













الإمر الأساسي في تطوير البرمجيات هو إنشاء تجارب الوحدات واضحة وفعالة وتعمل في الواقع أثناء عملية تطوير البرمجيات. تجارب الوحدات تفصل العناصر البرمجية الفردية وتؤكد أنها تعمل كما هو مقرر.
تجارب الوحدات الفعالة لا تعترف فقط بالأخطاء بل تساعدك أيضًا على الإطمئنان بأن كودك قابل للصيانة وقابل للتكاليف. ولكن يتطلب الأمر وقتا ومواردا لإنشاء تجميعة واسعة من تجارب الوحدات يدويا.
لقد حدثت العديد من التطورات الأخيرة في الذكاء الاصطناعي التي تعد بمساعدة في توطين عمليات تطوير تجارب الوحدات. في فبراير، أطلق محققون في ميتا مقالة عن تحسين تجارب الوحدة التلقائية باستخدام نماذج اللغات الكبيرة. وقد أعدتت هذه الطريقة الإبتكارية لتوطين تجارب الوحدة.
ألهمت أبحاثهم أداة جديدة تُدعى TestGen-LLM التي تستكشف إمكانية إستخدام نماذج اللغات الكبيرة لتحليل التجارب الوحدية القائمة وتحسينها لزيادة تغطية الكود.
على الرغم من أن لم يتم إصدار الكود لـ TestGen-LLM، سأقدم في هذه المقالة بدائل مفتوحة المصدر الملهمة من أبحاثهم. ستتعلم كيفية إنشاء مجموعات التجارب ولماذا هي أفضل من معظم نماذج اللغات الكبيرة، وأين يمكنك الحصول على هذه التكنولوجيا وبدء تجربتها.
جدول المحتويات
TestGen-LLM لـMeta
تتلاشى TestGen-LLM لـMeta مهمة كتابة الاختبارات الوحدية المتلاشية بواسطة القوة النموذجات اللغوية الكبيرة (LLM). قد تواجه النموذجات اللغوية العامة مثل Gemini أو ChatGPT صعوبات في قضية الكود الوحدي للاختبارات، التوجيه النموذجي للاختبارات، وتوليد الاختبارات التي لا تضيف قيمة. ولكن TestGen-LLM مخصص خصيصا للاختبارات الوحدية.
هذا التخصص يسمح له بفهم التعقيدات لبنية الكود ومنطق الاختبار، مما يؤدي إلى إنشاء مجموعات الاختبارات الموجهة وتوليد الاختبارات التي تضيف القيمة وتزيد التغطية الكودية.
TestGen-LLM قادر على تقييم الاختبارات الوحدية وتحديد المناطق للتحسين. يحقق هذا من خلال فهمه للأنماط الشائعة للاختبارات التي تم تدريبها عليها. ولكن توليد الاختبارات لوحدها لا يكفي للحصول على تغطية كافية للكود.
قام الباحثون في Meta بإنشاء حواجز داخل TestGen-LLM لضمان فعالية الاختبارات التي يكتبها. تعمل هذه الحواجز، التي يشار إليها بـالفلاتر، كآلية لرقابة الجودة. تقضي على الاقتراحات التي:
-
لن تتم ترجمتها
-
تفشل بدوام، أو
-
لا تحسن في الواقع التغطية الكودية (الاقتراحات التي تغطيها الاختبارات الأخرى بالفعل).
كيف تعمل TestGen-LLM؟
TestGen-LLM يستخدم منهجية تدعى “الهندسة البرمجية بناءة واثباتها” (Assured LLMSE). TestGen-LLM ببساطة يتم تكسير في الصنف التجاري الموجود بالقيود الاضافية للأختبارات، محافظة على جميع الأختبارات الحالية وبذلك تضمن عدم ظهور التردد.
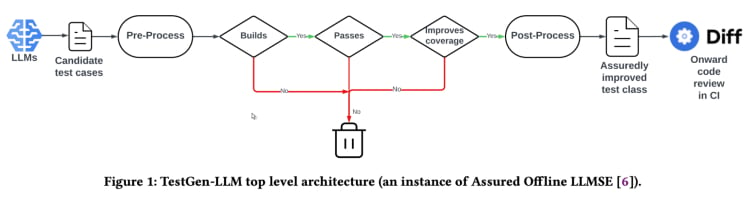
التسلسل الأساسي لتوليد الاختبارات(من وثيقة TestGen_LLM)
TestGen-LLM يولد مجموعة من الاختبارات ثم يقوم بتصفية الاختبارات التي لا تنتج ويترك أي تعامل لا ينجح. وأخيرًا يتم تخلية تلك التي لا تزيد التغطية البرمجية.
