













Het is belangrijk om tijdens het softwareontwikkelsproces heldere en efficiente unit tests schrijven die echt functioneren. Unit tests scheiden individuele codeonderdelen uit en bevestigen dat ze zoals gepland werken.
Effectieve unit tests nemen niet alleen fouten waar maar helpen ook om te zijn er van overtuigd dat uw code wordt onderhouden kan worden en betrouwbaar is. Maar het kost tijd en middelen om handmatig een uitgebreide suite van unit tests te maken.
Er zijn recente ontwikkelingen in de kunstmatige intelligentie die de automatisering van het proces van unit testontwikkeling beloven. In februari brachten onderzoekers bij Meta een paper uit over Automated Unit Test Improvement using Large Language Models. Dit introduceerde een innovatieve methode voor de automatisering van unit testing.
Hun onderzoek richt zich op een nieuwe tool genaamd TestGen-LLM, die de mogelijkheden onderzoeks laat zien van LLMs om bestaande unit tests te analyseren en te verbeteren om de code-omschrijving te vergroten.
Alhoewel het code voor de TestGen-LLM niet werd uitgebracht, zal ik in dit artikel een open-source alternatief introduceren dat inspireerd is door hun onderzoek. U zult leren hoe het test Suites genereert, waarom het beter is dan de meeste LLMs en waar u deze technologie in handen krijgt om eraan te beginnen.
Inhoudsopgave
Meta’s TestGen-LLM
Meta’s TestGen-LLM verkrijgt de tijdrovende taak van het schrijven van unit tests door de kracht van Grote Taal Modelsen (LLMs) in te zetten. Algemeen doelgerichte LLMs zoals Gemini of ChatGPT kunnen wellicht tegenstromen met de specifieke domein van unit testcode, testsyntaxis, en het genereren van tests die geen waarde toevoegen. Maar TestGen-LLM is speciaal aangepast voor unit testing.
Deze specialisatie maakt het hem mogelijk om de complexiteiten van code structuur en test logica te begrijpen, wat resulteert in meer doelgerichte test suites en het genereren van tests die echt waarde toevoegen en de code covergrootte verhogen.
TestGen-LLM kan unit tests evalueren en gebieden voor verbeteringen identificeren. Het behaalt dit door zijn kennis van algemene test patronen die hij is geëvalueerd met. Maar het alleen genereren van tests is onvoldoende voor een goede code covergrootte.
Meta’s onderzoekers hebben veiligheidsmaatregelen binnen TestGen-LLM geïmplementeerd om de effectiviteit van de door hem geschreven tests te waarborgen. Deze veiligheidsmaatregelen, bekend als filters, fungeren als een kwaliteitscontrole mechanisme. Ze elimineren suggesties die:
-
niet kunnen worden gecompileerd
-
consistent mislukken, of
-
geen echte verbetering van de code covergrootte opleveren (suggesties die reeds worden gecoverd door andere tests).
Hoe werkt TestGen-LLM?
TestGen-LLM gebruikt een methode die “Gegarandeerde LLM-gebaseerde Software Engineering” (Assured LLMSE) heet. TestGen-LLM voegt simpelweg extra testgevallen toe aan een bestaande testklasse, behoudt alle bestaande testgevallen en garandeert zo dat er geen regressie zal zijn.
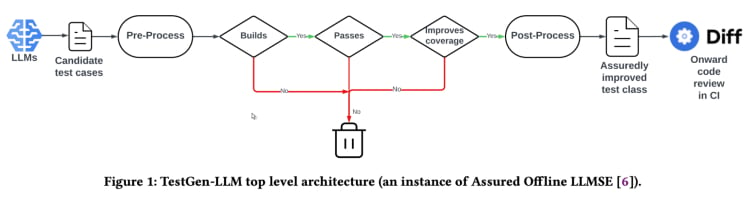
Testgeneratie workflow(Uit het TestGen_LLM paper)
TestGen-LLM genereert een stel testen, filtert daarna de testen uit die niet worden uitgevoerd en laat die testen die niet slagen vallen. Uiteindelijk discardeert het die testen die de code-coverage niet verhogen.
Na het automatiseren van een testpakket met TestGen-LLM heeft Meta een menselijke reviewer gebruikt om testen aan te nemen of te verwerpen waarbij de gegenereerde testen een acceptatiegraad hadden van 73% in hun beste gemelde gevallen.
