente comienza a escribir y a iterar las pruebas.
Cómo Usar Cover-Agent
Es hora de probar Cover-Agent. Utilizaremos una simple aplicación calculadora.py para comparar la cobertura de código para pruebas manuales y automatizadas.
Pruebas Manuales
def add(a, b):
return a + b
def subtract(a, b):
return a - b
def multiply(a, b):
return a * b
def divide(a, b):
if b == 0:
raise ValueError("Cannot divide by zero")
return a / b
Este es el archivo test_calculator.py colocado en la carpeta de pruebas.
# tests/test_calculator.py
from calculator import add, subtract, multiply, divide
class TestCalculator:
def test_add(self):
assert add(2, 3) == 5
Para ver la cobertura de pruebas, necesitamos instalar pytest-cov, una extensión de pytest para la generación de informes de cobertura mencionada anteriormente.
pip install pytest-cov
Ejecute el análisis de cobertura con:
pytest --cov=calculator
La salida muestra:
Name Stmts Miss Cover
-----------------------------------
calculator.py 10 5 50%
-----------------------------------
TOTAL 10 5 50%
La salida anterior muestra que 5 de las 10 sentencias en calculadora.py no son ejecutadas, resultando en una cobertura de código de solo un 50%. Para un base de código más grande, esto se convertirá en un serio problema y llevará a retrasos.
Ahora veamos si cover-agent puede hacer mejor.
Pruebas Automatizadas con Cover-Agent
Para configurar Codium’s Cover-Agent, siga estos pasos:
Primero, instale Cover-Agent:
pip install git+https://github.com/Codium-ai/cover-agent.git
Asegúrese de que su OPENAI_API_KEY está configurado en sus variables de entorno, ya que es necesario para la API de OpenAI.
A continuación, escriba los comandos para iniciar la generación de pruebas en la terminal:
cover-agent \
--source-file-path "calculator.py" \
--test-file-path "tests/test_calculator.py" \
--code-coverage-report-path "coverage.xml" \
--test-command "pytest --cov=. --cov-report=xml --cov-report=term" \
--test-command-dir "./" \
--coverage-type "cobertura" \
--desired-coverage 80 \
--max-iterations 3 \
--openai-model "gpt-4o" \
--additional-instructions "Since I am using a test class, each line of code (including the first line) needs to be prepended with 4 whitespaces. This is extremely important to ensure that every line returned contains that 4 whitespace indent; otherwise, my code will not run."
Esto genera el siguiente código:
import pytest
from calculator import add, subtract, multiply, divide
class TestCalculator:
def test_add(self):
assert(add(2, 3), 5
def test_subtract(self):
"""
Test subtracting two numbers.
"""
assert subtract(5, 3) == 2
assert subtract(3, 5) == -2
def test_multiply(self):
"""
Test multiplying two numbers.
"""
assert multiply(2, 3) == 6
assert multiply(-2, 3) == -6
assert multiply(2, -3) == -6
assert multiply(-2, -3) == 6
def test_divide(self):
"""
Test dividing two numbers.
"""
assert divide(6, 3) == 2
assert divide(-6, 3) == -2
assert divide(6, -3) == -2
assert divide(-6, -3) == 2
def test_divide_by_zero(self):
"""
Test dividing by zero, should raise ValueError.
"""
with pytest.raises(ValueError, match="Cannot divide by zero"):
divide(5, 0)
Puede ver que el agente también escribió pruebas que comprenden errores para cualquier caso de borde.
Ahora es hora de probar la cobertura de nuevo:
pytest --cov=calculator
Salida:
Name Stmts Miss Cover
-----------------------------------
calculator.py 10 0 100%
-----------------------------------
TOTAL 10 0 100%
En este ejemplo hemos alcanzado una cobertura de código de 100%. Para bases de código más grandes, el procedimiento es relativamente el mismo. Puede leer esta guía para una guía paso a paso en una base de código más grande.
Aunque Cover-Agent representa un avance importante, es importante notar que esta tecnología todavía está en sus primeras etapas. La investigación y el desarrollo continuos son cruciales para una mayor refinación y una amplia adopción, y codiumAI lo invita a que haga sus contribuciones a esta herramienta de código abierto.
Ventajas de Open Source Cover-Agent
La naturaleza de código abierto de Cover-Agent ofrece varias ventajas que deben ayudar a impulsar la tecnología hacia adelante. Entre ellas están:
-
Accesibilidad: Su naturaleza de código abierto permite experimentación con pruebas basadas en LLM y es accesible a desarrolladores con diferentes orígenes. Esto aumentará el número de usuarios y llevará a la desarrollación de una mejor tecnología y a más aplicaciones..
-
Cooperación: Los desarrolladores pueden realizar contribuciones, proponer mejoras, proponer nuevas características y reportar problemas. Cover-Agent se expandirá y desarrollará rápidamente en un proyecto perfecto para los desarrolladores..
-
Transparencia: La información sobre las operaciones internas está disponible, lo que promueve la confianza y finalmente aumentará el potencial de la tecnología.
Además de las ventajas de su código abierto, Cover-Agent ofrece a los desarrolladores un conjunto de beneficios propios:
-
Acceso Simple: Los desarrolladores pueden instalar y experimentar fácilmente pruebas basadas en LLM. Esto permite una exploración directa y inmediata de las capacidades de la tecnología y con poca o ninguna interrupción en su flujo de trabajo.
-
Personalización para Necesidades Específicas: La naturaleza de código abierto de Cover-Agent permite a los desarrolladores adaptar la herramienta a sus requisitos específicos de proyecto. Esto podría implicar modificar el modelo de LLM utilizado, ajustar los datos de entrenamiento para reflejar mejor su código base o integrar Cover-Agent con frameworks de prueba existentes. Este nivel de personalización capacita a los desarrolladores para aprovechar la potencia de las pruebas basadas en LLM de una manera que se ajuste a sus necesidades de proyecto.
- Integración Fácil: Se integra fácilmente con VSCode (un popular editor de código), lo que hace que la integración con flujos de trabajo existentes sea fácil. También se puede integrar fácilmente con pruebas humanamente escritas existentes.
¿Cómo Puedes Contribuir a Cover-Agent?
El código fuente de Cover-Agent está disponible públicamente a través de este repositorio de GitHub. Encouritan a desarrolladores de todos los orígenes a probar su producto y aportar contribuciones para mejorar y ampliar esta nueva tecnología.
Conclusión
Las herramientas de mejora de pruebas basadas en LLM (Large Language Model) poseen un gran potencial para revolucionar la forma en que los desarrolladores abordan las pruebas unitarias. Al aprovechar el poder de los grandes modelos de lenguaje específicamente entrenados en código, estas herramientas pueden automatizar la creación de pruebas, mejorar la cobertura de código y, finalmente, aumentar la calidad del software.
Mientras que la investigación de Meta con TestGen-LLM ofrece valiosas insigthts, la falta de código disponible públicamente impide una adopción más amplia y un desarrollo en curso. Afortunadamente, Cover-Agent ha proporcionado una solución de acceso fácil y personalizable. Empodera a los desarrolladores a experimentar con pruebas basadas en LLM y contribuir a su evolución.
El potencial de TestGen-LLM y Cover-Agent es inmenso, y su desarrollo futuro a través de contribuciones de desarrolladores llevará a una herramienta revolucionaria que transformará la generación automática de pruebas para siempre.
Conéctate conmigo en LinkedIn y Twitter si encontraste esto útil.
Source:
https://www.freecodecamp.org/news/automated-unit-testing-with-testgen-llm-and-cover-agent/