بعد استخدام TestGen-LLM لتلبية مجموعة اختبارات تلقائيًا، استخدمت Meta مراجع بشري للموافقة أو الرفض للاختبارات التي تم توليدها بواسطة البرنامج وحصلت على معدل اقتابلات 73% في أفضل الحالات المراجعت عنها.
ووفقًا للوثيقة، يولد TestGen-LLM اختبار واحد في كل تلك المرات الذي يأخذ ثم يضيف إلى صنف اختبار قد كتب مسبقًا بواسطة مطور. ولكنه لا يتم توليد الاختبارات بالضبط لأي قواعد اختبار معينة.
تم إظهار فعالية TestGen-LLM في مسابقات اختبار البرمجيات الداخلية في Meta. هناك ، تم استخدام الأداة لتحليل الصنف الاختباري الحالي وإقتراح التحسينات. النتائج كانت مبهرة:
“75% من اختبارات TestGen-LLM تنشأ بشكل صحيح، و 57% ينجحون بشك
كما أن الإرشادات من TestGen-LLM قد تم تقديرها كمفيدة ومتعلقة بالمطورين الذين شاركوا في الاختبارات التوغوغية.
تنفيذ مصدر مفتوح (Cover-Agent)
تحقيق TestGen-LLM من Meta يمكن أن يغير جذرياً الاختبارات الوحدية وتوليد الاختبارات التلقائية. ستساعد الأداة على تحسين تغطية الشفرة وتسريع إنشاء الاختبارات باستخدام LLM المدربة خصيصاً على الشفرة. ولكن هذه التكنولوجيا ليست متاحة لأي أحد، لأن الشفرة لـ TestGen-LLM لم تُنشر.
مطورون يهتمون بهذه التكنولوجيا سيكونون عابرون بسبب عدم وجود الشفرة على مستوى العامة. بعد كل شيء، يوفر دراسة TestGen-LLM من Meta نظرة إلى المستقبل الذي يمكن أن يصبحه الاختبارات التلقائية.
من الملذاذ جداً الإمكانية للغوص في العمل الداخلي لأحدث التكنولوجيا، وفهم سياساتها في التصميم القراري، وربما حتى المساهمة في تشكيل تطورها. ولكن بينما يعتبر عدم وجود الشفرة من Meta عائقاً، يوجد تنفيذ مصدر مفتوح يُدعى Cover-Agent يمكن أن يعد مثالياً بديلاً.
Cover-Agent لـ CodiumAI هو أول تنفيذ مفتوح لأداة الاختبار التلقائية القائمة على TestGen-LLM. مستلهماً من أبحاث Meta، يصبح الآن Cover-Agent في جبهة تطورات الاختبارات الوحدية التي تقوم بواسطة الذكاء الاصطناعي في المصادر المفتوحة.
لماذا الحاجة ل LLM محددة للاختبار؟
بما أن معظم LLM (مثل ChatGPT و Gemini) قادرة على توليد الاختبارات، فما الضرورة للتكنولوجيا الجديدة؟
تم إنشاء Cover-Agent و TestGen-LLM ليكونوا الخطوة التالية في تطور الاختبارات الوحدية الآمنة والفعالة. وهما يهدفان إلى تجنب الأخطاء الشائعة التي يواجهها المطورون عند إنتاج الاختبارات مع LLMs مثل:
-
تخيل LLM
-
إنتاج اختبارات لا تضيف قيمة
-
إنتاج اختبارات تفصل بعض أجزاء الكود، مما يؤدي إلى تغطية كود منخفضة
لتغلب على تلك التحديات (بالتحديد للاختبارات الاحتمالية للوحدات) جاء باحثو TestGen-LLM بمعايير التالية التي يتم بموجبها تقديم الاختبارات المنتجة قبل أن يتم قبول الاختبار:
-
هل يتم ترجمة الاختبار المنتج وتشغيله بشكل صحيح؟
-
هل يزيد الاختبار في تغطية الكود؟
-
هل يضيف قيمة؟
-
هل يلزم الشروط الإضافية التي قد يكون لدينا؟
هذه هي الأسئلة والقضايا الأساسية التي يجب أن يحلها الاختبار المنتج قبل أن يعتبر تطوراً على التكنولوجيا القائمة. يوفر Cover-Agent اختبارات تحل هذه الأسئلة بدرجة عالية للغاية.