Volgens het paper genereert TestGen-LLM een enkele test bij elke uitvoering die dan toegevoegd wordt aan een bestaand testpakket dat eerder door een ontwikkelaar was geschreven. Maar het genereert niet noodzakelijkerwijs testen voor elk gegeven testpakket.
De Effectiviteit van TestGen-LLM werd getoond op test-a-thons binnen Meta. Hier werd het hulpmiddel gebruikt om bestaande testpakketten te analyseren en verbeteringen te suggesteren. De resultaten waren vertrouwd:
“75% van de testgevallen van TestGen-LLM werden correct uitgevoerd, 57% waren betrouwbaar succesvol en 25% verhoogden de coveragen. Tijdens de Instagram en Facebook test-a-thons van Meta verbeterde het 11,5% van alle klassen waaraan het werd toegepast, met 73% van zijn aanbevelingen voor de productie-uitvoering door Meta software Engineers aanvaard”.
Ook de aanbevelingen van TestGen-LLM werden door de deelnemende ontwikkelaars in de test-a-thons als nuttig en relevant beschouwd.
Open-source implementatie (Cover-Agent)
De onderzoek van TestGen-LLM van Meta heeft veel potentiële veranderingen in unit testing en geautomatiseerd testgenereren. Het hulpmiddel zal waarschijnlijk helpen bij het verbeteren van de code cover en het versnellen van testcreatie door middel van LLMs die speciaal op code getraind zijn. Maar deze technologie is niet beschikbaar voor iedereen, aangezien het codebestand voor TestGen-LLM niet is vrijgegeven.
Ontwikkelaars die interesse hebben in deze technologie zijn waarschijnlijk teleurgesteld door het ontbreken van beschikbare code op het publieke domein. Na alles is het onderzoek van Meta’s TestGen-LLM een inzicht in de toekomst van geautomatiseerd testen.
Het is vrij aantrekkelijk om in de interne werkingen van de nieuwste technologie te kunnen duiken, haar besluitvormingsprocessen te kunnen begrijpen en misschien zelfs de ontwikkeling ervan te kunnen beïnvloeden. Maar terwijl het ontbreken van Meta’s code een belemmering is, bestaat er een open-source implementatie genaamd Cover-Agent die als nuttige alternatief kan dienen.
CodiumAI's Cover-Agent is de eerste open-source implementatie van een geautomatiseerd testgereedschap gebaseerd op TestGen-LLM. gestimuleerd door de onderzoek van Meta, is Cover-Agent nu aan de vooravond van de ontwikkelingen in open-source AI-gebaseerd unit testing door deze inspanningen.
Waarom zijn specifieke testgerichte LLMs nodig?
Als de meeste LLMs (zoals ChatGPT en Gemini) in staat zijn tests te genereren, dan waarom een nieuwe technologie beschermen?
Hmm, Cover-Agent en TestGen-LLM zijn ontworpen om de volgende stap in de evolutie van efficiente unit testing uit te voeren. Hun doel is om common pitfalls te vermijden die ontwikkelaars tegenkomen bij het genereren van testen met LLMs, zoals:
-
LLM Hallucination
-
Testen die geen waardevolle toevoeging zijn
-
Testen die een deel van het codeoverschrijden, waardoor de code-coverage laag is
Om dergelijke uitdagingen te overwinnen (specifiek voor regressie unit tests) hebben de TestGen-LLM onderzoekers de volgende criteria bedacht die de gegenereerde testen moeten meeten voordat de test wordt geaccepteerd:
-
Compileert de gegenereerde test correct en wordt hij correct uitgevoerd?
-
Wordt de test de code-coverage vergroten?
-
Voegt de test waardevolle toevoegingen toe?
-
Voldoet de test aan eventuele extra vereisten die we mogen hebben?
Dit zijn fundamentele vragen en problemen die de gegenereerde test moet oplossen voordat hij wordt beschouwd als een verbetering op de bestaande technologie. Cover-Agent levert testen die deze vragen en problemen op een boventoons hoog niveau beantwoorden.
Hoe werkt Cover-Agent?
Het Cover-Agent is een onderdeel van een breedere reeks hulpprogrammas ontworpen om de creatie van eenheidstests voor softwareprojecten te automatiseren. Het maakt gebruik van de Generative AI-model TestGen-LLM om de testproces te vereenvoudigen en te versnellen, waardoor een hoogwaardig softwareontwikkelsysteem wordt gegarandeerd.
Het systeem bestaat uit verschillende componenten:
-
Test Uitvoerder: Voert commando’s of scripts uit om de test suite te laten draaien en genereert code覆盖 rapporten.
-
CoverageParser: Controleert of de code覆盖 toeneemt als tests worden toegevoegd, waardoor nieuwe tests bijdragen aan de algehele testeffectiviteit.
-
PromptBuilder: Verzamelt de nodige gegevens uit de codebasis en bouwt het prompt op dat wordt doorgegeven aan de Grote Taal Model (LLM).
-
AICaller: Interageert met de LLM om tests te genereren op basis van het aangeleverde prompt.
Deze componenten werken samen met TestGen-LLM om alleen tests te genereren die zijn gegarandeerd om de bestaande codebasis te verbeteren.
Hoe gebruik je Cover-Agent?
Vereisten
Alvorens u Cover-Agent kunt beginnen te gebruiken, moet u de volgende vereisten aanwezig hebben:
-
OPENAI_API_KEYingesteld in uw omgevingsvariabelen, nodig voor het aanroepen van deOpenAI API. -
Code Coveragetool: Een Cobertura XML code coveragelijkingsrapport is vereist voor correct functioneren van de tool. Bijvoorbeeld in Python kun je
pytest-covgebruiken. Voeg de optie--cov-report=xmltoe bij het uitvoeren van Pytest.
Installatie
Als u Cover-Agent direct uit de opslagplaats uitvoert, heeft u ook het volgende nodig:
-
Python geïnstalleerd op uw systeem.
-
Poetry geïnstalleerd voor het beheren van Pythonpakketafhankelijkheden. U kunt instructies voor de installatie van Poetry hier vinden.
Standalone Runtime
U kunt Cover-Agent installeren als een Python Pip pakket of als een zelfstandig uitvoerbare bestand.
Python Pip
Om het Python Pip-pakket direct via GitHub te installeren, voert u de volgende opdracht uit:
pip install git+https://github.com/Codium-ai/cover-agent.git
Binaire
U kunt het binaire bestand uitvoeren zonder dat er een Python-omgeving op uw systeem is geïnstalleerd (bijvoorbeeld, binnen een Docker-container die geen Python bevat). U kunt het uitvoerbare bestand voor uw systeem downloaden door naar de uitgavepagina van het project te gaan.
Repository Setup
Voer de volgende opdracht uit om alle afhankelijkheden te installeren en het project van bron te draaien:
poetry install
Code uitvoeren
Na het downloaden van het uitvoerbare bestand of de Pip-pakkette te hebben geïnstalleerd, kunt u nu Cover-Agent gebruiken om unit tests te genereren en te valideren.
U kunt het vanaf de commandoregel uitvoeren met de volgende opdracht:
cover-agent \
--source-file-path "path_to_source_file" \
--test-file-path "path_to_test_file" \
--code-coverage-report-path "path_to_coverage_report.xml" \
--test-command "test_command_to_run" \
--test-command-dir "directory_to_run_test_command/" \
--coverage-type "type_of_coverage_report" \
--desired-coverage "desired_coverage_between_0_and_100" \
--max-iterations "max_number_of_llm_iterations" \
--included-files "<optional_list_of_files_to_include>"
U kunt de voorbeeldenprojecten binnen dit repository gebruiken om deze code als test uit te voeren.
Command Arguments
-
source-file-path: Pad naar het bestand dat de functies of codeblokken bevat die we willen testen.
-
test-file-path: Pad naar het bestand waar de tests door de agent worden geschreven. Het is het beste om een skelet van dit bestand te maken met minstens één test en de vereiste import-declaraties.
-
code-coverage-report-path: Pad waar het code-overzichtsrapport wordt opgeslagen.
-
test-command: Opdracht om de testen uit te voeren (bijvoorbeeld pytest).
-
test-command-dir: Directory waar de testopdracht moet worden uitgevoerd. Stel dit in op de root of de locatie van uw hoofdbestand om problemen met relatieve importeren te vermijden.
-
coverage-type: Type van de coveragen die moet worden gebruikt. Cobertura is een goed standaardtype.
-
desired-coverage: Coverage doel. Hoe hoger hoe beter, alhoewel 100% vaak onpraktisch is.