كيف يعمل Cover-Agent؟
Cover-Agent هو جزء من مجموعة أوسع من الأدوات المصممة لأتمتة إنشاء اختبارات الوحدات لمشاريع البرمجيات. باستخدام نموذج الذكاء الاصطناعي التوليدي TestGen-LLM، يهدف إلى تبسيط وتسريع عملية الاختبار، مما يضمن تطوير برمجيات عالية الجودة.
يتكون النظام من عدة مكونات:
- منفذ الاختبار: ينفذ الأوامر أو النصوص لتشغيل مجموعة الاختبار وتوليد تقارير تغطية الكود.
- محلل التغطية: يتحقق من زيادة تغطية الكود عند إضافة الاختبارات، مما يضمن أن الاختبارات الجديدة تساهم في فعالية الاختبار الكلية.
- باني الموجه: يجمع البيانات الضرورية من قاعدة الشيفرة ويبني الموجه الذي سيتم تمريره إلى نموذج اللغة الكبير (LLM).
- مُستدعي الذكاء الاصطناعي: يتفاعل مع نموذج اللغة الكبير (LLM) لتوليد الاختبارات بناءً على الموجه المقدم.
تعمل هذه المكونات معًا مع TestGen-LLM لتوليد اختبارات مضمونة لتحسين قاعدة الشيفرة الحالية فقط.
إستخدام كوвер-أجنت
المتطلبات
يجب أن يكون لديك الحاجة إلى المتطلبات التالية قبل بدء استخدام كوвер-أجنت:
-
OPENAI_API_KEYمعرف في متغيرات البيئة الخاصة بك، وهو مطلوب للتواصل معOpenAI API. -
أداة تغطية الكود: يتطلب أداة العمل بشكل صحيح تقرير تغطية الكود Cobertura XML. على سبيل المثال، في Python يمكنك استخدام
pytest-cov.أضف خيار--cov-report=xmlعند تشغيل Pytest.
التثبيت
إذا كنت تشغل كوвер-أجنت مباشرة من المستودع، ستحتاج أيضاً إلى:
-
Python مثبت على نظامك.
-
بويتري مثبت لإدارة اعتمادات حزمة Python. يمكنك العثور على تعليمات التثبيت لبويتري هنا.
وقت التشغيل المستقل
تستطيع تثبيت Cover-Agent كحزمة Python Pip أو تشغيله كبرنامج مستقل.
Python Pip
لتثبيت الحزمة الخاصة بـ Python Pip مباشرة من GitHub، قم بتشغيل الأمر التالي:
pip install git+https://github.com/Codium-ai/cover-agent.git
الثنائي
يمكنك تشغيل الثنائي دون تثبيت بيئة Python على النظام (على سبيل المثال، داخل محاكي دوكر الذي لا يحتوي Python). يمكنك تنزيل الإصدار المناسب لنظامك بالذهاب إلى صفحة الإصدار للمشروع.
إعداد المستودع
قم بتشغيل الأمر التالي لتثبيت جميع الإعتمادات وتشغيل المشروع من المصدر:
poetry install
تشغيل الكود
بعد تحميل البرنامج الثنائي أو تثبيت الحزمة الخاصة بـ Pip، يمكنك الآن تشغيل Cover-Agent لتوليد وتحقيق الاختبارات الوحدية.
قم بتشغيله من سطر الأوامر باستخدام الأمر التالي:
cover-agent \
--source-file-path "path_to_source_file" \
--test-file-path "path_to_test_file" \
--code-coverage-report-path "path_to_coverage_report.xml" \
--test-command "test_command_to_run" \
--test-command-dir "directory_to_run_test_command/" \
--coverage-type "type_of_coverage_report" \
--desired-coverage "desired_coverage_between_0_and_100" \
--max-iterations "max_number_of_llm_iterations" \
--included-files "<optional_list_of_files_to_include>"
يمكنك استخدام المشاريع الأمثلة في هذا المستودع لتشغيل هذا الكود كاختبار.
معاملات الأمر
-
source-file-path: المسار للملف الذي يحتوي على الوظائف أو الكود الذي نريد إختباره.
-
test-file-path: المسار للملف الذي سيكتب فيه الأجنبي الاختبارات. من الأفضل إنشاء هيكل لهذا الملف بأقل من تجربة والبيانات اللازمة للإستيراد.
-
code-coverage-report-path: المسار الذي يُحفظ فيه تقرير تغطية الكود.
-
test-command: الأمر لتشغيل الاختبارات (مثل pytest).
- test-command-dir: المجلد الذي يجب تشغيل الأمر الاختباري فيه. قم بتعيين هذا إلى الجذر أو موقع ملفك الرئيسي لتجنب مشاكل مع الاستيراد النسبي.