-
max-iterations: Aantal keren dat de agent moet proberen om testcode te genereren. Meer iteraties kunnen leiden tot hogere OpenAI-token-gebruik.
-
bijkomende-instructies: Opdrachten om erop toe te zien dat de code in een bepaalde manier geschreven wordt. Bijvoorbeeld, hier specificeren we dat de code moet worden geformatteerd om binnen een testklasse te werken.
Bij het uitvoeren van de opdracht start de agent met schrijven en iteraties op de tests.
Hoe Cover-Agent te gebruiken
Het is nu tijd om Cover-Agent uit te proberen. We zullen een eenvoudige calculator.py app gebruiken om de code coveragen te vergelijken tussen handmatig en geautomatiseerd testen.
Handmatig testen
def add(a, b):
return a + b
def subtract(a, b):
return a - b
def multiply(a, b):
return a * b
def divide(a, b):
if b == 0:
raise ValueError("Cannot divide by zero")
return a / b
Dit is het bestand test_calculator.py geplaatst in de map test.
# tests/test_calculator.py
from calculator import add, subtract, multiply, divide
class TestCalculator:
def test_add(self):
assert add(2, 3) == 5
Om de test coveragen te zien moeten we pytest-cov installeren, een pytest-uitbreiding voor coveragerapportage, zoals eerder werd gemeld.
pip install pytest-cov
Voer de coveragediagnose uit met:
pytest --cov=calculator
Het resultaat laat zien:
Name Stmts Miss Cover
-----------------------------------
calculator.py 10 5 50%
-----------------------------------
TOTAL 10 5 50%
Het bovenstaande resultaat laat zien dat 5 van de 10 uitdrukkingen in calculator.py niet worden uitgevoerd, waardoor er maar 50% code coveraget wordt behaald. Voor een grotere codebasis zal dit een ernstig probleem worden en leiden tot setbacks.
Laten we nu zien of cover-agent beter kan.
Geautomatiseerd testen met Cover-Agent
Om Codium’s Cover-Agent in te stellen, volg deze stappen:
Eerst installeer Cover-Agent:
pip install git+https://github.com/Codium-ai/cover-agent.git
Zorg ervoor dat uw OPENAI_API_KEY is ingesteld in uw omgevingsvariabelen, omdat het nodig is voor de OpenAI API.
Vervolgens schrijft u de commando’s om tests te beginnen genereren in de terminal:
cover-agent \
--source-file-path "calculator.py" \
--test-file-path "tests/test_calculator.py" \
--code-coverage-report-path "coverage.xml" \
--test-command "pytest --cov=. --cov-report=xml --cov-report=term" \
--test-command-dir "./" \
--coverage-type "cobertura" \
--desired-coverage 80 \
--max-iterations 3 \
--openai-model "gpt-4o" \
--additional-instructions "Since I am using a test class, each line of code (including the first line) needs to be prepended with 4 whitespaces. This is extremely important to ensure that every line returned contains that 4 whitespace indent; otherwise, my code will not run."
Dit genereert het volgende code:
import pytest
from calculator import add, subtract, multiply, divide
class TestCalculator:
def test_add(self):
assert(add(2, 3), 5
def test_subtract(self):
"""
Test subtracting two numbers.
"""
assert subtract(5, 3) == 2
assert subtract(3, 5) == -2
def test_multiply(self):
"""
Test multiplying two numbers.
"""
assert multiply(2, 3) == 6
assert multiply(-2, 3) == -6
assert multiply(2, -3) == -6
assert multiply(-2, -3) == 6
def test_divide(self):
"""
Test dividing two numbers.
"""
assert divide(6, 3) == 2
assert divide(-6, 3) == -2
assert divide(6, -3) == -2
assert divide(-6, -3) == 2
def test_divide_by_zero(self):
"""
Test dividing by zero, should raise ValueError.
"""
with pytest.raises(ValueError, match="Cannot divide by zero"):
divide(5, 0)
U kunt zien dat de agent ook tests heeft geschreven die controleren op fouten voor elke edge case.
Nu is het tijd om de coveraging opnieuw te testen:
pytest --cov=calculator
Uitvoer:
Name Stmts Miss Cover
-----------------------------------
calculator.py 10 0 100%
-----------------------------------
TOTAL 10 0 100%
In dit voorbeeld hebben we 100% code coveraging behaald. Voor grotere codebasissen is de procedure relatief hetzelfde. U kunt deze handleiding doorlezen voor een doorlopende walkthrough op een grotere codebasis.
Alhoewel Cover-Agent een significante stap vooruit is, is het belangrijk om te noteren dat deze technologie nog in zijn beginfase is. Doorlopende onderzoek en ontwikkeling zijn crucial voor verdere verfijning en bredere adoptie, en CodiumAI nodigt u uit om uw bijdragen te leveren aan dit open bron tool.
Voordelen van het Open Source Cover-Agent
De open bron natuur van Cover-Agent biedt verschillende voordelen die ervoor moeten zorgen dat de technologie vooruit gaat. Daarvan zijn:
-
Toegankelijkheid: Door zijn open bron karakter kan LLM-gebaseerde testen experimenten worden uitgevoerd en is het toegankelijk voor ontwikkelaars met verschillende achtergrondenDit zal de aantrekkelijkheid voor gebruikers vergroten en leiden tot de ontwikkeling van betere technologie en meer toepassingen..
-
Samenwerking: Ontwikkelaars kunnen bijdragen, suggesties voor verbeteringen aanbieden, nieuwe functies voorstellen en problemen rapporteren. Cover-Agent zal snel groeien en ontwikkelen tot een perfect project voor ontwikkelaars..
-
Transparantie: Informatie over de interne werkingen is beschikbaar en dit bevordert de vertrouwelijkheid en zal uiteindelijk de potentie van de technologie vergroten.
Naast de voordelen van open bron biedt Cover-Agent ontwikkelaars ook een reeks eigen voordelen:
-
Eenvoudige toegang: Ontwikkelaars kunnen gemakkelijk LLM-gebaseerde testen installeren en experimenteren. Dit stelt hen in staat de capaciteiten van de technologie direct en eigenhandig te testen, zonder hun werkproces veel of wel vast tezetten.
-
Aanpassing aan specifieke behoeften: De open-source aard van Cover-Agent staat ontwikkelaars toe de tool aan hun specifieke projectvereisten aan te passen. Dit kan betrekking hebben op het aanpassen van het gebruikte LLM-model, het aanpassen van trainingsdata om beter hun codebasis te reflecteren, of het integreren van Cover-Agent met bestaande testframeworks. Deze niveau van aanpassing geeft ontwikkelaars de macht om de kracht van LLM-gebaseerde testen in een manier te gebruiken die overeenkomt met hun projectbehoeften.
-
Eenvoudige integratie: Het wordt gemakkelijk geïntegreerd met VSCode (een populair code-editor), waardoor integratie met bestaande workflow eenvoudig wordt. U kunt het ook gemakkelijk integreren met bestaande handgeschreven testen.
Hoe kunt u bijdragen aan Cover-Agent?
Het broncodebestand van Cover-Agent is publiek beschikbaar via dit GitHub-repo. Ze bevelen ontwikkelaars van alle achtergronden aan om hun product te testen en bijdragen aan de verdere verbetering en groei van deze nieuwe technologie.
Conclusie
Testverbeterings工具 gebaseerd op LLM (Large Language Model) bevatten een ongeëvenaard potentiële vooruitzicht voor de revolutie in de wijze waarop ontwikkelaars aan unit testing doen. Door de kracht van grote taalmodellen die speciaal zijn getraind op code in te zetten, kunnen deze tools het testaanmaken verstrekkingskrachtig maken, de code-coëfficiënt verbeteren en uiteindelijk de softwarekwaliteit verhogen.
Hoewel de onderzoek van Meta met TestGen-LLM waardevolle inzichten biedt, belemmert de ontbrekende openbaar beschikbare code de breedte van de adoptie en de voortdurende ontwikkeling. Toch heeft Cover-Agent een voorhanden beschikbaar en aanpasbaar oplossing geleverd. Het geeft ontwikkelaars de macht om met LLM-gebaseerde testen te experimenteren en bijdragen aan hun ontwikkeling.
Het potentiële voor Cover-Agent en TestGen-LLM is ongeëvenaard, en de verdere ontwikkeling door bijdragen van ontwikkelaars zal leiden tot een revolutie in het geautomatiseerde testgeneratie.
Meld je aan met mij op LinkedIn en Twitter als je dit vindt dat het nuttig was.
Source:
https://www.freecodecamp.org/news/automated-unit-testing-with-testgen-llm-and-cover-agent/