- coverage-type: نوع التغطية المستخدم. Cobertura هو الافضل بشكلافتراضي.
- desired-coverage: هدف التغطية. الأعلى أفضل، رغم أن 100% غالبا ما غير ممكن.
- max-iterations: عدد المحاولات التي يجب على العميل إعادة محاولة لتوليد شيفرة الاختبار. المزيد من التكرارات قد يؤدي إلى زيادة استخدام رموز OpenAI.
-
additional-instructions: تلك الإشارات التي تحافظ على كتابة الكود بطريقة محددة. على سبيل المثال، نحن هنا نحدد أن الكود يجب أن يُهيأ ليعمل داخل فئة اختبارية.
عند تشغيل الأمر، يبدأ الوكيل بكتابة وتكرار الاختبارات.
كيفية استخدام Cover-Agent
حان الوقت لاختبار Cover-Agent. سنستخدم تطبيق calculator.py بسيط لمقارنة تغطية الكود للاختبارات اليدوية والتلقائية.
الاختبار اليدوي
def add(a, b):
return a + b
def subtract(a, b):
return a - b
def multiply(a, b):
return a * b
def divide(a, b):
if b == 0:
raise ValueError("Cannot divide by zero")
return a / b
هذا هو test_calculator.py الموجود في مجلد الاختبار.
# tests/test_calculator.py
from calculator import add, subtract, multiply, divide
class TestCalculator:
def test_add(self):
assert add(2, 3) == 5
لرؤية تغطية الاختبار، يجب علىنا تثبيت pytest-cov، وهو إضافة لpytest لتقارير التغطية كما ذكر مسبقا.
pip install pytest-cov
شغل التحليل التغطية ب:
pytest --cov=calculator
ستظهر الخرج:
Name Stmts Miss Cover
-----------------------------------
calculator.py 10 5 50%
-----------------------------------
TOTAL 10 5 50%
الخرج أعلاه يظهر أن 5 من 10 البيانات في calculator.py لم تنفذ، مما يؤدي إلى تغطية كود 50% فقط. لقاعدة بيانات كبيرة سيصبح هذه قضية خطيرة وتؤدي إلى الخطوة الخلفية.
الآن دعونا نرى إذا كان cover-agent يمكن أن يفعل أفضل.
الاختبار التلقائي بواسطة Cover-Agent
لإعداد Cover-Agent لـ Codium، إتبع الخطوات التالية:
أولاً، تثبيت Cover-Agent:
pip install git+https://github.com/Codium-ai/cover-agent.git
تأكد من أن مفتاح OpenAI_API_KEY معين في مادات بيئة محيط، وهو مطلوب للAPI OpenAI.
من ثم، كتابة الأوامر للبدء في توليد الاختبارات في الطرفال:
cover-agent \
--source-file-path "calculator.py" \
--test-file-path "tests/test_calculator.py" \
--code-coverage-report-path "coverage.xml" \
--test-command "pytest --cov=. --cov-report=xml --cov-report=term" \
--test-command-dir "./" \
--coverage-type "cobertura" \
--desired-coverage 80 \
--max-iterations 3 \
--openai-model "gpt-4o" \
--additional-instructions "Since I am using a test class, each line of code (including the first line) needs to be prepended with 4 whitespaces. This is extremely important to ensure that every line returned contains that 4 whitespace indent; otherwise, my code will not run."
هذه الخطوة تولد التالي الكود:
import pytest
from calculator import add, subtract, multiply, divide
class TestCalculator:
def test_add(self):
assert(add(2, 3), 5
def test_subtract(self):
"""
Test subtracting two numbers.
"""
assert subtract(5, 3) == 2
assert subtract(3, 5) == -2
def test_multiply(self):
"""
Test multiplying two numbers.
"""
assert multiply(2, 3) == 6
assert multiply(-2, 3) == -6
assert multiply(2, -3) == -6
assert multiply(-2, -3) == 6
def test_divide(self):
"""
Test dividing two numbers.
"""
assert divide(6, 3) == 2
assert divide(-6, 3) == -2
assert divide(6, -3) == -2
assert divide(-6, -3) == 2
def test_divide_by_zero(self):
"""
Test dividing by zero, should raise ValueError.
"""
with pytest.raises(ValueError, match="Cannot divide by zero"):
divide(5, 0)
يمكنك رؤية أيضًا أن العميل أيضًا أكتب اختبارات تفقد الأخطاء لأي حالات الحاجة الخارجية.
الآن يوم الآن لإختبار الغطاء مجددًا:
pytest --cov=calculator
الخريطة:
Name Stmts Miss Cover
-----------------------------------
calculator.py 10 0 100%
-----------------------------------
TOTAL 10 0 100%
في هذا المثال أنجزنا 100% من غطاء البرمجيات. وبالنسبة للأساسات الكبيرة للبرمجيات، تلك الإجراءات نفسها. يمكنك قراءة هذه الدراسة للمساعدة في إجراء تجربة على أساسة أكبر.
بينما Cover-Agent يمثل خطوة هامة في المساءلة، ولكن من المهم للملاحظة أن هذه التكنولوجيا مازالت في مراحلها المبكرة. لا يتم بحث وتطوير أكثر لتنجيم وتوسيع الاستخدام ويدعو codiumAI لإشرافك بتساهمك في هذه الأداة المفتوحة المصدر.
المزايا من Cover-Agent المفتوح المصدر
تعميمًا توفر طبيعة المصدر المفتوح لCover-Agent مزايا عدة التي يمكن أن تساعد في تقدم التكنولوجيا. ومن بينها:
- الوصولية: طبيعتها المفتوحة المصدر تسمح للتجربات التساؤلية والتجريبية القائمة على LLM ويمكن الوصول للمطورين مع خلفيات مختلفة هذا سيزيد العدد من المستخدمين وسيقود إلى تطوير ت
-
التعاون: يستطيع المطورون المساهمة وإقتراح تحسينات، وإقتراح ميزات جديدة وإبلاغ المشاكل. ستنمو وتتطوير Cover-Agent بسرعة ليصبح مشروعا مثاليا للمطورين..
-
الشفافية: تتوافر معلومات عن العمليات الداخلية وهذا يعزز الثقة وسيزيد بذلك إمكانيات التكنولوجيا.
بالإضافة إلى مزايا المصدر المفتوح، توفر Cover-Agent للمطورين مجموعة قوية من الفوائد الخاصة به..
-
الوصول السهل: يمكن للمطورين تثبيت وتجربة التجربة المبنية على LLM بسهولة. هذا يسمح بإستكشاف مباشر وفوري لقدرات التكنولوجيا دون إزعاج كبير في سير عملهم.
-
التخصيص للحاجات المحددة: تتيح جوهر مصدرها المفتوح لبرنامج Cover-Agent للمطورين تكييف الأداة لتلك الحاجات الخاصة بمشروعهم. قد يتمحور هذا في تعديل نموذج LLM المستخدم، أو تعديل بيانات التدريب لتعكس أفضل مجموعة الشفرات الخاصة بهم، أو دمج Cover-Agent مع إطارات الاختبار التي توجد بالفعل. هذا المستوى من التخصيص يمكن للمطورين استغلال قوة اختبار LLM بطريقة تتماشى مع حاجات مشروعهم.
-
التكامل السهل: يمكن دمجه بسهولة مع VSCode (محرر الشفرات الشائع) الذي يجعل التكامل مع جردتهم العملية القائمة سهلا. يمكنك أيضًا دمجه بسهولة مع الاختبارات المكتوبة بواسطة البشر.
كيف يمكنك المساهمة في Cover-Agent؟
تتوفر من مصدر واوعي البرمجيات مفتوح المصدر من خلال هذا المخزون GitHub. يشجعون المطورين من جميع الأحيان على اختبار منتجهم والمساهمة لتحسين وتوسيع هذه التكنولوجيا الجديدة بشكل أكبر.
الختام
الأدوات المبنية على اختبارات التطوير التي تم تدريبها على نماذج كبيرة من اللغة تم تدريبها على البرمجيات تمتلك قدرات كبيرة لتغيير طريقة مواجهة المطورين للاختبارات الوحدية. من خلال تسخير قوة النماذج الكبيرة التي تم تدريبها على البرمجيات، يمكن لهذه الأدوات تسهيل إنشاء الاختبارات، وتحسين تغطية البرمجيات، وفي النهاية تحسين جودة البرمجيات.
بينما يقدم بحث Meta بواسطة TestGen-LLM معلومات قيمة، يقع عدم توفر البرمجيات المكتوبة بشكل عام يحدد تعقيد وتطور التبني الواسع. لحسن الحظ، قدم Cover-Agent حلولاً متاحة وتختزل بالفعل وتمكين المطورين للتجربة مع اختبارات مبنية على النماذج الكبيرة والمساهمة في تطويرها.
توفر القدرة ل TestGen-LLM وCover-Agent كبيرة والتطوير المتاح من خلال المساهمات من المطورين سيقود إلى أداة ثورية ستغير التوليد الآلي للاختبارات بشكل دائم.
Source:
https://www.freecodecamp.org/news/automated-unit-testing-with-testgen-llm-and-cover-agent/